Co-presented with Francesca Lazzeri at Data+AI Summit 2021
In this session, we show how to leverage CORD dataset, containing more than 400000 scientific papers on COVID and related topics, and recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease.
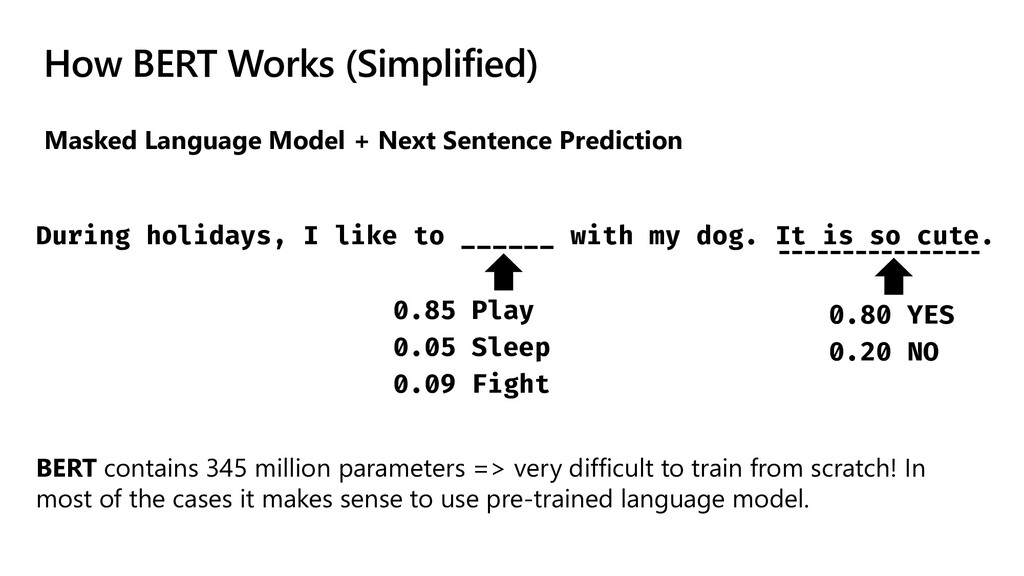
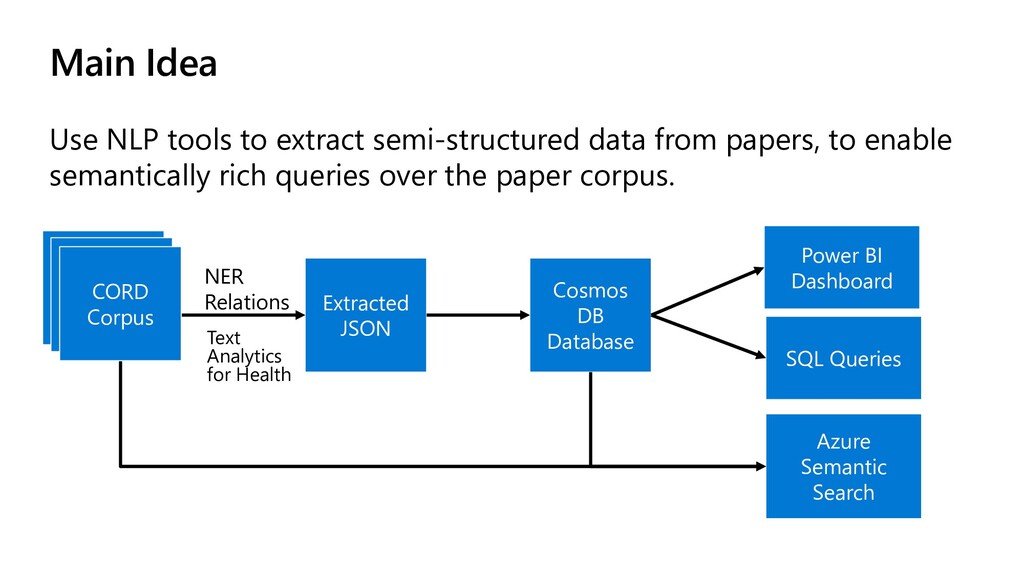
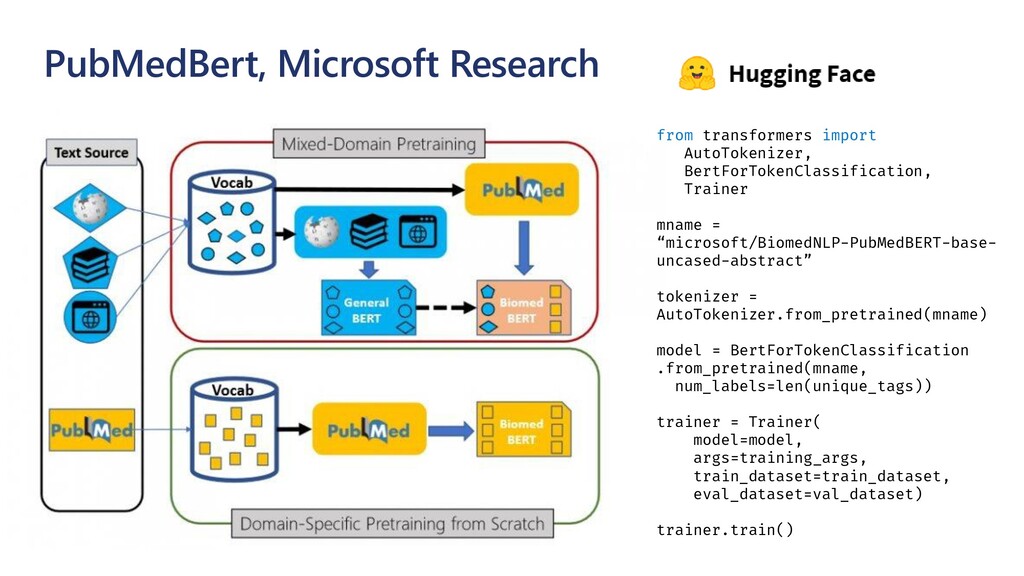
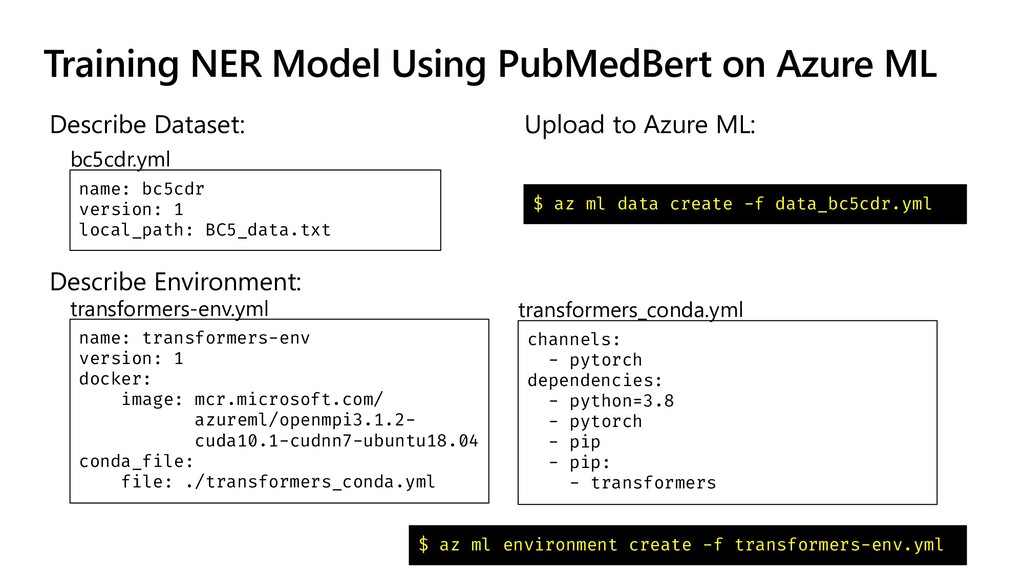
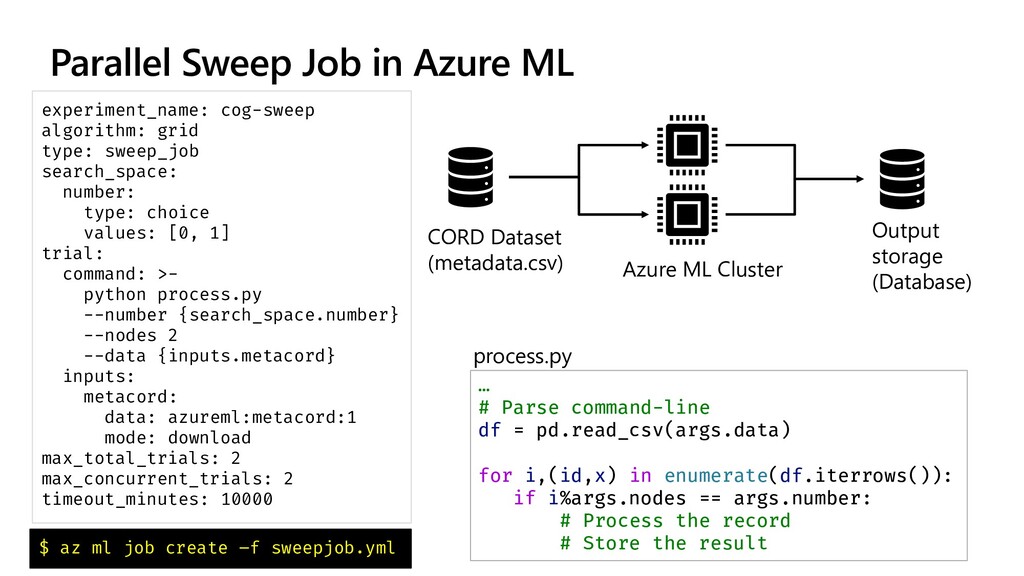
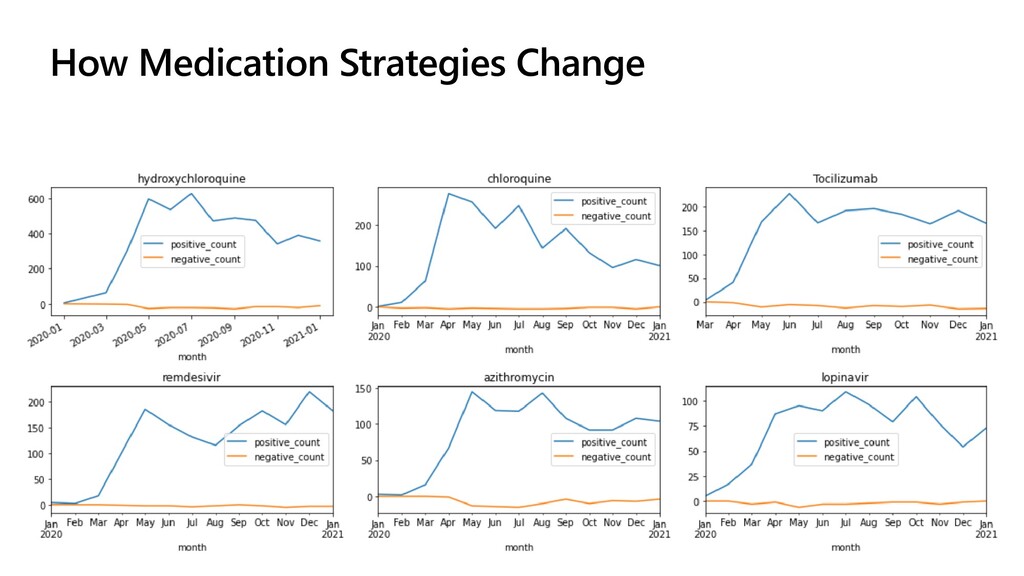
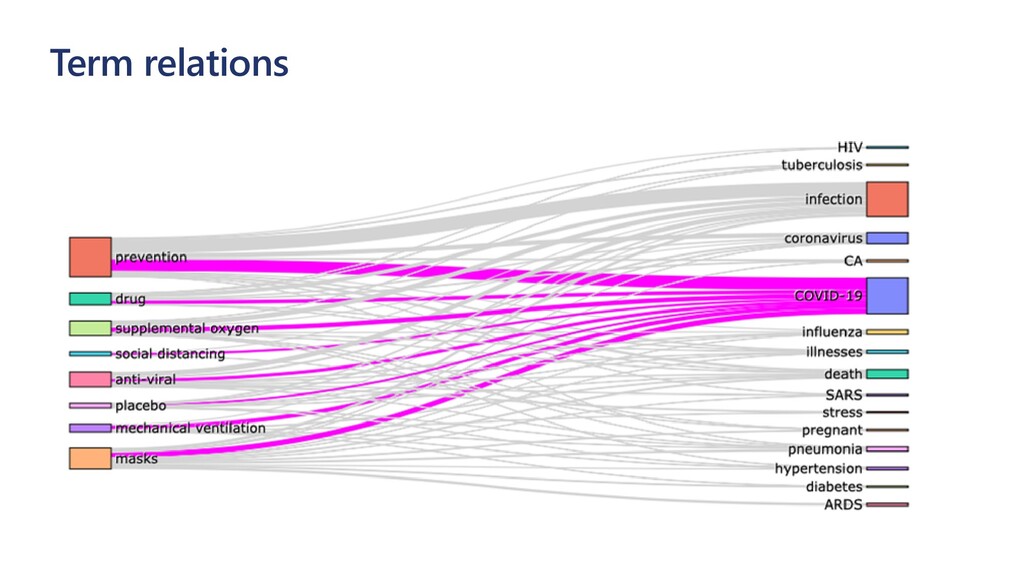
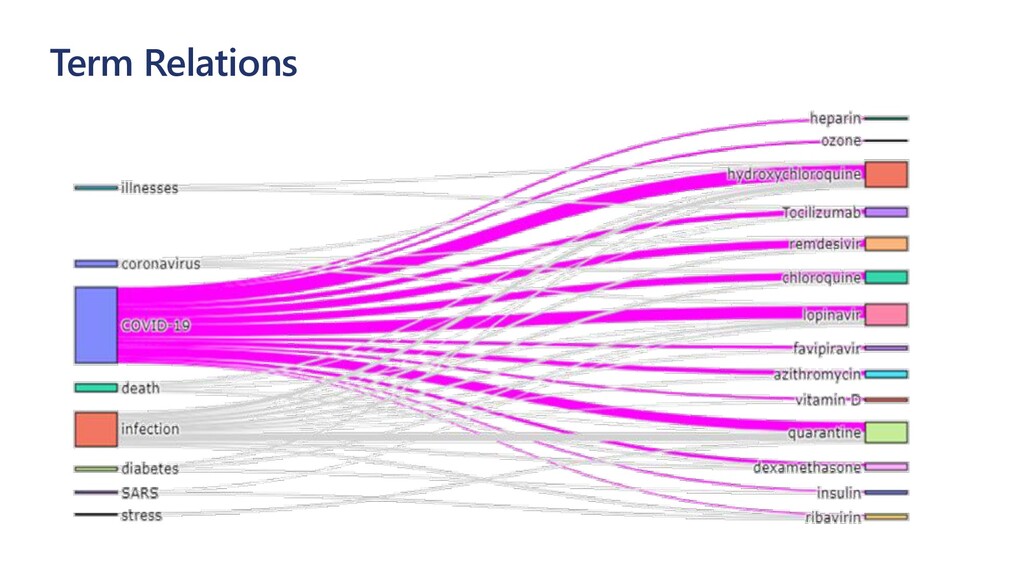
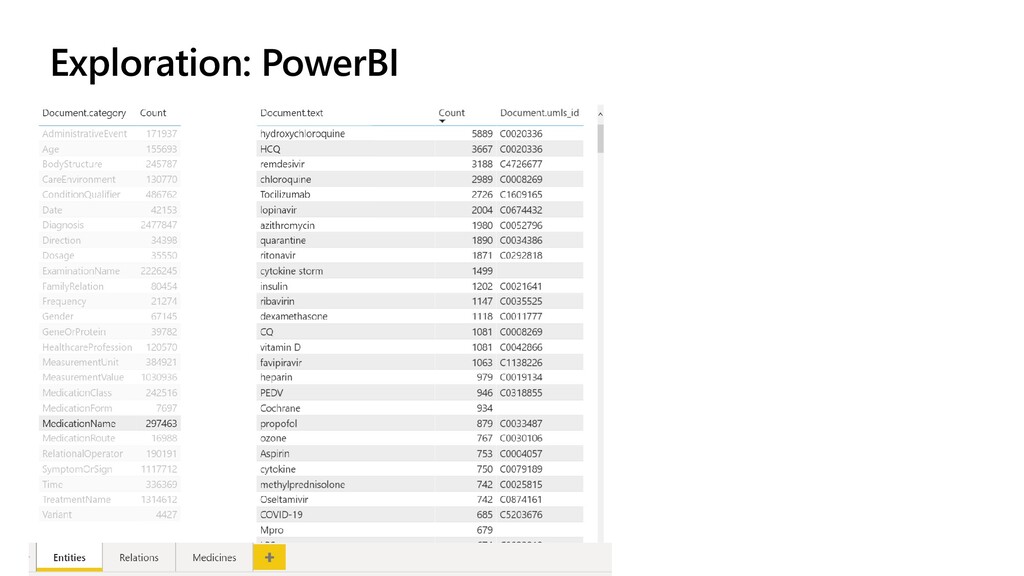
The idea explored in our talk is to apply modern NLP methods, such and named entity recognition (NER) and relation extraction to article’s abstracts (and, possibly, full text), to extract some meaningful insights from the text, and to enable semantically rich search over the paper corpus. We first investigate how to train NER model using Medical NER dataset from Kaggle, and specialized version of BERT (PubMedBERT) as a feature extractor, to allow automatic extraction of such entities as medical condition names, medicine names and pathogens. Entity extraction alone can provide us with some interesting findings, such as how approaches to COVID treatment evolved with time, in terms of mentioned medicines. We demonstrate how to use Azure Machine Learning for training the model.
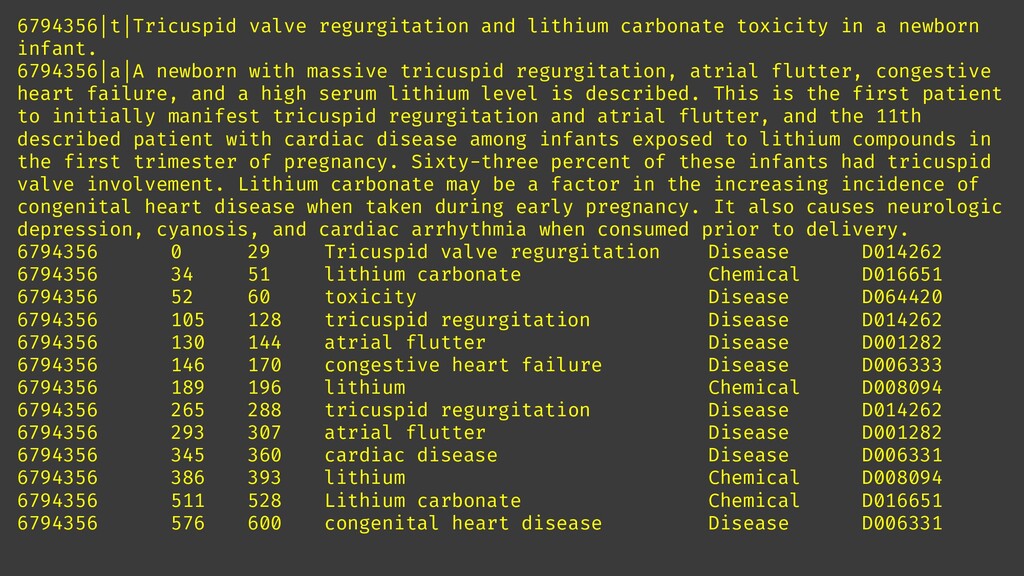
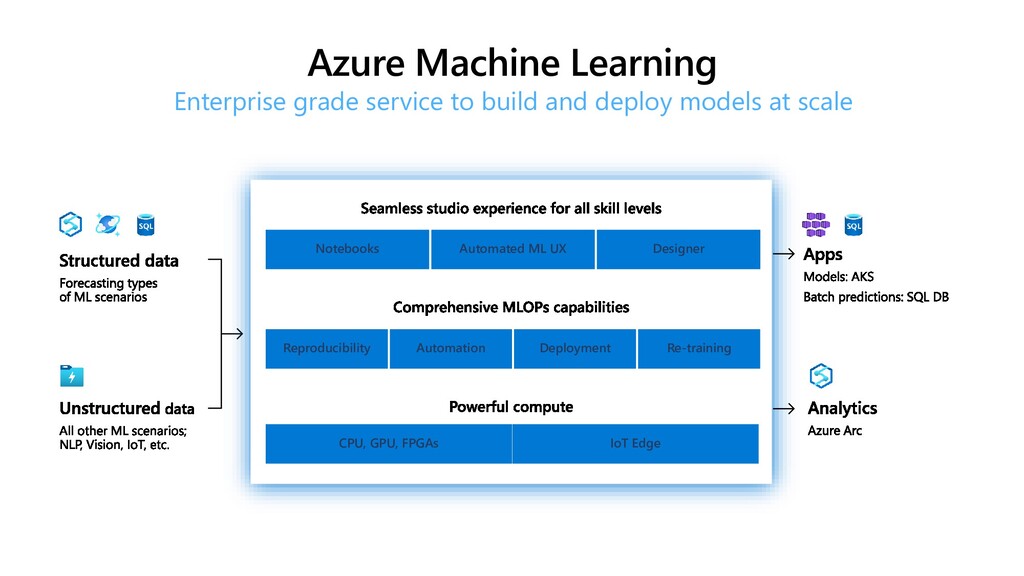
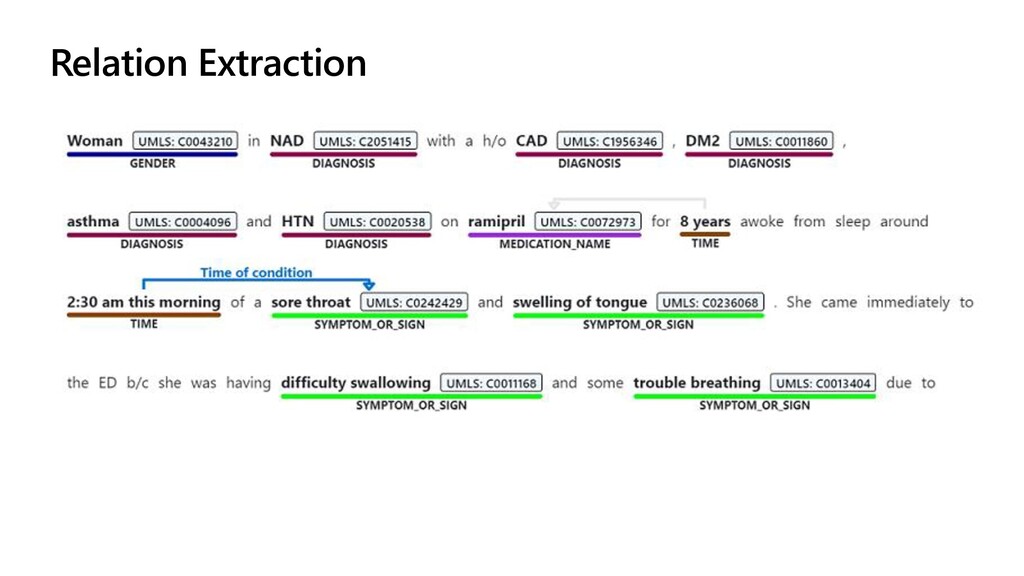
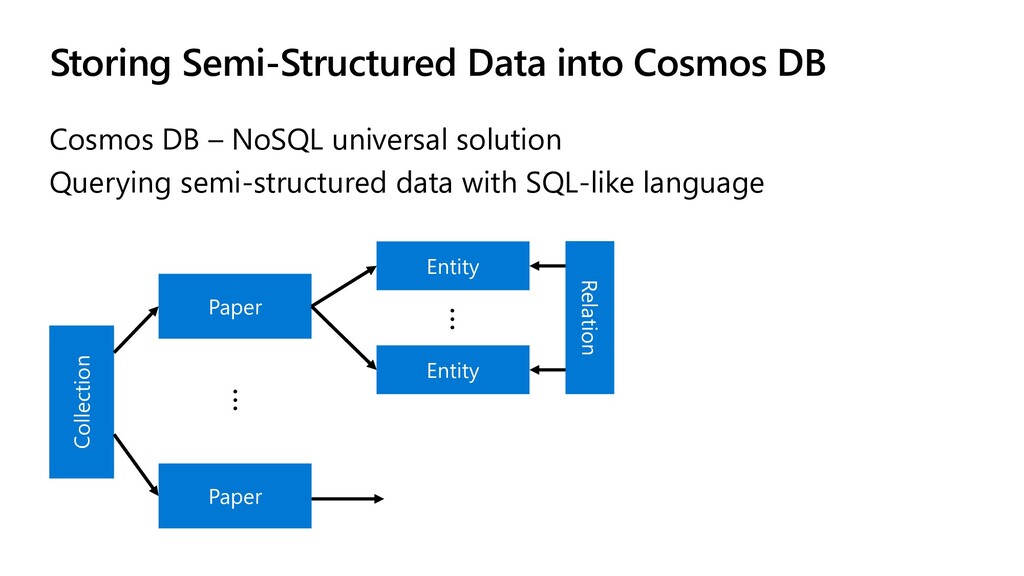
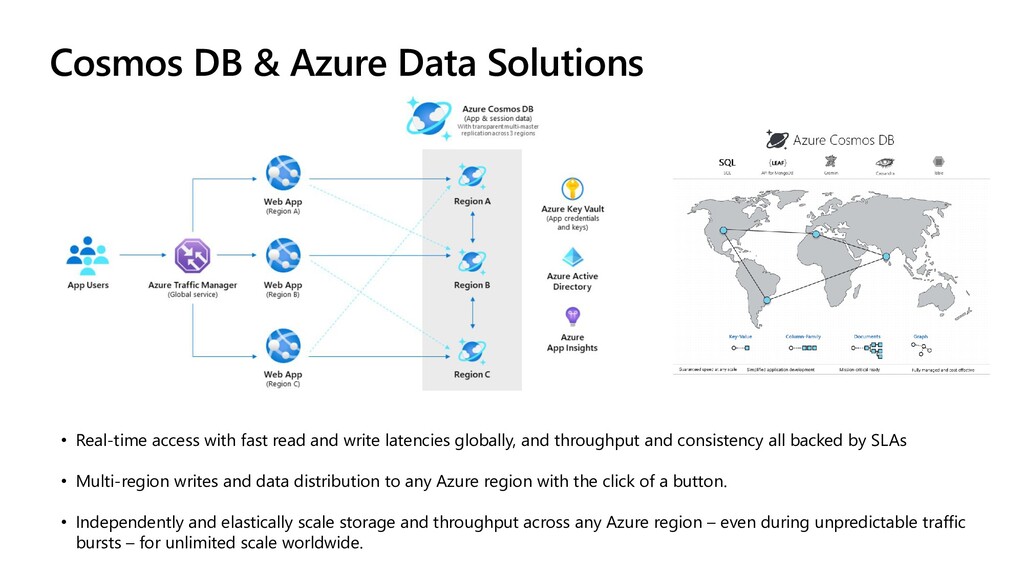
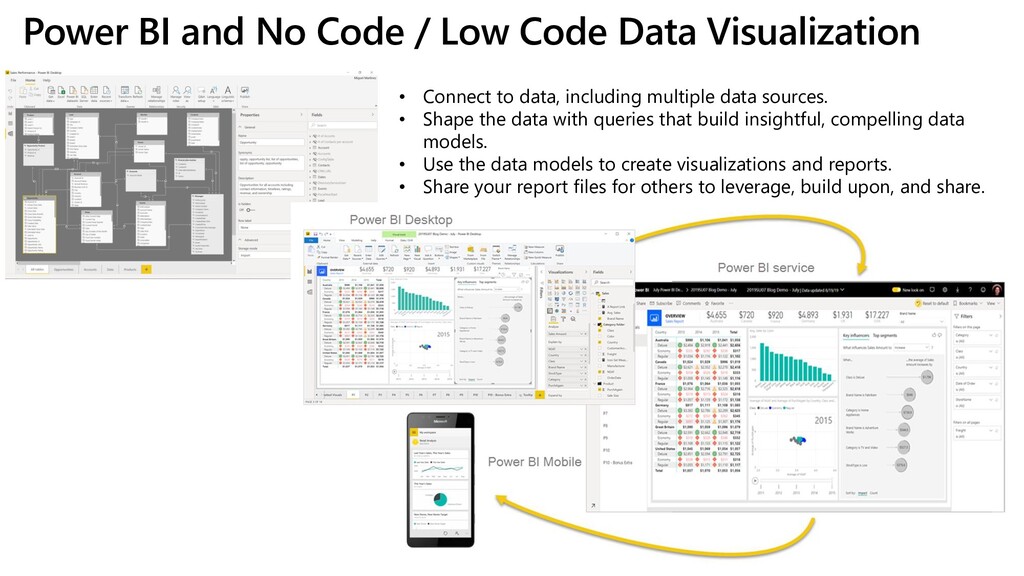
To take this investigation one step further, we also investigate the usage of pre-trained medical models, available as Text Analytics for Health service on the Microsoft Azure cloud. In addition to many entity types, it can also extract relations (such as the dosage of medicine provisioned), entity negation, and entity mapping to some well-known medical ontologies. We investigate the best way to use Azure ML at scale to score large paper collection, and to store the results.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}