A single line of code can shape an organization's financial future. Drawing inspiration from five real examples of million-dollar lines of code, we will challenge conventional views on engineering's pivotal role in cloud cost optimization.
Prepare for a plot twist, however: premature cost optimization can become a distraction and inadvertently hinder innovation. While unchecked cloud costs can cause another kind of distraction (one where you run out of money), pursuing cost reduction incorrectly or at the wrong time can be fatal to market growth and finding that elusive product-market fit.
Done right, success lies in cultivating a deeper understanding of the economic implications of our efforts as engineers, allowing us to find the balance between user delight, innovation, and cost-efficient code. By venturing into the heart of these million-dollar lines of code and the forces that created them, we uncover the right timing and approach for engineering cost optimization and how to use cost efficiency metrics as powerful constraints that drive innovation, accelerate growth, and engineer profit.
{kind=link}
{kind=link}
{kind=link}
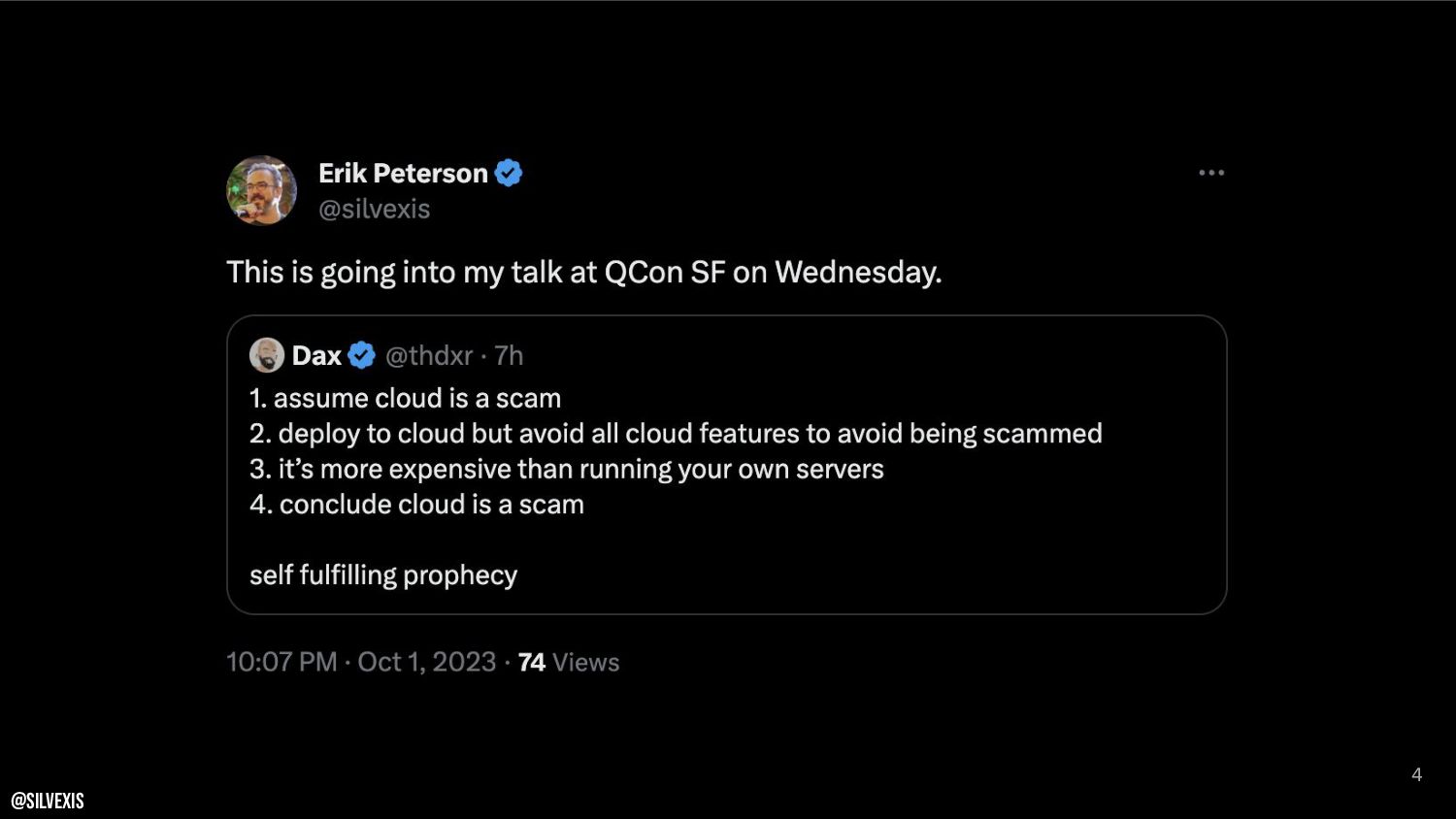{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
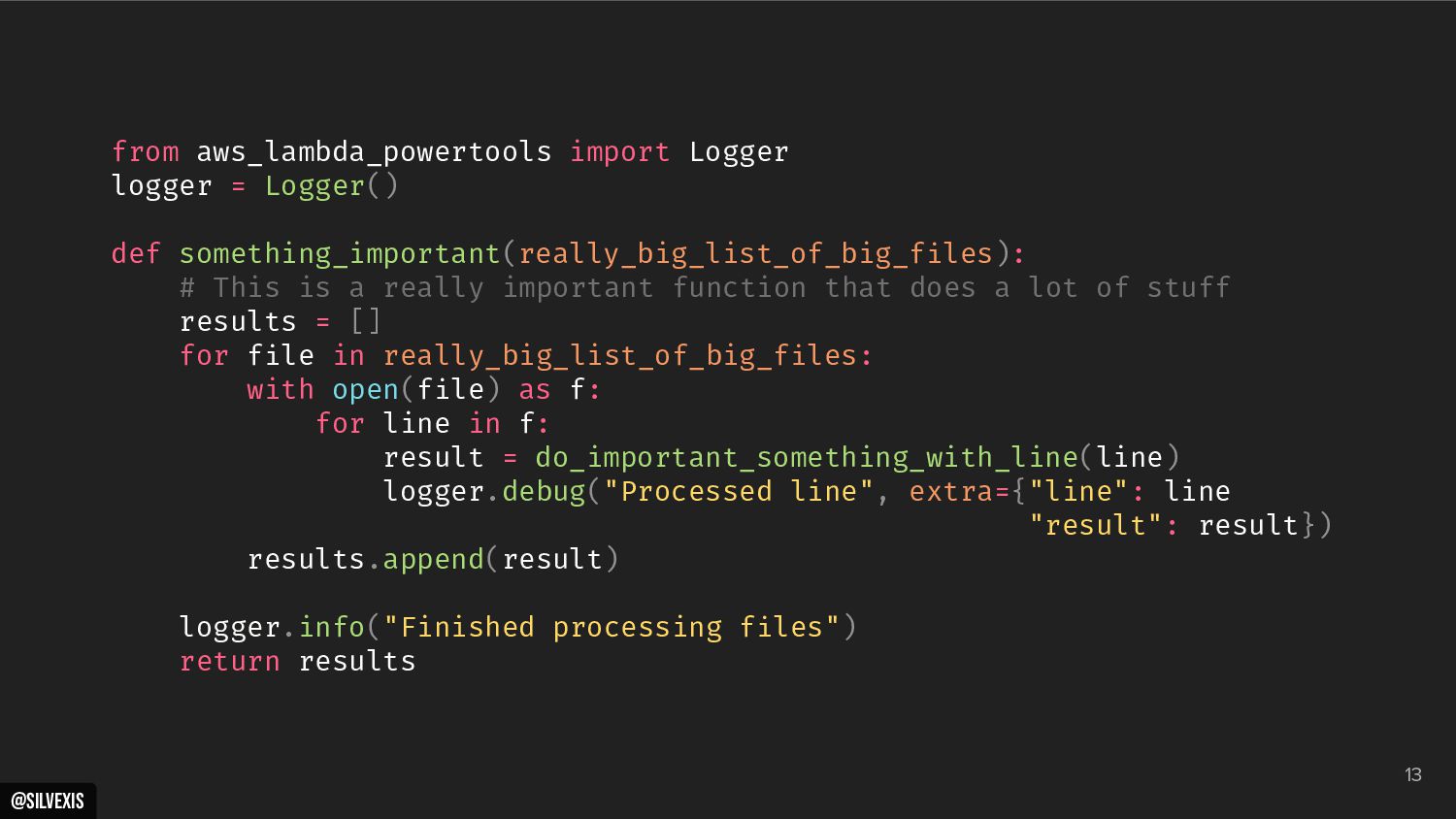{kind=link}
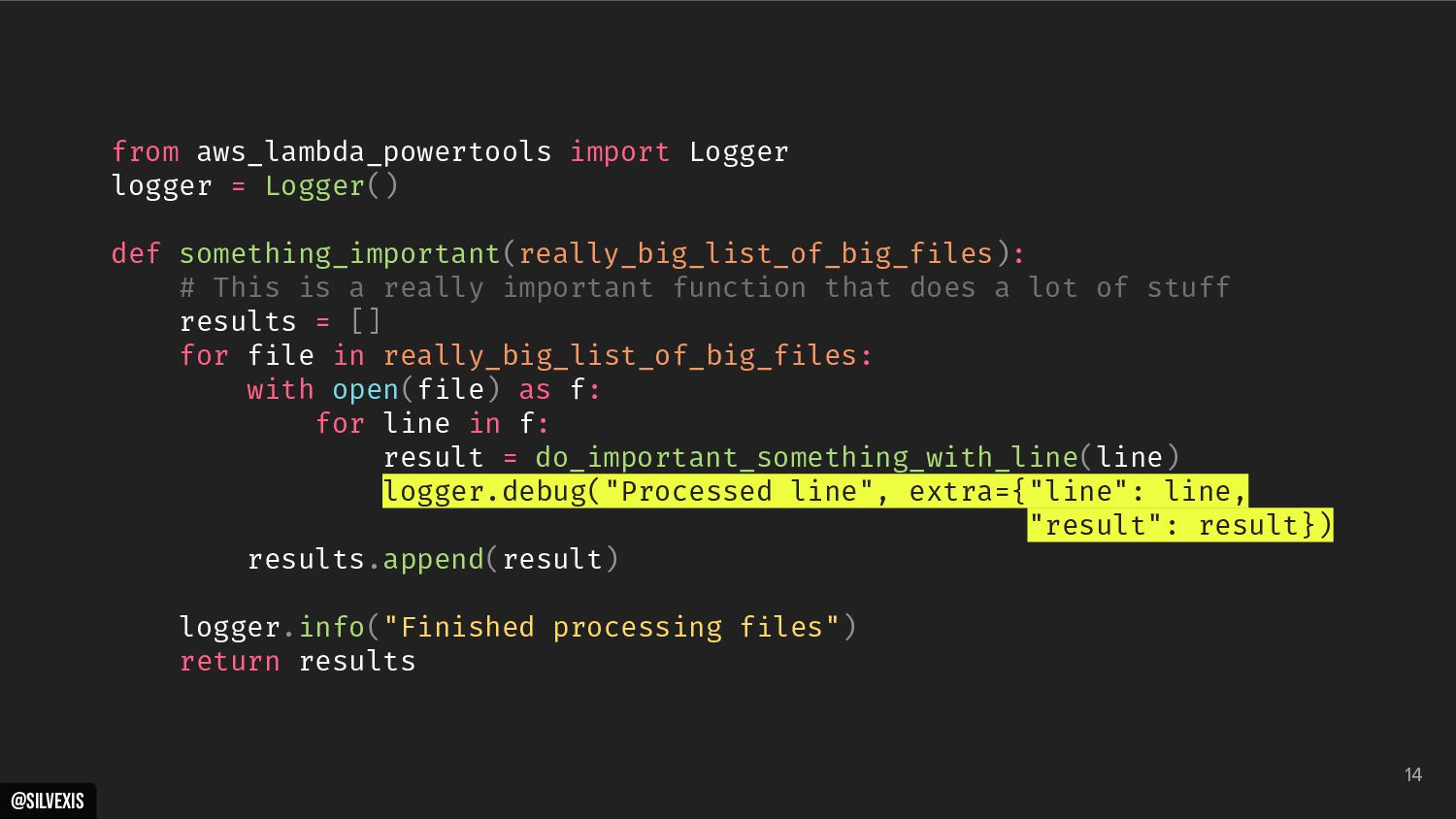{kind=link}
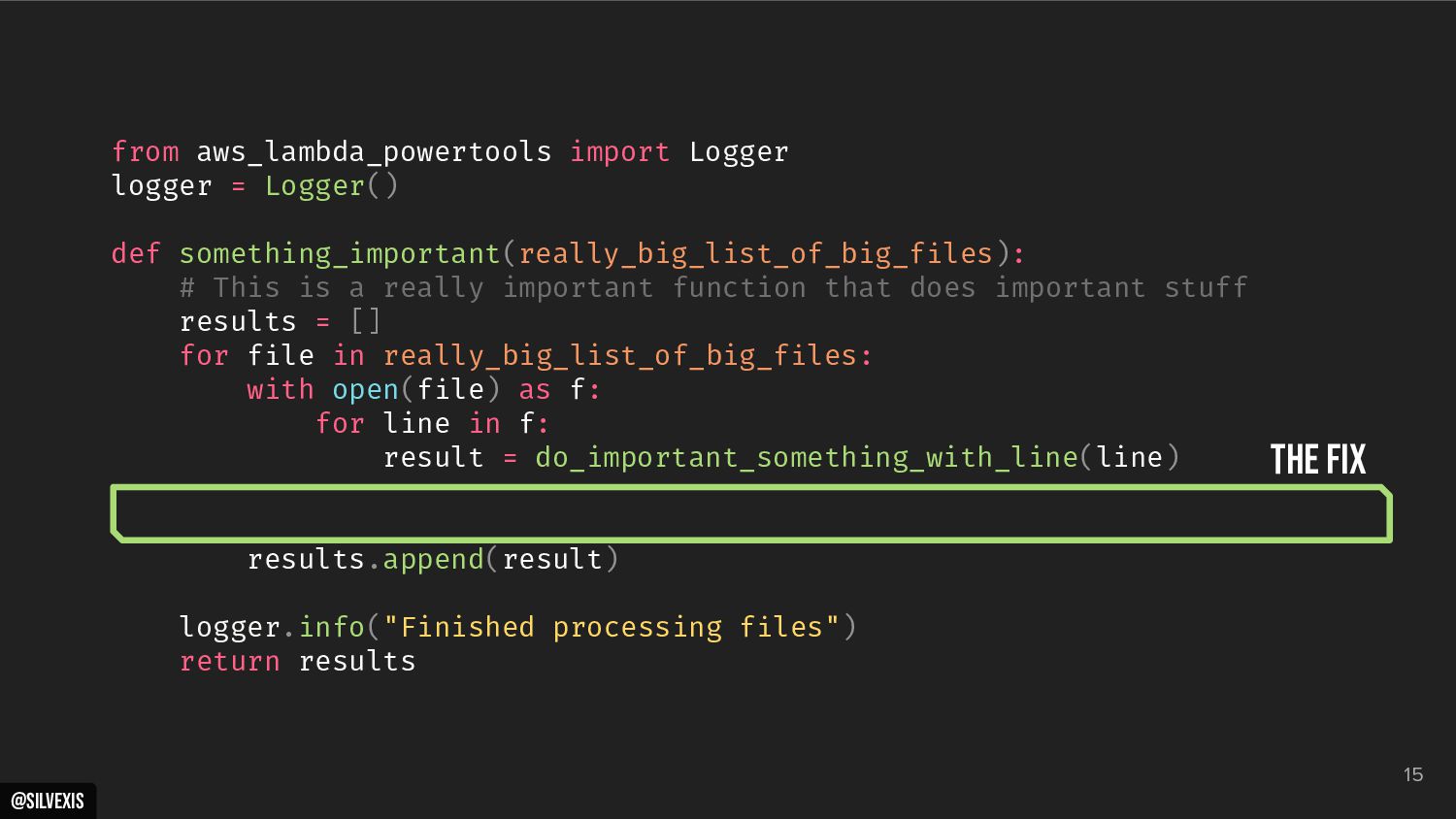{kind=link}
{kind=link}
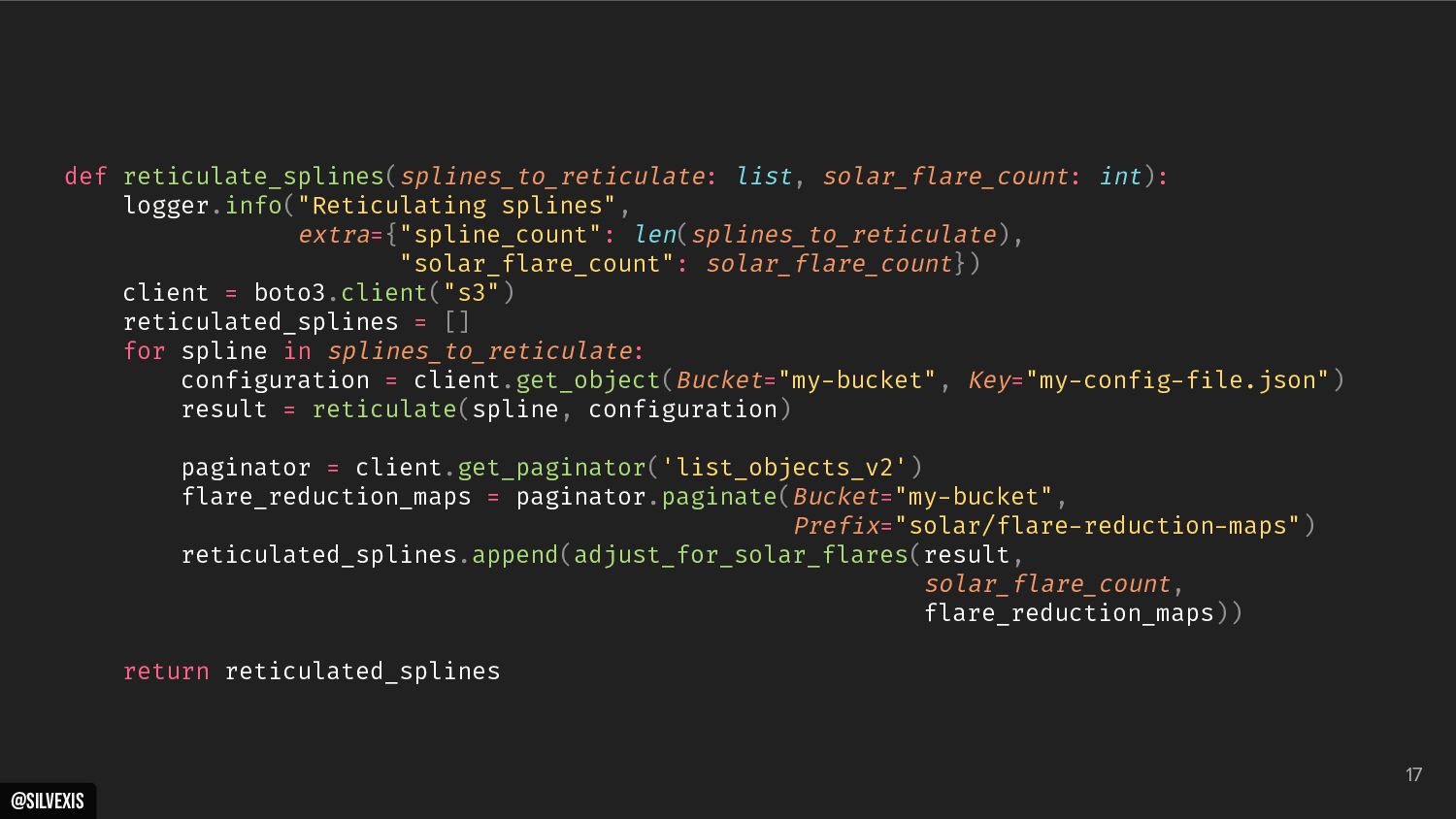{kind=link}
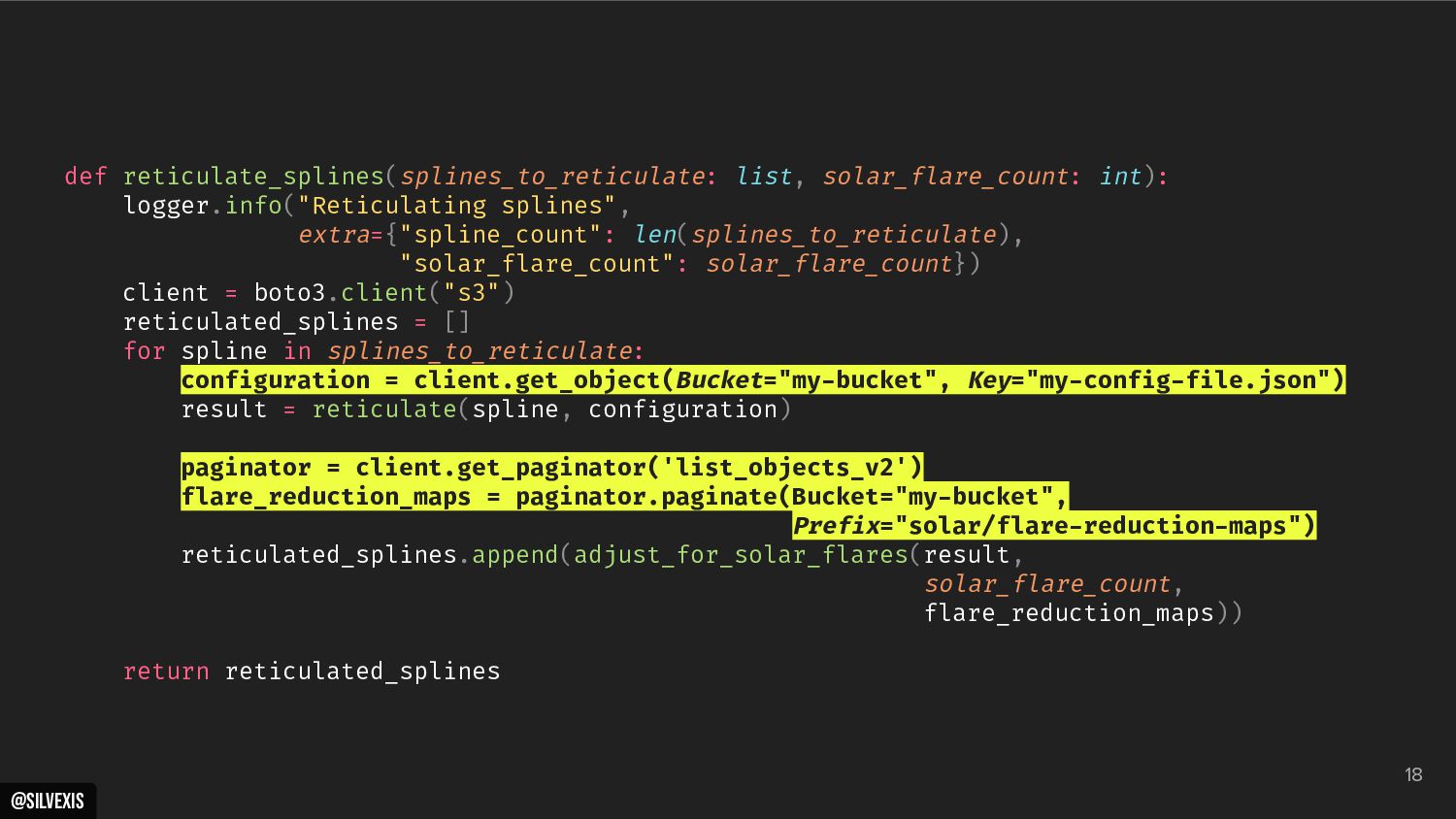{kind=link}
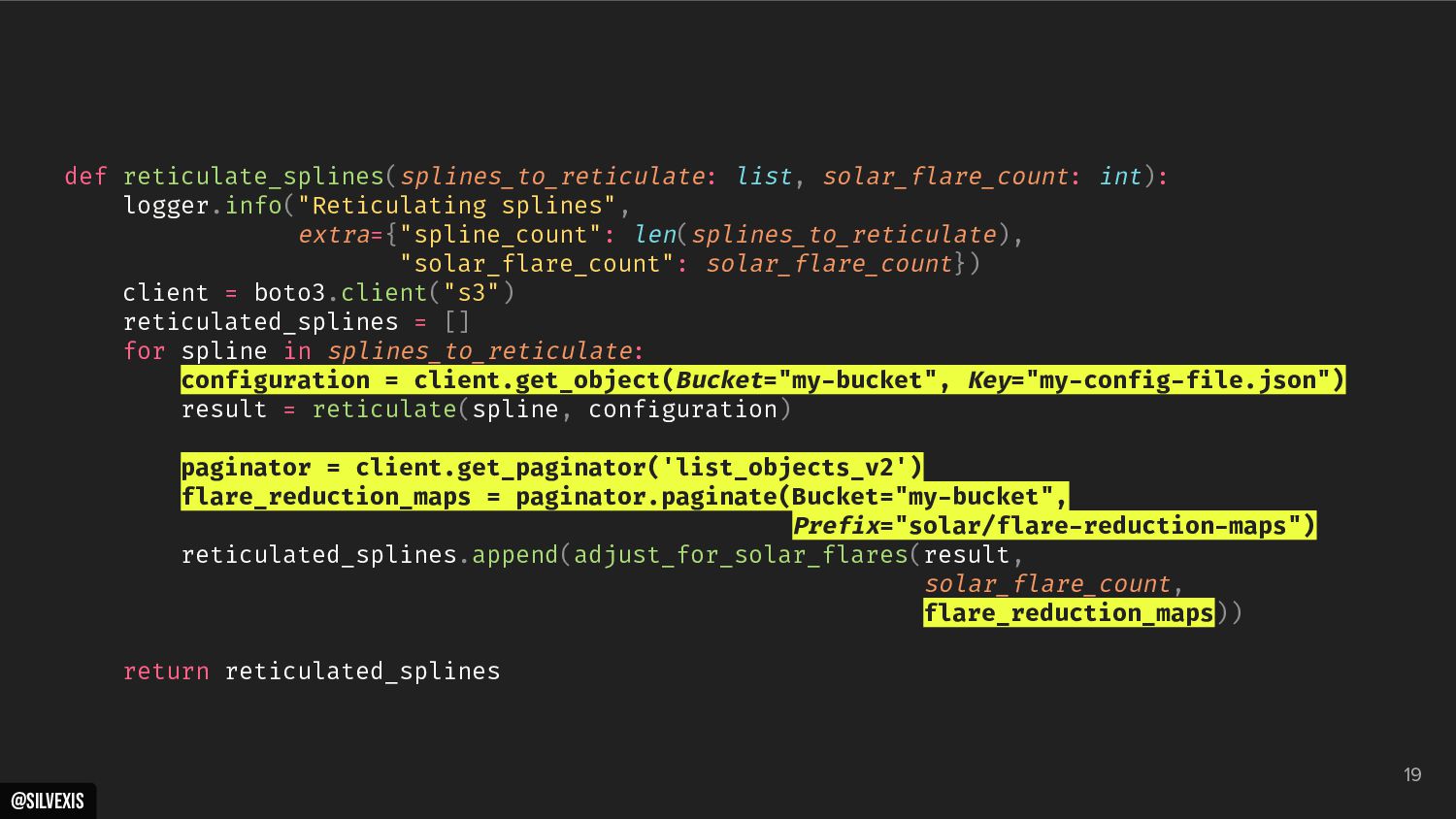{kind=link}
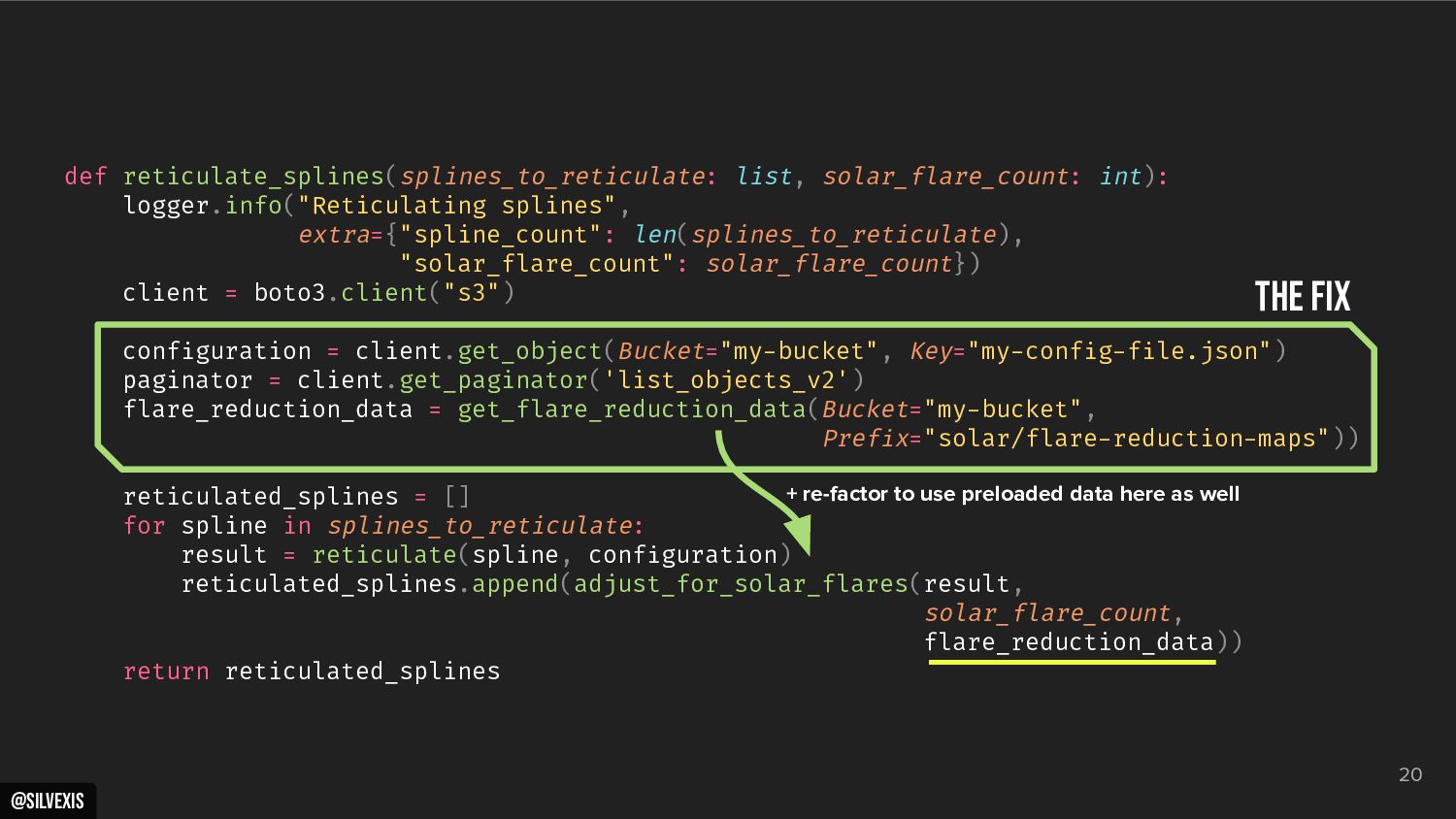{kind=link}
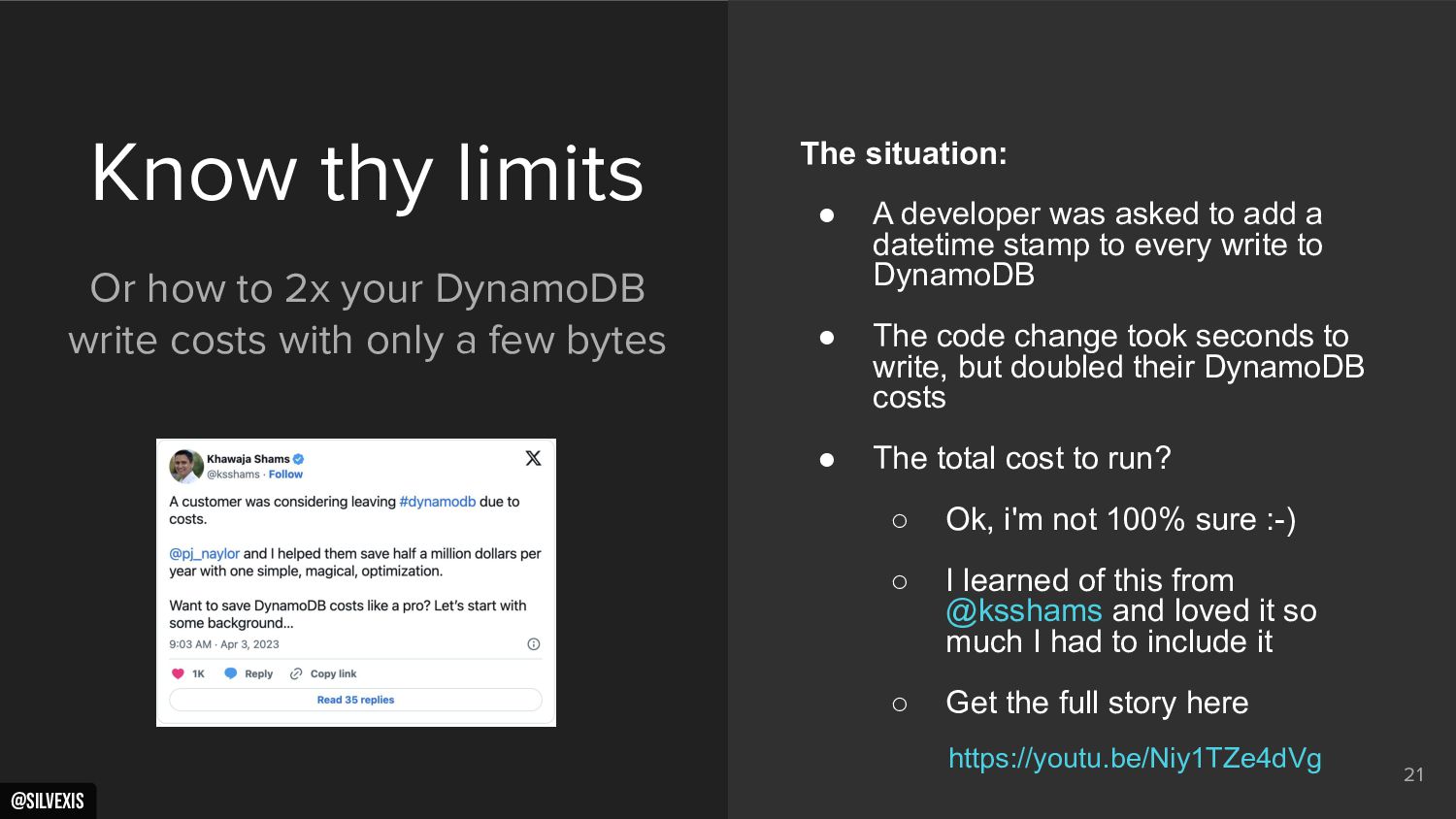{kind=link}
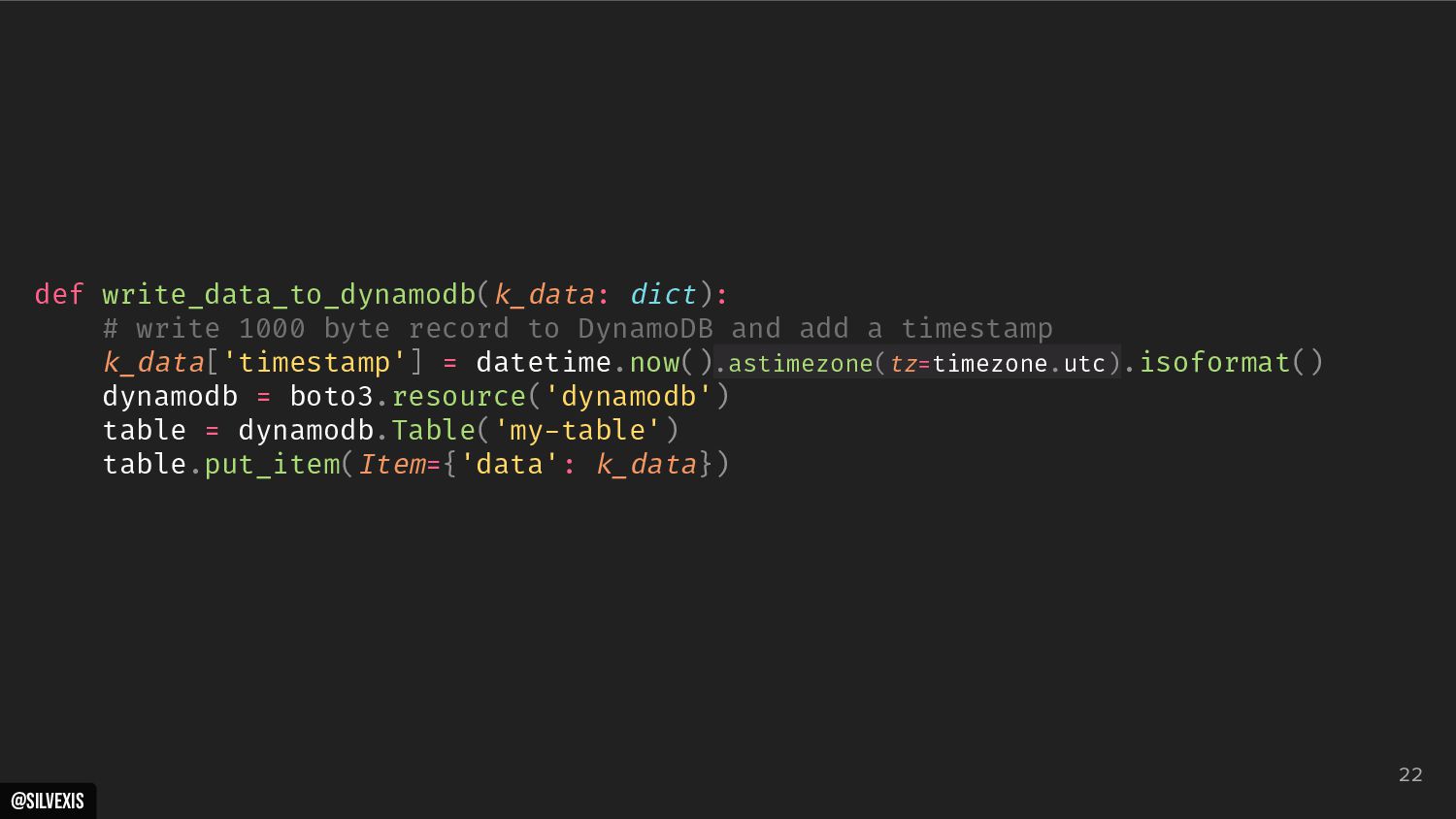{kind=link}
{kind=link}
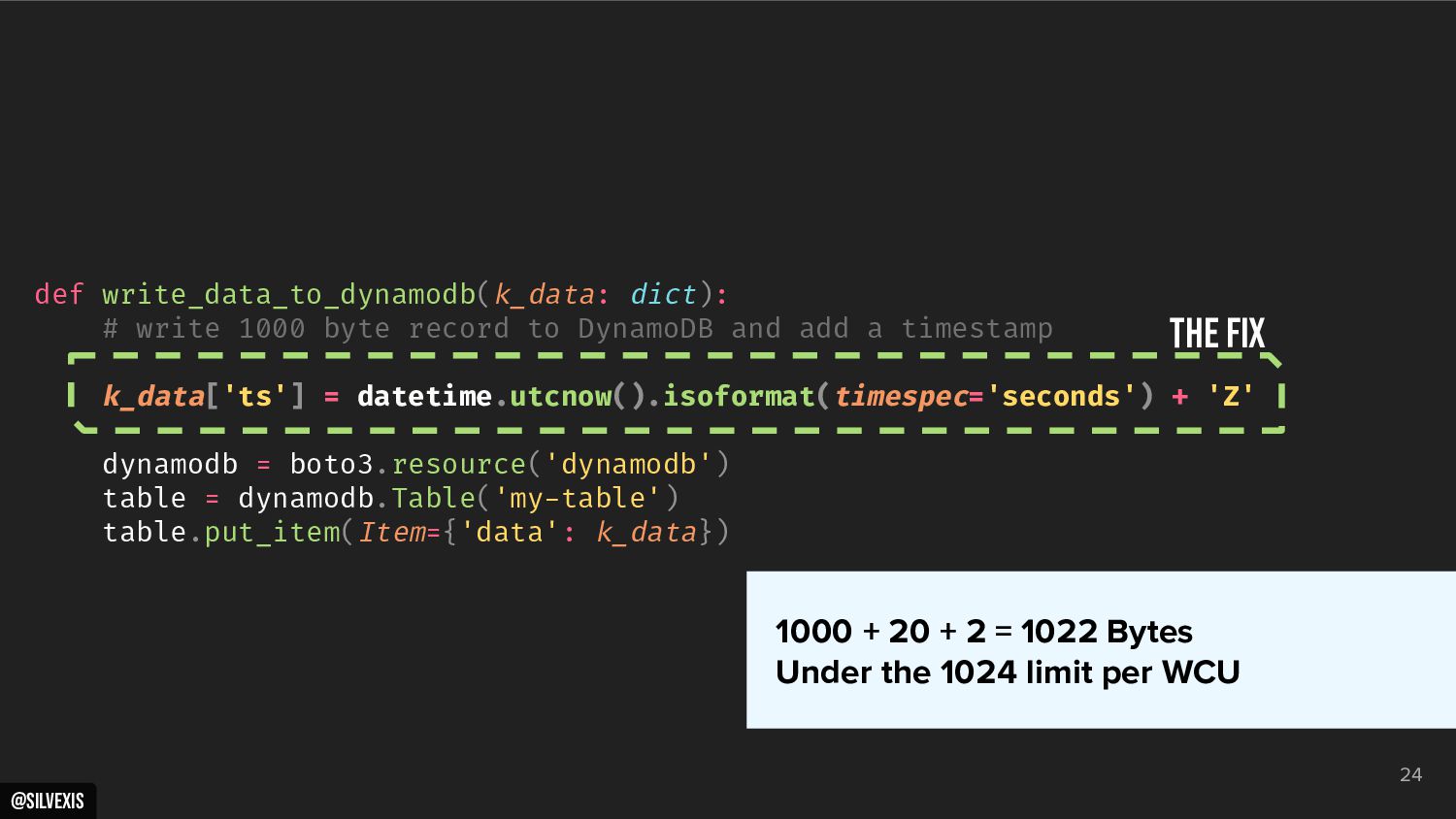{kind=link}
{kind=link}
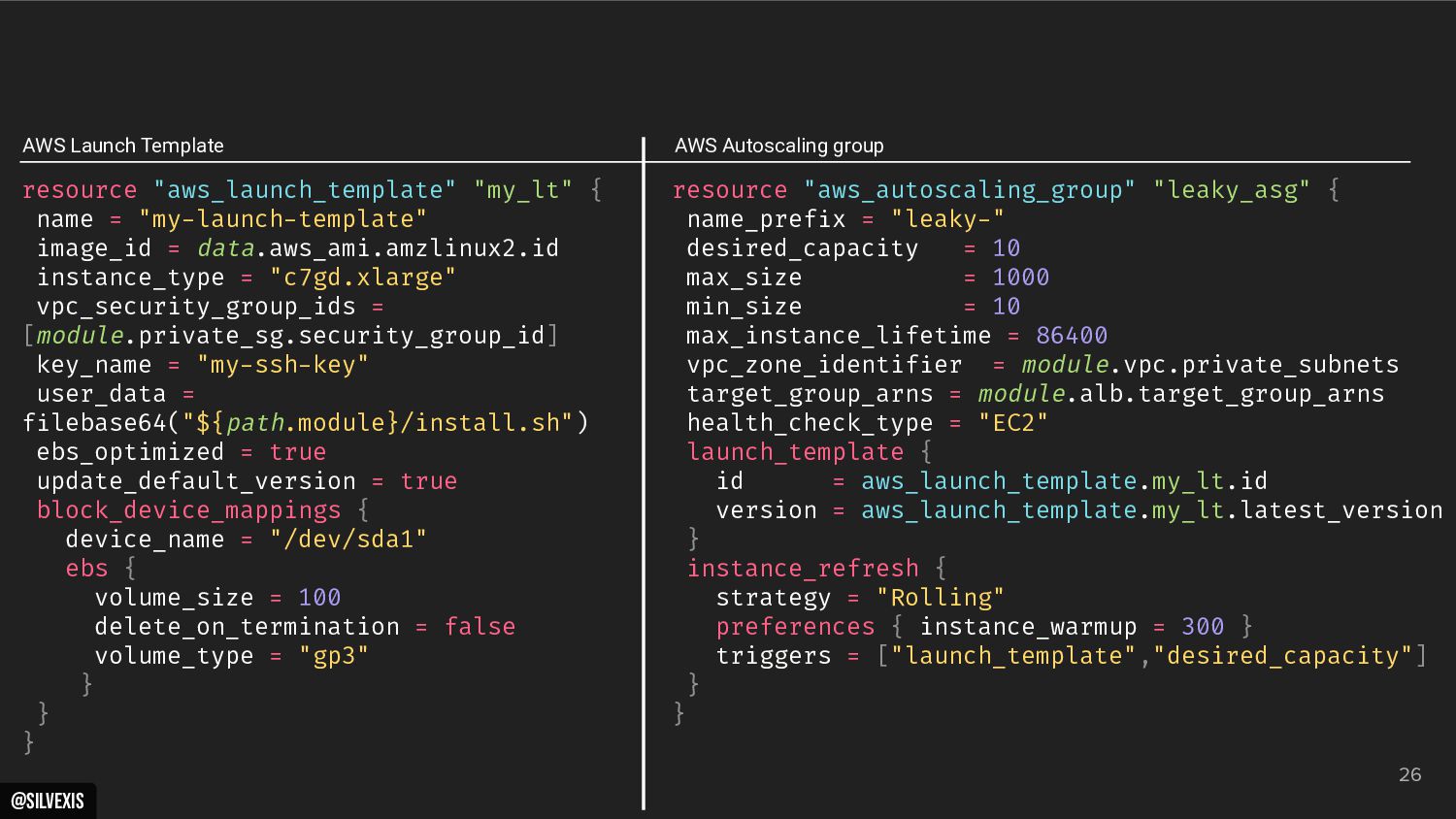{kind=link}
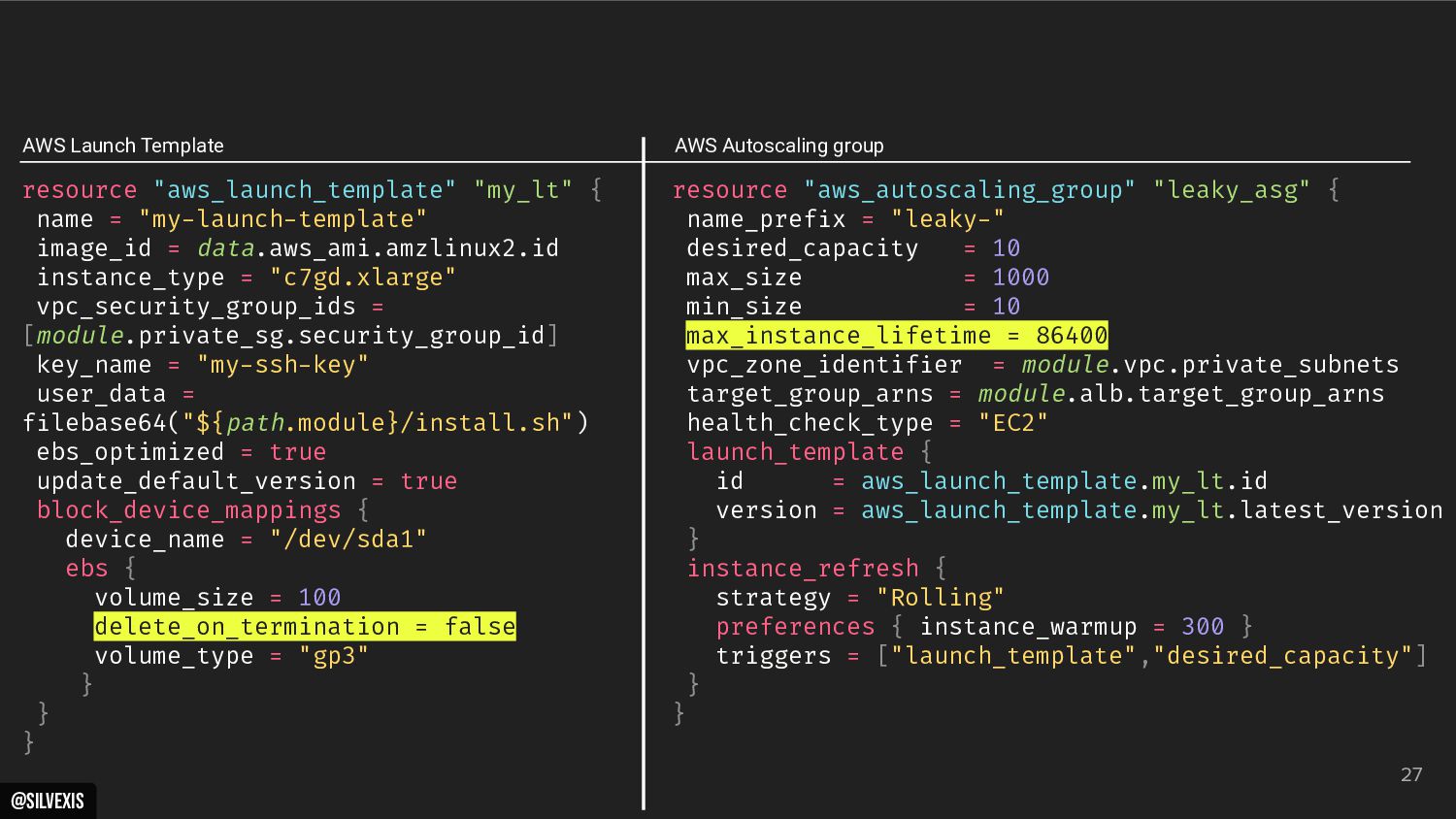{kind=link}
{kind=link}
{kind=link}
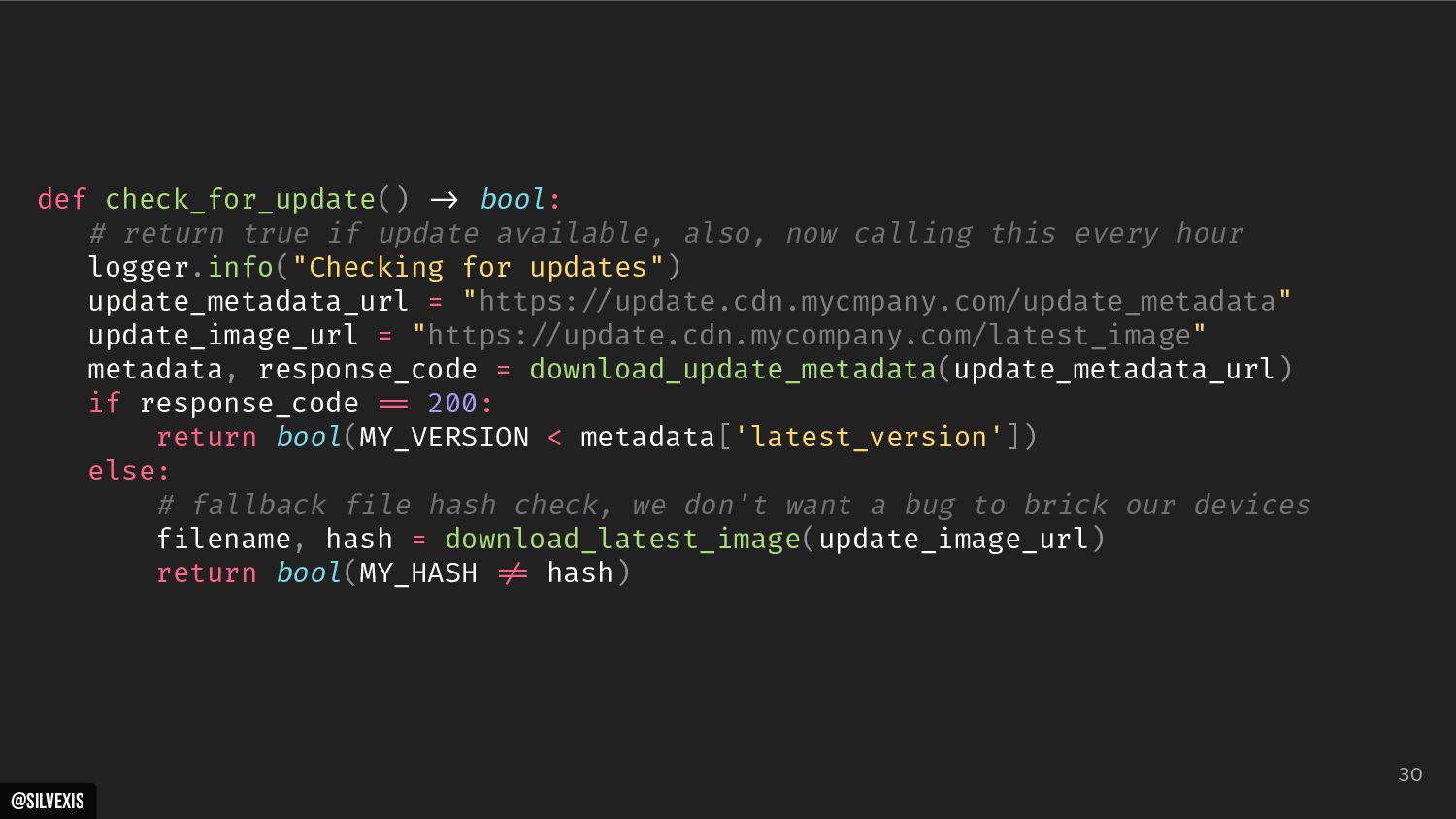{kind=link}
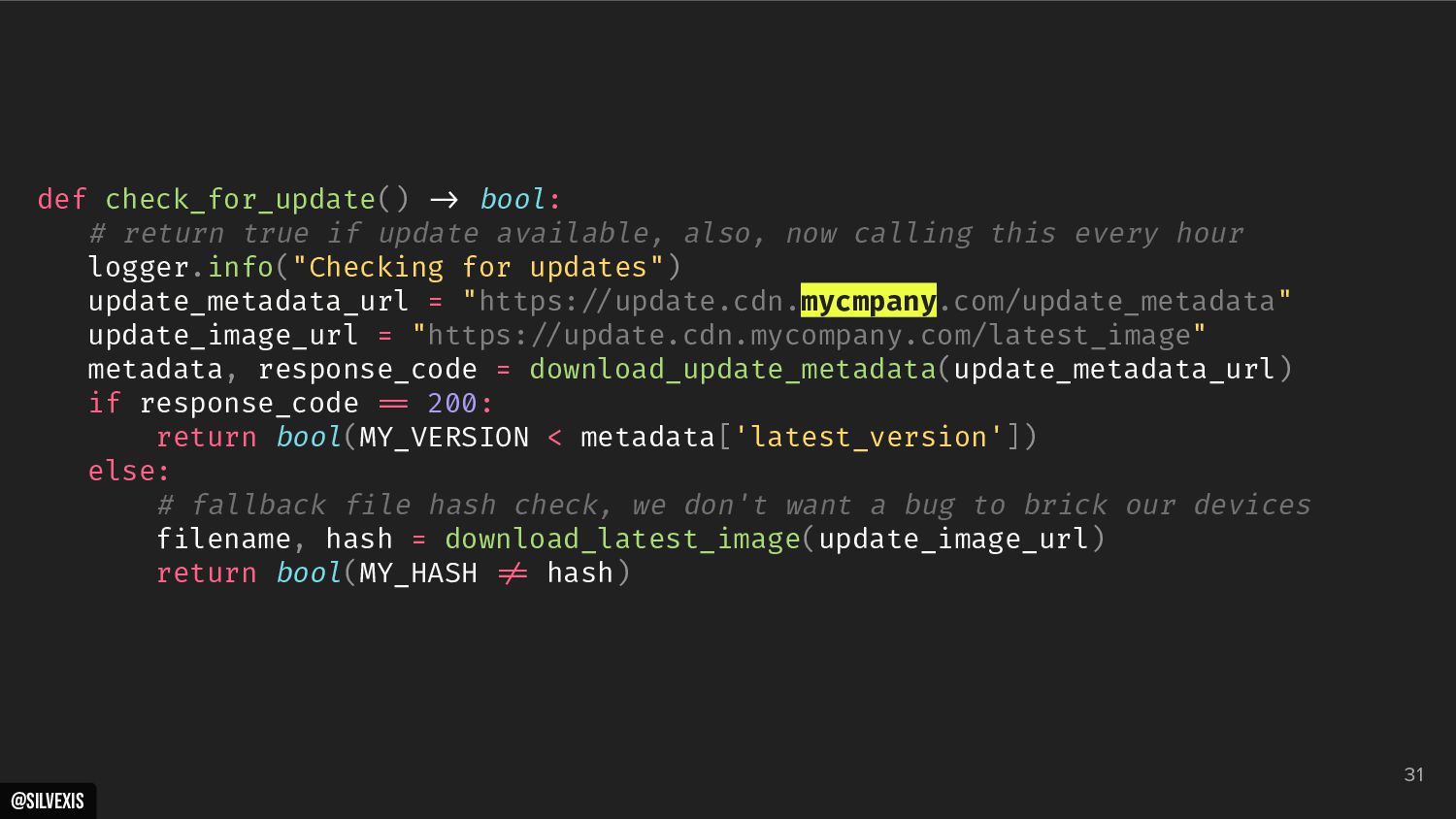{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}