Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【データベース】統計情報の影響範囲【第4回】
Search
Shin
October 10, 2024
6
0
Share
【データベース】統計情報の影響範囲【第4回】
Shin
October 10, 2024
More Decks by Shin
See All by Shin
【DWH】Snowflakeのクラスタリングキーについて
sk8er_boi_shin
0
8
【DWH】Snowflakeで等価条件なのにコストが変わる理由
sk8er_boi_shin
0
8
【DWH】 PostgreSQLとSnowFlake_設計思想とデータ管理の違い
sk8er_boi_shin
0
11
【PostgreSQL】メンテナンス系コマンドの種類
sk8er_boi_shin
0
22
【データベース】統計情報と物理順序
sk8er_boi_shin
0
48
感情を整える習慣で仕事はもっとラクになる
sk8er_boi_shin
0
18
【データベース】RedisとPostgreSQL
sk8er_boi_shin
0
110
【データベース】統計情報と単一カラムのヒストグラム
sk8er_boi_shin
0
13
伝わるプロジェクト_伝わらないプロジェクト.pdf
sk8er_boi_shin
0
15
Featured
See All Featured
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
340
4 Signs Your Business is Dying
shpigford
187
22k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
1.9k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
231
23k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
900
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
270
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
290
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.7k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.7k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
0
1.3k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.8k
Transcript
【データベース】 統計情報の影響範囲
目次 1. クエリが実行される流れ 2. 統計情報とは? 3. 実行計画とは? 4. 索引(INDEX)とは? 5.
データの選択性とフィルタリング 6. パーティショニングの最適化 7. キャッシュ利用の最適化 8. 検証 ◦ 索引の効率利用 ◦ データの選択性とフィルタリング ◦ パーティショニングの最適化 ◦ キャッシュ利用の最適化 9. まとめ
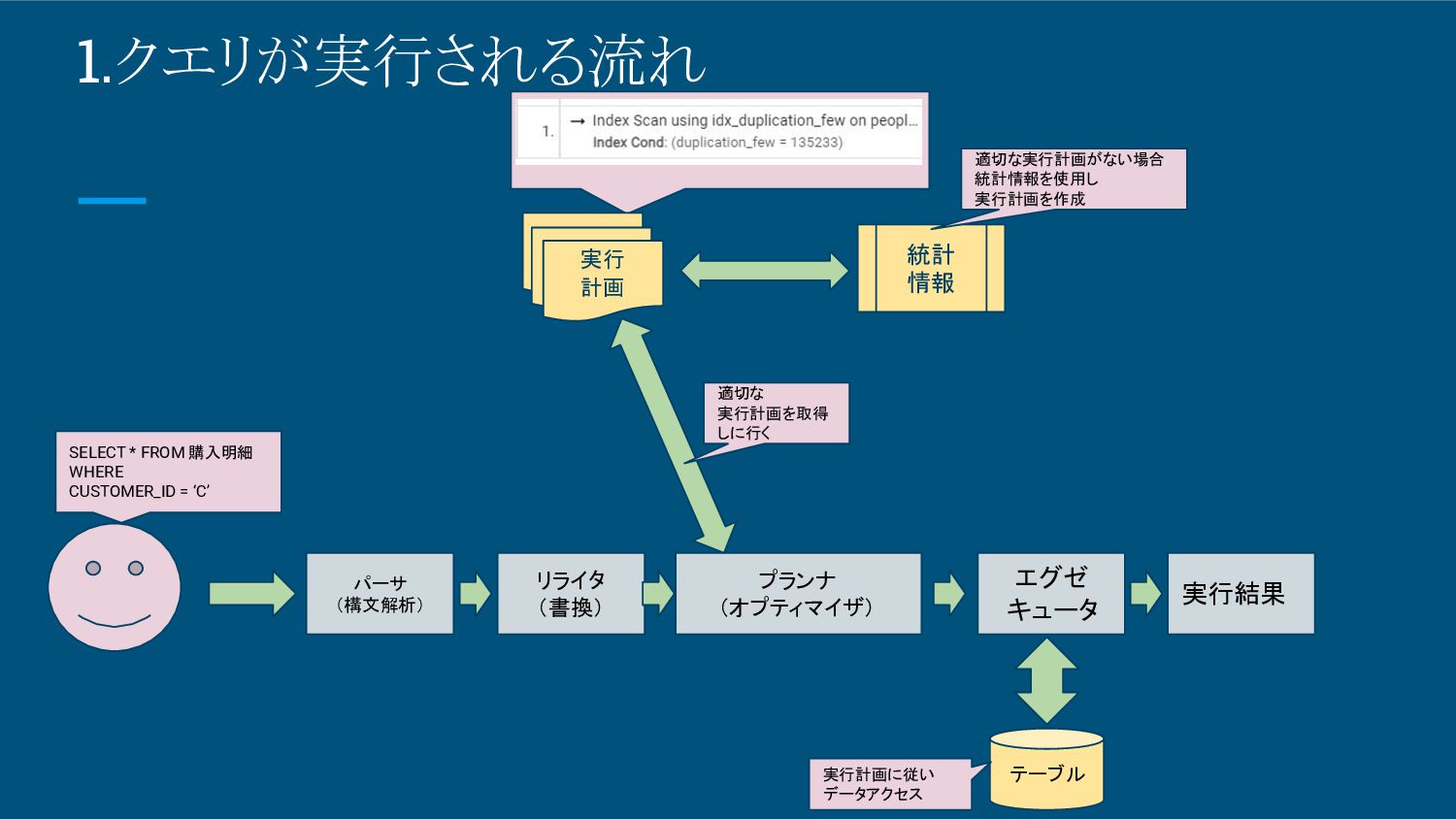
1.クエリが実行される流れ SELECT * FROM 購入明細 WHERE CUSTOMER_ID = ‘C’ パーサ
(構文解析) リライタ (書換) プランナ (オプティマイザ) エグゼ キュータ 実行結果 きゃ 実行 計画 統計 情報 適切な実行計画がない場合 統計情報を使用し 実行計画を作成 テーブル 実行計画に従い データアクセス 適切な 実行計画を取得 しに行く
1.クエリが実行される流れ • 実行計画とは ◦ DBMSがクエリを最適に実行するための手順書 ▪ どのインデックスを使用するか ▪ どのテーブルをどの順番で結合するか ▪
テーブルスキャンorインデックススキャン ▪ 等
2.統計情報とは? • 統計情報とは ◦ 実行計画を作成するための材料 ◦ データの量や分布に関するメタ情報(ヒストグラム) ▪ 最大値 ▪
最小値 ▪ NULLの数 ▪ 重複の値とその数 ▪ 等 ◦ 統計情報が最新なら正確な実行計画を作成できる ◦ 古くなるとパフォーマンスに悪影響を与える ⇨以降のスライドでは統計情報が影響する範囲を解説
3.実行計画とは? • クエリの実行計画とは? ◦ クエリを効率的に実行するためのデータベースの「手順書」 ◦ EXPLAIN コマンドで確認可能 • 重要性
◦ パフォーマンスのボトルネックを特定 ◦ インデックス使用状況を確認 ◦ 最適化の機会を発見 ◦ 統計情報が正確であれば効率的な実行計画が選ばれる
3.実行計画とは? • 主要なポイント ◦ スキャン方法 ▪ Seq Scan(全行読み込み) ▪ Index
Scan(少量のデータ(テーブルの数%)に絞り込む際にINDEXを使用) ▪ Bitmap Index Scan(大量データの効率的フィルタリング) ◦ 結合方法 ▪ Nested Loop • 1つ目のテーブル(外側のテーブル)の各行に対し、もう1つのテーブル(内側の テーブル)の全行をループしながら比較し、条件に一致する行を見つけるまで処 理を繰り返す。 ▪ Hash Join(ハッシュを使用した結合) ▪ Merge Join(ソート済みデータの結合。大規模。) ◦ ソートとフィルタリング ▪ 結果の並べ替えと条件によるデータ抽出
4.索引(INDEX)とは? • INDEXとは? ◦ データを効率的に検索するための、「本の索引」のようなもの。 • 適切な列にINDEX作成 ◦ フィルタリングや結合に使用。一意性のあるカラムに使用すると効果的。 •
複合INDEXの活用 ◦ 複数条件に対し、関係するカラムをまとめて指定。 • クエリの最適化 ◦ 特にフィルタリングや結合は INDEXのカラムを使用したい。 • カバリングINDEX ◦ 条件が全てINDEXに含まれる場合、テーブルアクセス不要で効率的。 • INDEXのメンテナンス ◦ 更新の多いテーブルは定期的に INDEXの再構築が必要。
4.索引(INDEX)とは?(TIPS:複合INDEXのコツ) • 頻繁に使用する列を優先 ◦ WHERE句やJOINでよく使われる列を含める。 • 条件の順序に合わせる ◦ 複合インデックスの列順は、クエリでの条件の適用順に合わせる。 ▪
JOIN • データ量の少ないテーブルから結合 • 適切なINDEXを使用する結合キーが優先 ▪ WHERE • 一意性の高いカラムから使用 • 範囲検索(>、<等)よりも等価条件(=)から • 選択性の高い列を前に ◦ ユニークな値が多い列(選択性の高い列)を先に配置すると効果的。 • 不要な列は避ける ◦ インデックスに含める列は最小限に抑える。必要な列だけを選ぶ。 • カバリングインデックスを考慮 ◦ SELECT句で参照する列もインデックスに含めると、クエリがインデックスのみで完結する。
4.索引(INDEX)とは?(TIPS:INDEX再構築と統計情報更新) • インデックス再構築 ◦ 目的: 物理削除や頻繁な更新でインデックスが断片化し、検索効率が低下した際に、インデックスの構造を 再構築してパフォーマンスを回復させる。 ◦ 実施タイミング: 物理削除が多い場合(影響大)や、断片化(追加や更新)が進んだ場合(影響中〜小)。
◦ 効果: インデックス内の空き領域を整理し、検索速度やクエリパフォーマンスを向上。 • 統計情報の更新 ◦ 目的: データベースが最適なクエリ実行計画を選べるように最新のデータ分布情報を提供する。 ◦ 実施タイミング: データの追加・更新・削除により、データ分布が変化した場合。 ◦ 効果: クエリ実行計画の最適化により、効率的なインデックス利用とパフォーマンス向上。 • 簡潔にまとめると: ◦ インデックス再構築は、断片化によるパフォーマンス低下を解消するために行う。 ◦ 統計情報の更新は、データの分布が変わったときにクエリの最適化を支援するために行う。
5.データの選択性とフィルタリング • 選択性とは ◦ クエリの条件に一致するデータの割合を指す。 ◦ 選択性が高いほどフィルタリング後のデータは少なく、パフォーマンスが向上。 ▪ 高い選択性 •
ユニークな列(例: 社員ID)→ インデックスが有効。 ▪ 低い選択性 • 繰り返しの多い列(例: 性別)→ フルテーブルスキャンが選ばれやすい。 • フィルタリング ◦ WHERE句などを使って、条件に合うデータを絞り込むプロセス。 • 最適化 ◦ 選択性の高い列にインデックスを作成し、効率的なフィルタリングを行うとクエリのパフォー マンスが向上。
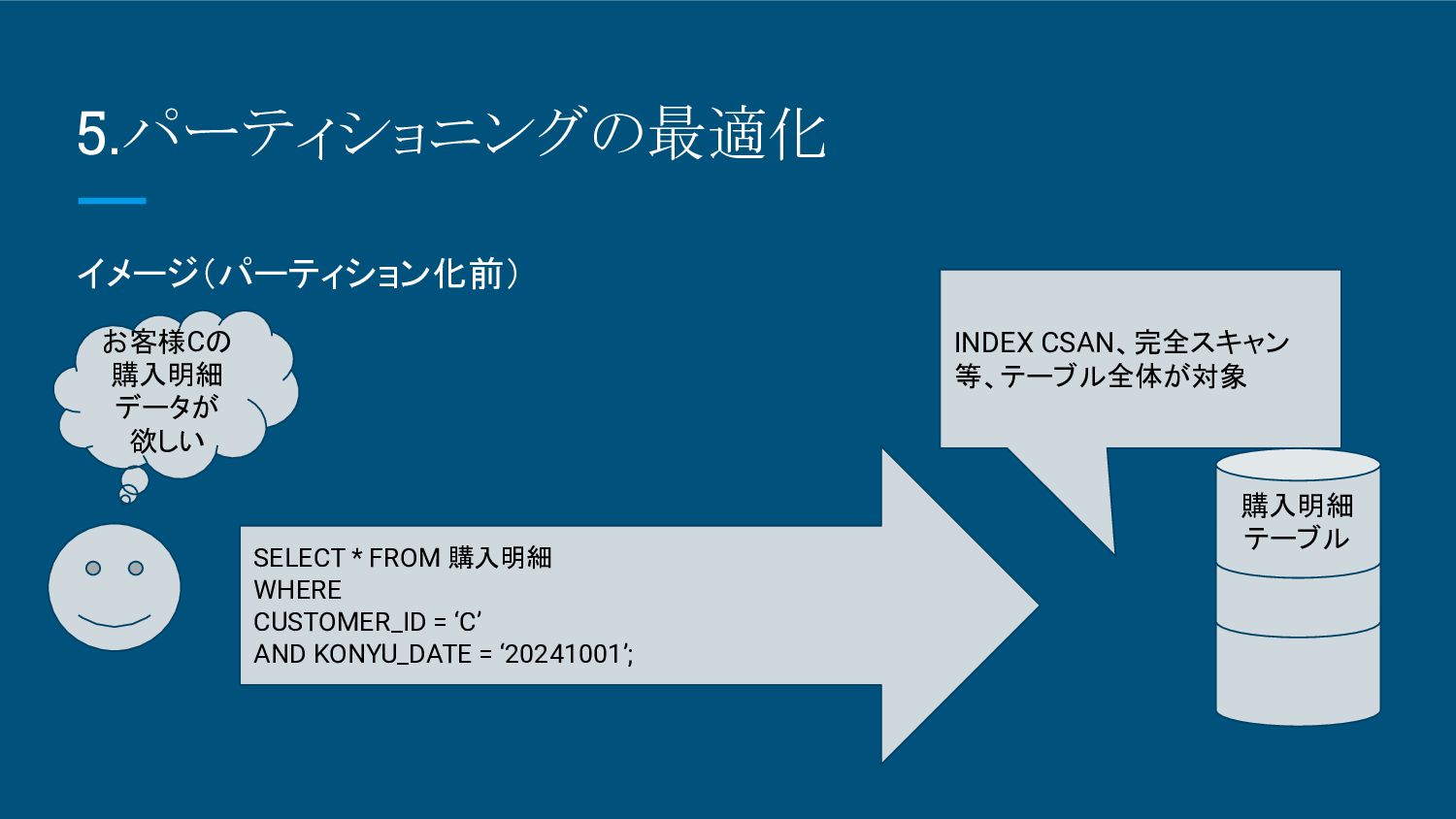
6.パーティショニングの最適化 • パーティショニングの最適化 とは ◦ 大量のデータを持つテーブルを複数の小さなパーティションに分割し、クエリ のパフォーマンスや管理の効率を向上させる技術・最適化することで、デー タベースの処理を高速化し、I/O負荷を軽減。 • パーティショニングのメリット
◦ クエリのスキャン範囲が狭まり、パフォーマンス向上 。 ◦ データの追加・削除が効率化され、管理が簡単。 ◦ アーカイブやバックアップ がパーティション単位で容易
6.パーティショニングの最適化 イメージ(パーティション化前) 購入明細 テーブル お客様Cの 購入明細 データが 欲しい INDEX CSAN、完全スキャン
等、テーブル全体が対象 SELECT * FROM 購入明細 WHERE CUSTOMER_ID = ‘C’ AND KONYU_DATE = ‘20241001’;
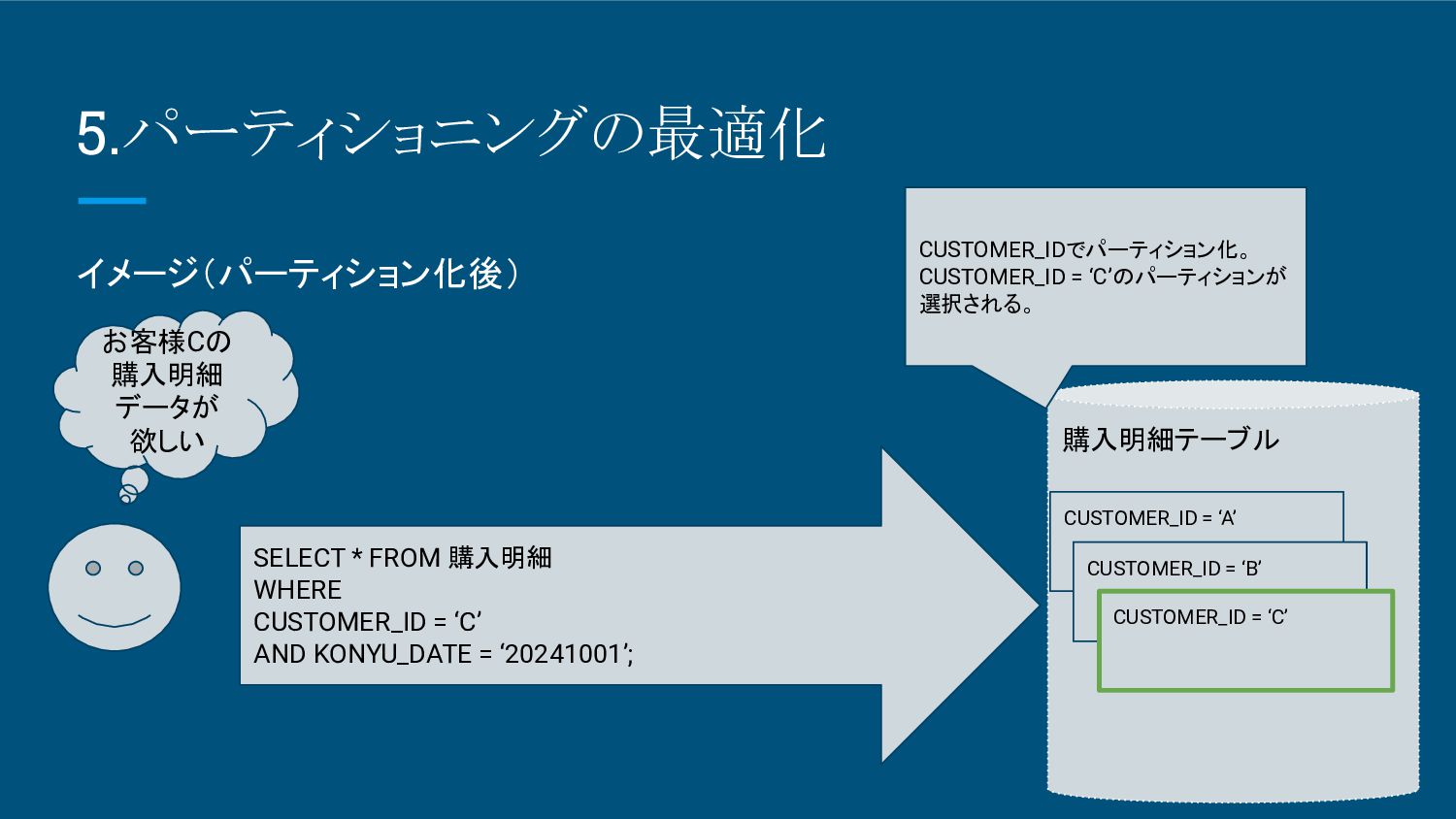
6.パーティショニングの最適化 イメージ(パーティション化後) 購入明細テーブル お客様Cの 購入明細 データが 欲しい SELECT * FROM
購入明細 WHERE CUSTOMER_ID = ‘C’ AND KONYU_DATE = ‘20241001’; CUSTOMER_IDでパーティション化。 CUSTOMER_ID = ‘C’のパーティションが 選択される。 CUSTOMER_ID = ‘A’ CUSTOMER_ID = ‘B’ CUSTOMER_ID = ‘C’
6.パーティショニングの最適化 イメージ(パーティション化後) 購入明細テーブル CUSTOMER_ID = ‘A’ CUSTOMER_ID = ‘B’ CUSTOMER_ID
= ‘C’ ・親テーブル テーブル全体のメタデータ管理( INDEX、構造や制約) 実際のデータは保持していない。 クエリ実行時に各パーティション(子テーブル)への振り分けルールを定義。 ・子テーブル(各パーティション) 分割済みの実データを保持。 独立した物理テーブルとして扱う。
6.パーティショニングの最適化 • パーティショニングの方法 ◦ 範囲パーティショニング( Range Partitioning) ▪ 特定の範囲でデータを分割。 ▪
例: 年ごとにデータを分割する。2023年のデータはPartition1、2024年のデータはPartition2に格納。 ▪ 使用シーン : 大量の履歴データを管理し、特定の期間に対してクエリを実行する場合に最適。 ◦ リストパーティショニング( List Partitioning) ▪ 特定の値のリストでデータを分割。 ▪ 例: 地域ごとに分割する。地域AはPartition 1、地域BはPartition 2に格納。 ▪ 使用シーン : データを特定のカテゴリ(国、地域、部署など)ごとに管理・検索したい場合に有効。 ◦ ハッシュパーティショニング( Hash Partitioning) ▪ ハッシュ関数を使ってデータを均等に分散。 ▪ 例: ID値を基にデータを均等に複数のパーティションに振り分ける。 ▪ 使用シーン : データの偏りを防ぎ、均等に分散させたい場合や、アクセス負荷を均等化したい場合に最適。
6.パーティショニングの最適化 • パーティショニングの最適化方法 ◦ クエリ条件に合ったパーティションキーを選ぶ( WHERE句)ことで、スキャン対象が限定 されクエリが高速化。 ◦ 適切なパーティション数を設定し、パフォーマンスと管理のバランスを取る。 ◦
メンテナンスの自動化で運用効率を向上。 ▪ 定期的に古いパーティションをアーカイブしたり、パーティションを追加するツール を作成することで効率化が可能。 • パーティションプルーニング ◦ 不要なパーティションをクエリ実行時にスキップすることで、検索効率を最大化。
6.パーティショニングの最適化 • 選定事例 ◦ 範囲パーティショニング ▪ 連続的なデータ(日時や数値)で効率的に管理する場合。 ▪ 例: 「2019年」「2020年」といったように、年度ごとに分割されるテーブル。
◦ リストパーティショニング ▪ 特定の値やカテゴリに基づいてデータを分割したい場合。 ▪ 例: 「日本」「アメリカ」「イギリス」のように、国ごとにデータを分割するケース。 ◦ ハッシュパーティショニング ▪ データをランダムに分散させ、均等な負荷を目指したい場合。 ▪ 例: 大量のユーザーデータを均等に分散させ、特定のパーティションへの負荷集中を 避ける場合。
6.パーティショニングの最適化 • Q:Aカラムでパーティショニングし、クエリではBカラムでフィルタ リングした場合どうなるか? ◦ 全ての子テーブルに対しスキャンが実行される。 ▪ 子テーブルが多くなるとパフォーマンスに影響が出る可能性がある ため、子テーブルに対しINDEXを作成する。
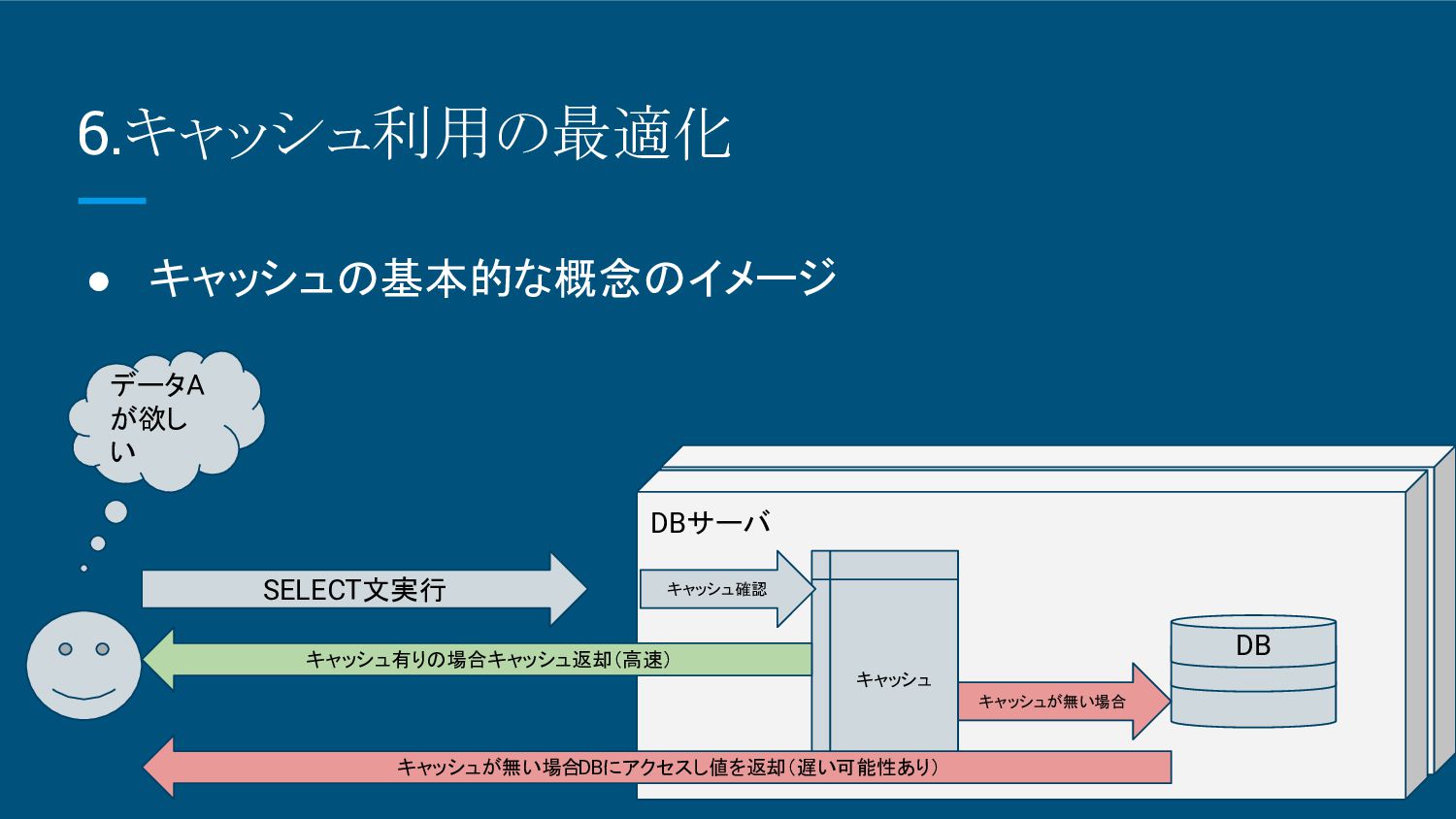
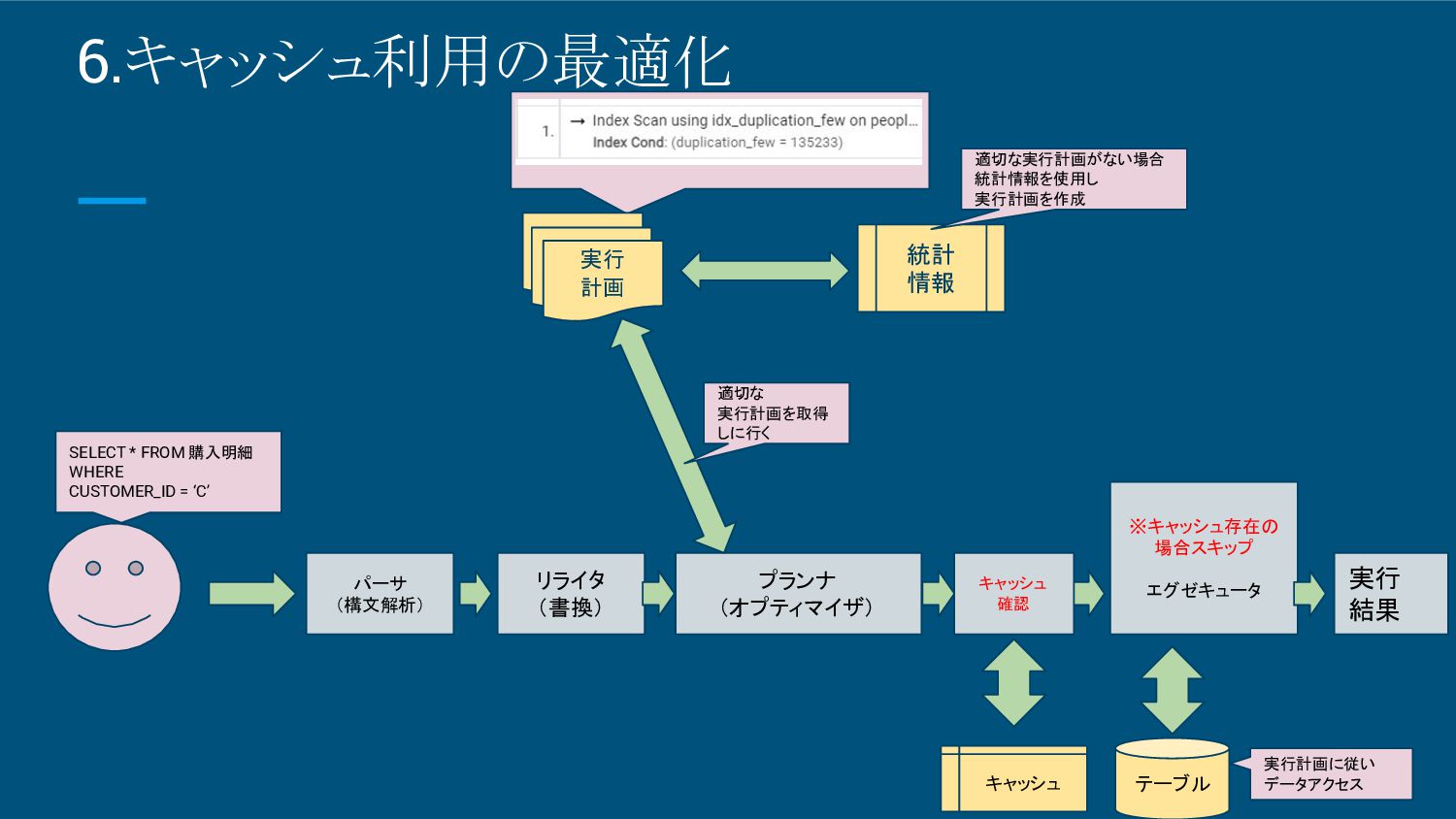
7.キャッシュ利用の最適化 • キャッシュの基本的な概念 ◦ キャッシュとは、データベースがよく使うデータをメモリ上に保持し、再利用す る仕組み。 ◦ これにより、ディスクI/O(ディスクへの読み書き)を減らし、アクセス速度が向 上します。 ◦
キャッシュされるのは、クエリ結果やテーブル、インデックスの一部など、頻 繁に参照されるデータ。
DBサーバ 7.キャッシュ利用の最適化 • キャッシュの基本的な概念のイメージ DB データA が欲し い キャッシュ SELECT文実行
キャッシュ確認 キャッシュが無い場合 キャッシュ有りの場合キャッシュ返却(高速) キャッシュが無い場合 DBにアクセスし値を返却(遅い可能性あり)
8.キャッシュ利用の最適化 • キャッシュ最適化のポイント ◦ よく使うデータのキャッシュ化 ▪ 頻繁にアクセスされるデータ(例 : ユーザー情報や設定値)は、キャッシュに保持されるとパフォーマン スが大幅に向上。
◦ 適切なキャッシュサイズの設定 ▪ サイズが小さすぎるとキャッシュのヒット率が低下し、サイズが大きすぎると他のプロセスに影響を与 える。 ◦ インデックスのキャッシュ利用 ▪ 特に大規模なテーブルで重要。よく使うインデックスをキャッシュに保持することで、インデックススキャ ンが効率化され、クエリの実行速度が大幅に向上。 ◦ クエリ結果のキャッシュ ▪ 特定のクエリ結果が繰り返し使用される場合、その結果をキャッシュして再利用することが可能。これ により、同じクエリを何度も実行する必要がなくなり、応答時間が劇的に短縮される。
8.キャッシュ利用の最適化 SELECT * FROM 購入明細 WHERE CUSTOMER_ID = ‘C’ パーサ
(構文解析) リライタ (書換) プランナ (オプティマイザ) ※キャッシュ存在の 場合スキップ エグゼキュータ 実行 結果 きゃ 実行 計画 統計 情報 適切な実行計画がない場合 統計情報を使用し 実行計画を作成 テーブル 実行計画に従い データアクセス 適切な 実行計画を取得 しに行く キャッシュ 確認 キャッシュ
8.【検証】検証に使用する環境 • データベース Postgresql • テーブル名 PEOPLE • 統計情報は最新の状態 • データ数 400万件 •
Index ◦ index名:Idx_people_person_id 指定カラム: person_id ◦ index名:Idx_people_duplication_many 指定カラム: duplication_many ◦ index名:Idx_people_duplication_forty_type 指定カラム: duplication_forty_type • カラム ◦ person_id, duplication_few(INTEGER型)(一意なデータ) ◦ duplication_many(INTEGER型)(重複のあるデータ) ▪ 0 :40万件 ▪ 1 :40万件 ▪ 2 :40万件 ▪ 3 :40万件 ▪ 4 :280万件
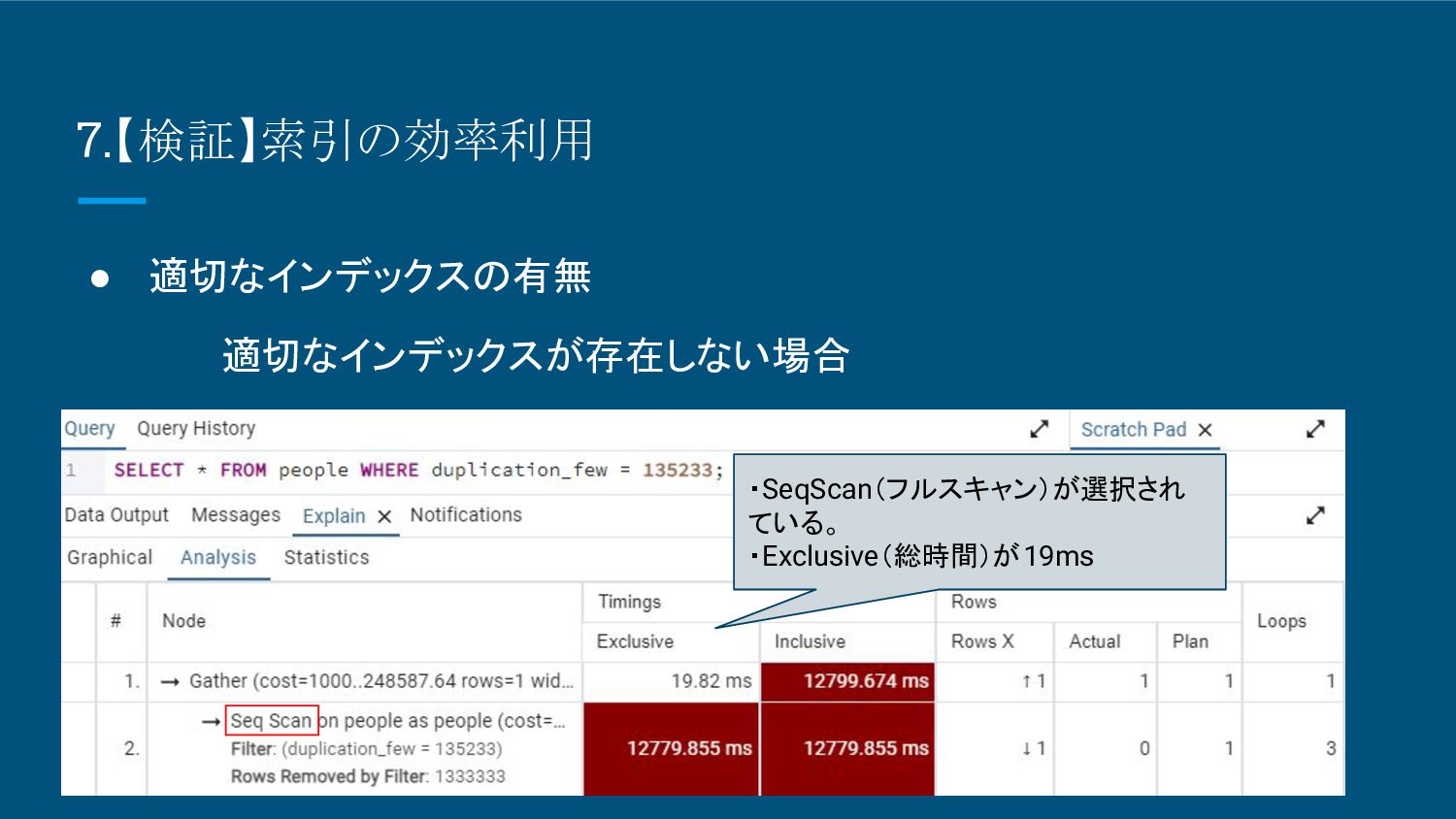
8.【検証】索引の効率利用 • 適切なインデックスの有無 適切なインデックスが存在しない場合 ・SeqScan(フルスキャン)が選択され ている。 ・Inclusive(総時間)が12799ms
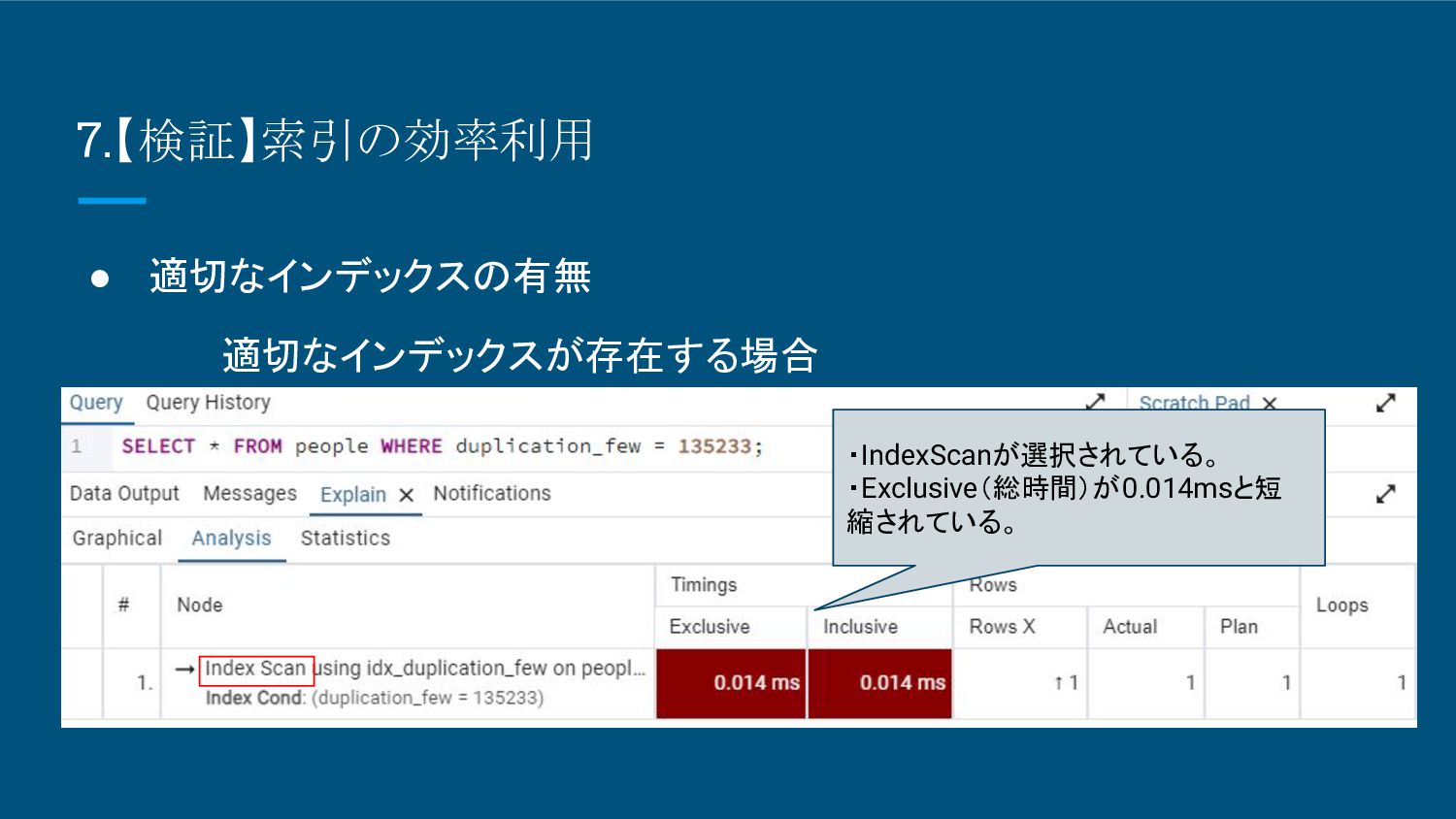
8.【検証】索引の効率利用 • 適切なインデックスの有無 適切なインデックスが存在する場合 ・IndexScanが選択されている。 ・Inclusive(総時間)が0.014msと短縮 されている。
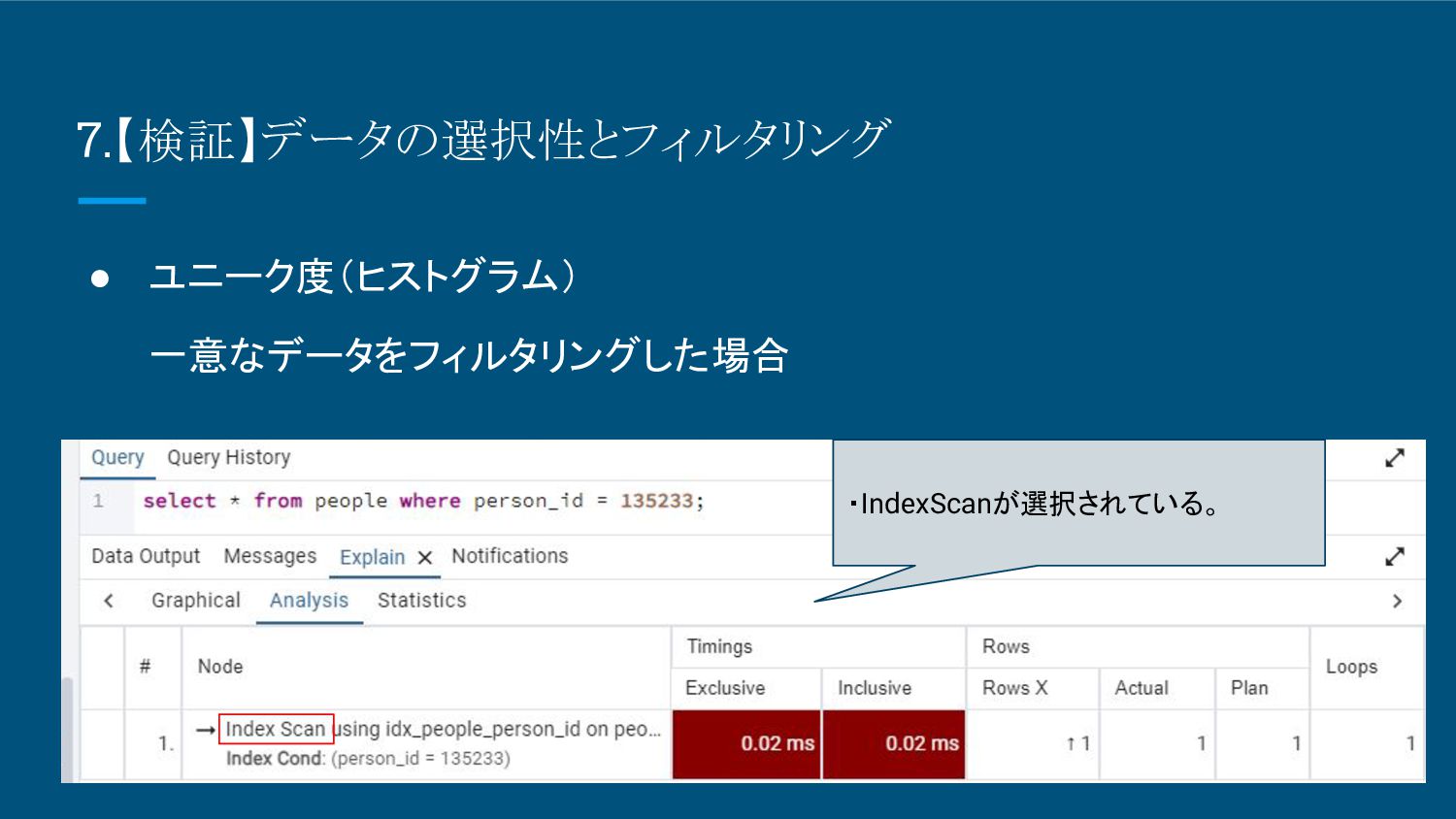
8.【検証】データの選択性とフィルタリング • ユニーク度(ヒストグラム) 一意なデータをフィルタリングした場合 ・IndexScanが選択されている。
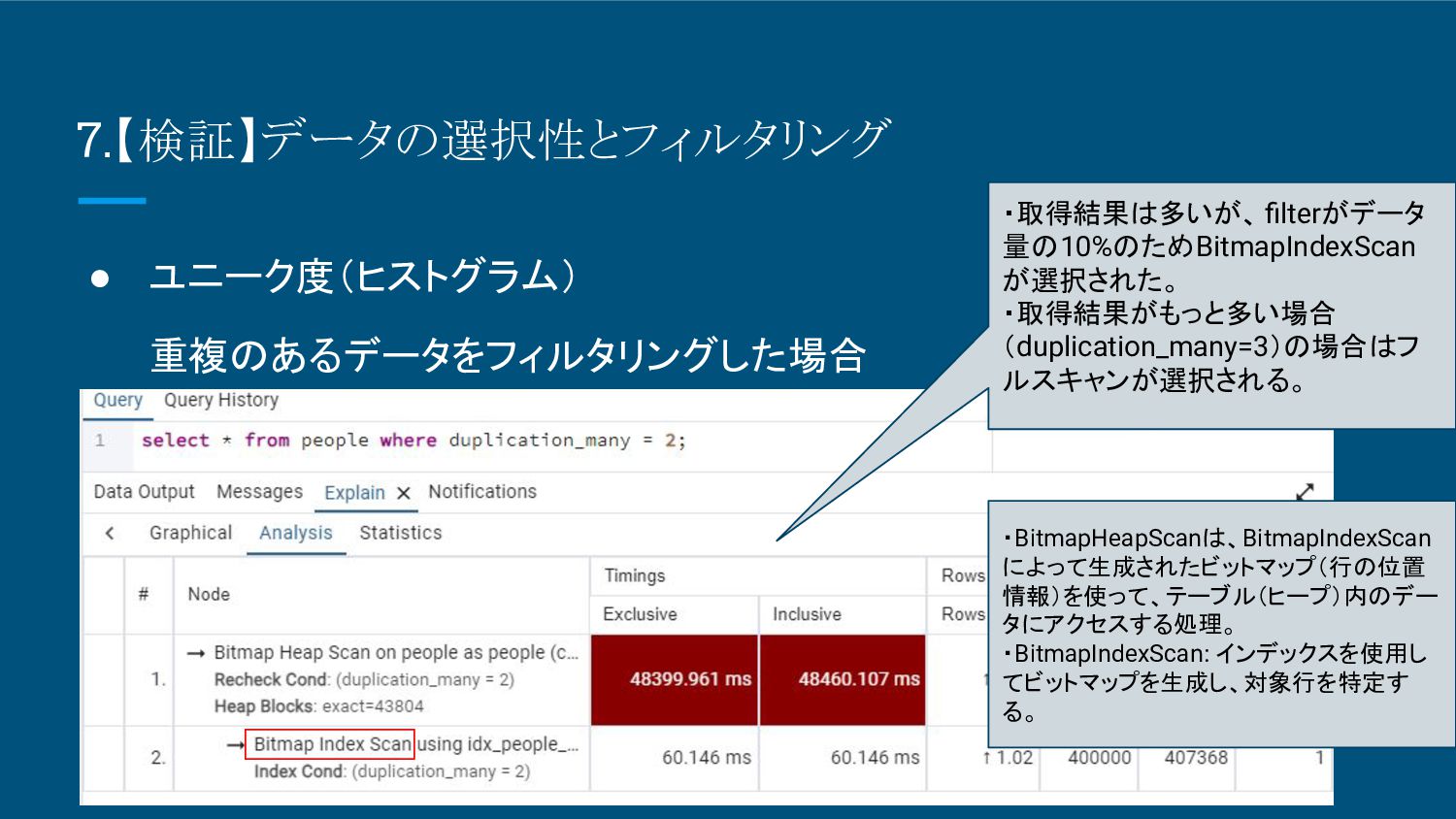
8.【検証】データの選択性とフィルタリング • ユニーク度(ヒストグラム) 重複のあるデータをフィルタリングした場合 ・取得結果は多いが、 filterがデータ 量の10%のためBitmapIndexScan が選択された。 ・取得結果がもっと多い場合 (duplication_many=3)の場合はフ
ルスキャンが選択される。 ・BitmapHeapScanは、BitmapIndexScan によって生成されたビットマップ(行の位置 情報)を使って、テーブル(ヒープ)内のデー タにアクセスする処理。 ・BitmapIndexScan: インデックスを使用し てビットマップを生成し、対象行を特定す る。
8.【検証】パーティショニング PEOPLE_LIST_PARTITION テーブル DUPLICATION_MANY = 0 400,000 レコード DUPLICATION_MANY =
1 400,000 レコード DUPLICATION_MANY = 2 400,000 レコード DUPLICATION_MANY = 3 400,000 レコード DUPLICATION_MANY = 4 2,800,000 レコード PEOPLE テーブル DUPLICATION_MANY カラム 0: 400,000 レコード 1: 400,000 レコード 2: 400,000 レコード 3: 2,800,000 レコード パーティション済 非パーティション
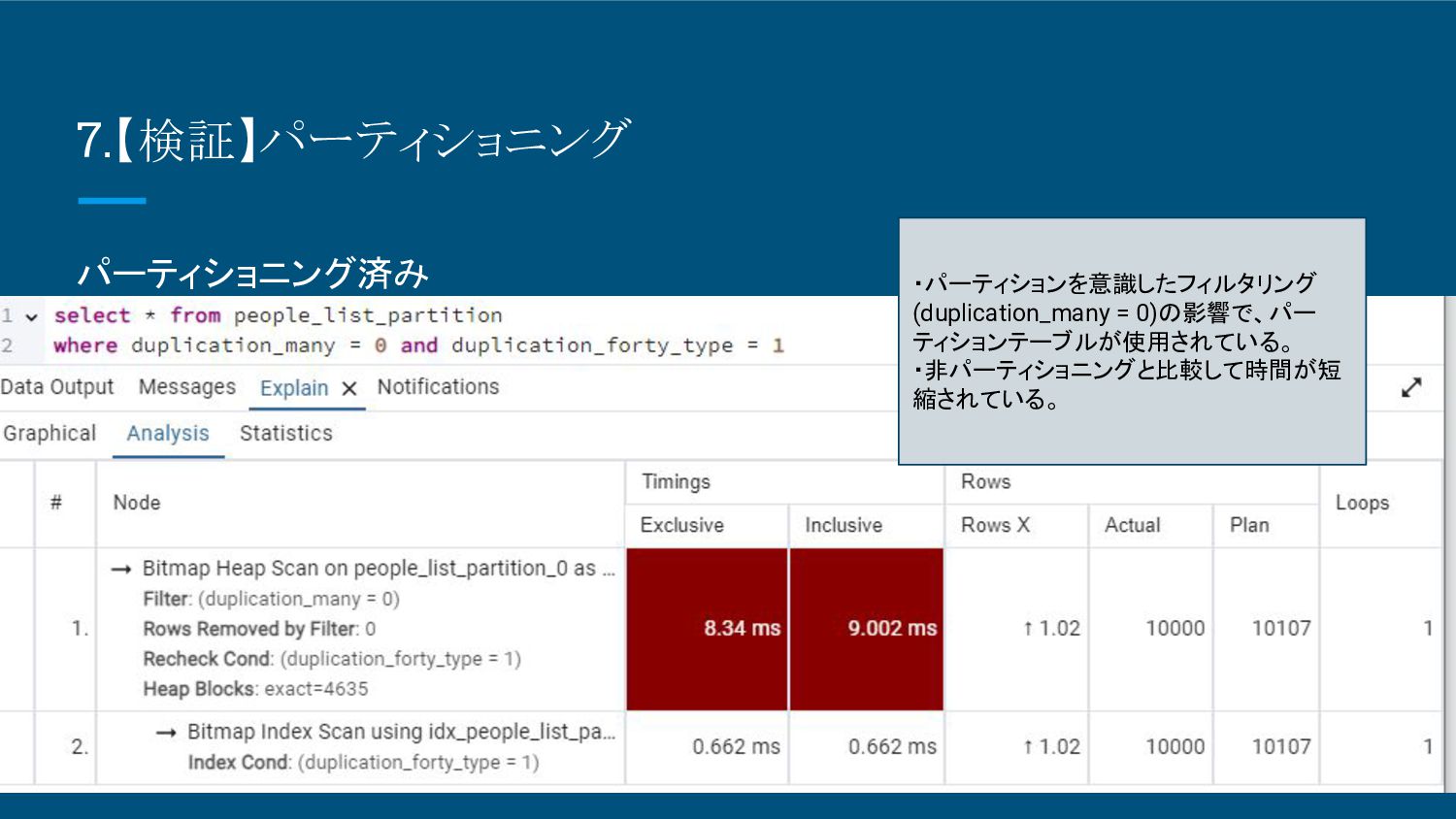
8.【検証】パーティショニング パーティショニング済み ・パーティションを意識したフィルタリング (duplication_many = 0)の影響で、パー ティションテーブルが使用されている。 ・非パーティショニングと比較して時間が短 縮されている。
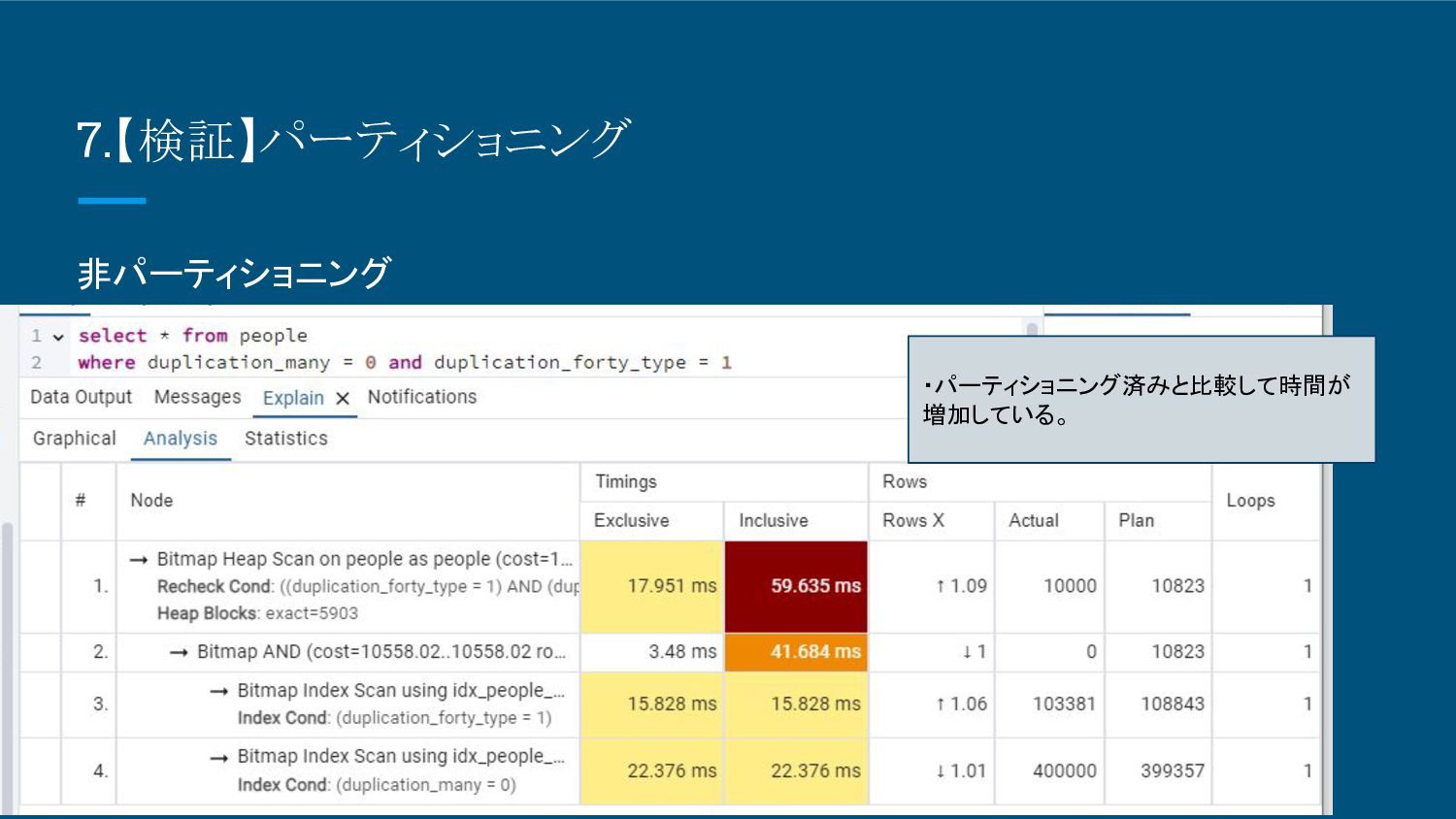
8.【検証】パーティショニング 非パーティショニング ・パーティショニング済みと比較して時間が 増加している。
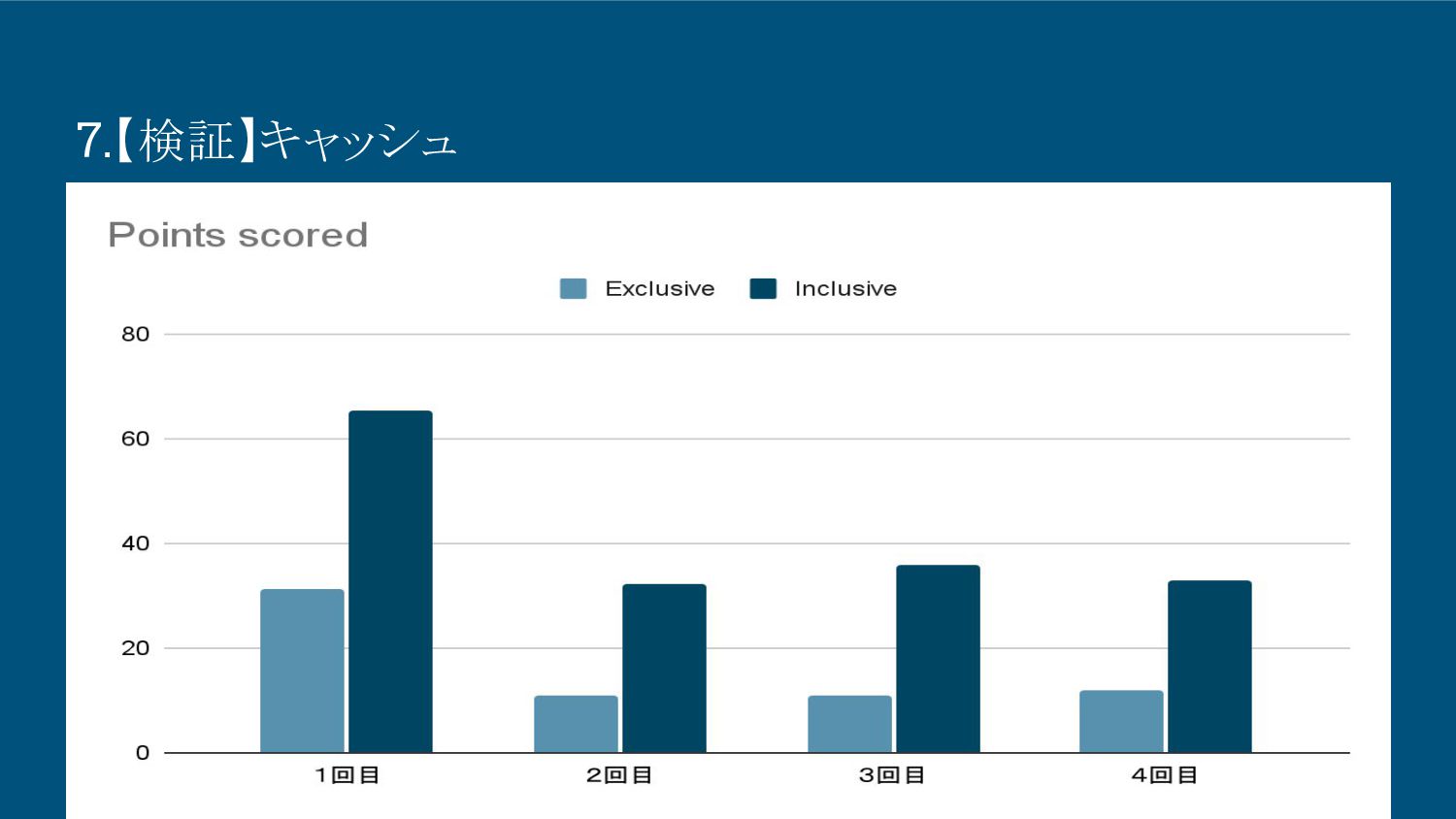
8.【検証】キャッシュ • 以下のとおり4回クエリを実行し検証を行う。 ◦ 1回目:キャッシュを使用しない ◦ 2回目:キャッシュを使用する ◦ 3回目:キャッシュを使用する ◦
4回目:キャッシュを使用する
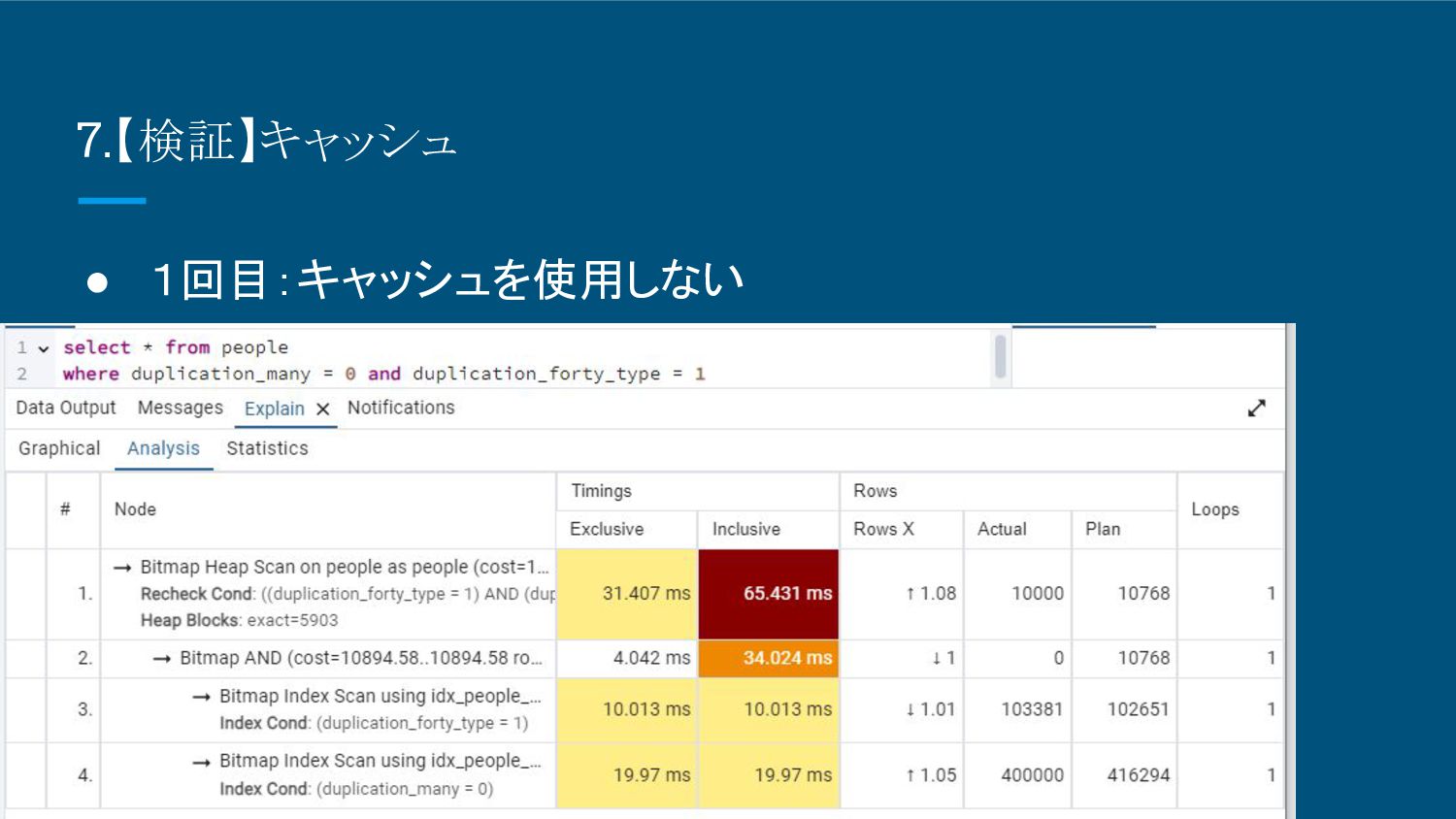
8.【検証】キャッシュ • 1回目:キャッシュを使用しない
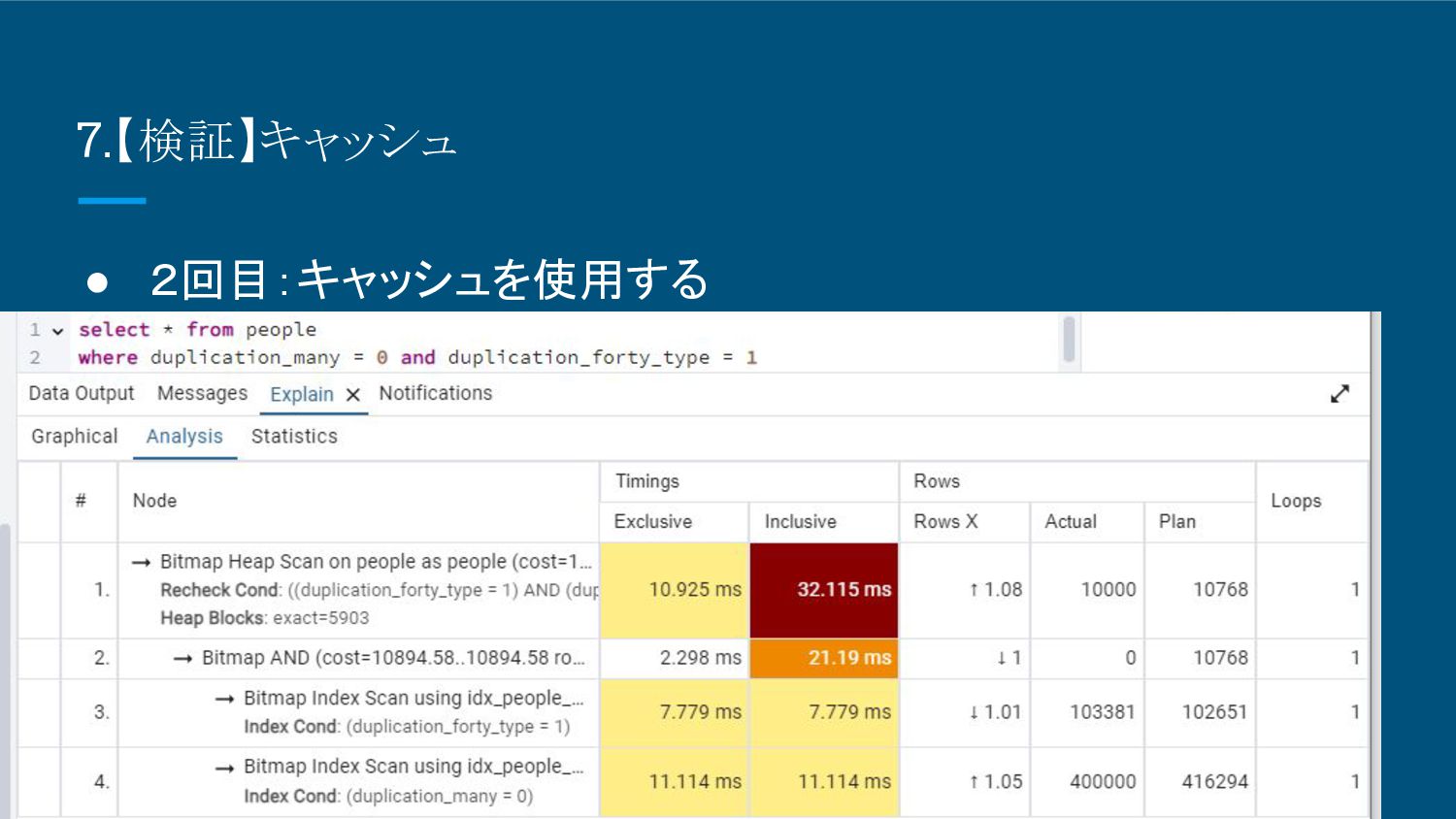
8.【検証】キャッシュ • 2回目:キャッシュを使用する
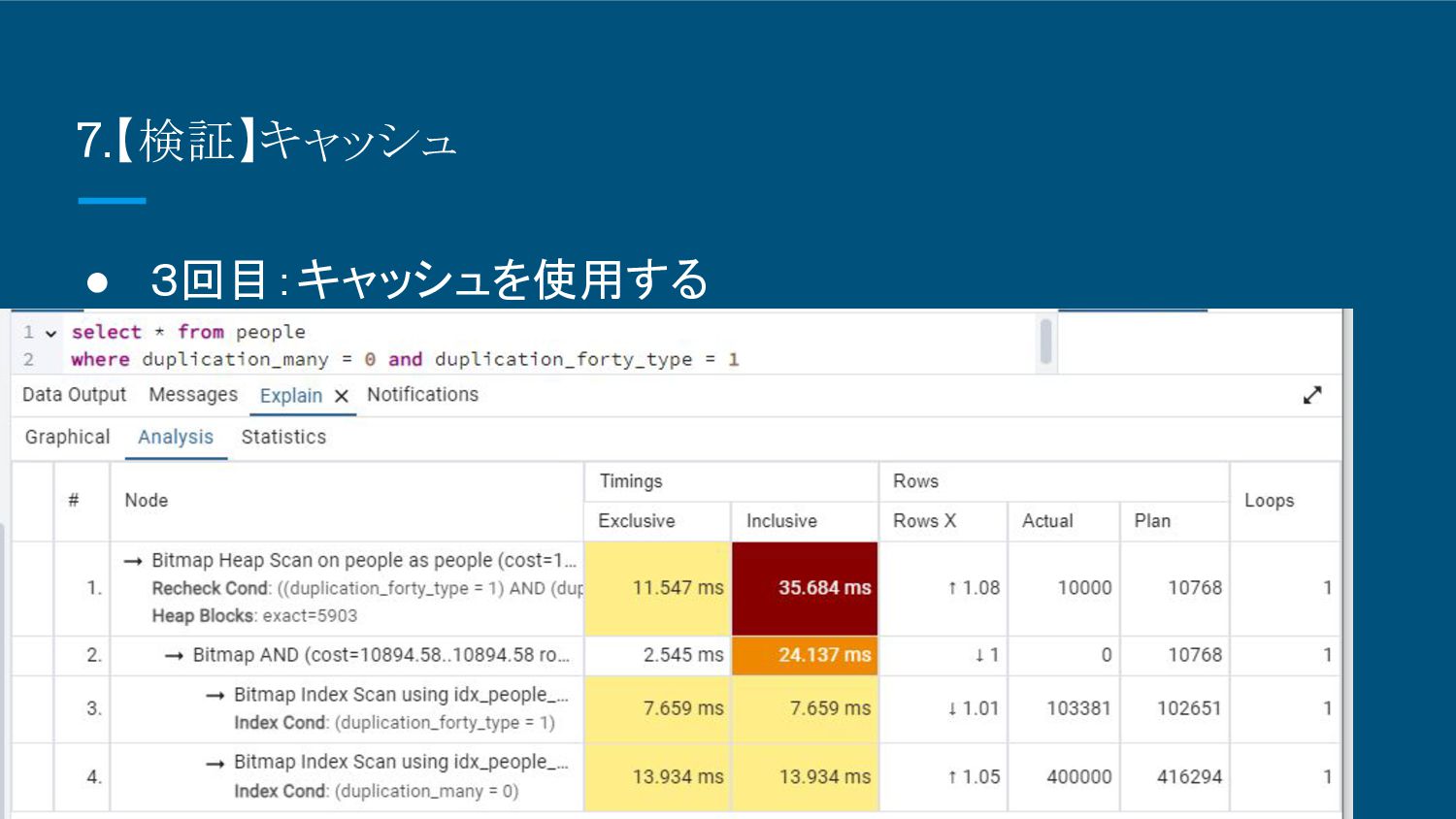
8.【検証】キャッシュ • 3回目:キャッシュを使用する
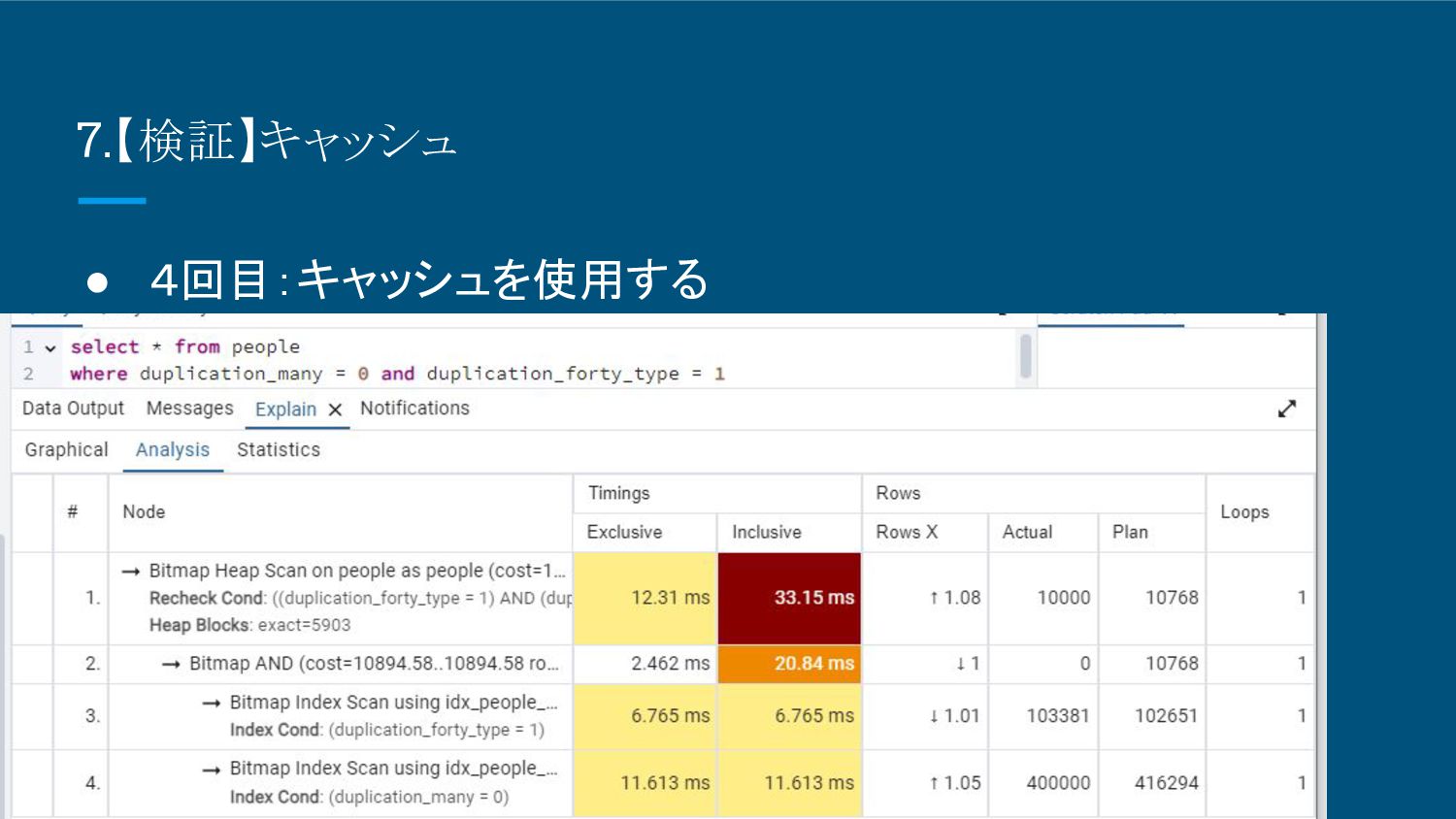
8.【検証】キャッシュ • 4回目:キャッシュを使用する
8.【検証】キャッシュ
9.まとめ • クエリ実行計画の最適化 ◦ 適切なインデックスの使用やデータ選択性の最適化により、クエリのパフォーマンスが向上。 Seq Scan(全行スキャン)とIndex Scanの使い分けが特に重要。 • 索引の効率的な利用
◦ よく使う列にインデックスを作成し、フィルタリングや結合に効果的に利用することでクエリ速度を 向上できる。特に選択性の高い列にはインデックスを優先して作成する。 • パーティショニングの効果 ◦ 大量データを扱うテーブルでは、パーティショニングによりデータの管理やクエリ実行速度が改善 される。クエリが特定のパーティションにだけアクセスすることで、パフォーマンスが向上。 • キャッシュ利用の最適化 ◦ 頻繁にアクセスされるデータをキャッシュすることで、ディスク I/Oを減らし、クエリの応答速度が大 幅に向上する。キャッシュサイズの適切な設定も重要。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}