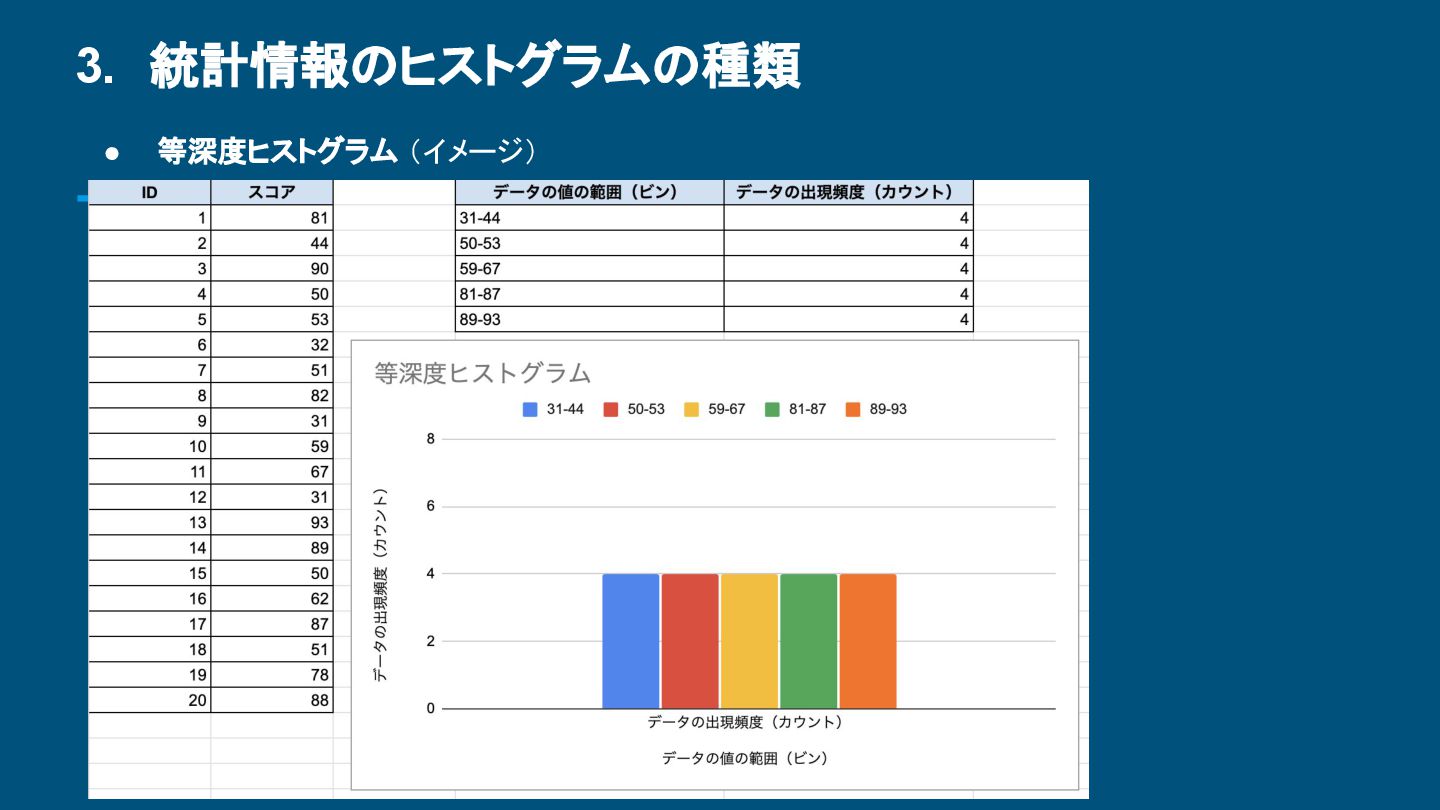
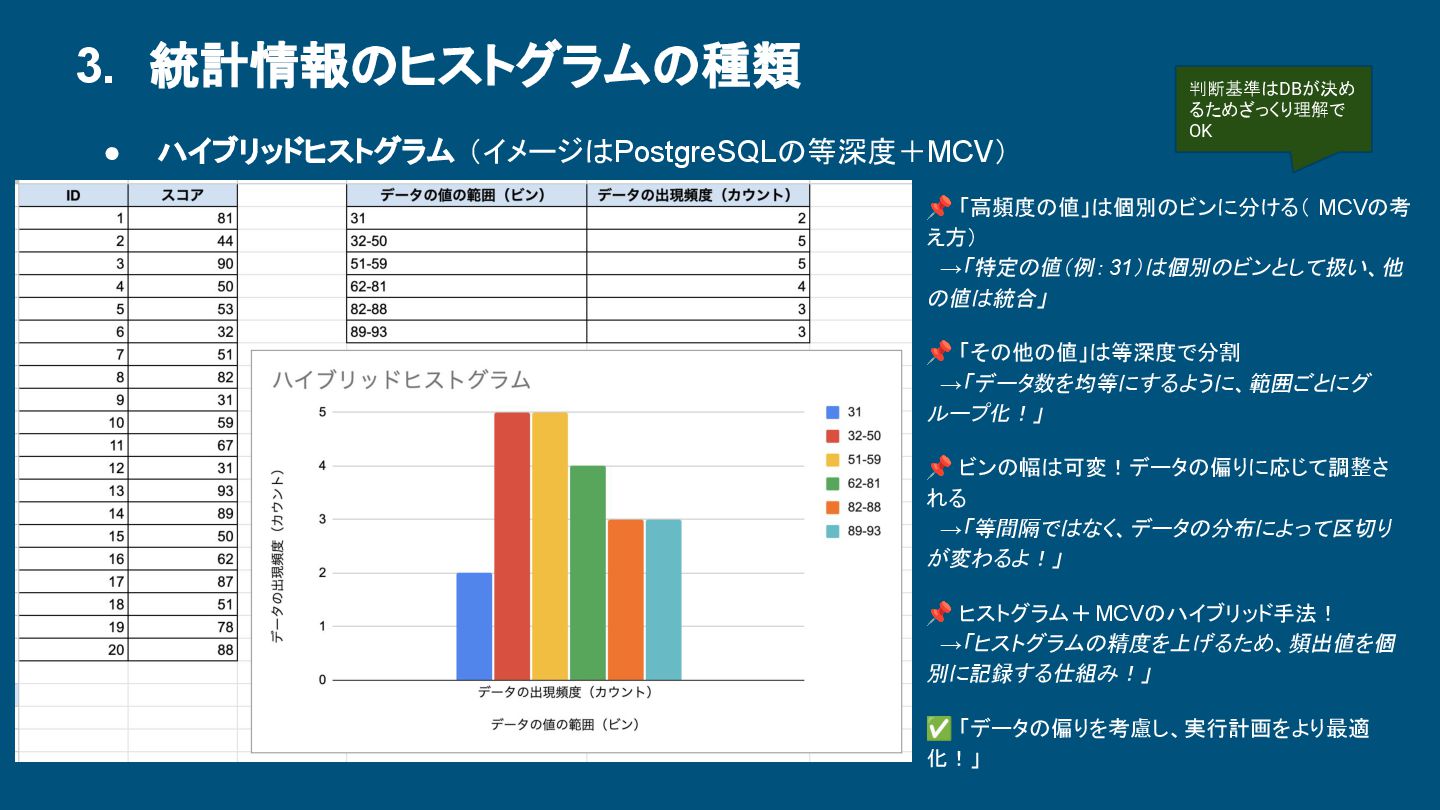
-1 (ユニーク) NULL {112, 38992…} (多いため略) 0.83 COL_B 31803 {100000} (39.95%) {10005, 10899…} (多いため略) -0.65 COL_C 2 {10000, 90000} (約50%ずつ) NULL 1.0 COL_D 10 {E, G, B, F, H, C, A, I, J, D} (約10%ずつ) NULL 0.108 ユニーク な値の数 よく出る値リスト (NULLはMCVを使用しない) 等深度ヒストグラムの境界 (NULLは等深度を使用しない ) カラム値の並びと物理順の相関 1 に近い:IndexScan向き -1に近い:逆IndexScan向き 0 に近い:FullScanの可能性 「物理順」 →ディスク上のデータの並び (実際の保存順) 「カラム値の順序」 →カラムの値を大小順に並べた場合の 論理的な概念(物理順とは関係なし)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
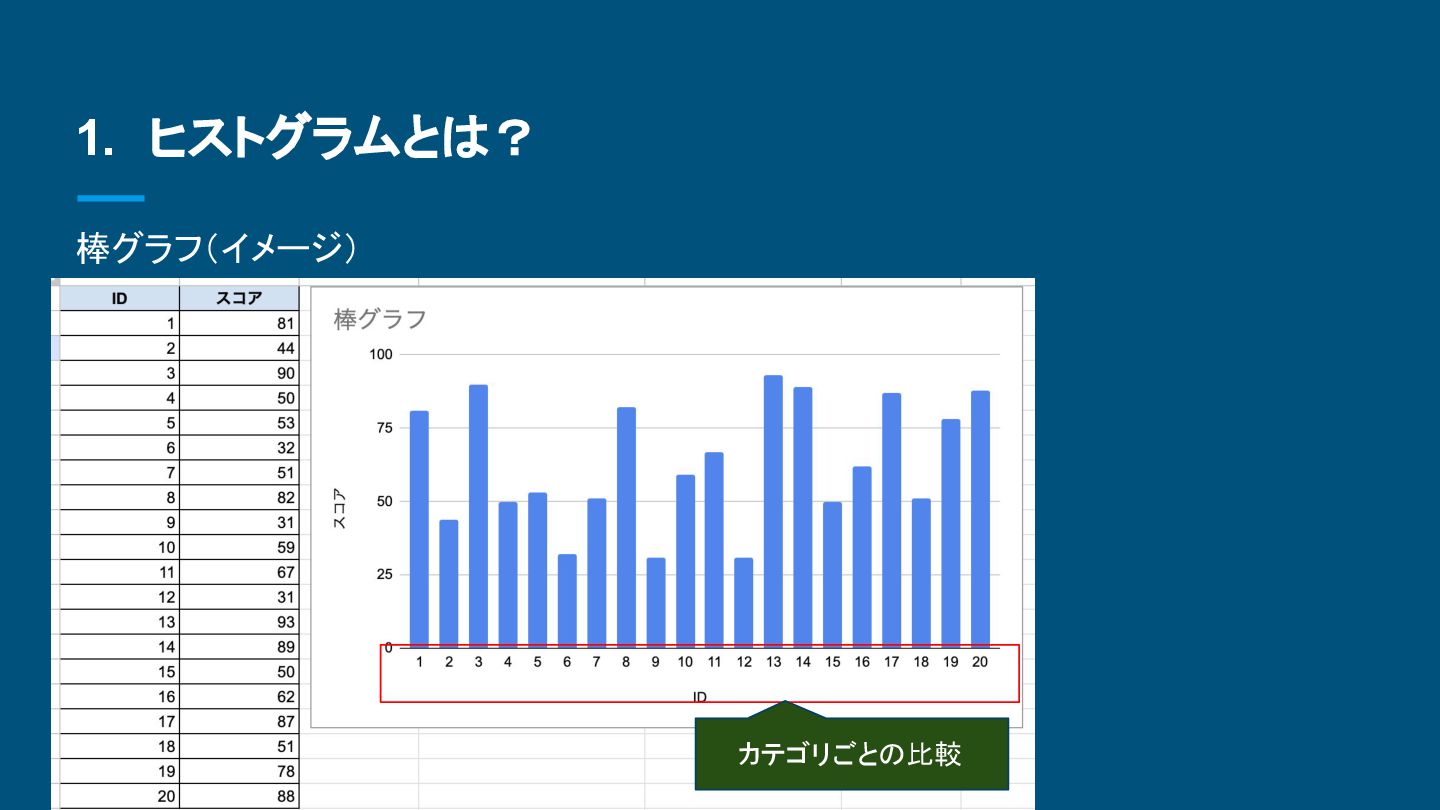{kind=link}
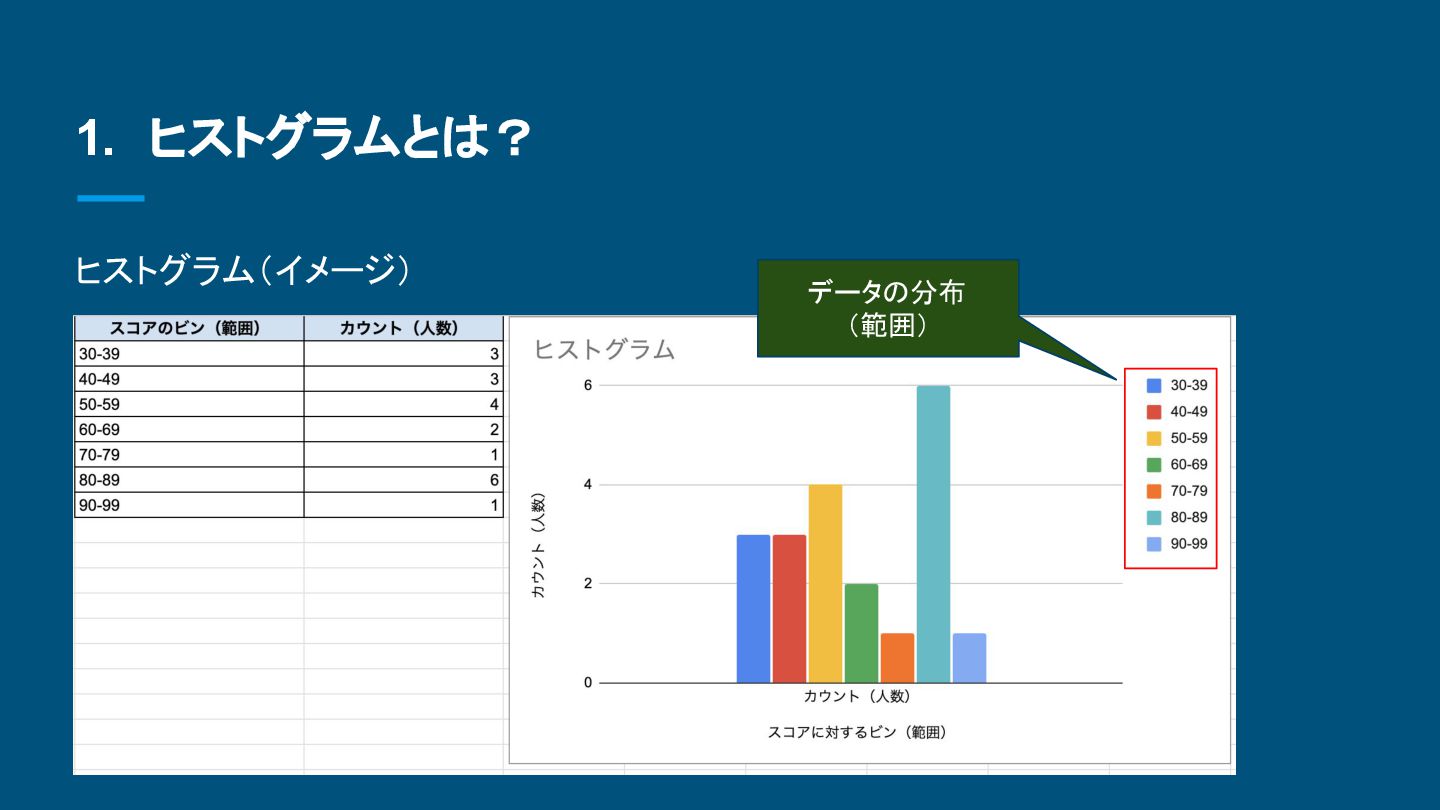{kind=link}
{kind=link}
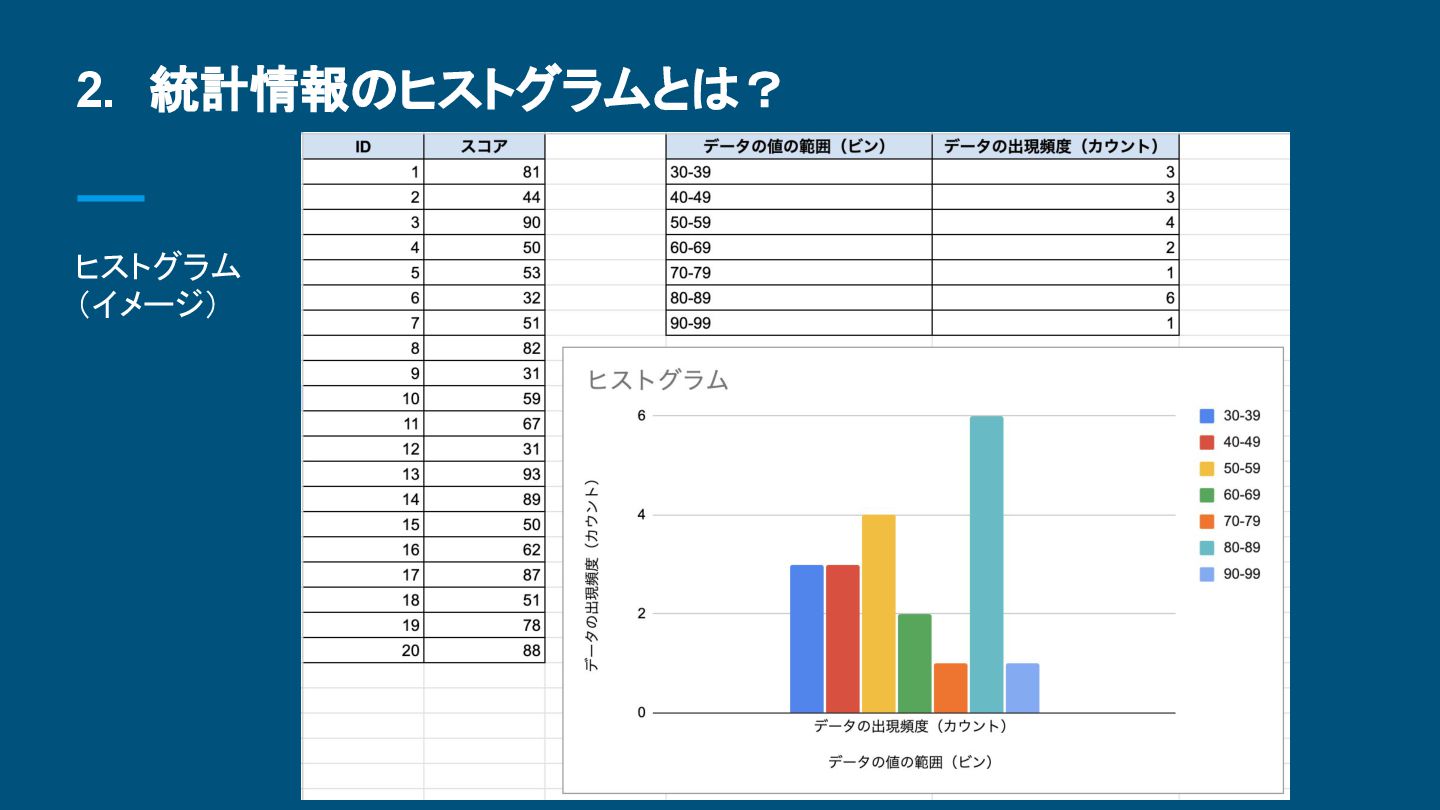{kind=link}
{kind=link}
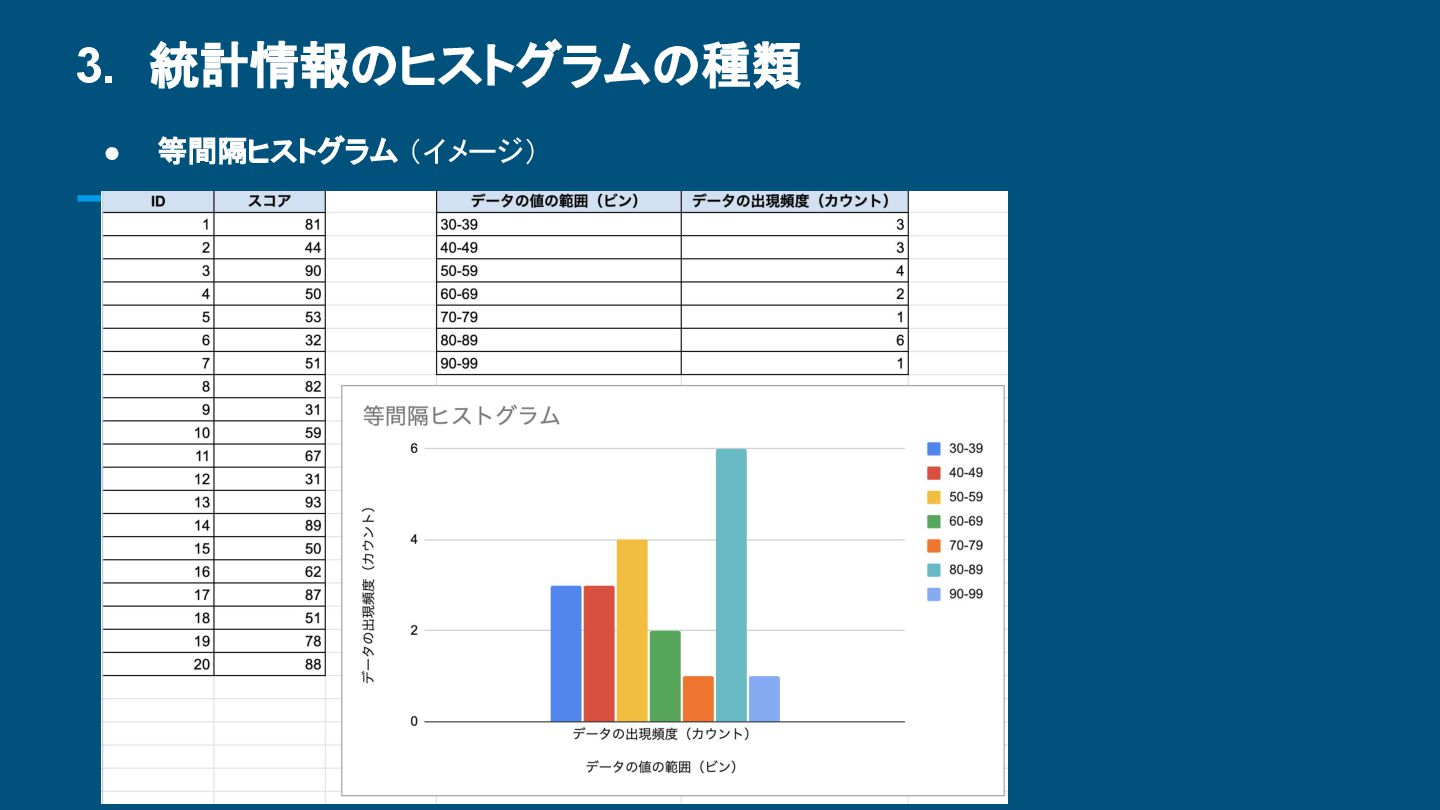{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}