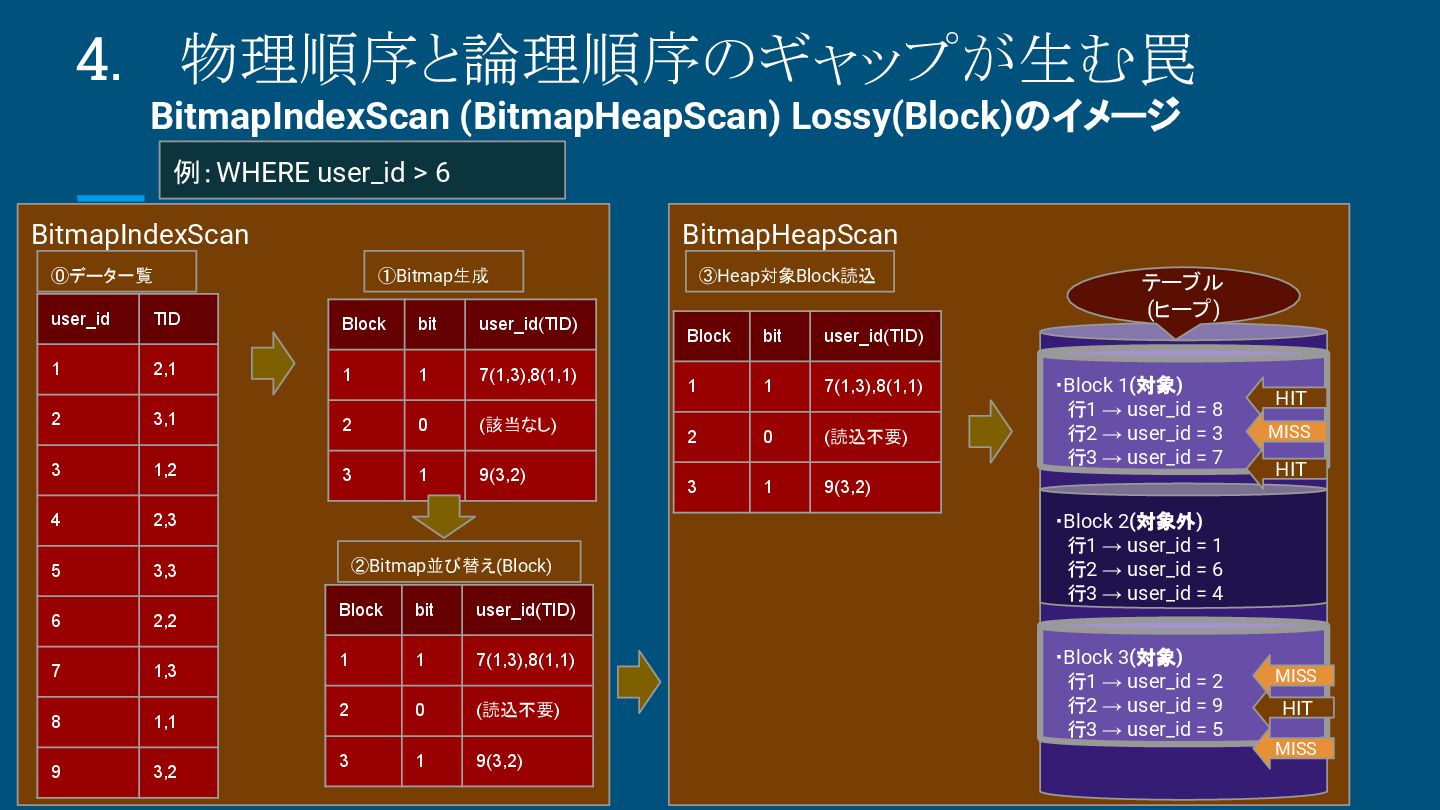
BitmapHeapScan ・Block 1(対象) 行1 → user_id = 8 行2 → user_id = 3 行3 → user_id = 7 ・Block 2(対象外) 行1 → user_id = 1 行2 → user_id = 6 行3 → user_id = 4 ・Block 3(対象) 行1 → user_id = 2 行2 → user_id = 9 行3 → user_id = 5 テーブル (ヒープ) HIT HIT Block bit user_id(TID) 1 1 7(1,3),8(1,1) 2 0 (該当なし) 3 1 9(3,2) ①Bitmap生成 ②Bitmap並び替え(Block) ③Heap対象Block読込 Block bit user_id(TID) 1 1 7(1,3),8(1,1) 2 0 (読込不要) 3 1 9(3,2) Block bit user_id(TID) 1 1 7(1,3),8(1,1) 2 0 (読込不要) 3 1 9(3,2) HIT MISS MISS MISS user_id TID 1 2,1 2 3,1 3 1,2 4 2,3 5 3,3 6 2,2 7 1,3 8 1,1 9 3,2 ⓪データ一覧
{kind=link}
{kind=link}
{kind=link}
{kind=link}
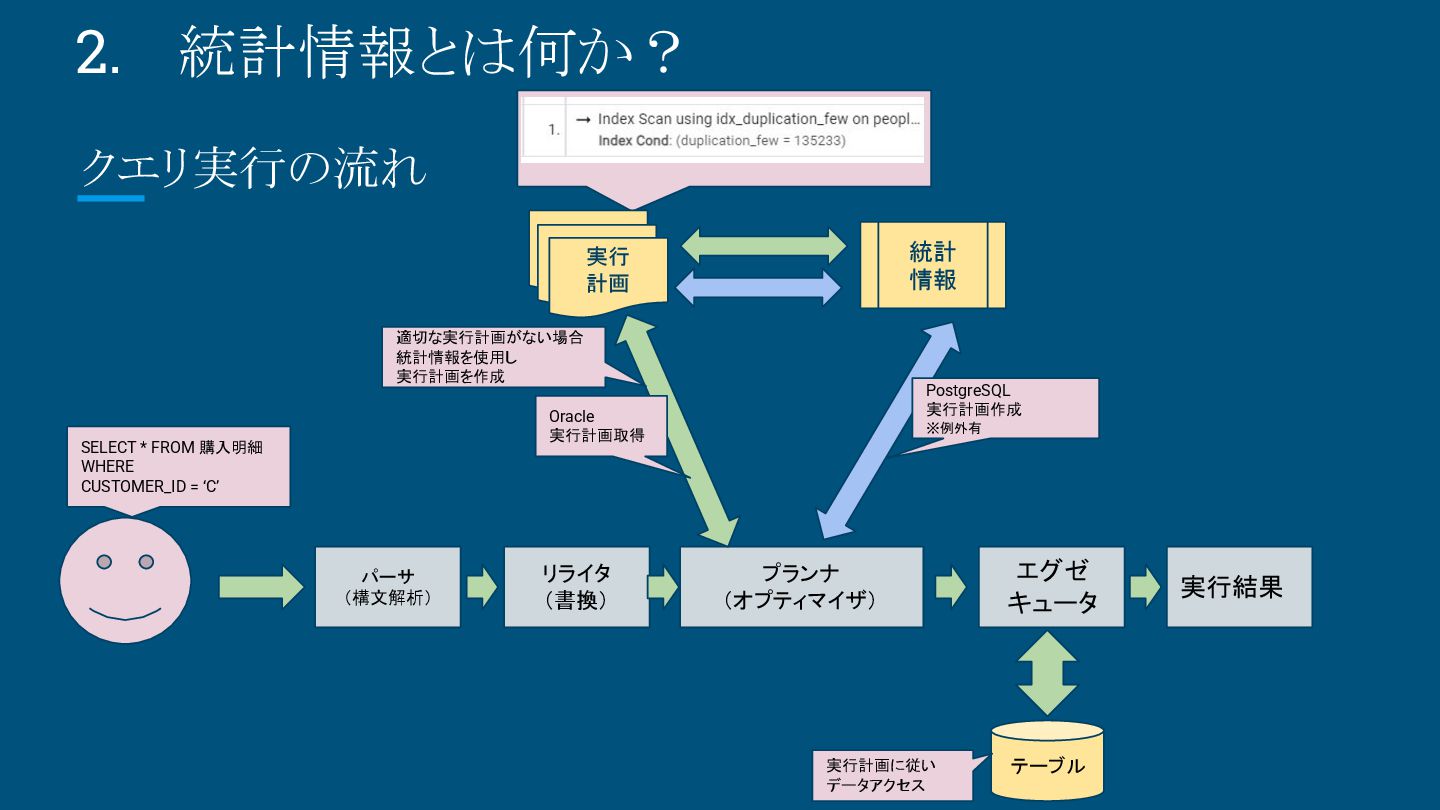{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
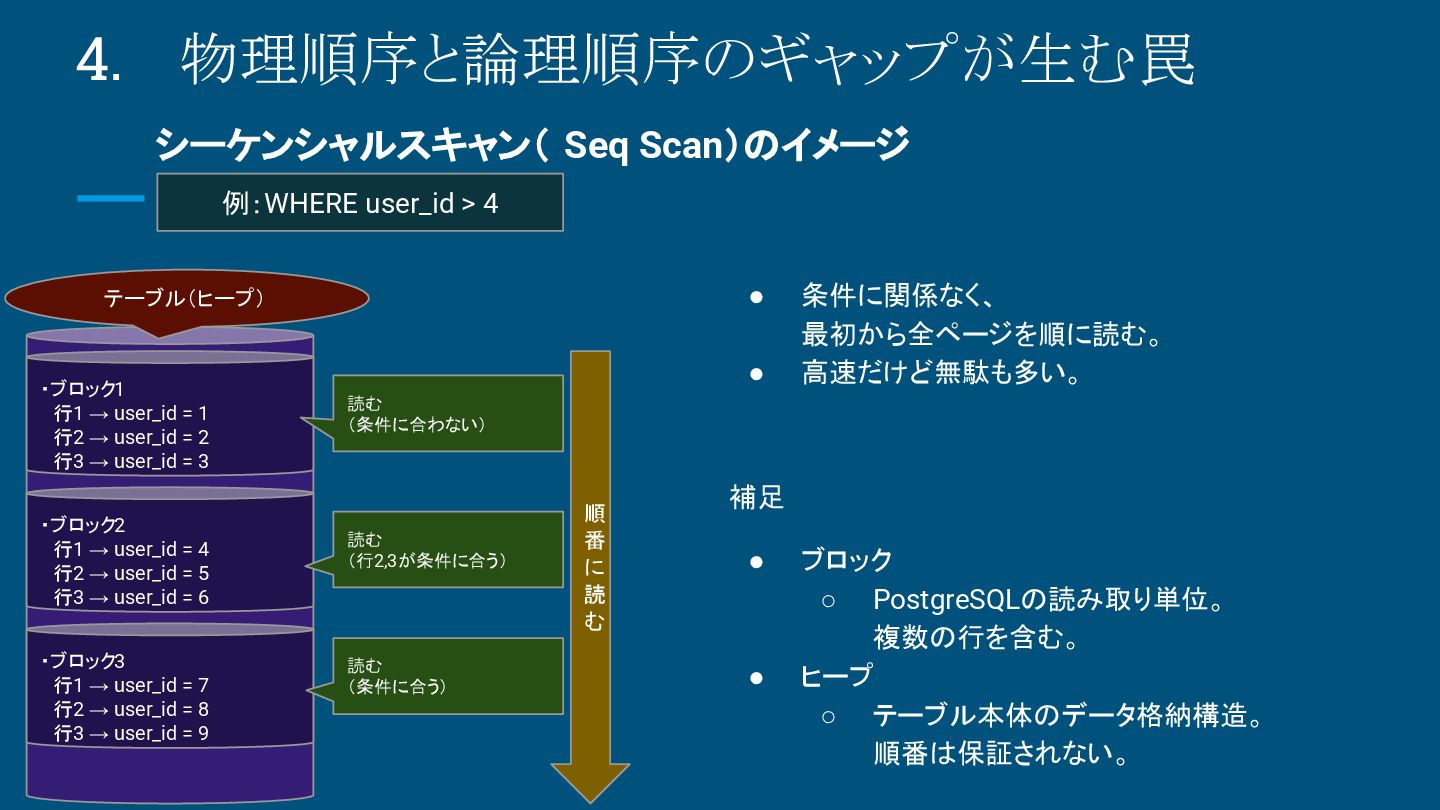{kind=link}
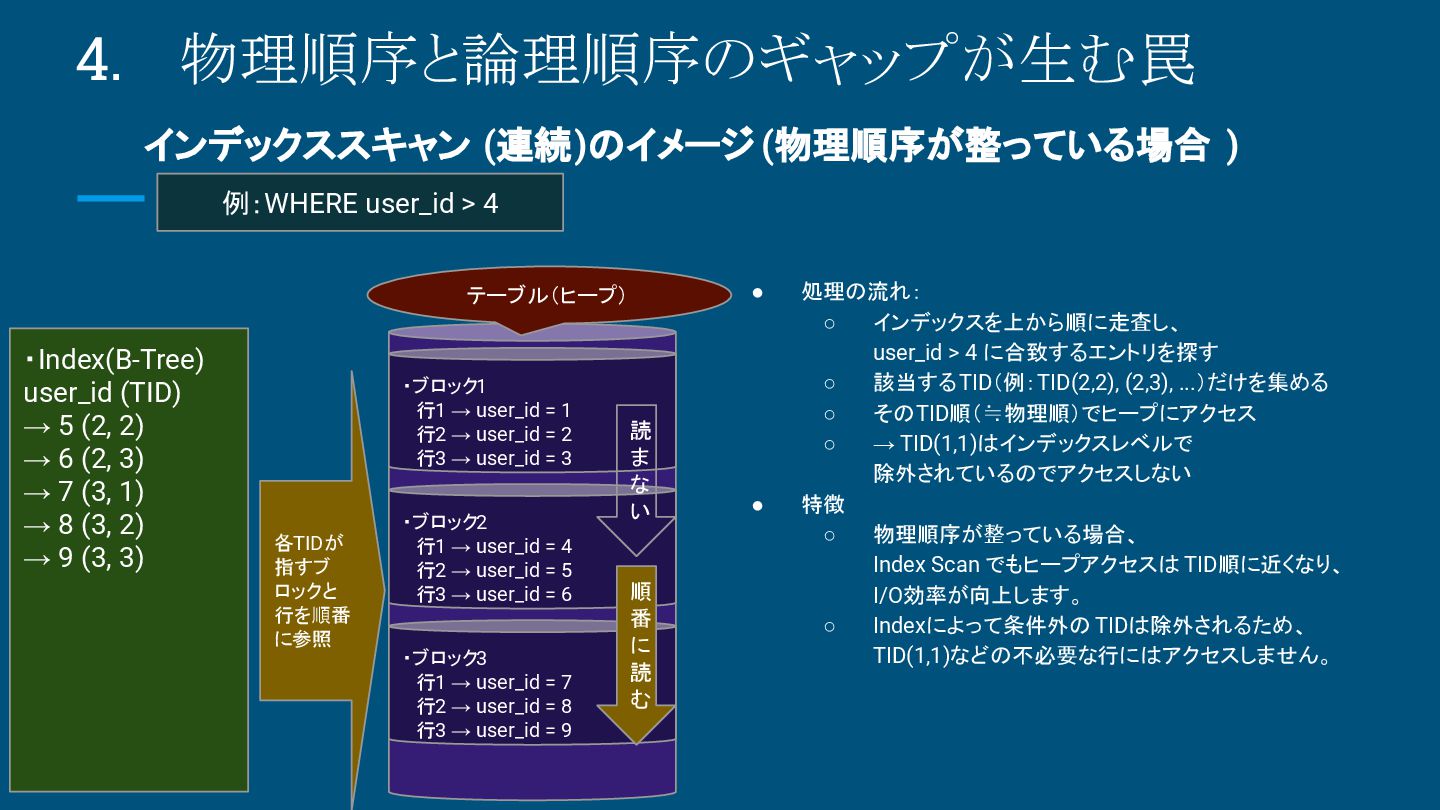{kind=link}
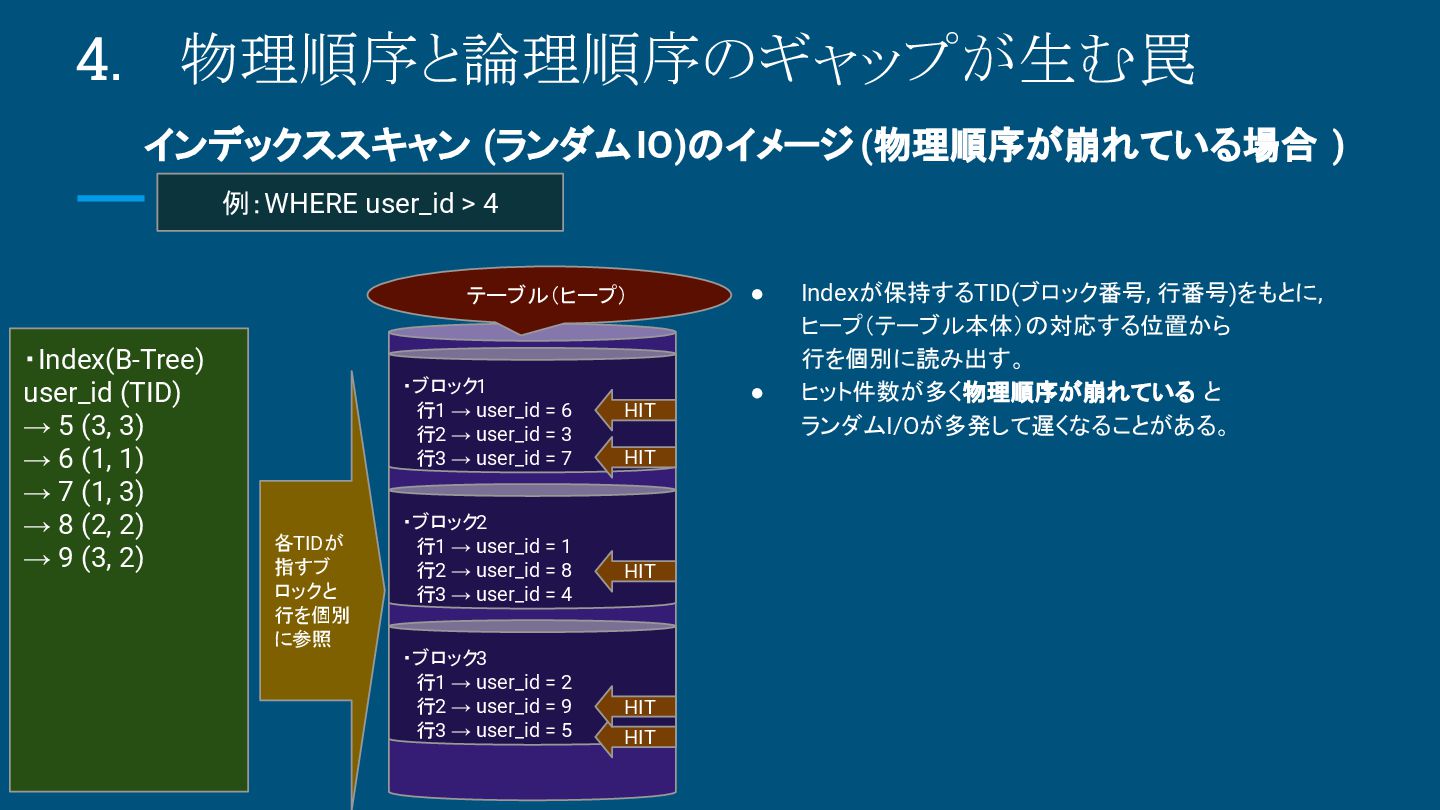{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
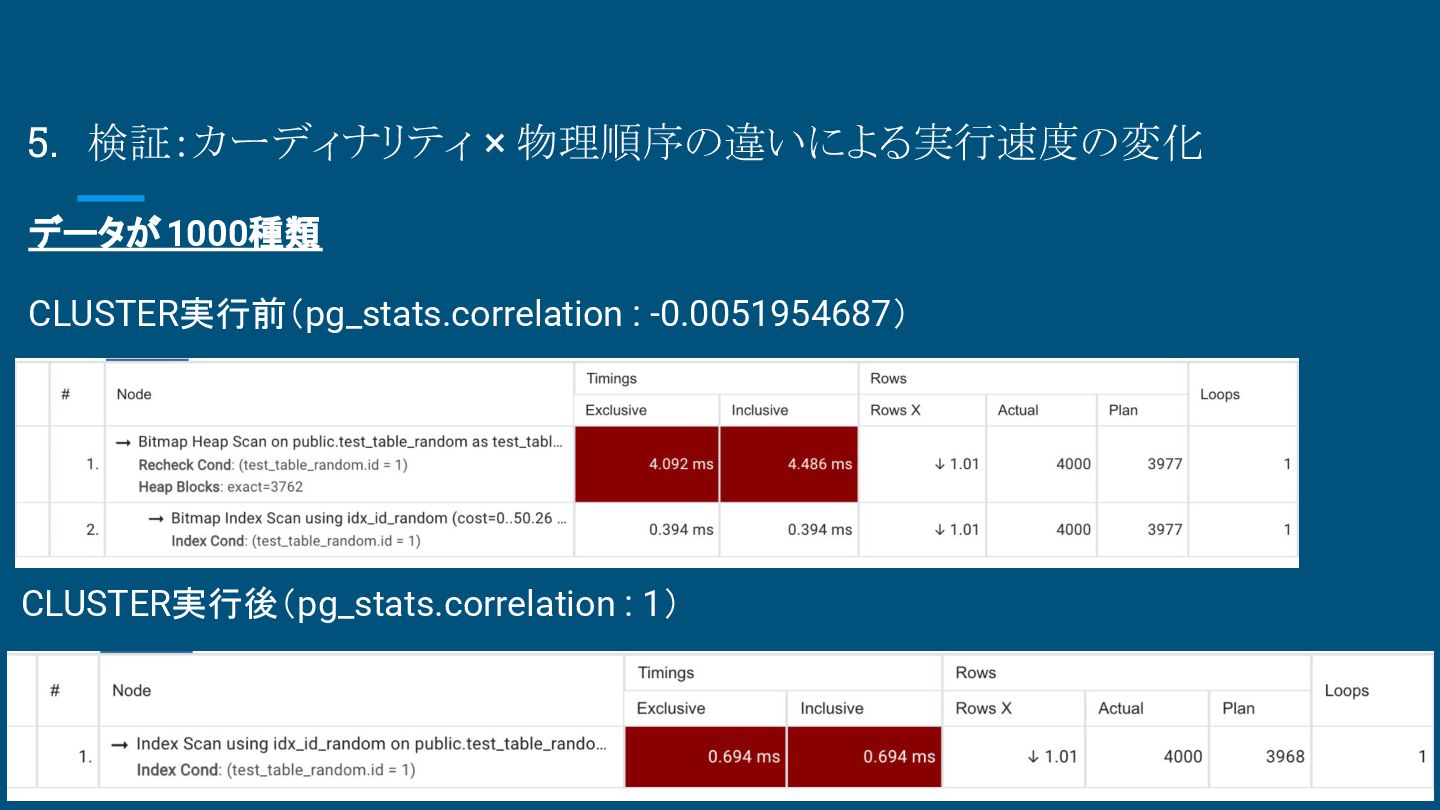{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}