Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
プログラミングコンテスト攻略のためのデータ分析入門 / Lambda + Athena + G...
Search
Hiroyuki S@no
July 09, 2018
Programming
2.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
プログラミングコンテスト攻略のためのデータ分析入門 / Lambda + Athena + Glue + Firehose でサーバーレスな分析基盤をつくってみた / dive-into-mixi-night-2018
Hiroyuki S@no
July 09, 2018
Other Decks in Programming
See All in Programming
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
140
どこまでゆるくて許されるのか
tk3fftk
0
390
Webフレームワークの ベンチマークについて
yusukebe
0
200
TAKTでAI駆動開発の品質を設計する
j5ik2o
7
1.7k
dRuby over BLE
makicamel
2
410
スマートグラスで並列バイブコーディング
hyshu
0
280
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
160
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
160
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
250
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
780
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
190
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
110
Featured
See All Featured
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Design in an AI World
tapps
1
260
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Build your cross-platform service in a week with App Engine
jlugia
234
18k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
640
WENDY [Excerpt]
tessaabrams
11
38k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
770
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
270
Transcript
--- Codeforces の提出ログで機械学習してみた 2018.07.06 - Dive into mixi night! #2
Hiroyuki Sano # mixi, Inc. 1
何を話すか 2 コンテストの分析を通して業務で使っている技術について紹介してみる • サーバーレスな分析基盤の構築 • Doc2Vec を使ったコンテストの問題分類
$ whoami 3
自己紹介 :-) • 名前: さの ひろゆき ◦ 2017年度新卒入社 4
仕事 • モバイルゲームに関するデータの分析と集計 • そのためのインフラおよび社内分析ツールの開発と運用 5
入社前の経歴 • 2009: パソコン甲子園プログラミング部門予選通過(会津大学) • 2010: 福岡にある工業高校を卒業後、高専編入に失敗し浪人 • 2011: 会津大学に入学
◦ IPA / 経産省: セキュリティ&プログラミングキャンプ2011 • 2012〜2013: 休学 • 2014: 復学 ◦ Aizu Online Judge 研究室 ▪ http://web-ext.u-aizu.ac.jp/~yutaka/ ◦ 第4期サイボウズ・ラボユース • 2015: 在学 ◦ Google Summer of Code 2015 ▪ https://github.com/rails/web-console • 2016: 在学 ◦ Google Summer of Code 2016 ◦ IPA / 経産省: 2016年度未踏事業クリエータ • 2017: 会津大学を中退してミクシィに新卒入社 6
0. はじめに 7
8
※ 注: Kaggleの話ではないです :-| 9
プログラミングコンテストを分析します :-) 10
プログラミングコンテストについて 競技プログラミング(Competitive Programming)と呼ばれるアルゴリズムの実装スキルを 競うコンテストがオンライン上で定期的に開催されている • Codeforces # https://codeforces.com • HackerRank
# https://www.hackerrank.com • AtCoder # https://atcoder.jp これらのコンテストでは難易度別に複数の問題が与えられて時間内に解答となるプログ ラムをなるべく早く多く実装していく 11
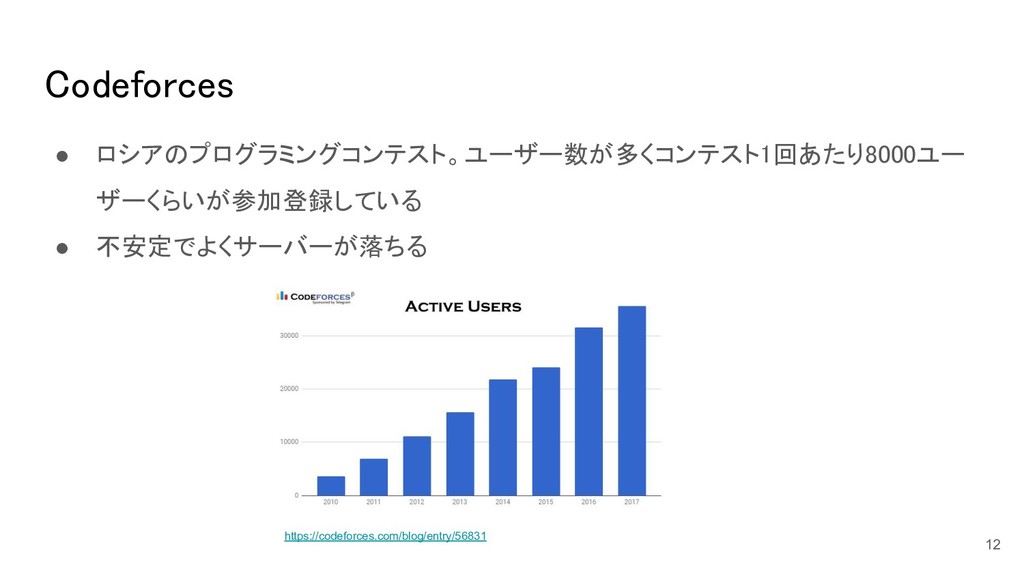
Codeforces • ロシアのプログラミングコンテスト。ユーザー数が多くコンテスト1回あたり8000ユー ザーくらいが参加登録している • 不安定でよくサーバーが落ちる https://codeforces.com/blog/entry/56831 12
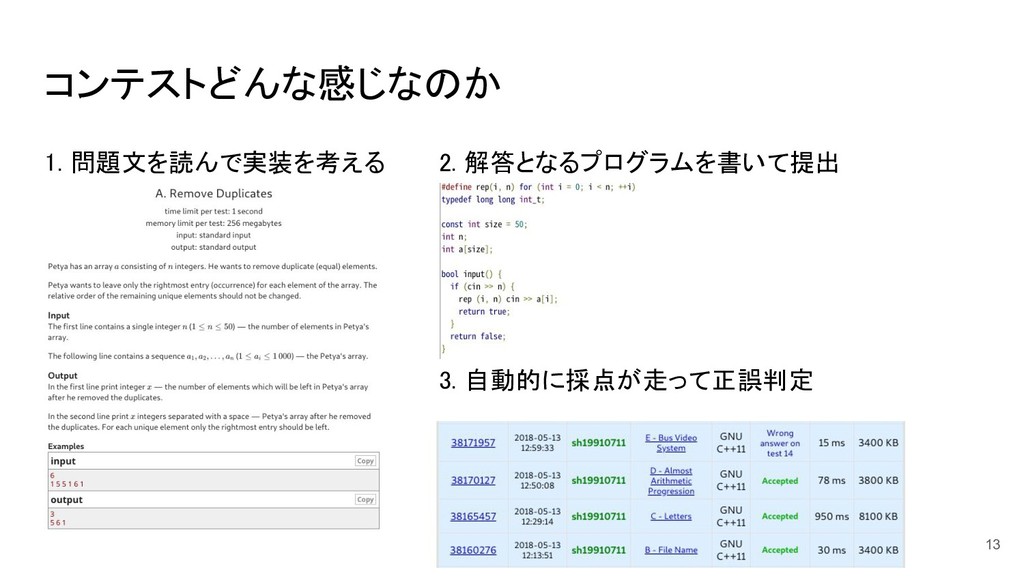
コンテストどんな感じなのか 2. 解答となるプログラムを書いて提出 1. 問題文を読んで実装を考える 3. 自動的に採点が走って正誤判定 13
Codeforces: 直近のコンテスト 14 昨年末にリリースされた量子コンピューティング用のプログラミング言語 Q# を使った Microsoft 主催のコンテストがある URL: http://codeforces.com/msqs2018
※ 7月7日(土)の午前1時から
1. データを集める 15
Codeforces API • コンテストの提出ログなどが取れる ◦ いつ・誰が・どの問題を正解・不正解だったのか ◦ ほかにも問題で使用するアルゴリズム名のタグが取れたりする • ほとんどの
Web API は認証不要で実行可能 URL: https://codeforces.com/api/help 16
Codeforces API: contest.status コンテスト別の全ユーザーの提出ログ(コンテスト終了後の提出も含む) 以下は Web API の実行例: 17
Codeforces API: contest.status の詳細 verdict という項目で正解したかどうかがわかる このデータを AWS を使って SQL
でクエリできる状態にしてみる ← verdict = OKだと正解 ← 使用したプログラミング言語の名前も取れる 18
効率的な分析のためには 必要なデータを必要なときに素早く取得できるようにしておく必要がある 19
目指すところ 問題別の正解者数などを SQL で集計したりできるようにする 20
設計 21
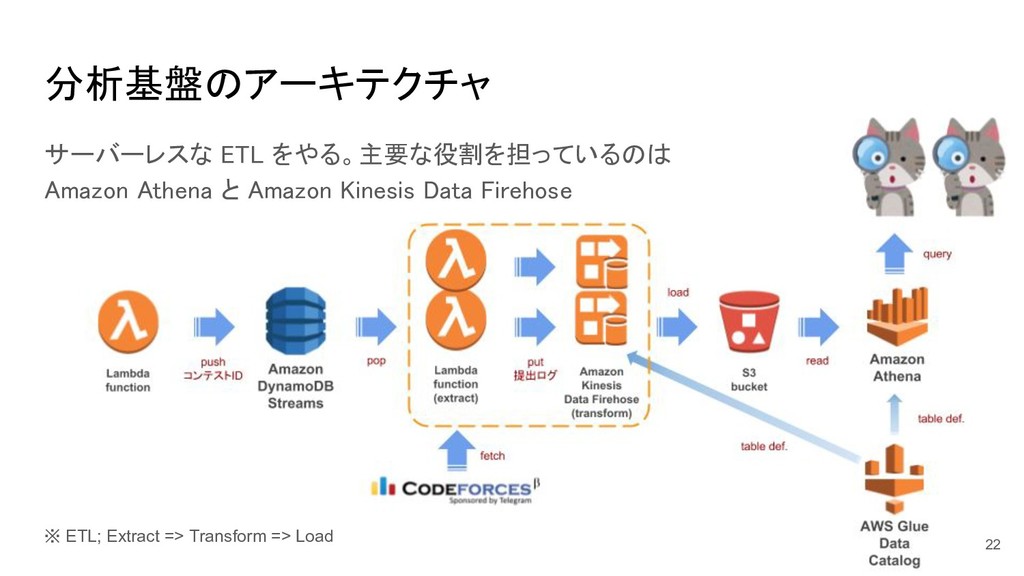
※ ETL; Extract => Transform => Load 分析基盤のアーキテクチャ サーバーレスな ETL
をやる。主要な役割を担っているのは Amazon Athena と Amazon Kinesis Data Firehose 22
Presto ベースのサーバーレスに使えるクエリサービス • Amazon S3 上に格納されているデータに対して SQL でクエリを実行可能 • 従量課金なので事故ると破産する可能性
◦ 巷で話題のクラウド破産を体験できるポテンシャルを持っている ◦ S3 から読んだデータ 1 TB あたり 5 USD ▪ 数十 GB 程度のデータ量であれば気兼ねなく使えるコスト感 ◦ クエリやテーブル定義、ファイルフォーマットを工夫すれば節約できる ※ Presto; Facebook 発の分析用途に適した分散クエリエンジン Athena; https://aws.amazon.com/jp/athena/ AWS: Amazon Athena # 1/3 23
AWS: AWS Glue # 2/3 Data Catalog を使って Athena で読めるテーブルを定義する
• Glue Data Catalog ◦ Glue や Athena 以外にもデータを扱うためのサービスが色々とある ◦ それらでテーブル定義やスキーマを共有できる機能 • Glue Job ◦ フルマネージドな Apache Spark の実行環境 • Glue Crawler ◦ テーブル定義情報を探索して Data Catalog に追加 AWS Glue; https://aws.amazon.com/jp/glue/ 24
AWS: Amazon Kinesis Data Firehose # 3/3 S3 へのデータ投入に Kinesis
Firehose を利用する • ストリーミングデータの処理に使える Kinesis Data 3兄弟の一角 ◦ Stream(PubSub) / Firehose(バッチ変換) / Analytics(集計) • データを投入するとバッチ単位でデータ変換して別のところに出力できる ◦ e.g., CloudWatch Events => Firehose => Elasticsearch • Parquet 形式での出力にも対応 ◦ Athena に適した列指向のファイルフォーマット Amazon Kinesis Data Firehose: https://aws.amazon.com/jp/kinesis/data-firehose/ 25
実装 26
実装: Glue Data Catalog にテーブルを定義する CloudFormation で 構成管理できる 27 ↓S3のパスや入出力形式を指定して
←テーブルのカラムを定義する
実装: Firehose の Delivery Stream を作成 28 Firehose も Glue
Data Catalog を 利用してデータ変換の形式を指定できる Parquet 変換の設定が CloudFormationから出来なかったので手 動設定。構成管理せずに Lambda から動的に立ち上げてデータ投 入がおわったら削除したりする方が良いかもしれない(だが実装が 重くなるかもしれない)
実装: Lambda 関数 # Extract Web API を実行してその結果を テーブル定義に合わせた形に変形する 29
実装: Lambda 関数 # ぶん投げる 変形したら JSON にして Firehose にぶん投げる
データが指定のファイルフォーマットに変換された状態で そのまま S3 に入っていくイメージ 30
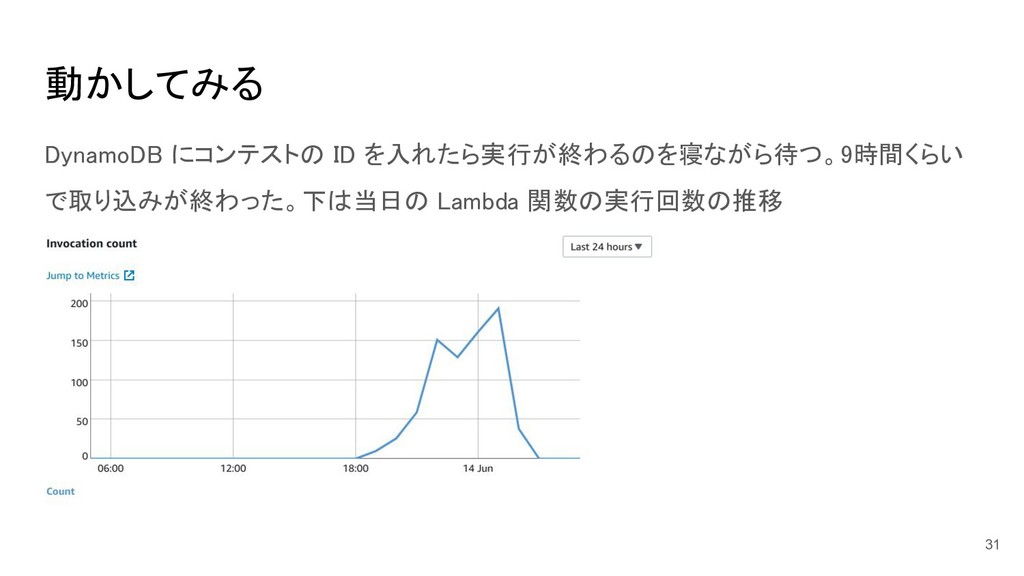
動かしてみる DynamoDB にコンテストの ID を入れたら実行が終わるのを寝ながら待つ。9時間くらい で取り込みが終わった。下は当日の Lambda 関数の実行回数の推移 31
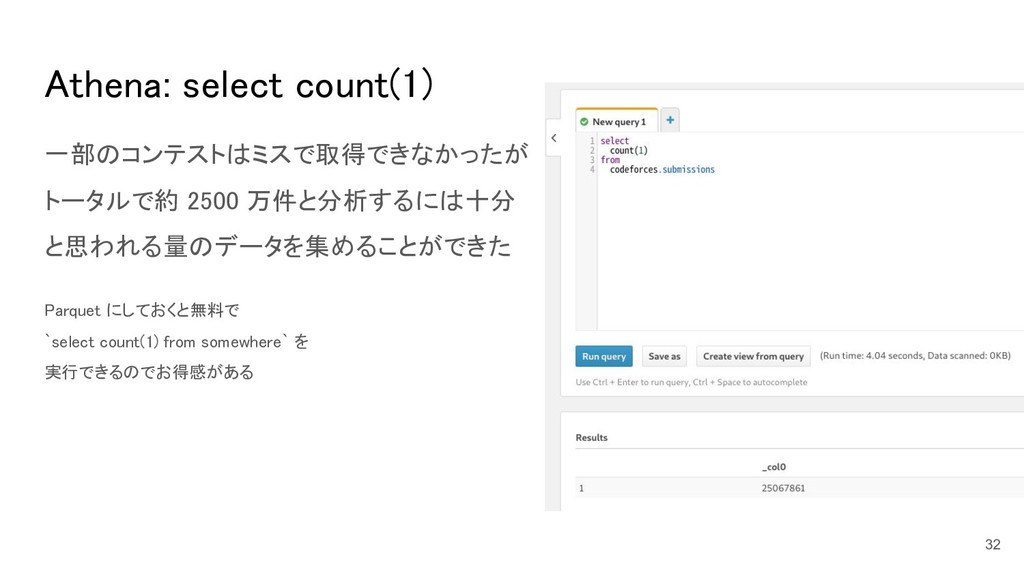
Athena: select count(1) 一部のコンテストはミスで取得できなかったが トータルで約 2500 万件と分析するには十分 と思われる量のデータを集めることができた Parquet にしておくと無料で
`select count(1) from somewhere` を 実行できるのでお得感がある 32
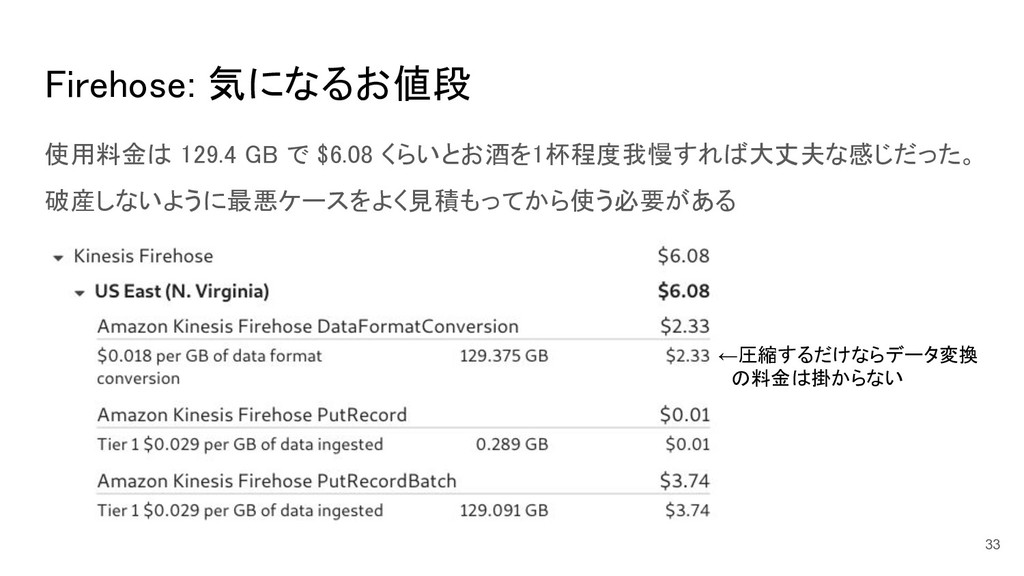
Firehose: 気になるお値段 使用料金は 129.4 GB で $6.08 くらいとお酒を1杯程度我慢すれば大丈夫な感じだった。 破産しないように最悪ケースをよく見積もってから使う必要がある 33
←圧縮するだけならデータ変換 の料金は掛からない
2. データを分析する 34
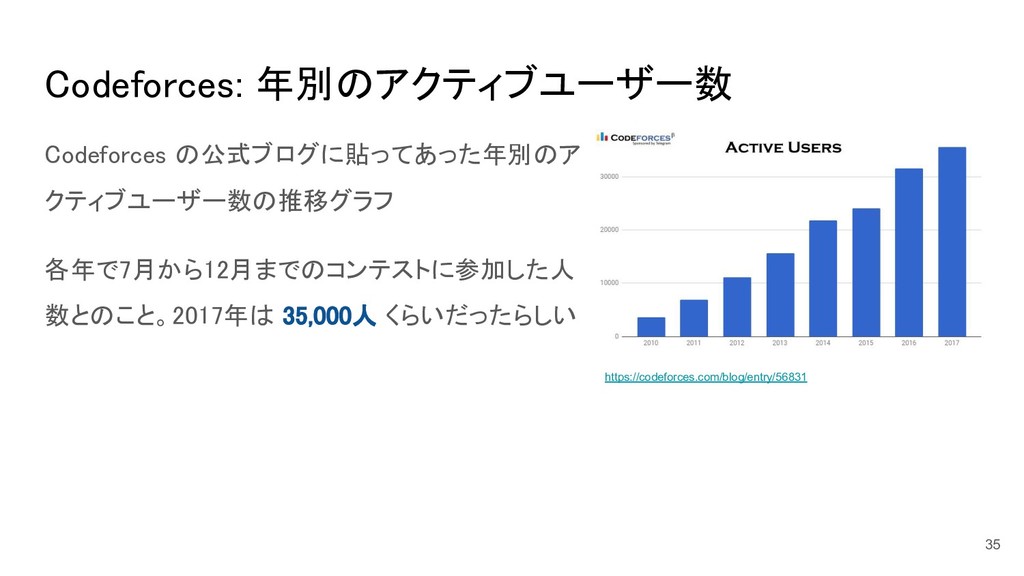
Codeforces: 年別のアクティブユーザー数 35 Codeforces の公式ブログに貼ってあった年別のア クティブユーザー数の推移グラフ 各年で7月から12月までのコンテストに参加した人 数とのこと。2017年は 35,000人 くらいだったらしい
https://codeforces.com/blog/entry/56831
35,000人 36
嘘かもしれない 37
嘘じゃないか確かめる 38 Athena を使って自分でアクティブ ユーザー数を求めてみる ここではコンテスト中に何らかの提 出を行ったことがあるユーザーをア クティブユーザーとして定義 データスキャン量は 200MB
程
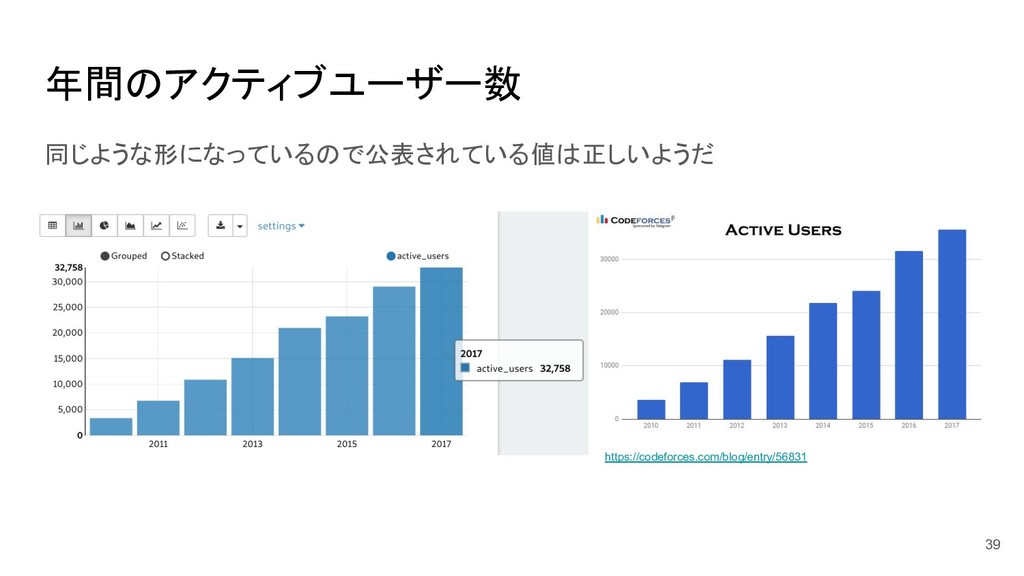
年間のアクティブユーザー数 同じような形になっているので公表されている値は正しいようだ 39 https://codeforces.com/blog/entry/56831
Doc2Vec 40
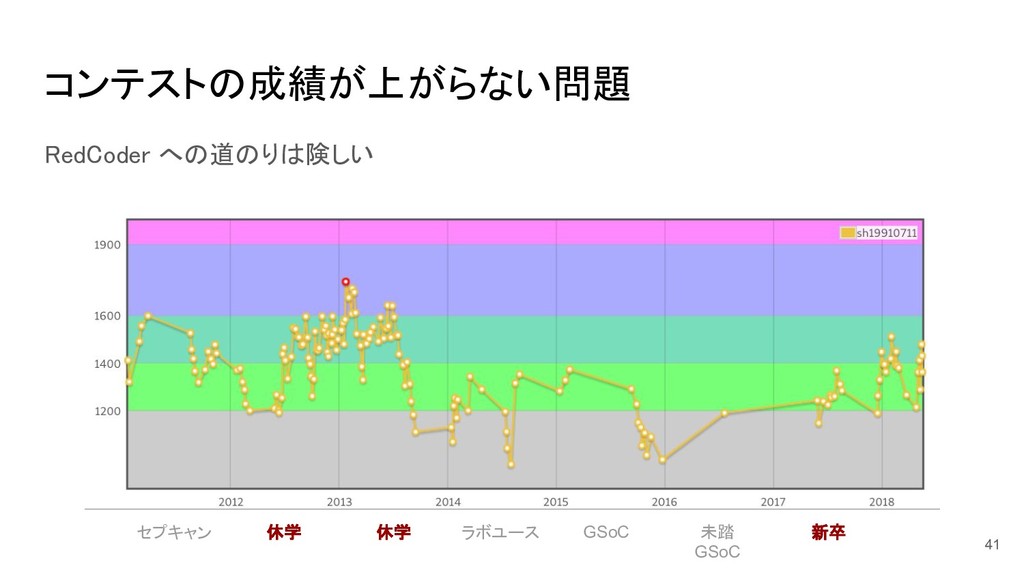
コンテストの成績が上がらない問題 41 RedCoder への道のりは険しい 休学 新卒 休学 ラボユース GSoC 未踏
GSoC セプキャン
問題 = 理想 - 現実 理想 = RedCoder / 現実
= 万年 GreenCoder なぜか • 練習しない • 解けなかった問題をそのままにしている 42
なぜ練習しないのか • 難しい問題 => 眠くなる • 簡単な問題 => 解く気がしない •
問題を探すのだるい いまの実力でストレスなく解ける手頃な難易度の問題を機械学習で良い感じに推薦して ほしい 43
44 Doc2Vec Document Embedding with Paragraph Vectors https://arxiv.org/abs/1507.07998 文章と単語をベクトルに落とし込んで 「レディー・ガガ」
- 「アメリカ人」 + 「日本人」 = 「浜崎あゆみ」 みたいな計算をできるようにする ※ 上記結果については賛否ありそう
Doc2Vec => Problem2Vec 例えば • 文書 = 問題 • 単語
= 正解したユーザー として Doc2Vec を適用すれば、その問題を誰が正解しているかという情報を元にして似 ている問題を良い感じに分類できないだろうか 45
gensim 46 gensim で Doc2Vec してみる • Python で書かれたライブラリ •
トピックモデルなどの機能を持つ(知らんけど) • Word2Vec や Doc2Vec の機能もある "gensim: Topic modelling for humans" https://radimrehurek.com/gensim/
gensim のインストール pip でインストールできる。csv を読むために pandas も入れておく ※ pandas; データを扱うためのライブラリ
47
Athena: 問題ごとに正解者の一覧をとる 48 ↑array_agg 関数を使うとカラムの値を group by で配列化できる 出力例
gensim: トレーニング実行 問題ごとに正解した ユーザーリストを単語 とみなして訓練しモデ ルを保存する 49 正解したユーザーリストがスペース区切りになっているので分割して gensim の
LabeledSentence というモデルに変換している
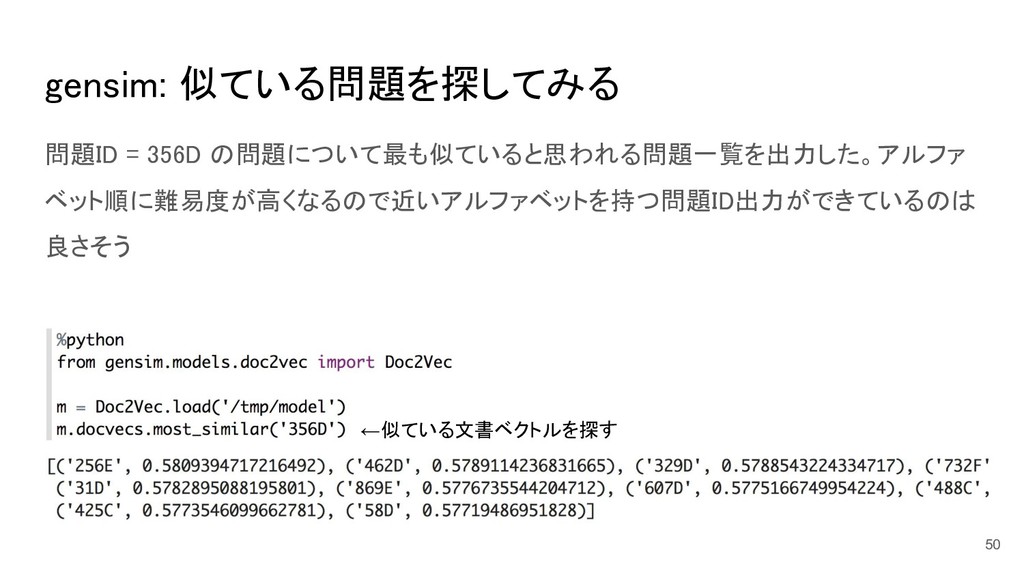
gensim: 似ている問題を探してみる 問題ID = 356D の問題について最も似ていると思われる問題一覧を出力した。アルファ ベット順に難易度が高くなるので近いアルファベットを持つ問題ID出力ができているのは 良さそう 50 ←似ている文書ベクトルを探す
gensim: 世界ランクトップと似ているユーザー 単語ベクトル(ユーザー)について も類似のベクトルを取得できる Problem2Vec による世界ランク トップの tourist に類似すると 思われるユーザーリスト
日本人を入れると日本人が出て来やすい傾向があ るようだった(コンテストに参加できる時間帯が似て いるからだろうか) 51 ↑ 7月2日時点の世界ランキング
3. まとめ # YWT 52
Y: やった 53 • サーバーレスな分析基盤をつくってみた • 集めたデータを分析可能な状態にした • gensim を使って
Doc2Vec してみた
W: わかった • Athena: タイムスタンプは文字列じゃなくて数値にしておく ◦ データスキャン量が全然違う • Doc2Vec ◦
難しめの問題だと解いてる人によって特徴が出るようだった ◦ 簡単な問題は解いてる人が多いので類似度が高くなりがちだった 54
T: 次やること • Firehose の動的生成 • Doc2Vec を使った練習システムの構築 55
Thank you ;-) 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}