Twitter, feel free to tweet about this session (use hashtag #MVMUG) • I encourage you to take photos or videos of today’s session and share them online • This presentation will be made available online after the event
measure of how much data loss the organisation is willing to sustain • RTO = Recovery Time Objective • RTO is a measure of how long of a wait the organisation is willing to tolerate before recovery is complete RPO versus RTO
before a disaster occurs • How often do you know before a disaster is going to occur? • DR = Disaster recovery • Seeks to recover apps/data after a disaster occurs • Think of DA as vMotion and DR as vSphere HA DR versus DA
Stretched Layer 2 connectivity between sites • 622 Mbps bandwidth (minimum) between sites • Less than 5 ms latency between sites (10 ms with vSphere 5 Enterprise Plus/Metro vMotion) • A single vCenter Server instance Requirements for vMSC
• Layer 3 connectivity • No minimum inter-site bandwidth requirements (driven by SLA/RPO/RTO) • No maximum latency between sites (driven by SLA/RPO/ RTO) • At least two vCenter Server instances Requirements for SRM
mobility No ability to test workload mobility No IP address changes needed Greater networking complexity (OTV, LISP, VXLAN) and cost Zero/near-zero RPO; RTO of only a few minutes (typically) Operational overhead managing DRS host affinity groups Single vCenter Server instance required Only a single vCenter Server instance supported
needed Typically higher RPO/RTO than vMSC No need for stretched Layer 2 connectivity (but is supported) Operational overhead managing protection groups/plans The ability to simulate and test the failover process Workload mobility is always disruptive never non-disruptive Supports multiple vCenter Server instances Requires at least two vCenter Server instances
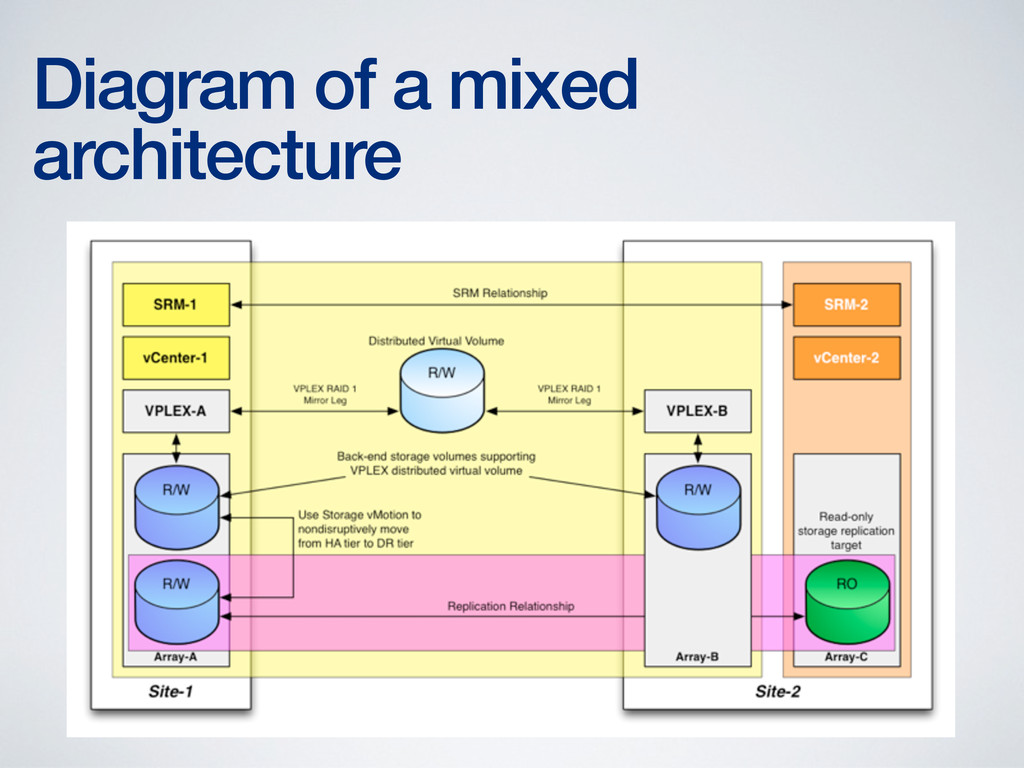
comparing SRM and vMSC • Any of my stretched cluster presentations (all available on my site, blog.scottlowe.org) discuss pros/cons and design considerations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}