curl -sL -w "%{http_code}¥n" –X POST ¥ ‘http://db:8086/db/test1/series?u=smly&p=yeah& time_precision=s’ -d ‘[ { “name”: “events”, “columns”: [“time”, “uid”, “action”], “points”: [ [1385390220, “5485”, “LEAVE”], ] }, }]’ 200 Need to specify the precision of the value Seconds (s) , milliseconds (m) or microseconds (u)
from InfluxDB import InfluxDBClient > c = InfluxDBClient( ‘root’, ‘root’, ‘smly’, ‘secret’, ‘testdb’) # Get points in last hour > c.query(“”” SELECT * FROM markov “””)
last hour から選択する) SELECT * FROM events, errors; SELECT * FROM /stats¥..*/i; SELECT * FROM events WHERE state == ‘NY’ SELECT * FROM log_lines WHERE line =~ /error/i; SELECT * FROM response_times WHERE value > 500; SELECT * FROM nagios_checks WHERE status != 0;
ID を管理するための key/value pair Key: “[PREFIX]~[DB]~[SERIES]~[COLUMN]”, Value: ColumnID Point / Data を管理するための key/value pair Key: [TIMESTAMP][SEQ_NUM][ColumnID], Value: Data
In the multithreaded case (12 workers), CSL tested 10x faster than a RWSpinLocked std::set for an averaged sized list (1K - 1M nodes). https://github.com/facebook/folly/blob/master/folly/ConcurrentSkipList.h folly 曰く、”マルチスレッドの場合 10 倍高速”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
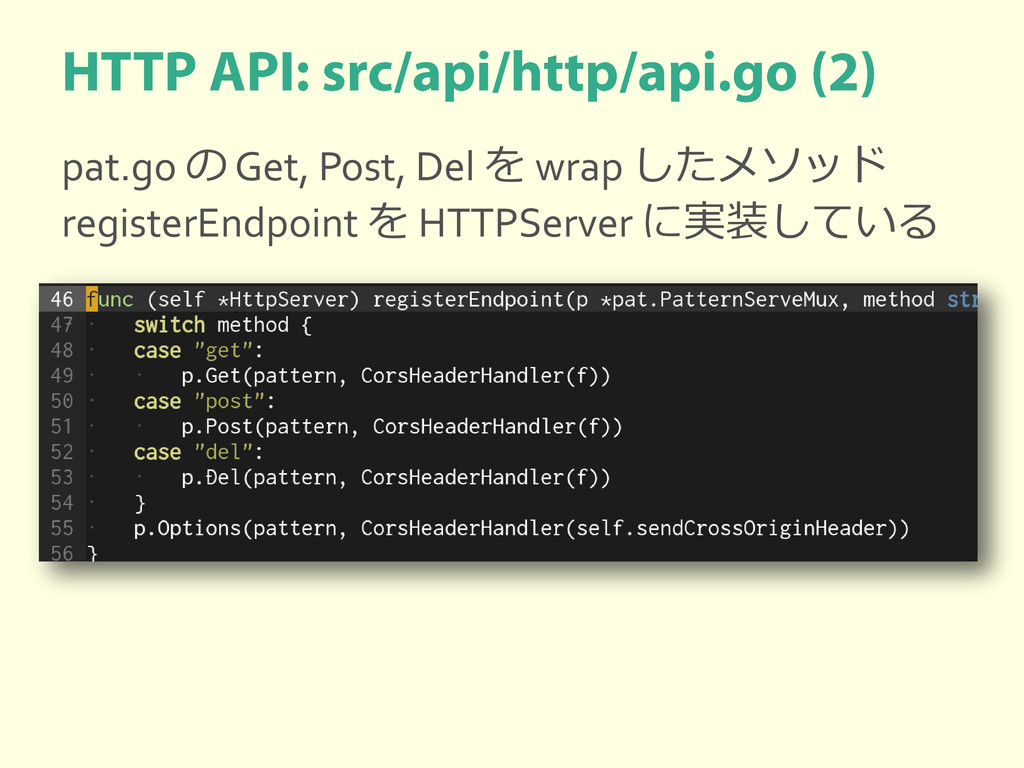{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![の記録例 [{ “name”: “events”, “columns”: [“uid”, “action”, “item”, “price”], “points”:](https://files.speakerdeck.com/presentations/a548dd803b9701317dc972a2d852fae1/slide_33.jpg){kind=link}
![の記録例 [{ “name”: “events”, “columns”: [“uid”, “action”, “item”, “price”], “points”:](https://files.speakerdeck.com/presentations/a548dd803b9701317dc972a2d852fae1/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}