What does it take to use serverless functions in production, with safety and at scale? In this presentation we cover a few specific approaches, patterns and best practices that you can use with any FaaS framework. These practices are geared towards improving quality, reducing risk, optimizing costs, and generally moving you closer towards production-readiness with serverless systems.
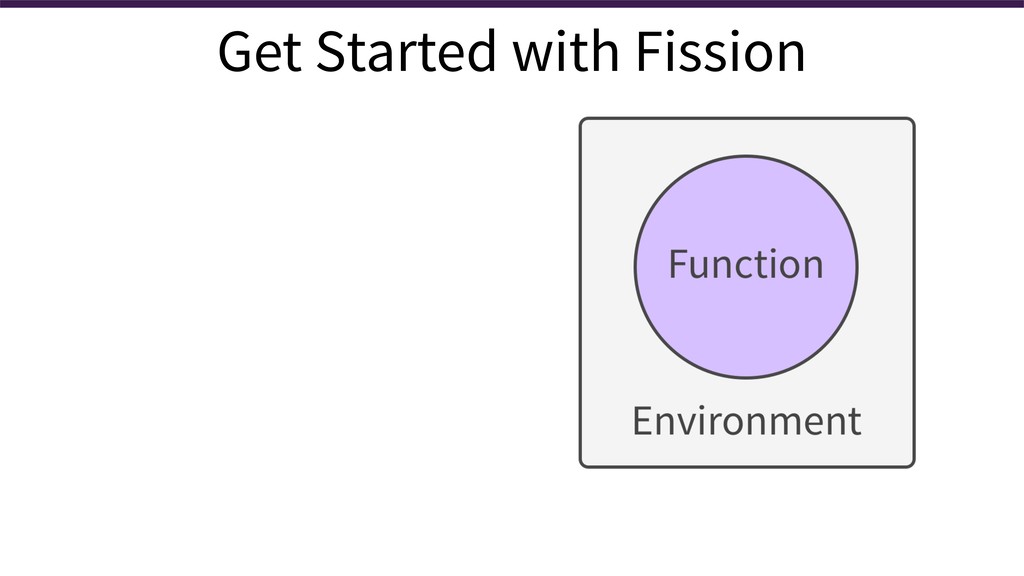
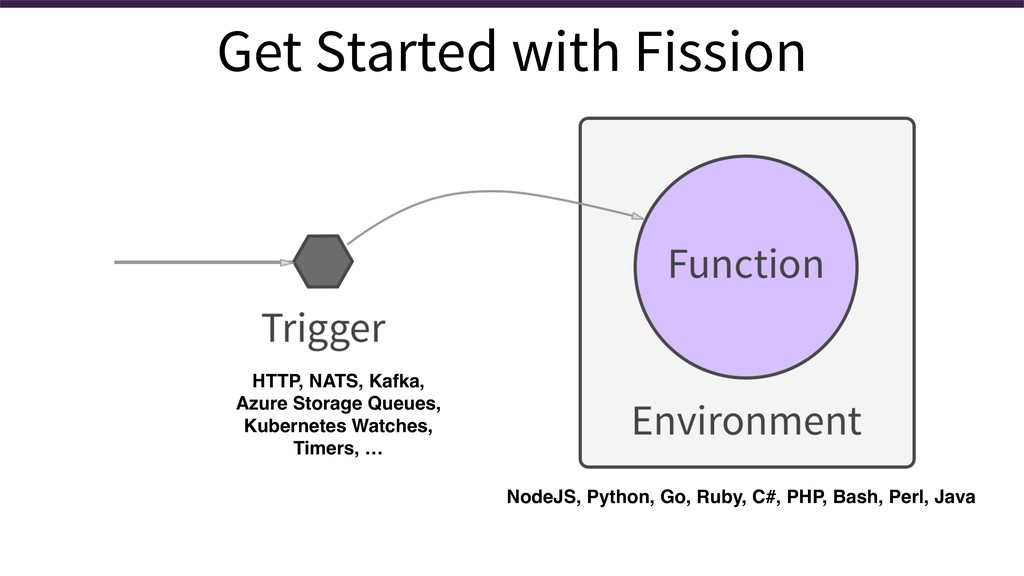
We also cover Fission, an open source FaaS framework for Kubernetes. We show how follow these practices easily with Fission, so you can use them on any infrastructure that runs Kubernetes (whether it's your datacenter or the public cloud).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}