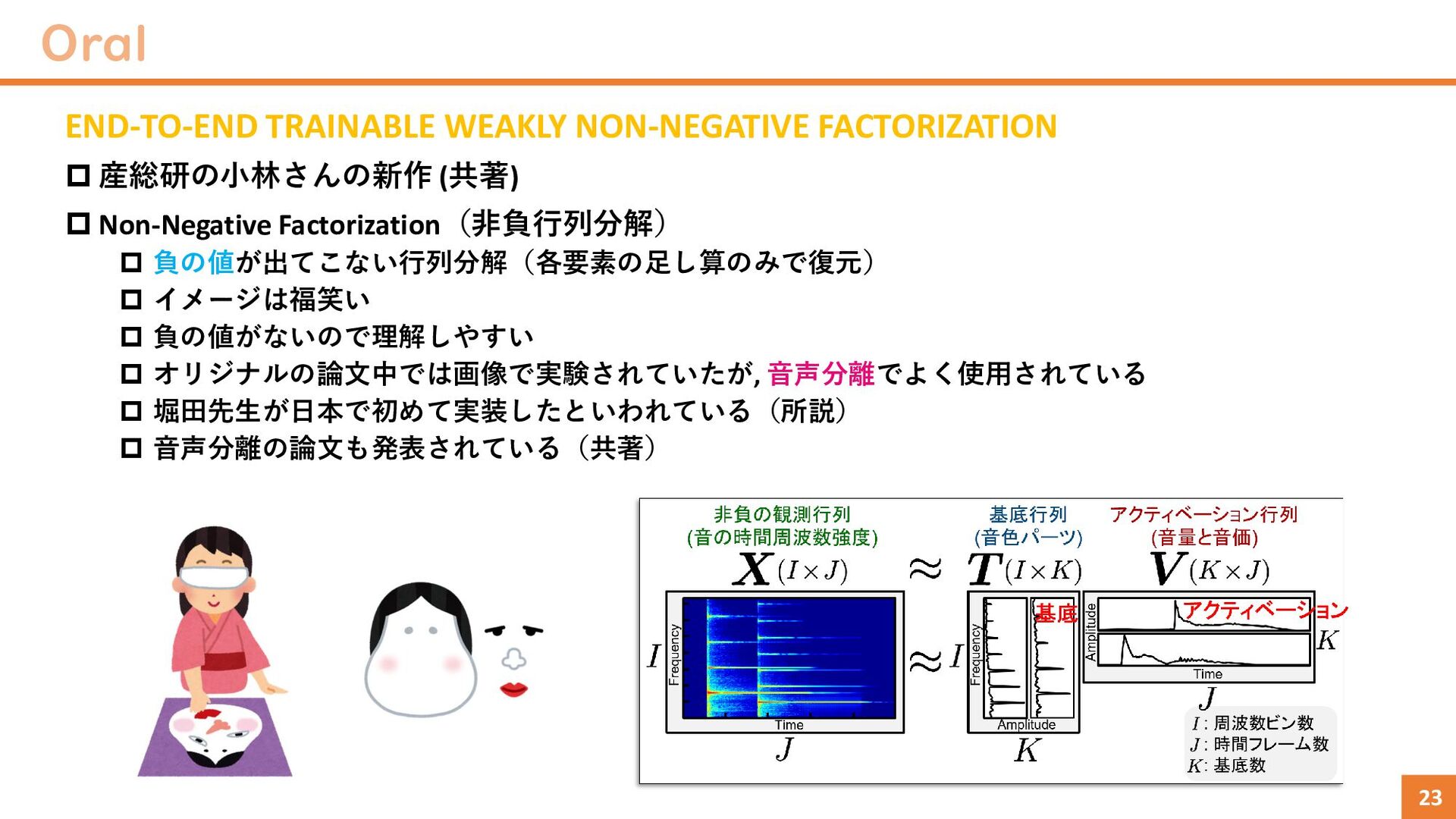
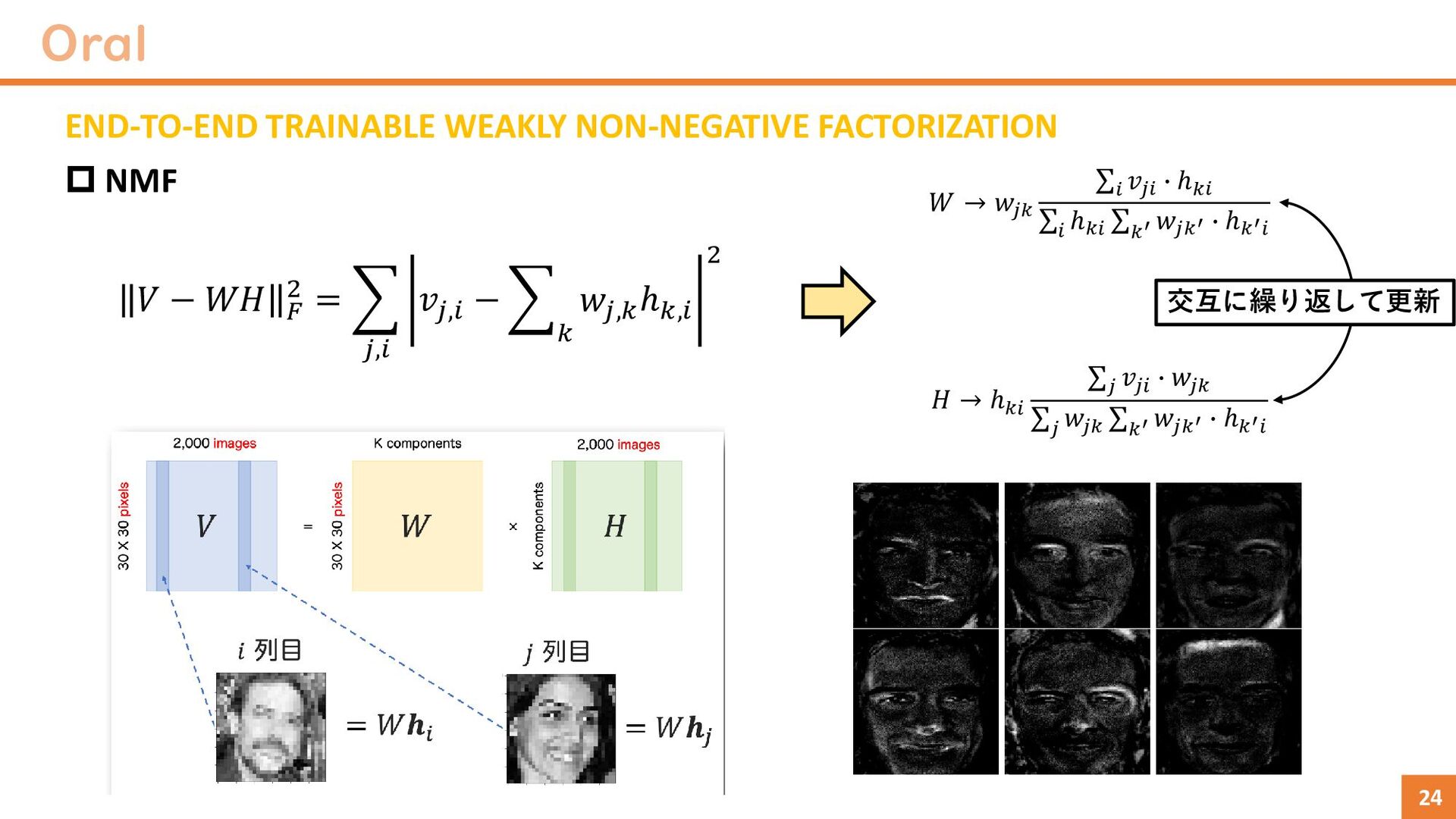
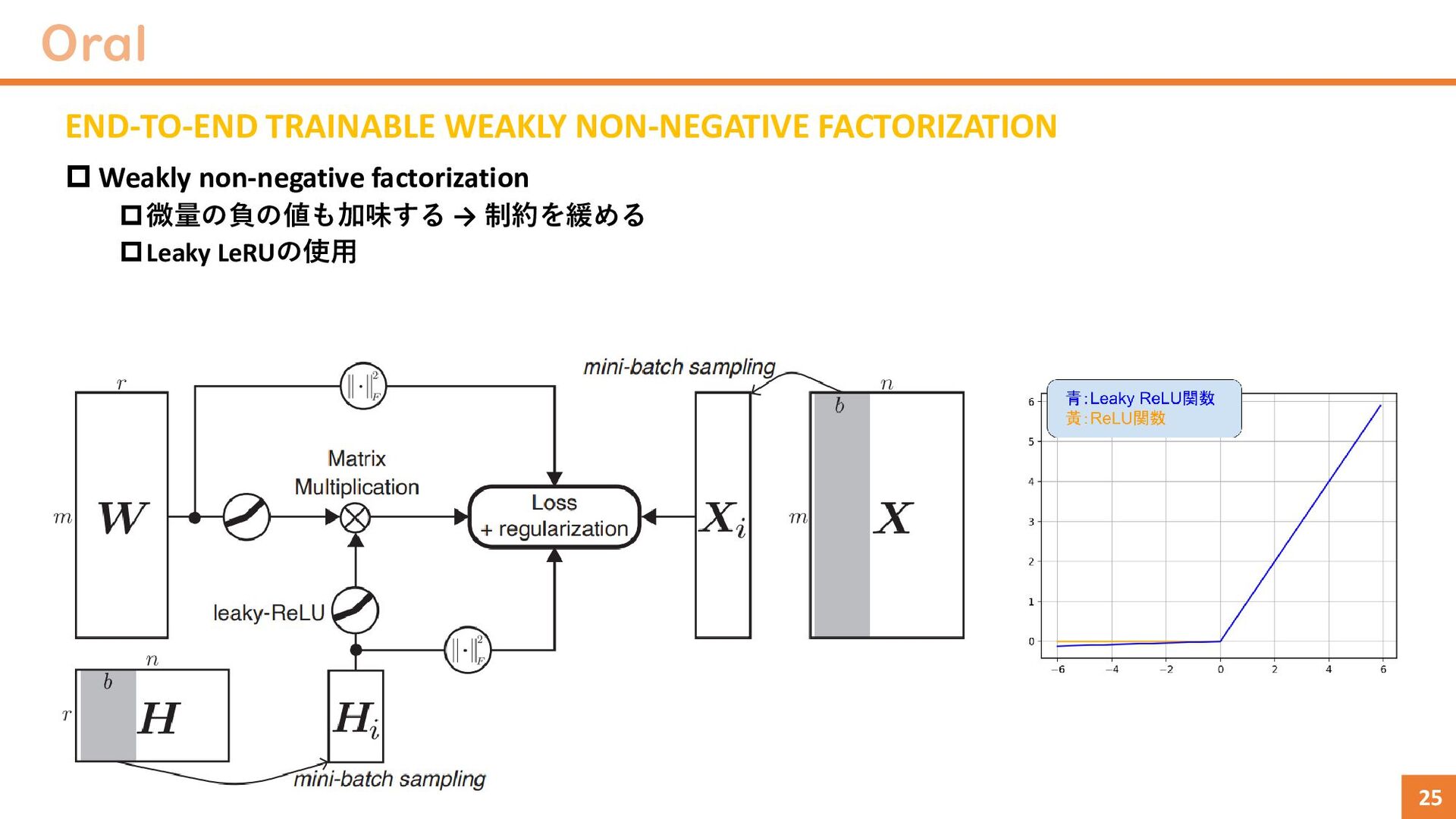
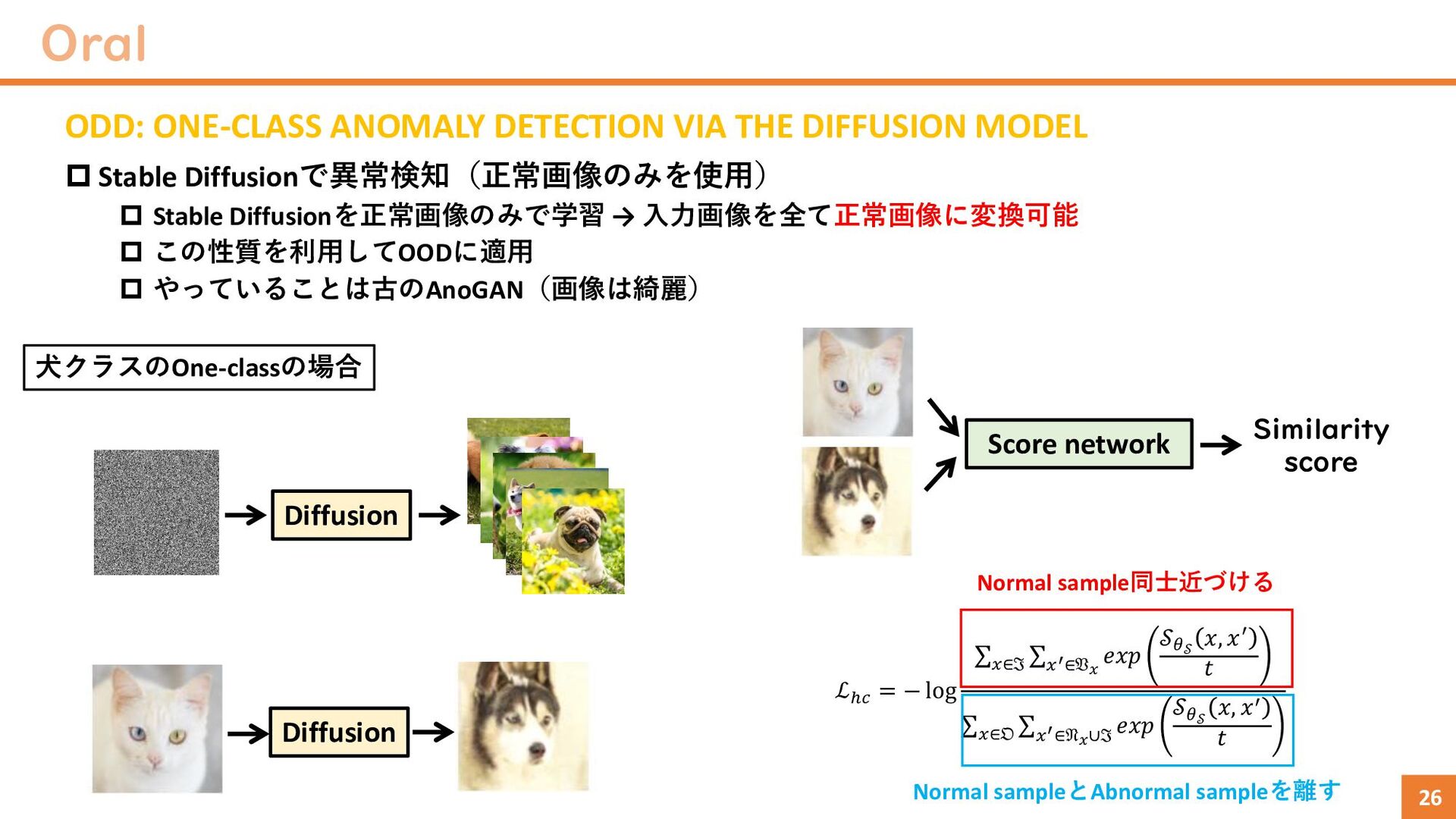
Stable Diffusionで異常検知(正常画像のみを使用) Stable Diffusionを正常画像のみで学習 → 入力画像を全て正常画像に変換可能 この性質を利用してOODに適用 やっていることは古のAnoGAN(画像は綺麗) Diffusion Diffusion Score network Similarity score ℒℎ𝑐 = − log σ𝑥∈ℑ σ 𝑥′∈𝔙𝑥 𝑒𝑥𝑝 𝒮𝜃𝒮 𝑥, 𝑥′ 𝑡 σ 𝑥∈𝔒 σ 𝑥′∈𝔑𝑥∪ℑ 𝑒𝑥𝑝 𝒮𝜃𝒮 𝑥, 𝑥′ 𝑡 犬クラスのOne-classの場合 Normal sample同士近づける Normal sampleとAbnormal sampleを離す
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}