先行研究が少ない 現状Visual promptのみでは, LLMのような柔軟なZero-shot leanringには程遠い CLIPが強すぎる (データ数?言語の学習が強い?) CVでは出力形式がタスクによって全く異なるので, 最後を学習せざるを得ない... (Linear Classifier以外にはないのか...??) 将来的にはAnomaly detection, Segmentation, Detectionでもできそうな気がする (Anomaly detectionなら異常画像, Segmentationならラベル画像, DetectionならBoxをPromptとして)
{kind=link}
{kind=link}
{kind=link}
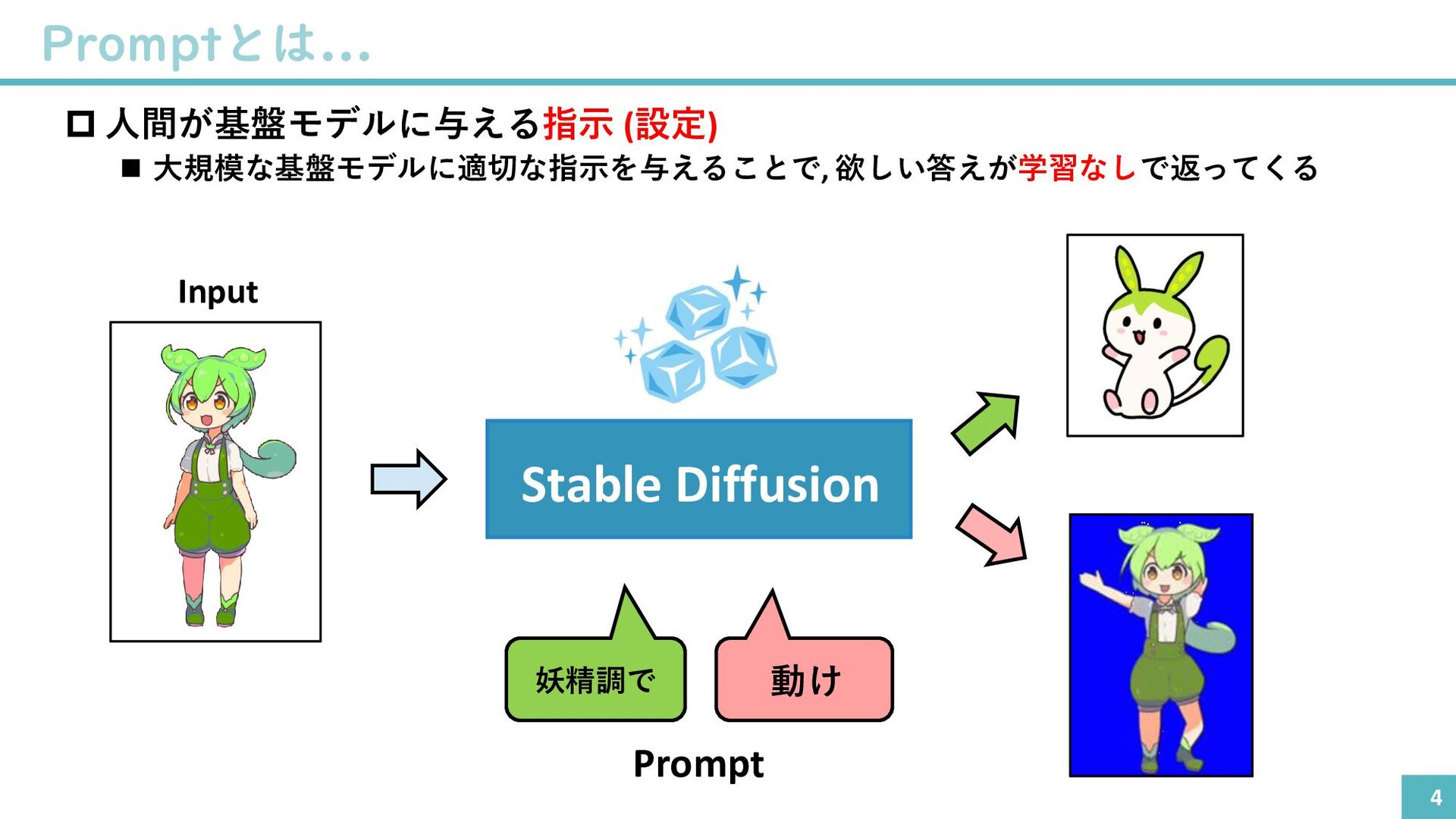{kind=link}
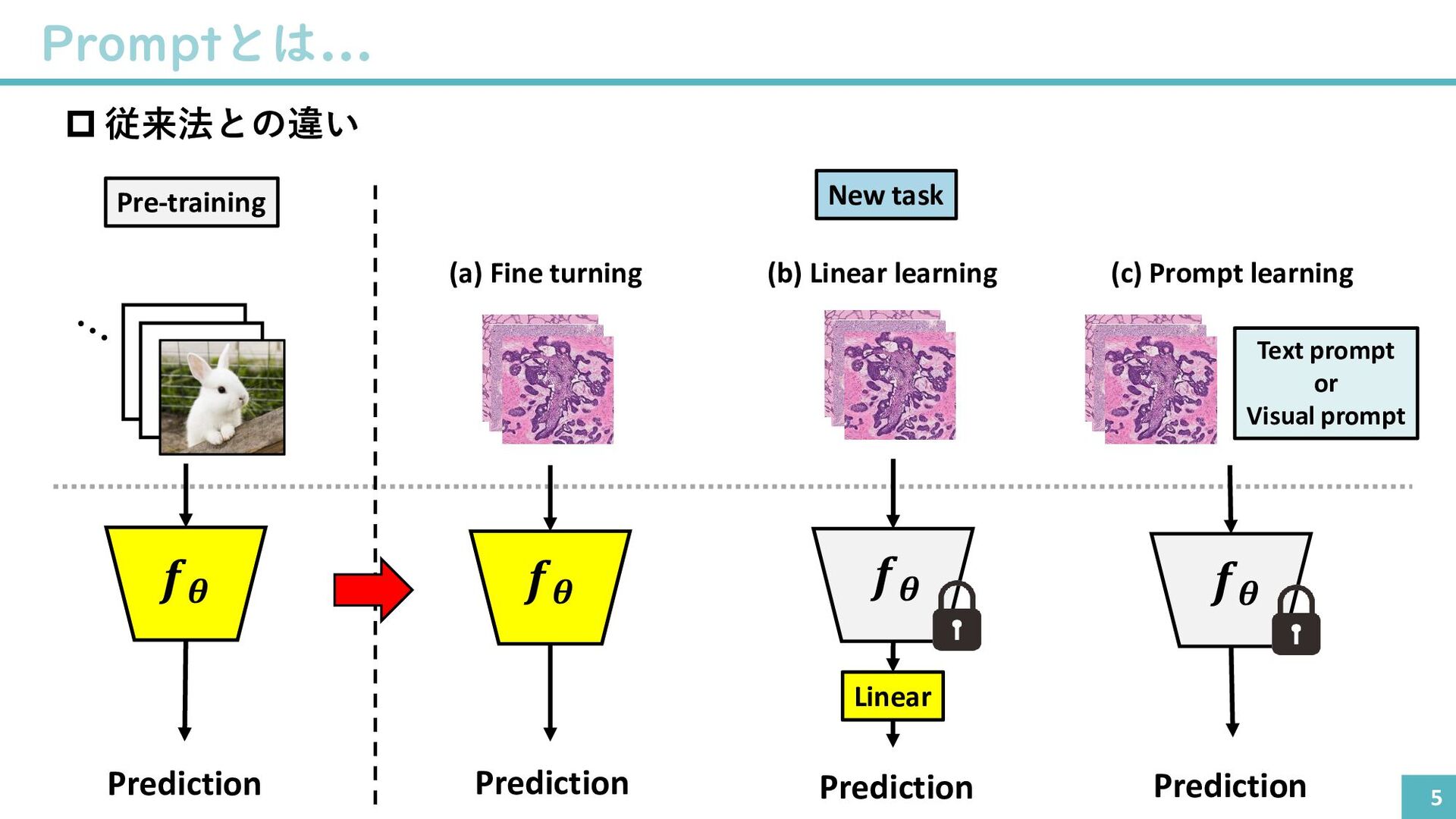{kind=link}
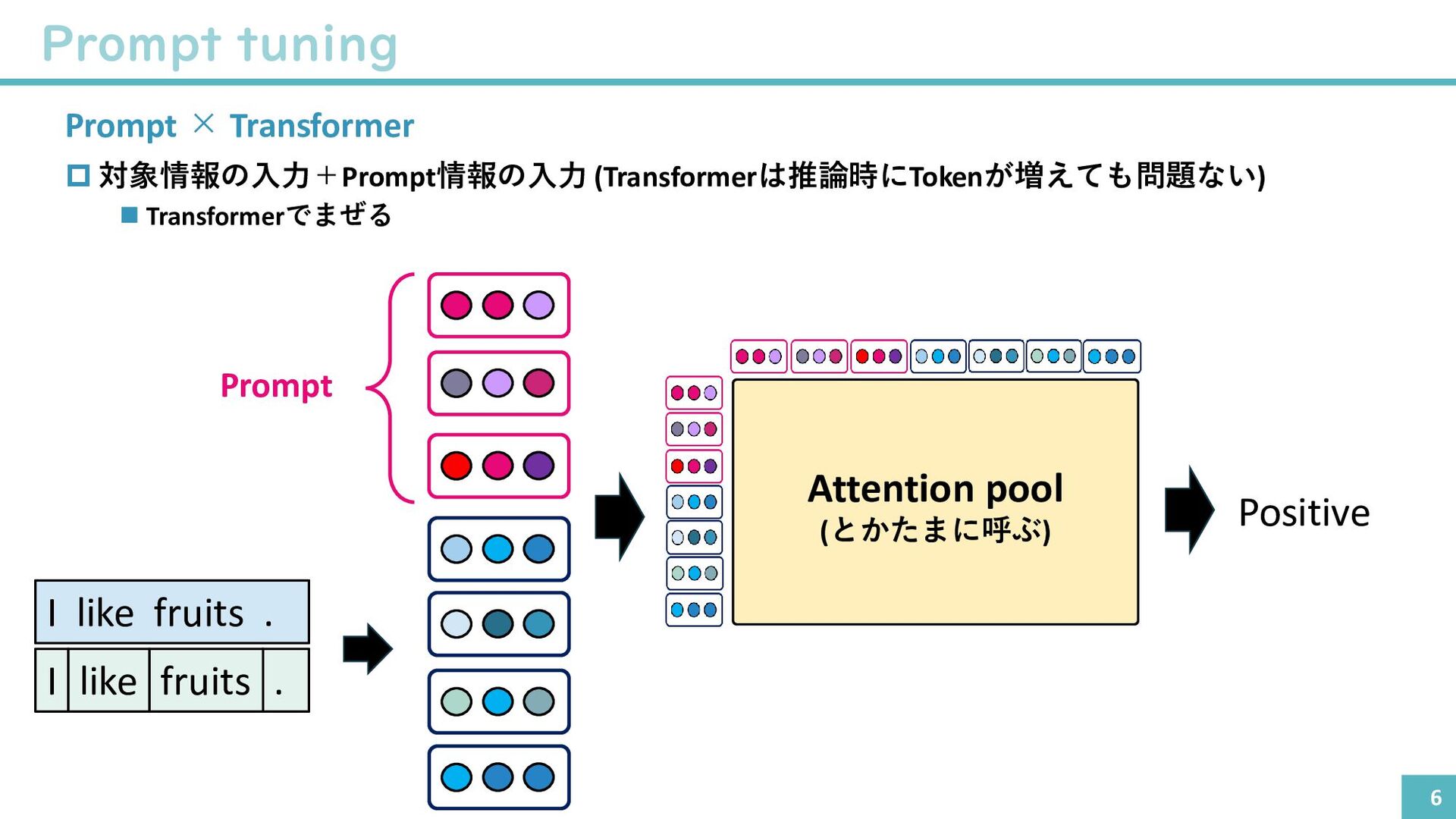{kind=link}
{kind=link}
{kind=link}
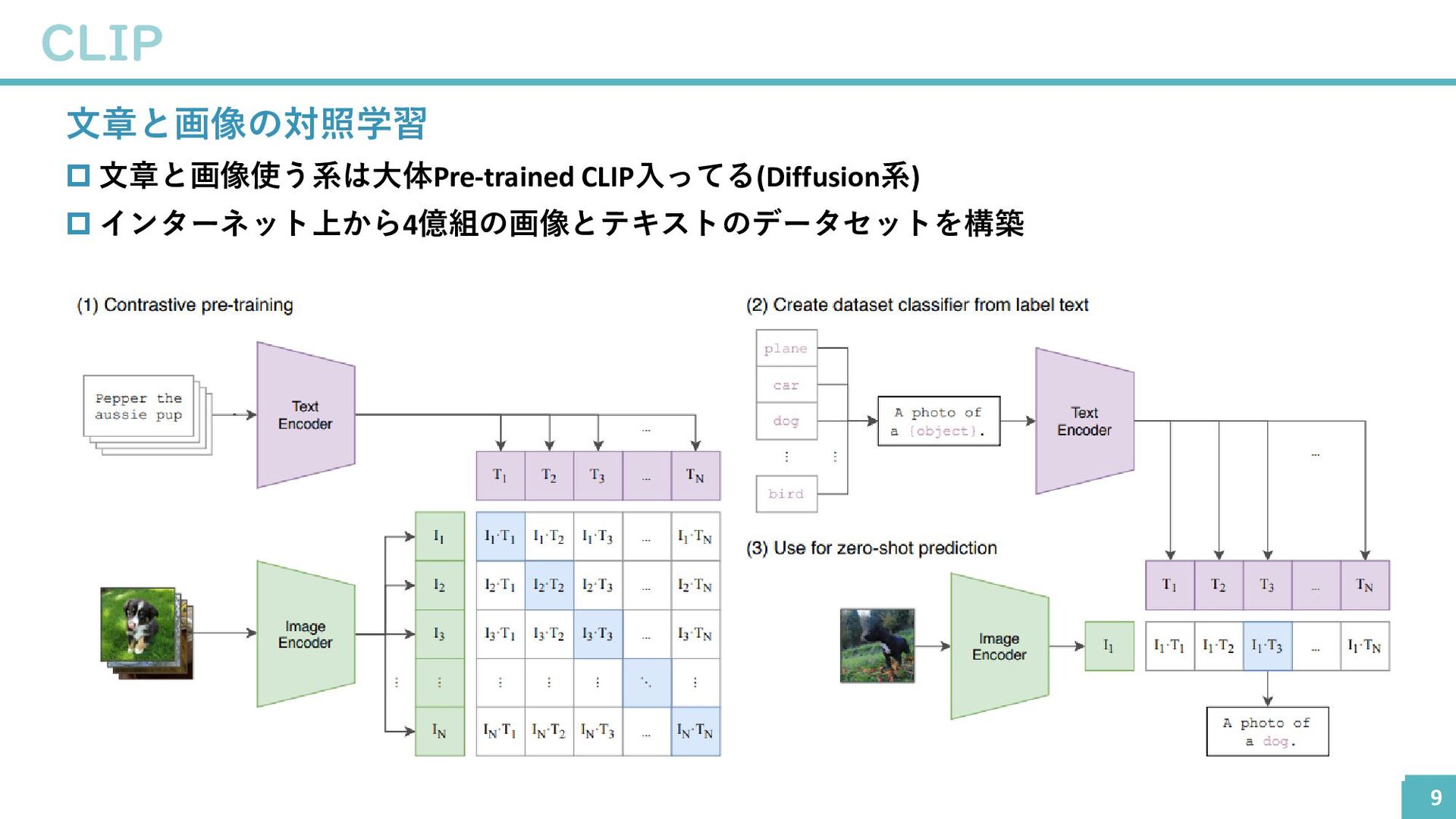{kind=link}
{kind=link}
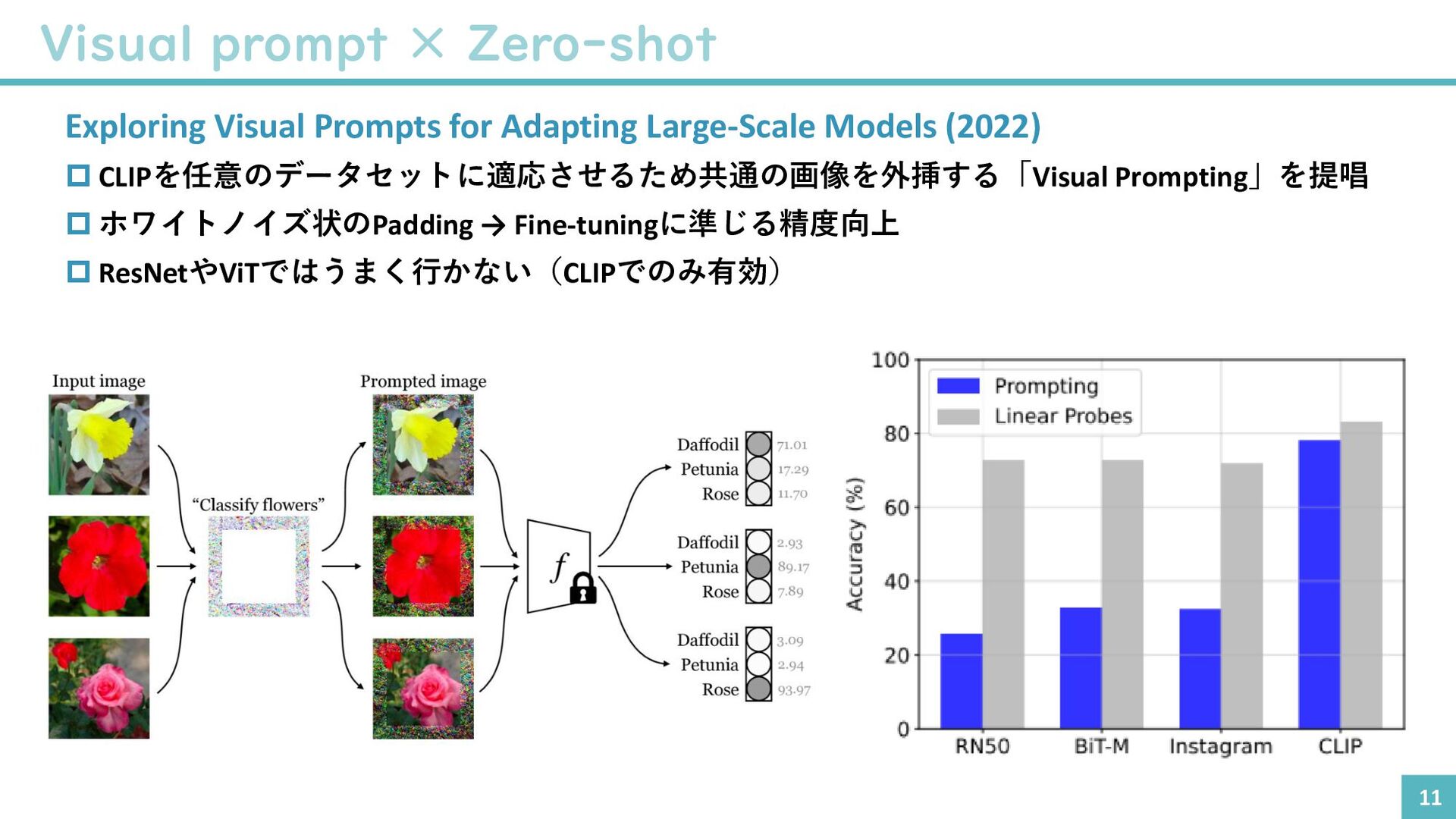{kind=link}
{kind=link}
{kind=link}
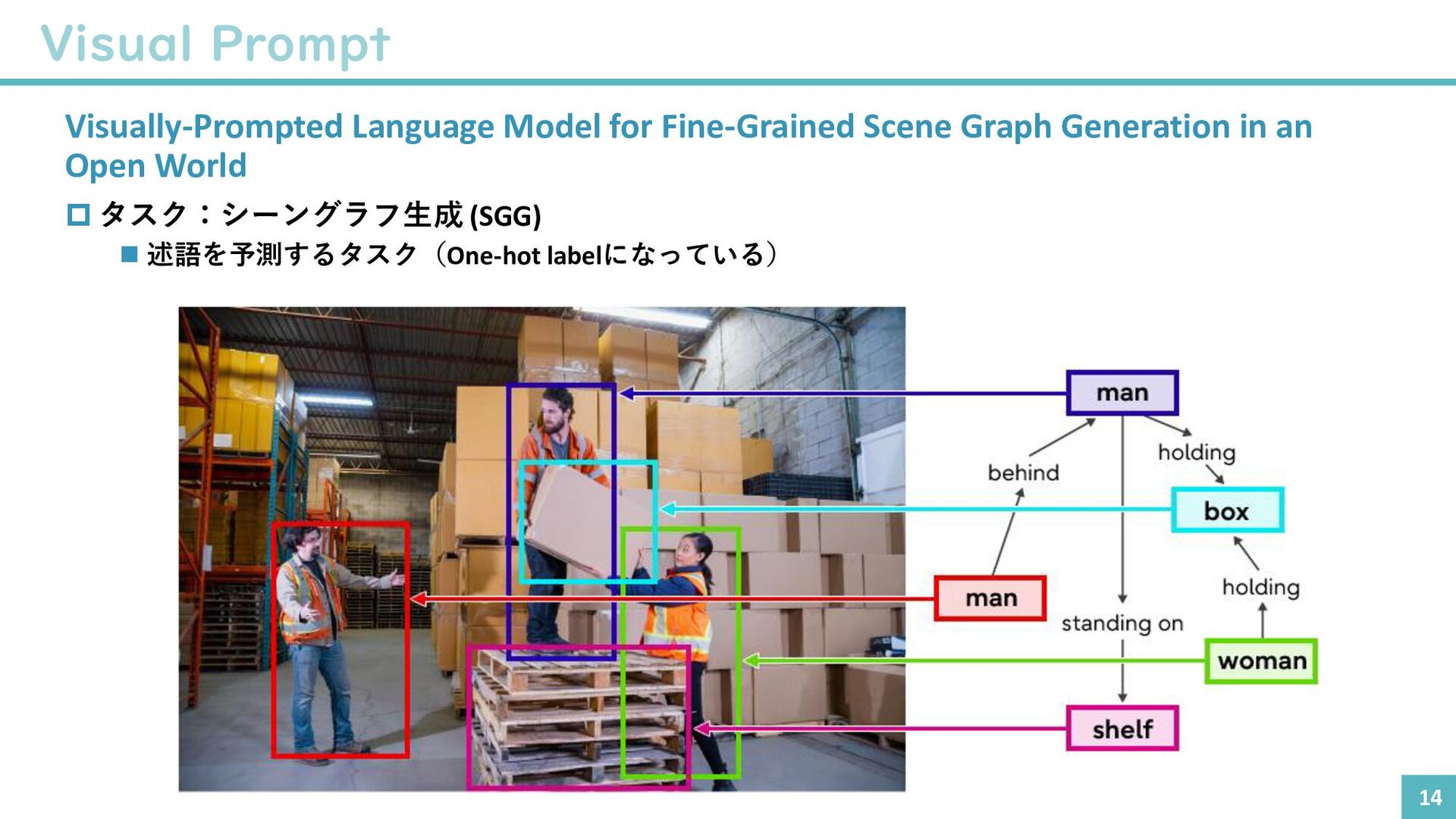{kind=link}
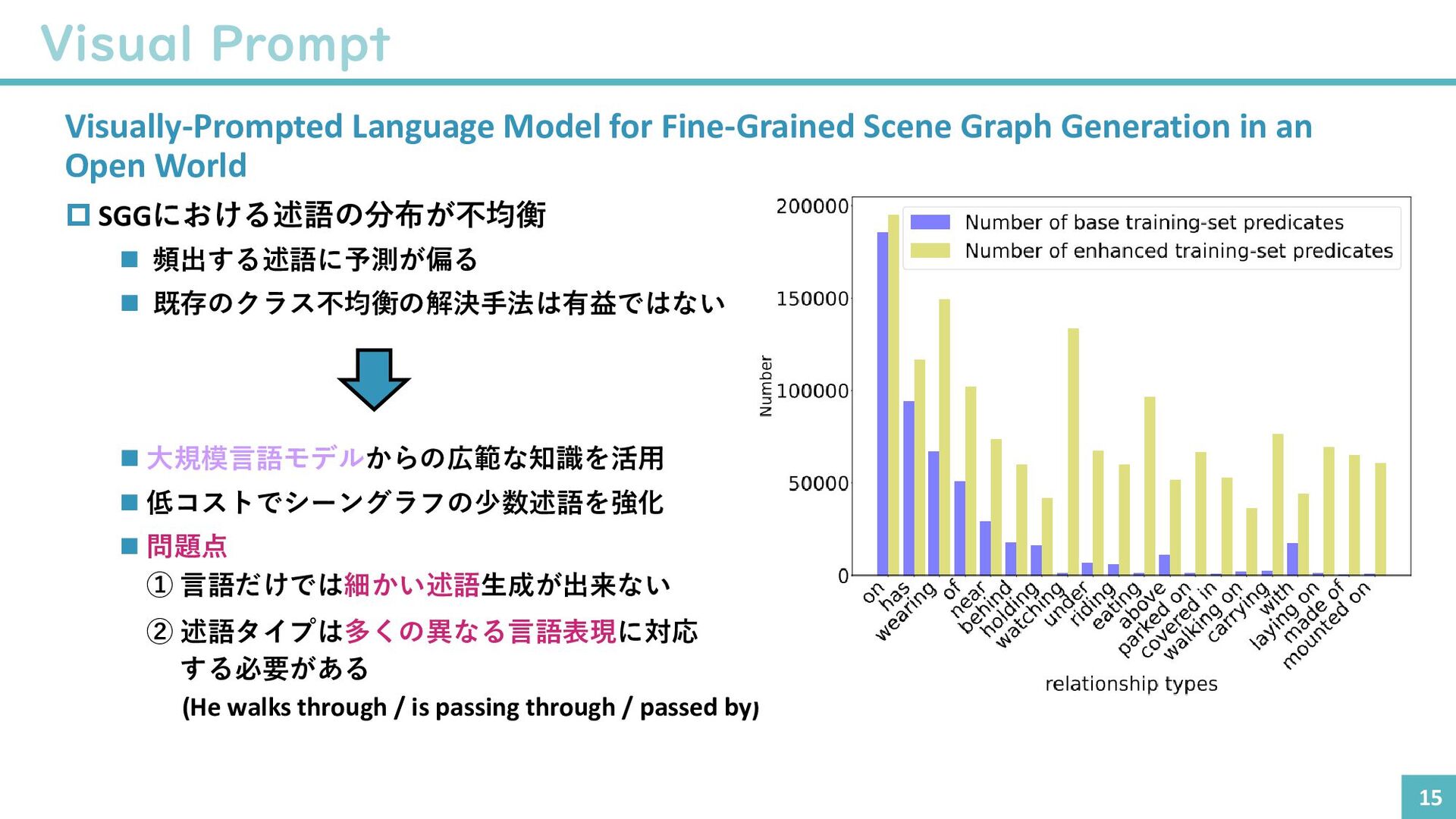{kind=link}
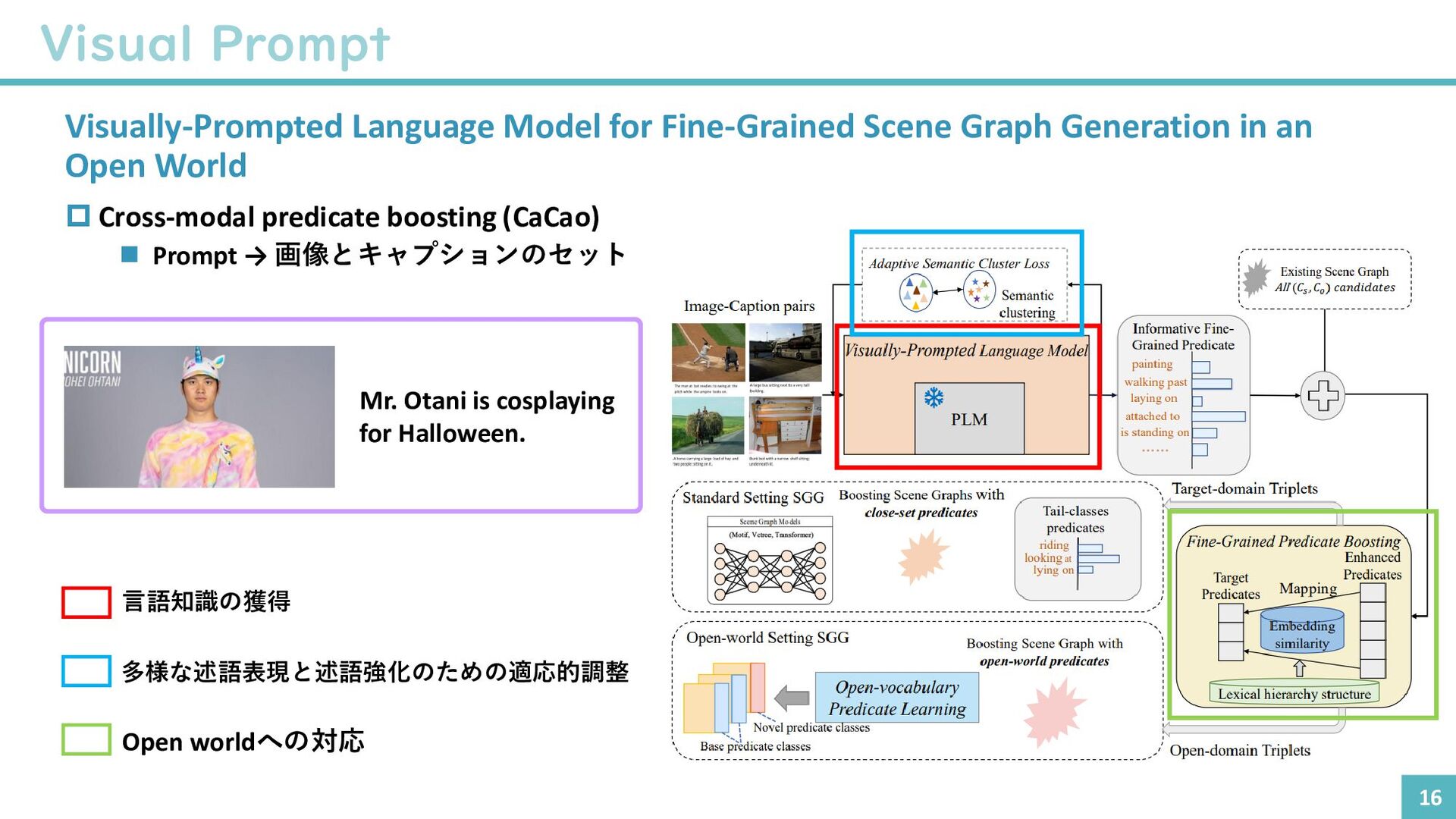{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}