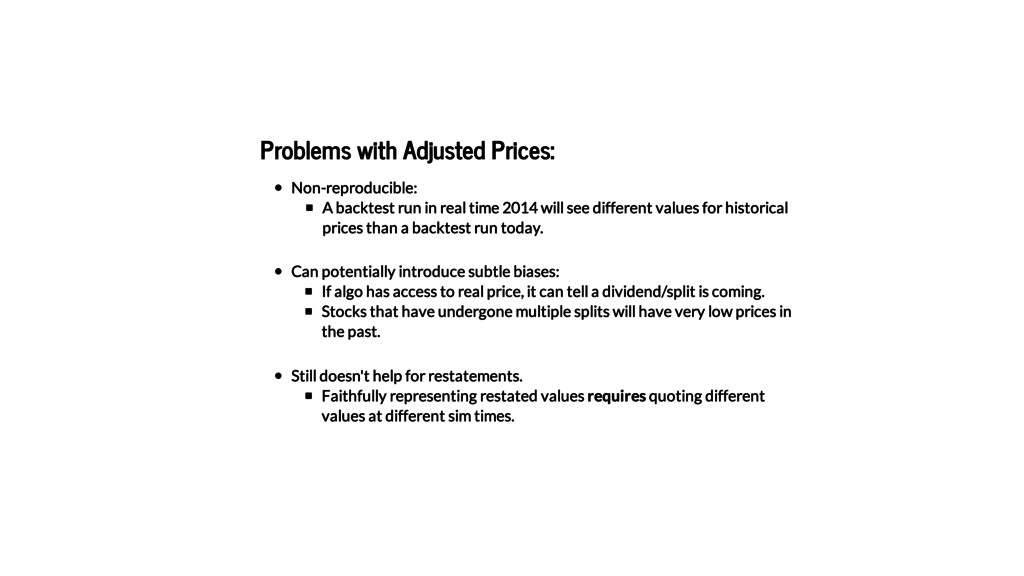
This talk details the challenges addressed during the development of Zipline's new Pipeline API, which provides a high-level expression language allowing users to describe computations on rolling windows of continuously-adjusted financial data. We discuss the notion of "perspectival" time-series data, arguing that this concept provides a useful framework for formally reasoning about financial data in the face of domain oddities like stock splits, dividends, and restatements.
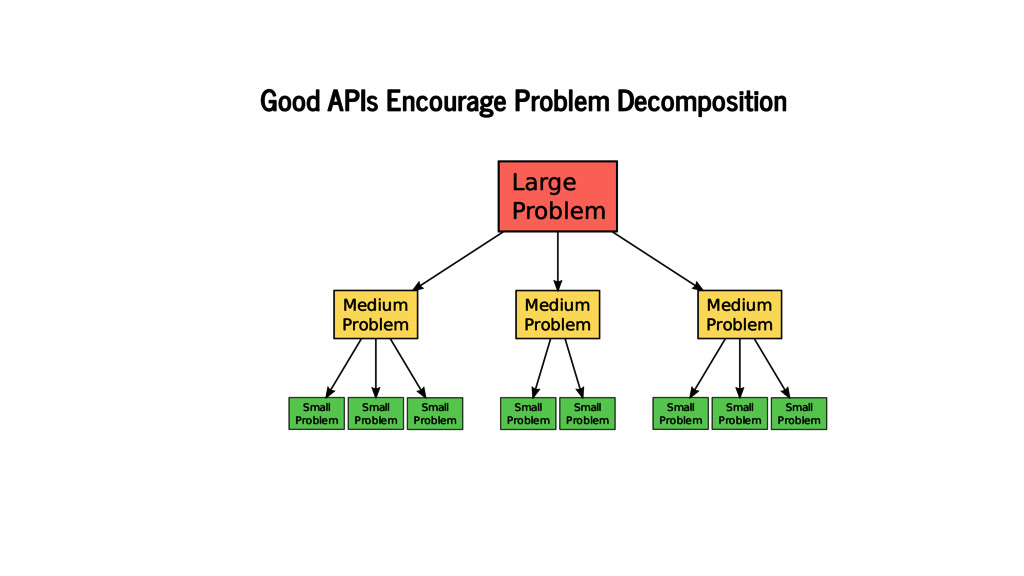
We also consider the architectural and performance benefits of developing an API focused on symbolic computation, drawing comparisons to several recent developments in the Python numerical ecosystem.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In [3]: Out[3]: from zipline.assets import AssetFinder finder = AssetFinder("sqlite:///data/assets.db")](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_28.jpg){kind=link}
![In [4]: daily_count = lifetimes.sum(axis=1) daily_count.plot(title="Companies in Existence by Day");](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_29.jpg){kind=link}
{kind=link}
![In [5]: AAPL_prices = pd.read_csv( 'data_public/AAPL-split.csv', parse_dates=['Date'], index_col='Date', ) def](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_31.jpg){kind=link}
![In [6]: plot_prices(AAPL_prices);](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_32.jpg){kind=link}
![In [7]: naive_returns = AAPL_prices.pct_change() naive_returns.plot();](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In [8]: from bcolz import open from humanize import naturalsize](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_48.jpg){kind=link}
![In [9]: !du -h -d0 data/equity_daily_bars.bcolz !du -h -d0 data/adjustments.db](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_49.jpg){kind=link}
![In [9]: !du -h -d0 data/equity_daily_bars.bcolz !du -h -d0 data/adjustments.db](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
![In [10]: import pandas as pd from zipline.utils.tradingcalendar import trading_day](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_53.jpg){kind=link}
![In [11]: Out[11]: # load_adjusted_array() returns a dictionary mapping columns](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_54.jpg){kind=link}
![In [14]: Out[14]: dates_iter = iter(dates[4:]) window = closes.traverse(5) window](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_55.jpg){kind=link}
![In [15]: # This cell is run multiple times to](https://files.speakerdeck.com/presentations/4007ec4b5c0d49bcac6789966a69683c/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}