Scott Sanderson describes the architecture of the Quantopian Research Platform, a Jupyter Notebook deployment serving a community of over 100,000 users, explaining how, using standard extension mechanisms, it provides robust storage and retrieval of hundreds of gigabytes of notebooks, integrates notebooks into an existing web application, and enables sharing notebooks between users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
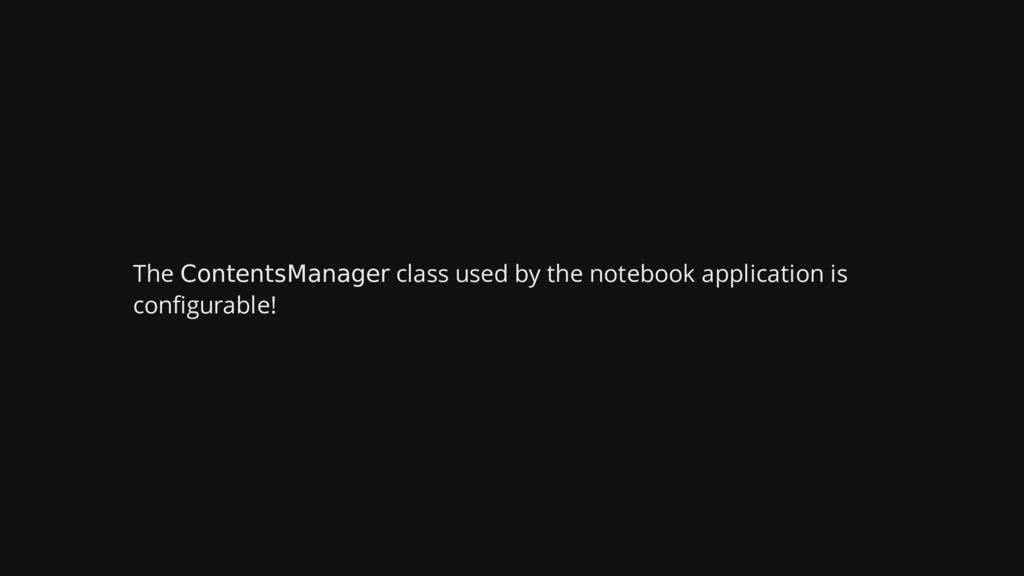{kind=link}
![ContentsManager Interface ContentsManager.get(path[, content, type, ...]) Get a model. ContentsManager.save(model,](https://files.speakerdeck.com/presentations/c19a247a9eb2485eb5796e16a231a02b/slide_21.jpg){kind=link}
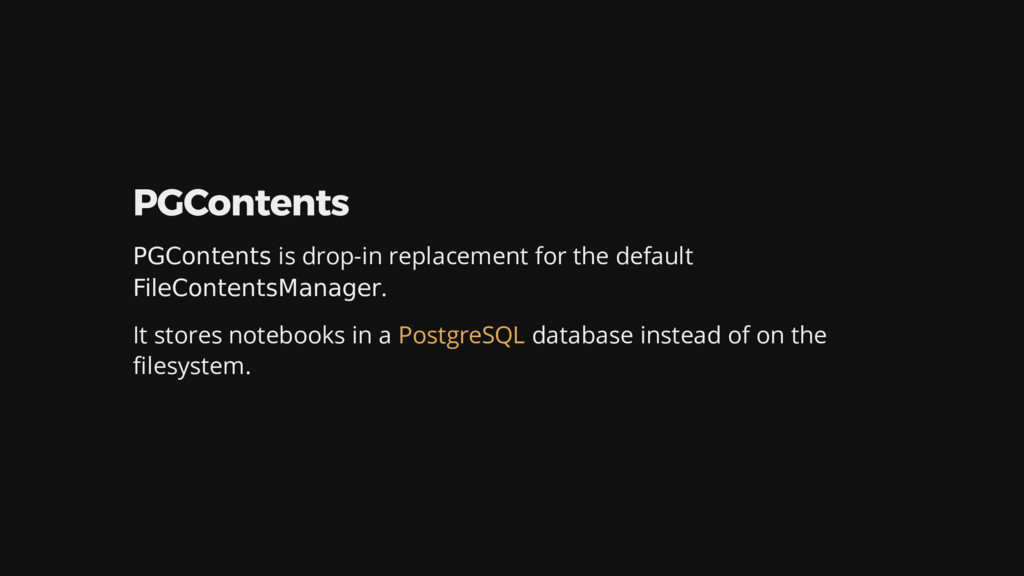{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
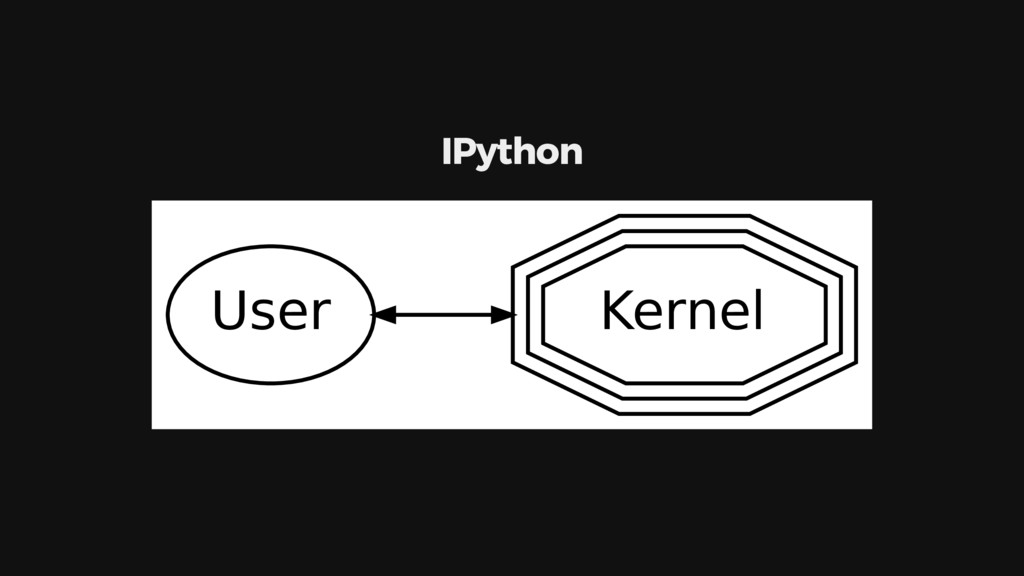{kind=link}
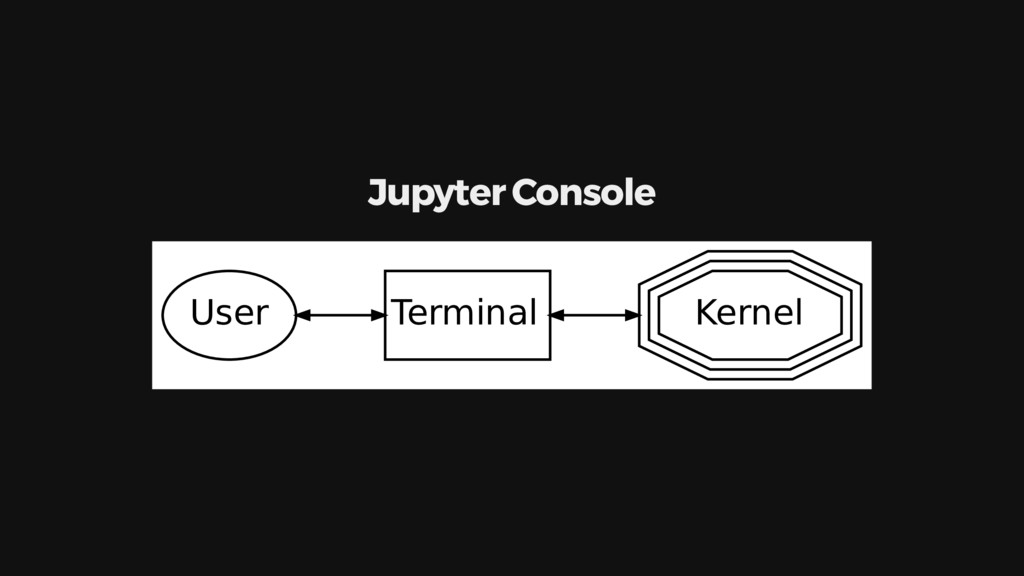{kind=link}
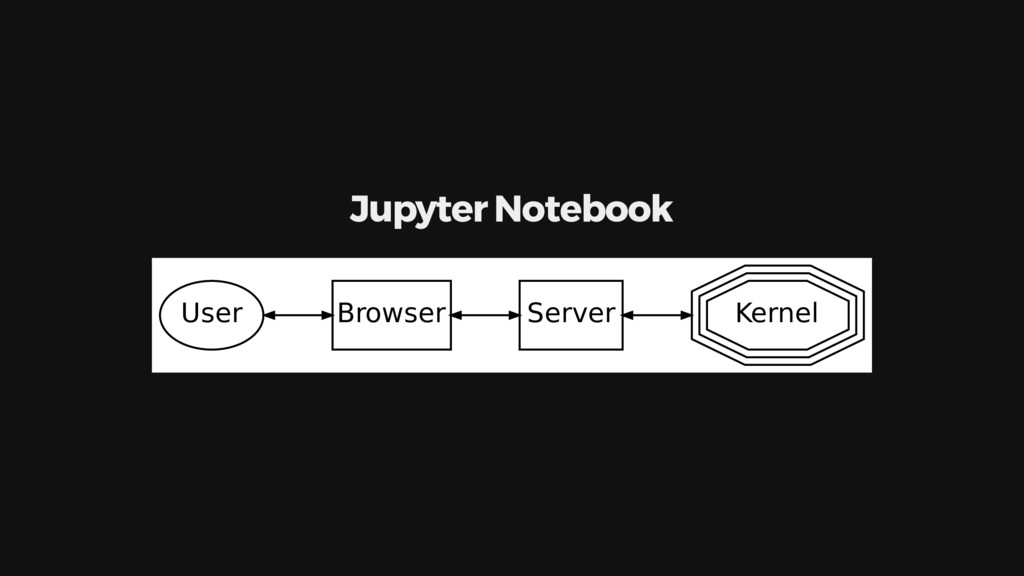{kind=link}
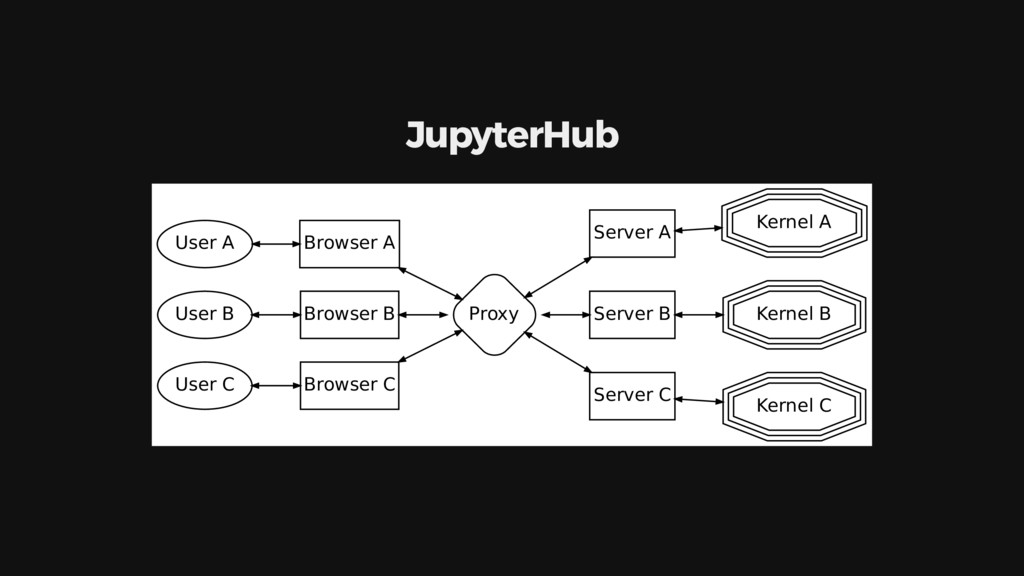{kind=link}
{kind=link}
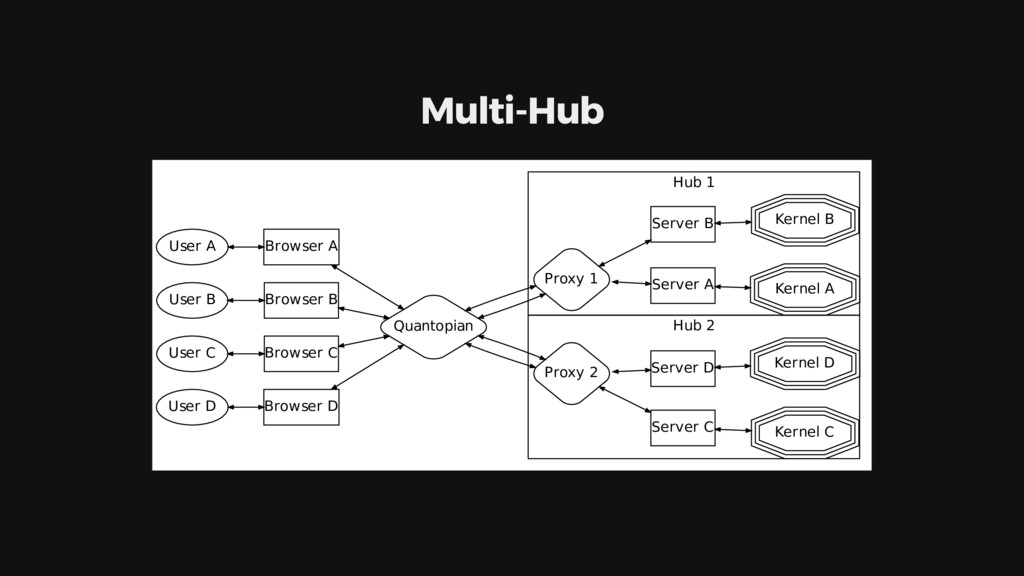{kind=link}
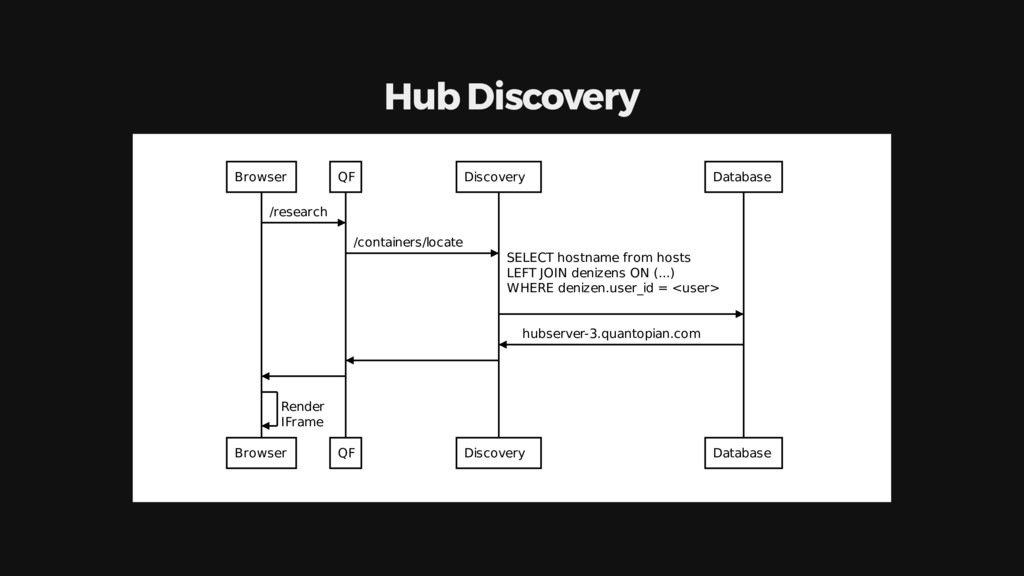{kind=link}
{kind=link}
{kind=link}
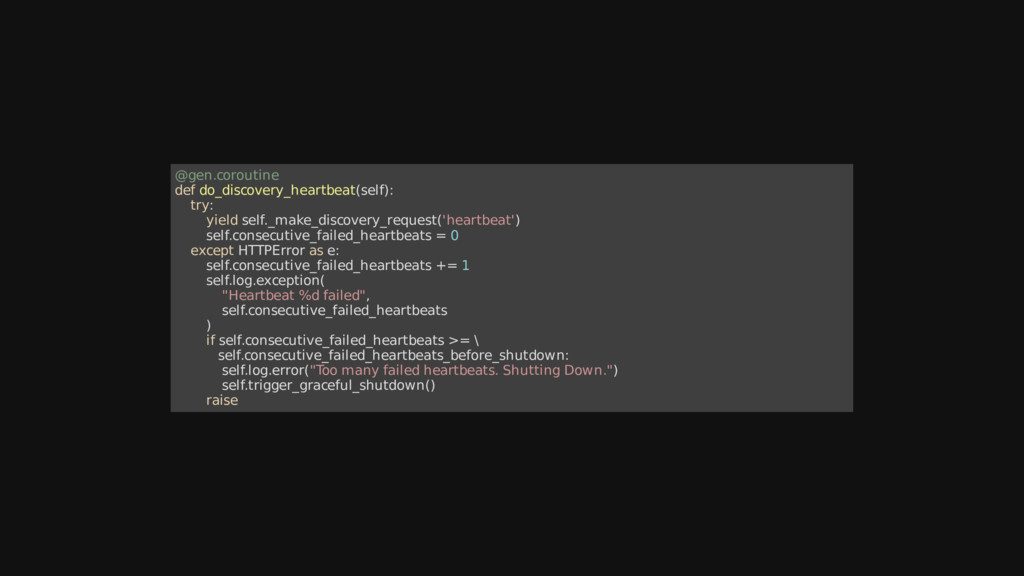{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}