18.335,69,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0, 0 2006,F, 18.875,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 2006,NA, 18.995,10,0,0,0,0,0,0,0,0,0,0,0,1,0,0,5,1,1,0,3,0,1,0,0,0,1,0,0,0,2,0,0,0,0,0,1, 1 R - Unser Dataset Aus einem Sozialen Netzwerk wurden die 500 häufigsten Begriffe von High-School Schülerprofilen den oben genannten Kategorien zugewiesen und die Häufigkeit der Begriffe pro User gezählt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14 Clustering der Daten > interests <- teens[5:40] > interests_z](https://files.speakerdeck.com/presentations/cd38903a707444a0a93521e2b1b43c52/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![20 SparkConf sparkConfig = new SparkConf(); sparkConfig.setMaster("local[3]").setAppName("ES Loader"); sparkConfig.set("es.nodes", “XXX.eu-west-1.aws.found.io:9200");](https://files.speakerdeck.com/presentations/cd38903a707444a0a93521e2b1b43c52/slide_19.jpg){kind=link}
{kind=link}
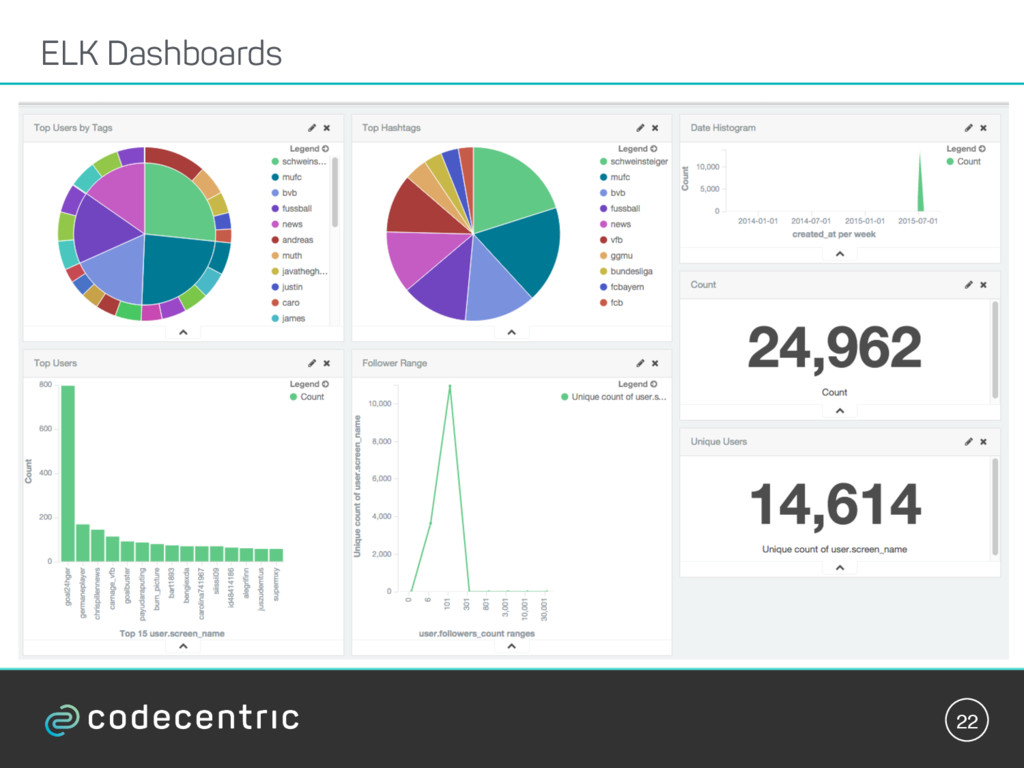{kind=link}
{kind=link}
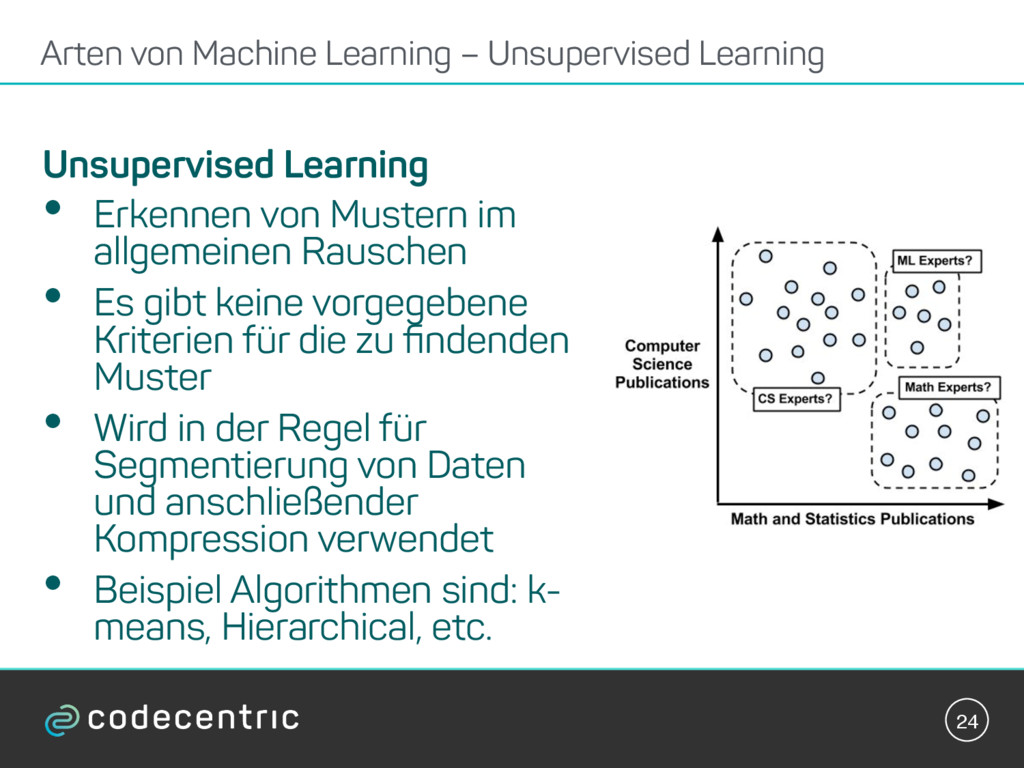{kind=link}
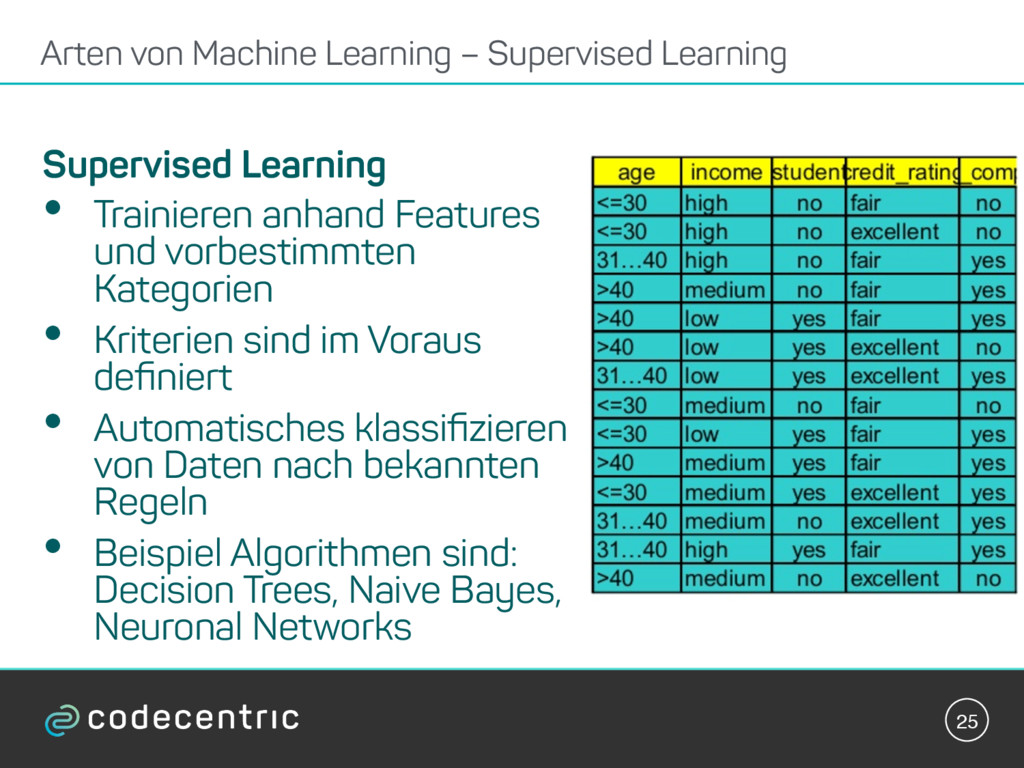{kind=link}
{kind=link}
{kind=link}
![28 private static String[][] clubs = new String[][] {{"FC Bayern",](https://files.speakerdeck.com/presentations/cd38903a707444a0a93521e2b1b43c52/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![33 Klassifizierungslauf : Spark public static void main(String[] args) throws](https://files.speakerdeck.com/presentations/cd38903a707444a0a93521e2b1b43c52/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}