auf Streams? Kein Problem. SQL und Joins auf non-RDBMS? Kein Problem. Graphen Operationen auf non-Graphen? Kein Problem. Map/Reduce aber in schnell? Gerne.
einem logischen Rechner Statisches Deployment von Mesos Dynamisches Deployment der Workload Gute Integration mit Hadoop, Kafka, Spark Wirklich wirklich vielen Maschinen - Rechenzentren
10'000 Requests pro Maschine und Sekunde Ausfallsicher Comfort eines Spaltenindex mit Append Only Performance Datensicher auch über mehrere Rechenzentren Stark in Denormalisierung
Mega Bytes pro Sekunde an Tausende von Clients Skaliert - Partitionierung der Daten auf handlebare Größen Datensicher - Append Only, um TBs an Daten ohne Performanceverluste zu speichern Verteilt - von Anfang an
Rechenzentrumsüberwachung basieren auf Single-Threaded, Cache-Optimized, Memory-Barrier Ringbuffer und sind per Definition "schlampig" und haben sehr statische und kleine Kontexte.
SMACK Aktualisieren der Nachrichtenseiten Klassifikation von Usern (Business) Realtime Bidding für Advertising IoT bei Automobilherstellern Digitalisierung der Fertigung
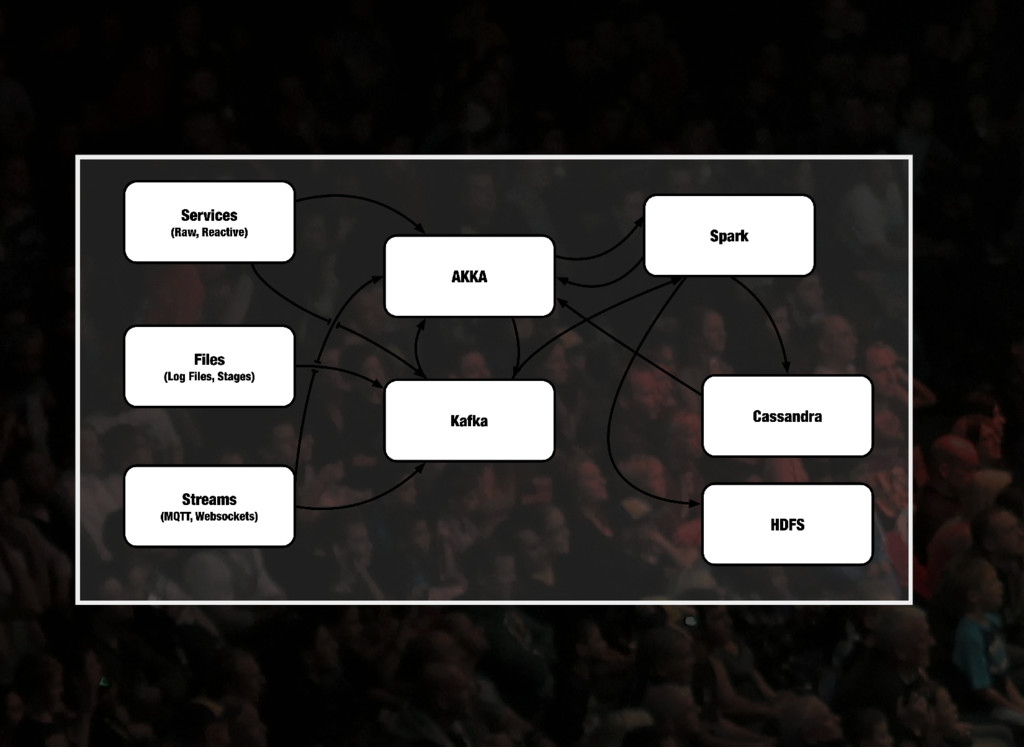
aus den Fenstern. Nutzt Kafka, Datenbanken, Akka oder andere Streams als Input Batches können per ETL in persistente Speicher geflushed werden Batch RDDs können per SQL In-Memory/Disk ausgeführt werden Klassifikation der Daten in neue RDDs oder persistente Speicher
Anzeige schalte ich? Welches X-Selling Angebot zeige ich? Mit Akka kann ich auf einzelne Events reagieren. Mit Spark Stream und Cassandra habe ich schnelle Speicher um einen Entscheidungskontext zu etablieren.
und Spark. Es gibt raw streams für TCP, UDP Verbindungen, Files, etc. Es gibt reactive streams für Back Pressure Umgang. Kafka kann zwischen raw und reactive Streams konvertieren.
der Zeit verarbeitet werden können. Da Stream Events im Speicher bleiben sollen, muss der Gegendruck gemanaged werden, da sonst ein Speicherüberlauf provoziert wird! mehr später
muss es direkt in Akka eingespielt werden. Sonst über Kafka. Wieso Kafka? Append Only:Consumer können für Tage ausfallen. Broker:Reduktion der Punkt zu Punkt Verbindungen. Router:Routen von Streams inklusive (De-)Multiplexing. Pufferung:Ausgleichen von Lastspitzen. Replay:Fehler im Algorithmus und falsche Daten? Redeploy und Replay!
mehr Schutz vor Ausfällen und Elastizität. Mesos erfordert keine Virtualisierung oder Containerisierung. Kann alle Big Data Tools direkt ausführen. Die Workload bestimmt das Cluster.
bedrohliche Lastschwankungen. Buffer können Lastspitzen ausgleichen. Unbound Buffer können bei Speichererschöpfung fatale Probleme auslösen. Bound Buffer haben verschiedene Optionen bei ausgeschöpftem Speicher. FIFO Drop? FILO Drop? Reduced Sampling?
er von PUSH zu PULL. Dieser Fallback kann sich durch den Stream Graphen nach vorne durchziehen. Die Stromquelle wird schlussendlich vor die Entscheidung gestellt, wie damit umzugehen ist.
implementiert Reactive Streams. Spark Streaming 1.6 erlaubt Reactive Stream als Protokoll für die Konsumenten. Kafka ist ein idealer Bound Buffer für Event Ströme. Mesos Frameworks können Konsumenten on-the-fly out-scalen.
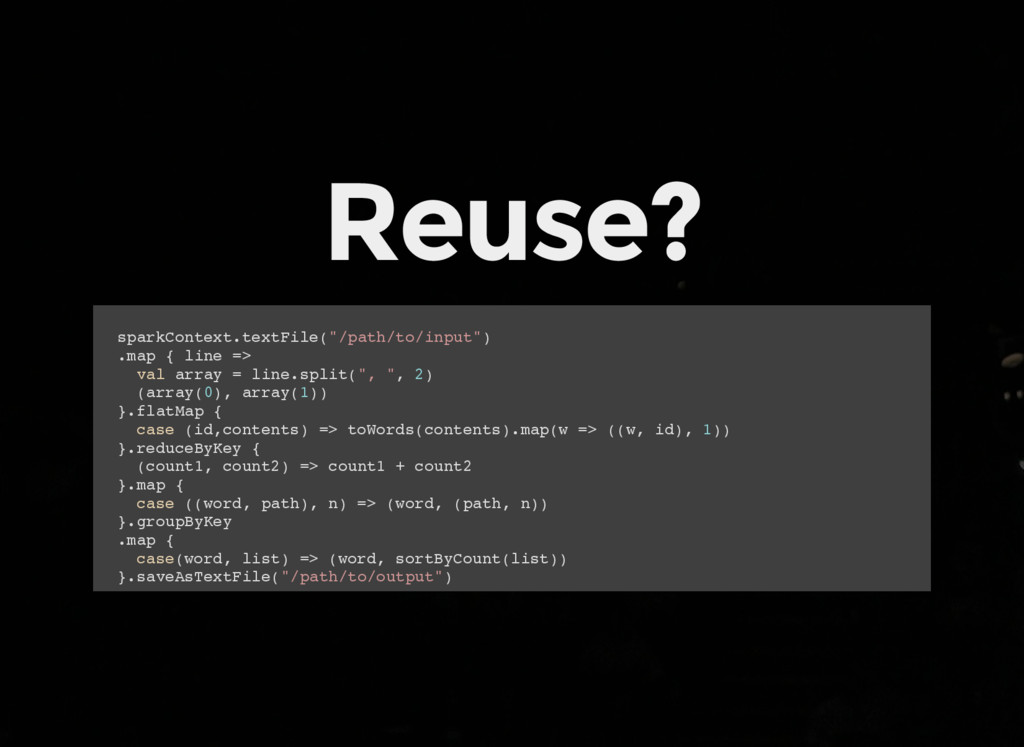
das führt zu keinen Überraschungen. Functions haben keine Seiteneffekte - keinen Zustand zwischen den Aufrufen manipulieren. Functions sind First Class - Erhöht die Wiederverwendung.
e x t . t e x t F i l e ( " / p a t h / t o / i n p u t " ) . m a p { l i n e = > v a l a r r a y = l i n e . s p l i t ( " , " , 2 ) ( a r r a y ( 0 ) , a r r a y ( 1 ) ) } . f l a t M a p { c a s e ( i d , c o n t e n t s ) = > t o W o r d s ( c o n t e n t s ) . m a p ( w = > ( ( w , i d ) , 1 ) ) } . r e d u c e B y K e y { ( c o u n t 1 , c o u n t 2 ) = > c o u n t 1 + c o u n t 2 } . m a p { c a s e ( ( w o r d , p a t h ) , n ) = > ( w o r d , ( p a t h , n ) ) } . g r o u p B y K e y . m a p { c a s e ( w o r d , l i s t ) = > ( w o r d , s o r t B y C o u n t ( l i s t ) ) } . s a v e A s T e x t F i l e ( " / p a t h / t o / o u t p u t " )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}