L I S I E R U N G & C O N TA I N E R • Virtualisierung kommt nicht, sie ist da. • Mal keine Zahlen von Amazon sondern von Azure: • 300’000 aktive Webseiten • 30’000’000’000’000 (Billionen) gespeicherte Objekte • 3’000’000 Anfragen pro Sekunde • 1’000’000 SQL Datenbanken • 300’000’000 Active Directory User • 15’000’000’000 $ Investion in Rechenzentren
L I S I E R U N G & C O N TA I N E R • Folgen wir dem Geld noch weiter: • Mesosphere - RZ Virtualisierung: 10,5 Mio $ • Docker - Container: 40 Mio $ • Stratoscale - Automatisierung u.a. Docker: 32 Mio $ • Mirantis - OpenStack Distro: 100 Mio $ • Metacloud - private Clouds: 15 Mio $ • Puppet Labs - DevOps: 40 Mio $ • Moogsoft - Cloud Monitoring: 11 Mio $
R E C H E N • Rechner sind „zu groß“: • 2001: Websphere Portal Server auf dem Pentium 60% CPU in Idle • 2015: Wildfly auf iCore7 2% CPU in Idle • Sub-Organisation des Blechs in virtuellen Maschinen • Lieferung von Computing Einheiten in Sekunden
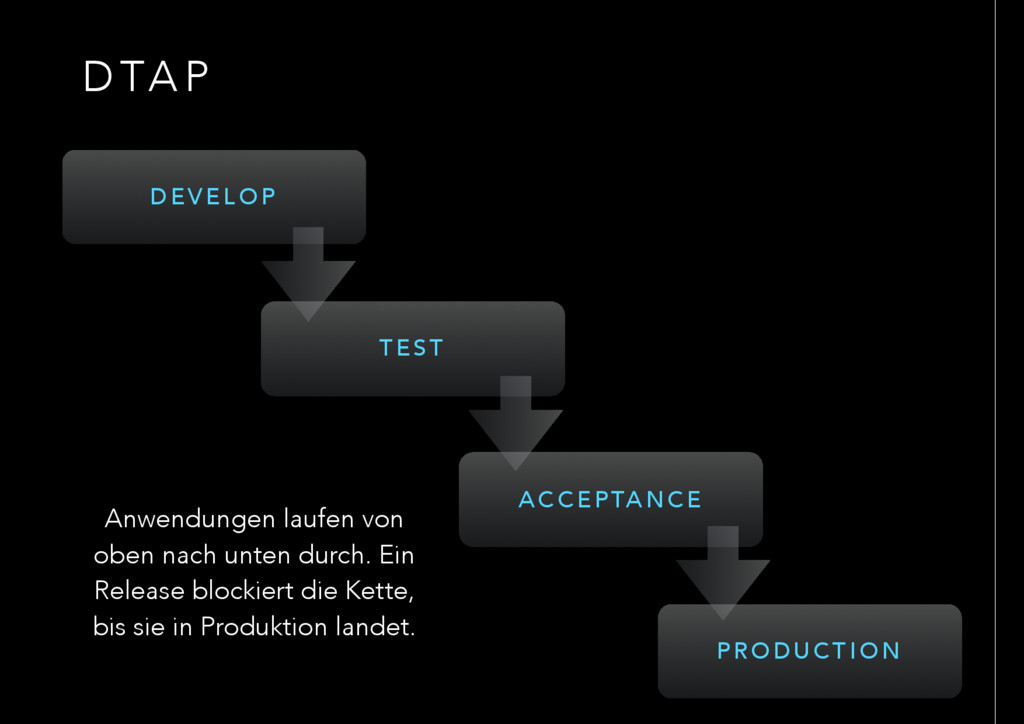
T E S T A C C E P TA N C E P R O D U C T I O N Anwendungen laufen von oben nach unten durch. Ein Release blockiert die Kette, bis sie in Produktion landet.
A N D TA P ? • meist sind die Umgebungen verschieden - insbesondere in Ihrer Qualität • Testdaten? • Cluster Topologien? • Hardware Größen? • Lizenzen? • Hardware Architekturen? • Konfigurationen • In Produktion treten Fehler zum ersten Mal auf, da der Auslöser in den vorherigen Umgebungen nicht existieren! • Verteilte Entwicklung passt schwer in das 1-D Layout • Roll-Backs inklusive Daten sind nicht getestet
R D V M S I Z E S . S K A L I E R T H O R I Z O N TA L . Die Produktionsumgebung besteht aus mehr Knoten, nicht aus größeren. Dann ist DTA mehr wie Produktion. WA S I S T M I T M I R ?
S - S C H A M A N I S M U S • Produktion wird immer als heilig gesehen. Sie ist immer anders und wird nur per Hand angefasst • Es entsteht eine Environment Drift • Daher treten Fehler häufiger in Produktion auf • Die Fehler sind natürlich ungeplant und deren Behebung auch • Aus Zeitmangel wird nur die Produktion repariert, die anderen Umgebungen bleiben außen vor • Der Drift vergrößert sich • Warum ist die Produktion wohl anders?
einen NoSQL Zoo • … gibt es Go, Erlang, Ruby, Server Side JS, Java • … gibt es vert.x, Tomcat, Jetty, Netty, JBoss, Grails, Hadoop • in einem Unternehmen, einem Bereich, einem Projekt
immer komplexer • Die ehemalige Standard Infrastruktur wird immer spezifischer und ausgeklügelter • Die Komplexität der Infrastruktur wird ähnlich groß wie in der Anwendung • OPS wird mehr zu DEV THERE ARE TOO FEW DAMN TOOLS FOR TODAY’S PROBLEMS
A U C H F Ü R I N F R A S T R U K T U R Infrastruktur wird immer komplexer. Deren Komplexität und Wandel müssen durch Automatisierung beherrscht werden. WA S I S T M I T M I R ?
baut immer bessere Infrastruktur • Entwicklung baut immer bessere Software • Beides muss regelmäßig integriert werden. • Das geht auch vollautomatisch auf einer DTAP Strecke…
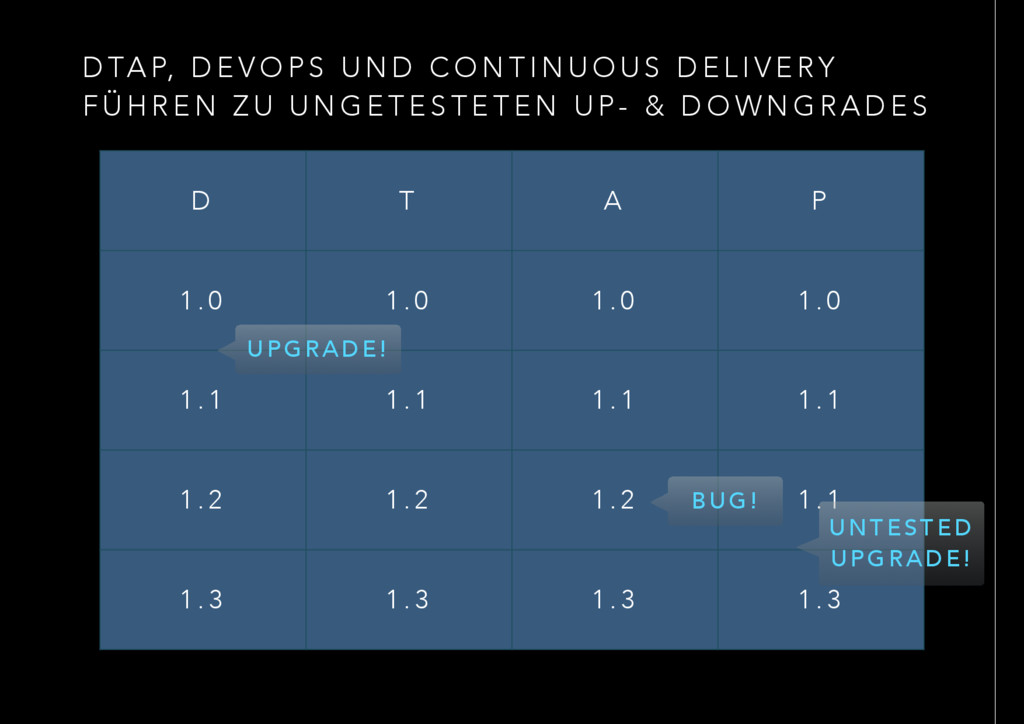
N G E N U N D I N F R A S T R U K T U R • Die Zusammenführung einer Infrastruktur- und Anwendungsrevision ist eine neue Release • Diese wird durch die DTAP geschoben • Solange die Release noch nicht in Produktion ist, ist die DTAP Strecke gesperrt • Es kann keine neue Revision für entweder Anwendung- oder Infrastrukturreleases geprüft werden
N D C O N T I N U O U S D E L I V E RY F Ü H R E N Z U U N G E T E S T E T E N U P - & D O W N G R A D E S D T A P 1 . 0 1 . 0 1 . 0 1 . 0 1 . 1 1 . 1 1 . 1 1 . 1 1 . 2 1 . 2 1 . 2 1 . 1 1 . 3 1 . 3 1 . 3 1 . 3 B U G ! U P G R A D E ! U N T E S T E D U P G R A D E !
V E R V E R E I N FA C H E N S O L U T I O N L I F E C Y C L E M A N A G E M E N T Speziell mit Infrastruktur Automatisierung werden Migrationen während den Up- & Downgrades wichtig und müssen getestet werden. WA S I S T M I T M I R ?
O D E • Continuous Delivery ist der Hit • Alle Bereiche übernehmen das Vorgehen • Jetzt muss Bereichsübergreifend auf Services zugegriffen werden • Nicht nur auf Services im Allgemeinen, auch auf spezifische Revisionsgruppen! • Die DTAP Strecke kann nicht nur durch eine laufende Release sondern durch externe Bereiche blockiert werden.
I N U O U S D E L I V E RY A U F • Laufende Releases sperren die DTAP Strecke, so dass Entwicklungen gequeued werden - Feature Branches sind somit auch tot • Externe Abhängigkeiten sperren einzelne DTAP Strecken - Dead Lock ist ohne weiteres möglich
C H M A L ? • Schrittweise Näherung an Produktionsbedingungen • Standard VM Size • DevOps • Schutz der Endanwender: • Interaktion mit der Lösung • Daten in der Lösung
E • Jedes Deployment von Anwendung und Infrastruktur ist eine eigenständige Release • Anstatt die Release durch die Umgebungen zu ziehen - ziehen die Releases an der Anwendung vorbei • Reconfiguration on the fly • Nodes hoch und runterfahren • Traffic umleiten • Datenquellen umziehen THERE ARE TOO MANY DAMN CONFUSING IDEAS IN THIS TALK
O N F I G U R AT I O N • Jede PAAS Lösung kommt mit einer „eleganten“ Möglichkeit Konfigurationen zur Laufzeit zu verwalten • Auch mit etcd können sich Knoten anmelden und Folge Konfigurationen generiert werden (Loadbalancer Konfiguration und Tomcats) • Konfigurationsfiles sollen keine Umgebung beschreiben (d.h. vorgeben) sondern werden aus der Umgebung erstellt. • Damit können neue Systeme zu neuen Umgebungen integriert werden und bestehende Umgebungen vergrößert/ verkleinert werden.
C O V E RY O V E R S E R V I C E D E F I N I T I O N Konfigurationen dürfen nicht Teil der Infrastruktur und Anwendungen sein. Konfigurationen leiten sich aus der jeweiligen Umgebung ab. WA S I S T M I T M I R ?
Daten laufen • Daten sind zu groß um kopiert zu werden • Daher müssen die Datenservices neu verlinkt werden, wenn eine neue Release in Produktion geht. • Snapshots - verhindern das Allerschlimmste • Inkompatible Änderungen in den Schemas? Drop the Schema.
E W O N N E N ? • Durch das tägliche Bauen von Produktionsumgebungen, ist diese „glasklar“ • Specification Drift ist unmöglich • Jeder kann eigene Testumgebungen bauen und nutzen • Keine Wartezeiten oder Locks für Releases • BTW: Anwendungen skalieren! • Komplexität ist noch vorhanden - nur anders verteilt
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}