Venue: OpenStack Summit 2018, Berlin
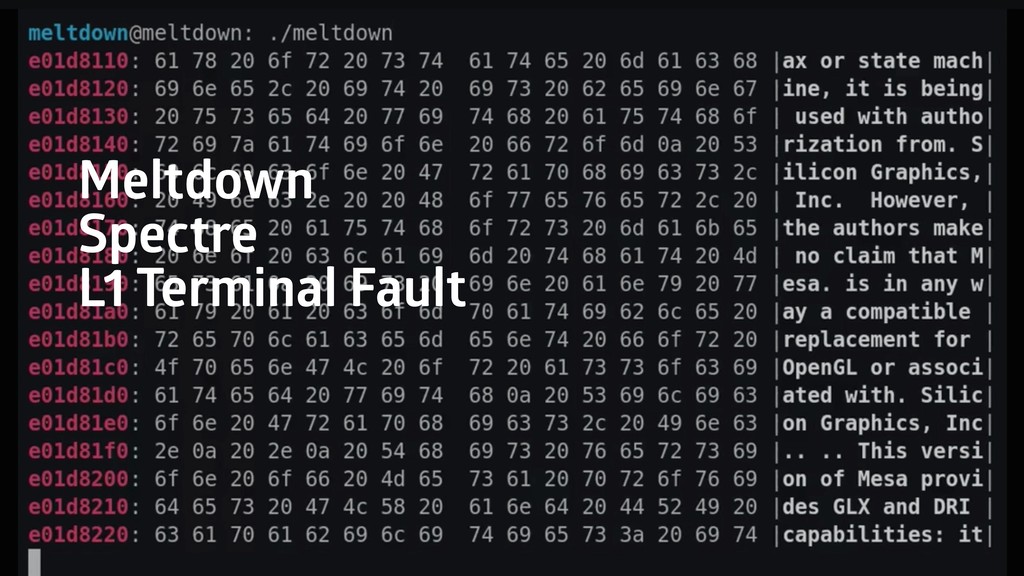
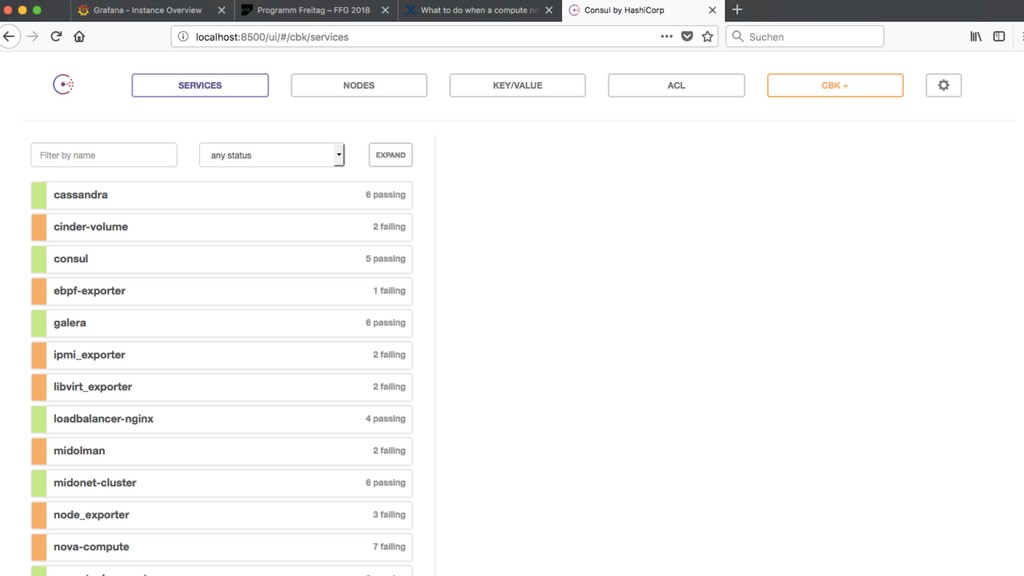
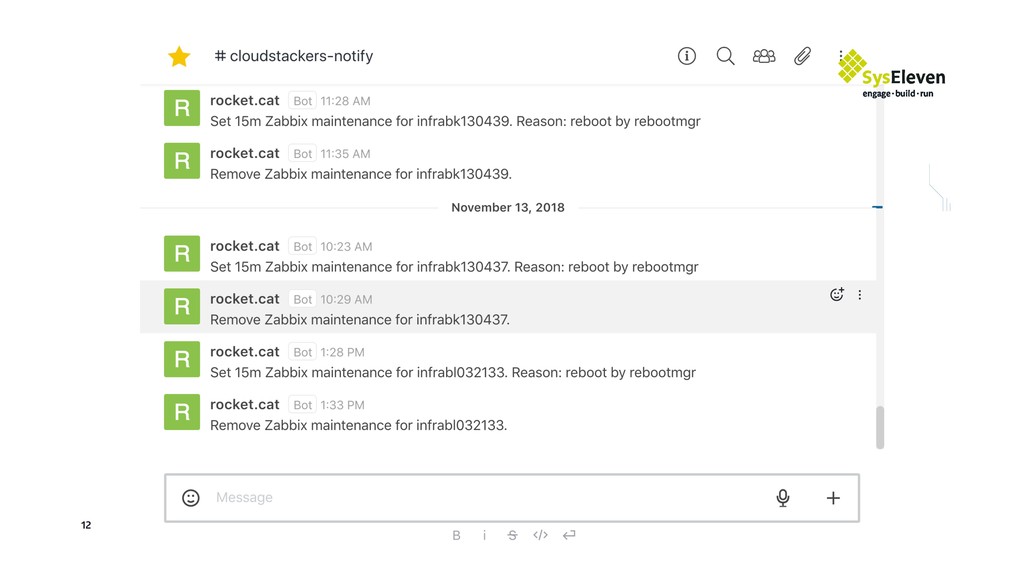
One of OpenStack’s claims is that it can be used as the foundation for public clouds. Technically, this is true: you can manage users, users can start VMs, etc. – but what challenges do you face when you really run a public cloud? In this session, we want to talk about the technical and human challenges we faced. It’s about how to continuously provide (security-) updates to a cloud, continuously evolve a production platform, and finally about one thing: how can we prevent breaking our cloud services? We decided to radically automate the maintenance of our platform. Updates and reboots happen without human control, so engineers have time for more important things. Veteran operations engineers have learned that machines can monitor many more states at the same time and are therefore often more accurate than humans. Developers have learned that great things can happen when they take responsibility for a production platform.
We published the Unattended Reboot Manager on GitHub right before the talk: https://github.com/syseleven/rebootmgr
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}