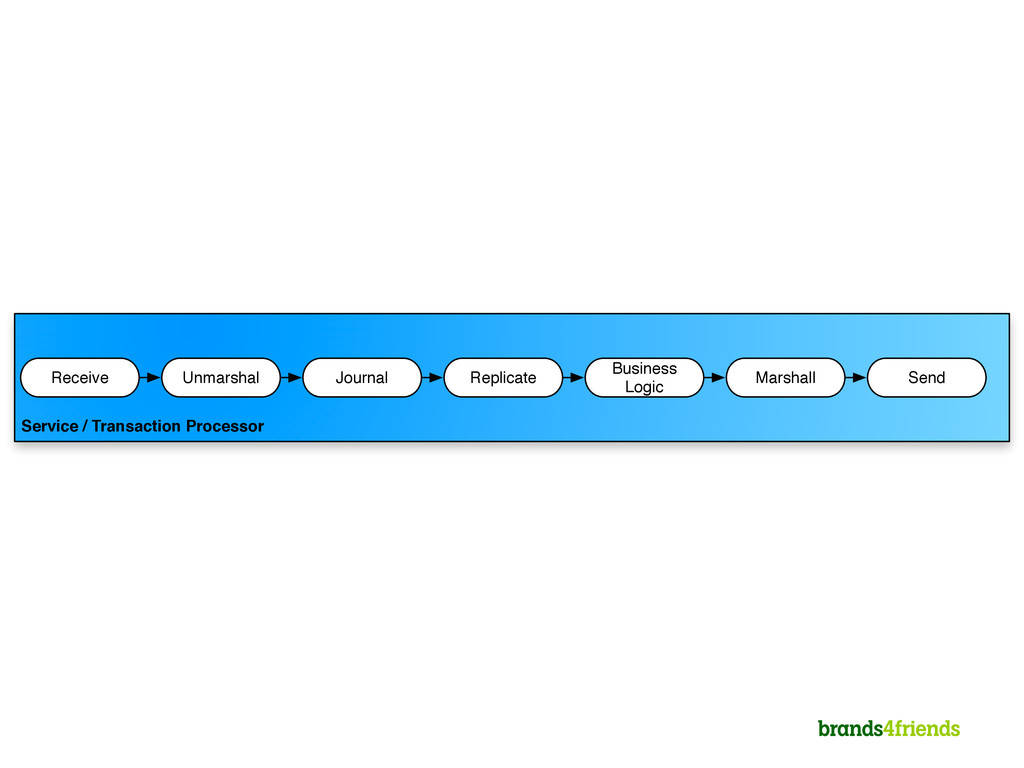
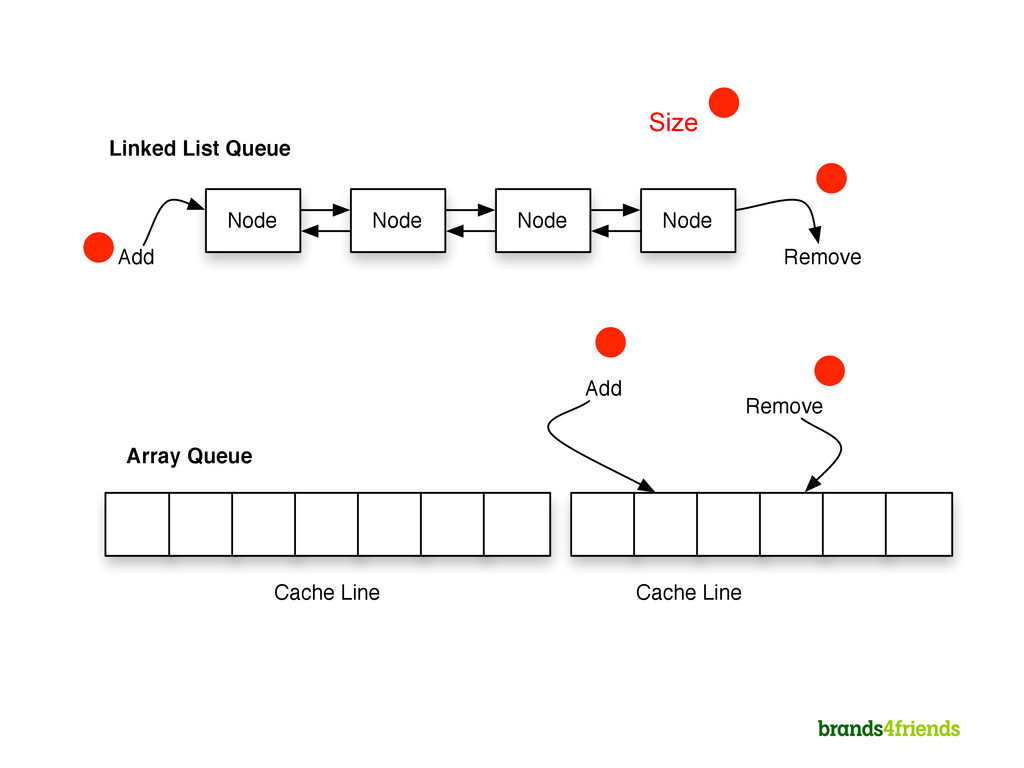
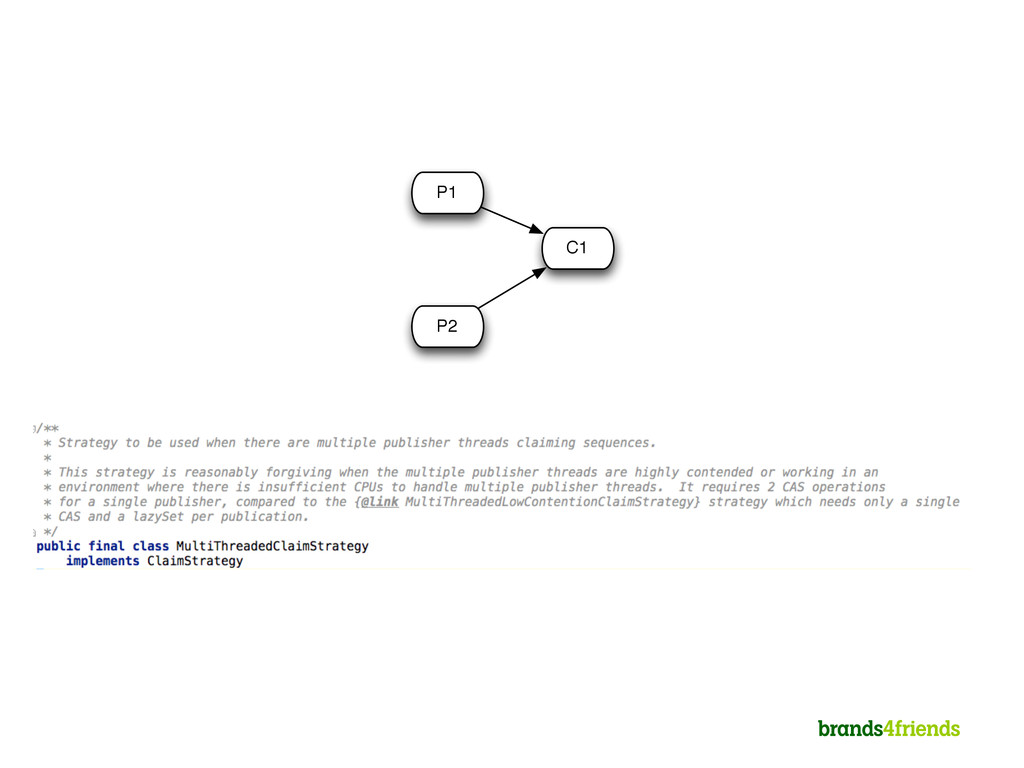
Reading (Take) and Writing (Add) are both write access => Write Contention 2. Write Contention solves with Locks 1. Other solutions include Deques 3. Locks lead to context switches to the kernel 1. Context switches lead to CPU cache misses etc. 2. Kernel might use opportunity to do other stuff as well
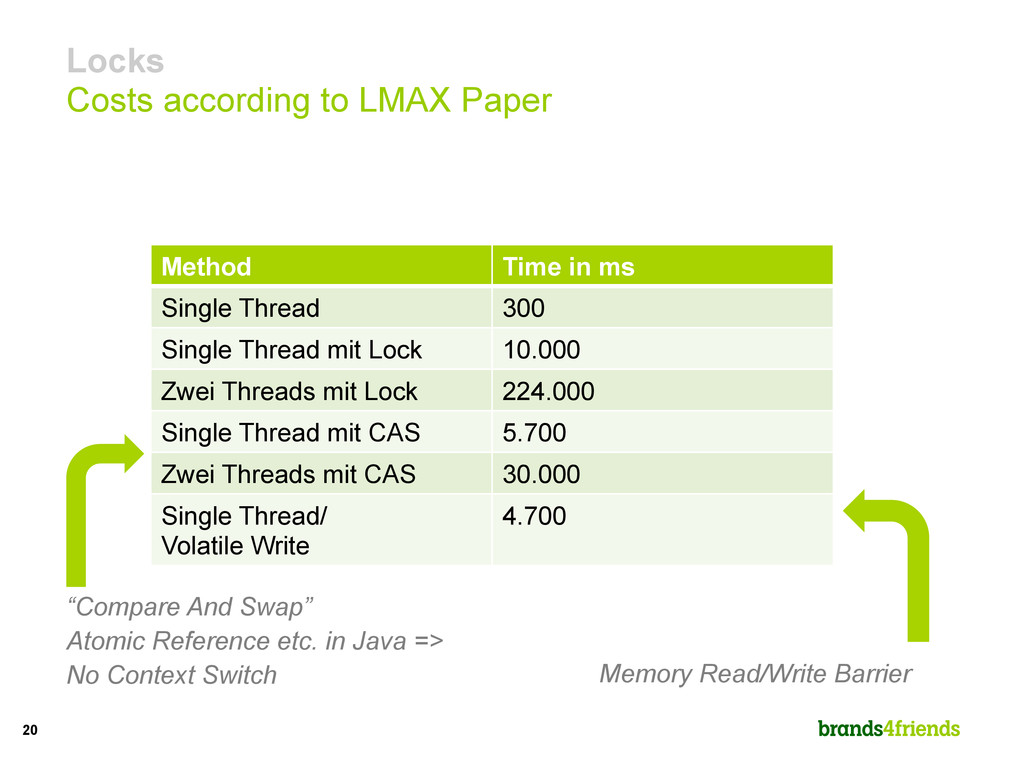
ms Single Thread 300 Single Thread mit Lock 10.000 Zwei Threads mit Lock 224.000 Single Thread mit CAS 5.700 Zwei Threads mit CAS 30.000 Single Thread/ Volatile Write 4.700 “Compare And Swap” Atomic Reference etc. in Java => No Context Switch Memory Read/Write Barrier
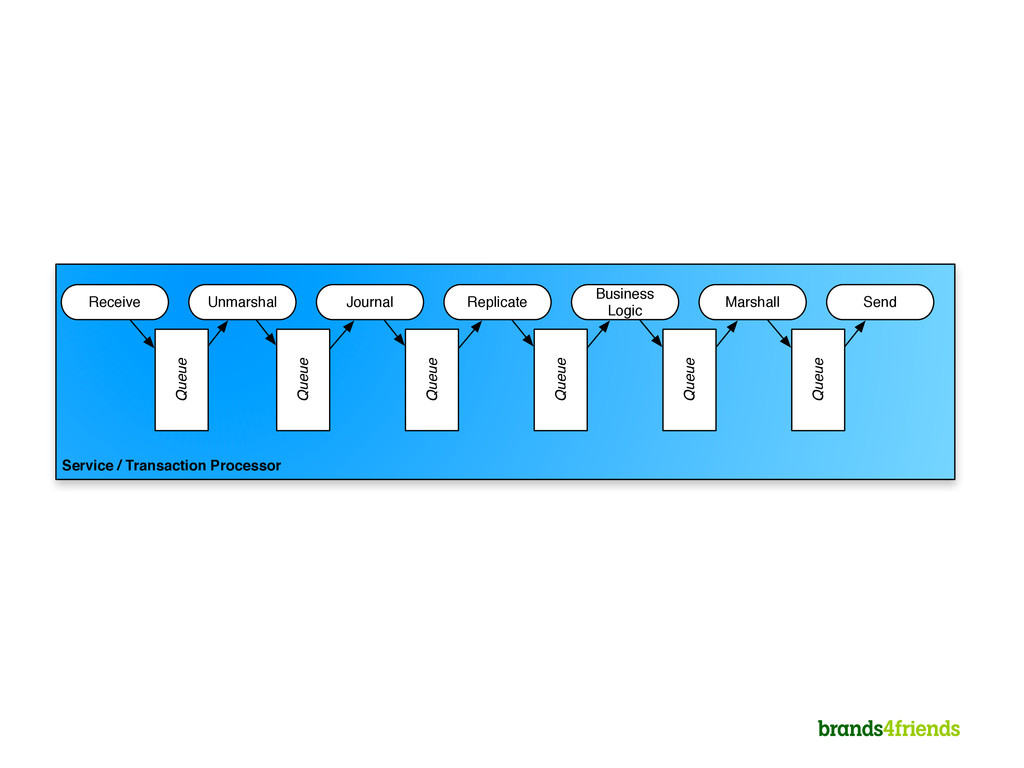
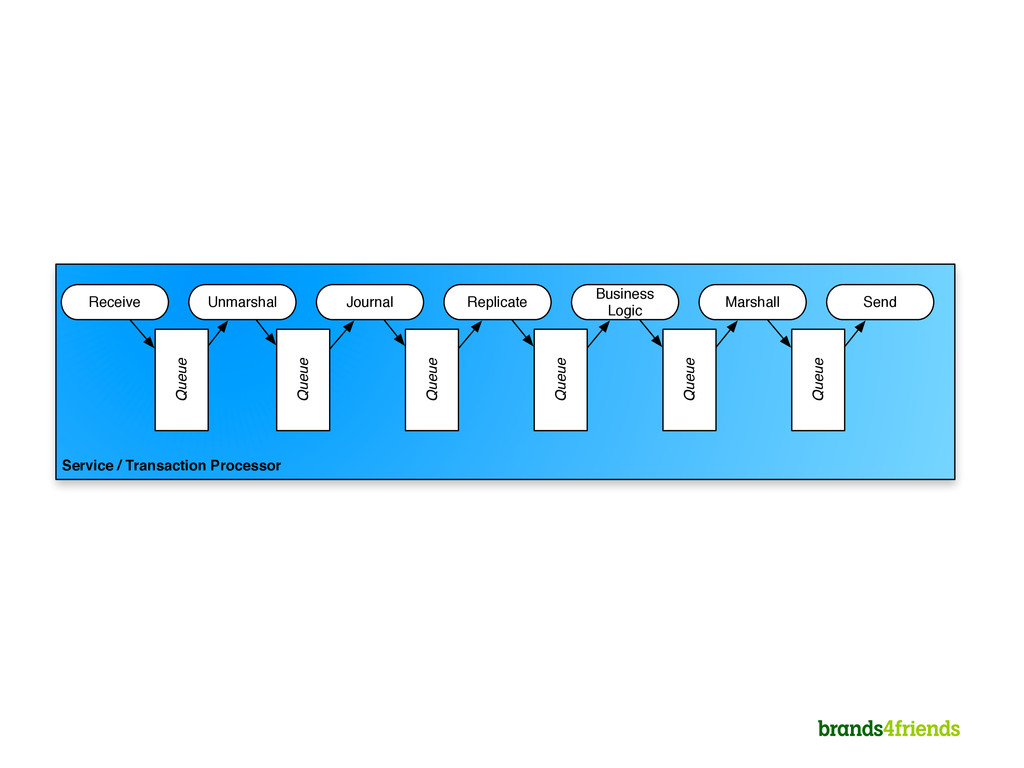
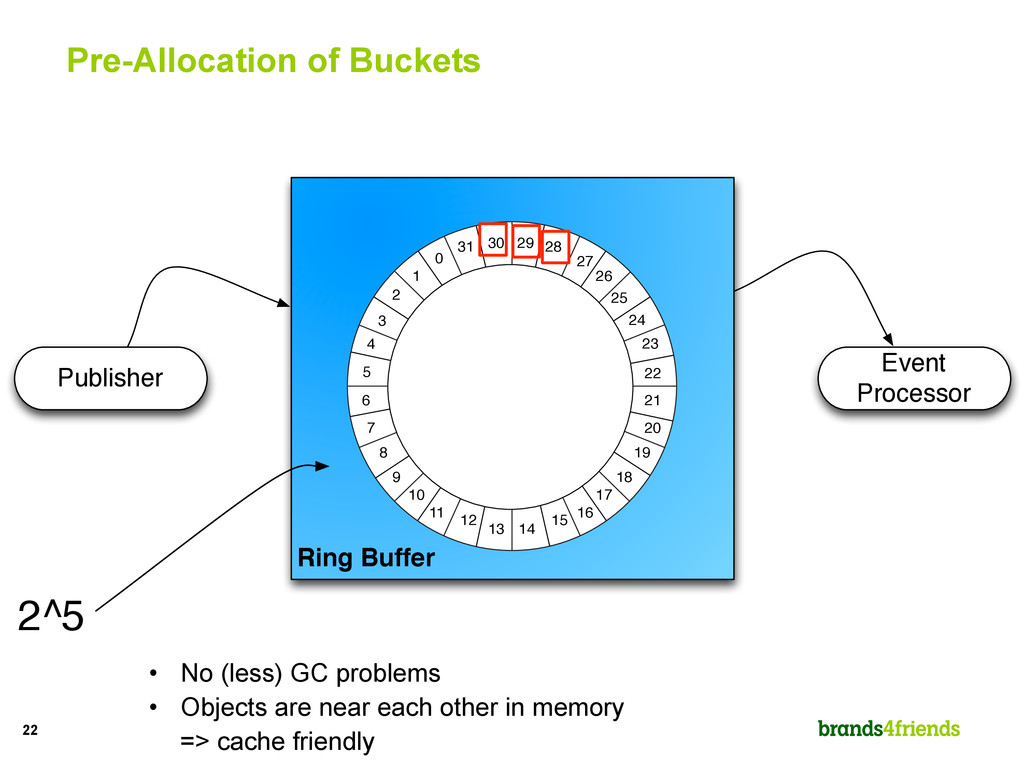
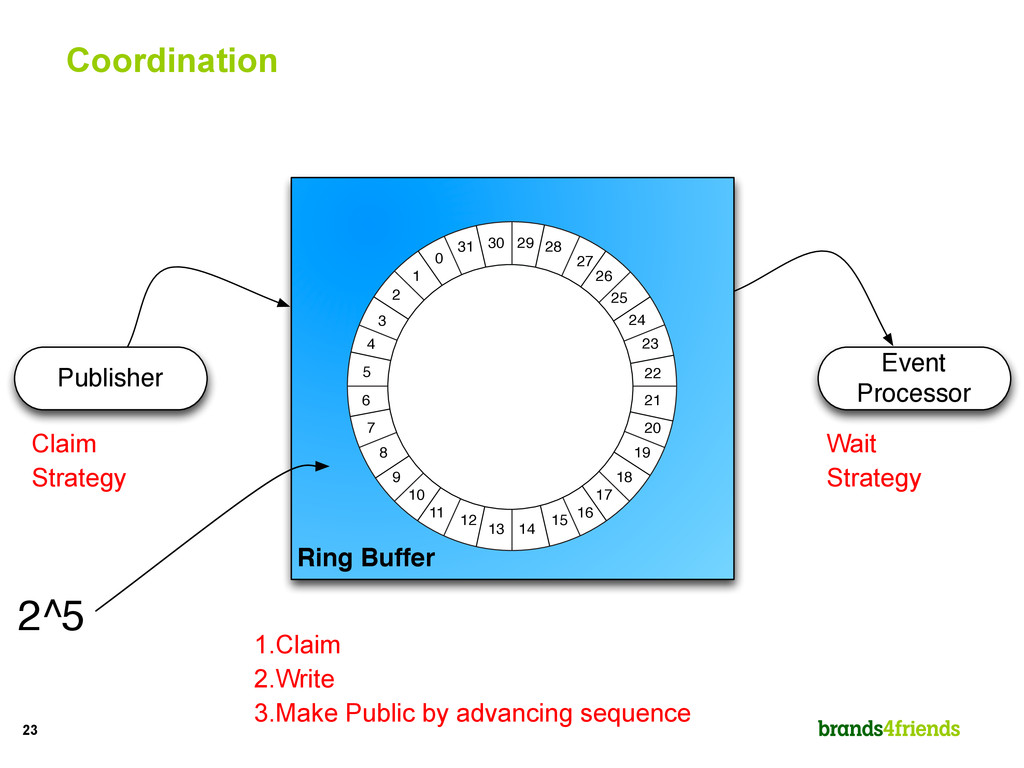
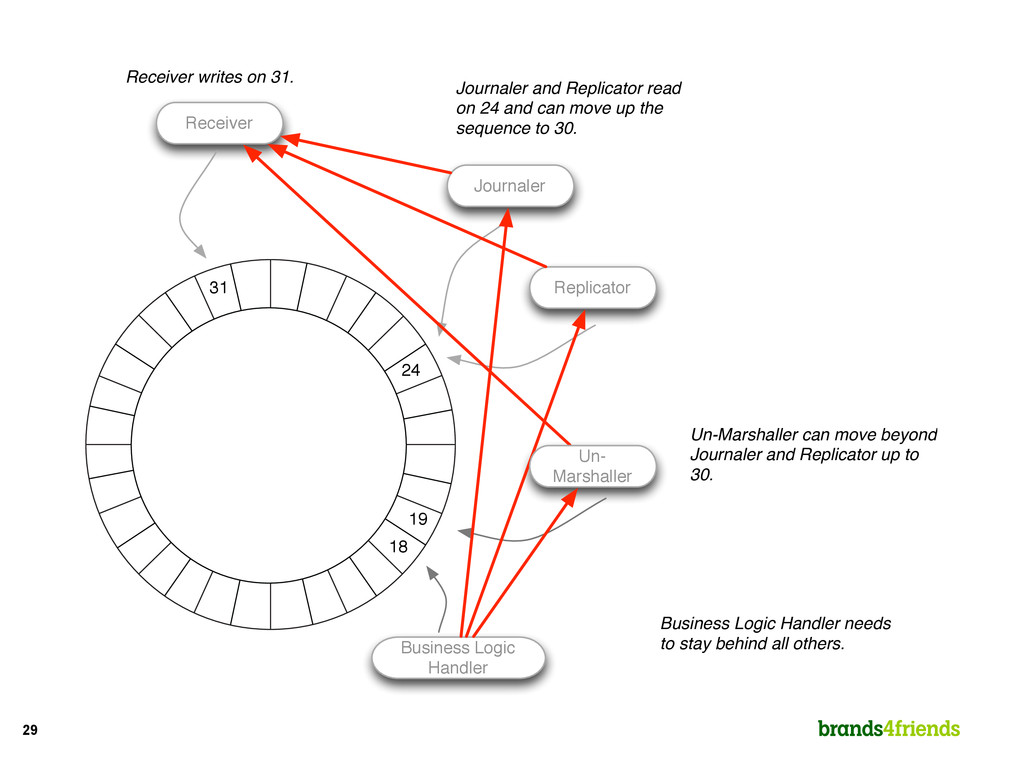
Handler Receiver writes on 31. Journaler and Replicator read on 24 and can move up the sequence to 30. Business Logic Handler needs to stay behind all others. Un-Marshaller can move beyond Journaler and Replicator up to 30. Un- Marshaller
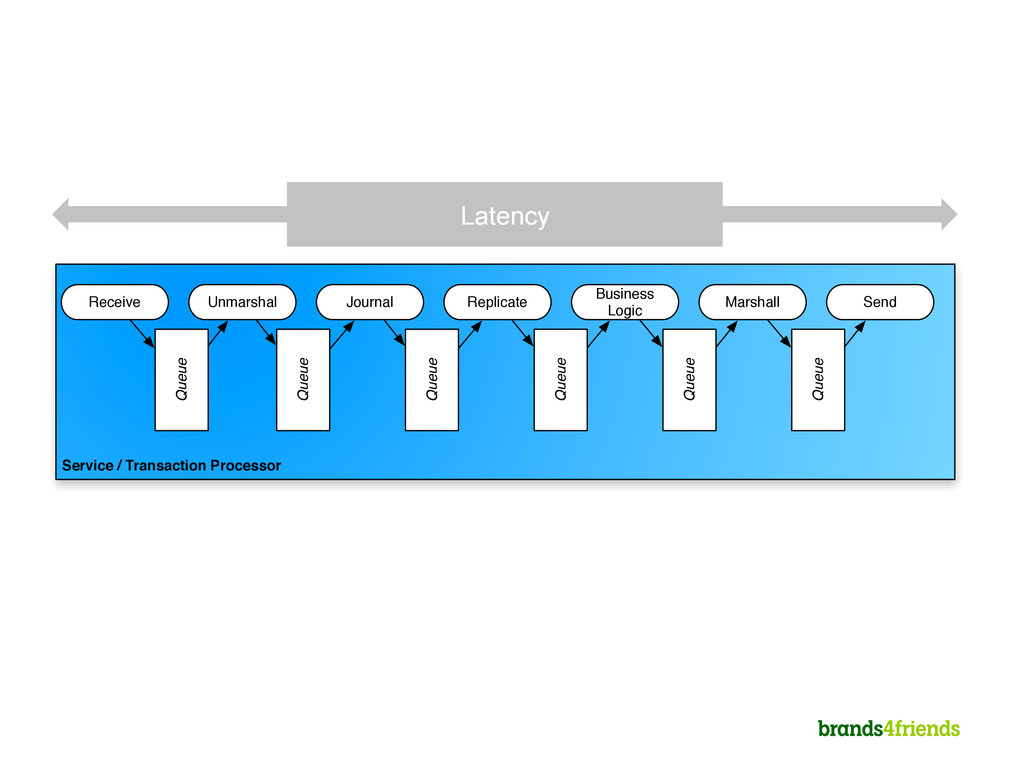
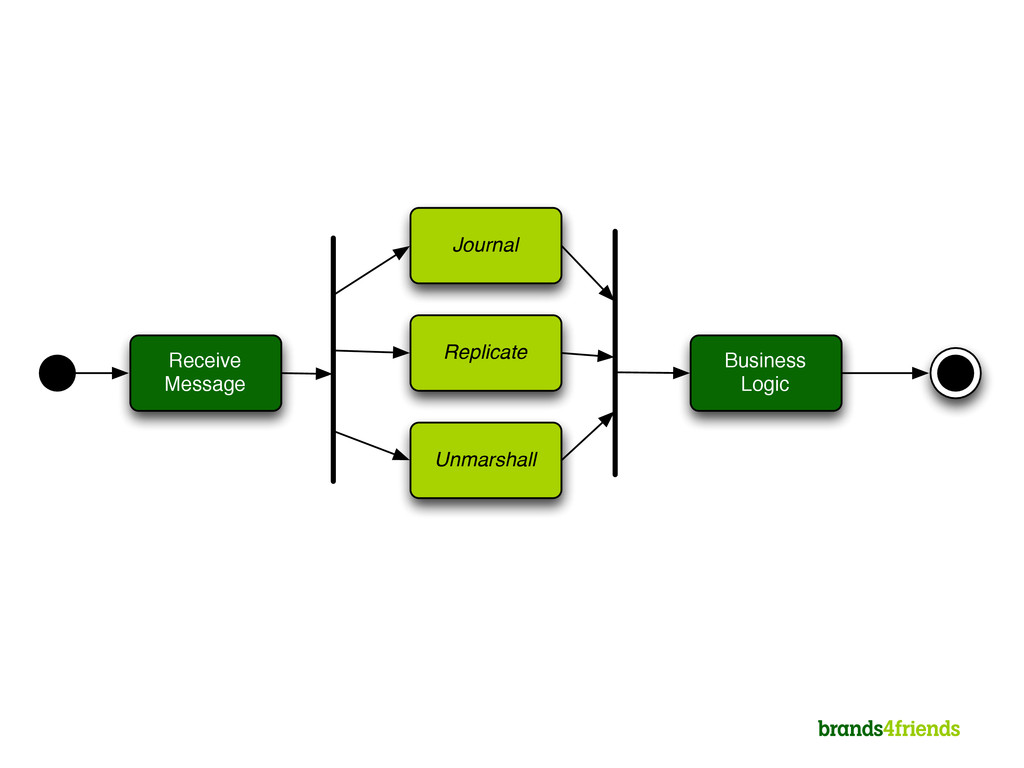
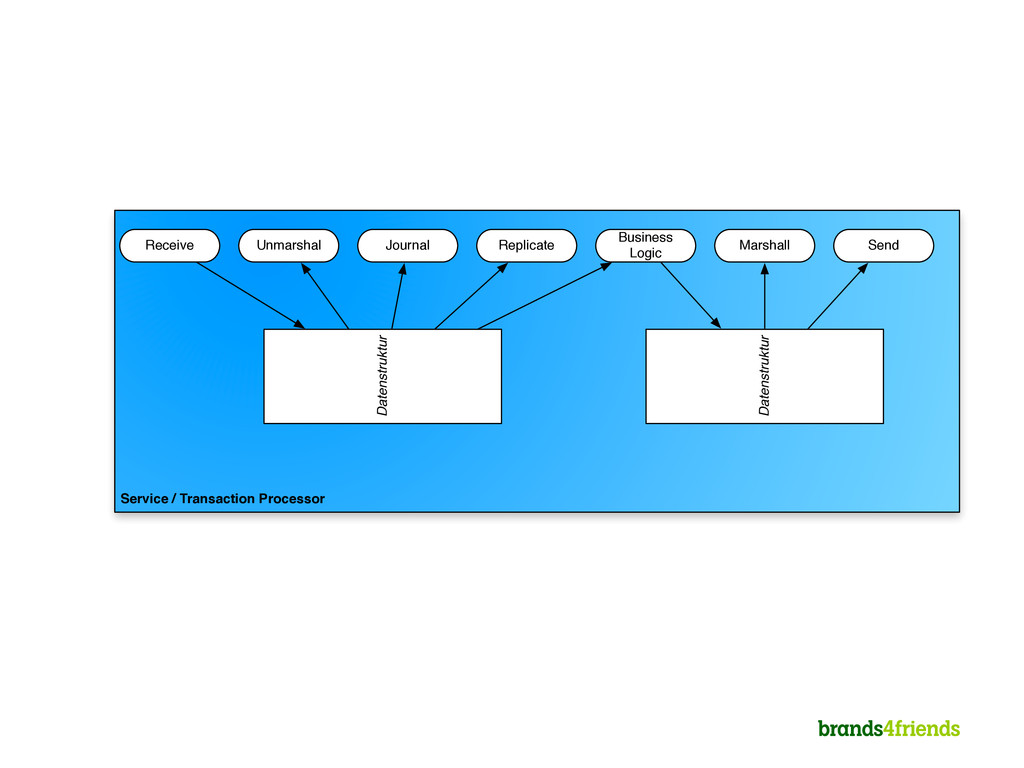
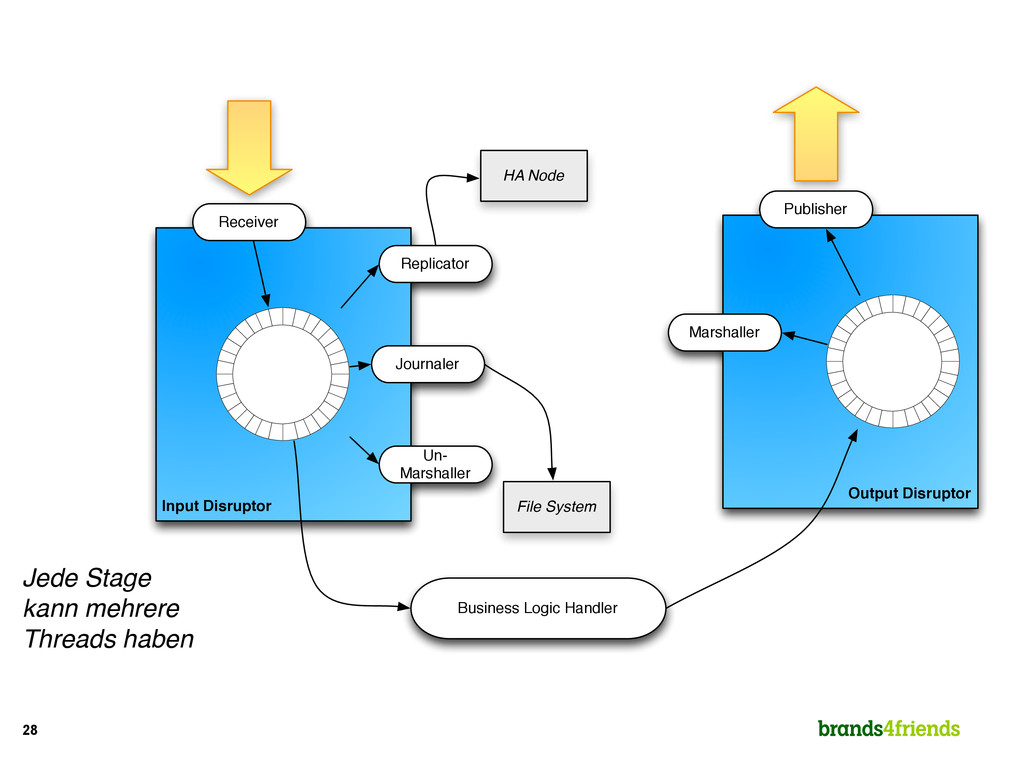
2. Everything in memory 3. Single threaded per CPU for business logic 4. Business logic has no I/O, I/O is done somewhere else 5. Scheduler “knows” dependencies of handlers
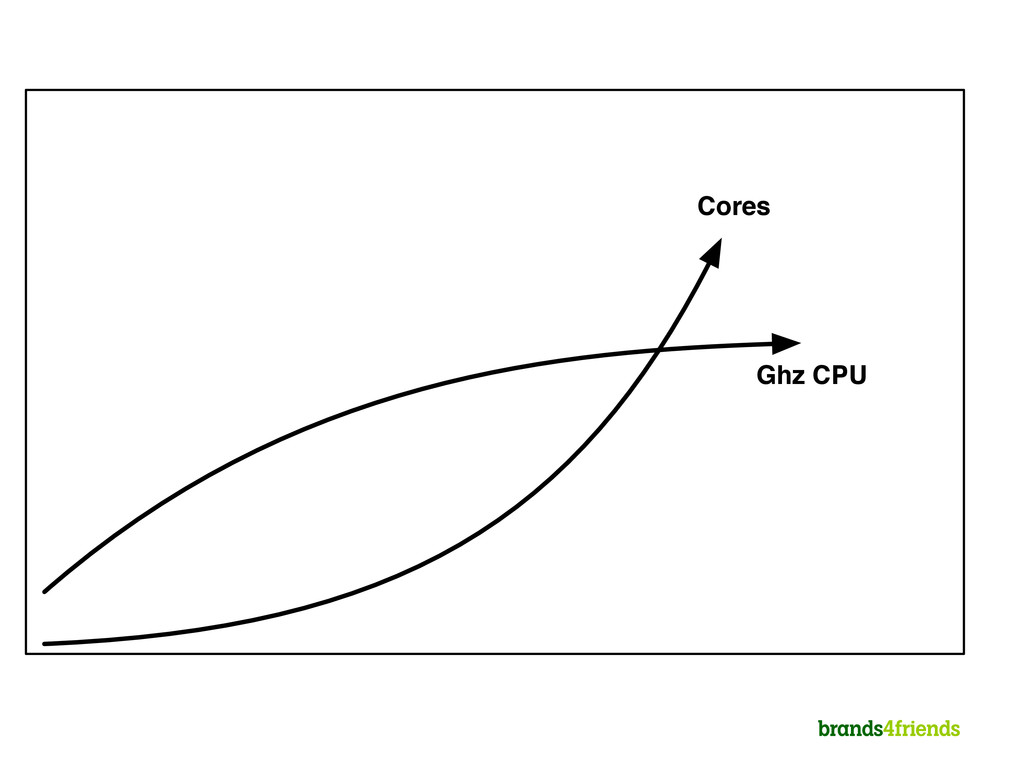
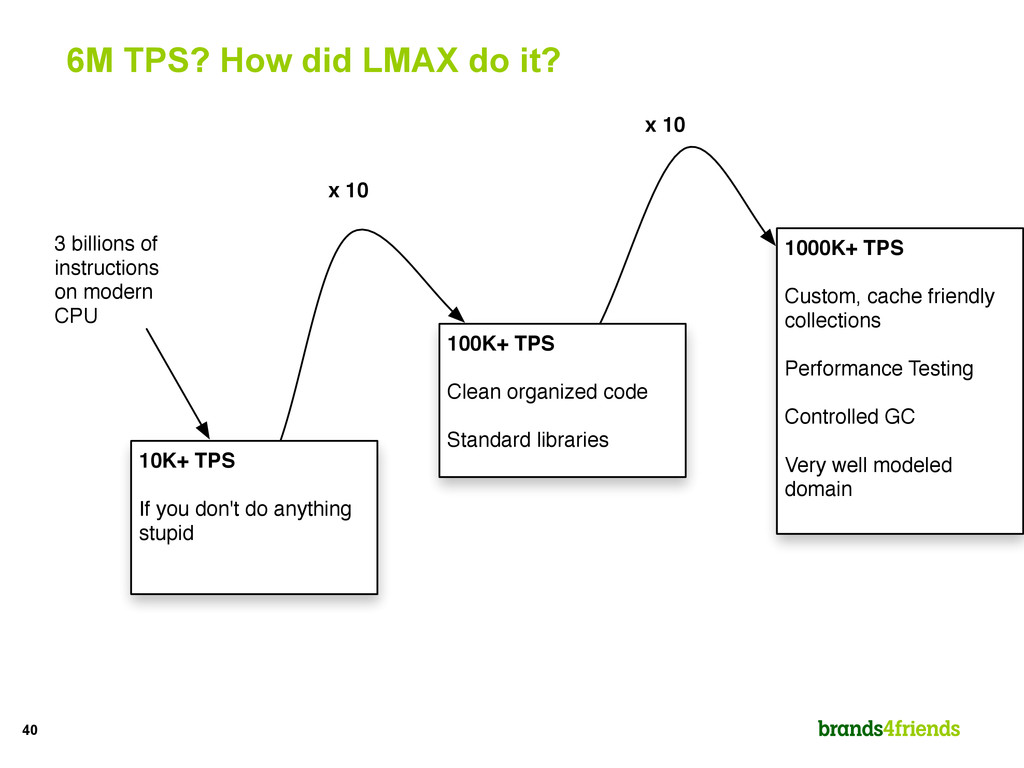
If you don't do anything stupid 3 billions of instructions on modern CPU 100K+ TPS Clean organized code Standard libraries 1000K+ TPS Custom, cache friendly collections Performance Testing Controlled GC Very well modeled domain x 10 x 10
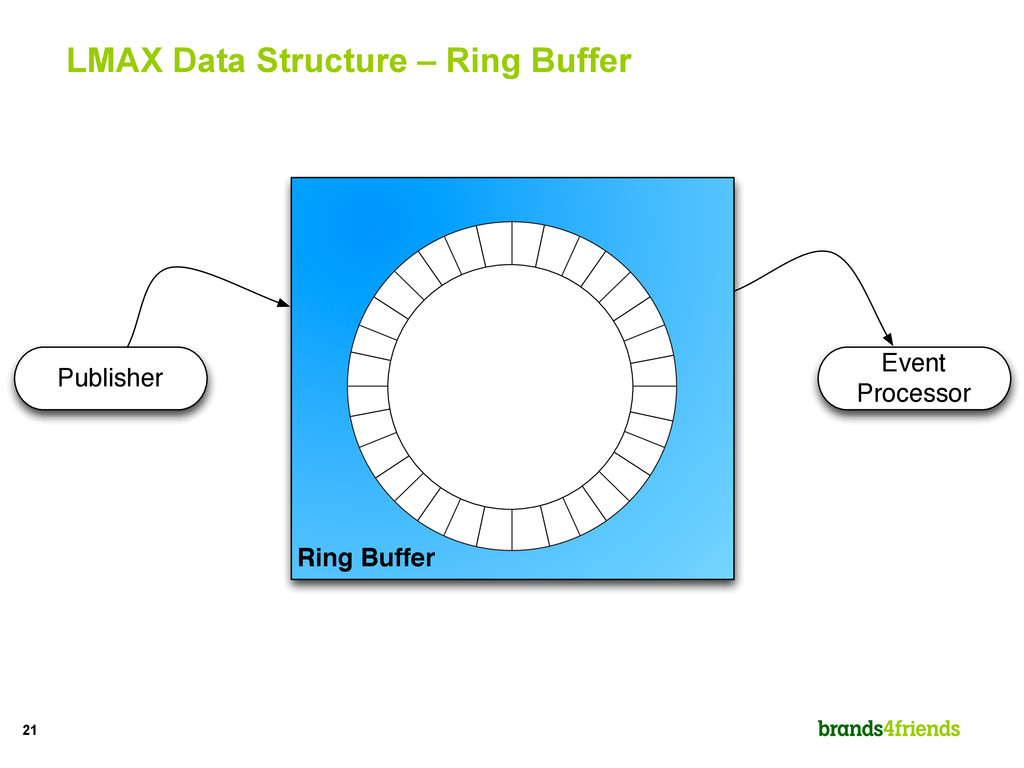
queues for exchanging data between concurrent threads”, Martin Thompson, Dave Farley, Michael Barker, Patricia Gee, Andrew Stewart, 2011 "The LMAX Architecture”, Martin Fowler, 2011 http://martinfowler.com/articles/lmax.html “How to do 100K+ TPS at less than 1ms latency”, Martin Thompson, Michael Barker, 2010
{kind=link}
![Me Stephan Schmidt Vice CTO brands4friends @codemonkeyism www.codemonkeyism.com [email protected]](https://files.speakerdeck.com/presentations/4f9185f791b203002201c7ae/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! @codemonkeyism [email protected]](https://files.speakerdeck.com/presentations/4f9185f791b203002201c7ae/slide_41.jpg){kind=link}
{kind=link}
{kind=link}