Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust Training Language Models to Self-Correct via Reinforcement Learning ICLR 2025 (Oral) 発表者:大井 聖也 東京科学大学 M2 井上研究室 2025/09/01 第17回最先端NLP勉強会 ※ 注釈がない場合、図表は論文からの引用です
Language Models Latently Perform Multi-Hop Reasoning? ACL2024. [2] Huang et al. Large Language Models Cannot Self-Correct Reasoning Yet. ICLR2024. [3] Qu et al. Recursive Introspection: Teaching LLM Agents How to Self-Improve. NeurIPS 2024. [4] Kim et al. Language Models can Solve Computer Tasks. NeurIPS 2023. [5] Havrilla et al. GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements. ICML2024
{kind=link}
{kind=link}
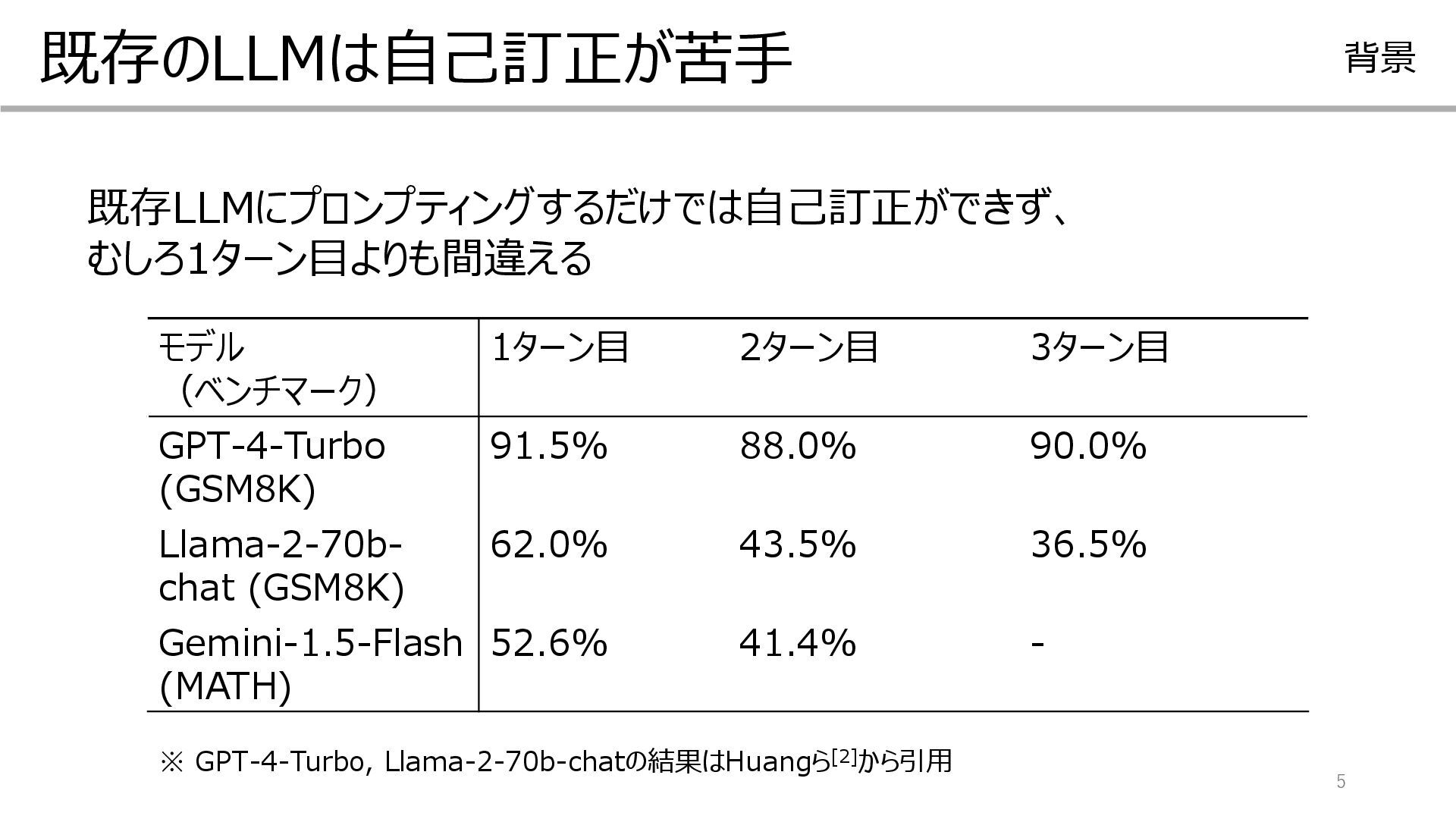
![3 LLMによる自己訂正 背景 自己訂正とは LLMが自身の出力の質を改善する能力 この論文では、1ターン目の出力を2ターン目で改善することを目指す なぜ必要か? LLMは必要な知識・能力があっても、1ターン目で誤答することが多い[1] 自己訂正によって誤答の修正が可能になれば、性能向上につながる 問題](https://files.speakerdeck.com/presentations/303add0b1f21471ab0efd5cd649ef927/slide_2.jpg){kind=link}
![4 LLMによる自己訂正 背景 自己訂正とは LLMが自身の出力の質を改善する能力 この論文では、1ターン目の出力を2ターン目で改善することを目指す なぜ必要か? LLMは必要な知識・能力があっても、1ターン目で誤答することが多い[1] 自己訂正によって誤答の修正が可能になれば、性能向上につながる 問題](https://files.speakerdeck.com/presentations/303add0b1f21471ab0efd5cd649ef927/slide_3.jpg){kind=link}
{kind=link}
![6 既存研究の問題点 背景 自己訂正能力の獲得に取り組んだ既存研究は存在するが ⚫ より高性能な教師モデルへのアクセス[3] ⚫ 人手・もしくは別のモデルが生成したデータへのアクセス[4] ⚫ 複数のモデルを訓練(例:生成モデル・検証モデル)[5]](https://files.speakerdeck.com/presentations/303add0b1f21471ab0efd5cd649ef927/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
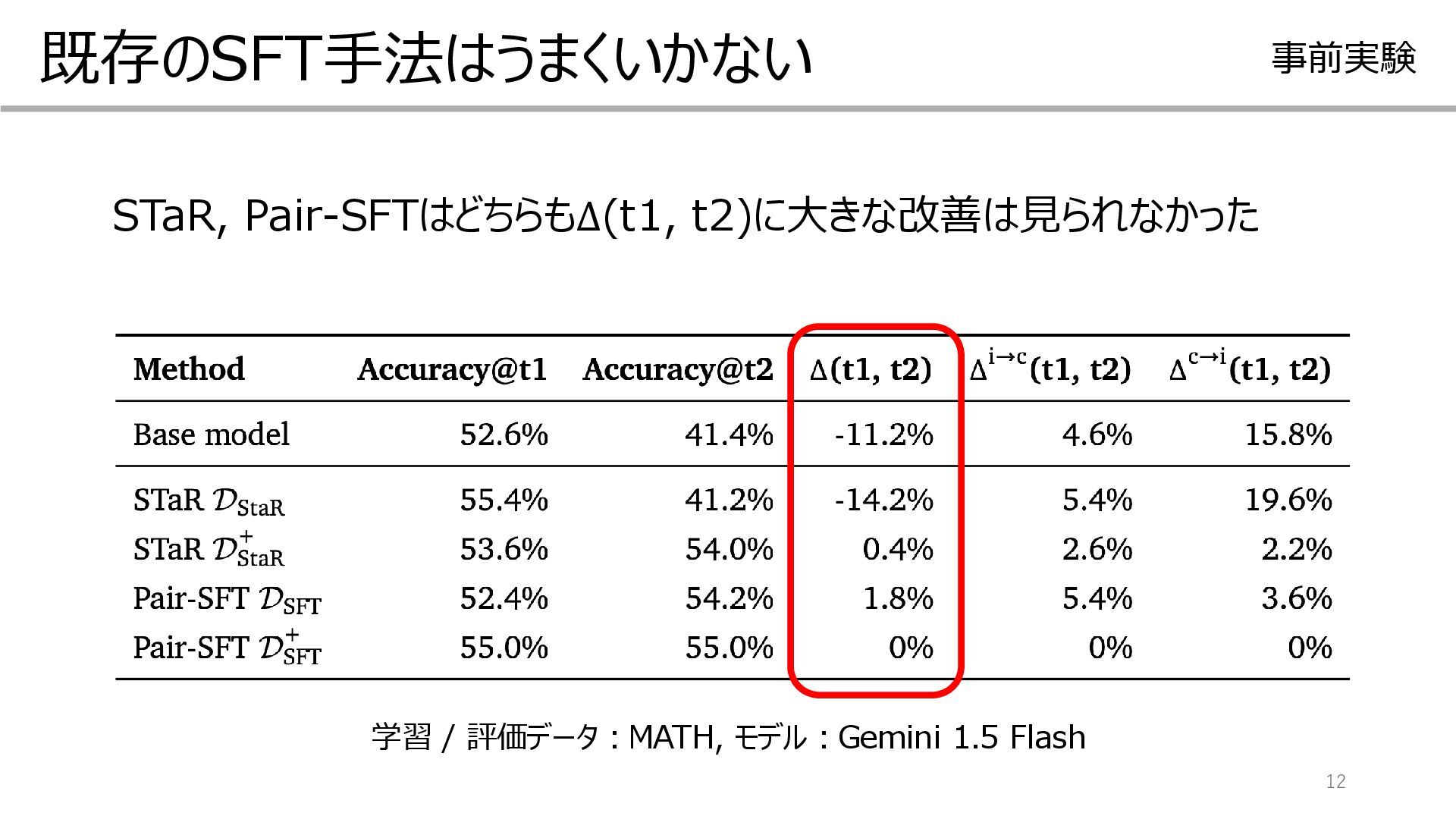
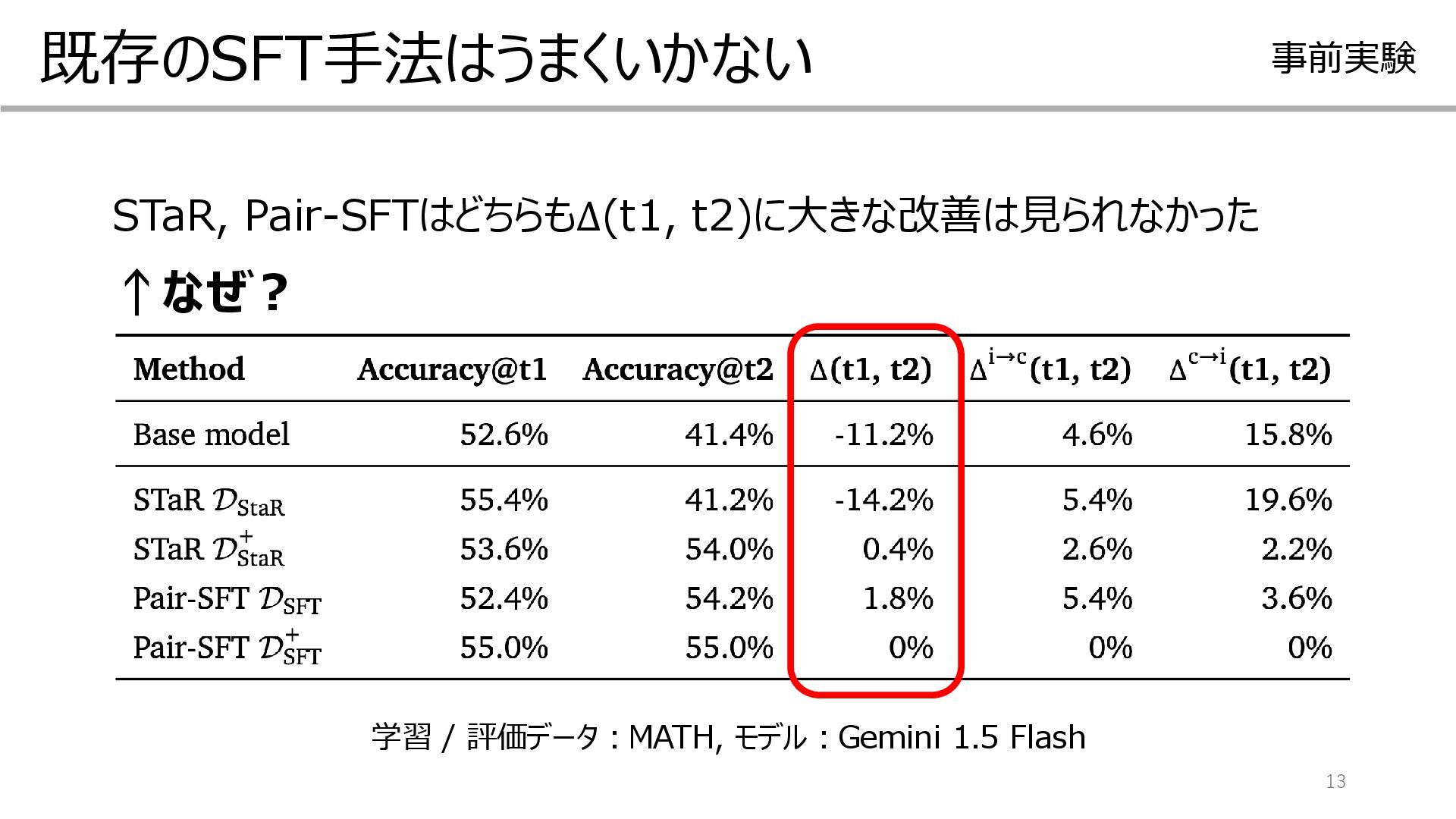
![回答(A) 11 既存のSFT手法を試す 事前実験 STaR[3] Pair-SFT※ 問題 ① 学習前のモデルに自己訂正をさせる ②](https://files.speakerdeck.com/presentations/303add0b1f21471ab0efd5cd649ef927/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
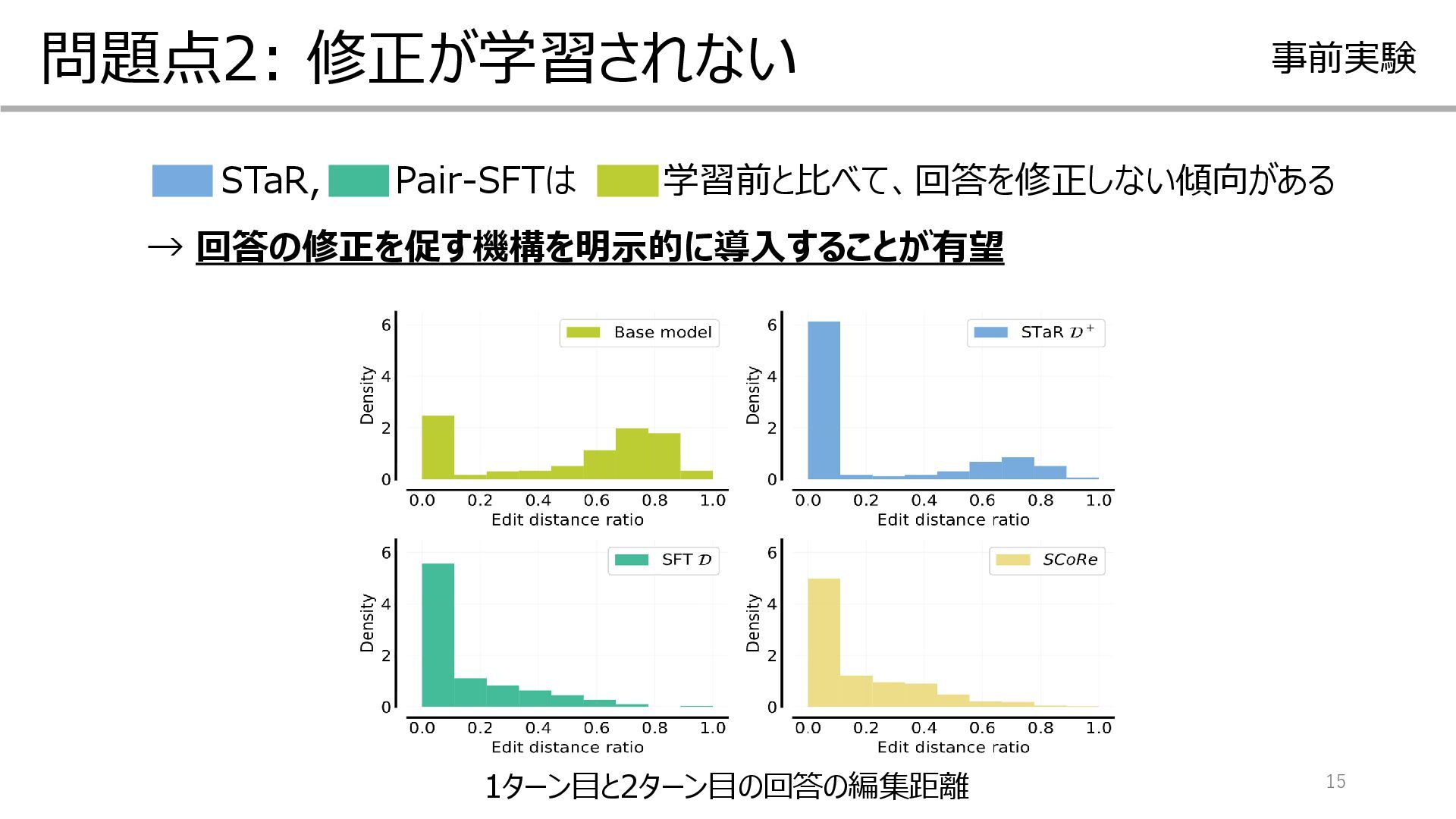{kind=link}
{kind=link}
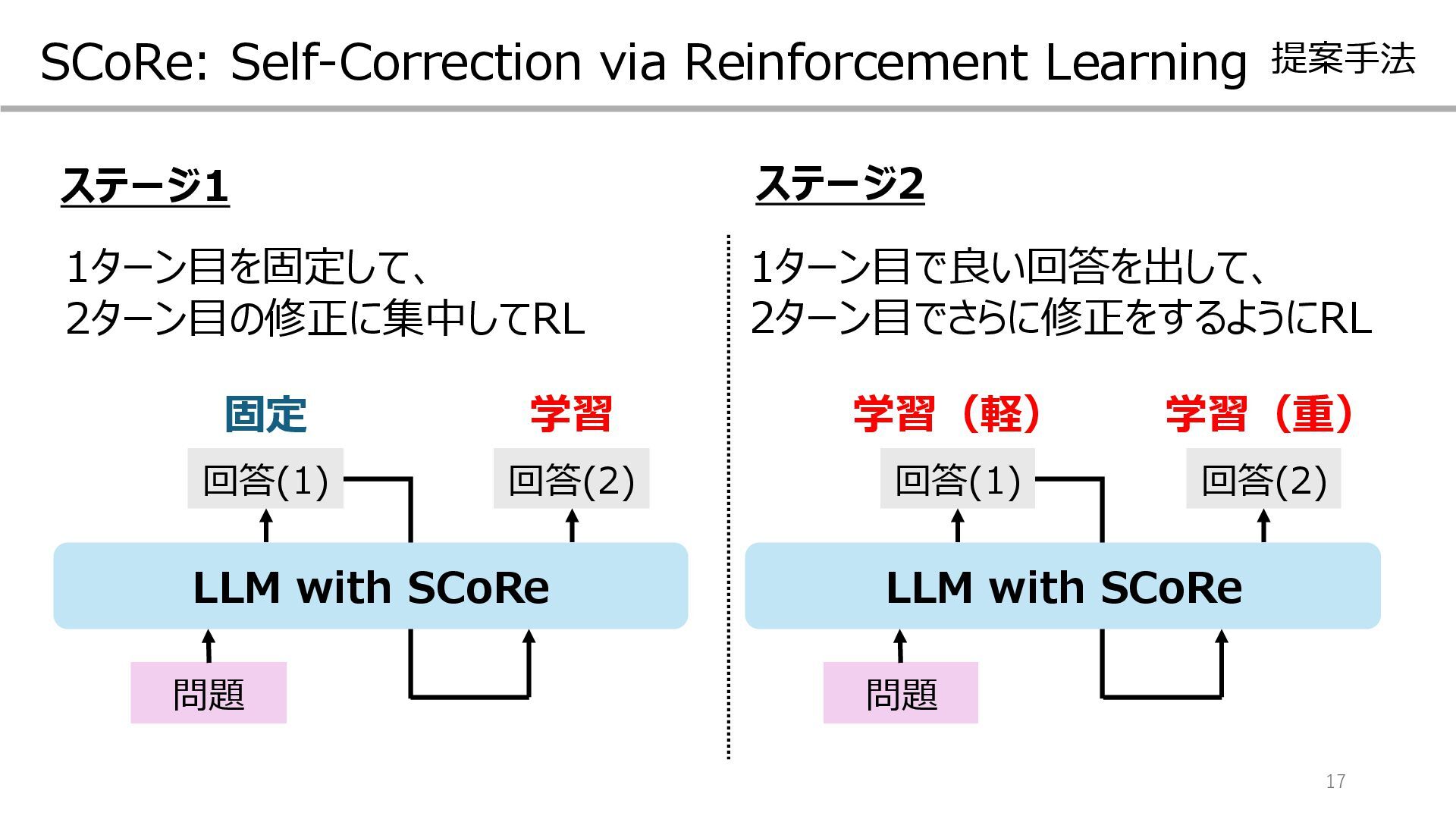{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
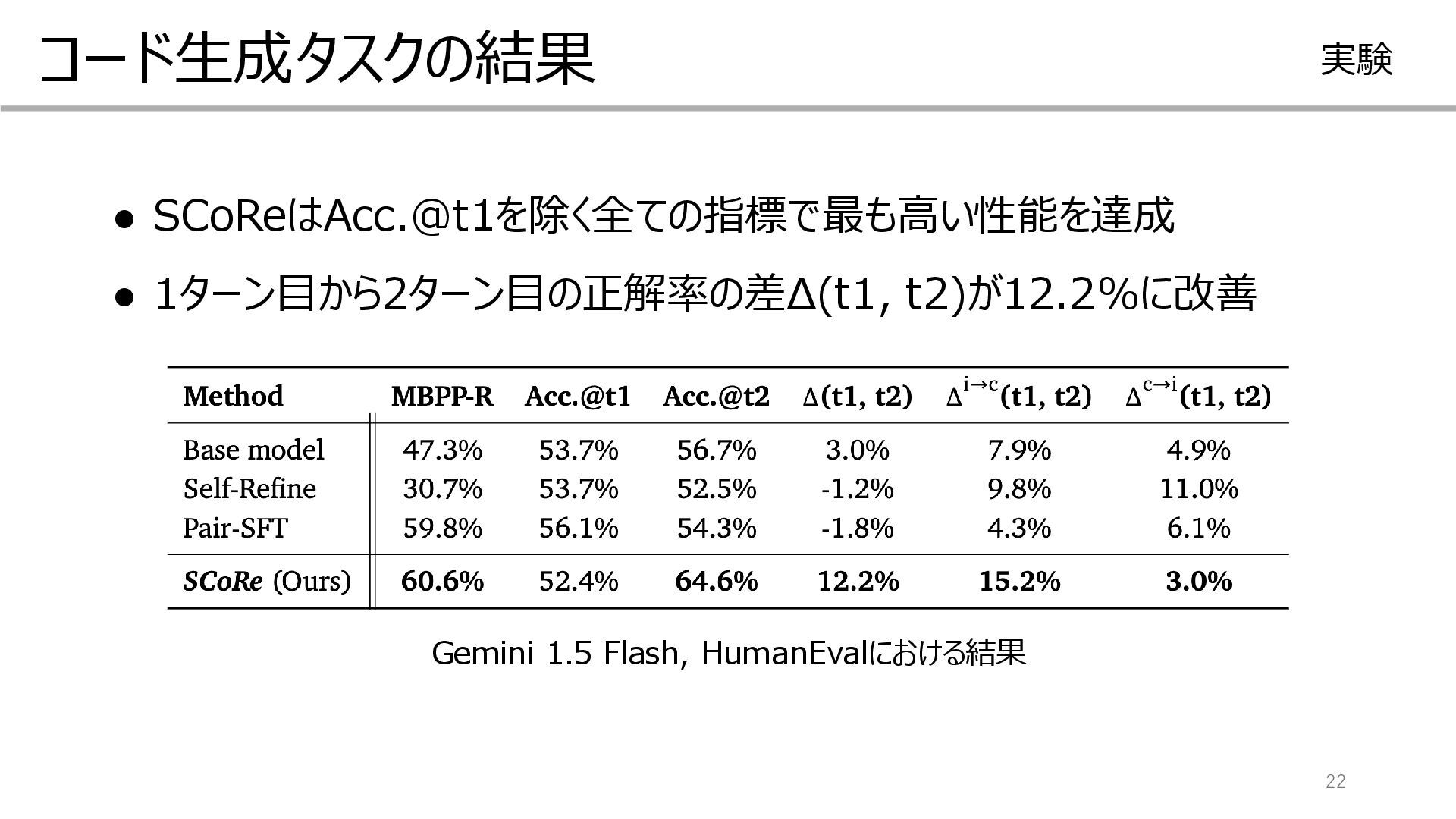{kind=link}
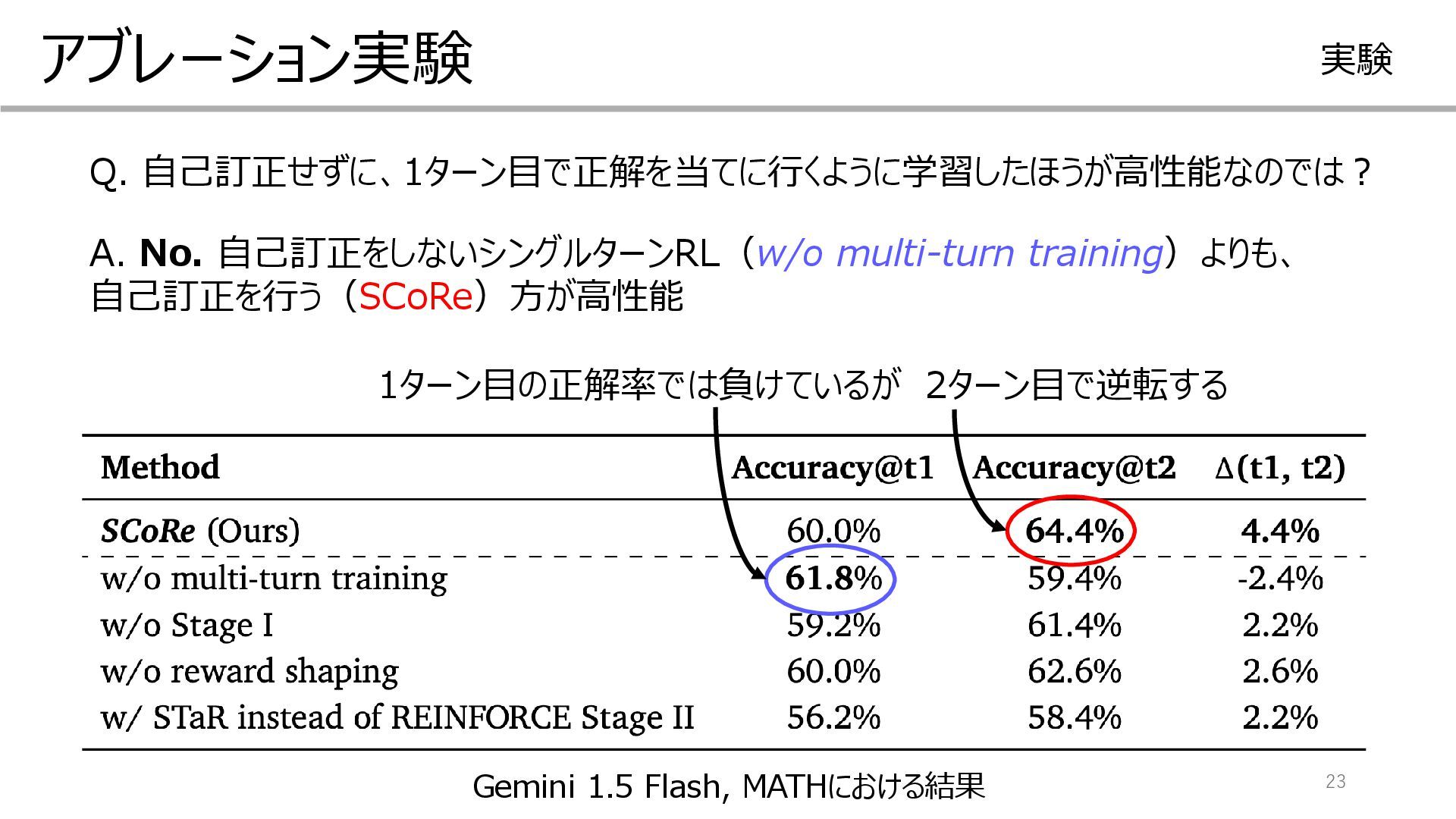{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![28 まとめ 参考文献 [1] Sohee Yang et al. Do Large](https://files.speakerdeck.com/presentations/303add0b1f21471ab0efd5cd649ef927/slide_27.jpg){kind=link}