Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigData-JAWS大石20211208_AQUA_.pdf
Search
Suguru Ohishi
December 08, 2021
910
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigData-JAWS大石20211208_AQUA_.pdf
Suguru Ohishi
December 08, 2021
More Decks by Suguru Ohishi
See All by Suguru Ohishi
ガンダム正史と宇宙世紀の真実_〜富野の意思と黒歴史の深淵〜
suguru0719
1
10
銀河英雄伝説_勉強会_2_イゼルローンフォートレス訪問記20201126.pdf
suguru0719
0
45
PCNW20250514(情シスはAIとどう向き合う?事例から学ぶ活用法)
suguru0719
0
190
なかい_かのってぃの誕生日を言い訳にした無差別ライトニングトークパーティー_超越境_LT20250312.pdf
suguru0719
0
69
なかい&かのってぃの誕生日を言い訳にした無差別ライトニングトークパーティー【超越境】銀河英雄伝説 艦船認識20250312
suguru0719
0
51
JBUG静岡#2プロジェクト管理勉強会宣伝LT
suguru0719
0
610
おかえり_Tech-in_AWS_20211213_全体公開大石.pdf
suguru0719
1
180
おかえり!Tech-in AWS 20211213 大石
suguru0719
0
210
セキュリティ入門とハッキング概説.pdf
suguru0719
0
310
Featured
See All Featured
For a Future-Friendly Web
brad_frost
183
10k
Paper Plane
katiecoart
PRO
2
52k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
560
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Amusing Abliteration
ianozsvald
1
240
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Scaling GitHub
holman
464
140k
Transcript
Redshift AQUA使ってみた… けど、コレはアンチパターン 2021/12/08 BigData-JAWS 勉強会#19 アイレット株式会社 ⼤⽯英 1/22
⾃⼰紹介 ⼤⽯ 英(Ohishi Suguru) アジャイル事業部 データ分析基盤セクション セクションリーダー アイレットに⼊社後、現在はデータ分析基盤の構 築・運⽤チームのチームリーダに 2/22
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 3/22
本⽇のアジェンダ 4/22 AQUA (Advanced Query Accelerator) for Amazon Redshift とは
検証検討 検証作業 検証結果 考察 蛇⾜w
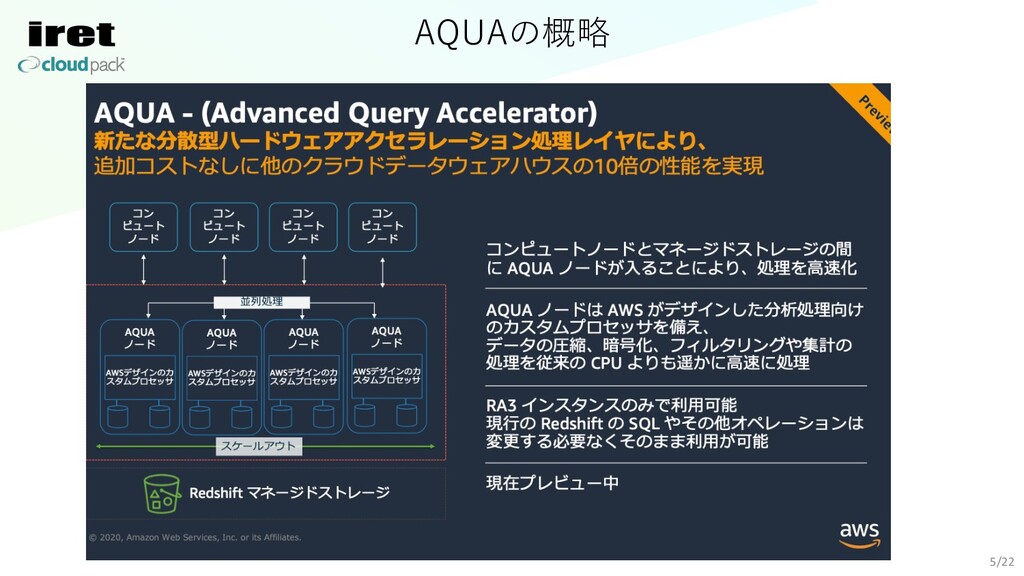
AQUAの概略 5/22
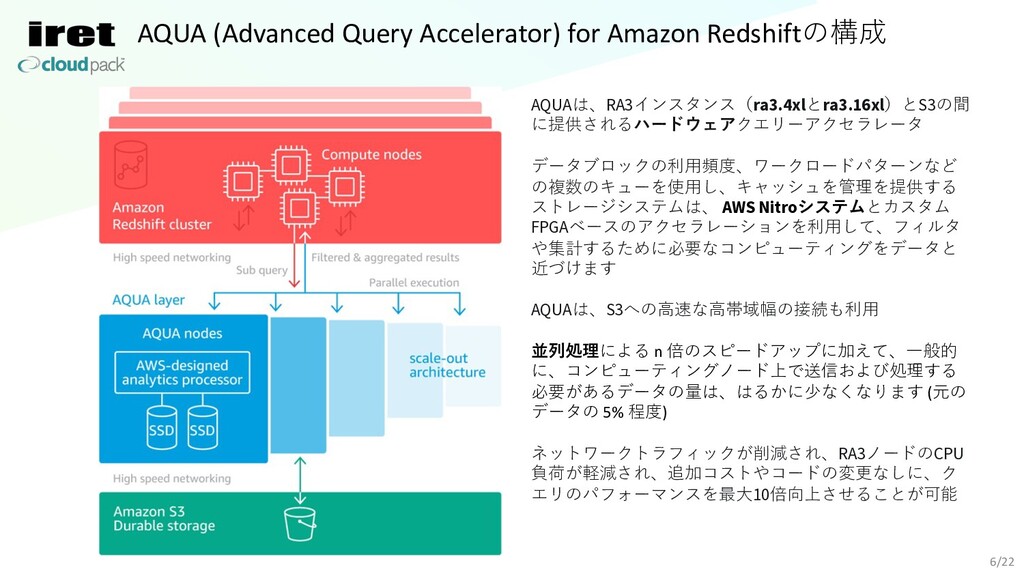
AQUA (Advanced Query Accelerator) for Amazon Redshiftの構成 6/22 AQUAは、RA3インスタンス(ra3.4xlとra3.16xl)とS3の間 に提供されるハードウェアクエリーアクセラレータ
データブロックの利⽤頻度、ワークロードパターンなど の複数のキューを使⽤し、キャッシュを管理を提供する ストレージシステムは、 AWS Nitroシステムとカスタム FPGAベースのアクセラレーションを利⽤して、フィルタ や集計するために必要なコンピューティングをデータと 近づけます AQUAは、S3への⾼速な⾼帯域幅の接続も利⽤ 並列処理による n 倍のスピードアップに加えて、⼀般的 に、コンピューティングノード上で送信および処理する 必要があるデータの量は、はるかに少なくなります (元の データの 5% 程度) ネットワークトラフィックが削減され、RA3ノードのCPU 負荷が軽減され、追加コストやコードの変更なしに、ク エリのパフォーマンスを最⼤10倍向上させることが可能
AQUA利⽤の注意点 7/22 ・AQUAはRA3インスタンスではデフォルトで選択/利⽤が可能 かつ、追加費⽤は不要 ・(AQUA利⽤に関する)設定値のデフォルトは”Automatic” ただし現時点ではアクティブ化されておらず、 ”Automatic”は”Turn Off”と同意でAQUAは機能しない その為、明⽰的に”Turn On”を指定する必要がある
ざっくりまとめると…以下の効果によるRedshiftの処理速度が期待される仕組み ・AWS Nitro Systemによる、I/O速度の向上による処理能⼒向上(RA3インスタンス) ・並列処理による、クエリ処理能⼒の向上
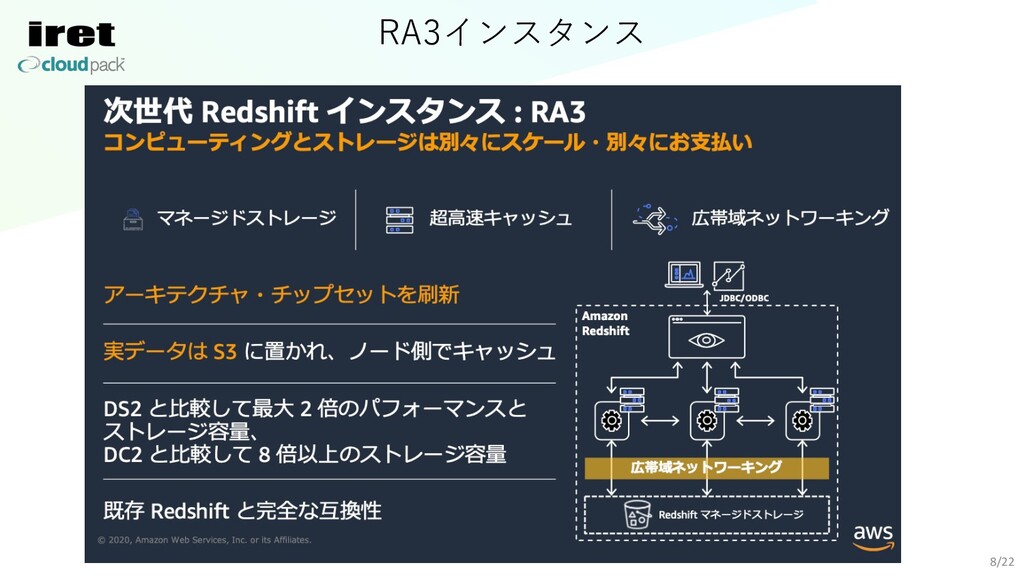
RA3インスタンス 8/22
RA3インスタンス 9/22
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 10/22
AQUA検証の経緯とか 11/22 話の発端は、⽇本で Advanced Query Accelerator (AQUA) for Amazon Redshift
がGAされた後 の5⽉の事(GAは4⽉) お客さん:最近AQUAってのが出たんだって? クエリが凄く早くなるって聞いたけど、ホント? ウチ :という話ですね〜 お客さん:御社で実績無い? ウチ :いや、流⽯にまだ無いですねぇ(^_^;) お客さん:なら試してみてよ 今のシステムもこの先速度向上考えなきゃならなくなるし ウチ :了解です〜 というざっくりした流れでAQUAの検証をする事になりました 結構カジュアルに⾊々チャレンジさせて下さるお客様 現在は“ClickHouse”というOSSのOLAP DBMSの検証もやってみたりしてます https://clickhouse.com/ このお客様ではEMRやRedshiftを利⽤されているので、Amazon Redshift Serverless とか Amazon EMR Serverless の検証リクエストもあったら⾯⽩いなぁと期待
検証検討 12/22 ノードタイプ検討 ・既存ノードタイプ 下記アップグレード検討表に記載 ・RA3 ノードタイプ コンピューティング性能とストレージを別々にサイジングでき、⽀払いも別 各ノードに⼤容量の⾼性能 SSD、⼤容量ローカル
SSD のサイズを超えた場合は、RMS (Redshift Management Storage) により⾃動的に Amazon S3 へオフロード ra3.4xlarge、ra3.16xlarge のマネージドストレージクォータは、128TB ストレージ、および⼿動スナップショットには別途費⽤がかかることに注意 ・RA3 ノードタイプへアップグレードする際の推奨事項 https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/working-with-clusters.html#rs-upgrading-to-ra3 料⾦/時間 説明 0.0261USD/GB RMS 料⾦、時間単位の使⽤量を⽉締め 既存の ノードタイプ 既存のノー ド数の範囲 推奨される 新しいノードタイプ アップグレードアクション dc2.8xlarge 2–15 ra3.4xlarge dc2.8xlarge の 1 つのノードごとに、ra3.4xlarge のノードを 2 つ作成 16–128 ra3.16xlarge dc2.8xlarge の 2 つのノードごとに、ra3.16xlarge のノードを 1 つ作成
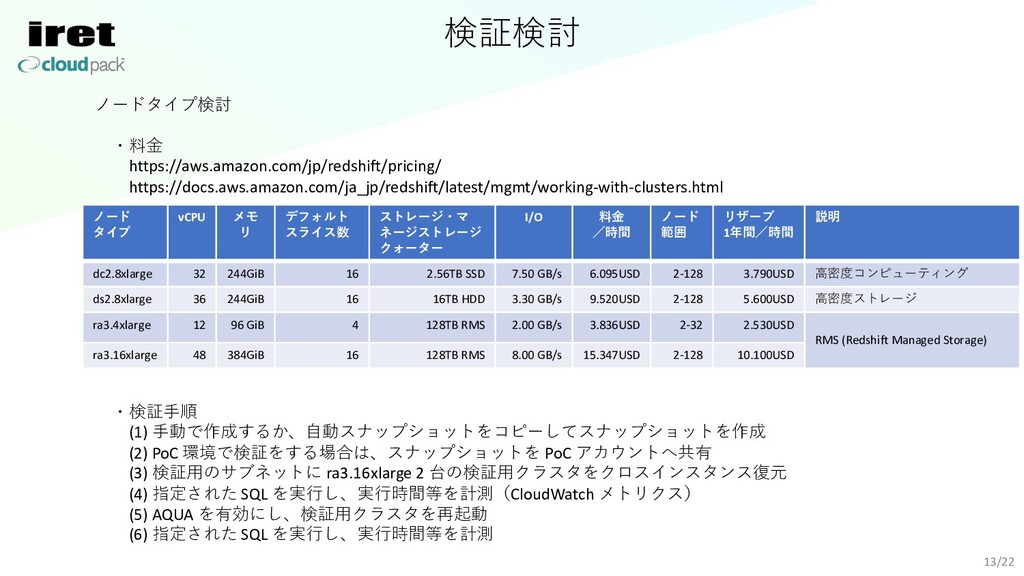
検証検討 13/22 ノードタイプ検討 ・料⾦ https://aws.amazon.com/jp/redshift/pricing/ https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/working-with-clusters.html ・検証⼿順 (1) ⼿動で作成するか、⾃動スナップショットをコピーしてスナップショットを作成 (2)
PoC 環境で検証をする場合は、スナップショットを PoC アカウントへ共有 (3) 検証⽤のサブネットに ra3.16xlarge 2 台の検証⽤クラスタをクロスインスタンス復元 (4) 指定された SQL を実⾏し、実⾏時間等を計測(CloudWatch メトリクス) (5) AQUA を有効にし、検証⽤クラスタを再起動 (6) 指定された SQL を実⾏し、実⾏時間等を計測 ノード タイプ vCPU メモ リ デフォルト スライス数 ストレージ・マ ネージストレージ クォーター I/O 料⾦ /時間 ノード 範囲 リザーブ 1年間/時間 説明 dc2.8xlarge 32 244GiB 16 2.56TB SSD 7.50 GB/s 6.095USD 2-128 3.790USD ⾼密度コンピューティング ds2.8xlarge 36 244GiB 16 16TB HDD 3.30 GB/s 9.520USD 2-128 5.600USD ⾼密度ストレージ ra3.4xlarge 12 96 GiB 4 128TB RMS 2.00 GB/s 3.836USD 2-32 2.530USD RMS (Redshift Managed Storage) ra3.16xlarge 48 384GiB 16 128TB RMS 8.00 GB/s 15.347USD 2-128 10.100USD
検証検討 14/22 AQUA検証検討 ・⼿順は、以下記事に沿って確認 https://aws.amazon.com/jp/blogs/news/new-aqua-advanced-query-accelerator-for-amazon-redshift/ AQUA を有効にした場合と無効にした場合の指定クエリ実⾏時間を⽐較する ・スナップショットからのクラスターの復元(クロスインスタンスの復元) https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/working-with-snapshots.html#working-with-snapshot-restore-cluster-from-snapshot ⼿動スナップショットを作成し、そのスナップショットから
Elastic-Resize 可能なクラスタへ復元する →確認事項 クラスタのバージョンが 1.0.10013 以降であること(1.0.26742:OK) 復元可能な設定 (ノードの数とノードの種類) は、元のクラスタ内のノード数と新しい クラスタのターゲットノードタイプによって決められるので事前に確認(ra3.16xlarge 2 台:OK) ⇒スナップショットはアカウント間で共有できるため、商⽤環境で作成したスナップショットを PoC 環境で復元し利⽤
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 15/22
検証作業 16/22 AQUA 検証 ・現在はdc2系を利⽤ ・5⽉31⽇(⽉) 23時50分に⼿動のスナップショット (6.2TB) を作成し、そのスナップショットをもとに ra3.16xlarge
2 台のクラスタ、現⾏同様の dc2.8xlarge 4 台のクラスタを作成 ・パファーマンス計測⼿順 コードコンパイル時間とリザルトキャッシュの影響を受けないようにして確認する (1) 初回実⾏時コードコンパイルが⾛っているため計測対象から外し、2回⽬以降の結果を使う (2)リザルトキャッシュをオフにする →show enable_result_cache_for_session; (現状の確認) set enable_result_cache_for_session = off; (設定⽅法) ⇒踏み台サーバーから psql コマンドを実⾏してクエリを実⾏するシェルを作成し、スクリプト からクエリ を実⾏して各クエリの実⾏時間を計測 Redshift のマネージメントコンソールを使⽤した場合は、キャッシュは ON の状態であるが、 セッションは、1クエリの実⾏毎に異なるのでそれでも良い? ・クエリ6は、2021-03-15 から 2021-03-25 期間が対象となっていたが、Parquet ファイルが作成 されたのが 2021-03-16 からだったため、対象期間を 2021-03-17 から 2021-03-27 に変更して実⾏
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 17/22
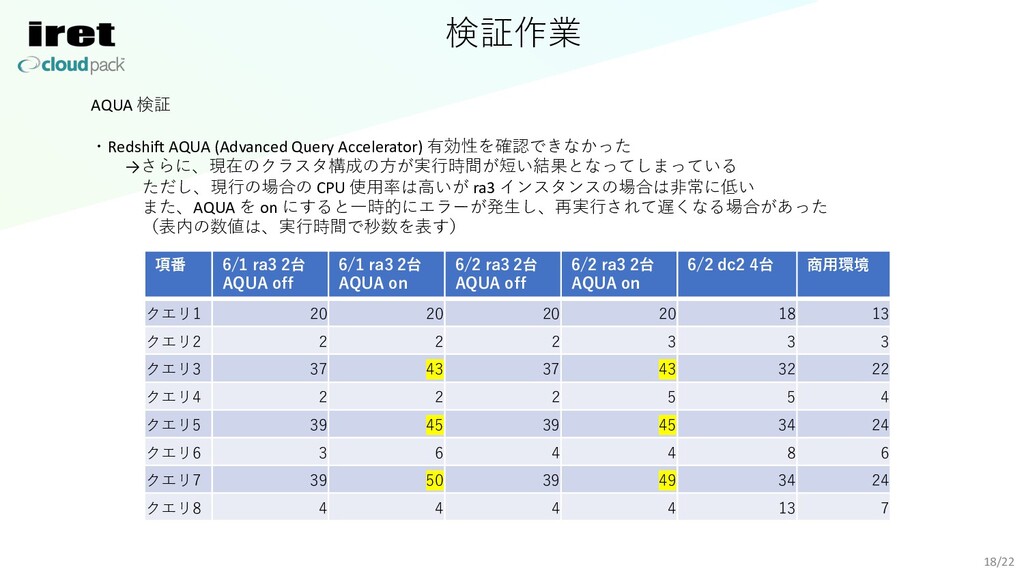
検証作業 18/22 AQUA 検証 ・Redshift AQUA (Advanced Query Accelerator) 有効性を確認できなかった
→さらに、現在のクラスタ構成の⽅が実⾏時間が短い結果となってしまっている ただし、現⾏の場合の CPU 使⽤率は⾼いが ra3 インスタンスの場合は⾮常に低い また、AQUA を on にすると⼀時的にエラーが発⽣し、再実⾏されて遅くなる場合があった (表内の数値は、実⾏時間で秒数を表す) 項番 6/1 ra3 2台 AQUA off 6/1 ra3 2台 AQUA on 6/2 ra3 2台 AQUA off 6/2 ra3 2台 AQUA on 6/2 dc2 4台 商⽤環境 クエリ1 20 20 20 20 18 13 クエリ2 2 2 2 3 3 3 クエリ3 37 43 37 43 32 22 クエリ4 2 2 2 5 5 4 クエリ5 39 45 39 45 34 24 クエリ6 3 6 4 4 8 6 クエリ7 39 50 39 49 34 24 クエリ8 4 4 4 4 13 7
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 19/22
考察 20/22 理由考察1 ・データ構造がAQUAに向いていない(いなかった) 検証で利⽤したデータが時系列で集積されたレコードが主である為、並列処理に向いていない 実データをそのまま利⽤したことがこの結果に結び付いたのであれば、AQUAの有効利⽤の為にはデータ構造⾃体も ⾒直す必要があると考えられる ・クエリがAQUAに向いていない(いなかった) ”AQUAは、現時点でLIKEやSIMILAR TOを特に⾼速化する”という仕組みである為、これらの命令句を使⽤しない場合、
効果が出ない可能性が⾼い INSERT、UPDATE、DELETE、CREATE TABLE AS、COPY、UNLOADおよびSELECT(述部なし)などの書き込みを実⾏する クエリは、現在サポートされていない 今後、AWSは追加のクエリのサポートを追加する予定 AQUAに向いていないデータ構造やクエリでAQUAを有効化した場合、分散処理化のオーバーヘッドにより処理速度が 低下するのではないか ・リザルトキャッシュを有効化していない事により、クエリのコンパイル時間が掛かってしまっているのではないか
考察 21/22 理由考察2 現時点では、クエリやワークロードによってはAQUAを使わない⽅がクエリが速くなることもあるので、AQUAのOn/Offを Redshiftが⾃動判定できるAutomatic(デフォルト)が使えるようになることが望まれる (現時点では、設定は可能ではあるが実態は”off”扱いとなる) 【AWS公式より】 関連クエリ – AQUA
は、LIKE 述語と SIMILAR_TO 述語で⼤規模なスキャン、集計、およびフィルタリングを実⾏するクエ リで最⼤ 10 倍のパフォーマンスを実現するよう設計されています。今後、その他のクエリのサポートが追加される予定 です 今回の検証では、データやDBの最適化、SQLの⾒直し等は⾏っていません 素のままAQUAを有効にした場合、速度の向上が⾒られるか否かを単純に確認したところで終了しています
本⽇のアジェンダ AQUA (Advanced Query Accelerator) for Amazon Redshift とは 検証検討
検証作業 検証結果 考察 蛇⾜w 22/22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}