Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Glue DataBrewでデータを クリーニング、加工してみよう
Search
suto
October 07, 2021
10k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Glue DataBrewでデータを クリーニング、加工してみよう
Developers.IO 2021 Decade で発表した資料です
suto
October 07, 2021
More Decks by suto
See All by suto
モダンデータスタック (MDS) の話とデータ分析が起こすビジネス変革
sutotakeshi
0
1.6k
DevelopersIO2023「Amazon DataZoneを触ってみた」
sutotakeshi
0
1.8k
re:Growth2022「Analytics系アップデートまとめ」
sutotakeshi
0
880
OSSデータカタログツール「DataHub」を触ってみた
sutotakeshi
0
6.3k
Featured
See All Featured
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
The SEO identity crisis: Don't let AI make you average
varn
0
520
WENDY [Excerpt]
tessaabrams
11
39k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4.1k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Evolving SEO for Evolving Search Engines
ryanjones
0
250
AI: The stuff that nobody shows you
jnunemaker
PRO
9
860
A Tale of Four Properties
chriscoyier
163
24k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
480
Transcript
Glue DataBrewでデータを クリーニング、加⼯してみよう 2021/10/7 データアナリティクス事業本部 須藤 健志
2 ⾃⼰紹介 須藤 健志(suto takeshi) 所属 データアナリティクス事業本部 『データ分析基盤や機械学習基盤のコンサル・構築を担当』 略歴 通信事業会社のNWエンジニア→メーカー系SIer
→クラスメソッドJoin(2020年4⽉) 好きなAWSサービス AWS CDK、Glue DataBrew、SageMaker
3 アジェンダ • はじめに • Glue Databrewの概要 • Glue Databrewの機能と特徴
• Glue Databrewの使いどころ • デモ • まとめ
4 はじめに データ分析・機械学習の前に⾏う 「データクレンジング」
5 はじめに •こんなことありませんか︖ • 誤記や表記ゆれがあり前処理がうまくいかない • 重複しているデータがある、⽋損値がある • エラーが発⽣してデータを取り込めない
6 はじめに データのクレンジングが必要 ⽋損の修正 重複データの削除 正規化・標準化 無関係なデータの削除や マスキング
7 はじめに しかしデータクレンジングには 時間とコストがかかる • ワークフローの構築とその⾃動化 • システム間で⼤容量データの移動
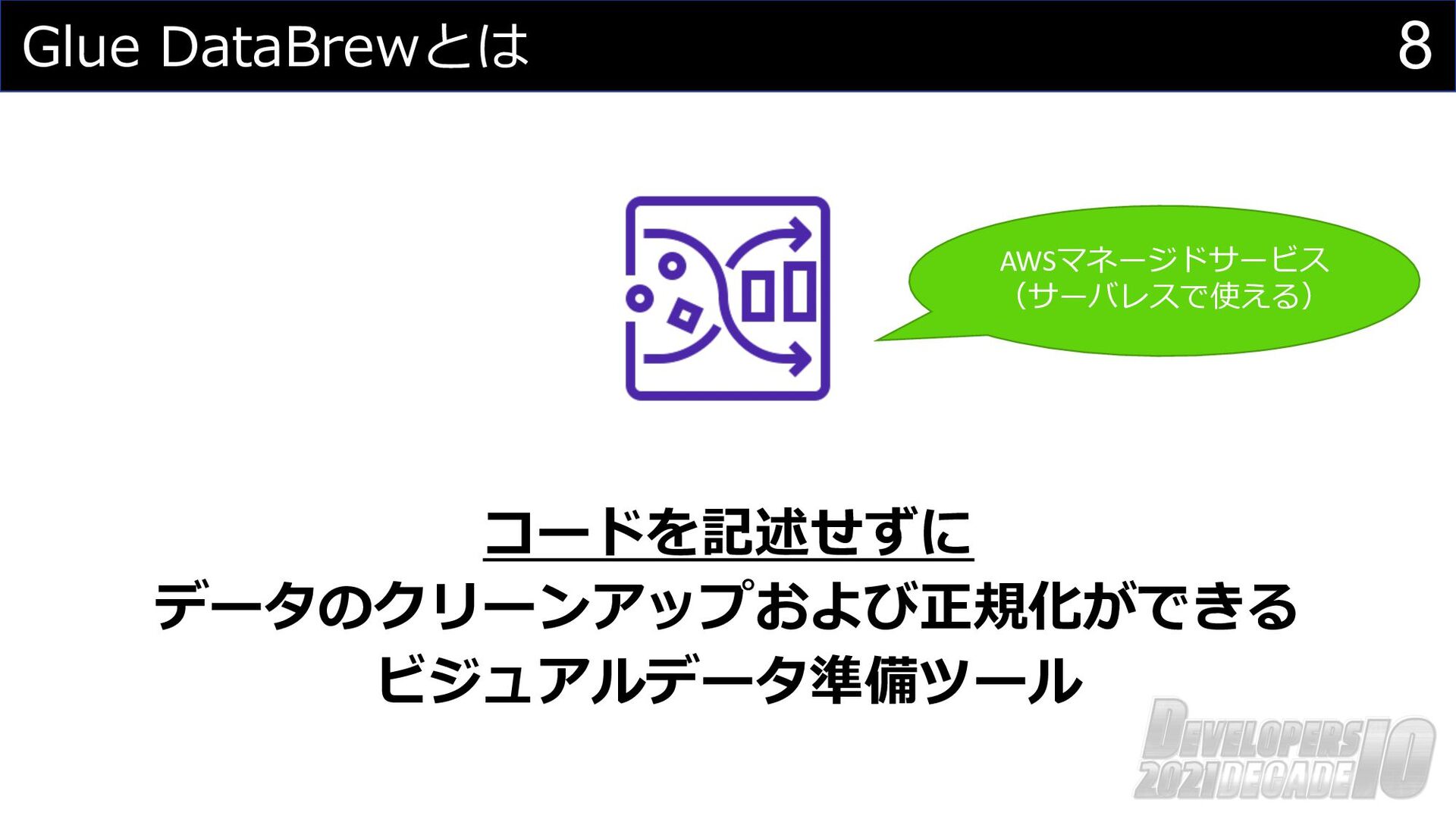
8 Glue DataBrewとは コードを記述せずに データのクリーンアップおよび正規化ができる ビジュアルデータ準備ツール AWSマネージドサービス (サーバレスで使える)
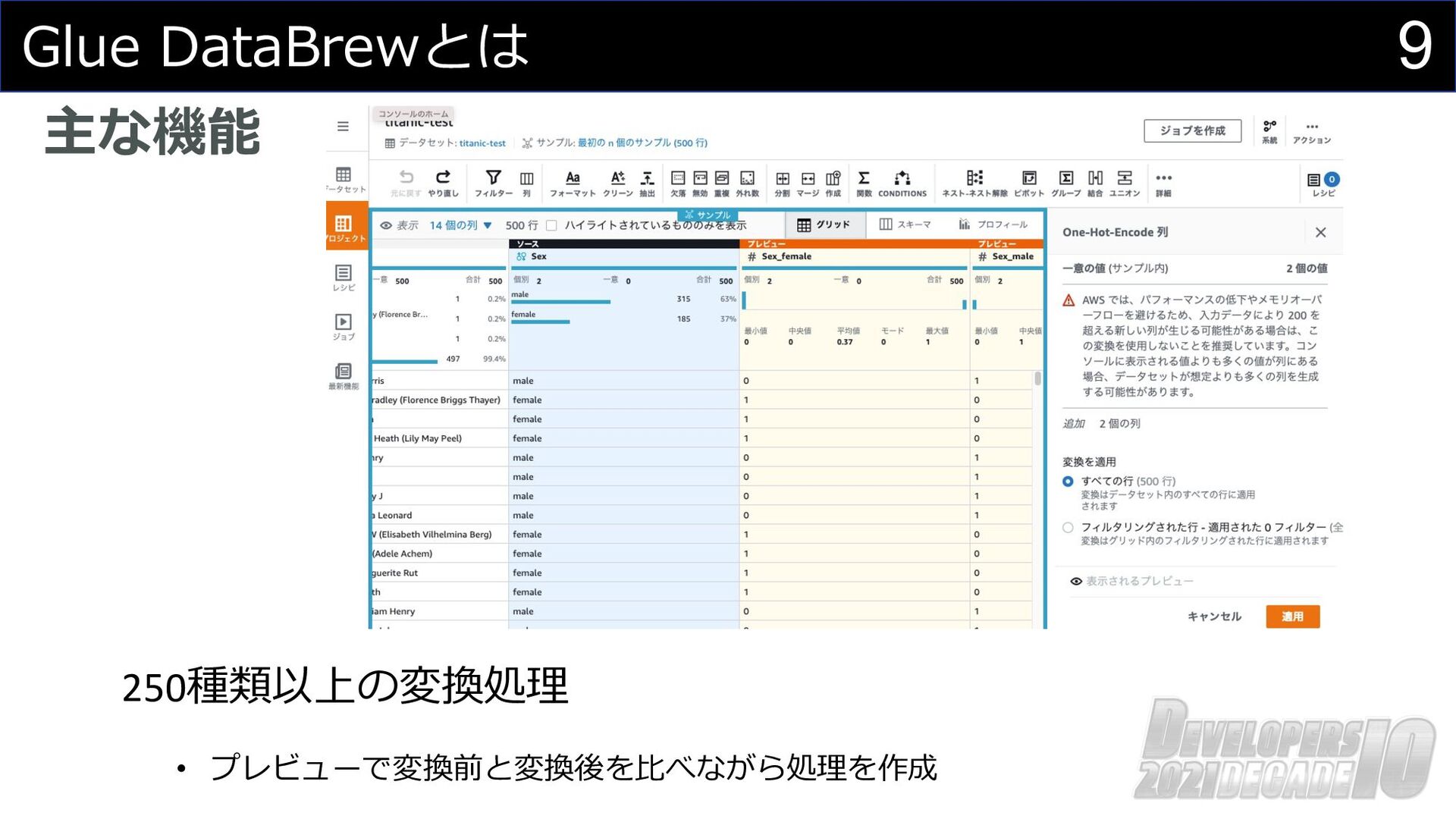
9 Glue DataBrewとは 主な機能 250種類以上の変換処理 • プレビューで変換前と変換後を⽐べながら処理を作成
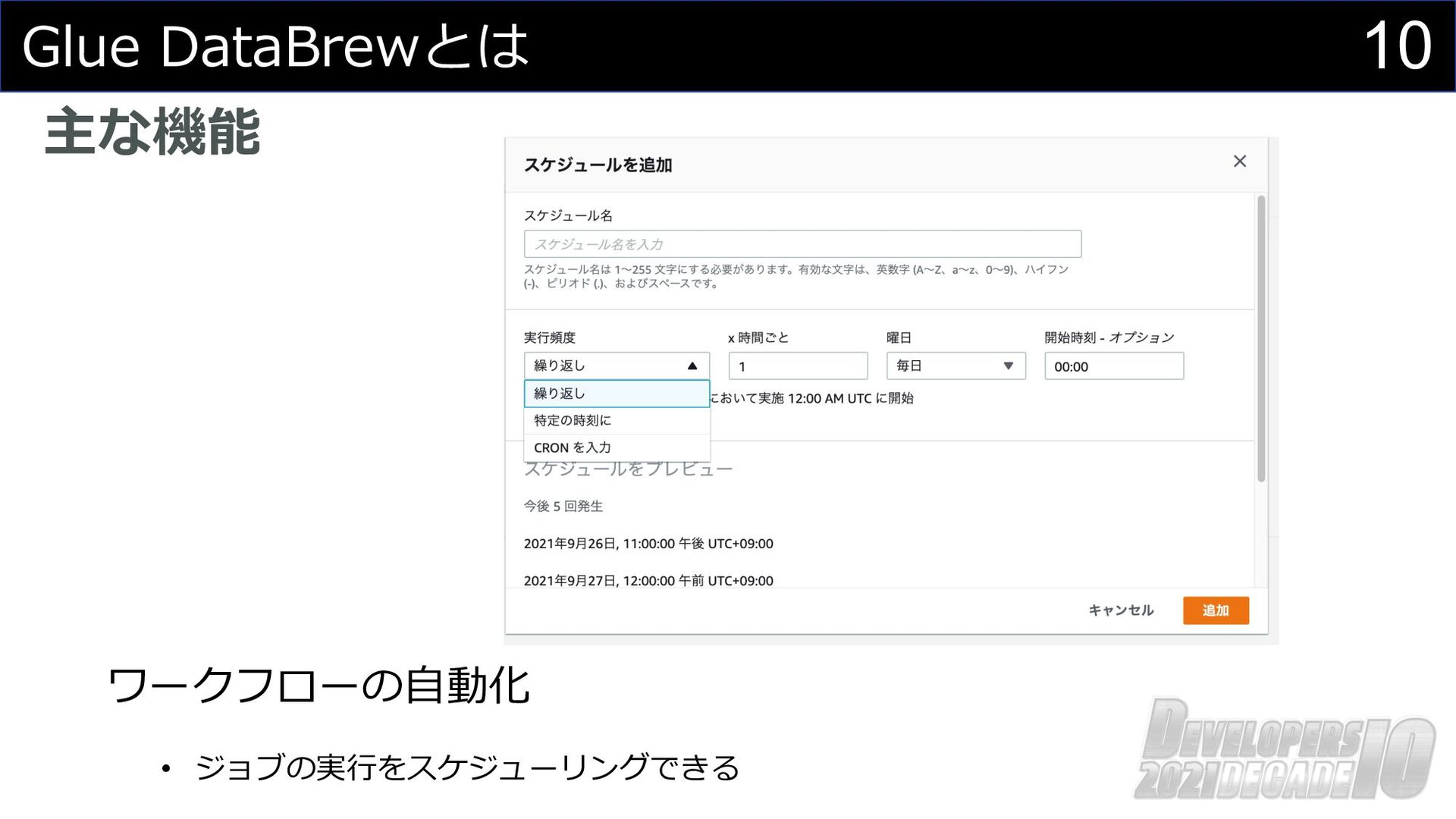
10 Glue DataBrewとは 主な機能 ワークフローの⾃動化 • ジョブの実⾏をスケジューリングできる
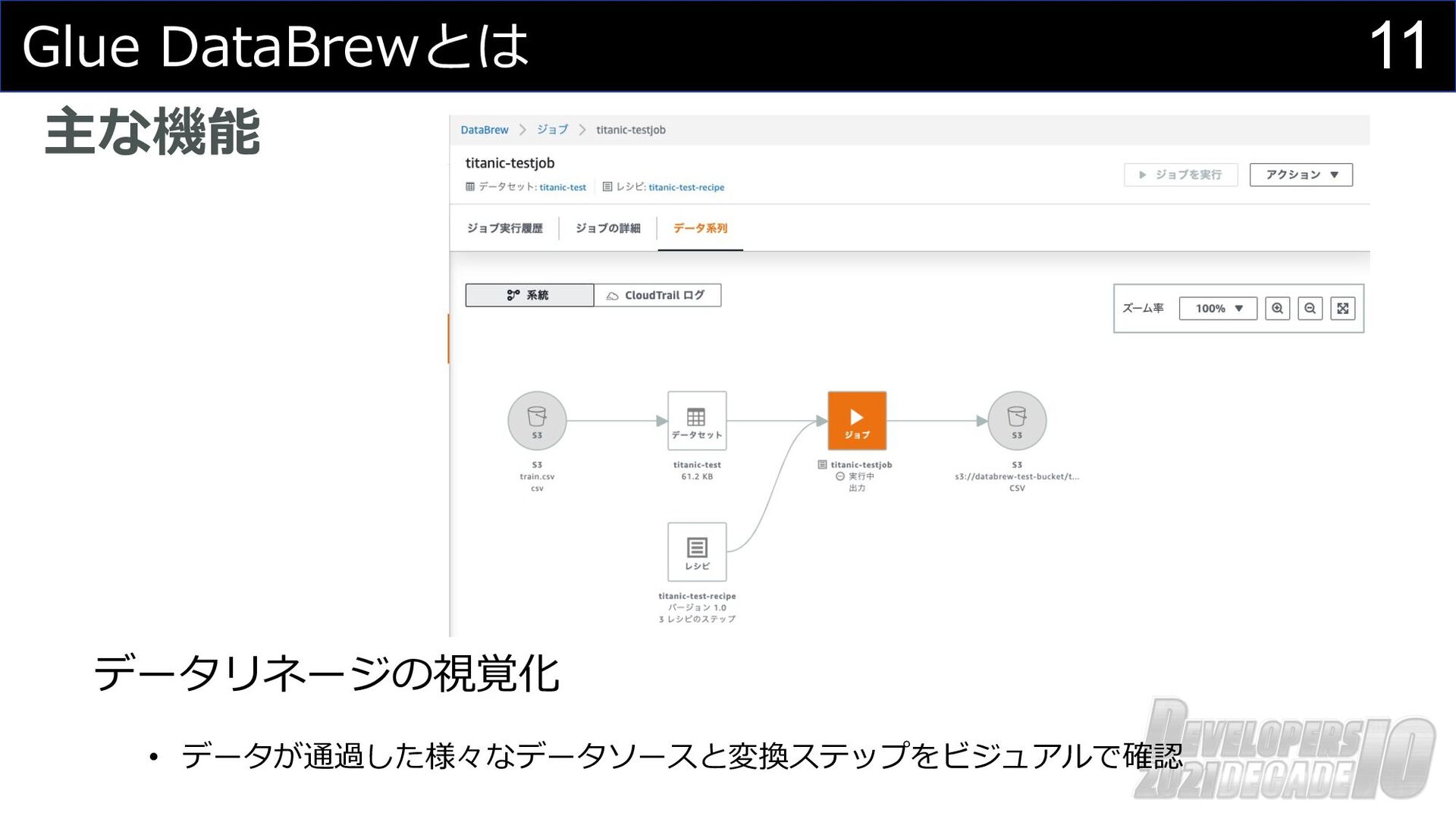
11 Glue DataBrewとは 主な機能 データリネージの視覚化 • データが通過した様々なデータソースと変換ステップをビジュアルで確認
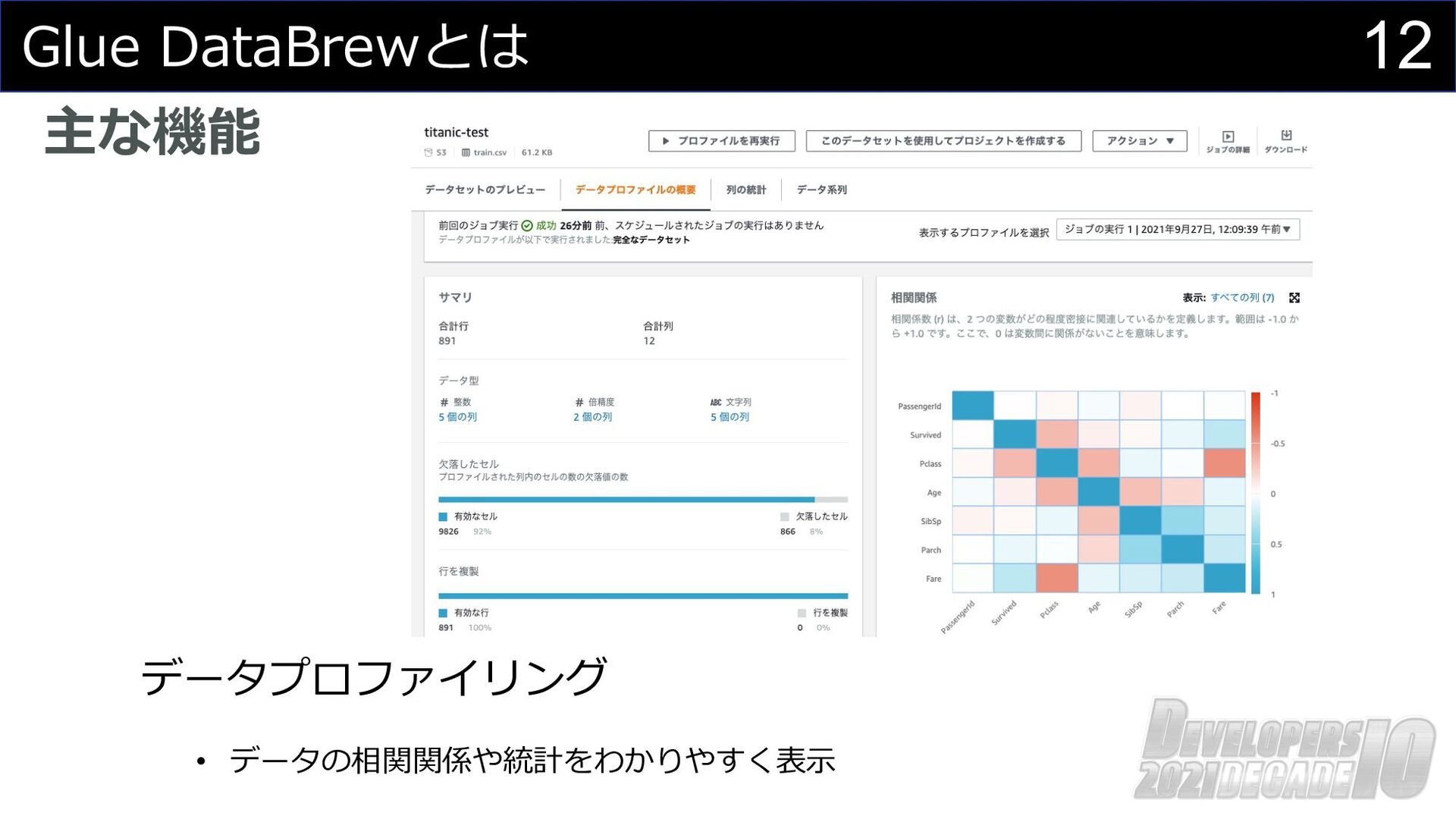
12 Glue DataBrewとは 主な機能 データプロファイリング • データの相関関係や統計をわかりやすく表⽰
13 Glue DataBrewとは サポートしているファイルタイプ 【⼊⼒ファイル】 • CSV • Parquet •
Json • Excel 【区切り⽂字】 • カンマ(,) • コロン(:) • セミコロン(:) • パイプ(|) • タブ(¥t) • キャレット(^) • バックスラッシュ(\) • スペース 【圧縮タイプ】 • なし • Snappy • Gzip • LZ4 • Bzip2 • Deflate • Brotli 【出⼒ファイル】 • CSV • Parquet • Glue Parquet • AVRO • ORC • XML • Json • Tableau Hyper
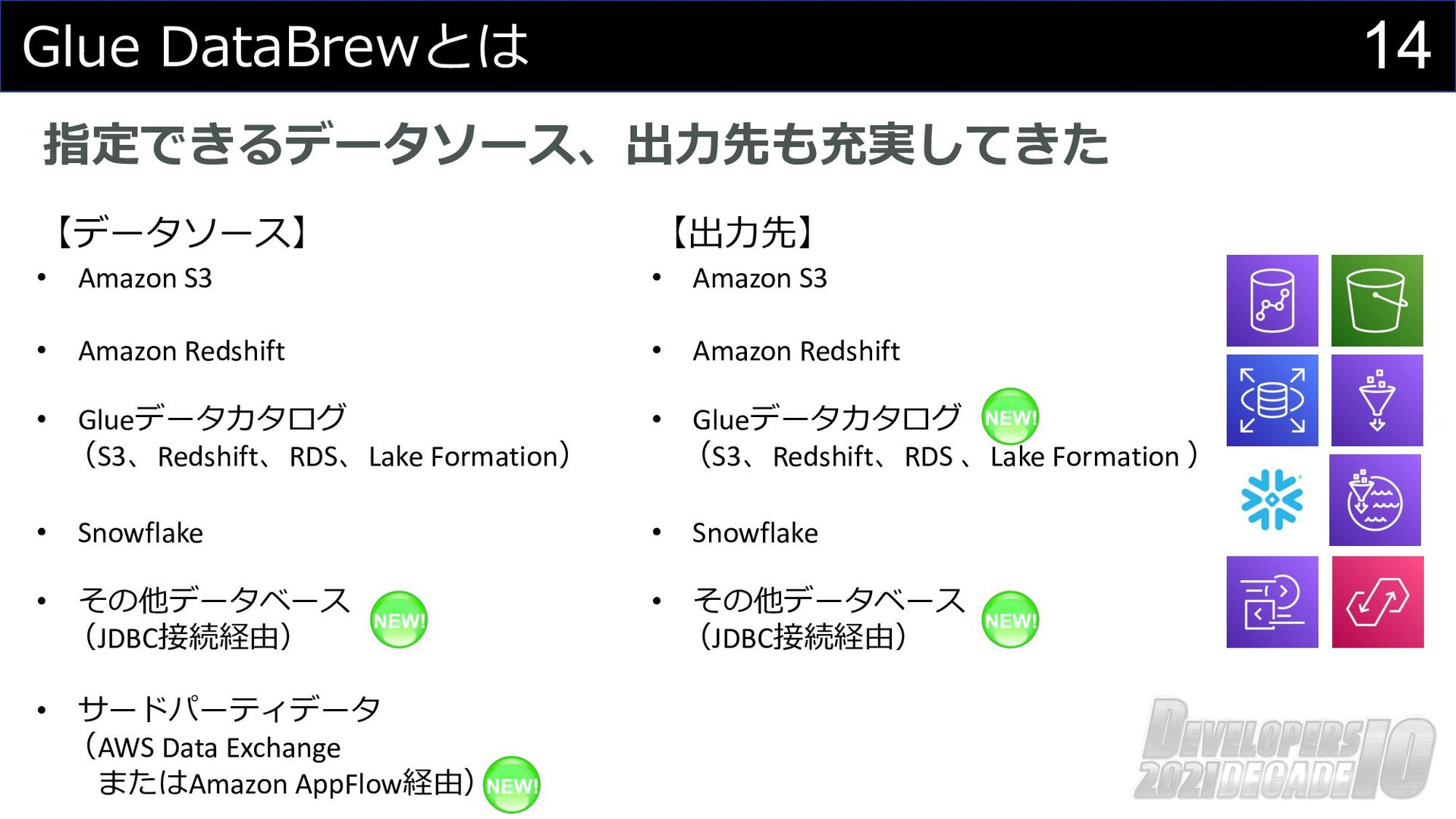
14 Glue DataBrewとは 指定できるデータソース、出⼒先も充実してきた 【データソース】 • Amazon S3 • Amazon
Redshift • Glueデータカタログ (S3、Redshift、RDS、Lake Formation) • Snowflake • その他データベース (JDBC接続経由) • サードパーティデータ (AWS Data Exchange またはAmazon AppFlow経由) 【出⼒先】 • Amazon S3 • Amazon Redshift • Glueデータカタログ (S3、Redshift、RDS 、Lake Formation ) • Snowflake • その他データベース (JDBC接続経由)
15 Glue DataBrewの料⾦ インタラクティブセッション(1.0$/30分) • プロジェクト画⾯を開くとセッション開始 • 未操作の時間が続けば⾃動でサスペンド • はじめてDataBrewを使う場合、最初の40セッションは無償
ジョブ実⾏(0.48$/ノード/時間) • ジョブ実⾏に使⽤されたノード数に基づいて1時間ごとに課⾦ • デフォルトでは各ジョブに5ノード割り当て • 1ノード4vCPUs、16GBメモリ
16 Glue DataBrewの使いどころ 主なユースケース • データをアドホックに探索して BIレポートやデータマートの作成に向けた策定 • 定常的かつ簡単なデータクリーニング処理を⾃動化したい •
データ準備処理のためのパイプラインを コーディングレスで構築したい
17 Glue DataBrewの使いどころ (技術的に可能だが)DataBrewには向かないケース • 複雑なETL処理 →実現に膨⼤なステップ数となるため • 機械学習における特徴量計算 •
データ分析における複数テーブルからの統計処理 →エンジニアからすればコード開発した⽅がラク • データ前処理⼯程を1つのサーバ内で⼀貫して素早く処理したい • Glue Databrewジョブの実⾏完了には時間がかかる • 同じ処理をコードで実⾏した⽅が早い
18 ここから実際の画⾯でデモをやっていきます 内容︓DataBrewプロジェクト作成〜レシピ作成〜ジョブ実⾏をやってみよう 使⽤するデータ︓Titanicの機械学習⽤データ (以下URLからダウンロードして、S3バケットに保存した状態からスタートします) https://www.kaggle.com/c/titanic/data
19 まとめ データクリーニング、正規化に使えるGlue DataBrew • サーバレスかつコードを書かずにデータ処理のジョブを作成で きるので構築に⼿間がかからない • プレビューで変換前/後を確認しながら様々な処理ができる •
データをアドホックに探索しながらワークフローを作るのに有 ⽤だが、複雑なETL処理の実装には向かない
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}