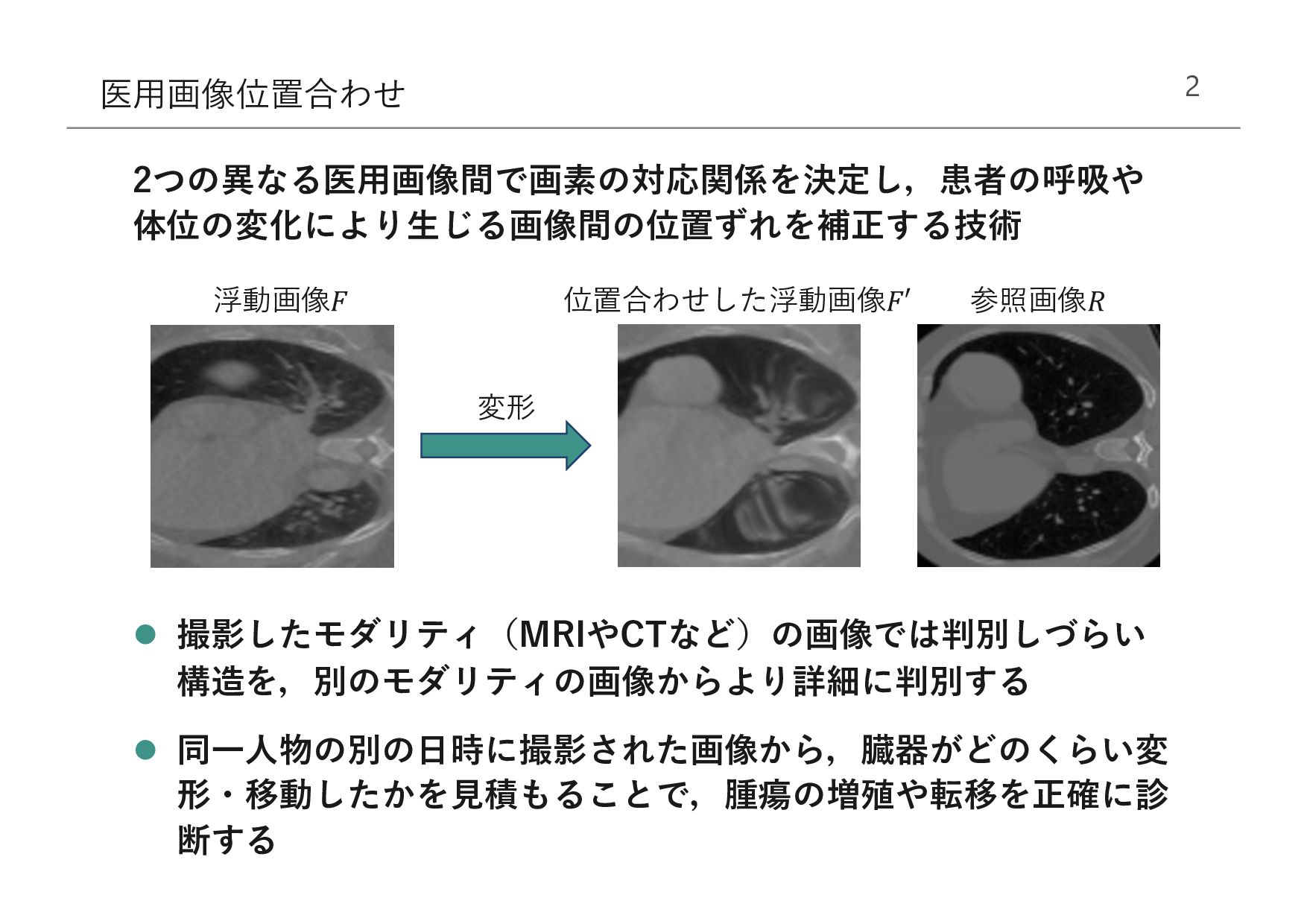
教師なし深層学習による位置合わせ[2] 浮動画像と参照画像間の類似度メトリクスを⽤いて学習する 類似度メトリクスがモダリティに依存するため,マルチモダリティ 間の位置合わせに失敗する l 相互情報量を⽤いた位置合わせ[3] モダリティへの依存が⼩さい類似度メトリクスであり,マルチモダ リティ間の位置合わせに有効 ⼤域的な指標であるため,物体の周辺構造を考慮しない [1] Xi Cheng, Li Zhang, and Yefeng Zheng. Deep similarity learning for multimodal medical images. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, pp. 1‒5, April 2016. [2] Guha Balakrishnan, Amy Zhao, Mert R Sabuncu, John Guttag, and Adrian V Dalca. An unsupervised learning model for deformable medical image registration. In Proceedings of the IEEE Conf. Computer Vision and Pattern Recognition, pp. 9252‒9260, 2018. [3] Josien PW Pluim, JB Antoine Maintz, and Max A Viergever. Mutual-informationbased registration of medical images: a survey. IEEE Trans. Medical Imaging, Vol. 22, No. 8, pp. 986‒1004, 2003.
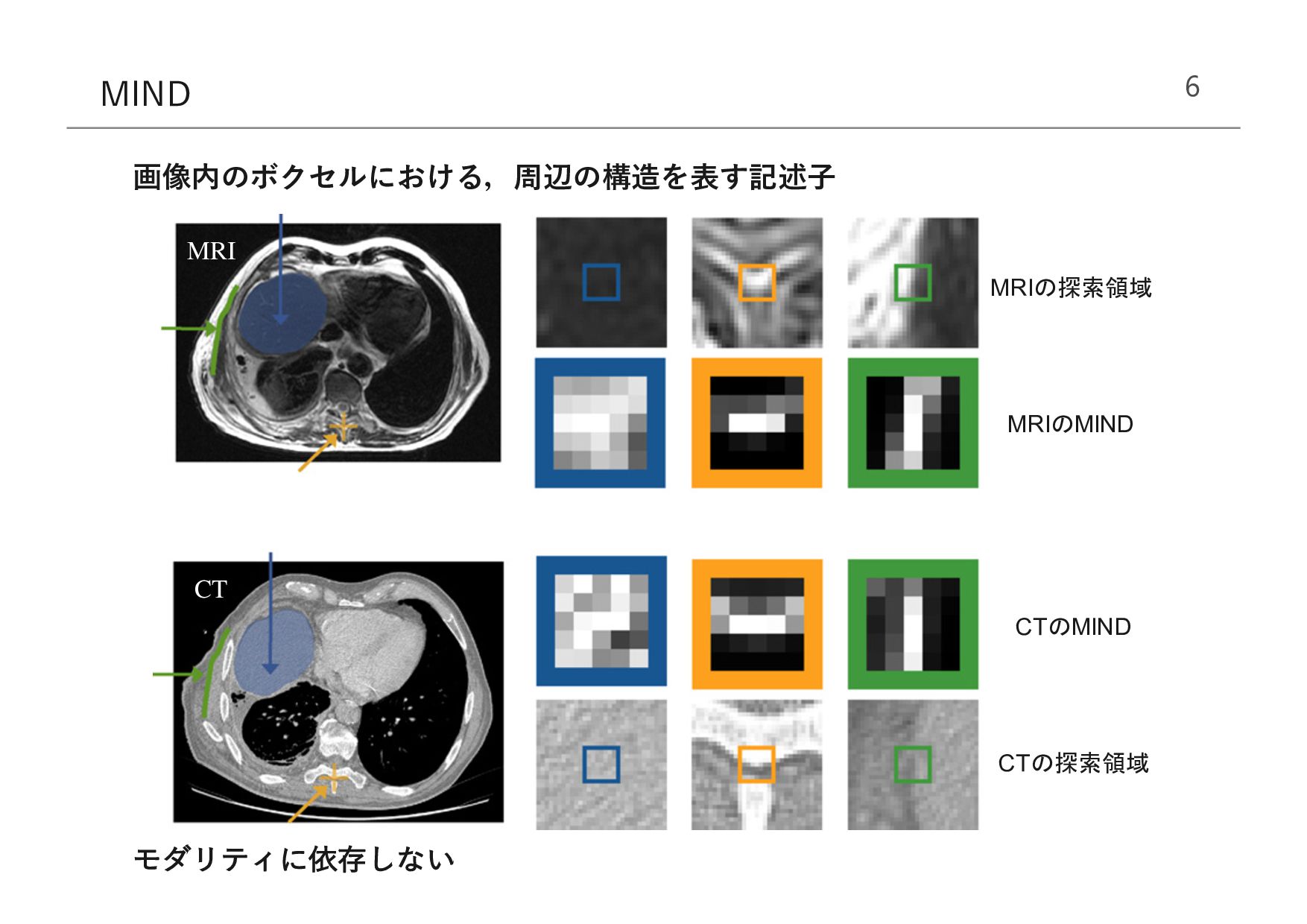
intensities with search region CT intensities with search region MIND for MRI MIND for CT L2 norm ed concept for the use of MIND for multimodal registration. MIND is calculated in a dense manner in CT and MRI. Three exemplary l s: homogenous intensities (liver), corner points at one vertebra and image gradients at the boundary between fat and non-fa M.P. Heinrich et al. / Medical Image Analysis 16 (2012) 1423–1435 モダリティに依存しない
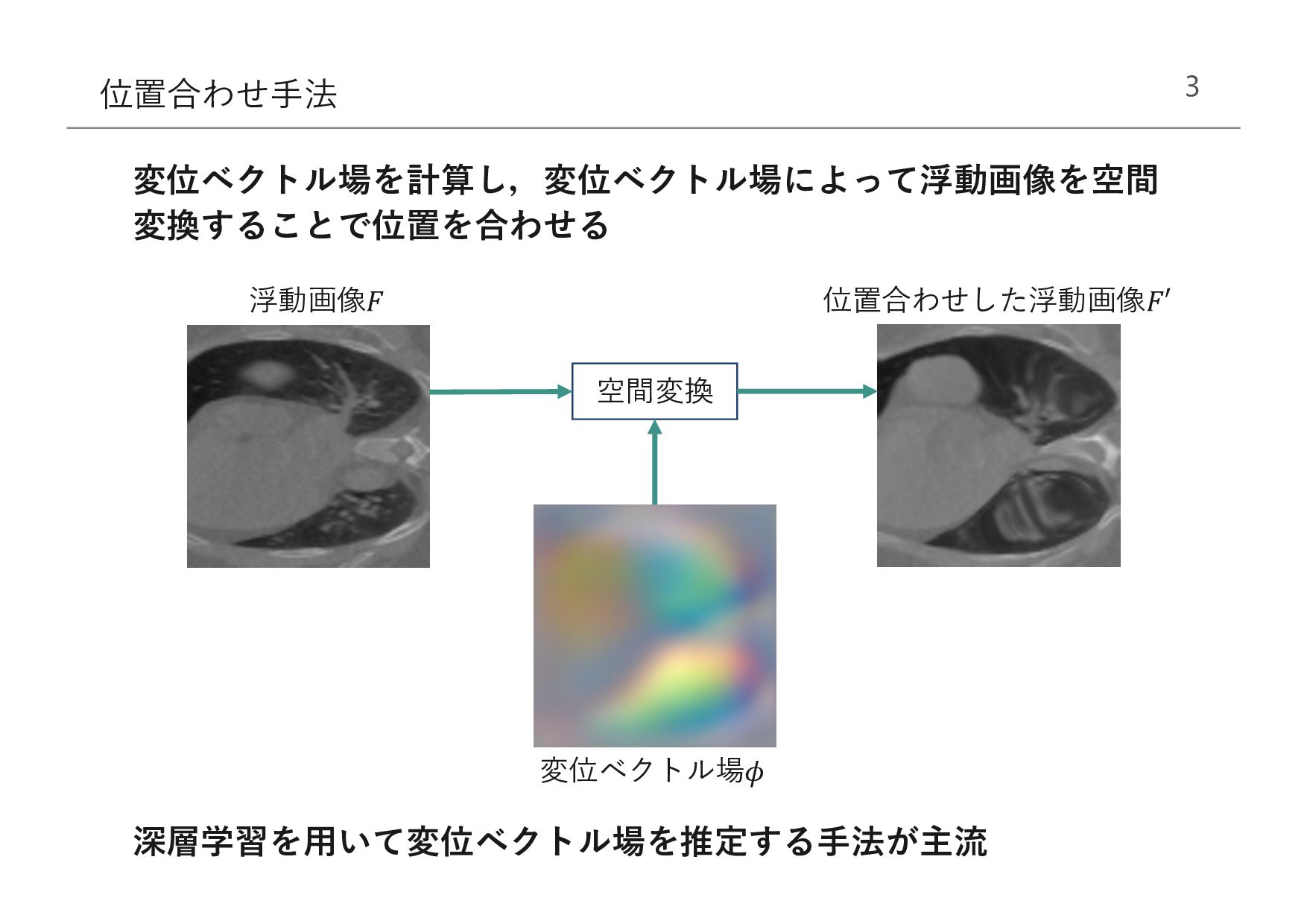
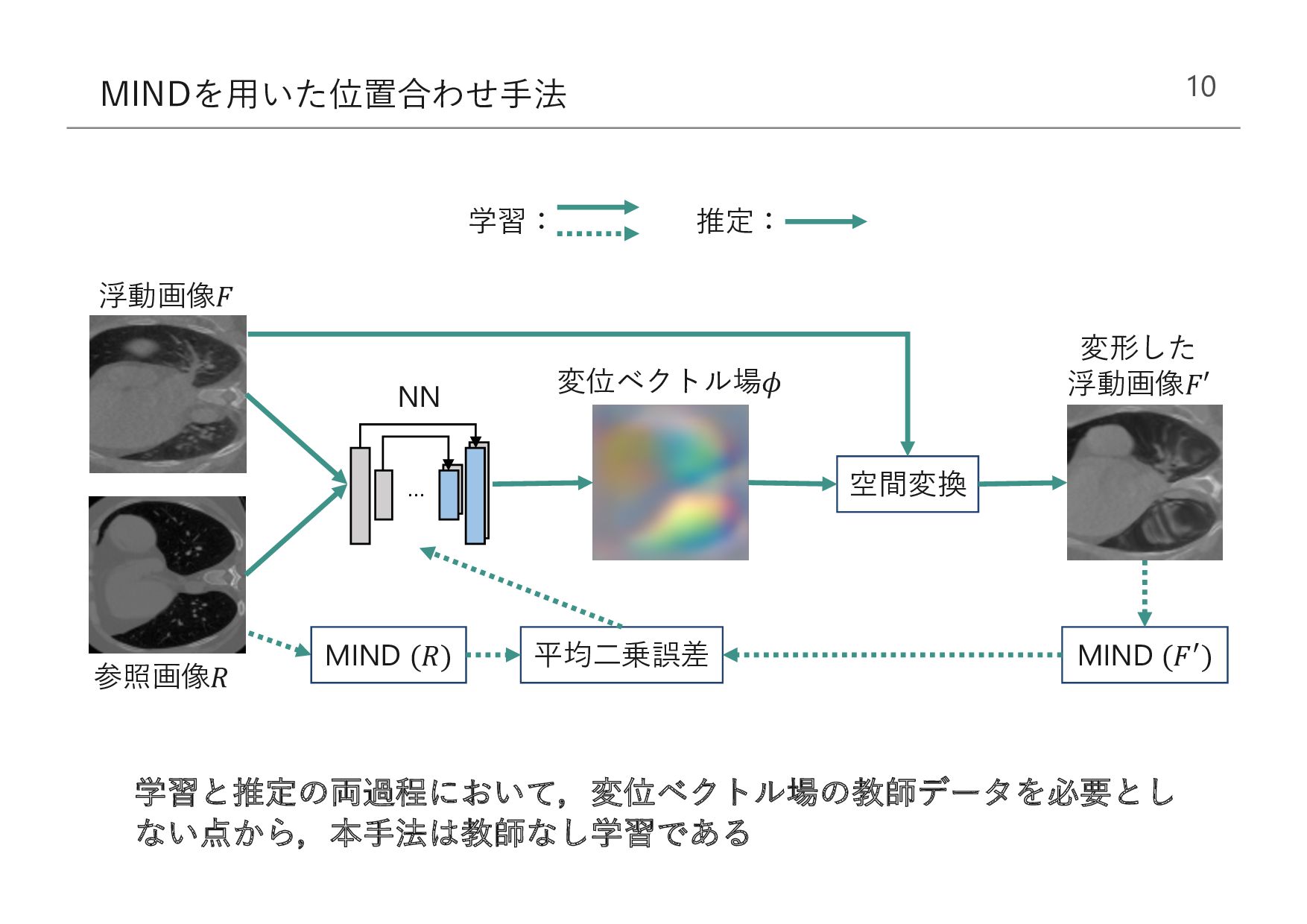
Moving 3D Image () Moved (()) Registration Field () & , Loss Function (ℒ) Fixed 3D Image () … Spatial Transform Figure 2: Overview of our method. We learn parameters for a function g that registers one 3D volume (M) to a second, fixed volume (F). During training, we warp M with φ using a spatial transformer function. Our loss compares Mφ and F and enforces smoothness of φ. " (,) for VoxelMorph-1 , Successive layers of the decoder operate on finer spa- tial scales, enabling precise anatomical alignment. How- ever, these convolutions are applied to the largest image 浮動画像 (") 参照画像 ($) %! ($,") 変位ベクトル場 (') 変形した浮動画像 (" ' ) 空間変換 損失関数 (ℒ) MIND (𝑅) 平均⼆乗誤差 NN 推定: 学習: 学習と推定の両過程において,変位ベクトル場の教師データを必要とし ない点から,本⼿法は教師なし学習である
{kind=link}
{kind=link}
{kind=link}
![4 関連研究 l 教師あり深層学習による位置合わせ[1] 変位ベクトル場をNN (Neural Network) で学習する 教師データである変位ベクトル場の作成は⼿間がかかる l](https://files.speakerdeck.com/presentations/f0dc84fc57cb4de99f6e1be796c4d84b/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
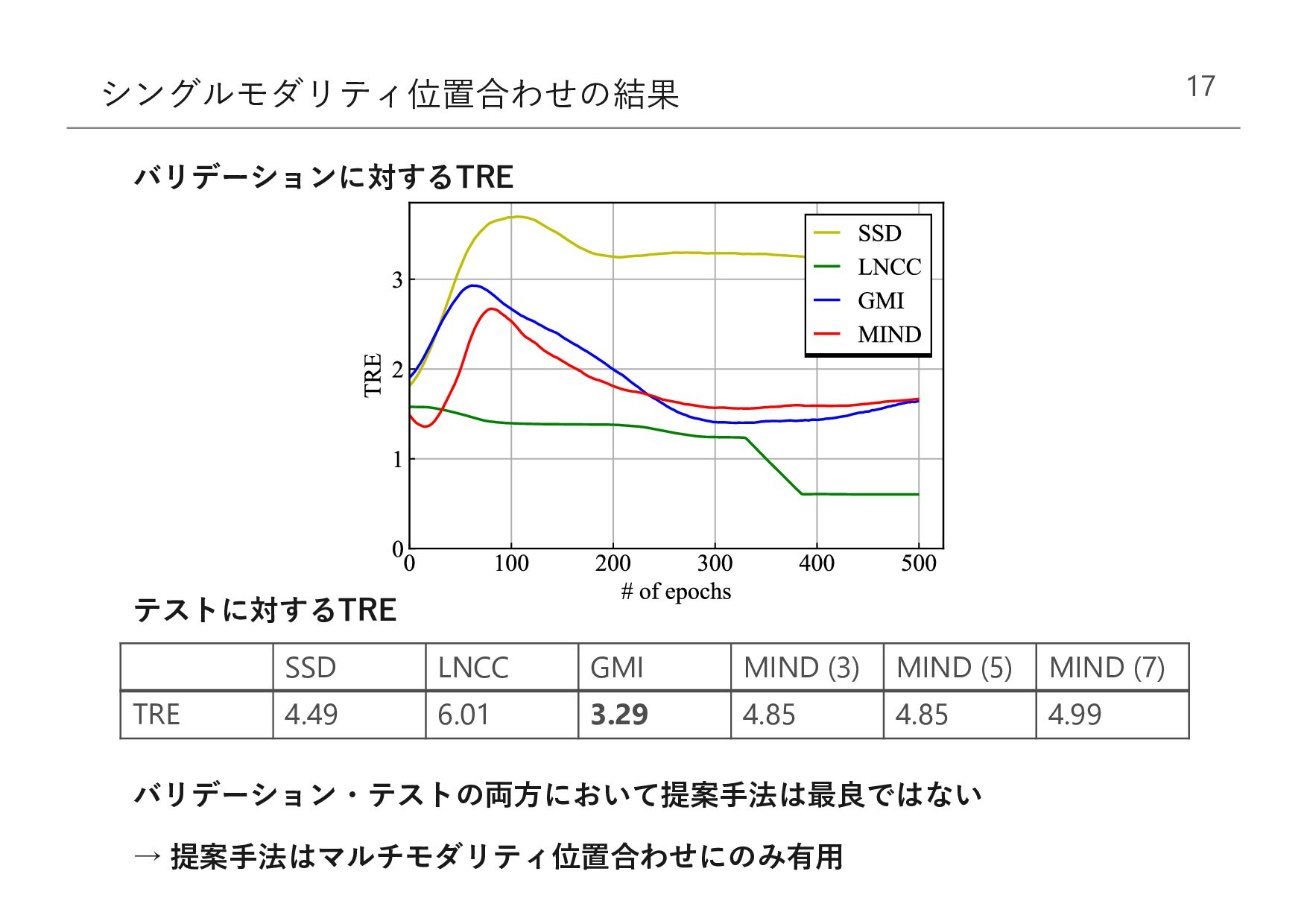{kind=link}
{kind=link}
{kind=link}