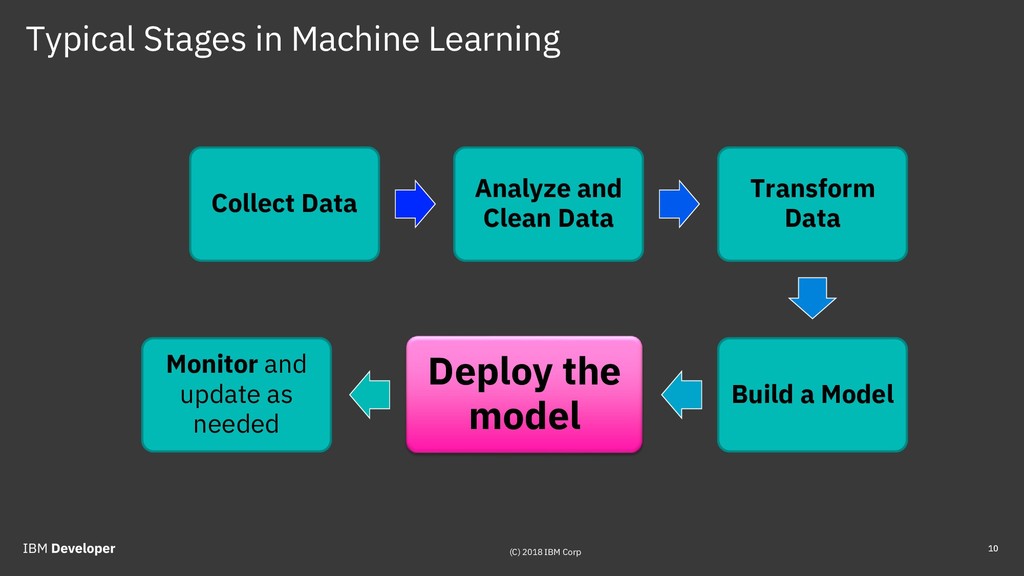
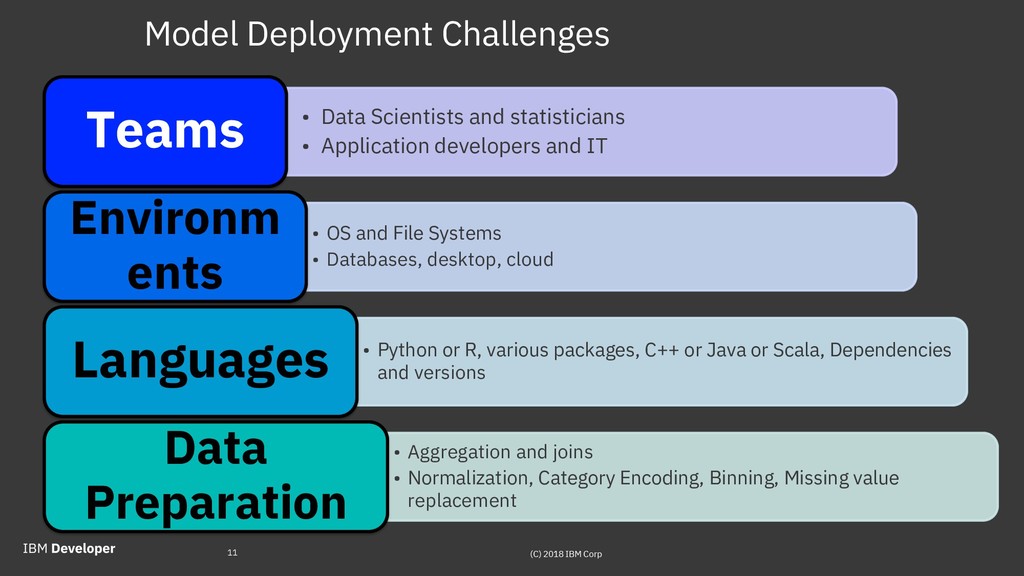
Predictive model deployment is the part of the machine learning process where the practical results are achieved, when the model is used for generating predictions on new data (known as scoring). The deployment used to present big difficulties, as models were typically built in one environment and needed to be deployed in a different one. Often they would need to be re-implemented in a new programming language, that would be very slow and error-prone.
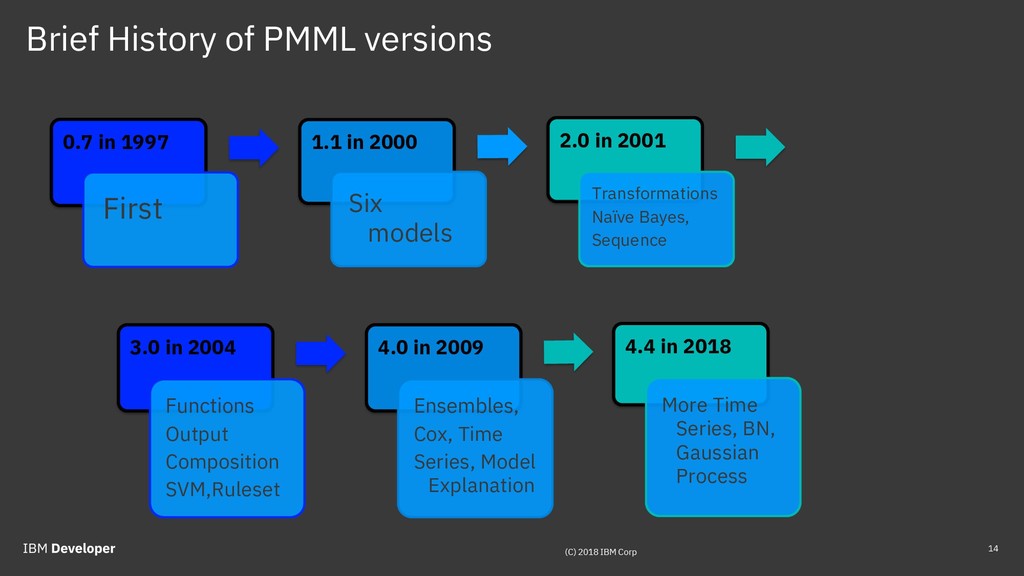
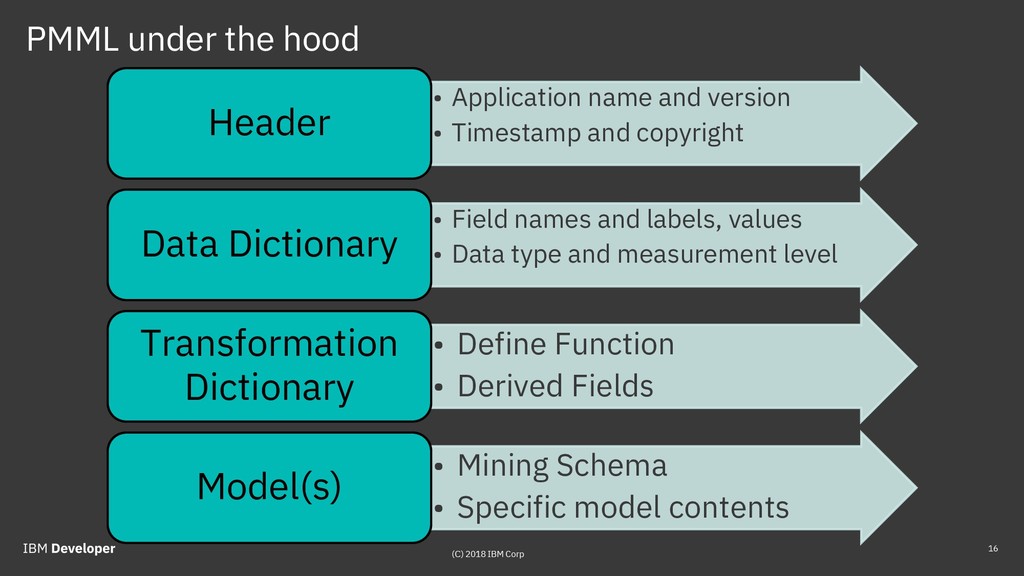
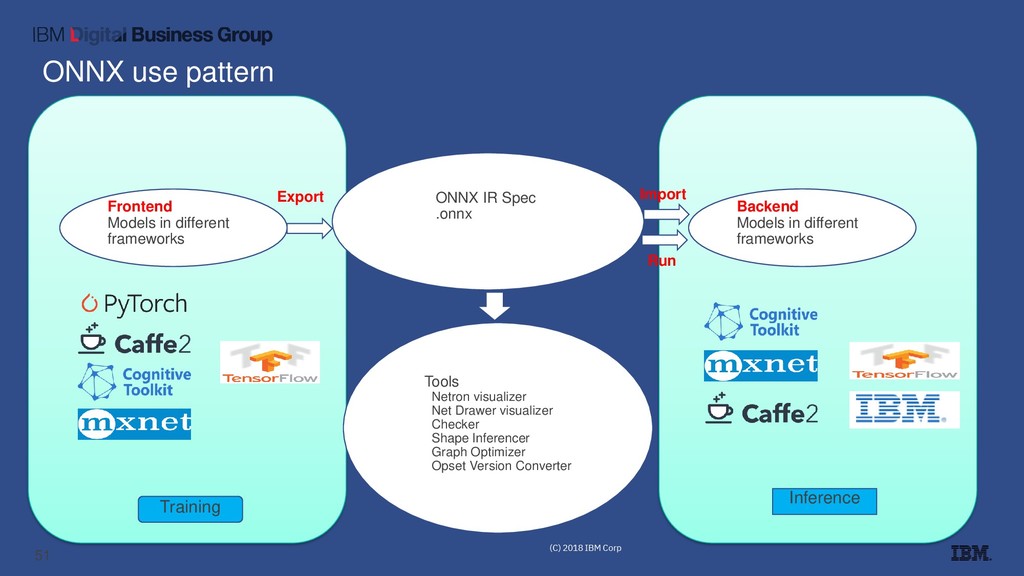
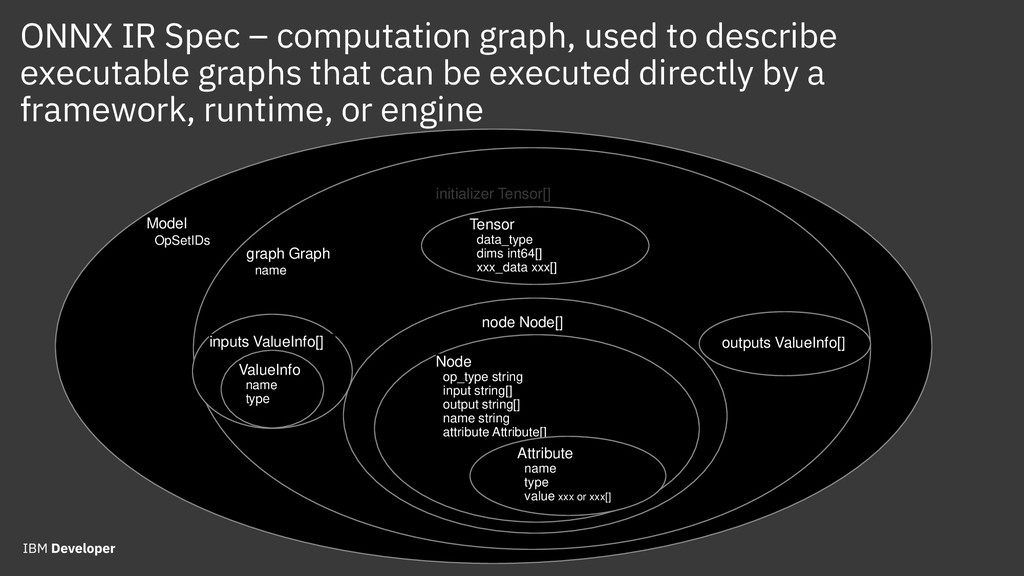
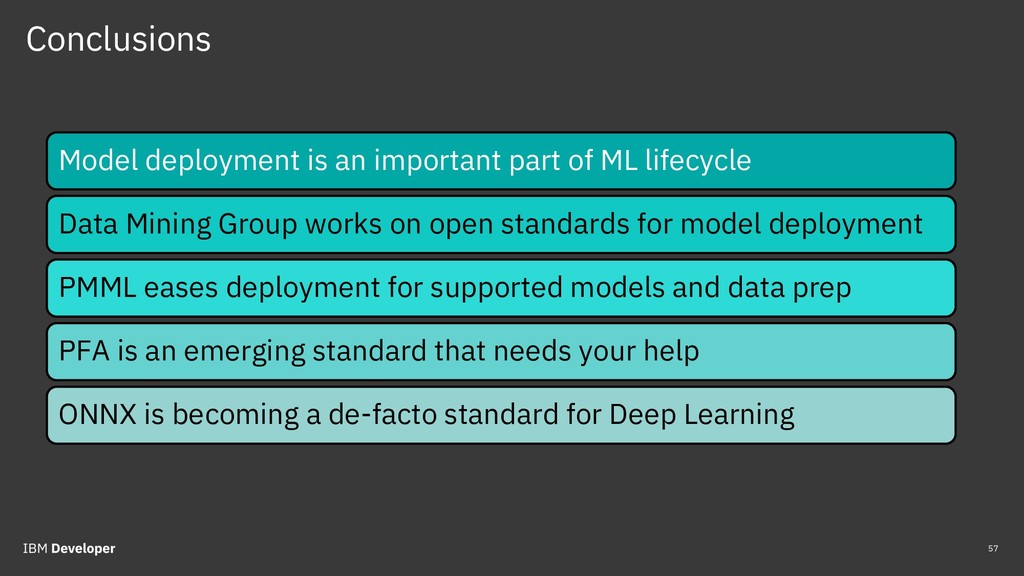
Predictive Model Markup Language (PMML) and Portable Format for Analytics (PFA) were developed by the Data Mining Group (DMG) that originated in Chicago. PMML has been around for more than 20 years and is used widely. PFA is an emerging standard that is getting a lot of interest. Open Neural Network eXchange (ONNX) format was recently developed by Facebook and Microsoft as a way to exchange deep learning (DL) models between different DL frameworks, and is now experiencing explosive growth. Attendees will get a good understanding of predictive model deployment challenges and approaches.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
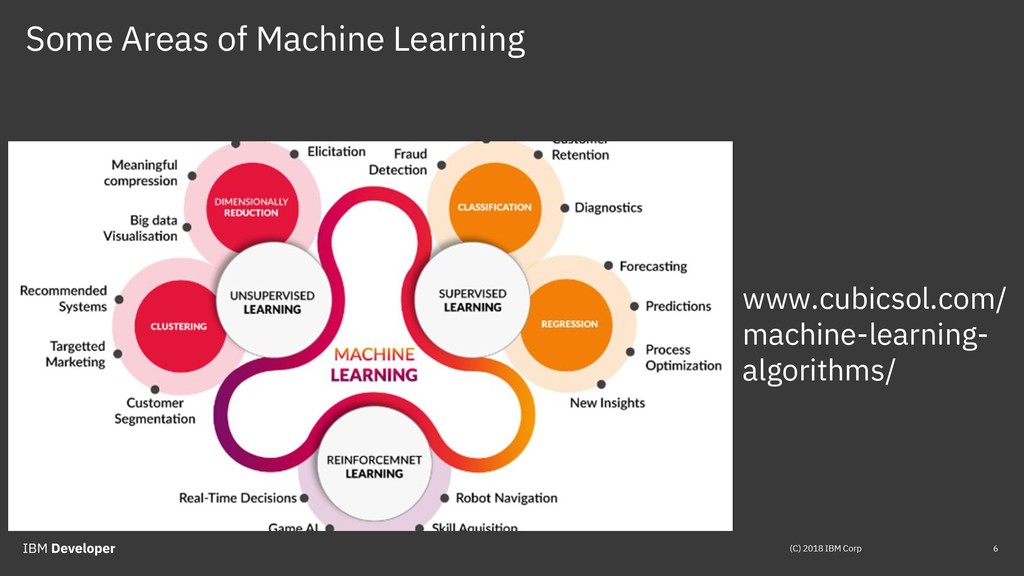{kind=link}
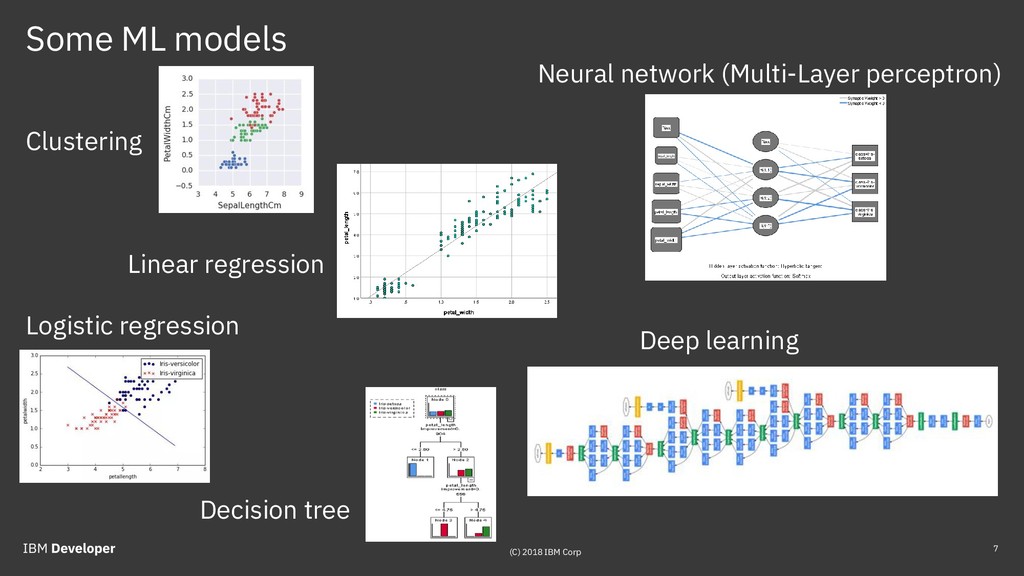{kind=link}
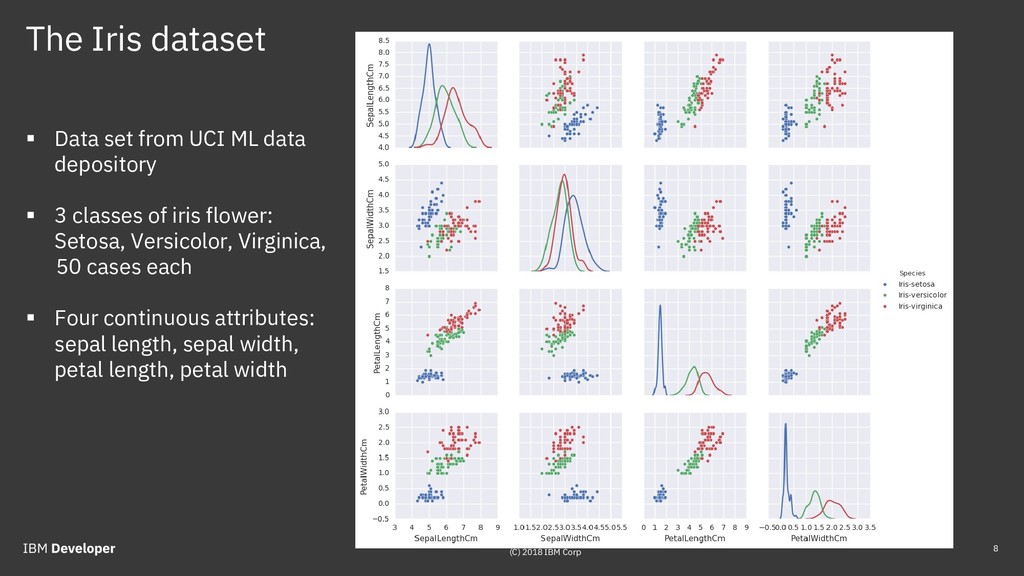{kind=link}
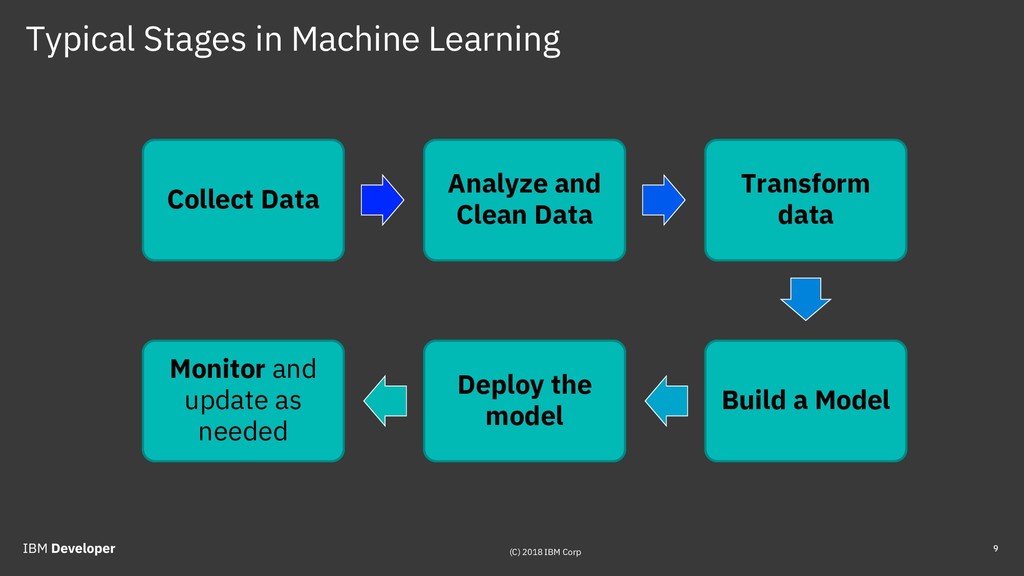{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
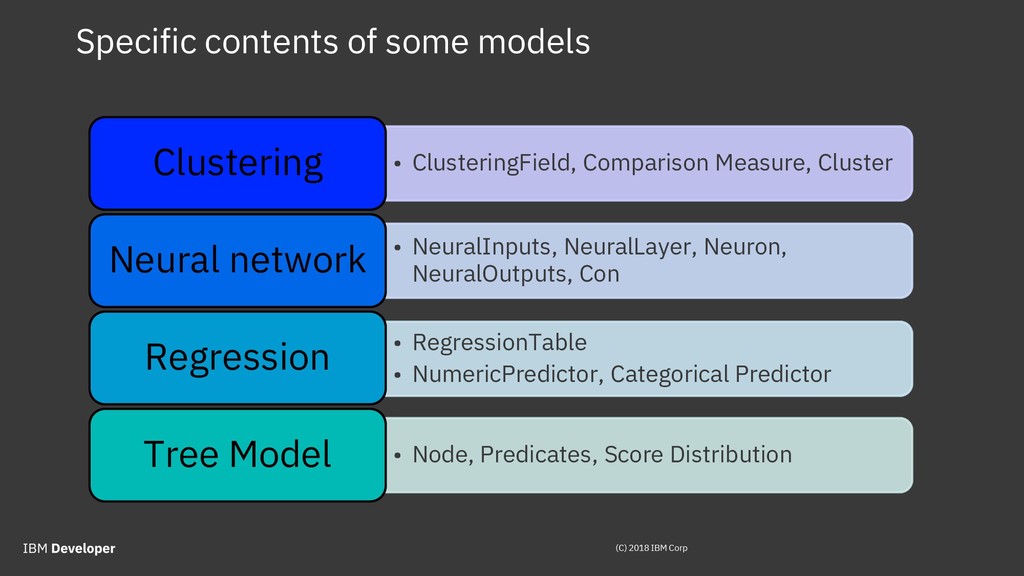{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
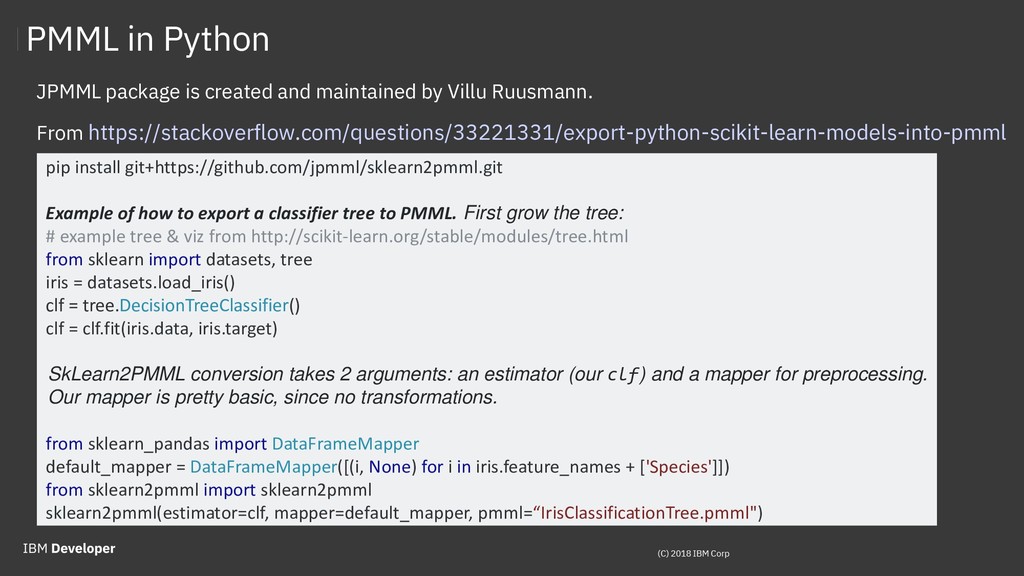{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
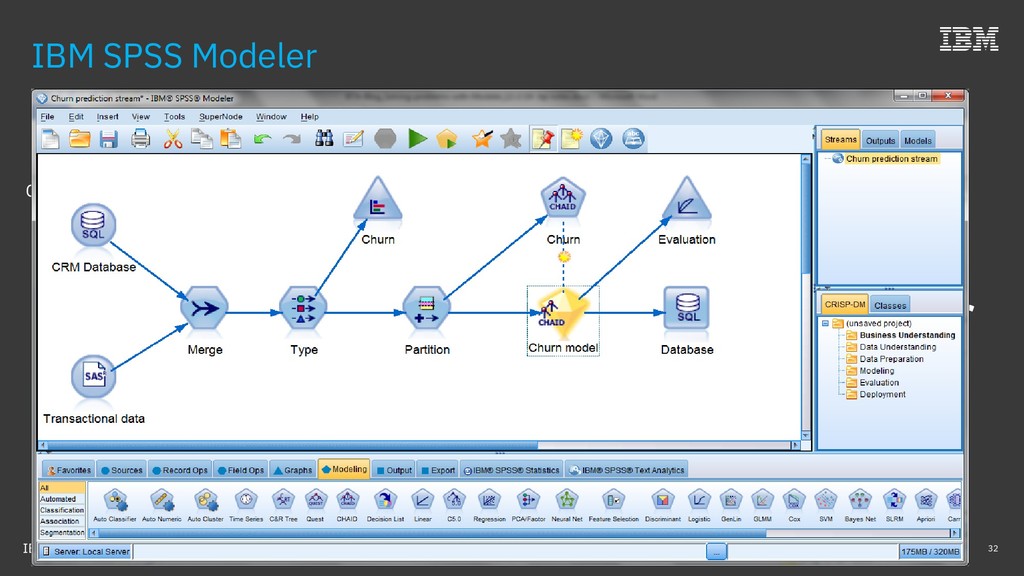{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}