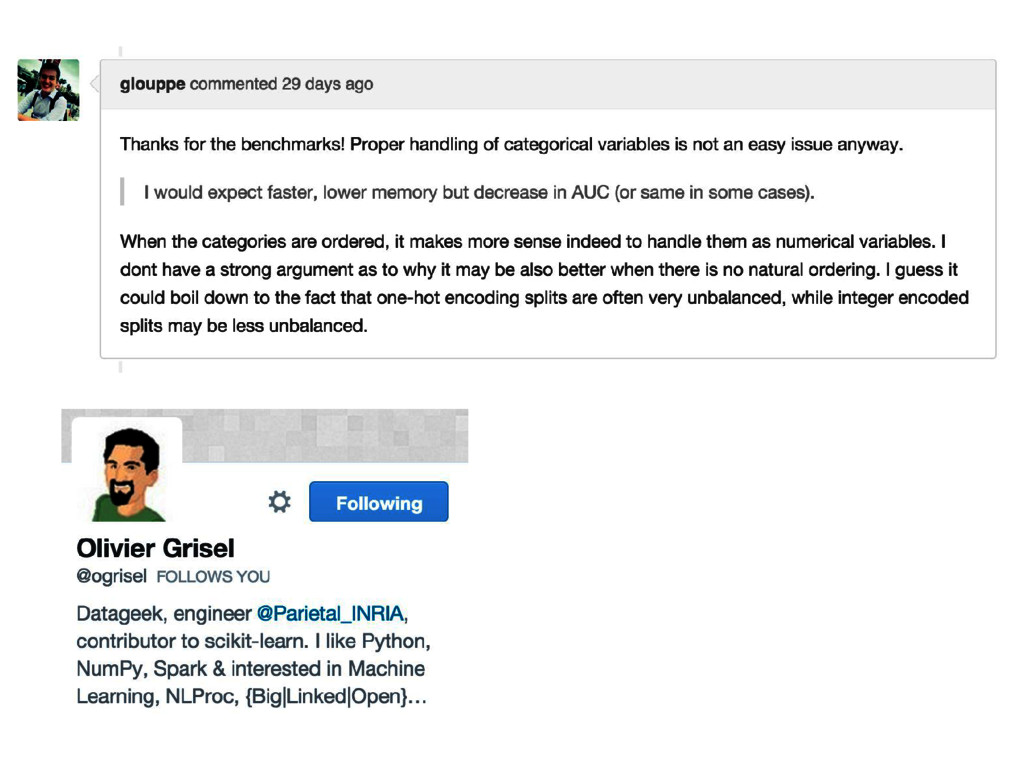
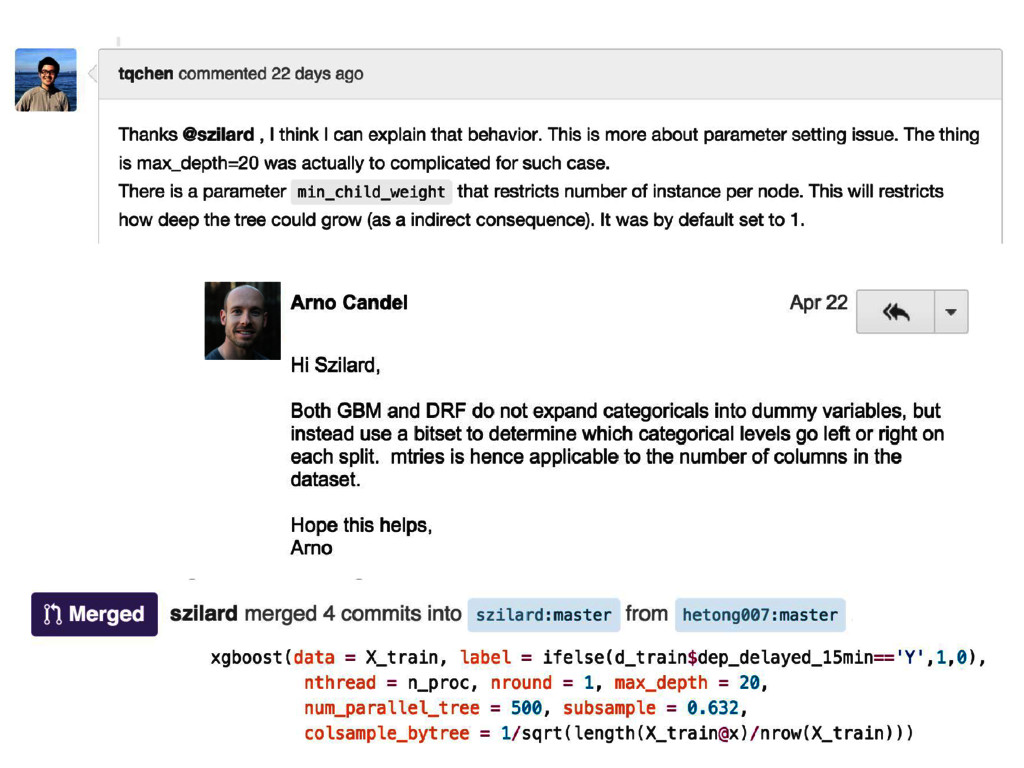
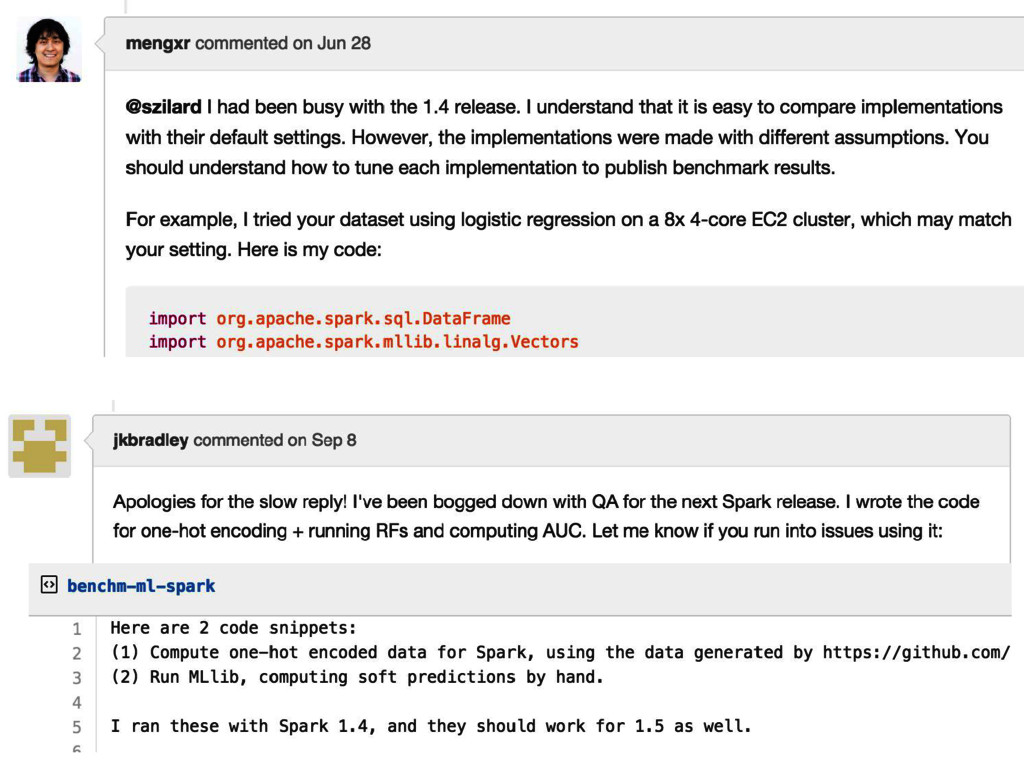
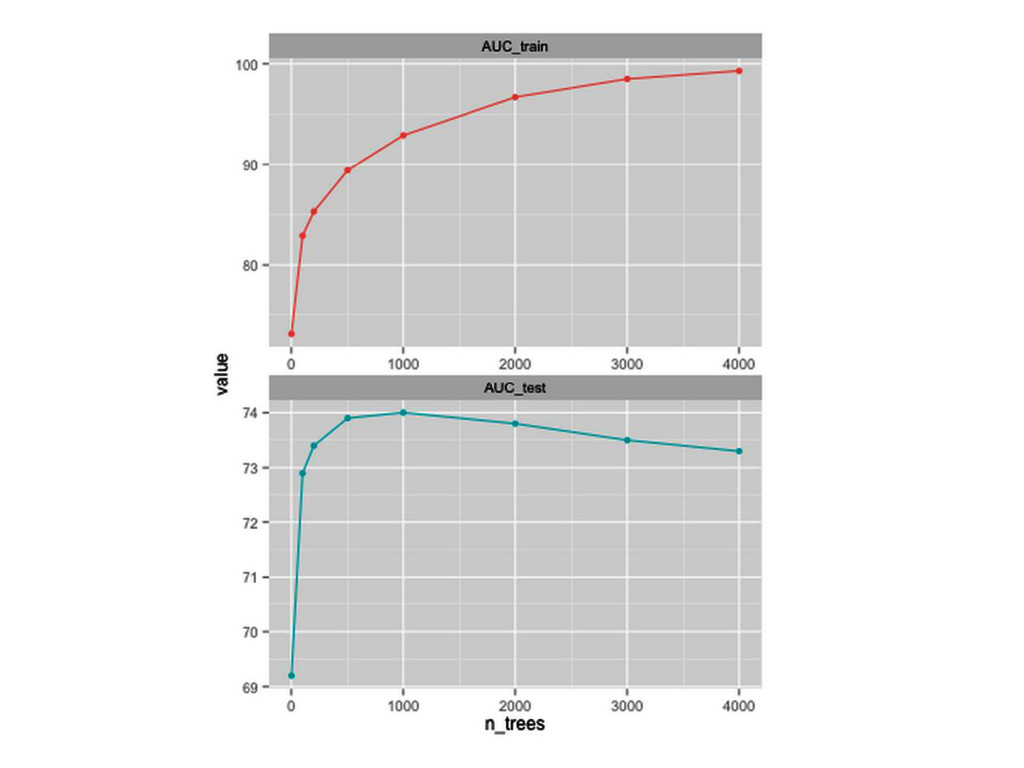
talk I cannot confirm nor deny if Epoch is using or not any of the methods, tools, results etc. mentioned in this talk. The results presented in this talk should not be considered as any indication whether Epoch is using these methods, tools, results etc. or not.
not “efficient” (from time budget perspective) to write my own algorithm [...] I can find open source code for what I want to do, and my time is much better spent doing research and feature engineering -- Owen Zhang http://blog.kaggle.com/2015/06/22/profiling-top-kagglers-owen-zhang-currently-1-in-the-world/
layer of complexity and [network] communication overhead. The ideal case is scaling linearly with the number of nodes; that’s rarely the case. Emerging evidence shows that very often, one big machine, or even a laptop, outperforms a cluster. http://fastml.com/the-emperors-new-clothes-distributed-machine-learning/
petabytes of [...] data to extract interesting features, but this paper explores the interesting possibility of switching over to a multi-core, shared-memory system for efficient execution on more refined datasets [...] e.g., machine learning http://openproceedings.org/2014/conf/edbt/KumarGDL14.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![I usually use other people’s code [...] it is usually](https://files.speakerdeck.com/presentations/4a521223fdc4478eae6ed955e395a2ff/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
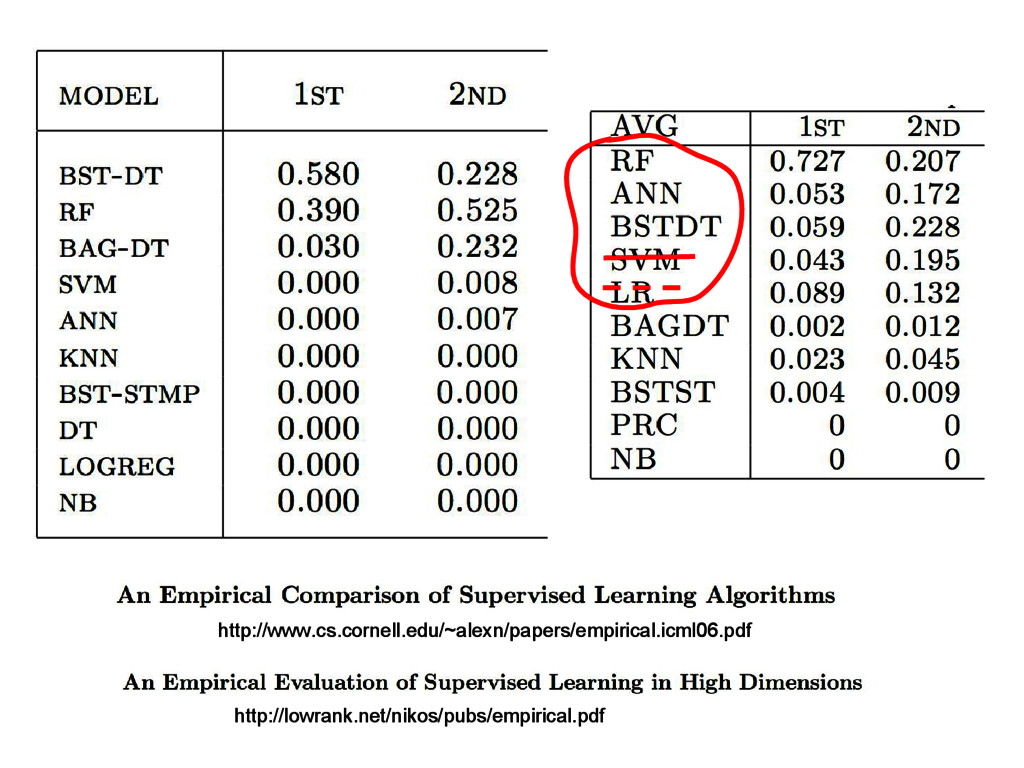{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
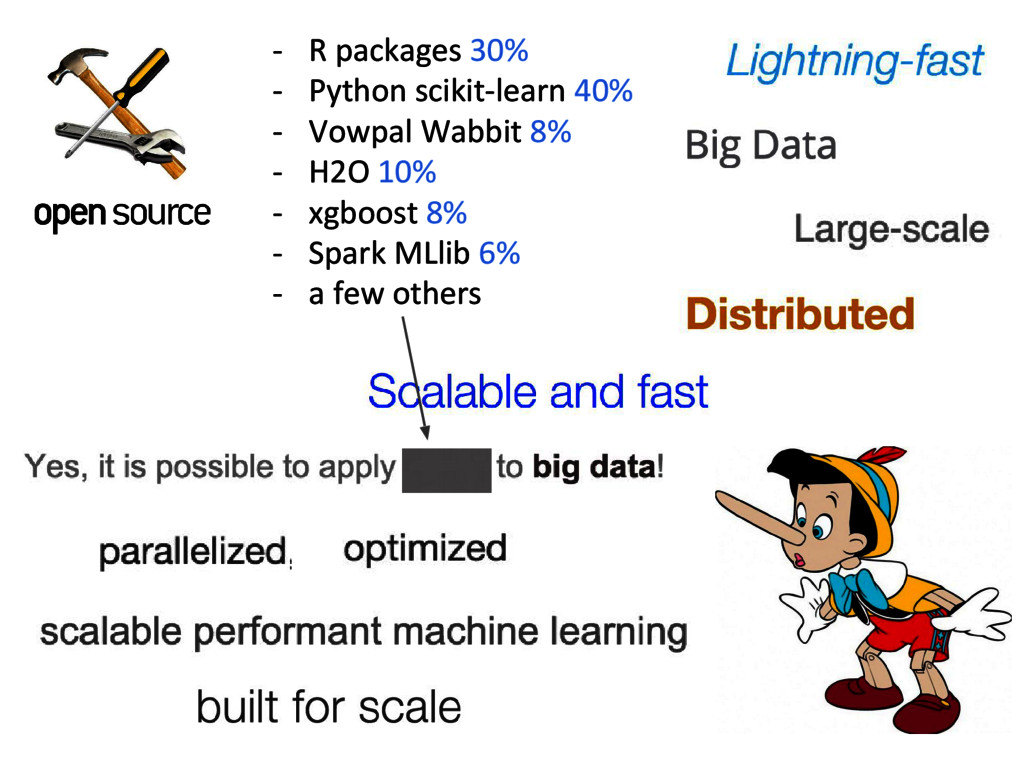{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
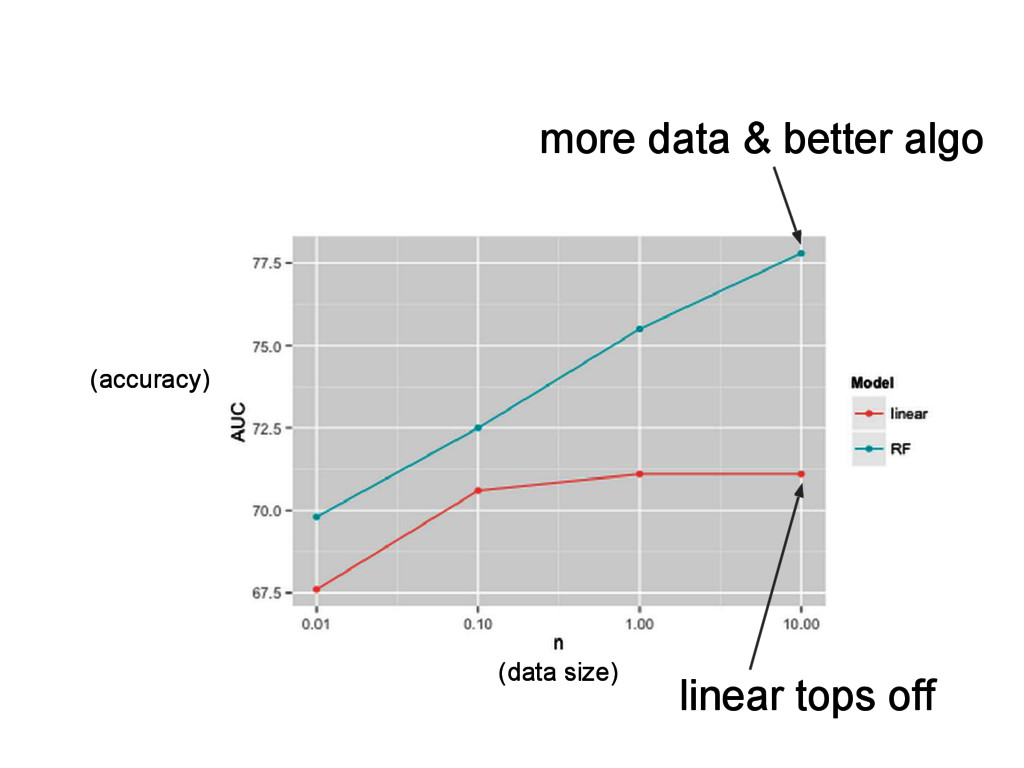{kind=link}
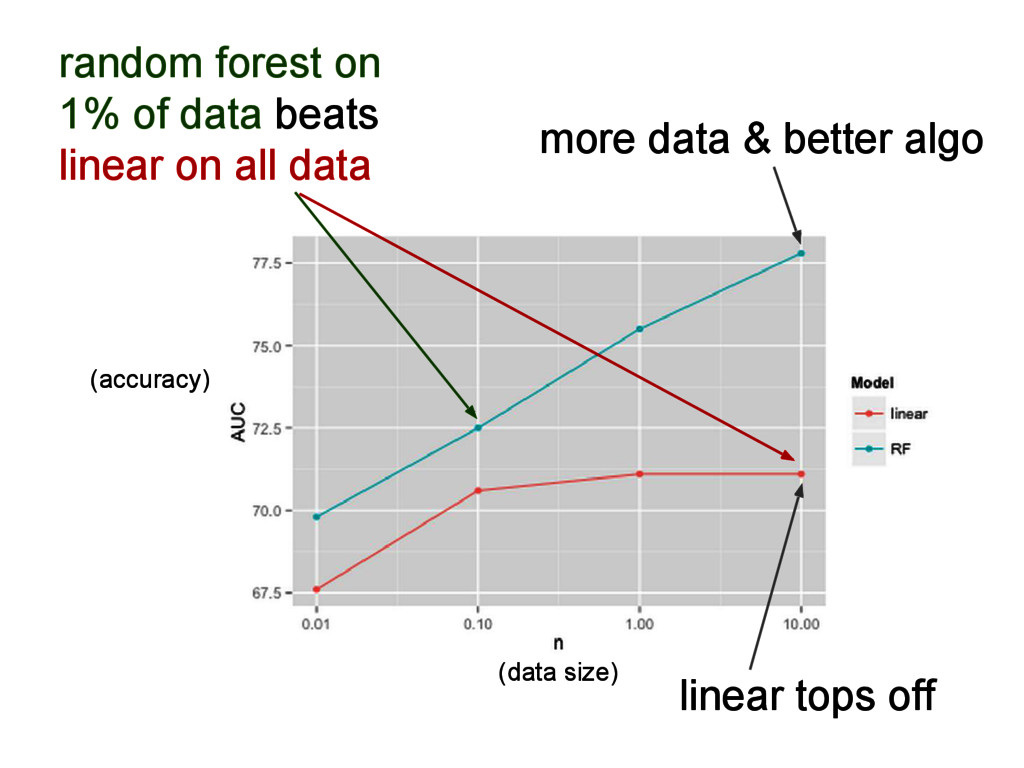{kind=link}
{kind=link}
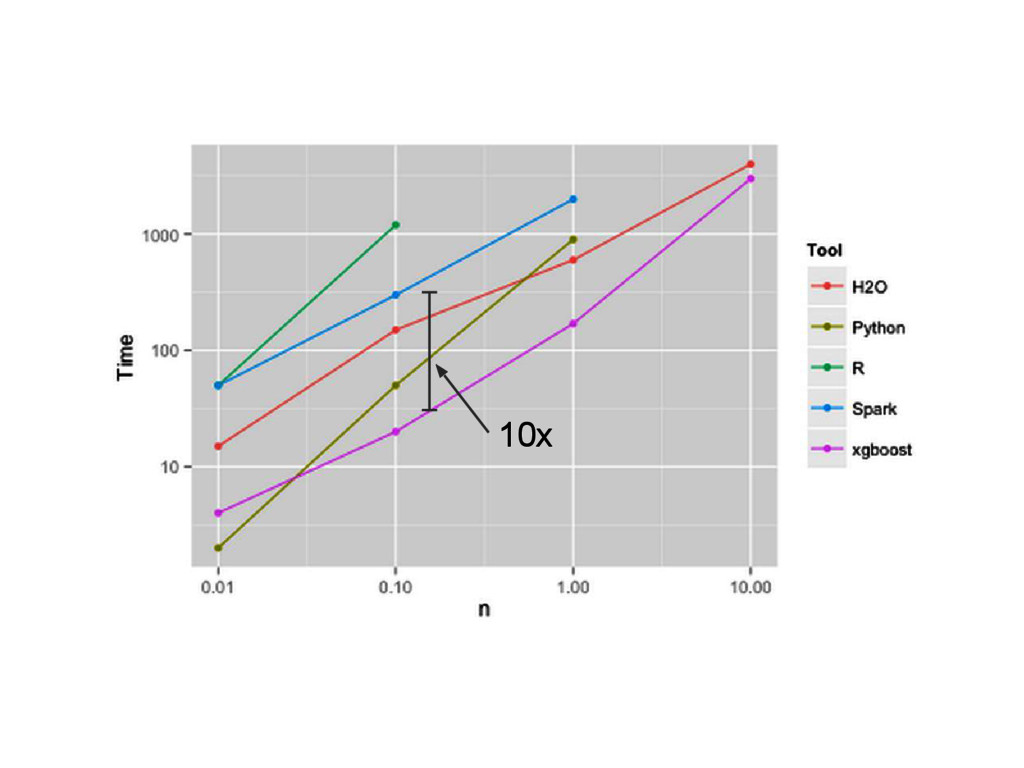{kind=link}
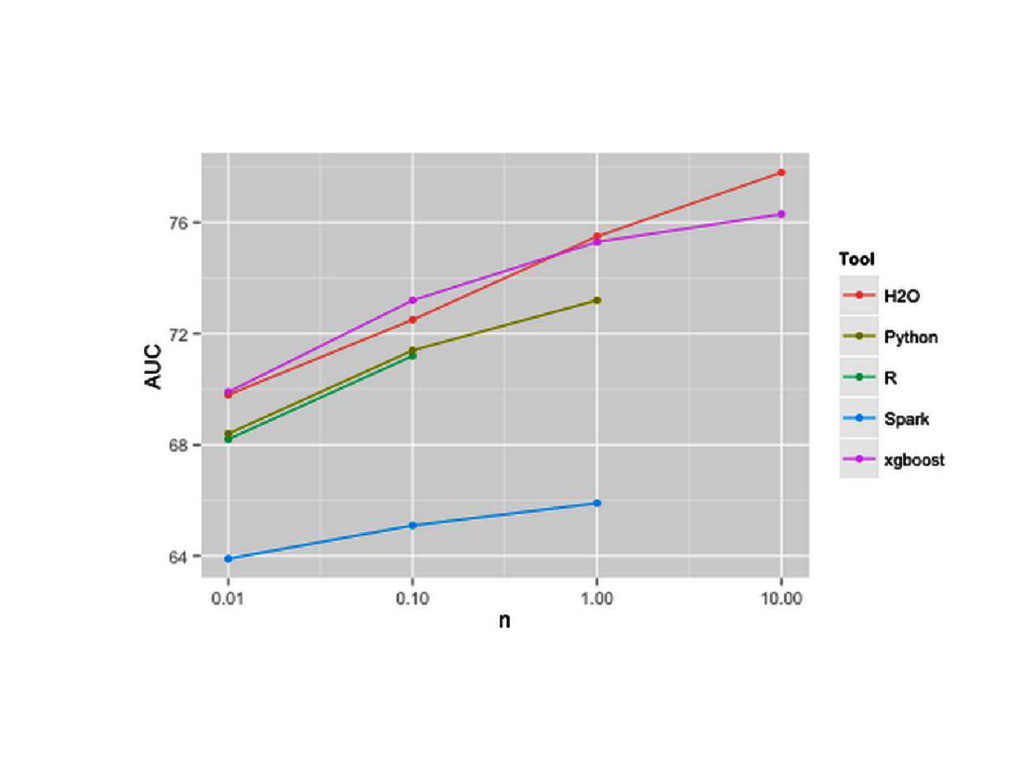{kind=link}
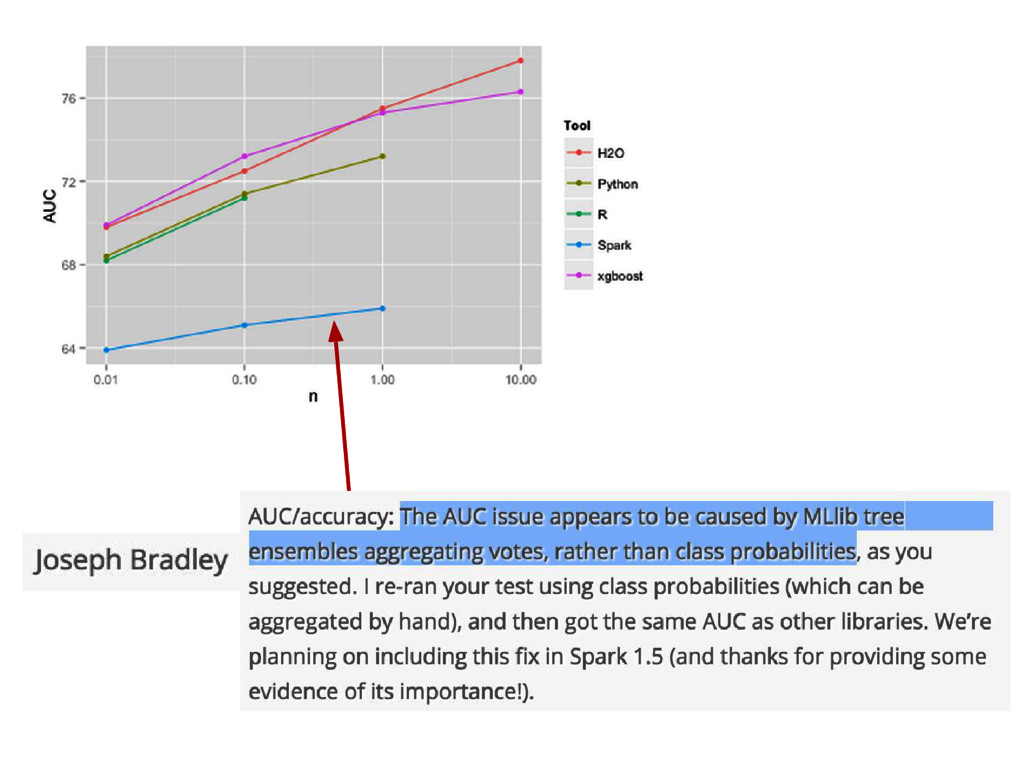{kind=link}
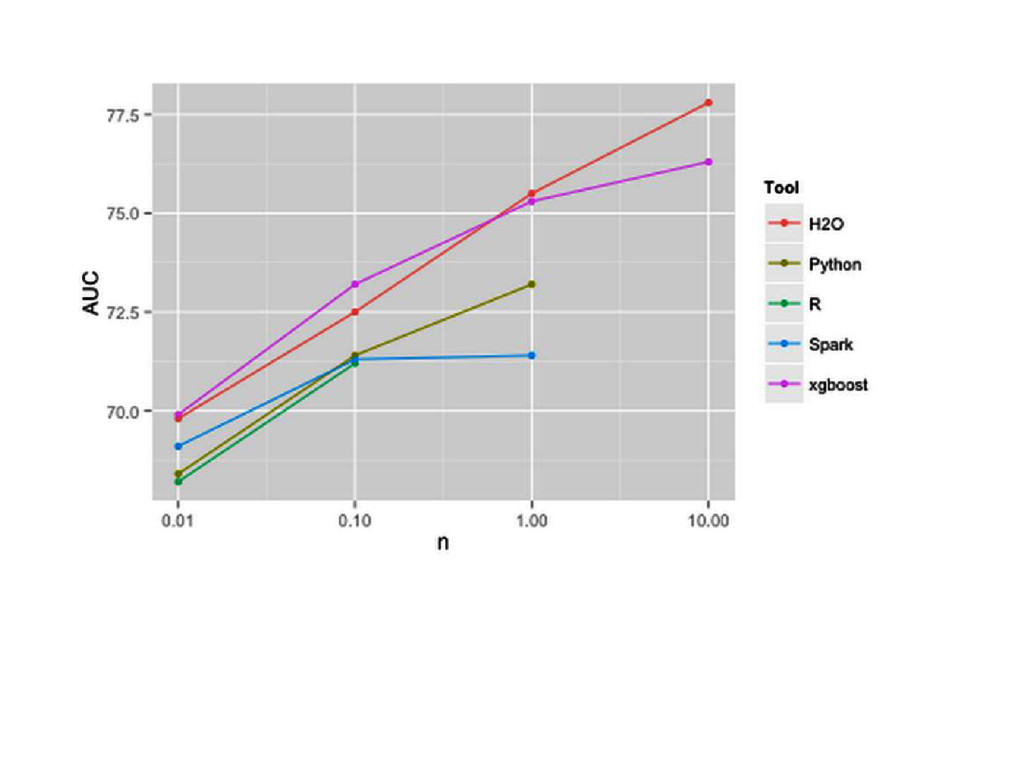{kind=link}
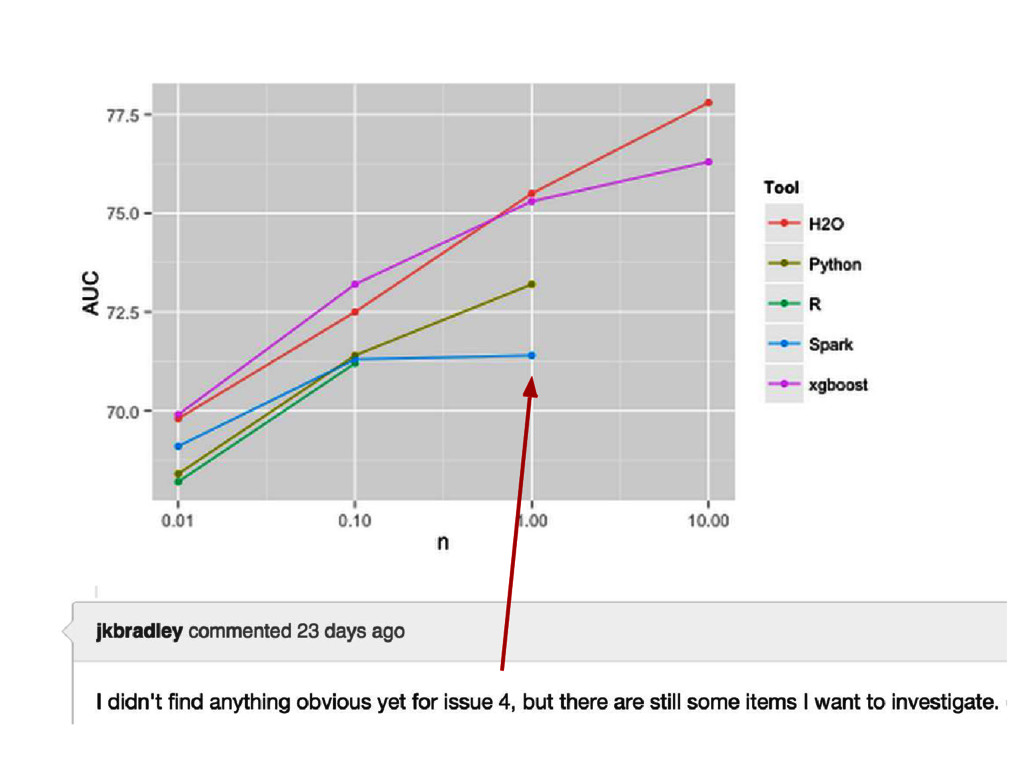{kind=link}
{kind=link}
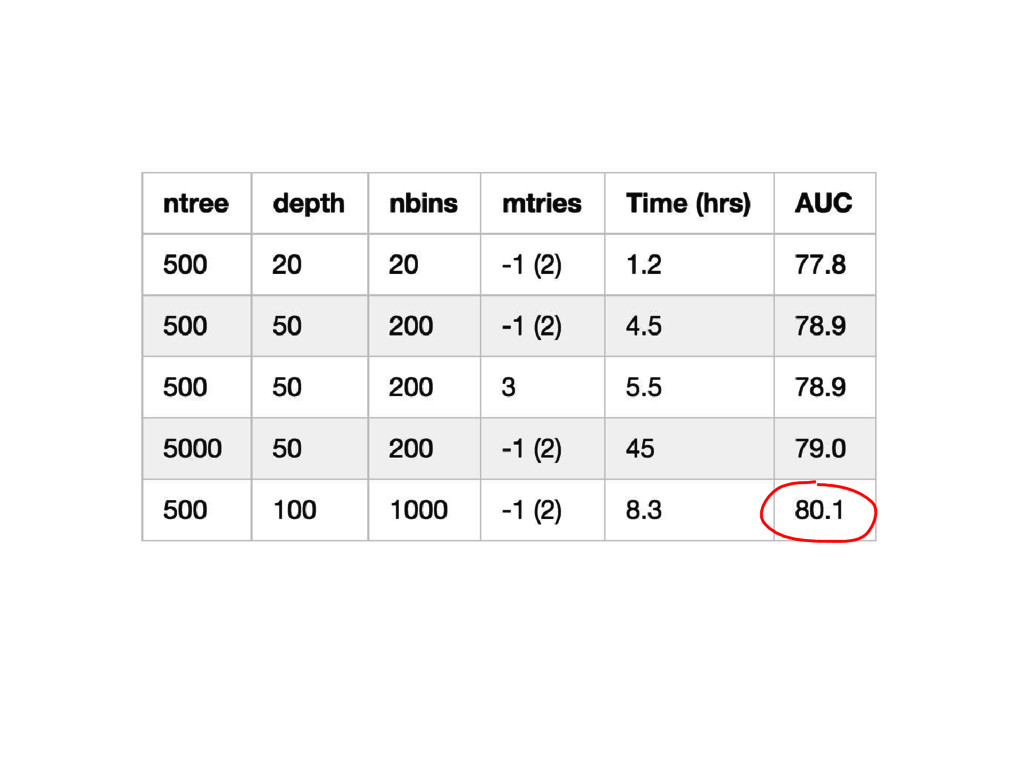{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![we will continue to run large [...] jobs to scan](https://files.speakerdeck.com/presentations/4a521223fdc4478eae6ed955e395a2ff/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
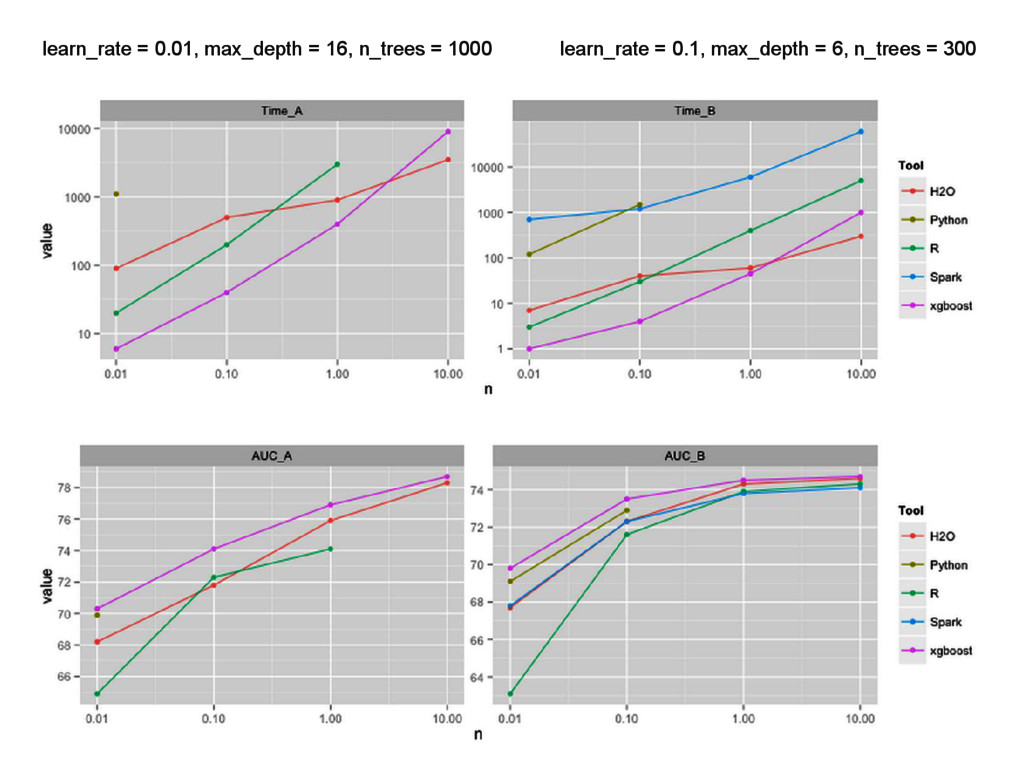{kind=link}
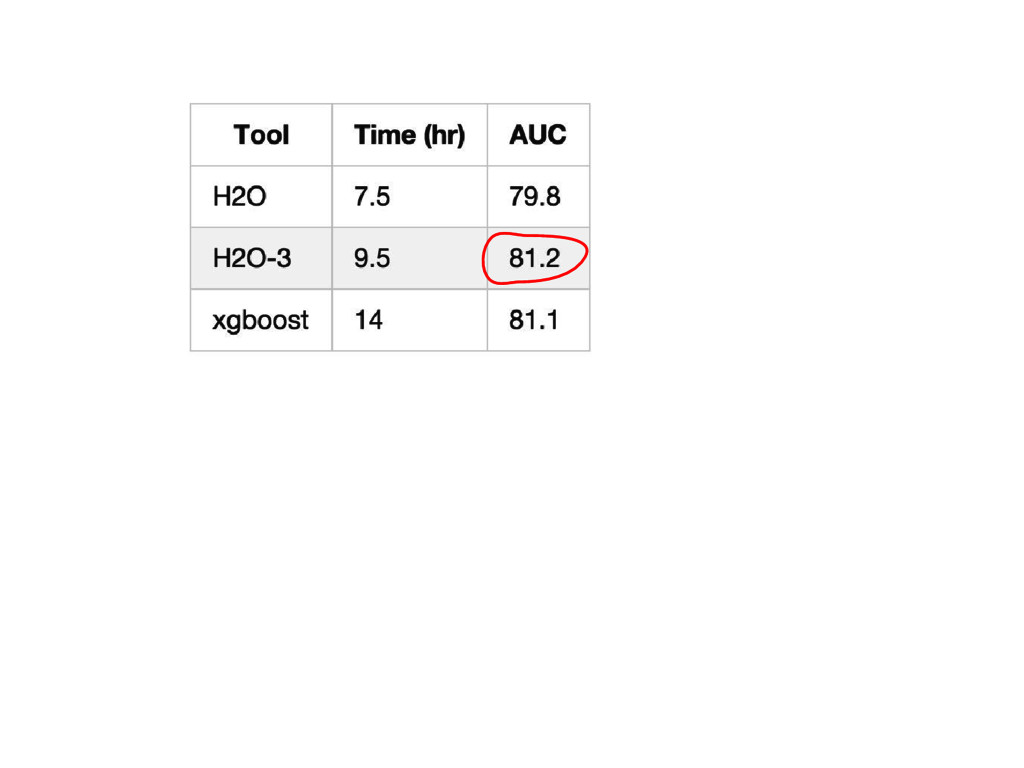{kind=link}
{kind=link}
{kind=link}
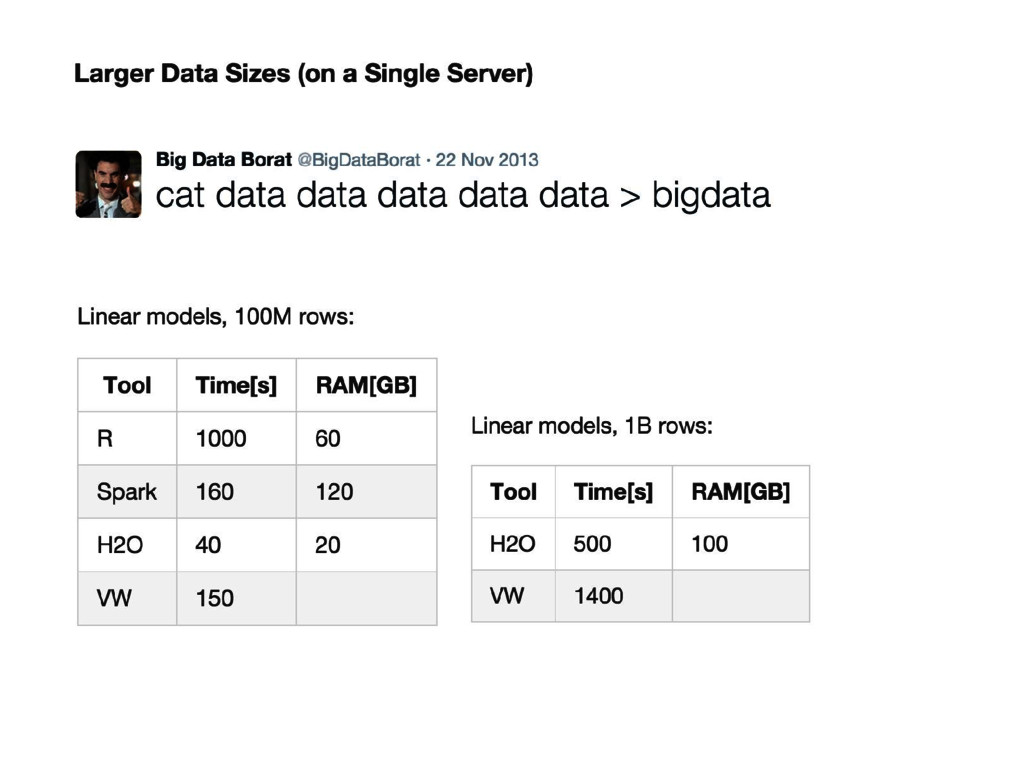{kind=link}
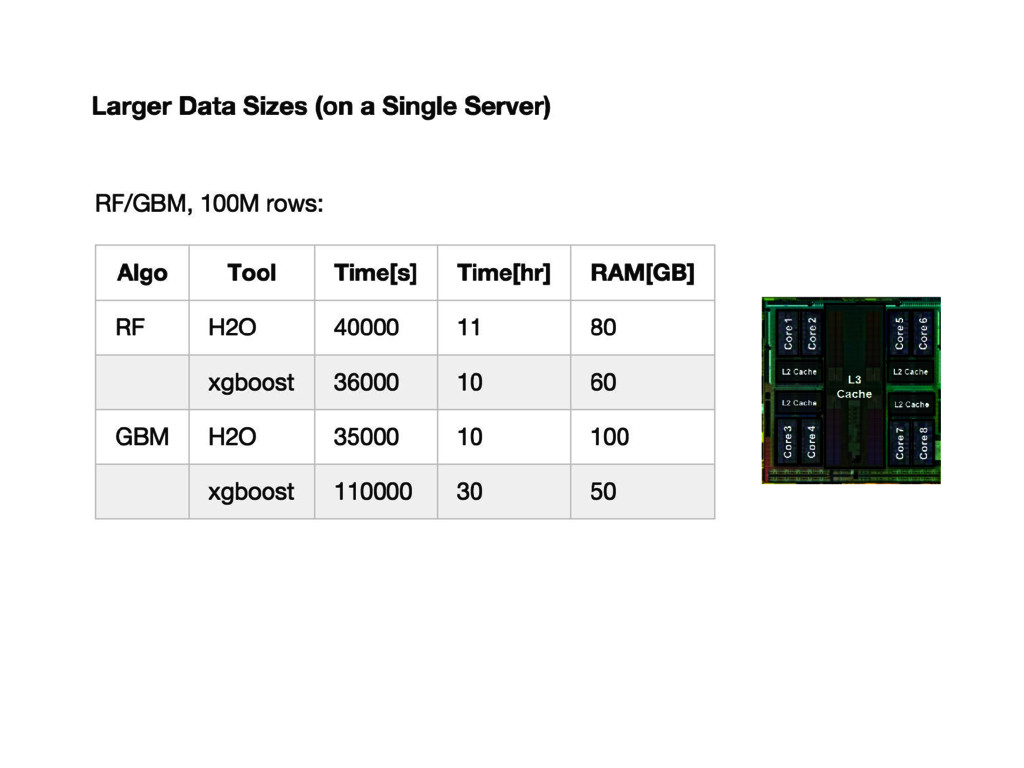{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
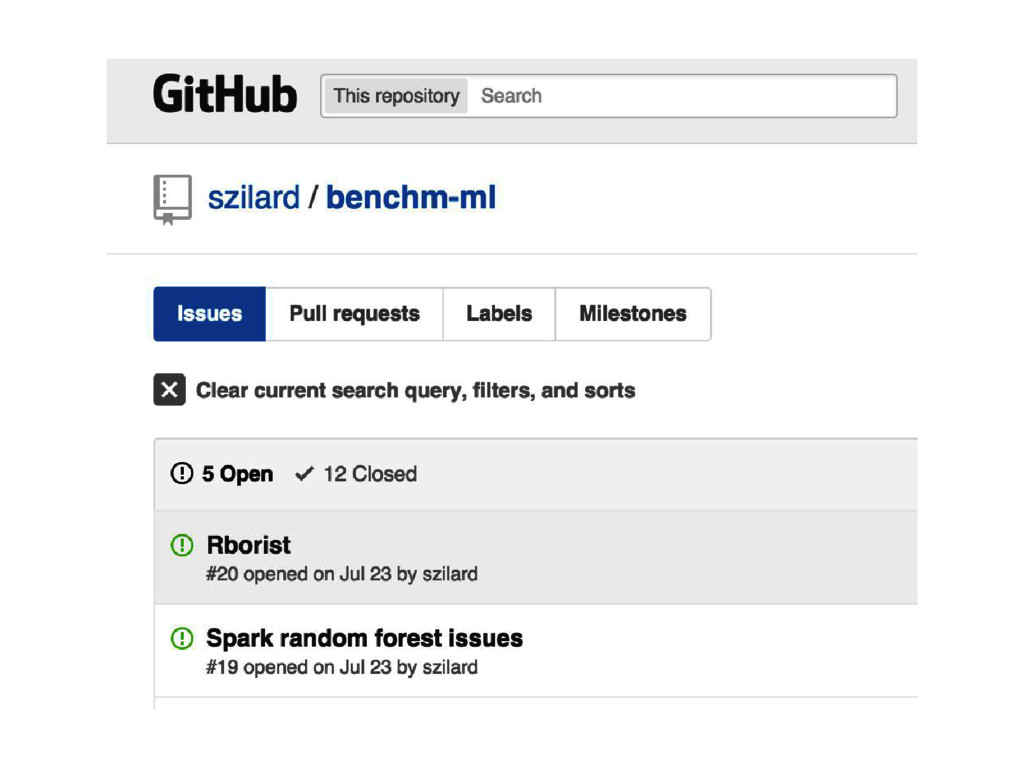{kind=link}
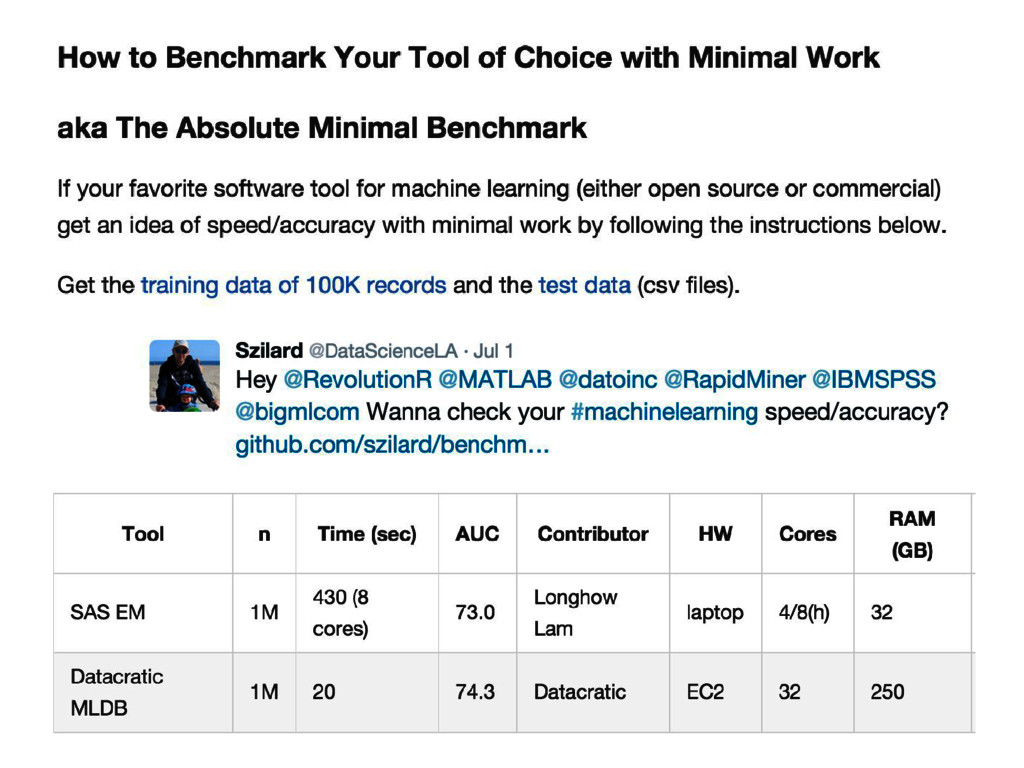{kind=link}
{kind=link}