Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
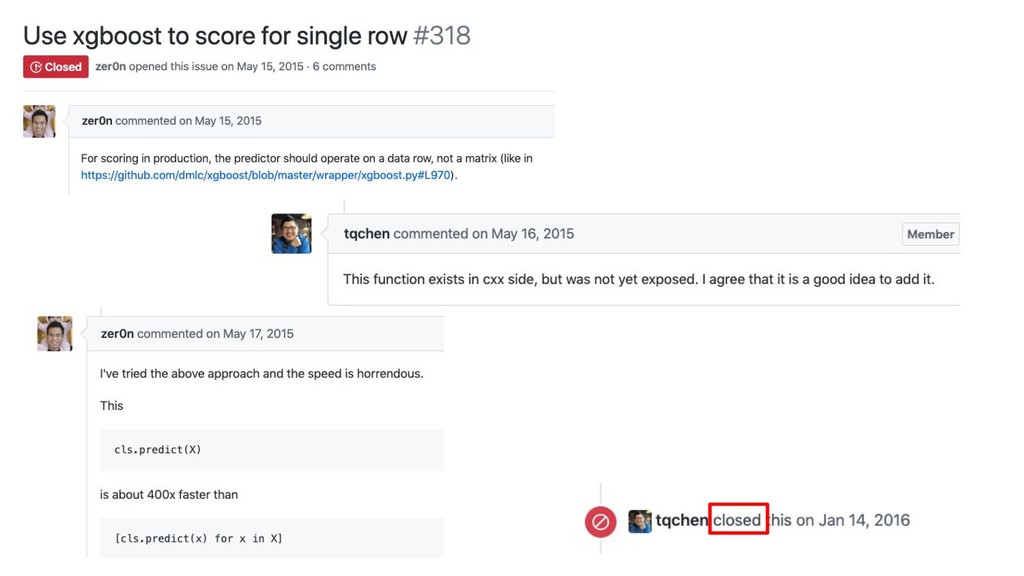
Better than My Meetup/Conference Talks: Going ...
Search
szilard
November 09, 2019
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Better than My Meetup/Conference Talks: Going Deeper in Various GBM Topics - GBM Advanced Workshop - Budapest, Nov 2019
szilard
November 09, 2019
More Decks by szilard
See All by szilard
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - Data Con LA - Oct 2020
szilard
0
240
Make Machine Learning Boring Again: Best Practices for Using Machine Learning in Businesses - Albuquerque Machine Learning Meetup (Online) - Aug 2020
szilard
0
170
Better than Deep Learning: Gradient Boosting Machines (GBM) - eRum conference - invited talk - June 2020
szilard
0
150
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - LA Data Science Meetup - February 2020
szilard
0
140
A Random Walk in Data Science and Machine Learning in Practice - CEU, Business Analytics Masters - Budapest, Febr 2020
szilard
0
340
Gradient Boosting Machines (GBM): From Zero to Hero (with R and Python Code) - Budapest BI Forum, Budapest, Nov 2019
szilard
0
170
Make Machine Learning Boring Again: Best Practices for Using Machine Learning in Businesses - LA Data Science Meetup - Playa Vista, August 2019
szilard
0
160
Better than Deep Learning: Gradient Boosting Machines (GBM) / 2019 edition - Budapest R and Data Science Meetups - Budapest, June 2019
szilard
0
140
Better than Deep Learning: Gradient Boosting Machines (GBM) / 2019 edition - LA R Meetup - Santa Monica, May 2019
szilard
0
38
Featured
See All Featured
How to make the Groovebox
asonas
2
2.3k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
From π to Pie charts
rasagy
0
240
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Become a Pro
speakerdeck
PRO
31
6k
How STYLIGHT went responsive
nonsquared
100
6.2k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
How to Ace a Technical Interview
jacobian
281
24k
Code Reviewing Like a Champion
maltzj
528
40k
Transcript
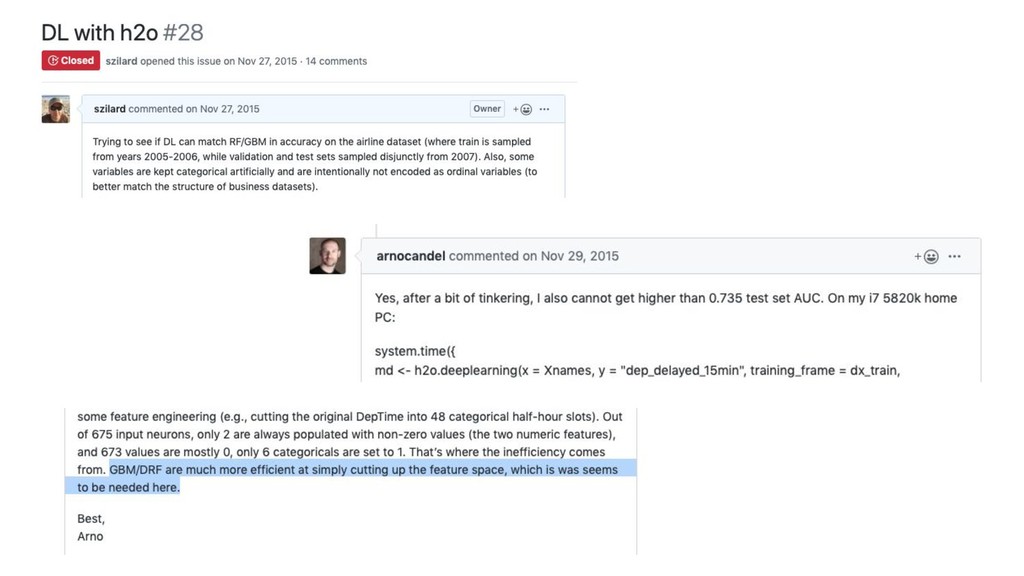
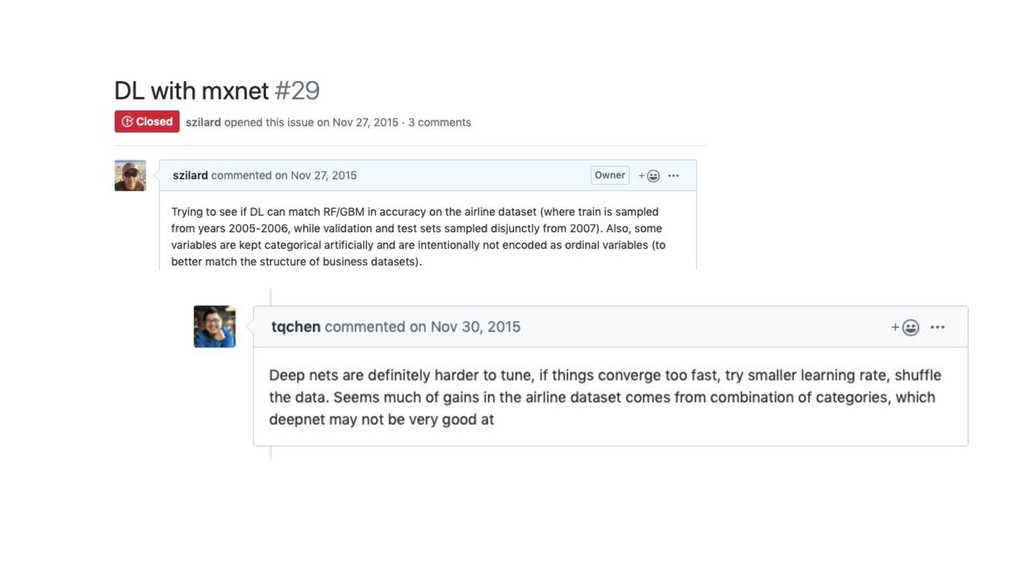
Better than My Meetup/Conference Talks: Going Deeper in Various GBM
Topics Szilard Pafka, PhD Chief Scientist, Epoch (USA) GBM Advanced Workshop Budapest Nov 2019
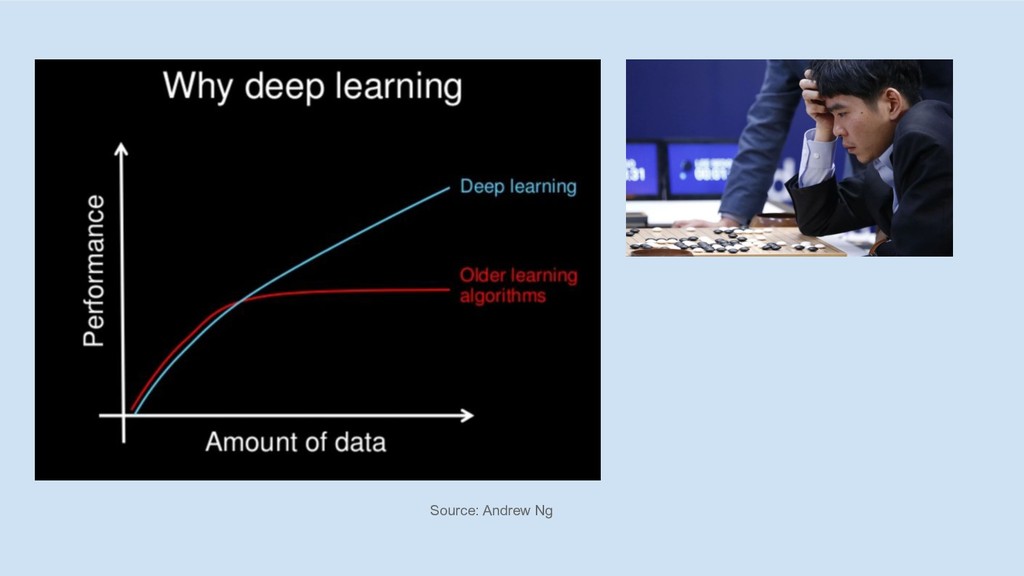
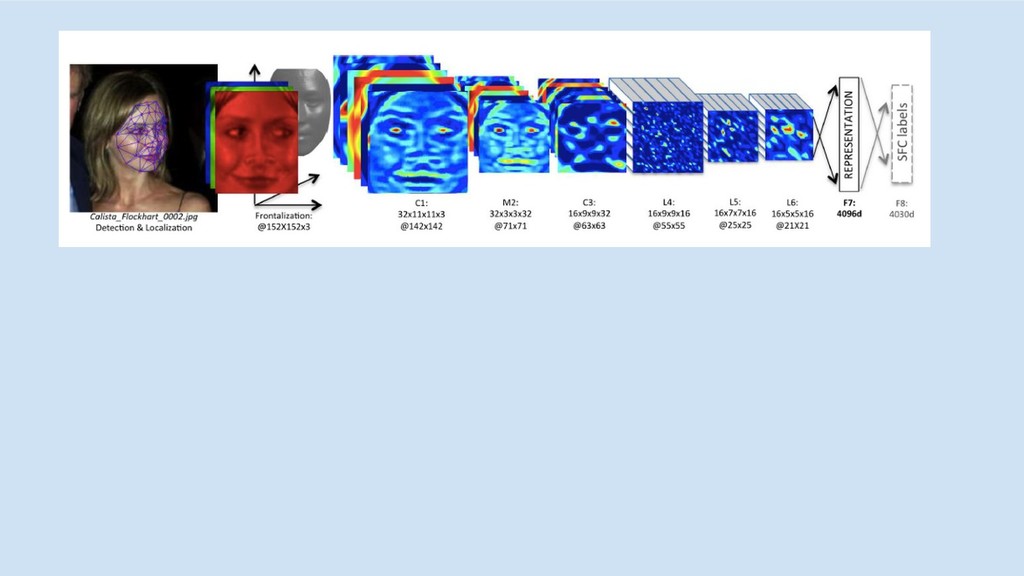
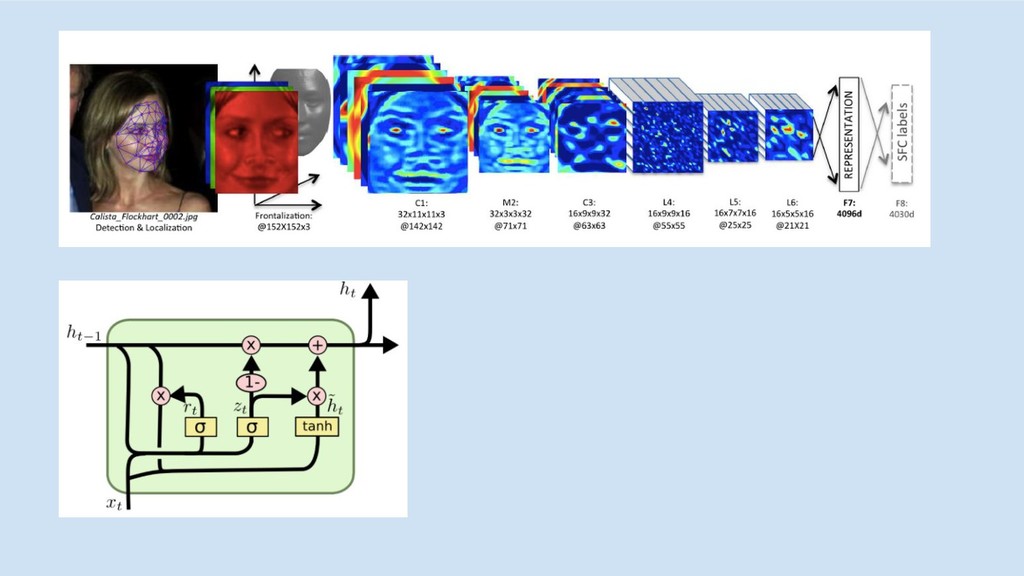
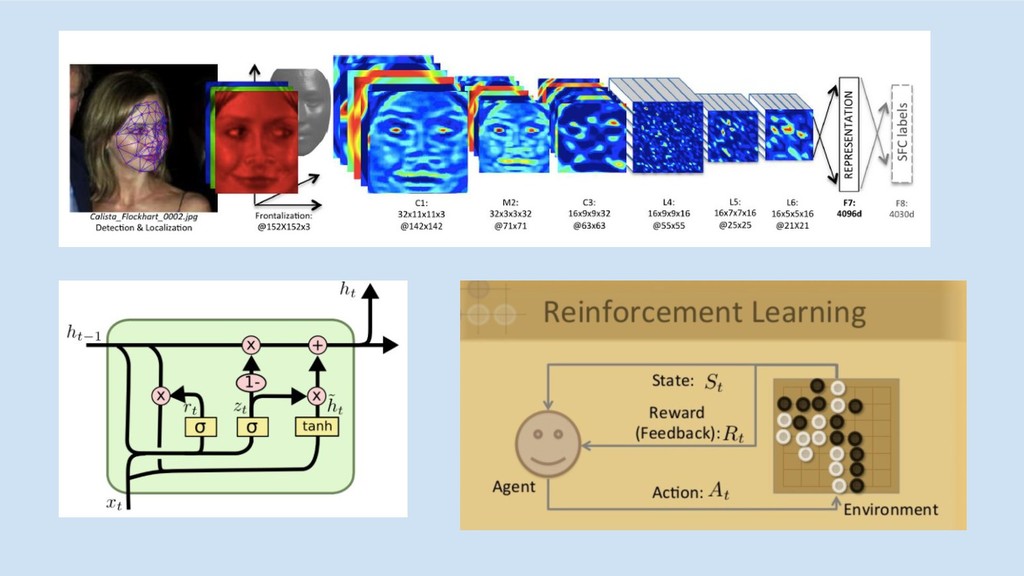
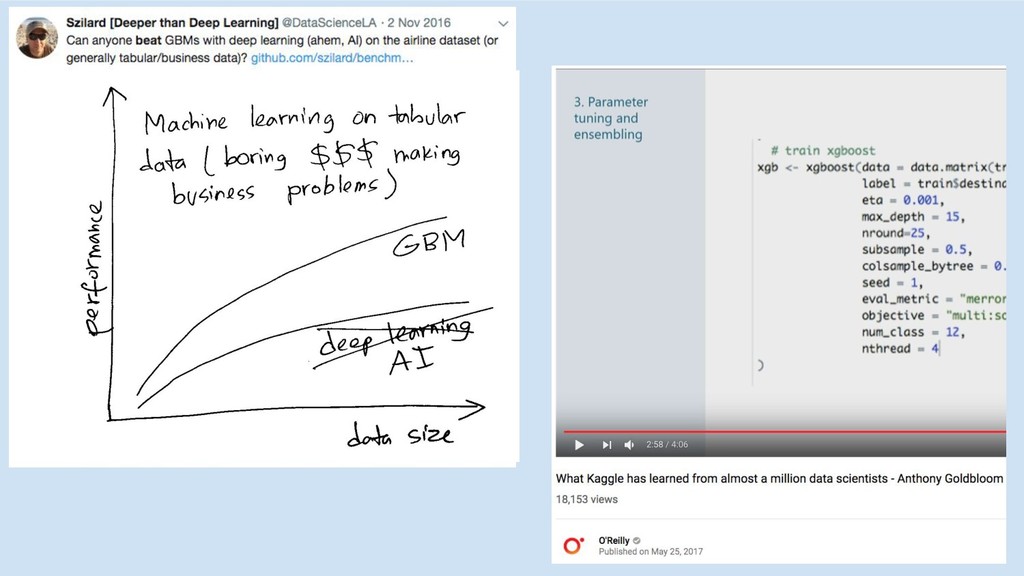
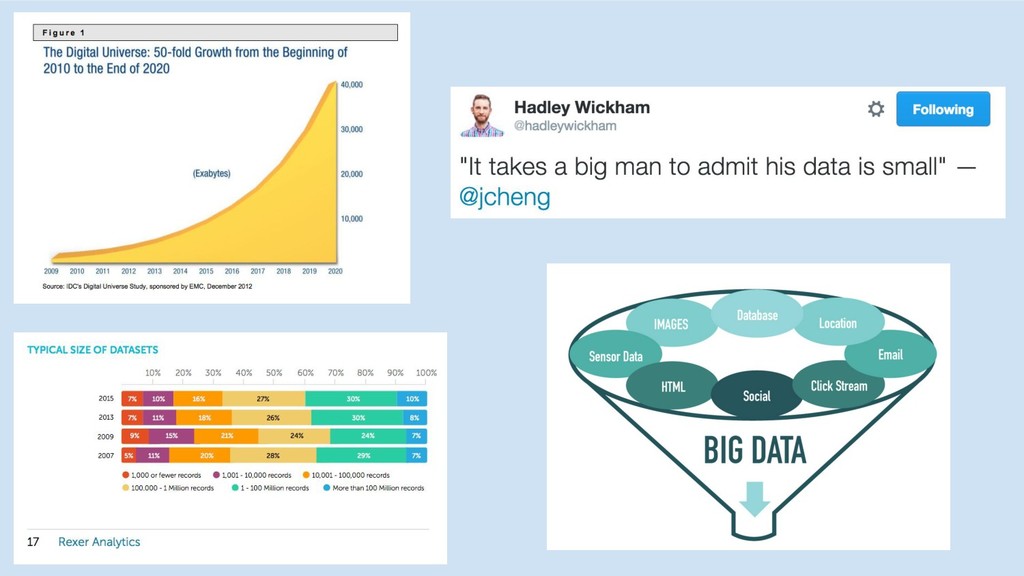
Why GBMs
None
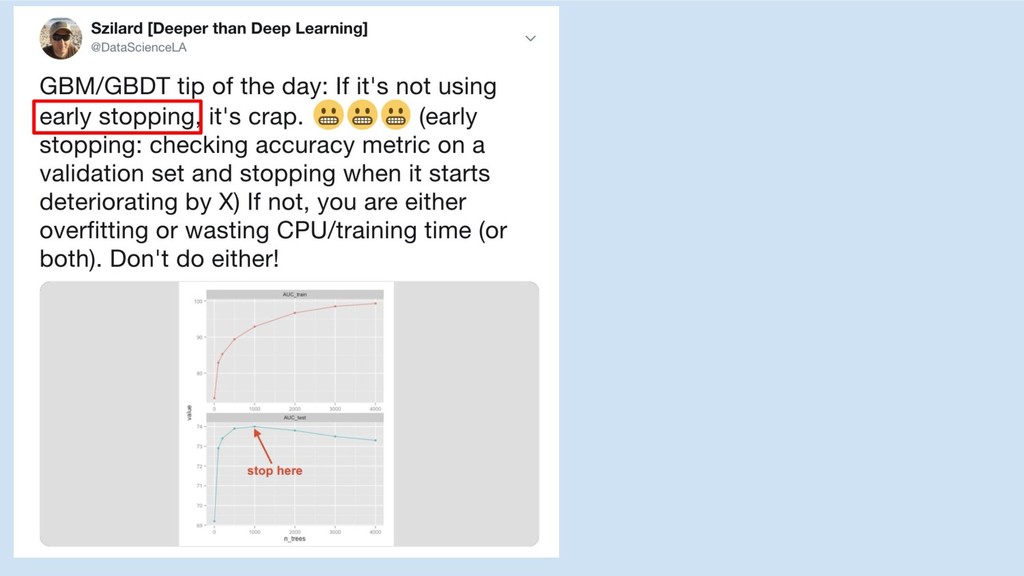
meetup/conference talks going deeper section dividers
None
Disclaimer: I am not representing my employer (Epoch) in this
talk I cannot confirm nor deny if Epoch is using any of the methods, tools, results etc. mentioned in this talk
Source: Andrew Ng
Source: Andrew Ng
Source: Andrew Ng
None
None
None
None
None
None
...
None
None
None
None
None
None
None
None
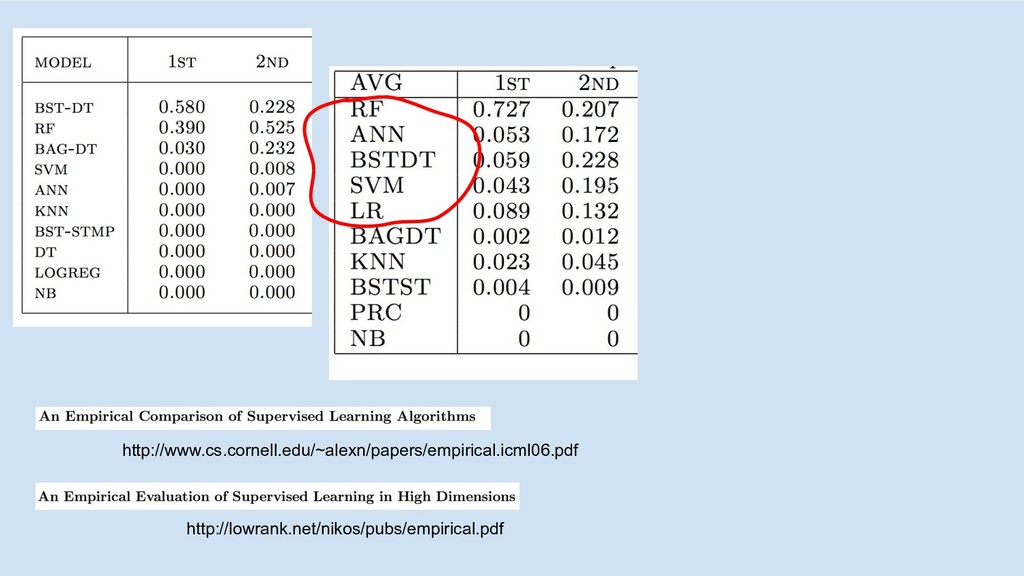
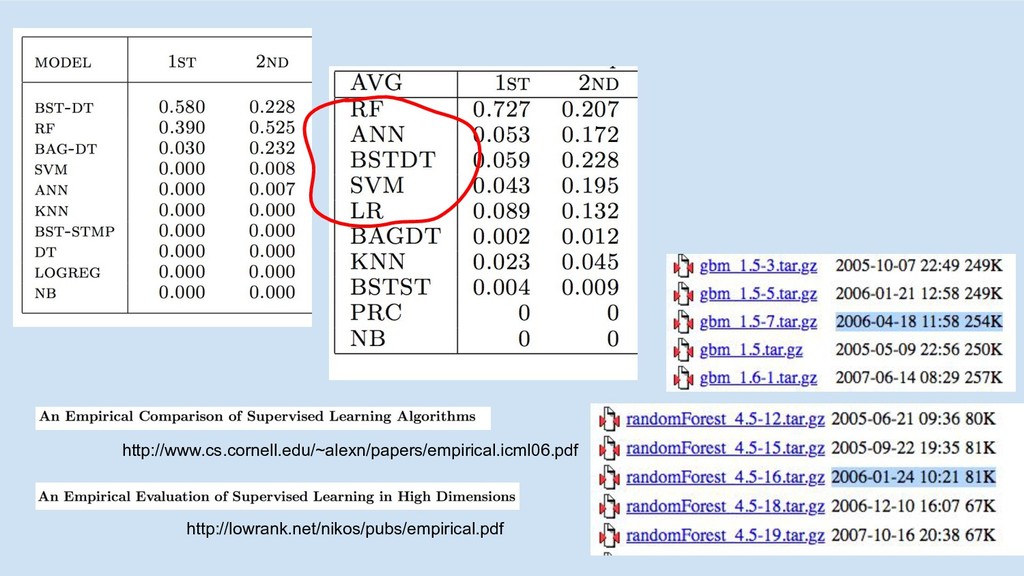
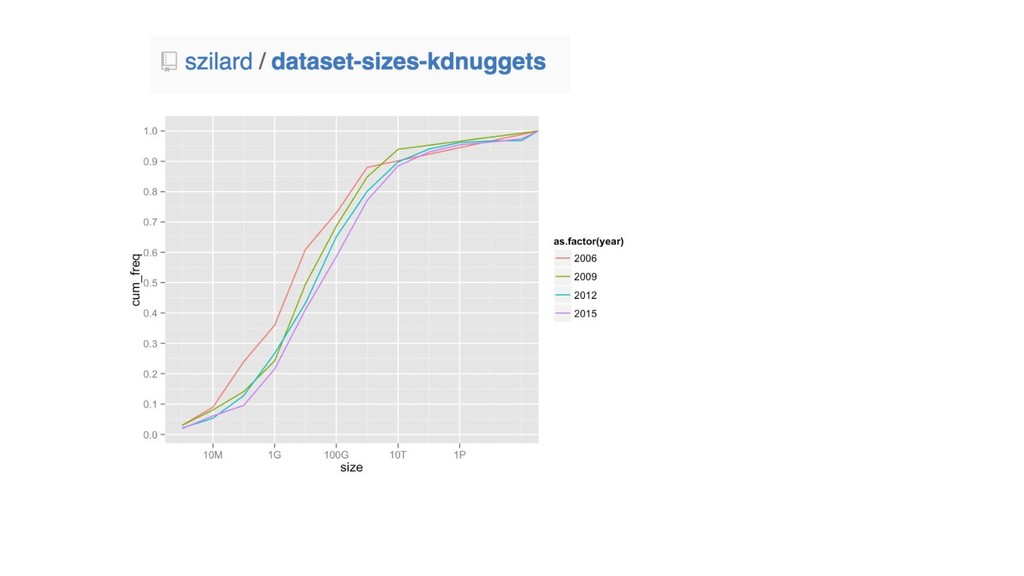
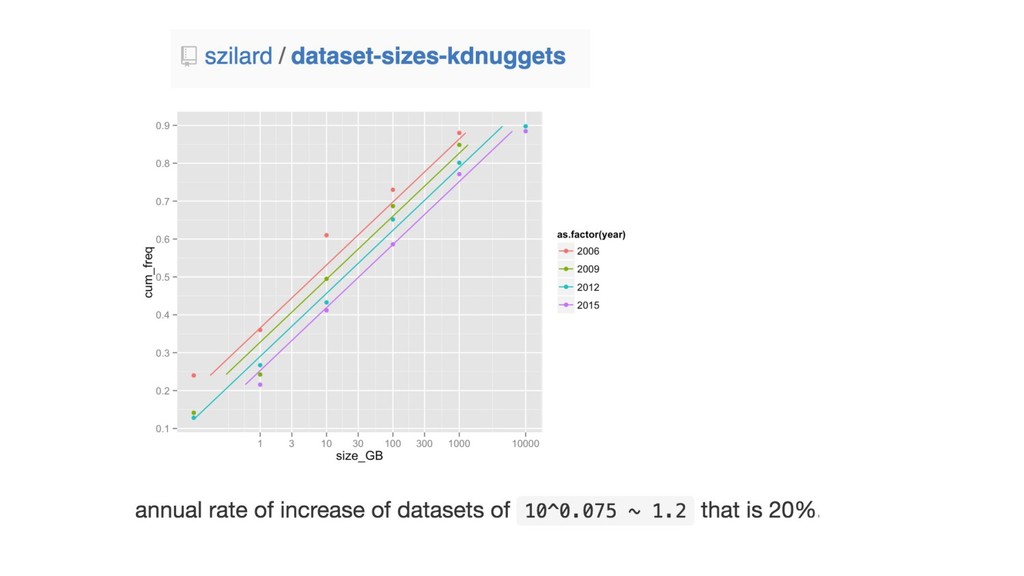
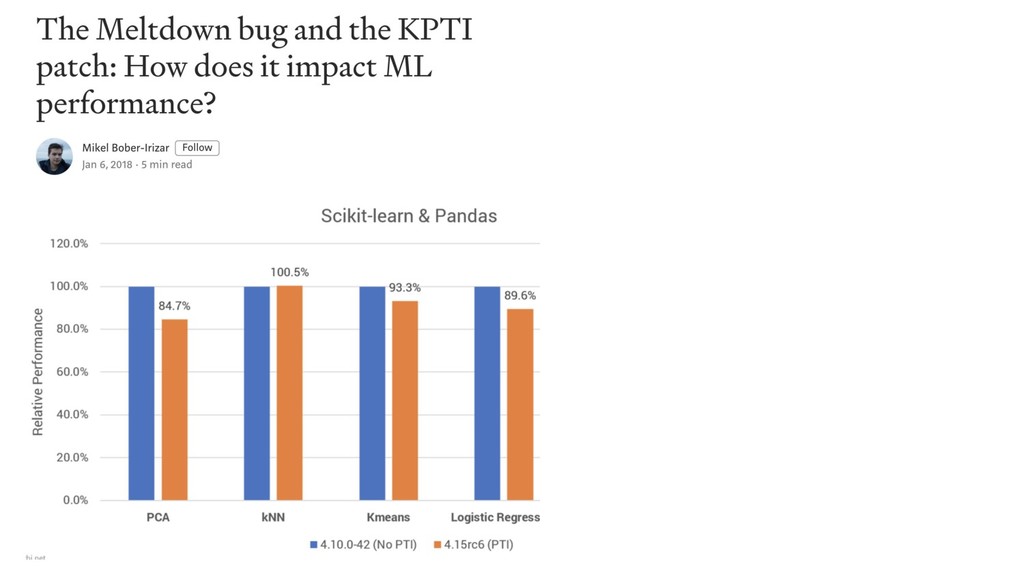
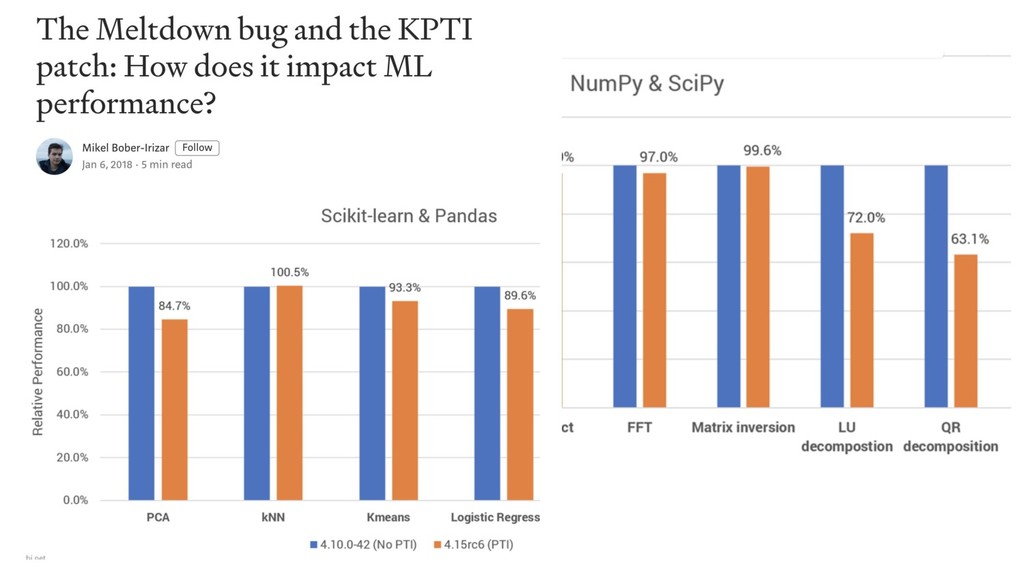
http://lowrank.net/nikos/pubs/empirical.pdf http://www.cs.cornell.edu/~alexn/papers/empirical.icml06.pdf
http://lowrank.net/nikos/pubs/empirical.pdf http://www.cs.cornell.edu/~alexn/papers/empirical.icml06.pdf
None
None
None
None
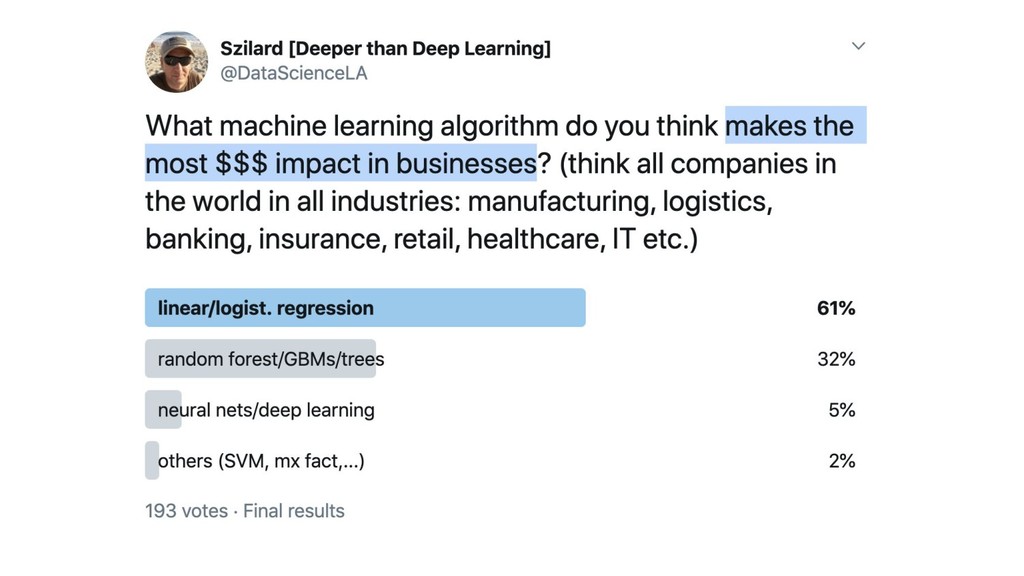
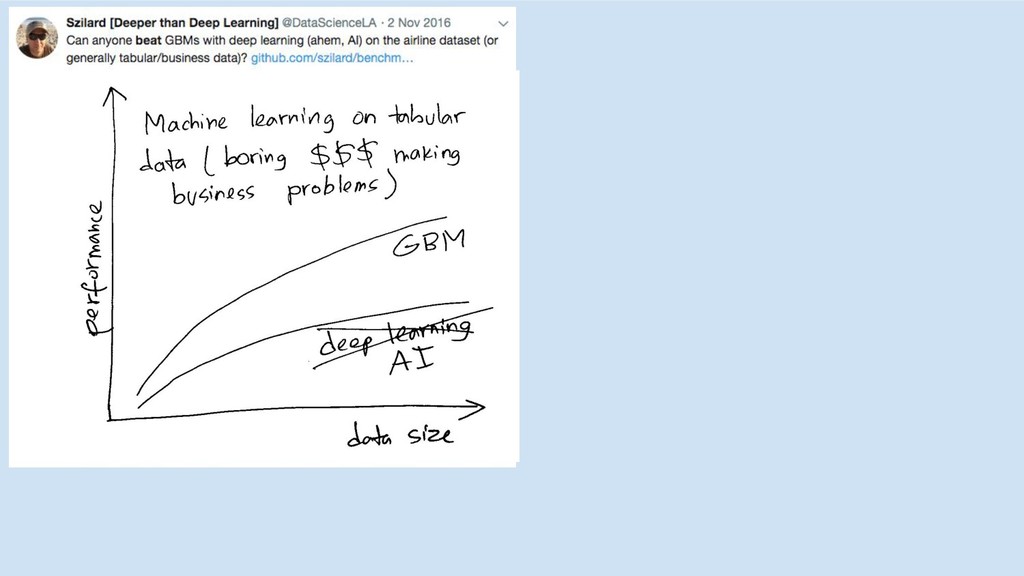
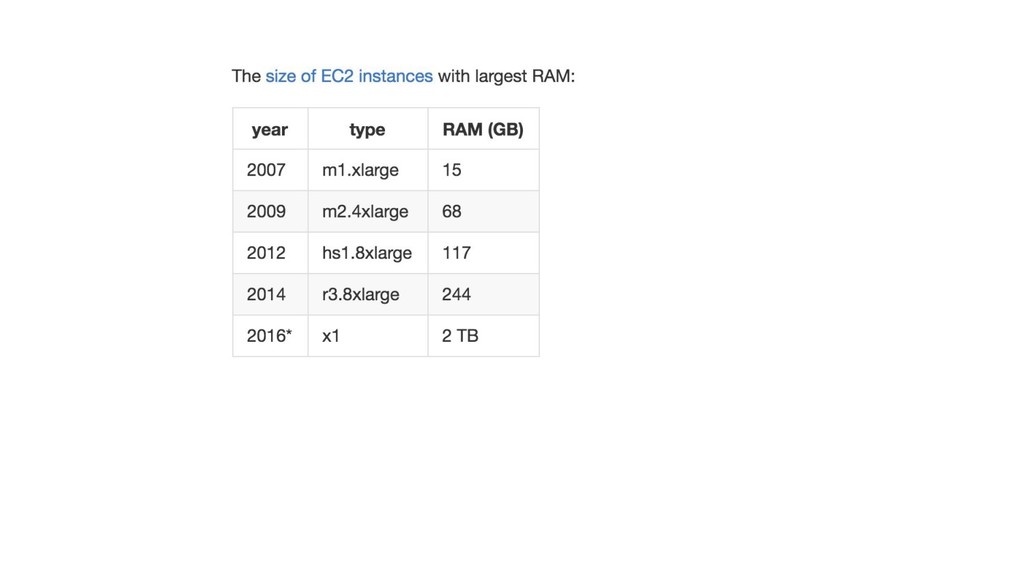
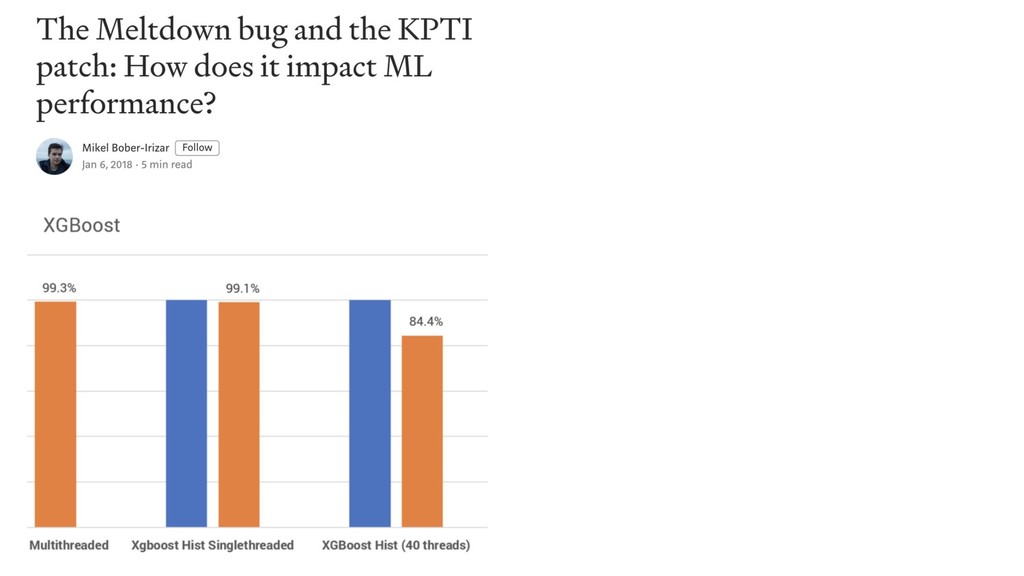
top algos (RF, boosting), all features 2007
top algos (RF, boosting), all features most algos (lin, tree,
nnet) worst algos (knn, NB) 2007
top algos (RF, boosting), all features most algos (lin, tree,
nnet) worst algos (knn, NB) top algos, removed top feature(s) 2007
None
None
None
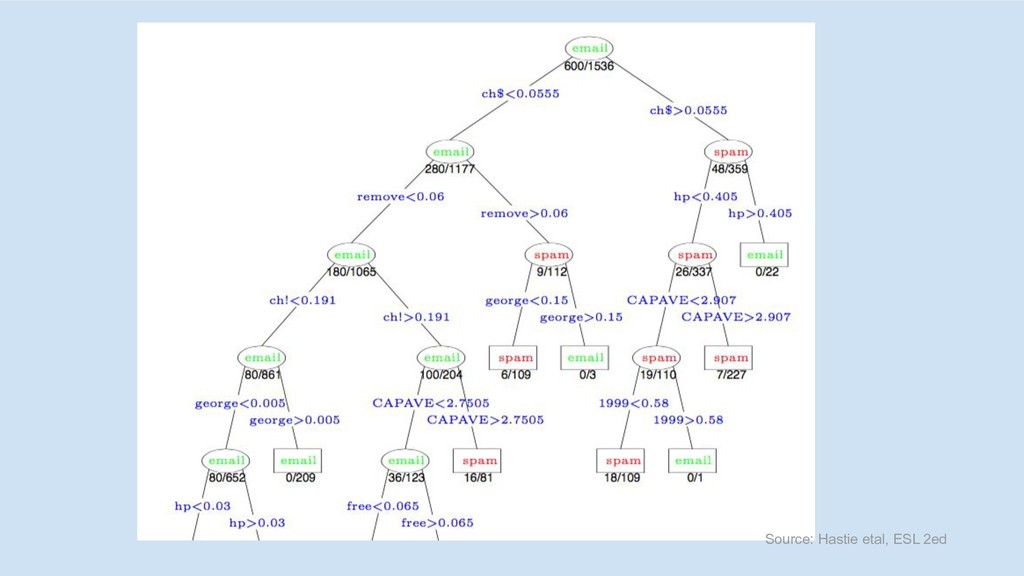
Source: Hastie etal, ESL 2ed
Source: Hastie etal, ESL 2ed
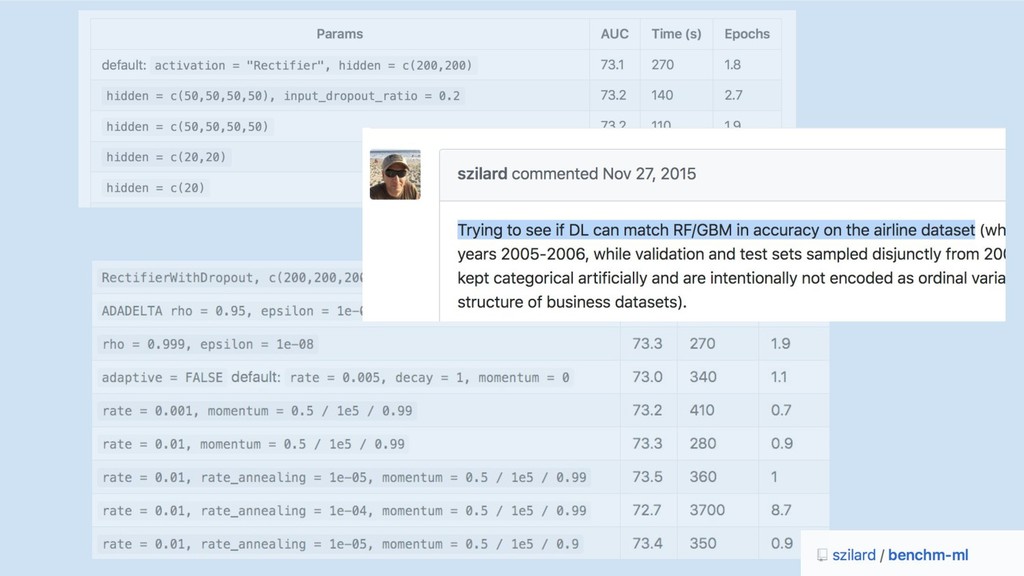
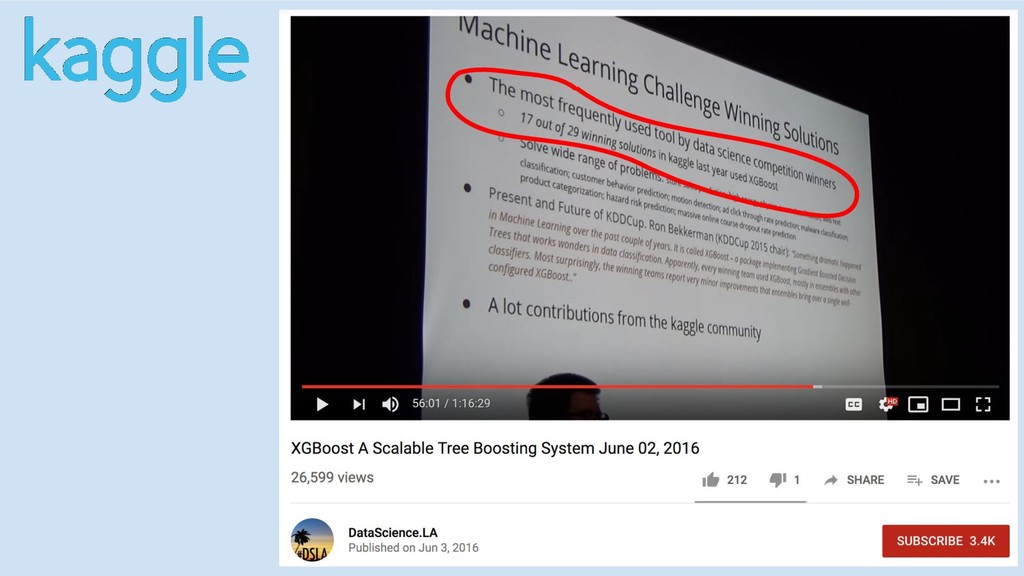
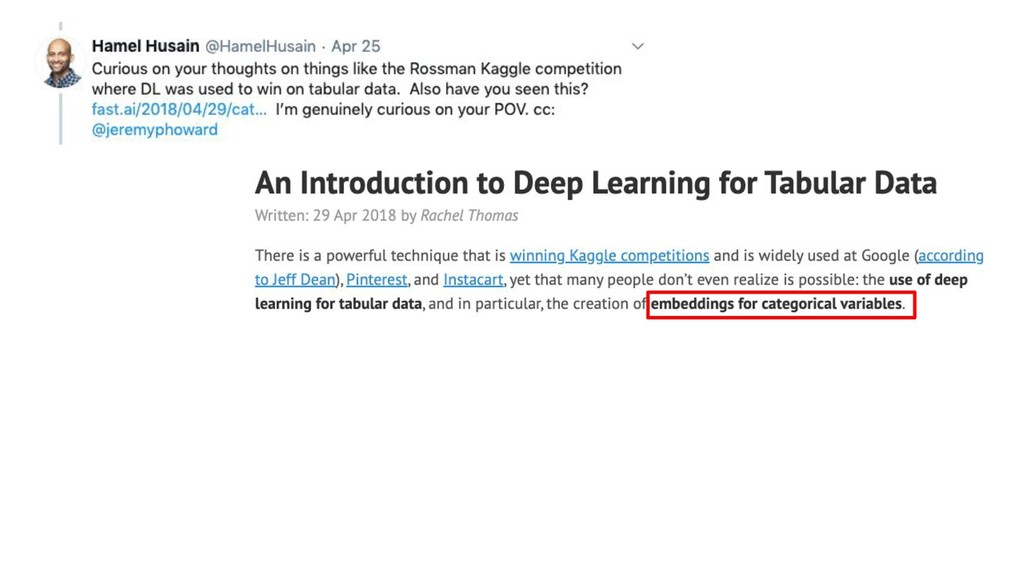
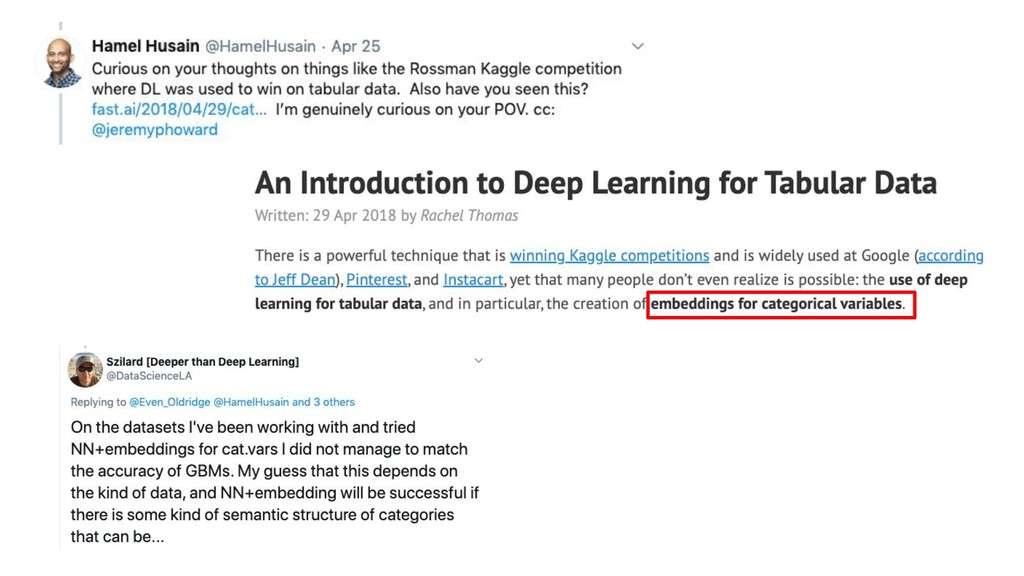
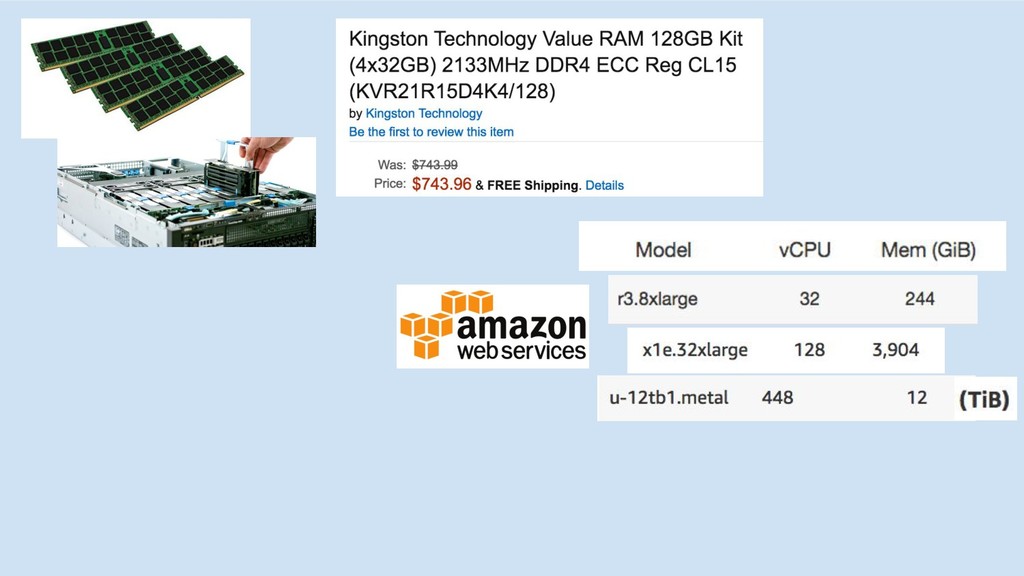
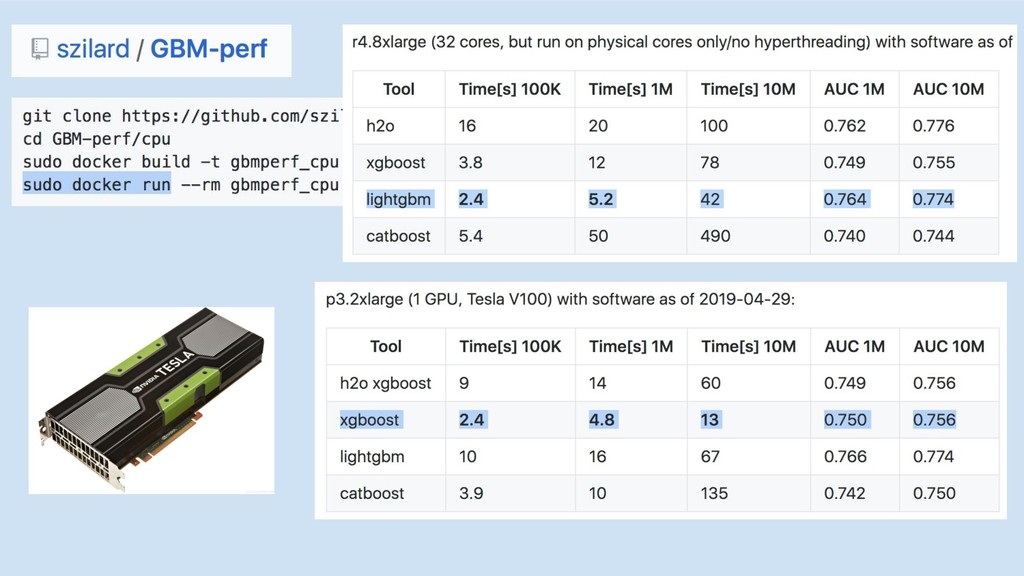
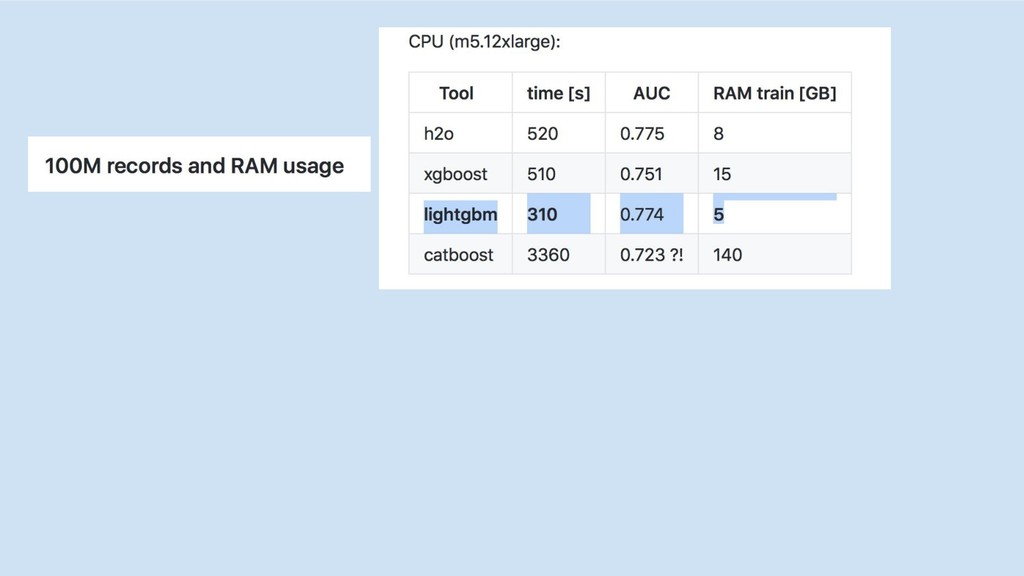
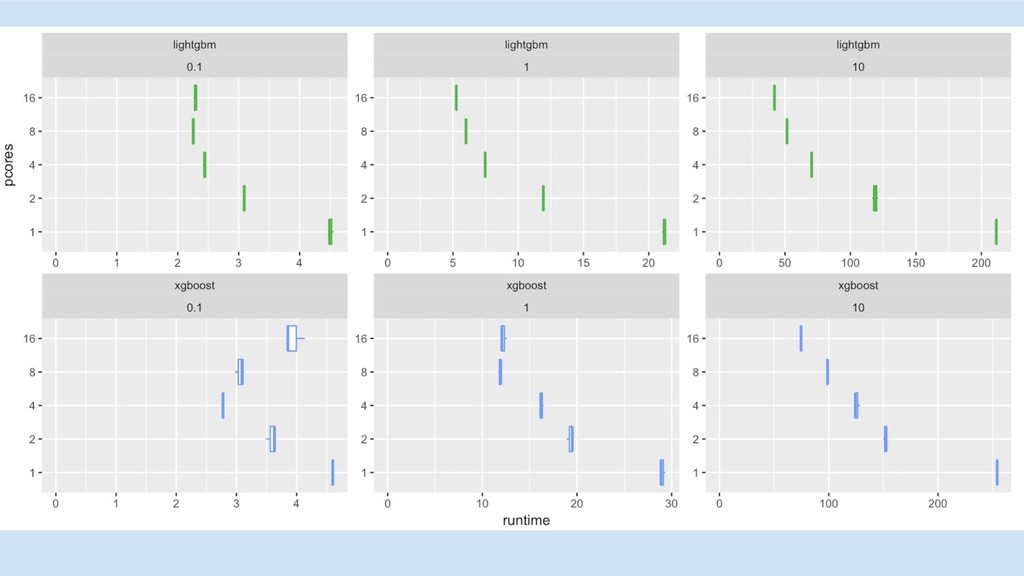
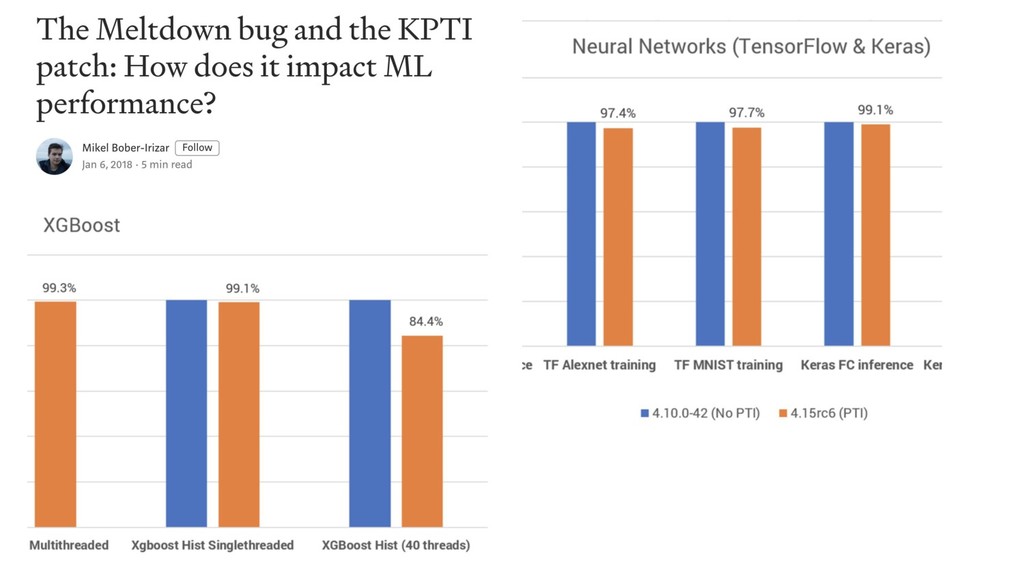
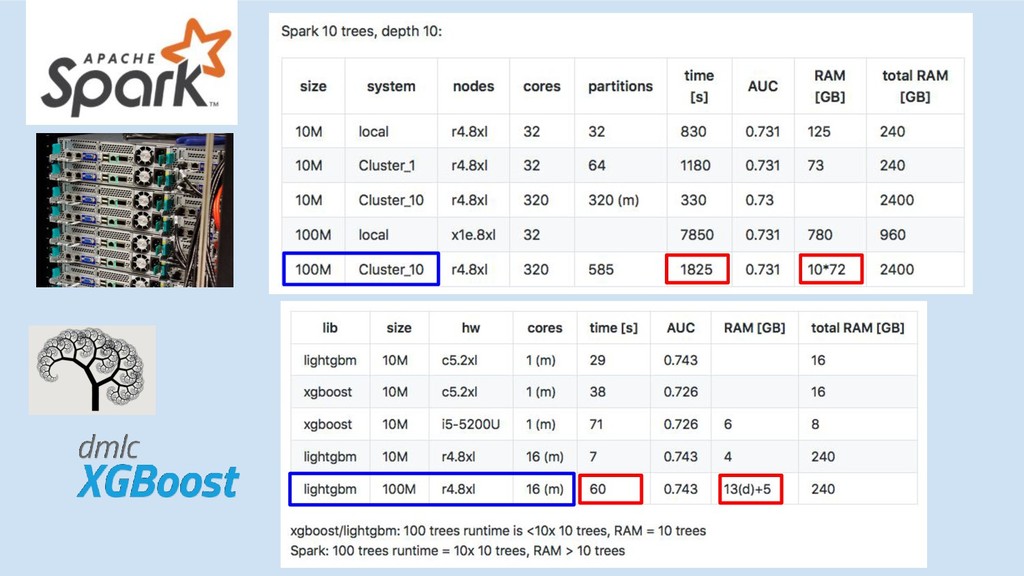
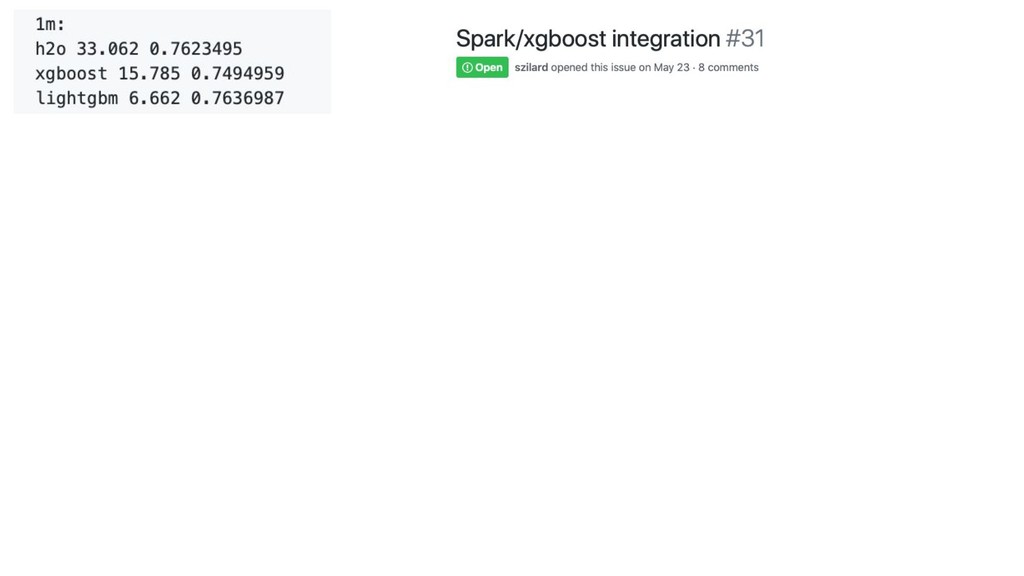
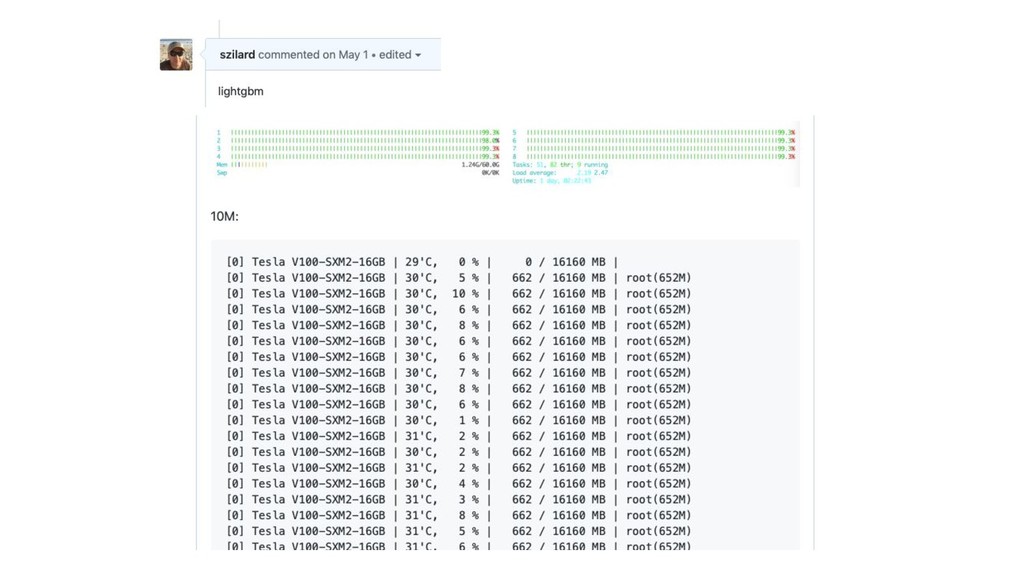
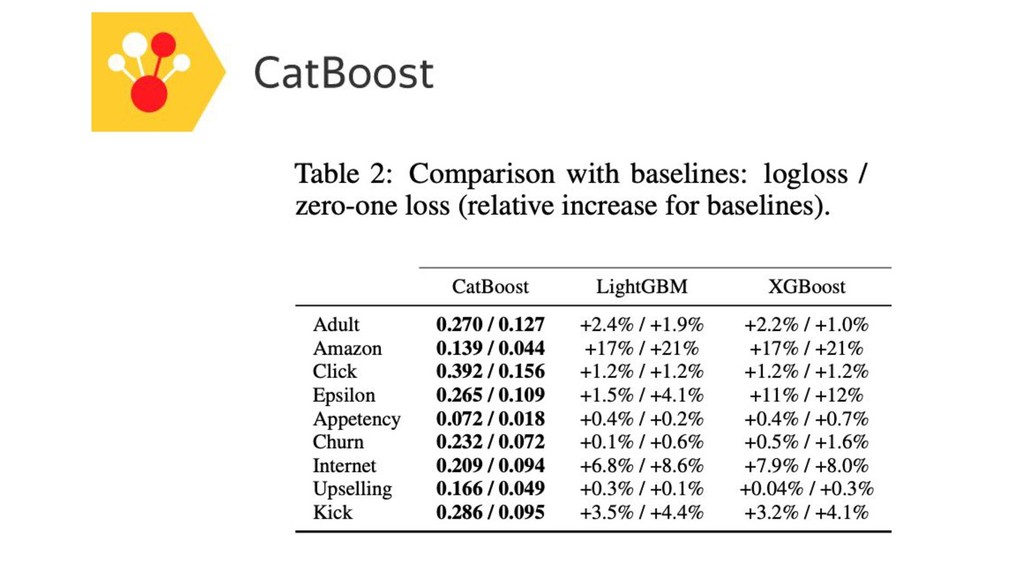
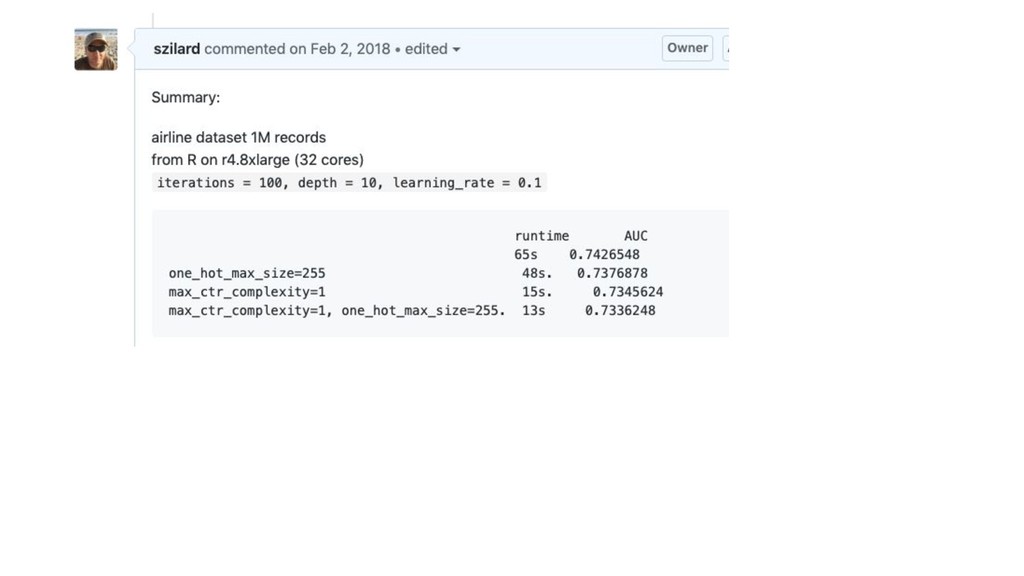
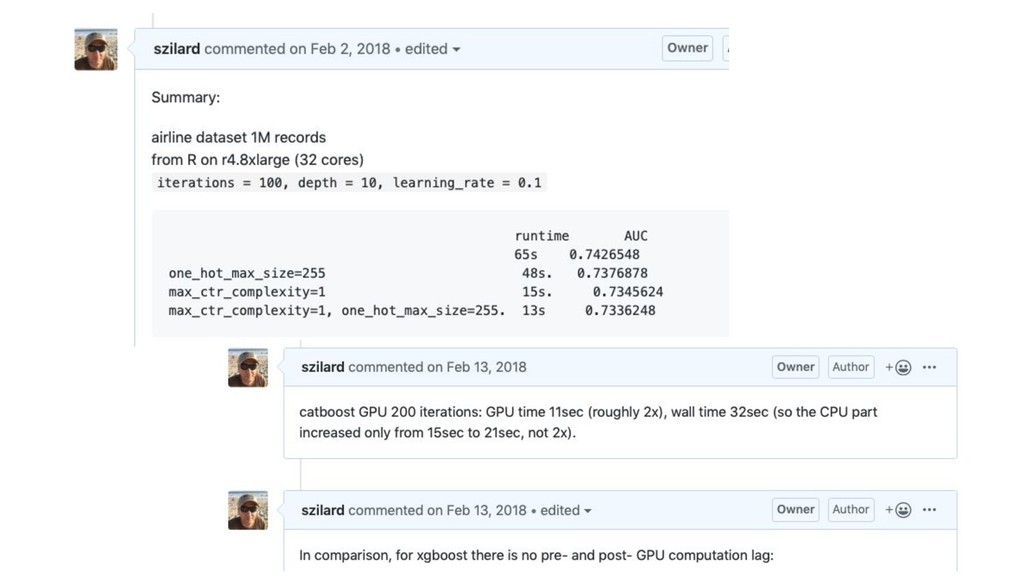
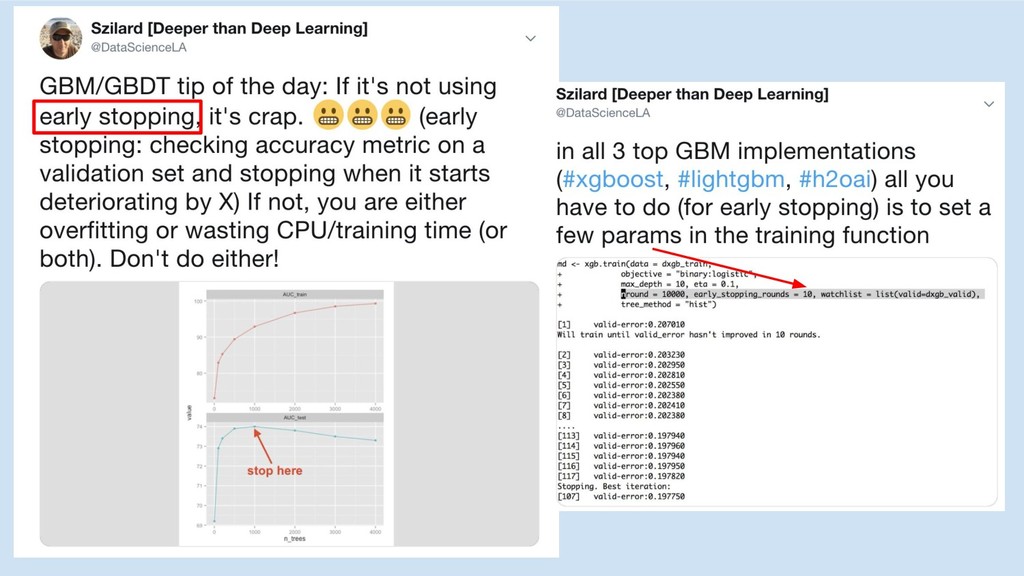
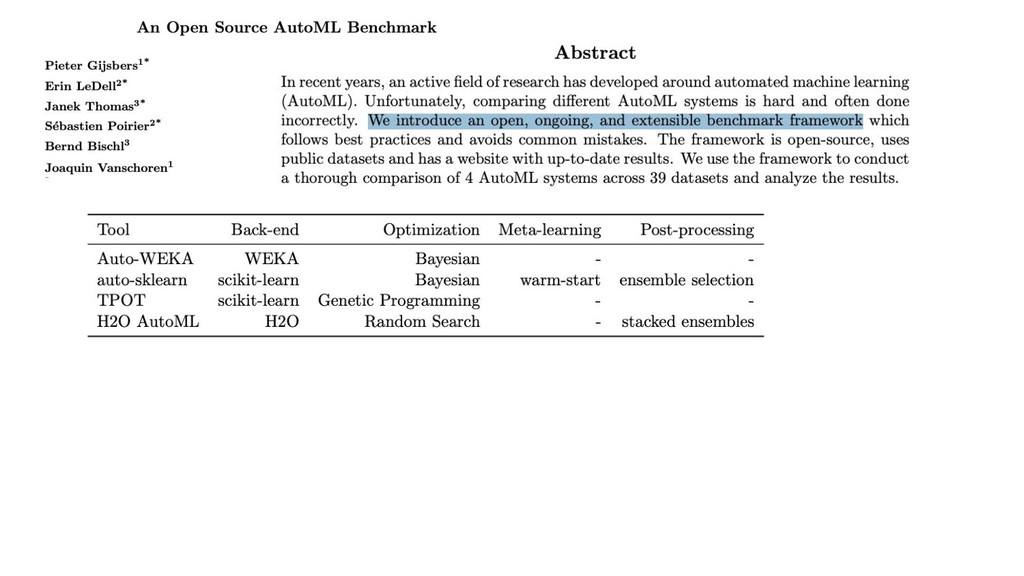
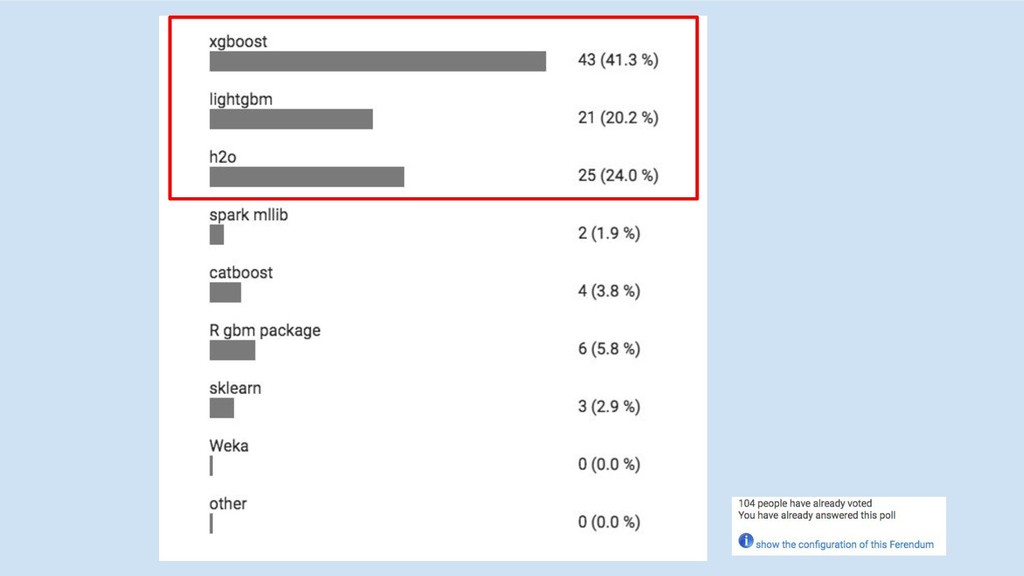
GBM libs
None
None
None
None
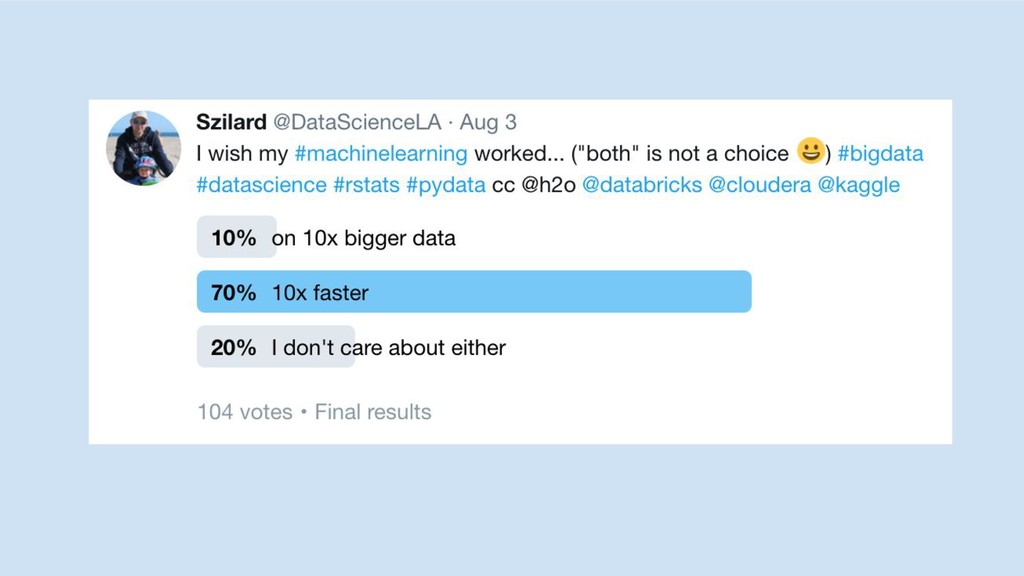
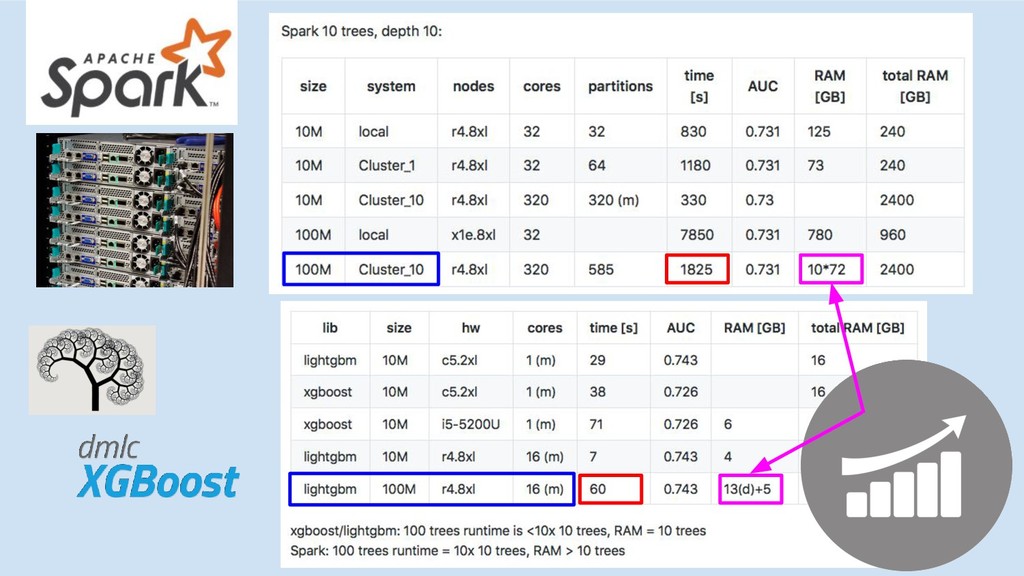
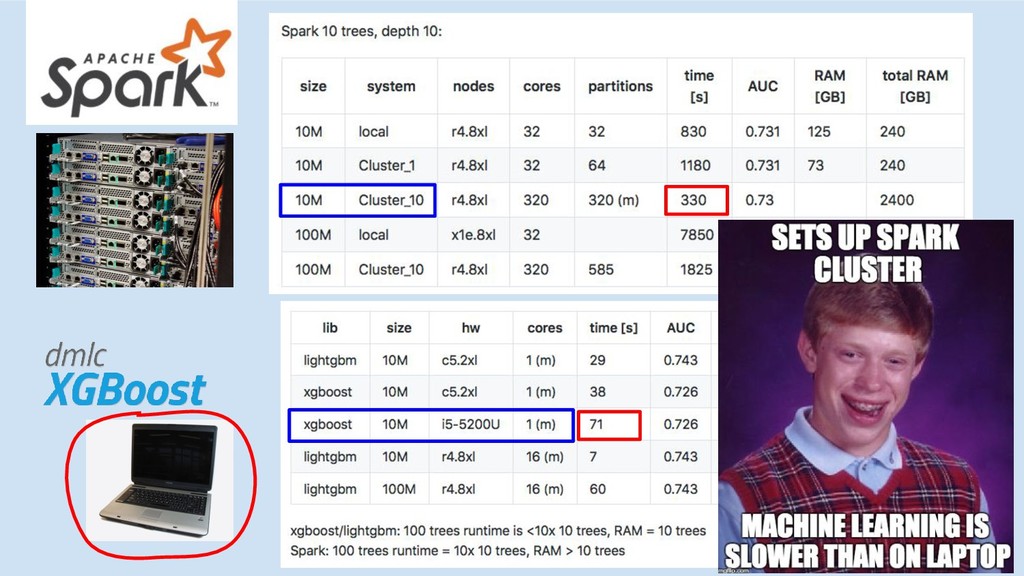
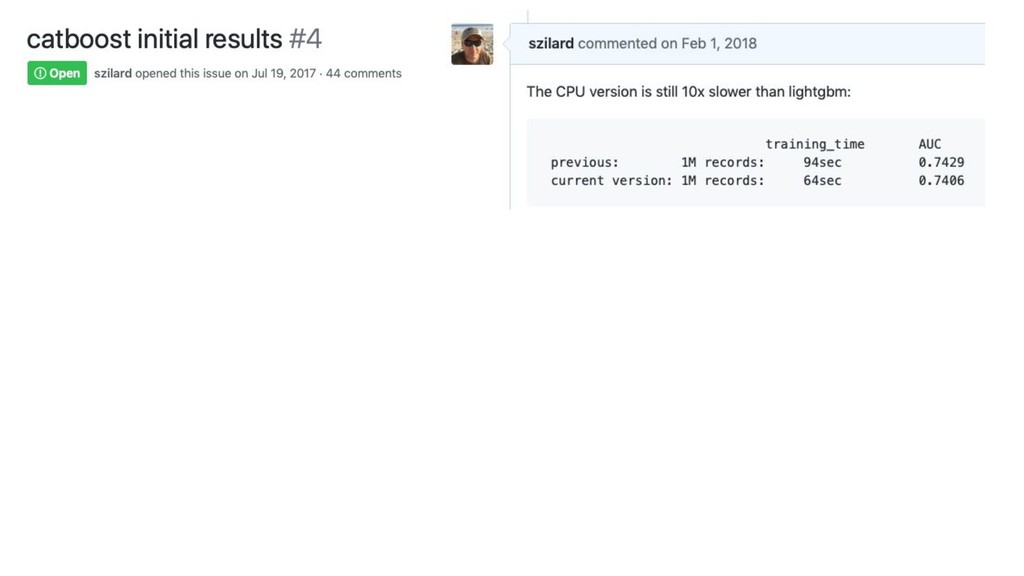
10x
10x
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
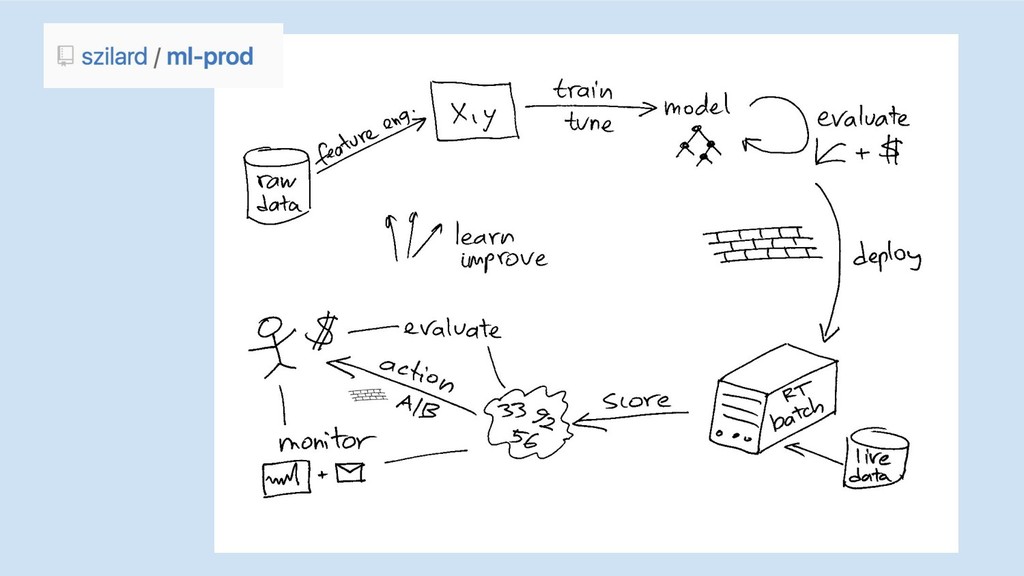
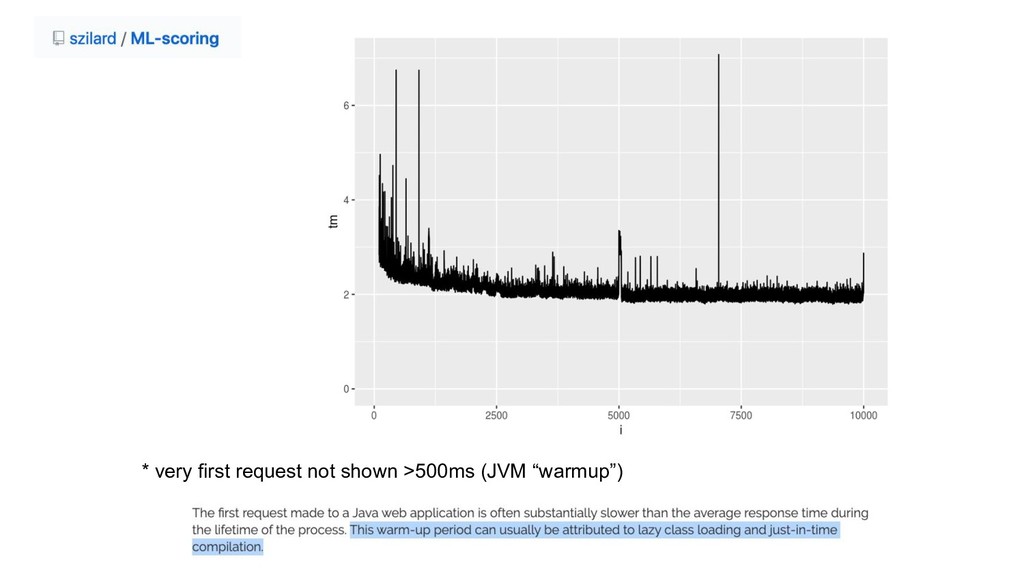
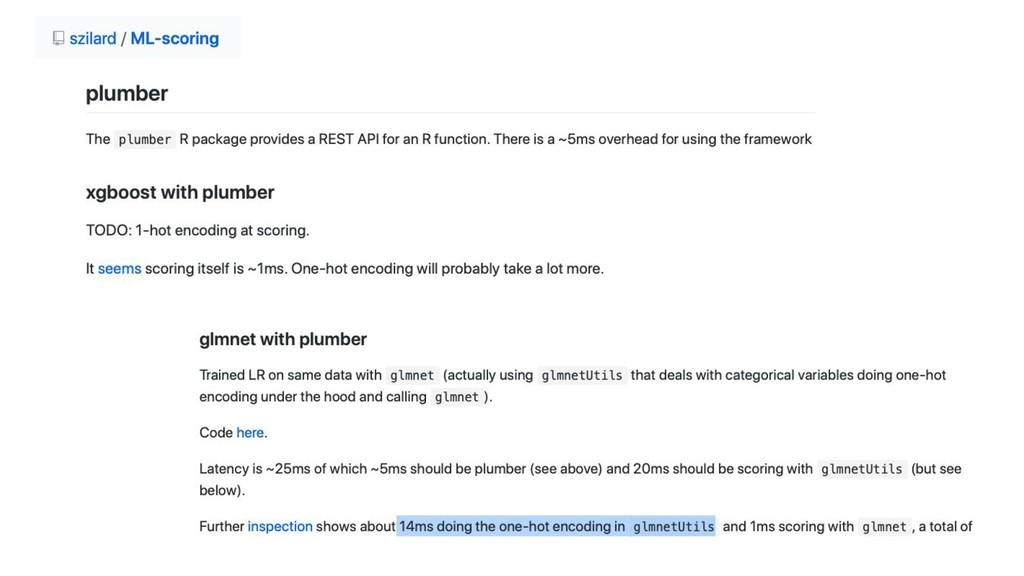
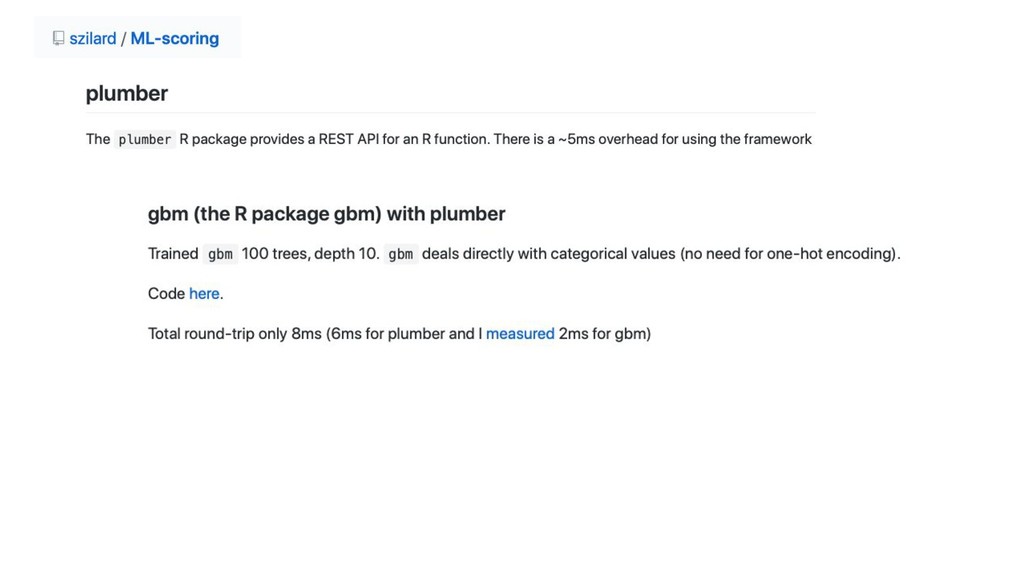
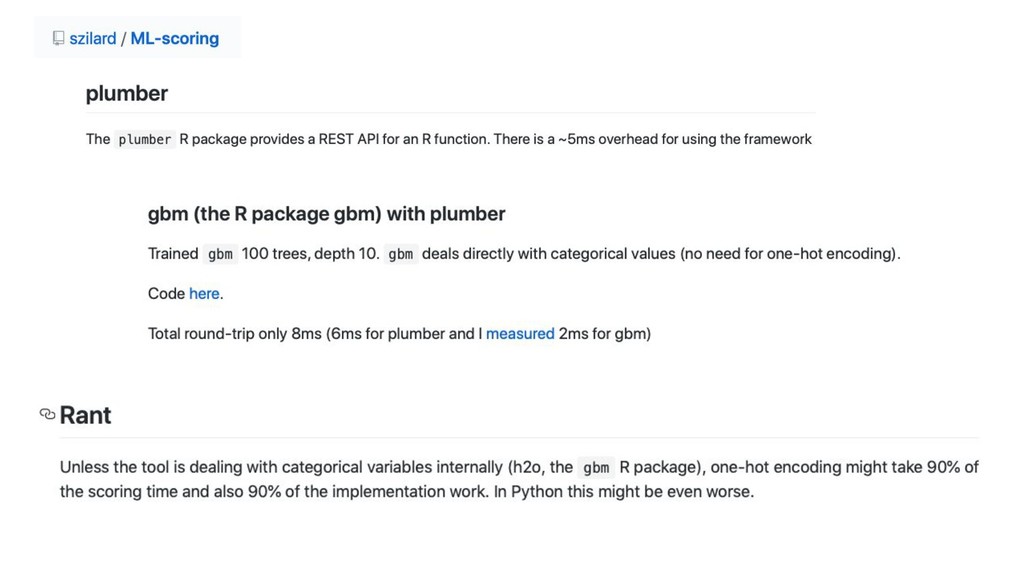
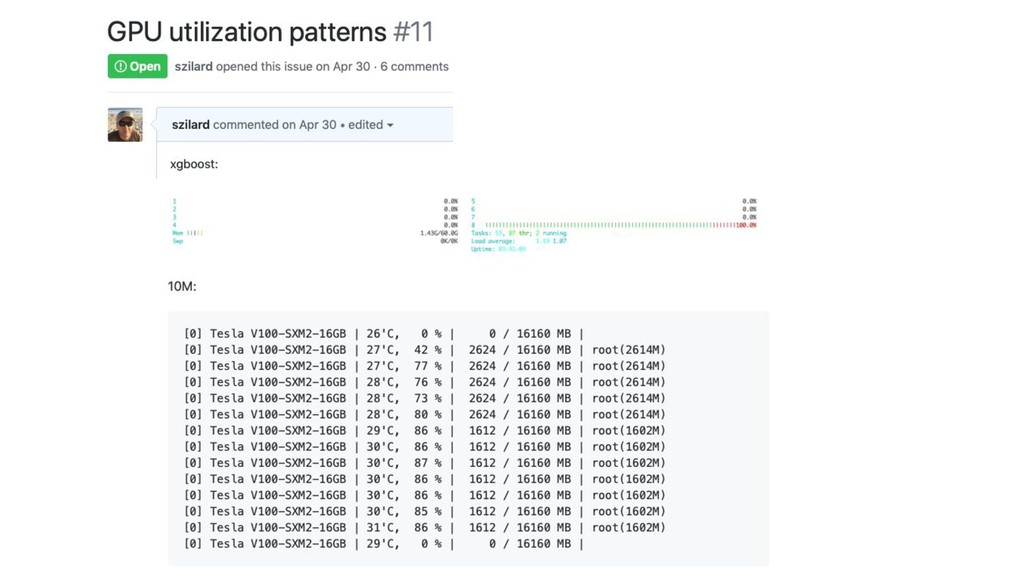
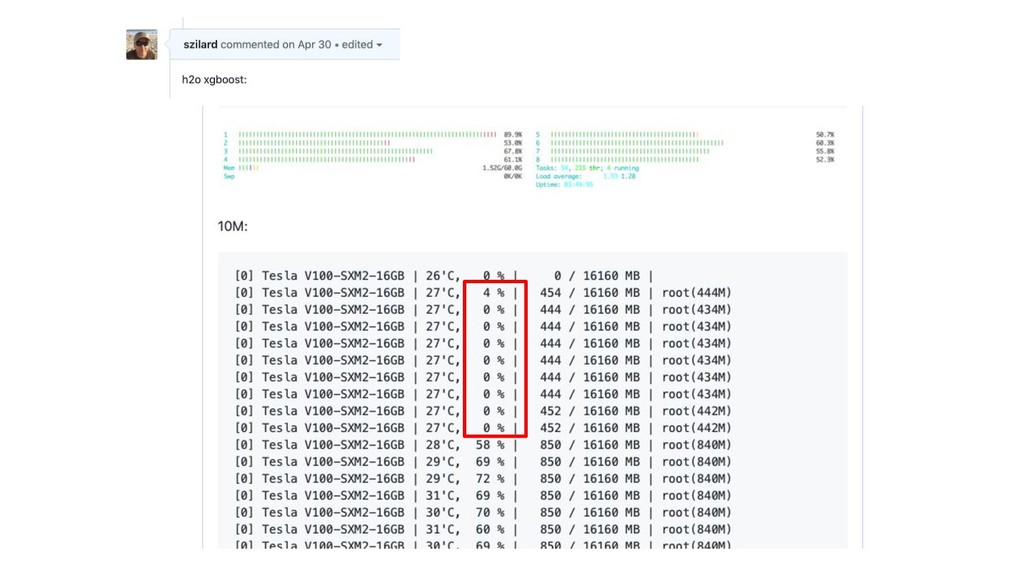
Scoring
None
None
None
None
None
* very first request not shown >500ms (JVM “warmup”)
None
None
None
None
None
None
None
None
None
None
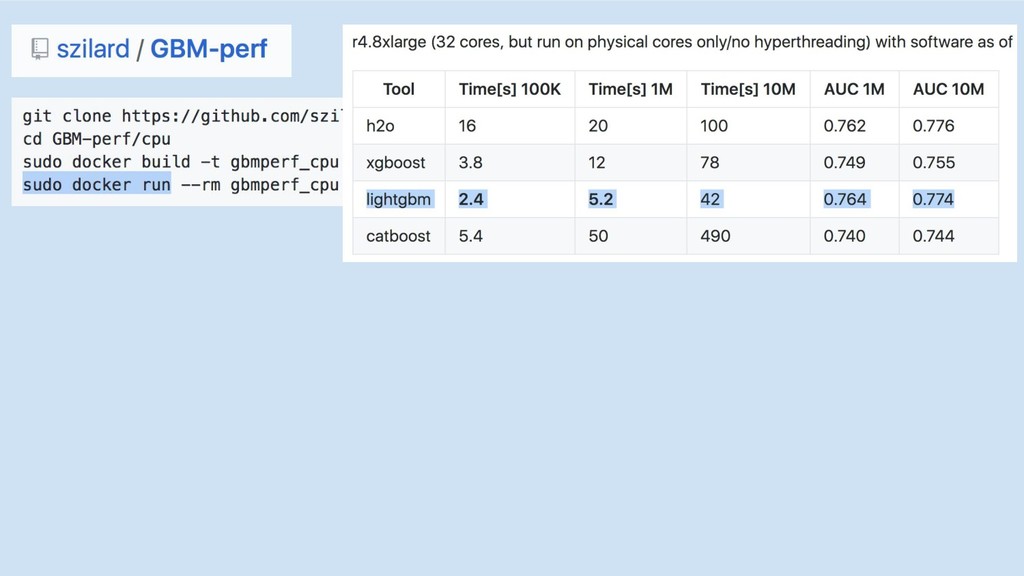
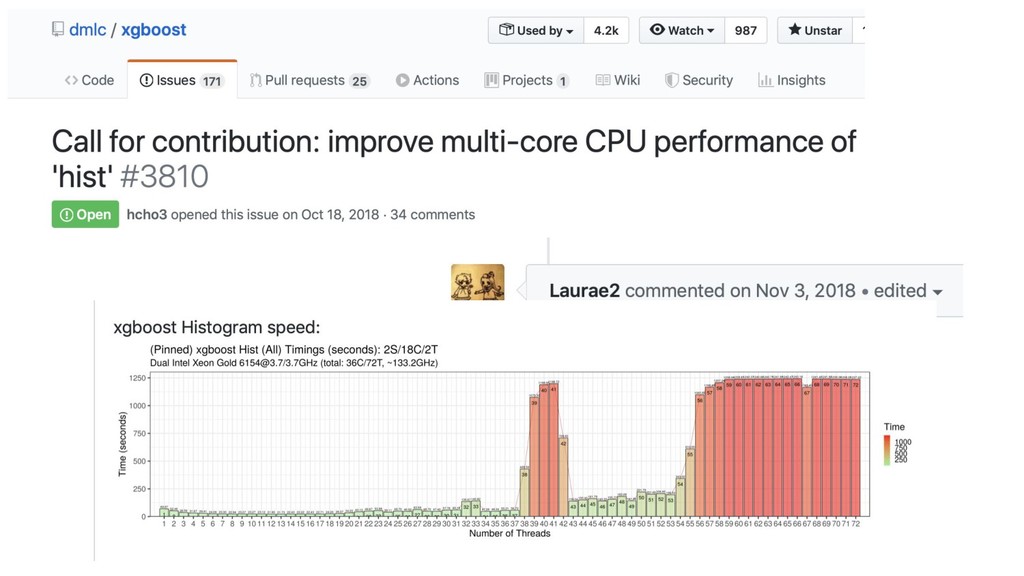
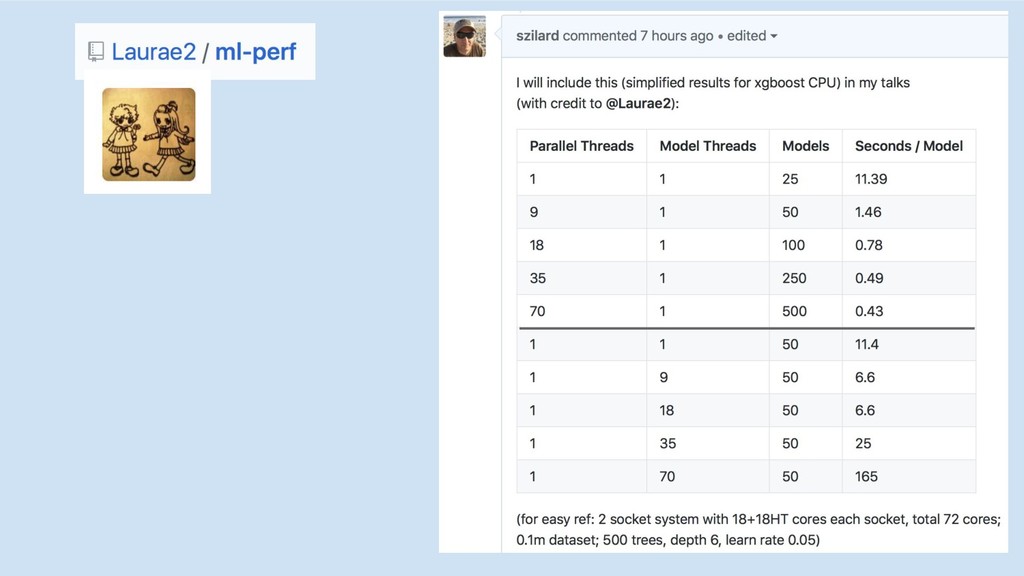
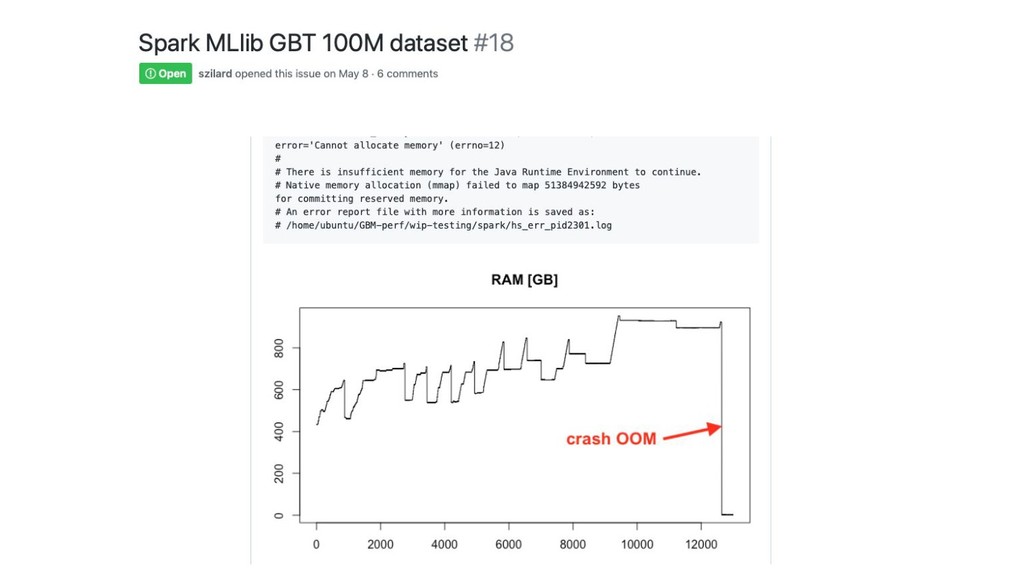
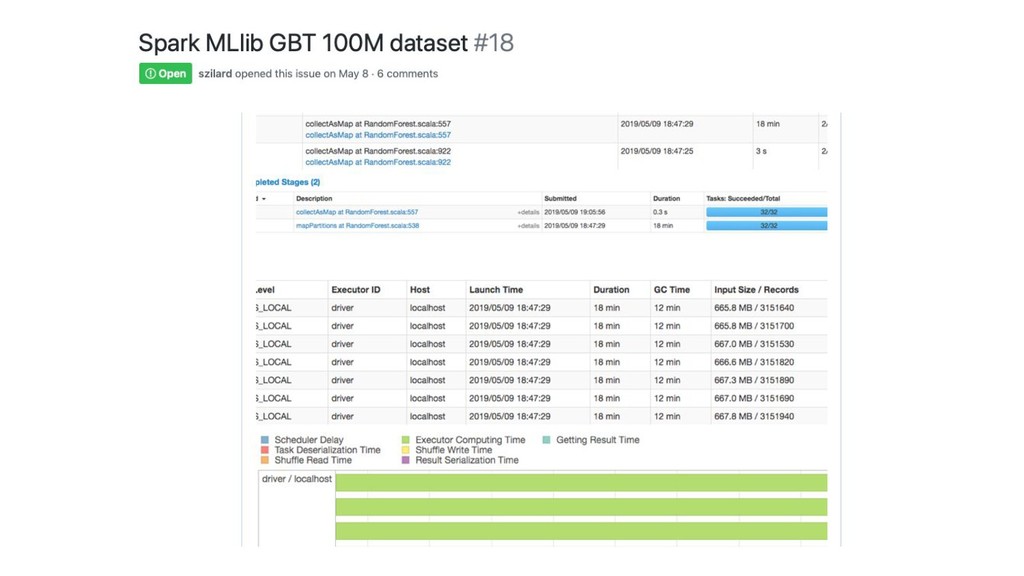
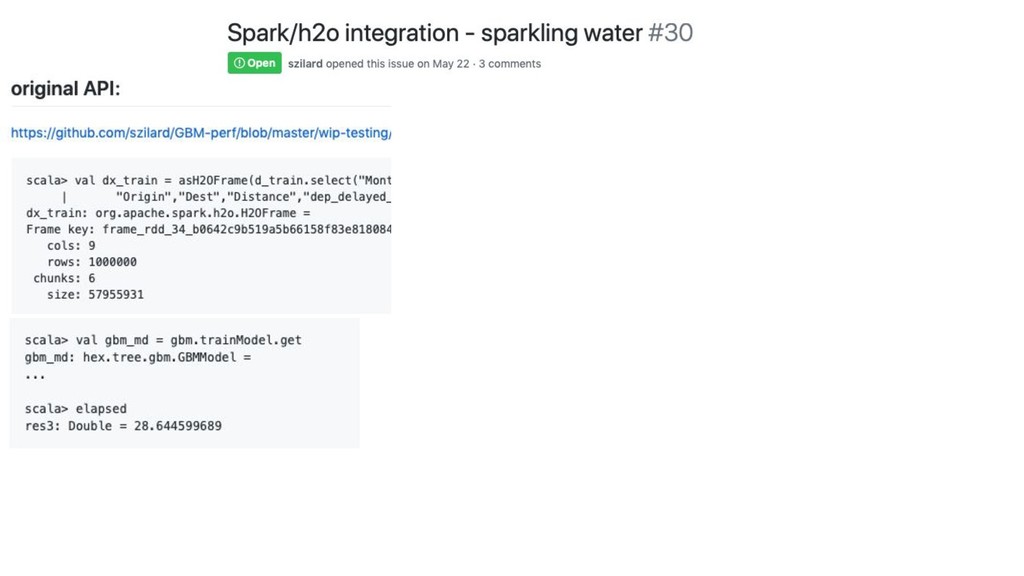
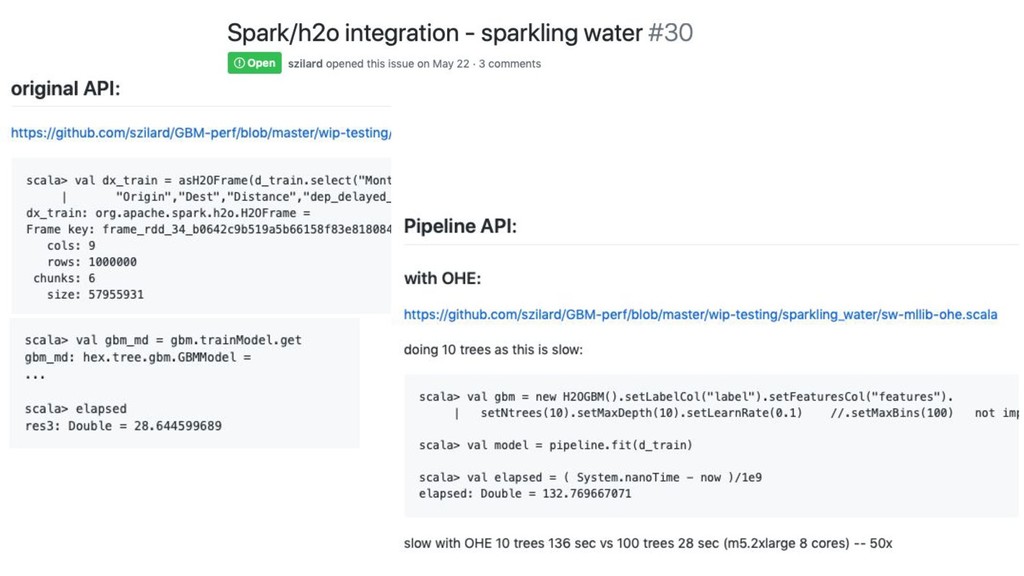
GBM-perf github repo
None
None
None
None
None
None
None
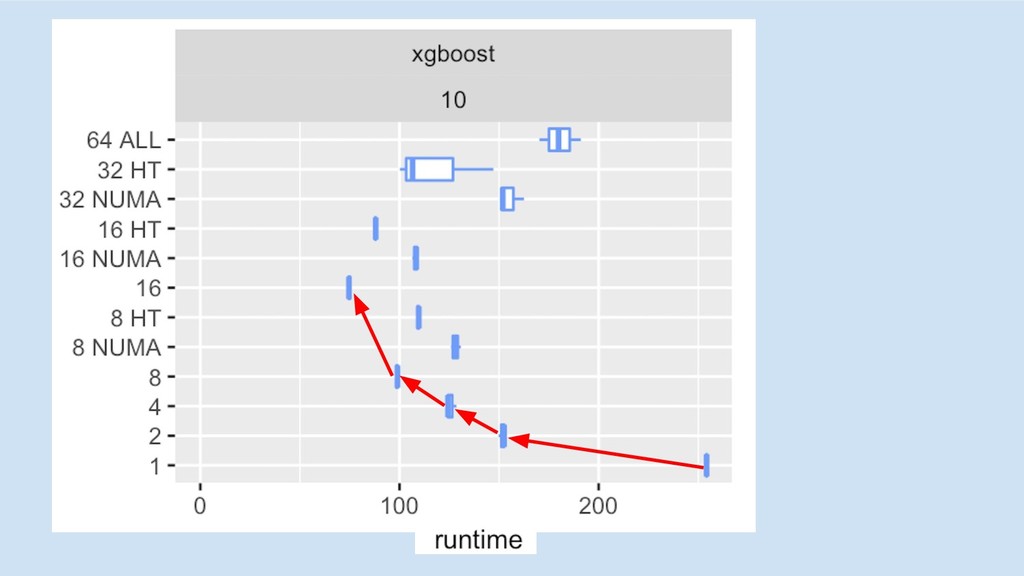
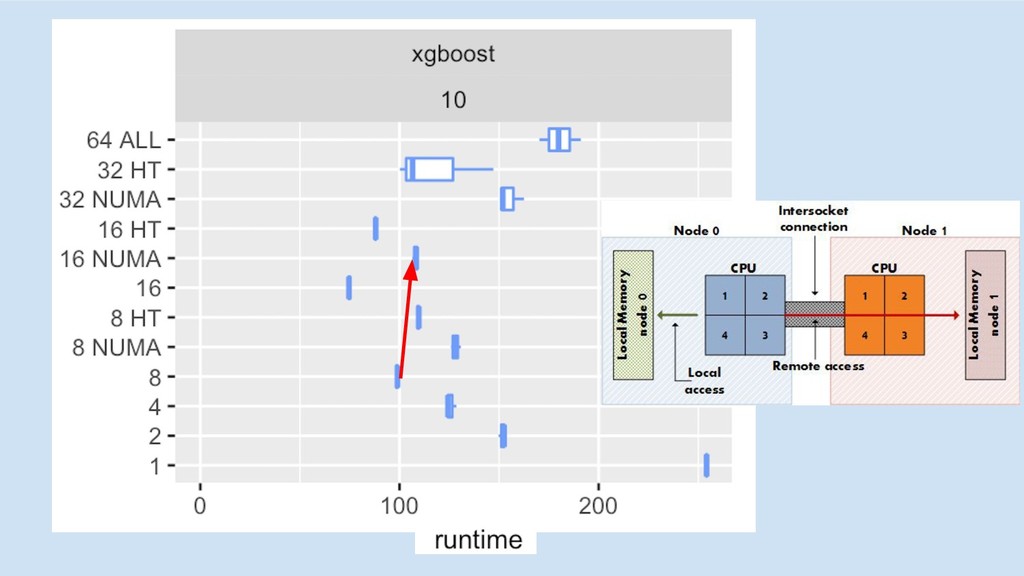
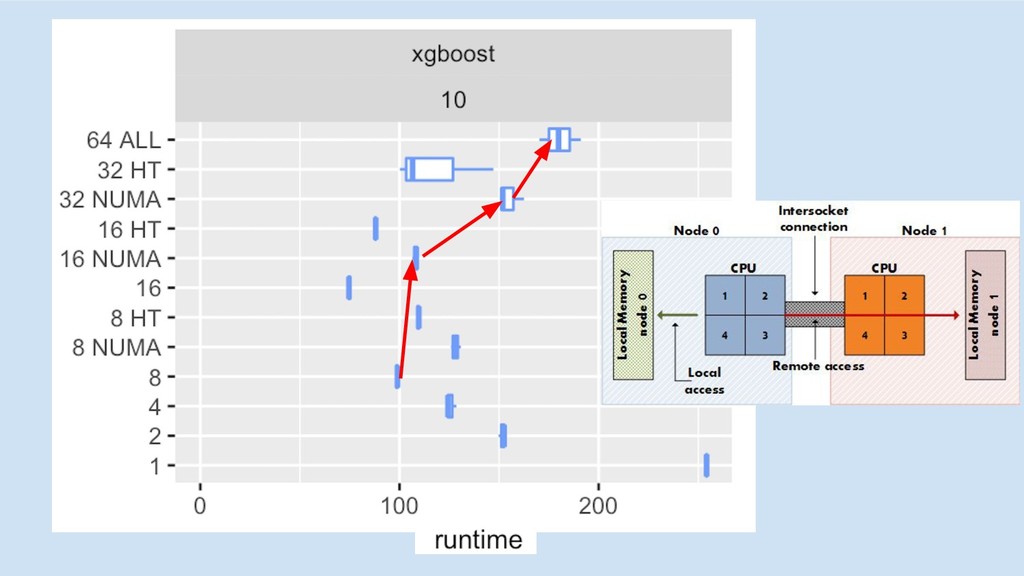
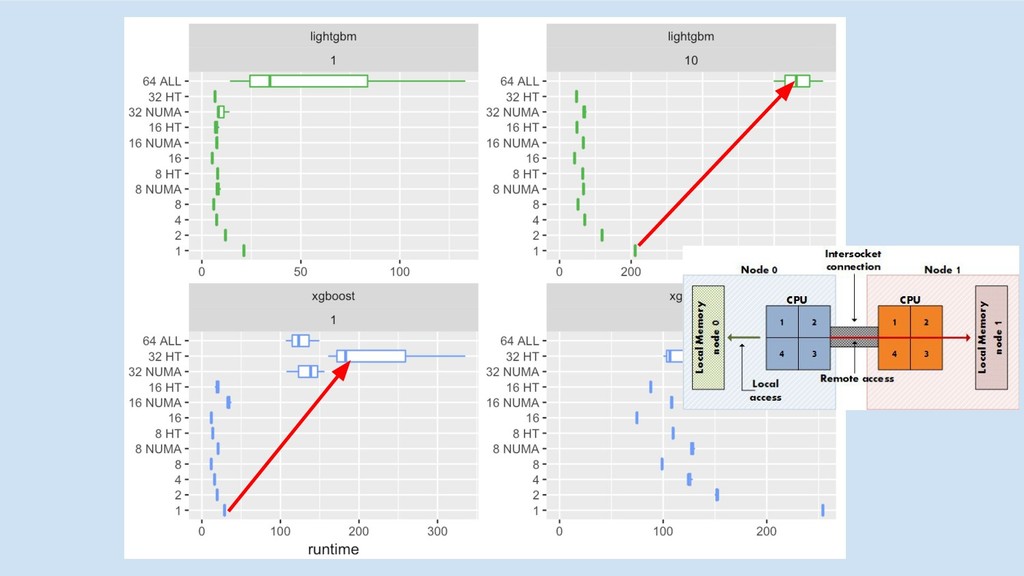
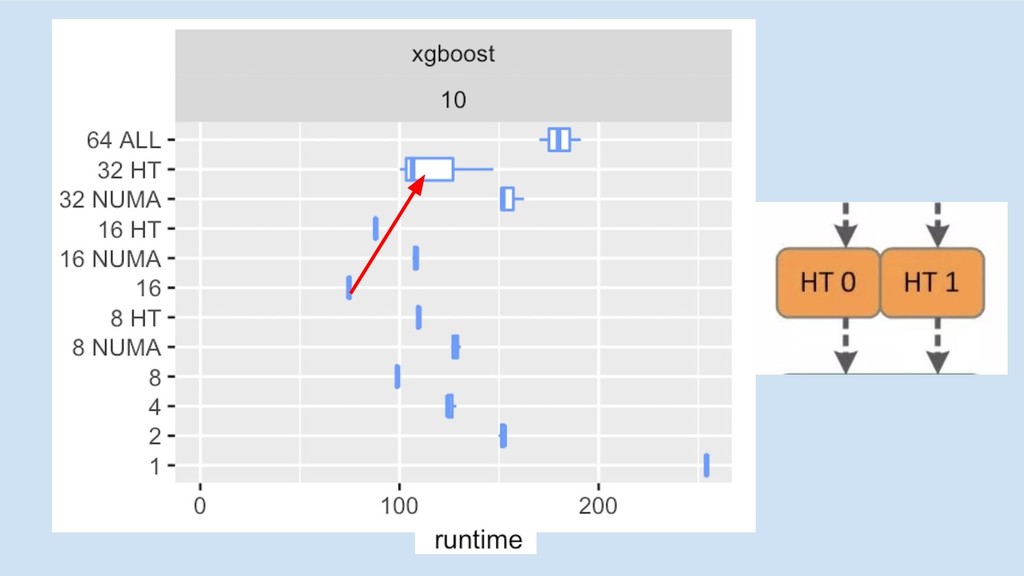
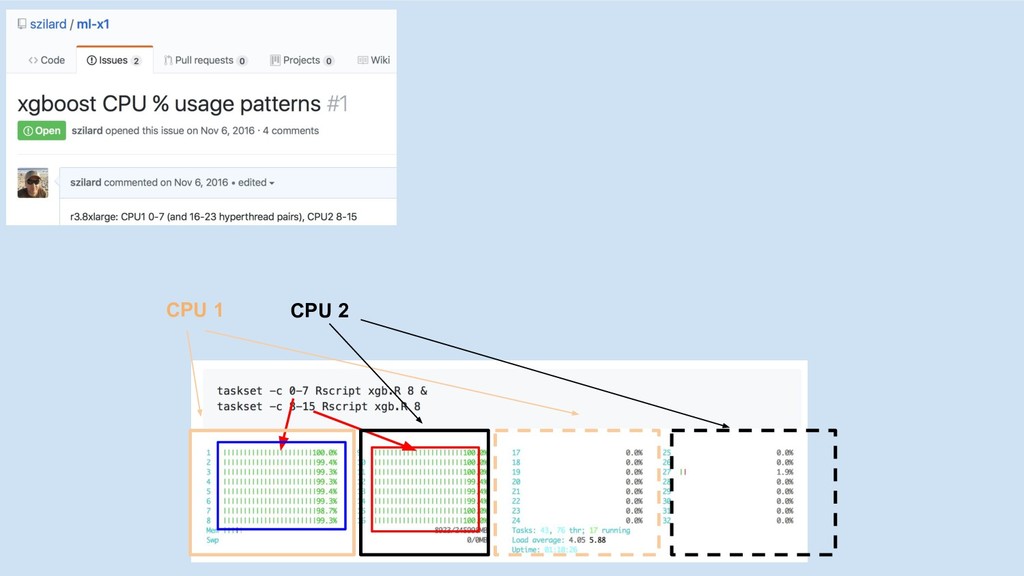
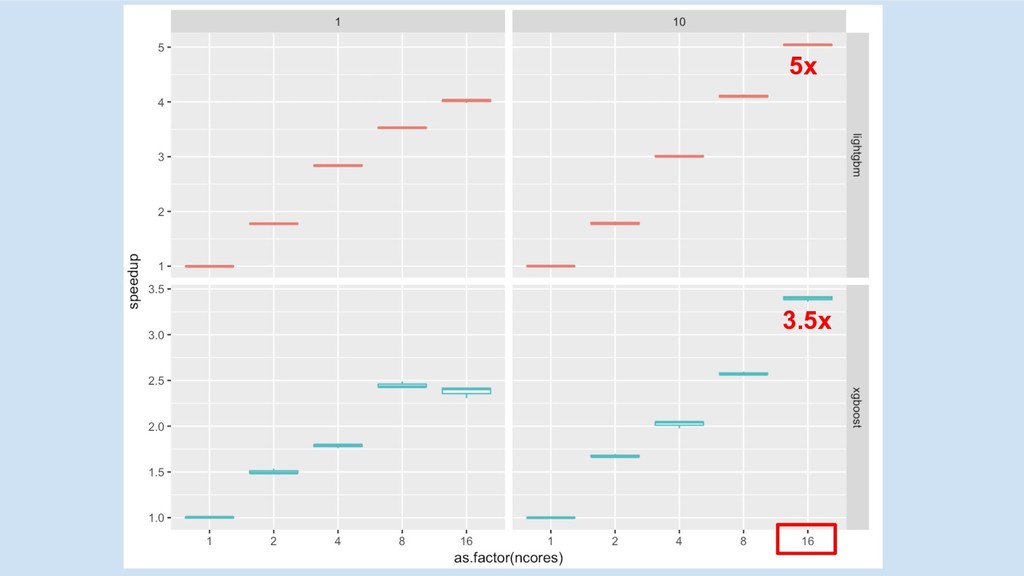
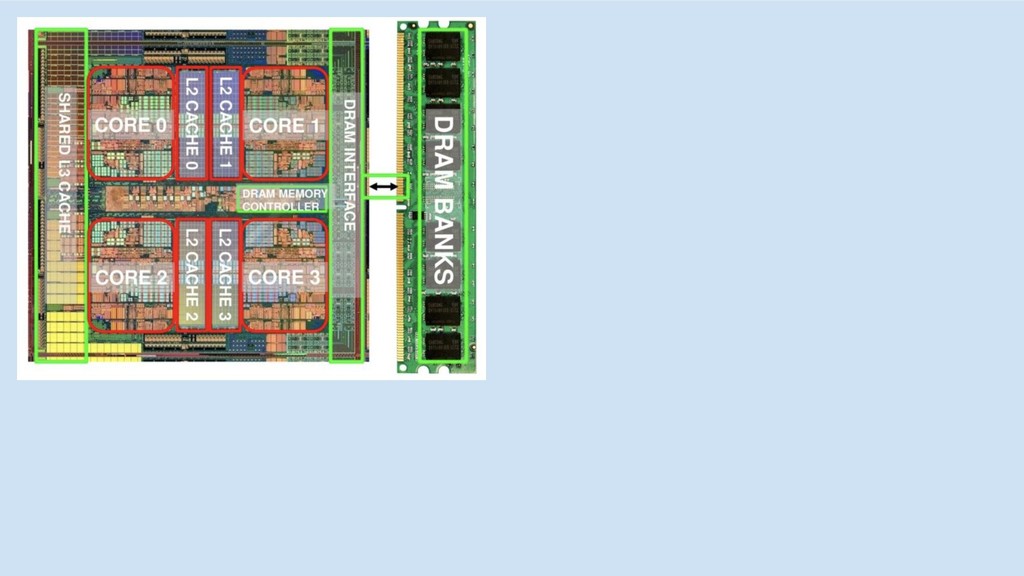
multi-core/socket
None
None
None
None
None
None
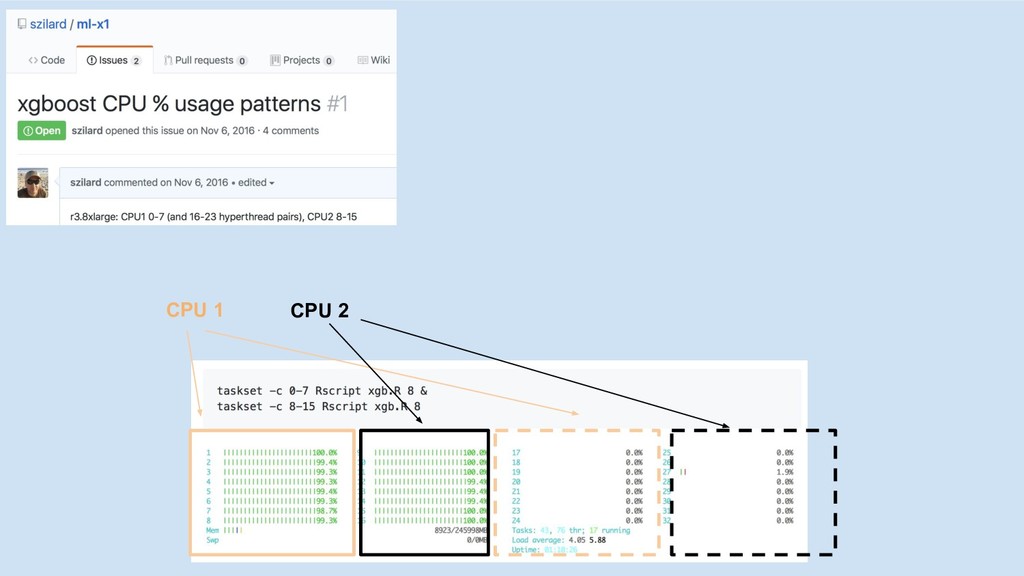
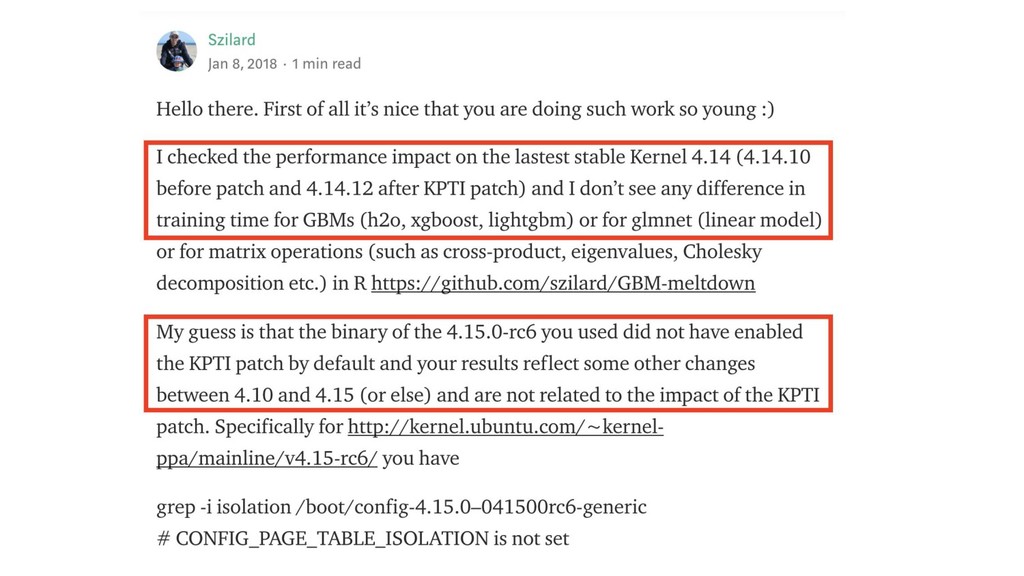
CPU 1
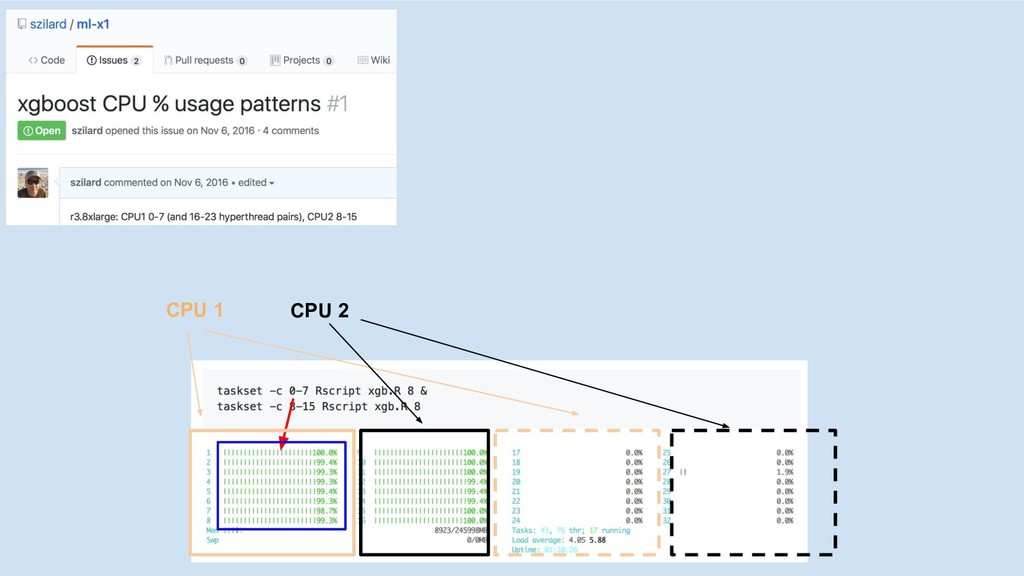
CPU 1 CPU 2
CPU 1 CPU 2
CPU 1 CPU 2
CPU 1 CPU 2
None
5x 3.5x
None
None
None
None
None
None
None
None
None
None
None
None
None
None
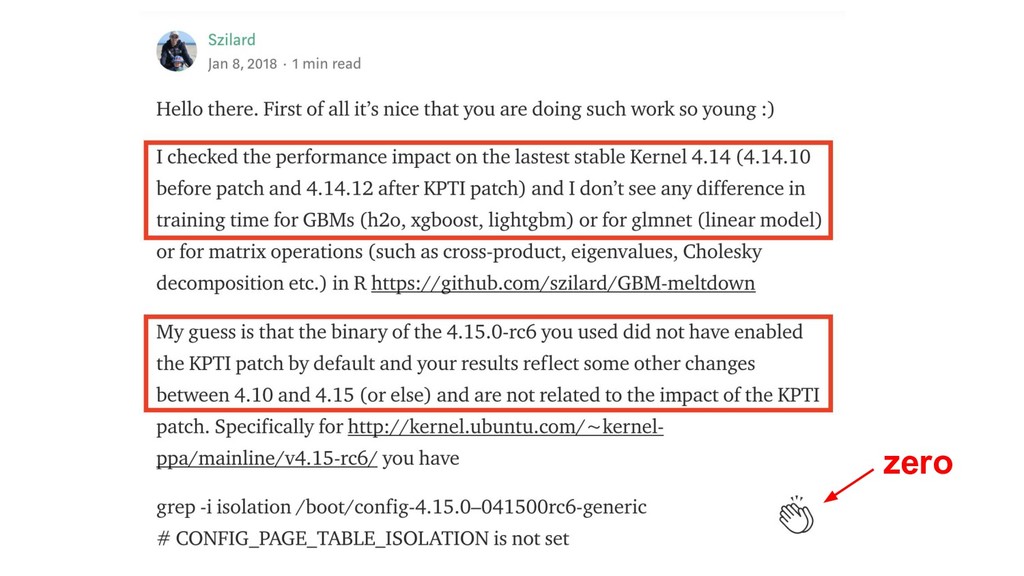
zero
None
None
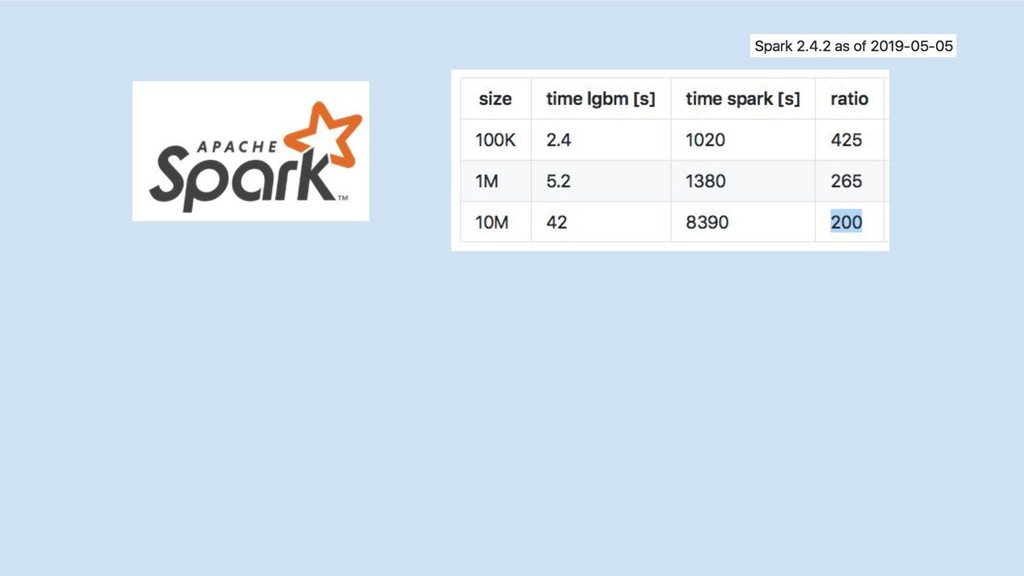
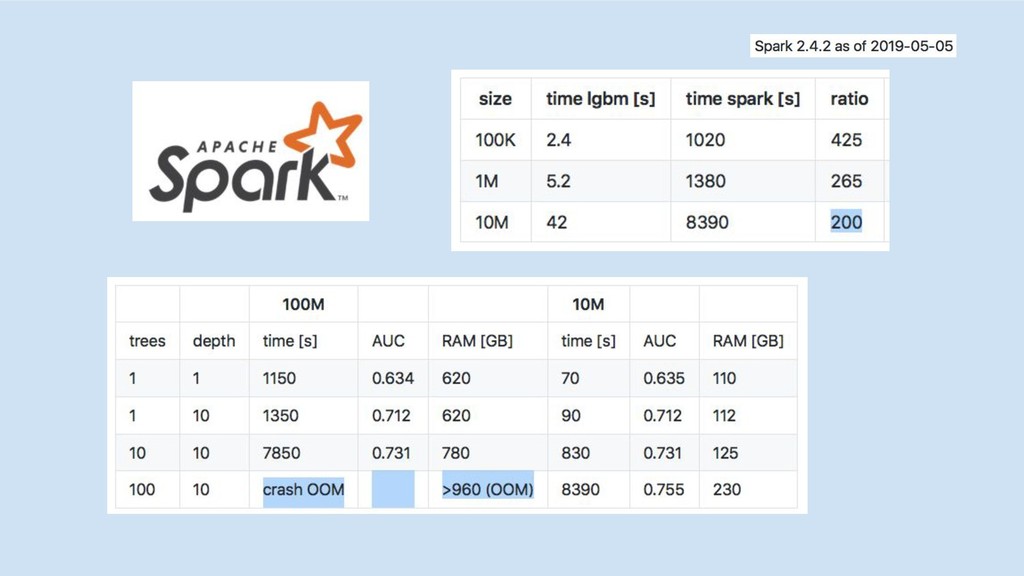
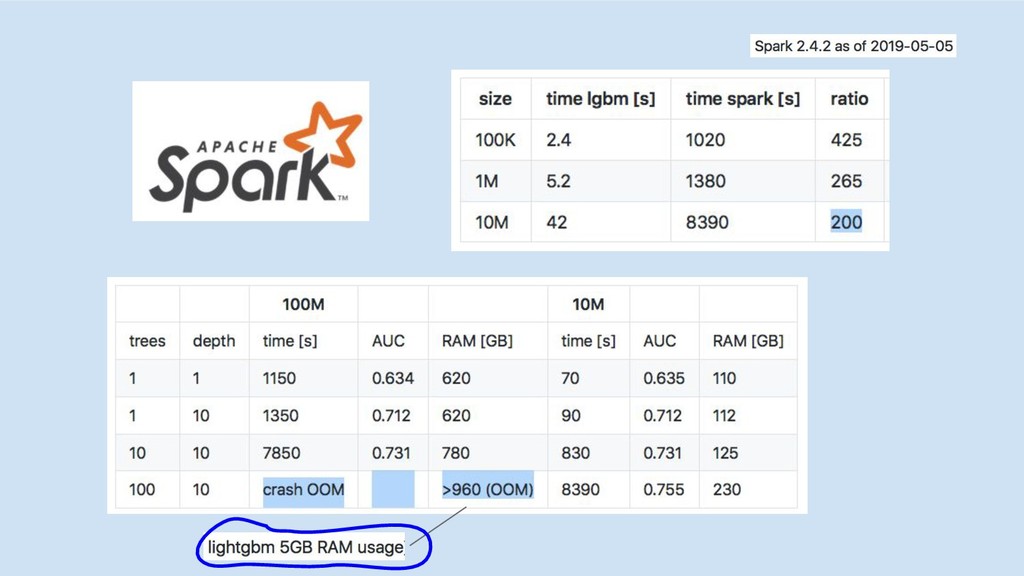
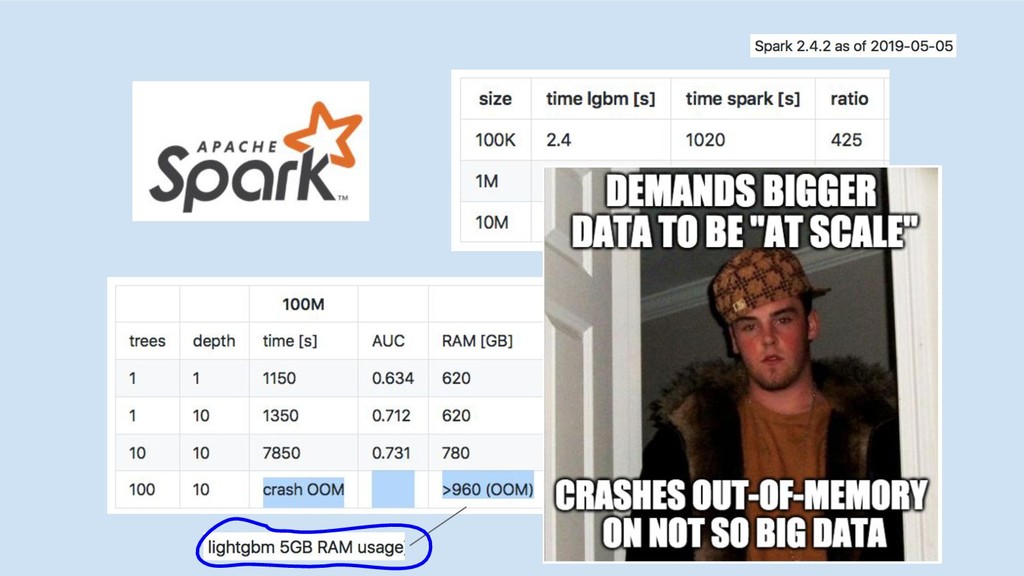
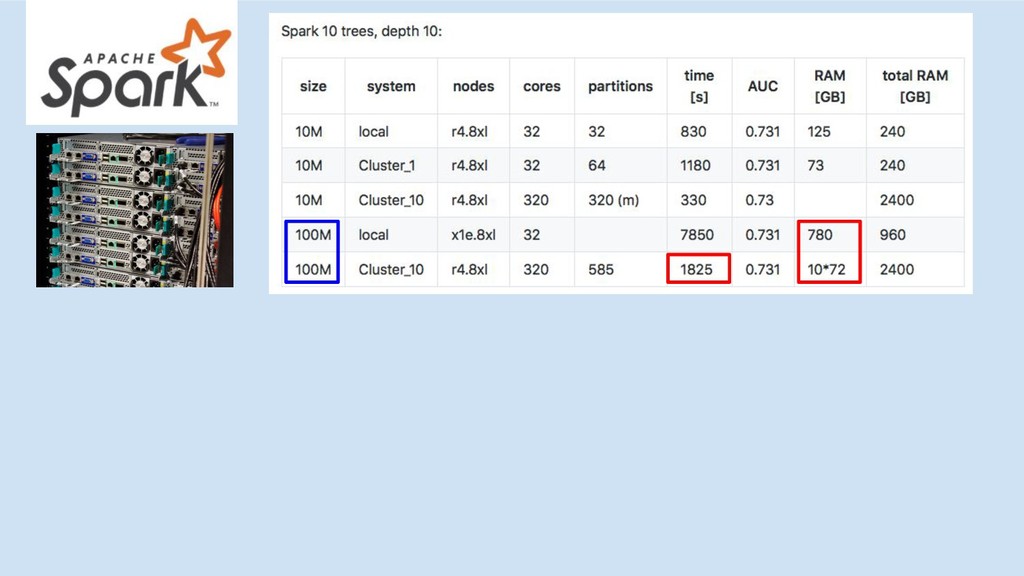
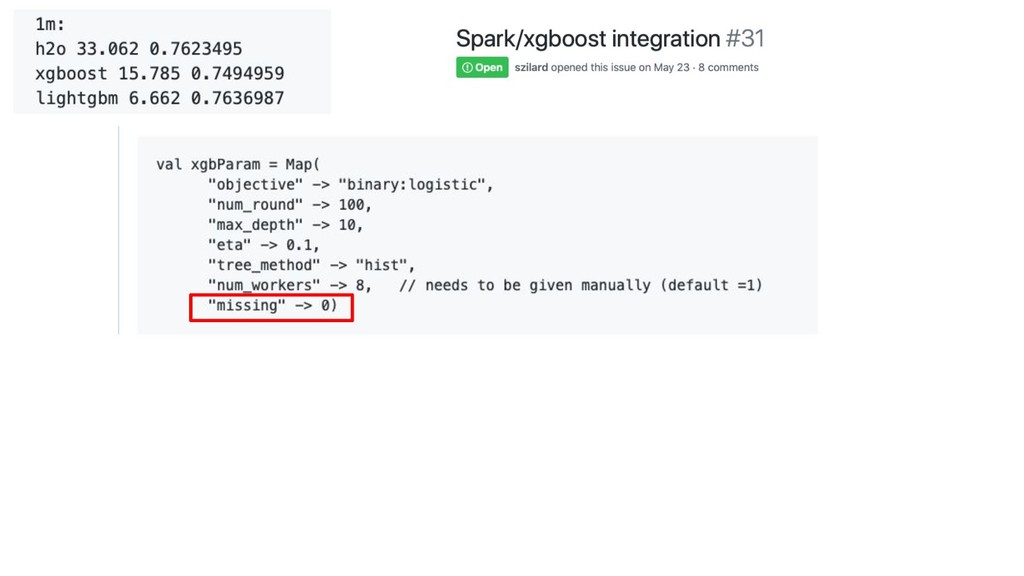
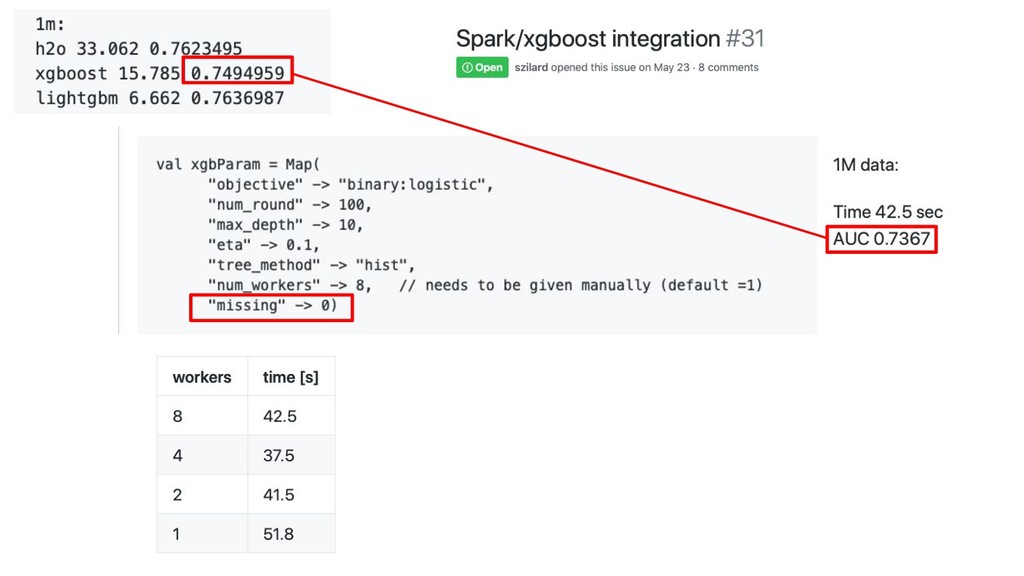
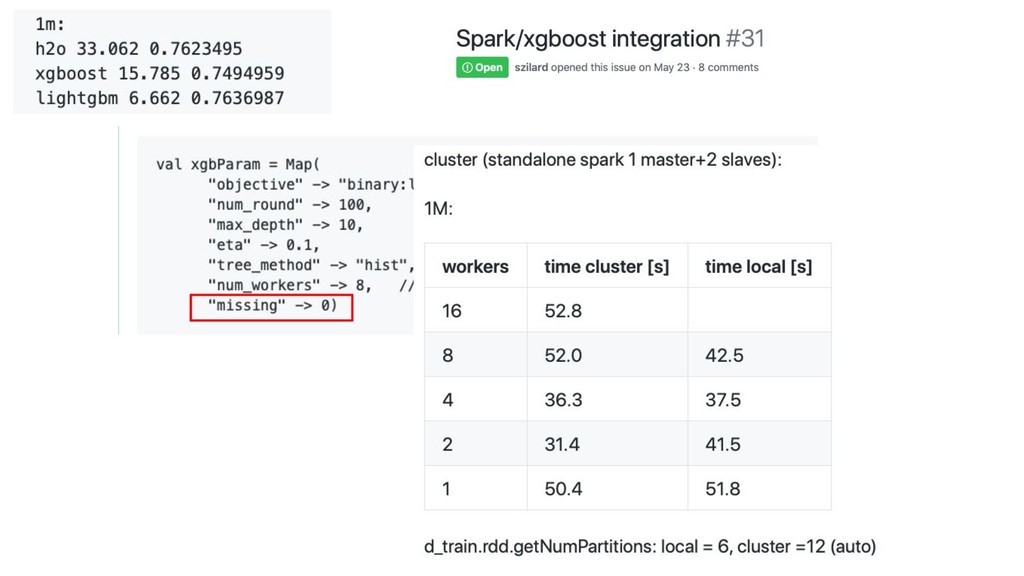
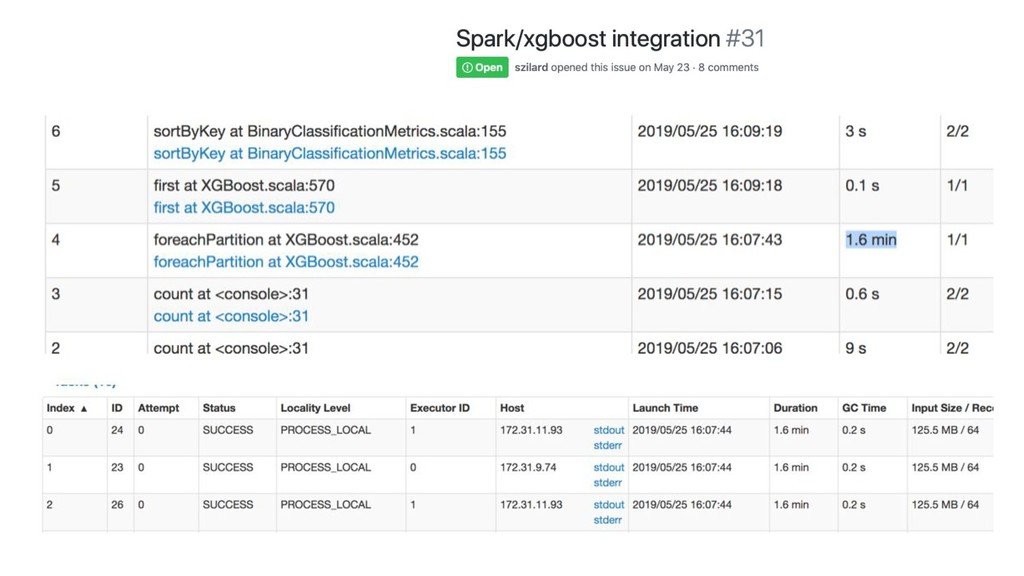
Spark
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
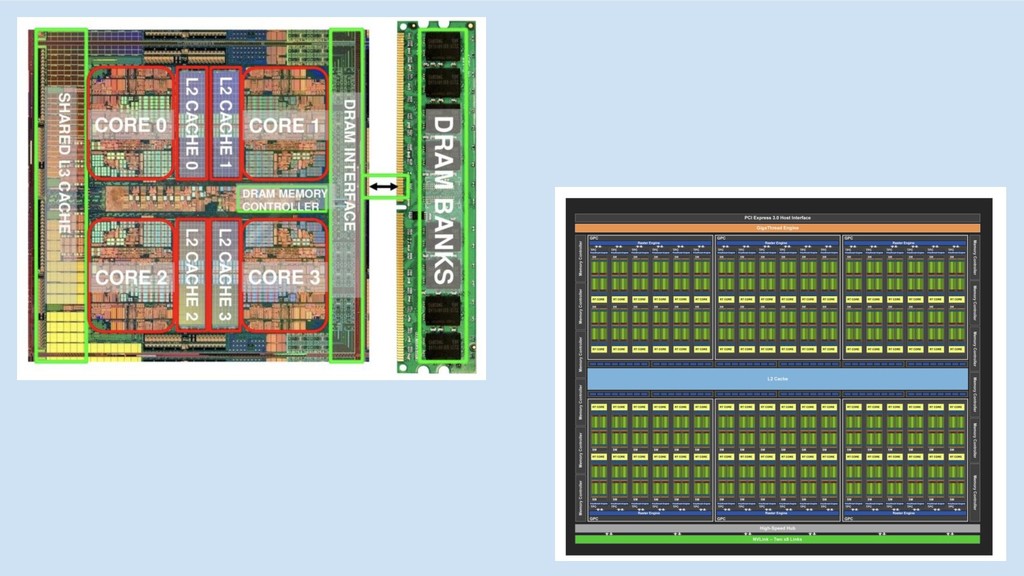
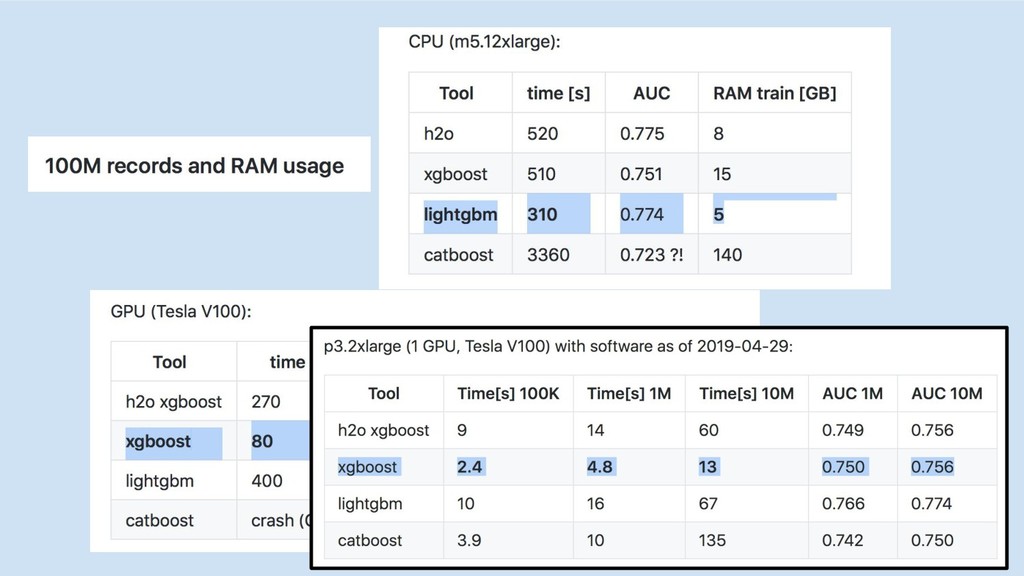
GPU
None
None
None
None
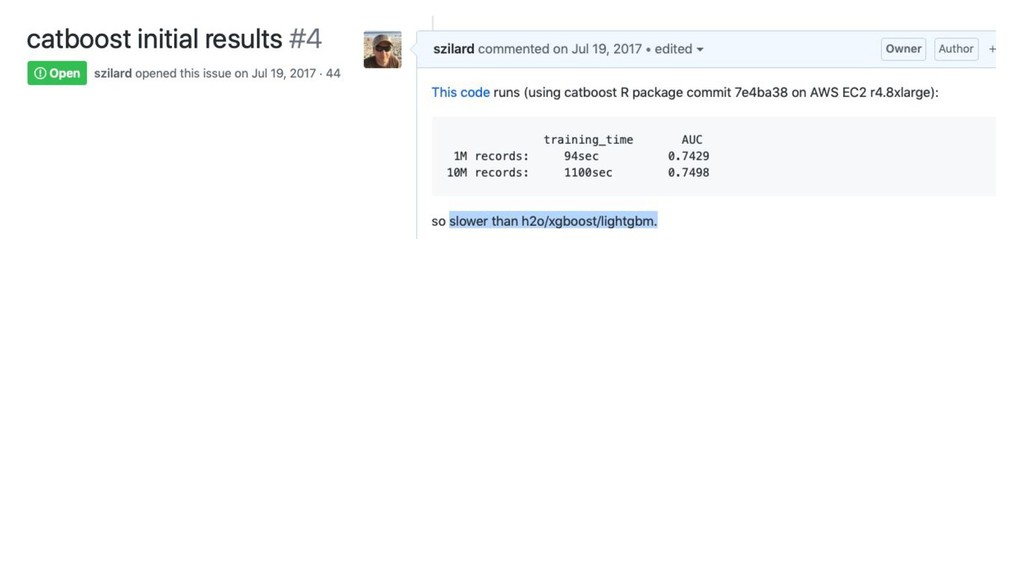
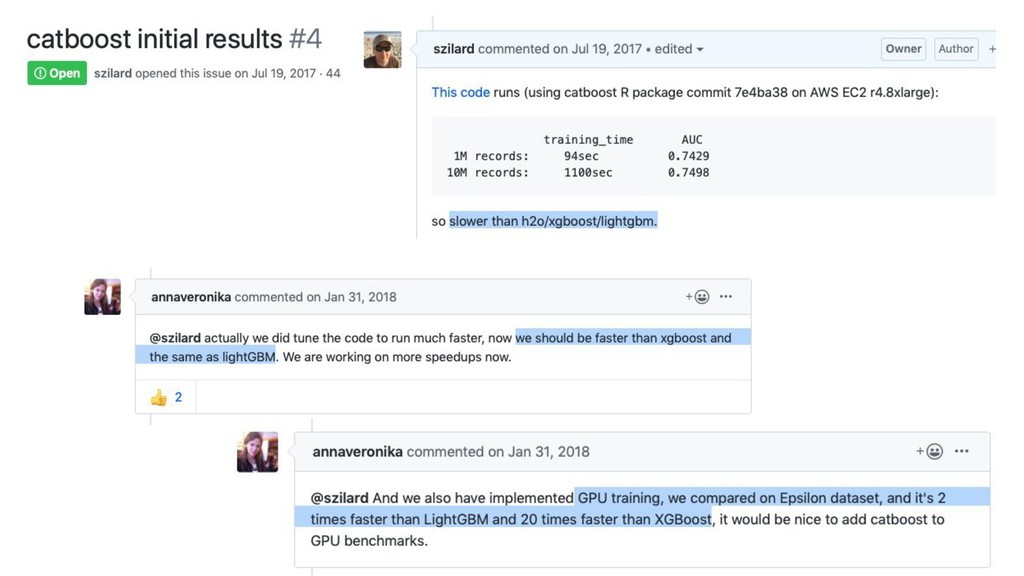
catboost
None
None
None
None
None
None
None
None
None
None
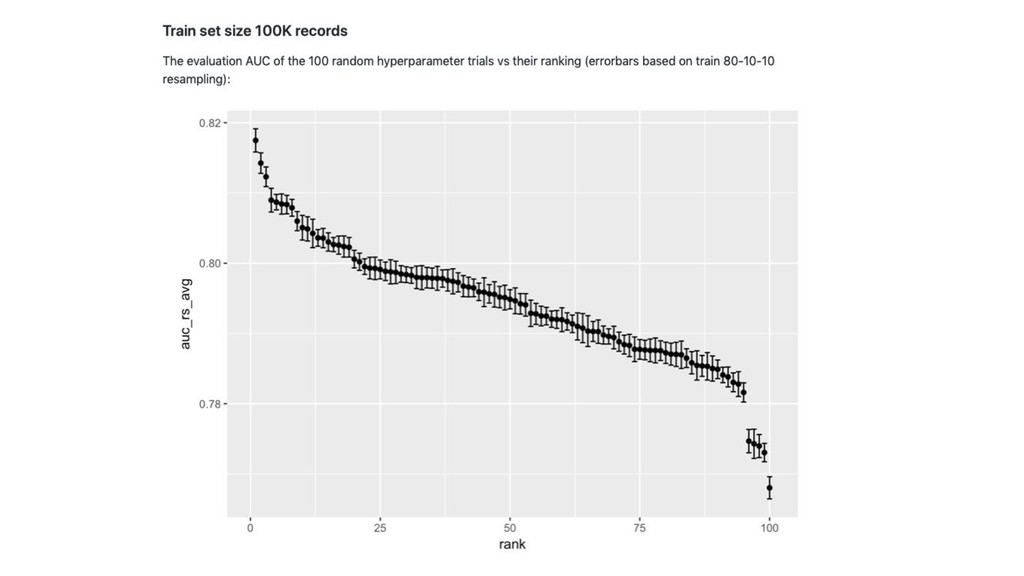
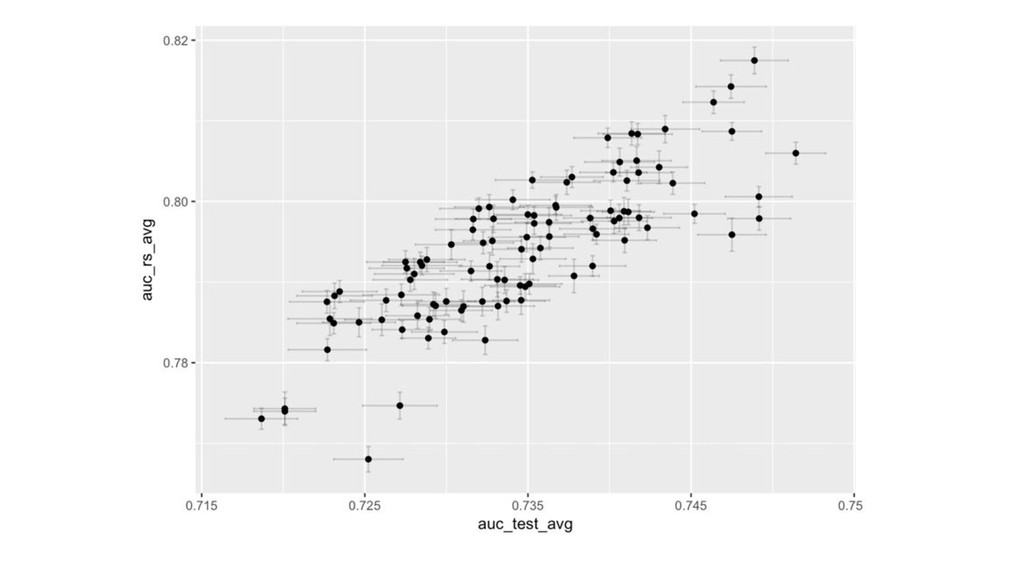
API / tuning
None
None
None
None
None
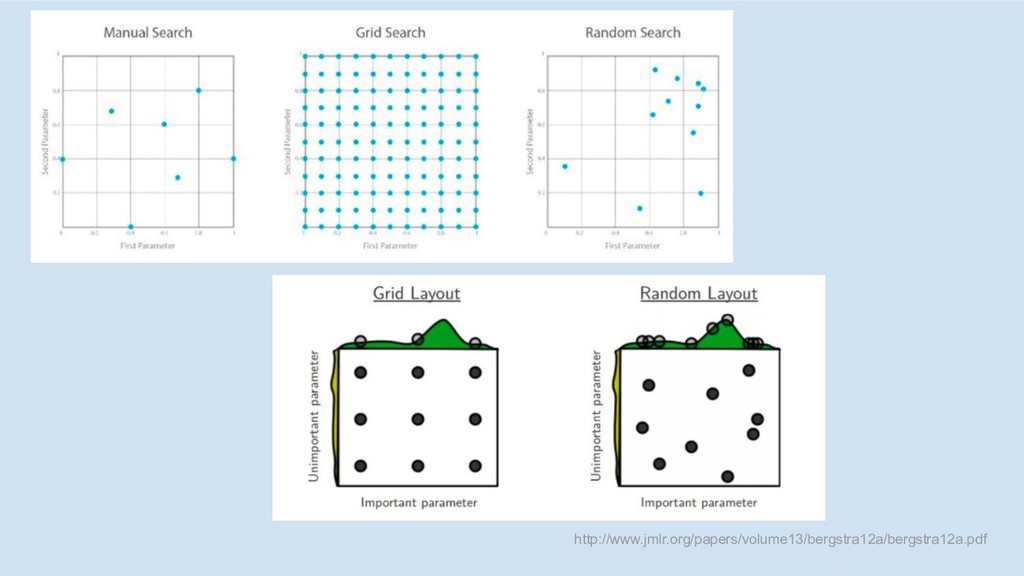
http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdf
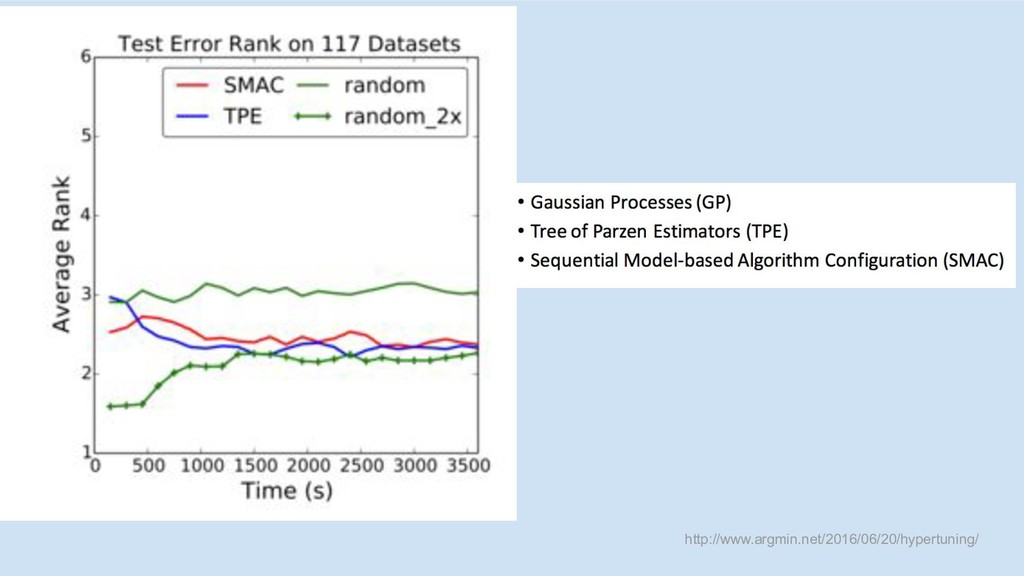
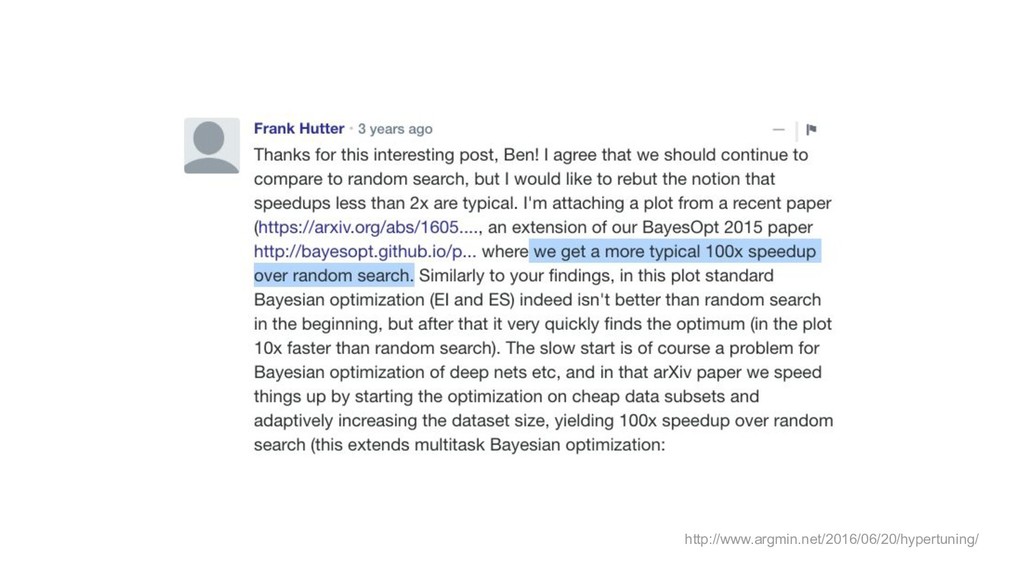
http://www.argmin.net/2016/06/20/hypertuning/
http://www.argmin.net/2016/06/20/hypertuning/
None
None
None
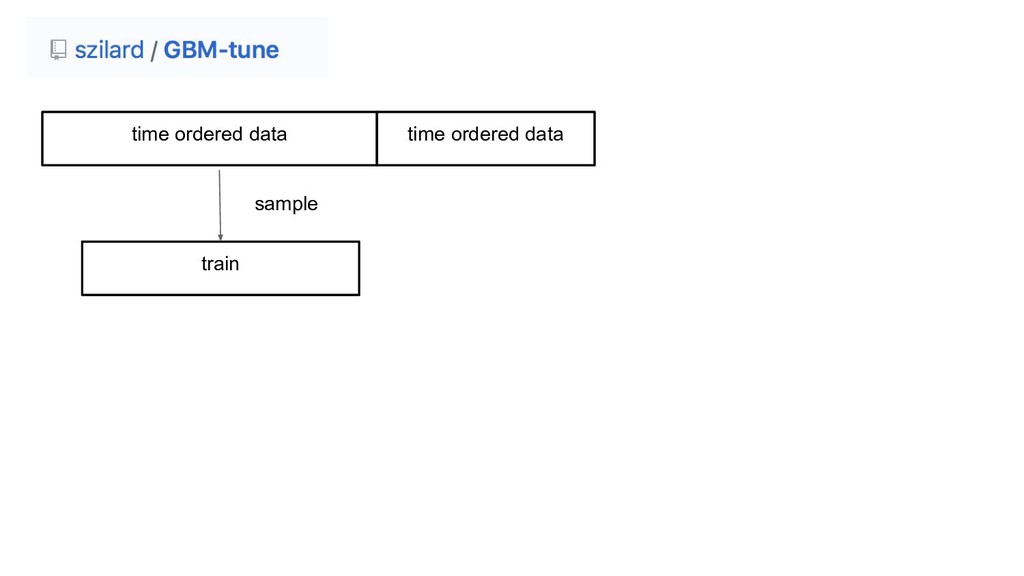
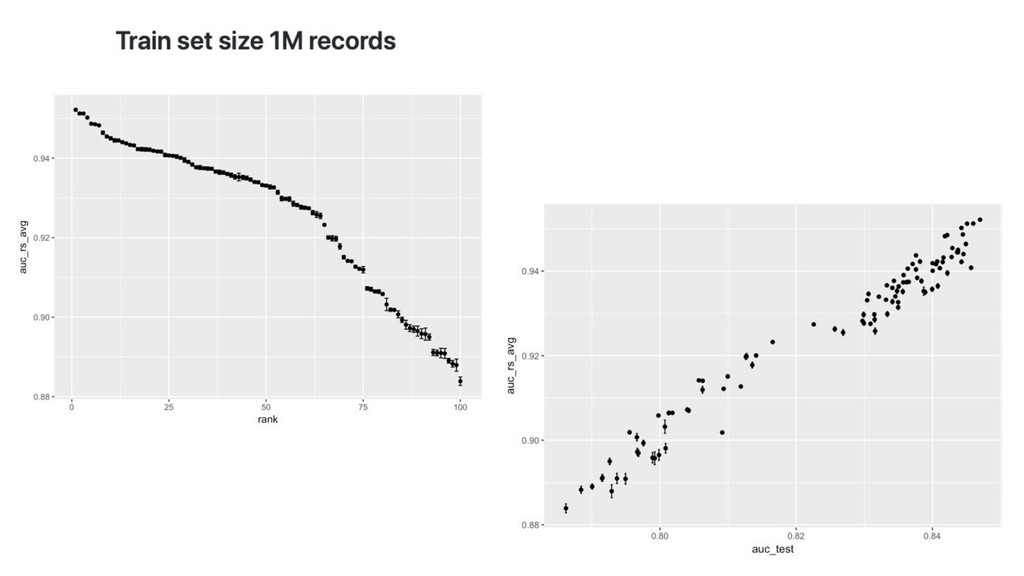
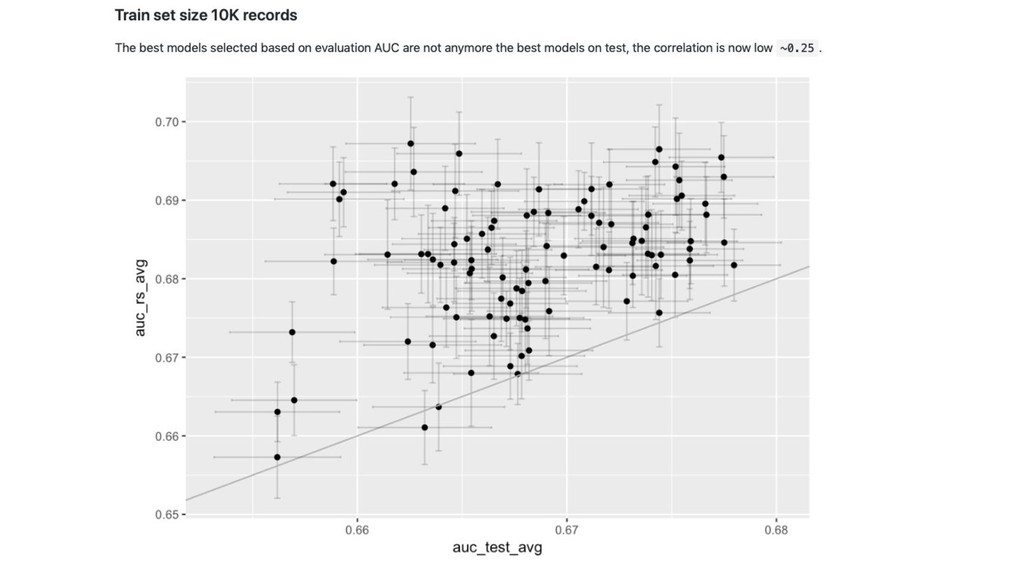
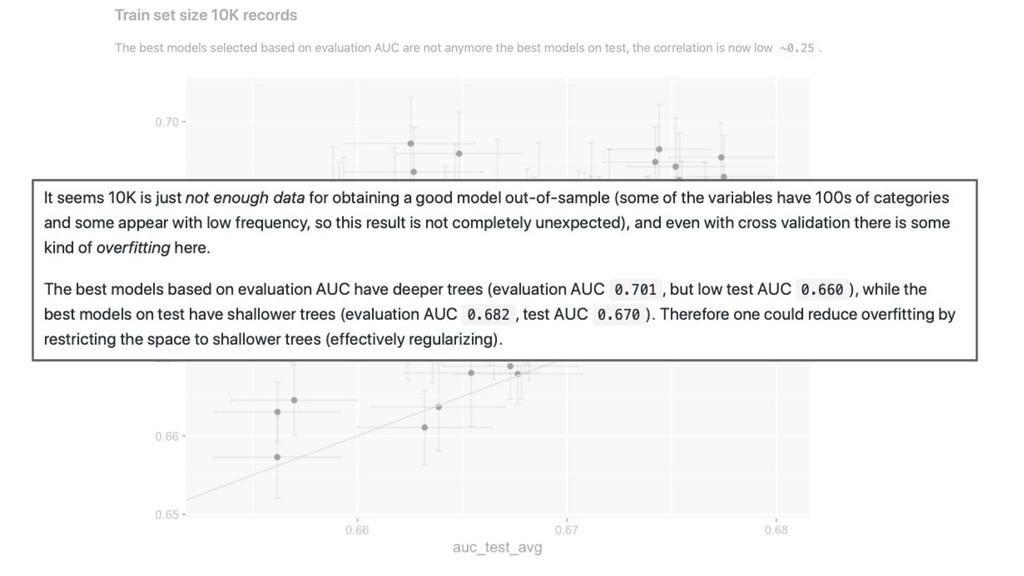
time ordered data time ordered data
time ordered data time ordered data train sample
time ordered data time ordered data train test sample sample
(slightly different distribution)
time ordered data time ordered data train test sample sample
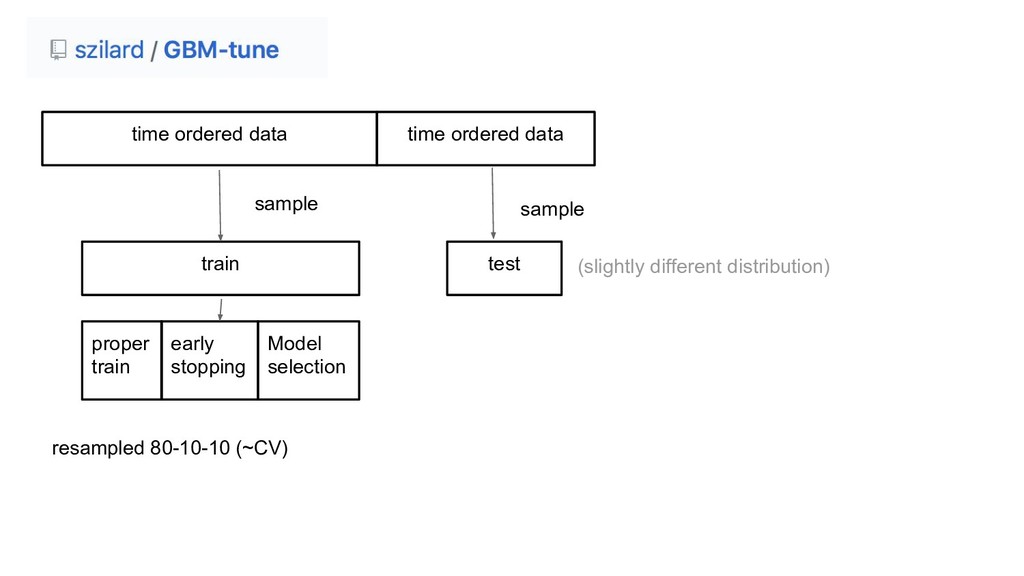
proper train early stopping Model selection resampled 80-10-10 (~CV) (slightly different distribution)
time ordered data time ordered data train test sample sample
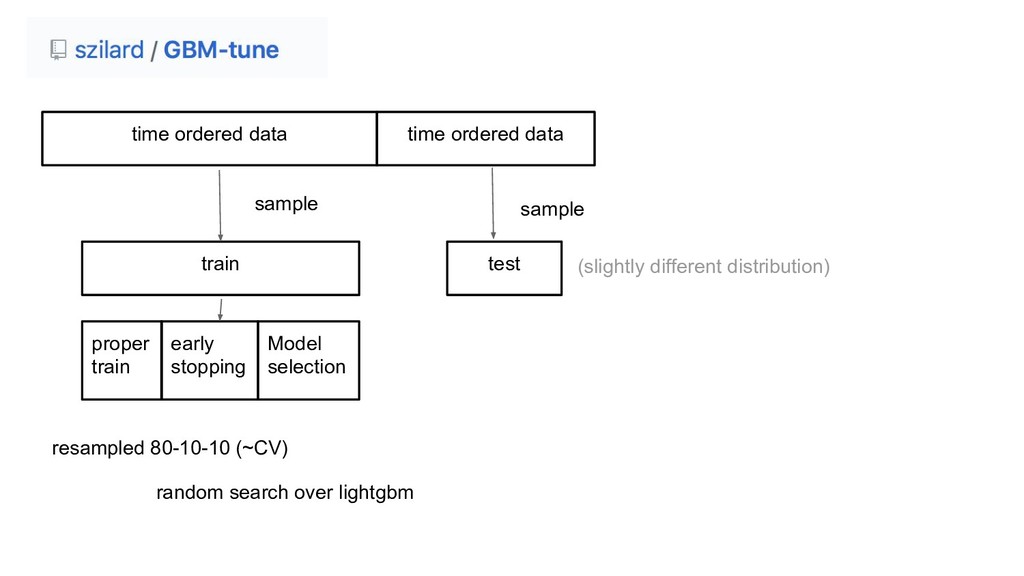
proper train early stopping Model selection random search over lightgbm resampled 80-10-10 (~CV) (slightly different distribution)
None
None
None
None
None
None
None
None
Closing
None
None
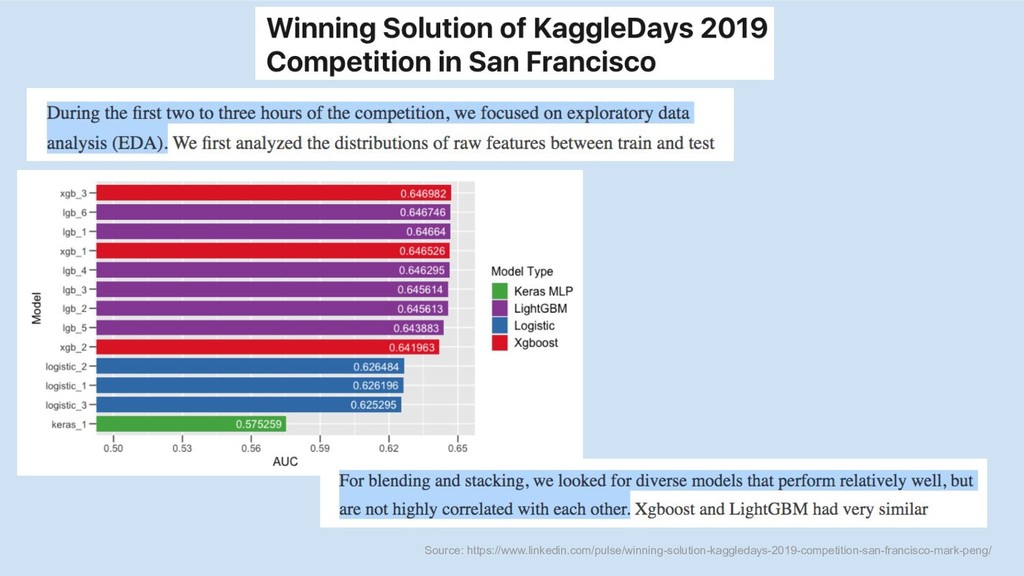
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
Source: https://www.linkedin.com/pulse/winning-solution-kaggledays-2019-competition-san-francisco-mark-peng/
None
More:
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}