Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
JOAI2026講評会スライド
Search
Tomo Hayakawa
April 15, 2026
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
JOAI2026講評会スライド
Tomo Hayakawa
April 15, 2026
Featured
See All Featured
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
For a Future-Friendly Web
brad_frost
183
10k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
560
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Deep Space Network (abreviated)
tonyrice
0
230
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Transcript
JOAI 2026 public6位/private8位 解法 広尾学園高等学校2年 早川智晴(Tomoharu Hayakawa)
1. 自己紹介 2. 大会中の取り組み方 3. モデル設計と選んだ理由 4. 工夫 5. 感想・来年の参加者に向けて
自己紹介 早川智晴 広尾学園高等学校2年生 主な活動: - AIを利用したスポーツ障害のリスク評価の研 究 (情報科学の達人7期生) - FIRST
Tech Challenge (Hiroo Robotics) - JOAI前はKaggle歴がほとんどない
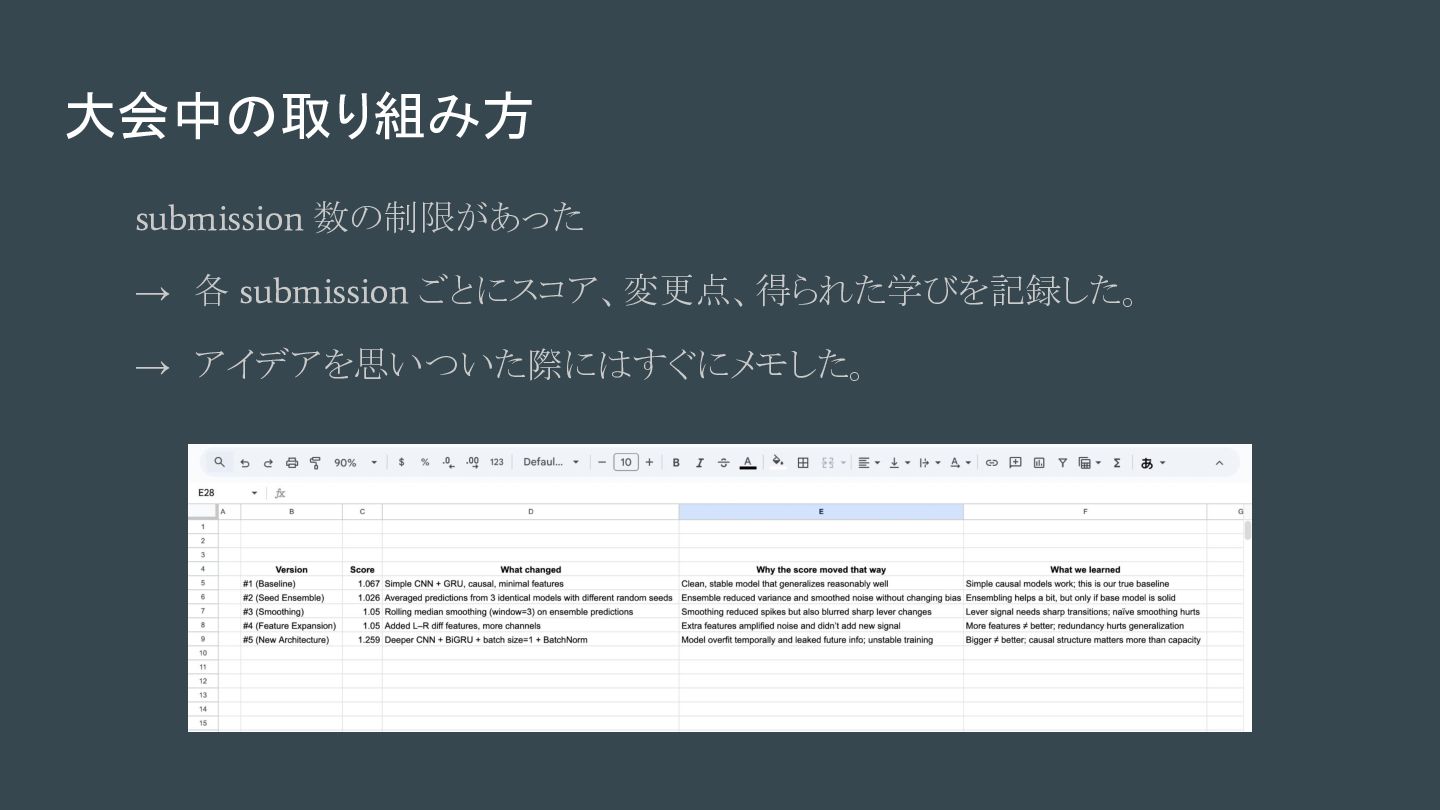
大会中の取り組み方 submission 数の制限があった → 各 submission ごとにスコア、変更点、得られた学びを記録した。 → アイデアを思いついた際にはすぐにメモした。
大会中の取り組み方 序盤 - タスクを熟読する - とにかく色々なモデ ルを実験する 中盤 - スコアが一番高かっ
たCNN+BiGRUを使うこ とにした - アンサンブルや損失 関数を試す 終盤 - ハイパラ、エポックな どを最終調整
課題の整理 1. ノイズの多い脳活動信号 2. マウス個体差および学習日ごとの差 3. 各サンプルが可変朝時系列である点
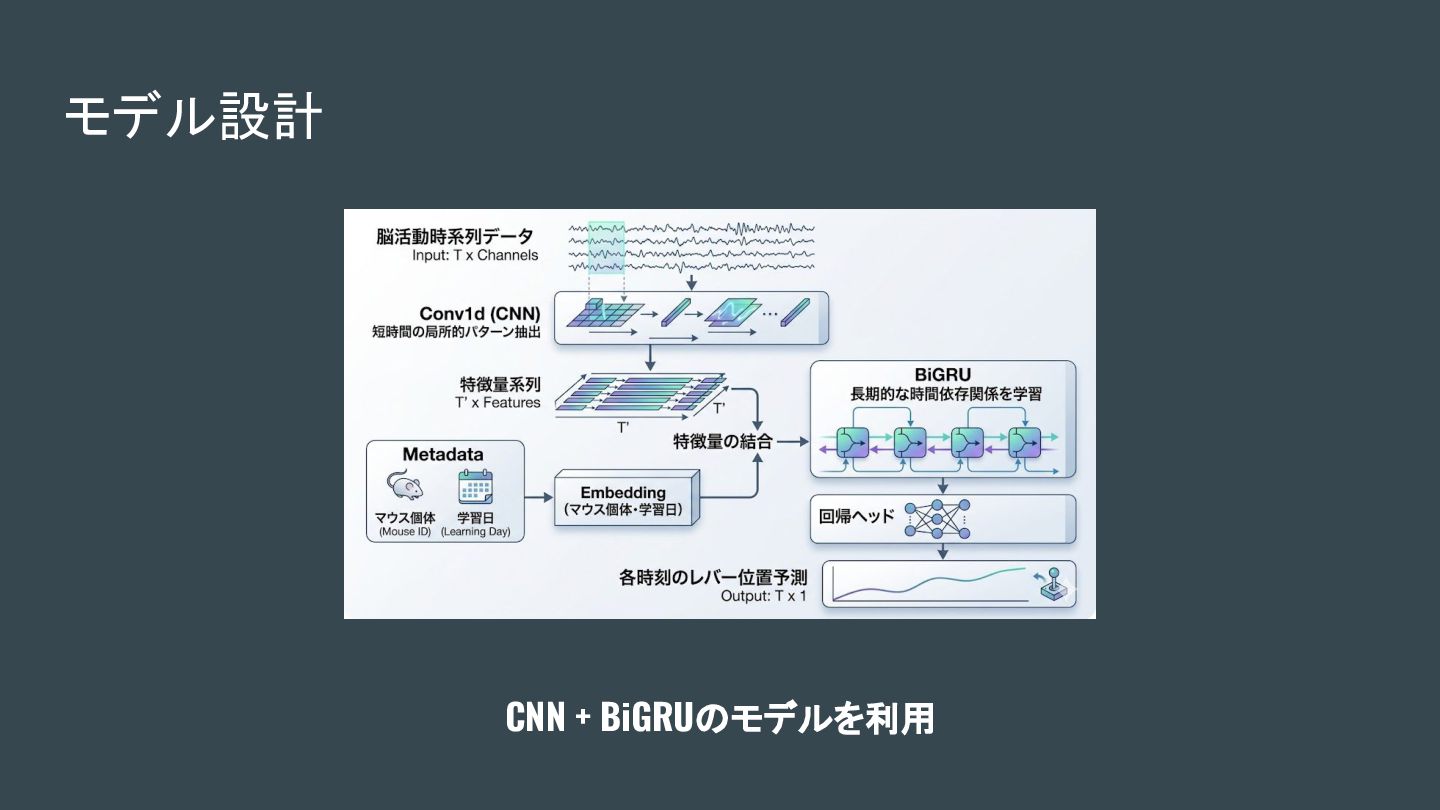
モデル設計 CNN + BiGRUのモデルを利用
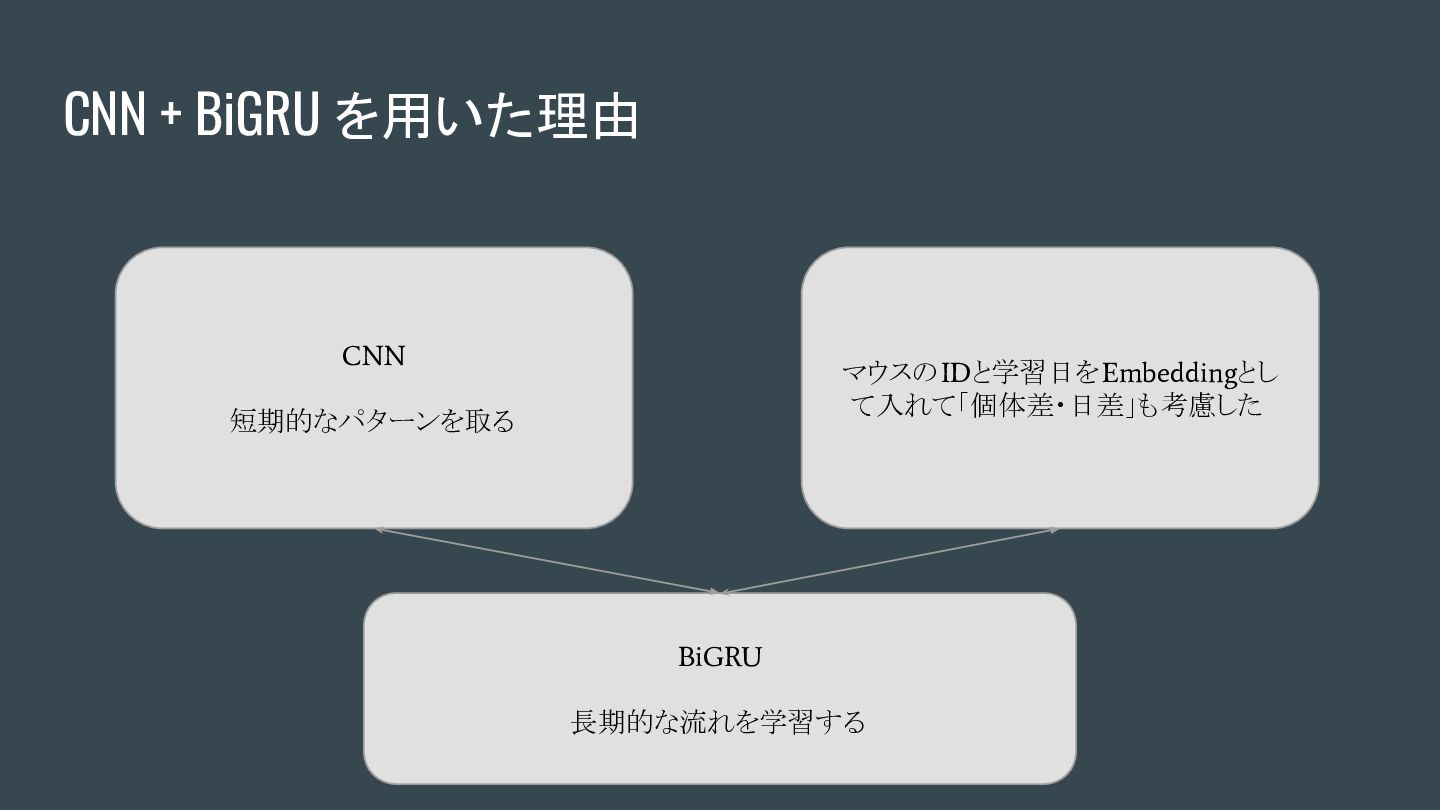
CNN + BiGRU を用いた理由 CNN 短期的なパターンを取る マウスのIDと学習日をEmbeddingとし て入れて「個体差・日差」も考慮した BiGRU 長期的な流れを学習する
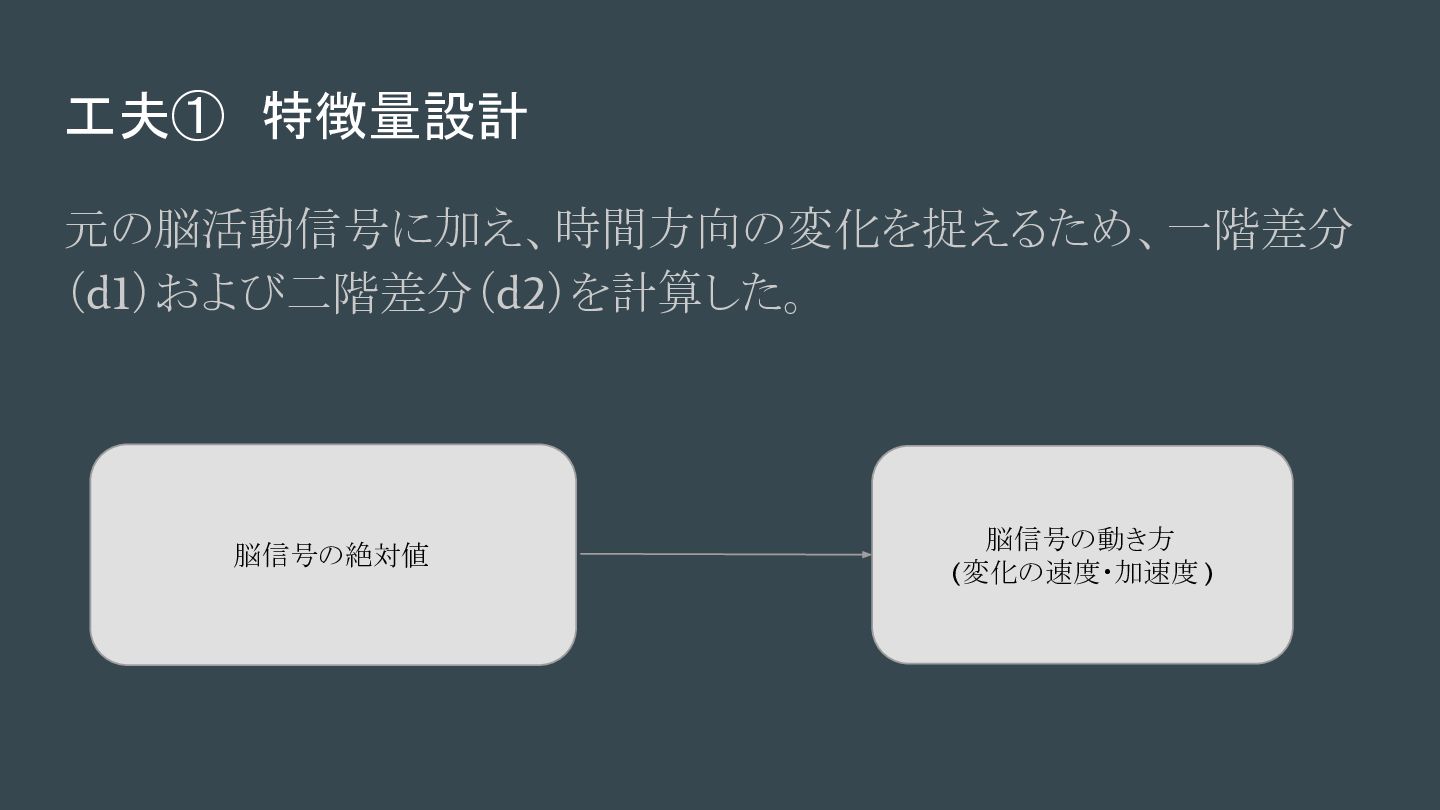
工夫① 特徴量設計 元の脳活動信号に加え、時間方向の変化を捉えるため、一階差分 (d1)および二階差分(d2)を計算した。 脳信号の絶対値 脳信号の動き方 (変化の速度・加速度 )
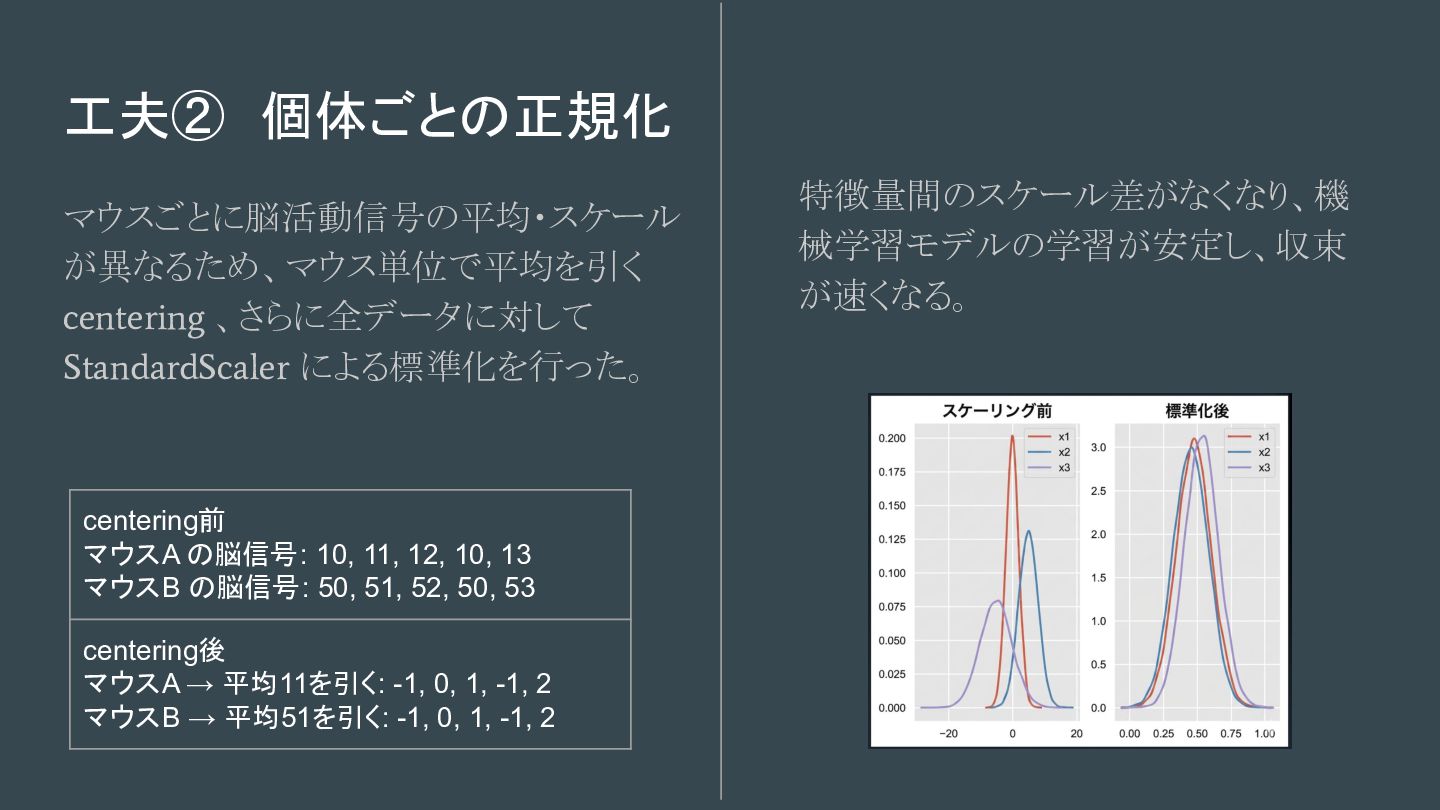
工夫② 個体ごとの正規化 マウスごとに脳活動信号の平均・スケール が異なるため、マウス単位で平均を引く centering 、さらに全データに対して StandardScaler による標準化を行った。 特徴量間のスケール差がなくなり、機 械学習モデルの学習が安定し、収束 が速くなる。
centering前 マウスA の脳信号: 10, 11, 12, 10, 13 マウスB の脳信号: 50, 51, 52, 50, 53 centering後 マウスA → 平均11を引く: -1, 0, 1, -1, 2 マウスB → 平均51を引く: -1, 0, 1, -1, 2
工夫③ 可変長時系列と mask 処理 各サンプルは可変長であるため、バッチ学習時には最大長に padding し、同時に mask を作成した。 モデル入力段階と損失計算時にも mask
を適用した → padding による誤学習を防ぐため
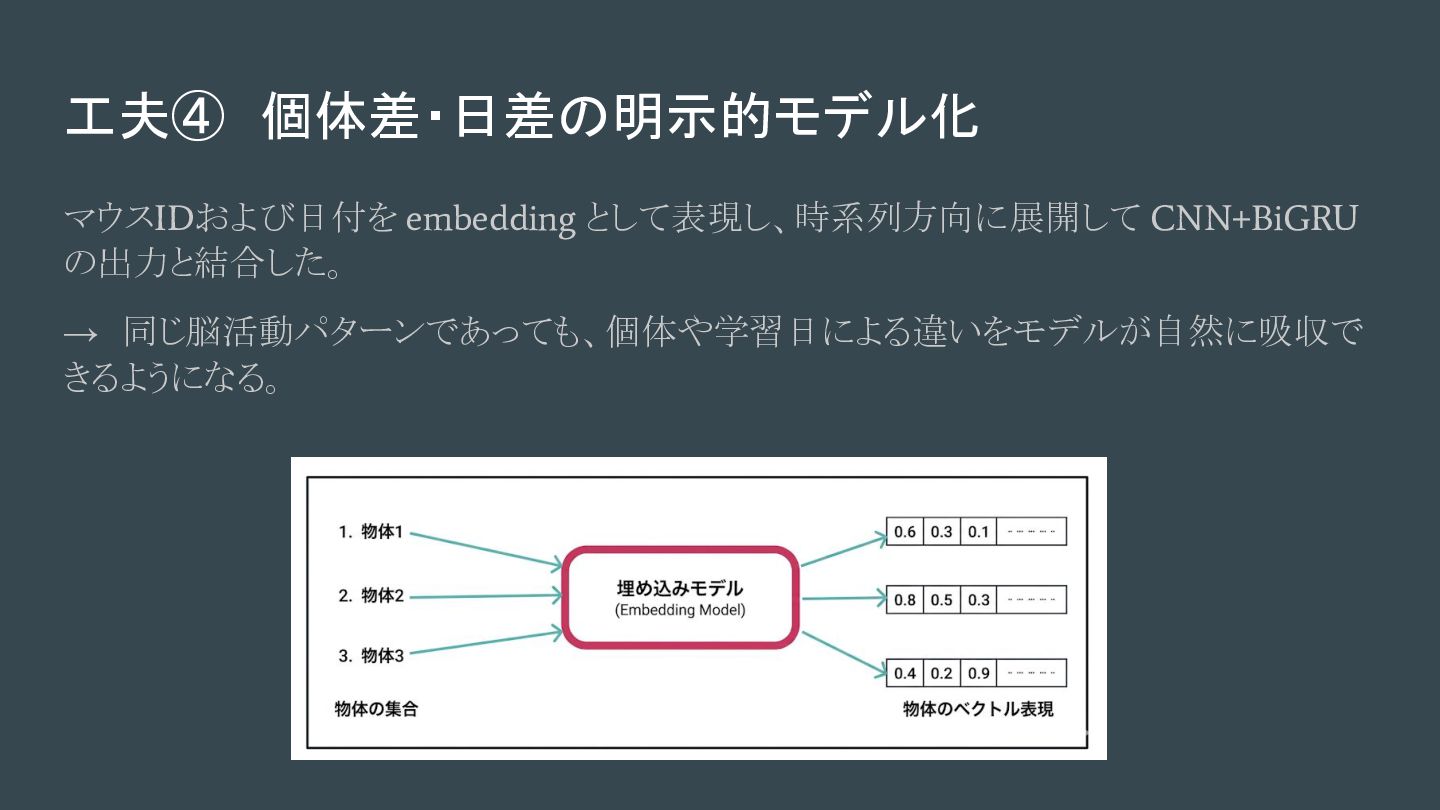
工夫④ 個体差・日差の明示的モデル化 マウスIDおよび日付を embedding として表現し、時系列方向に展開して CNN+BiGRU の出力と結合した。 → 同じ脳活動パターンであっても、個体や学習日による違いをモデルが自然に吸収で きるようになる。
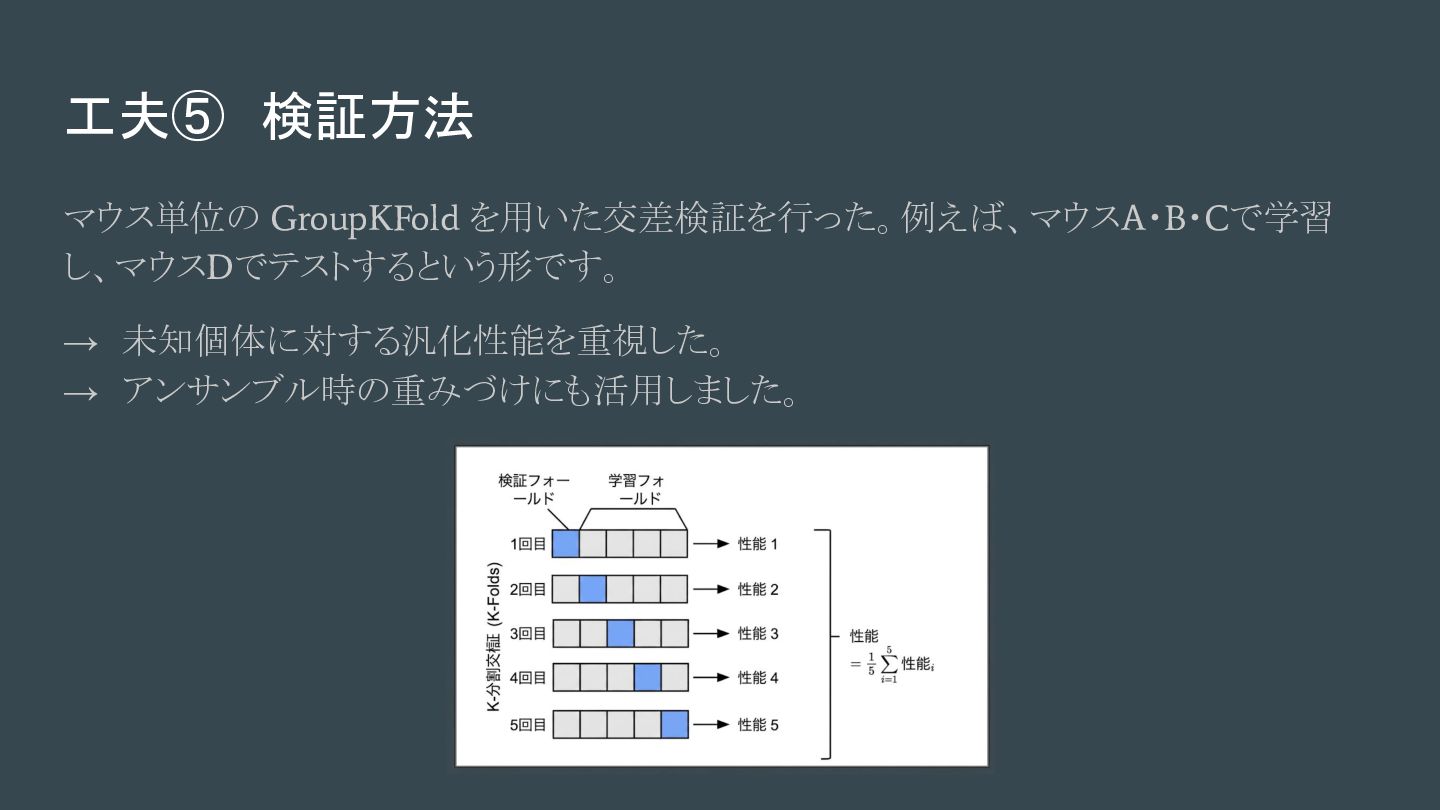
工夫⑤ 検証方法 マウス単位の GroupKFold を用いた交差検証を行った。例えば、マウスA・B・Cで学習 し、マウスDでテストするという形です。 → 未知個体に対する汎化性能を重視した。 → アンサンブル時の重みづけにも活用しました。
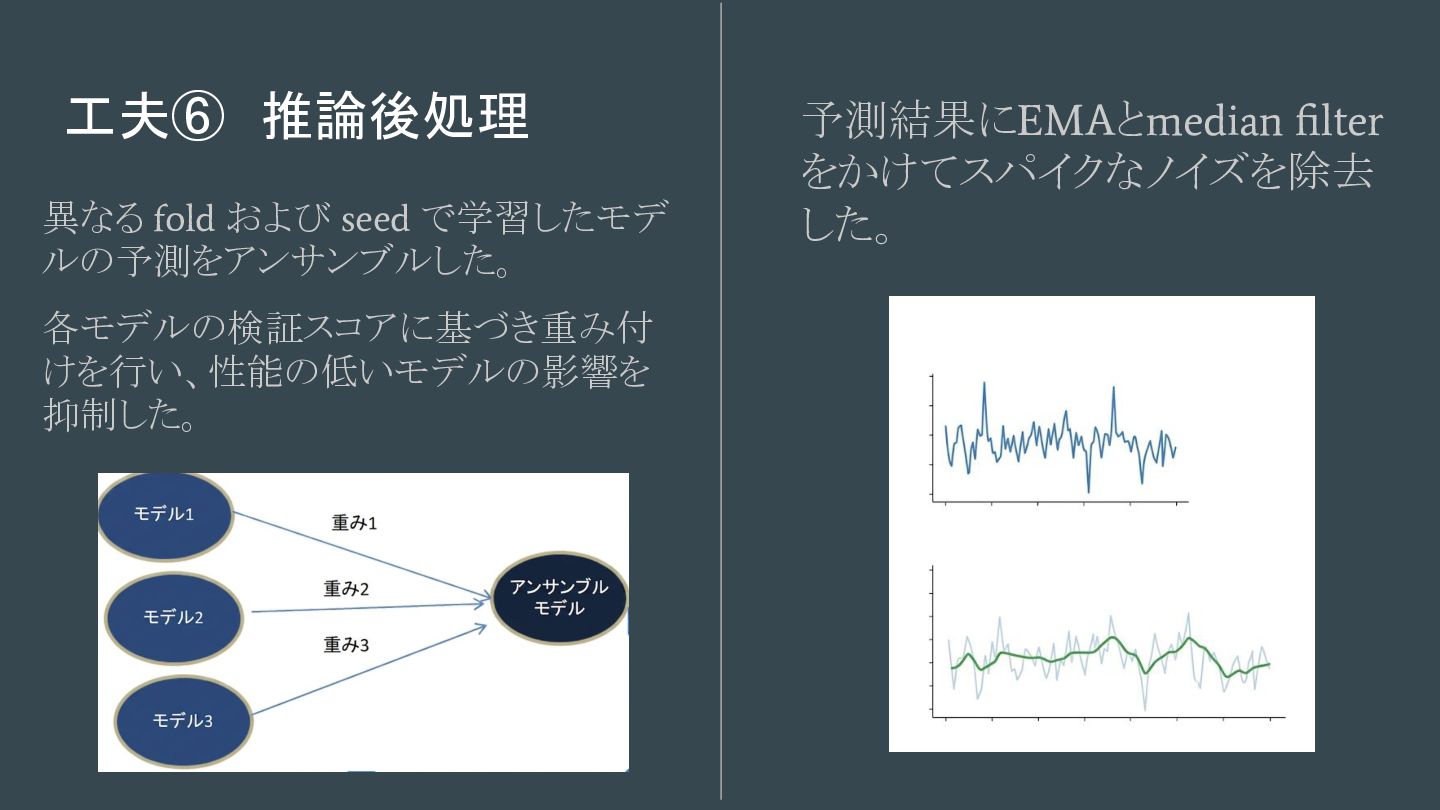
工夫⑥ 推論後処理 異なる fold および seed で学習したモデ ルの予測をアンサンブルした。 各モデルの検証スコアに基づき重み付 けを行い、性能の低いモデルの影響を 抑制した。
予測結果にEMAとmedian filter をかけてスパイクなノイズを除去 した。
感想・来年の参加者に向けて Kaggle歴がほぼない状態でこのコンペに取り組みました。私にとって一番重 要だったのは色々なことをためして、実験したことです。それによって、どうい うポイントでスコアが改善しかを分析することができて、少しずつスコアを改 善して追い上げることができました。 1. たくさん試す!過去のコンペを調べる。 2. LLMをうまく活用する!モデルの構造はLLMを使わない.。 3.
楽しむ!リーダーボードにとらわれない。
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}