Drug candidate identifcation based on gene expression of treated cells using tensor decomposition-based unsupervised feature extraction for large-scale data
Oral presentation at InCob2018, Delhi, 25th Sep. 2018
Accepted in BMC Bioinformatics
using tensor decomposition-based unsupervised feature extraction for large-scale data Y-h. Taguchi Department of Physics, Chuo University, Tokyo, Japan InCob2018, New Delhi, 25th Sep. 2018 Accepted in BMC Bioinformatics
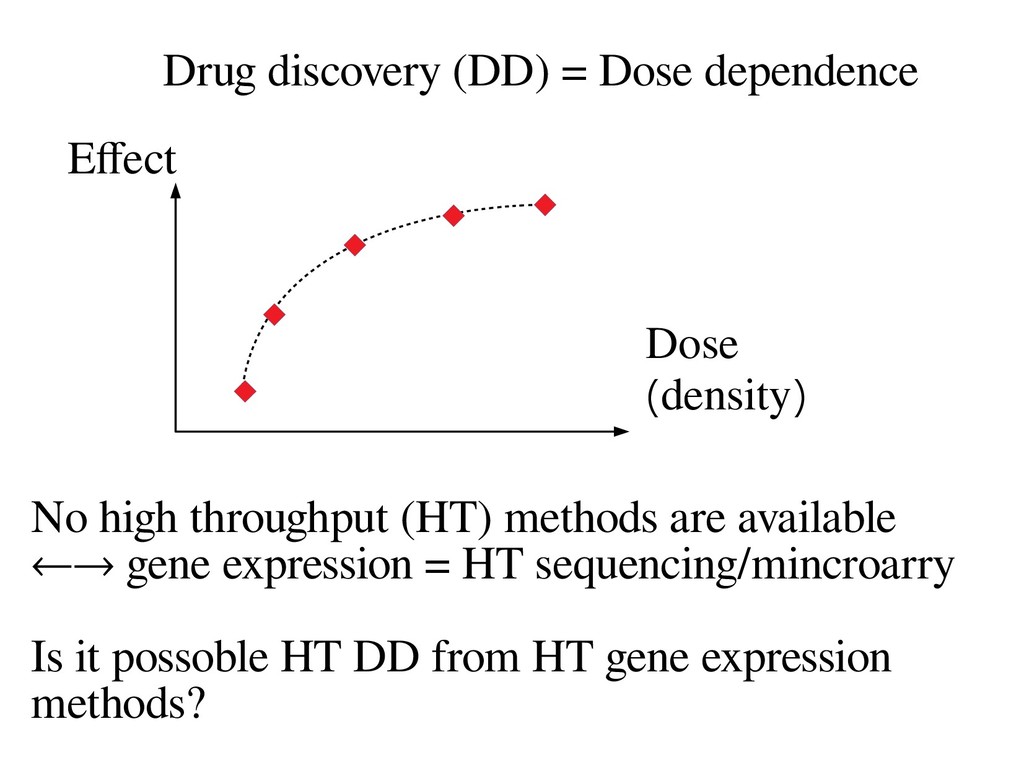
with various drugs with multiple dose density → Problem: How can we screen these? Regression analysis between gene expression and dose density? → Too small observations (a few dose density) might prevent us from obtaining signifcant P- values after correcting P-values with considering multiple comparisons. → How about unsupervised methods?
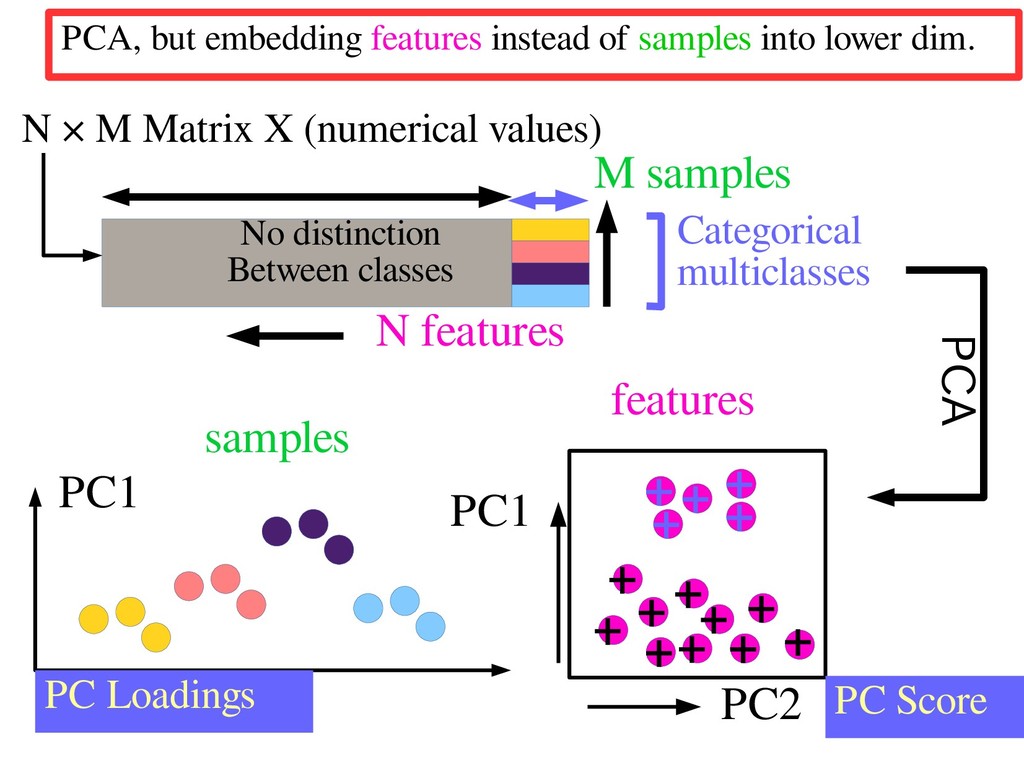
samples N × M Matrix X (numerical values) PC2 PC1 PC Score features + + + + + + + + + + + + + + + No distinction Between classes PCA, but embedding features instead of samples into lower dim.
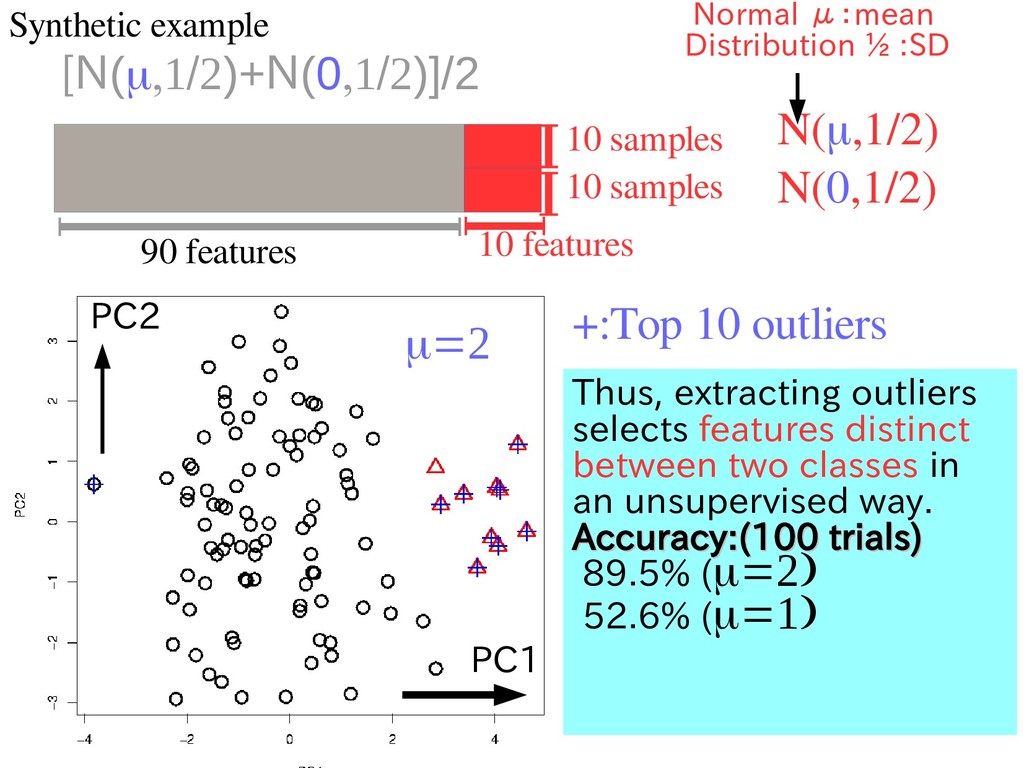
N(0,1/2) N(μ,1/2) [N(m,1/2)+N(0,1/2)]/2 +:Top 10 outliers m=2 Thus, extracting outliers selects features distinct between two classes in an unsupervised way. Accuracy:(100 trials) Accuracy:(100 trials) 89.5% (m=2) 52.6% (m=1) PC1 PC2 Normal μ:mean Distribution ½ :SD
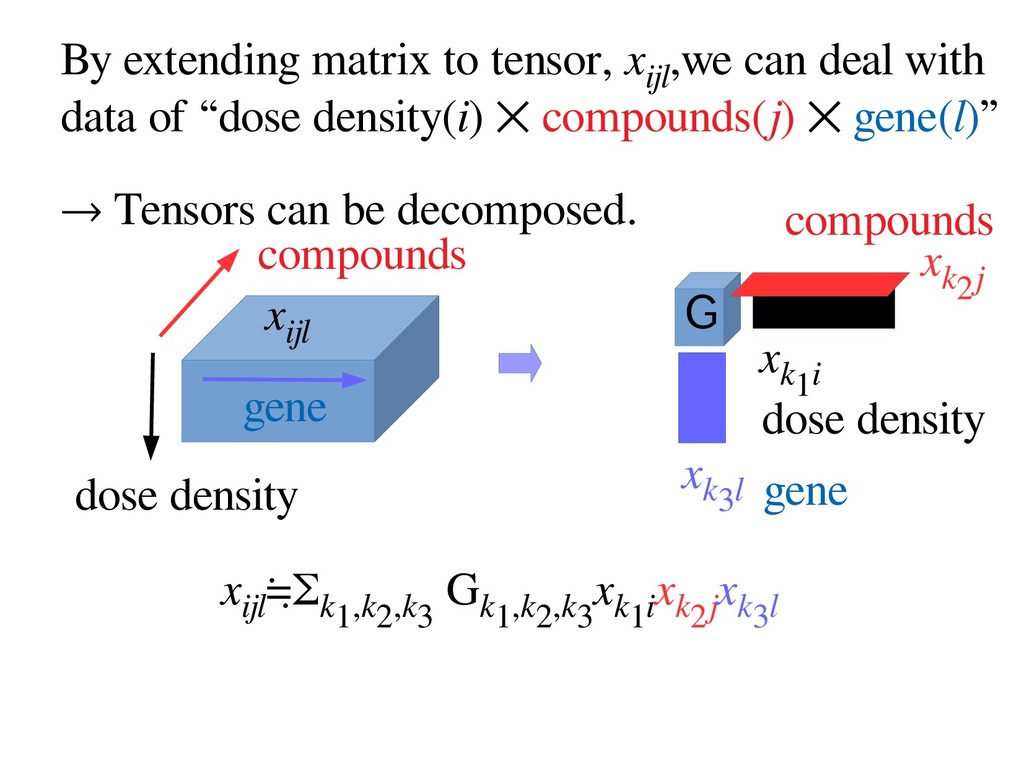
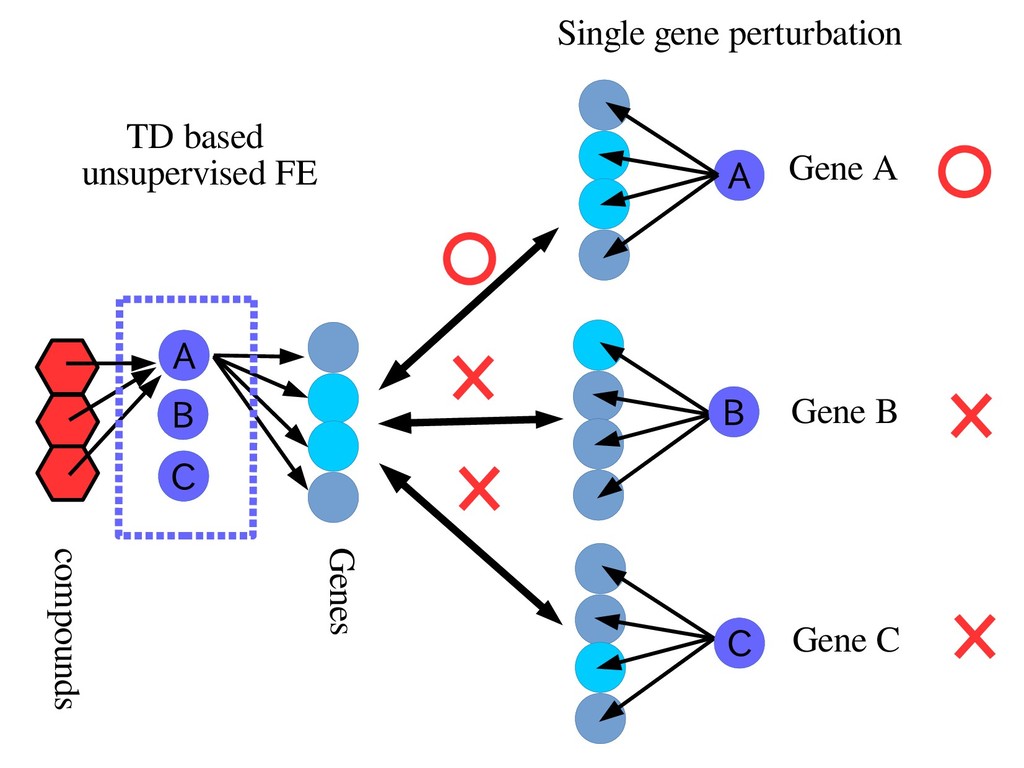
with data of “dose density(i) ⨉ compounds(j) ⨉ gene(l)” → Tensors can be decomposed. x ijl G x k1i x k2j x k3l x ijl ≒Σ k1,k2,k3 G k1,k2,k3 x k1i x k2j x k3l gene compounds dose density compounds dose density gene
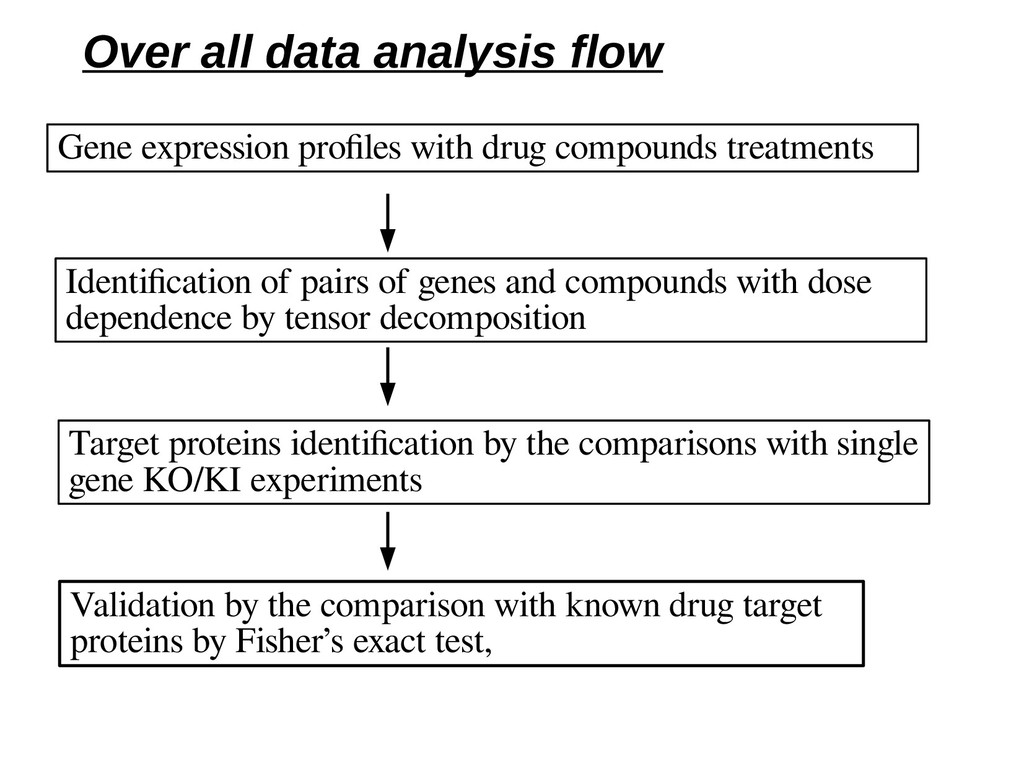
of genes and compounds with dose dependence by tensor decomposition Target proteins identifcation by the comparisons with single gene KO/KI experiments Validation by the comparison with known drug target proteins by Fisher’s exact test, Over all data analysis flow
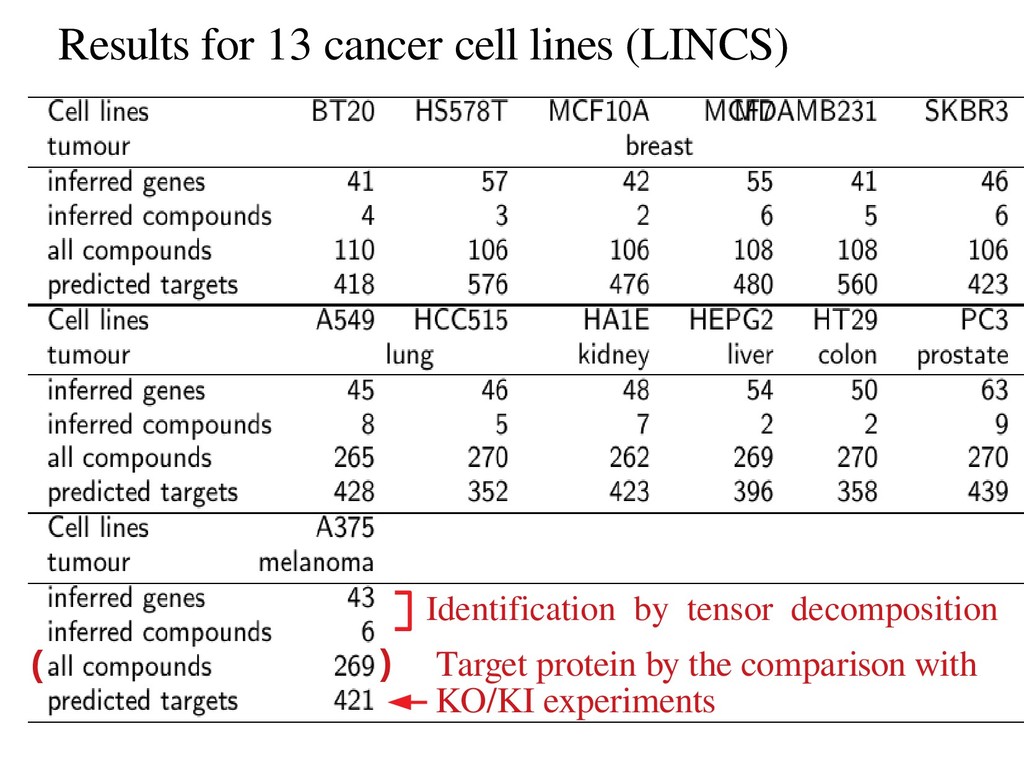
identify genes associated with dose denpendent gene expression profles based upon drug compounds treated gene expression profles. Drug target proteins are further infered by the comparisons with single gene KO/KI expressions. The results are signifcantly overlaped with known drug taregt proteins.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}