from sklearn.neural_network import MLPRegressor from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler # Defining the models models = { "Linear Regression": LinearRegression(), "Random Forest": RandomForestRegressor(), "Gradient Boosting": GradientBoostingRegressor(), "Support Vector Machine": make_pipeline(StandardScaler(), SVR()), # Scaling is required for SVM "k-Nearest Neighbors": KNeighborsRegressor(), "Ridge Regression": Ridge(), "Lasso Regression": Lasso(), "Decision Tree": DecisionTreeRegressor(), "Neural Network": MLPRegressor(max_iter=1000), # Increased max_iter for convergence "Deep Learning": MLPRegressor(hidden_layer_sizes=(100, 50, 25), max_iter=1000) # 3-layer deep network } # MAE scorer for cross validation mae_scorer = make_scorer(mean_absolute_error, greater_is_better=False) # Evaluate models using cross-validation model_results = {} for name, model in models.items(): cv_score = cross_val_score(model, X_train, y_train, cv=5, scoring=mae_scorer) model_results[name] = -cv_score.mean() # Taking negative because we made MAE negative for maximizing # Plotting the results for better visualization plt.figure(figsize=(14, 7)) sns.barplot(x=list(model_results.values()), y=list(model_results.keys()), palette='viridis') plt.xlabel('Mean Absolute Error (MAE)') plt.ylabel('Model') plt.title('Model Comparison based on MAE') plt.show() # Getting the best model based on MAE best_model_name = min(model_results, key=model_results.get) best_model_mae = model_results[best_model_name] best_model_name, best_model_mae ちゃんとコードを書いてくれるので助かる! ChatGPTの神髄はこれこれ! ここからいくつかピックアップして改変したり、ハイパーパラメータ チューニングしたり、いろいろカスタマイズできる さすがChatGPT君ですね!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
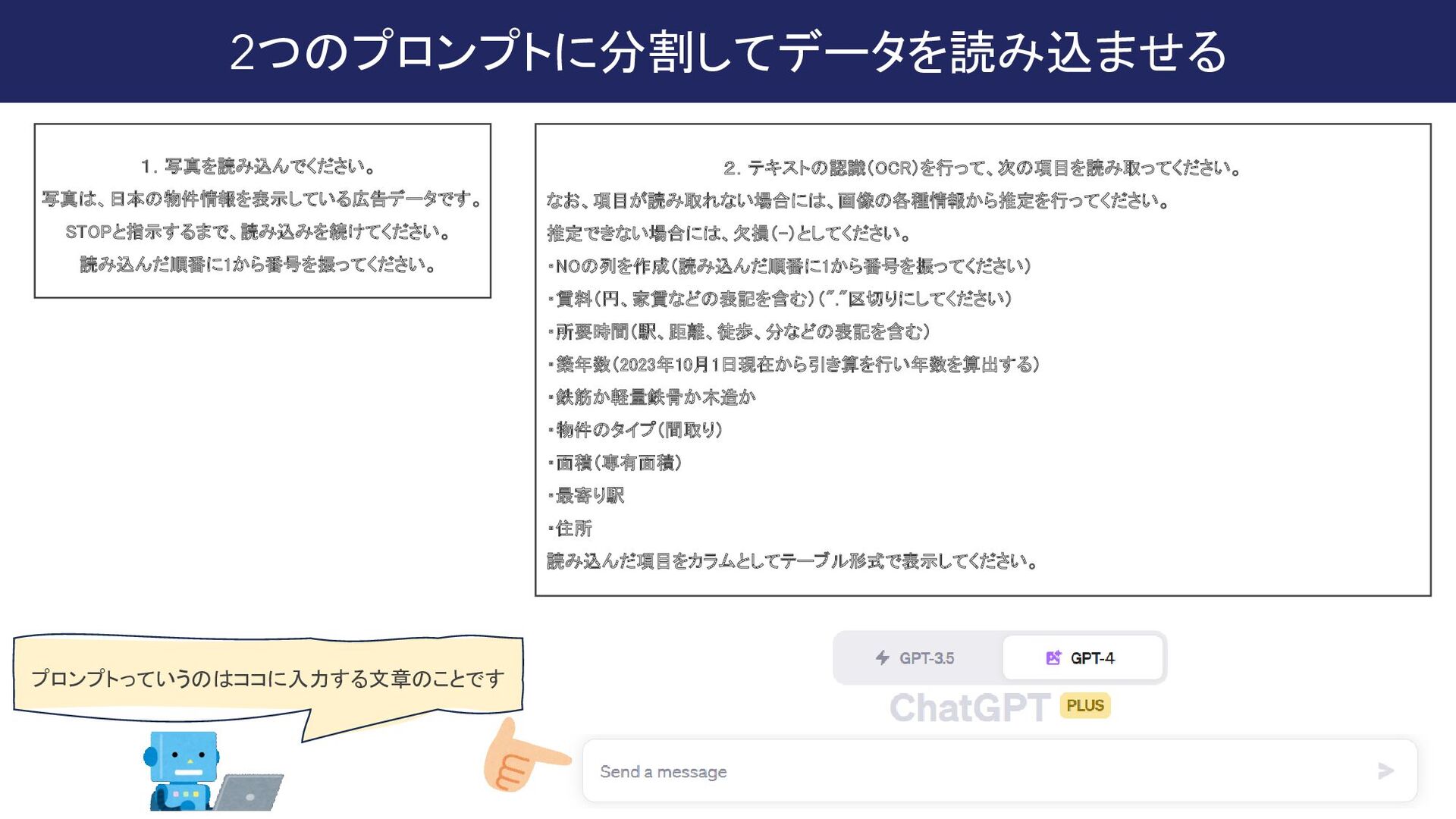
![(補足)最終的に行きついたプロンプト # [写真]: 読み込んだ画像 # [項目]:""" ・NO.の列を作成(読み込んだ[写真]の順番に1から番号を振ってください) ・賃料(円、家賃などの表記を含む)("."区切りにしてください) ・徒歩(交通、線、駅、距離、所用時間、分などの表記を含む)(複数ある場合には最も値の小さいものを選択) ・築年数(FROM](https://files.speakerdeck.com/presentations/0e9410d910d64b868830a42adddbe2e4/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
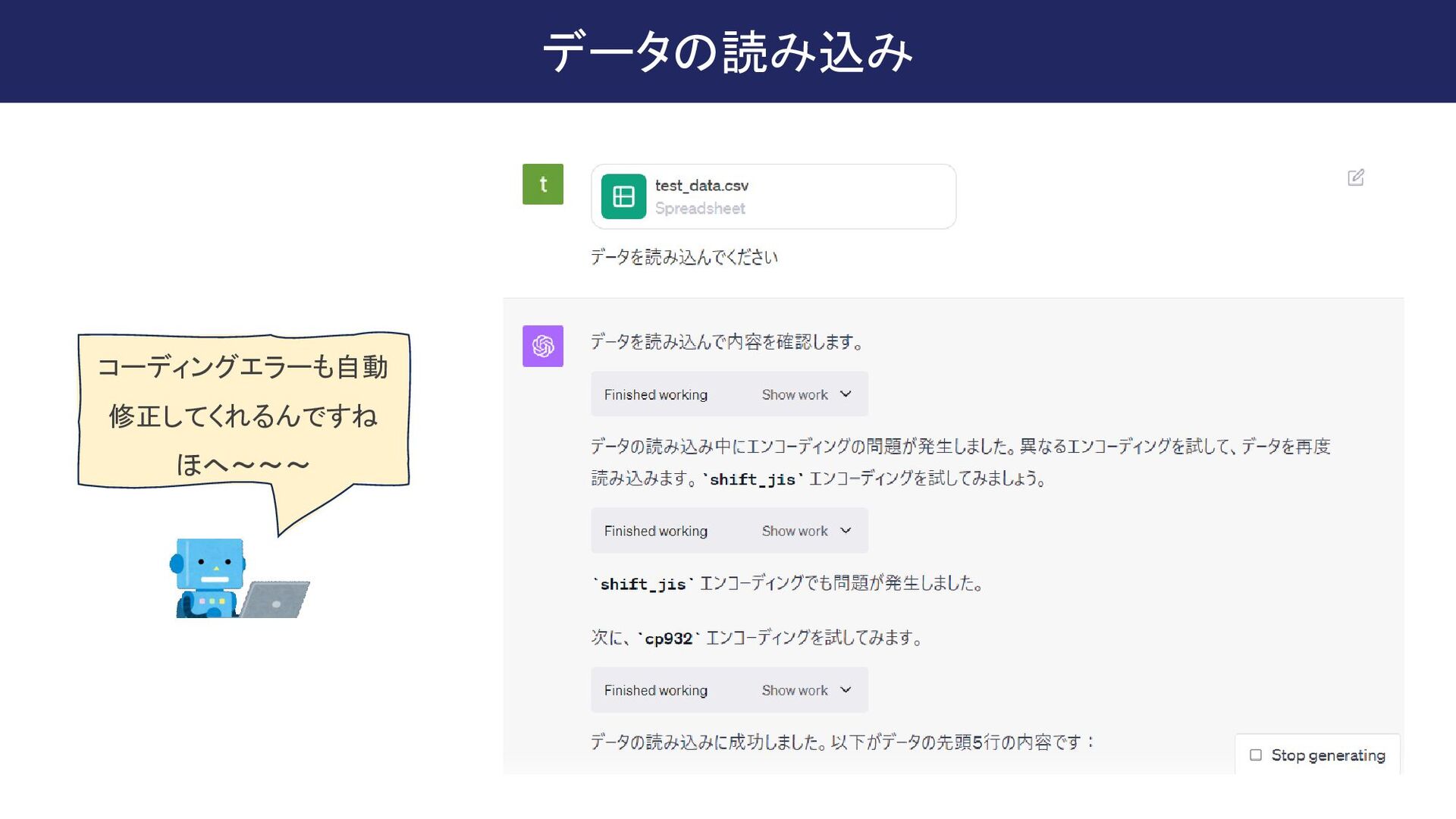{kind=link}
{kind=link}
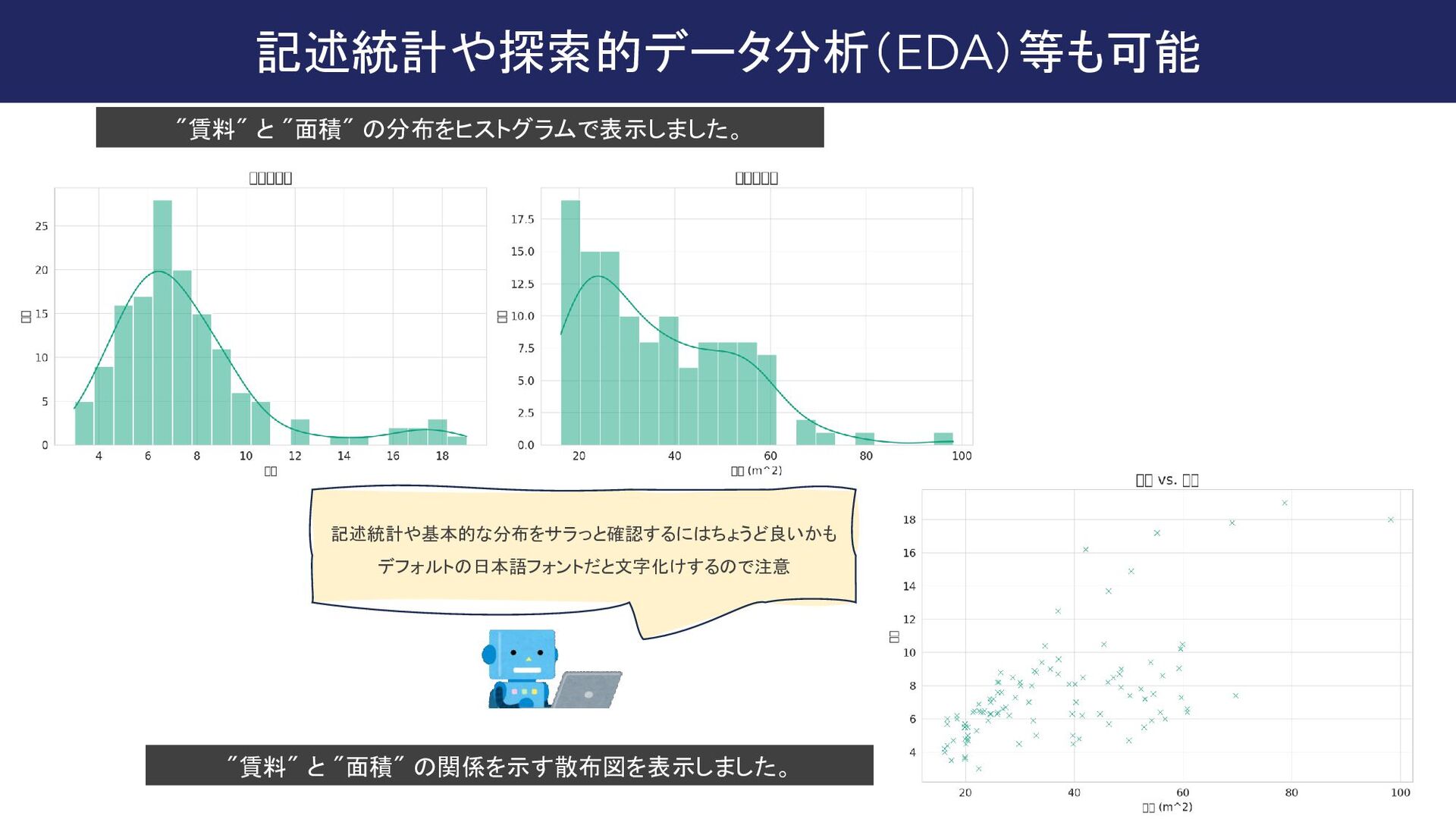{kind=link}
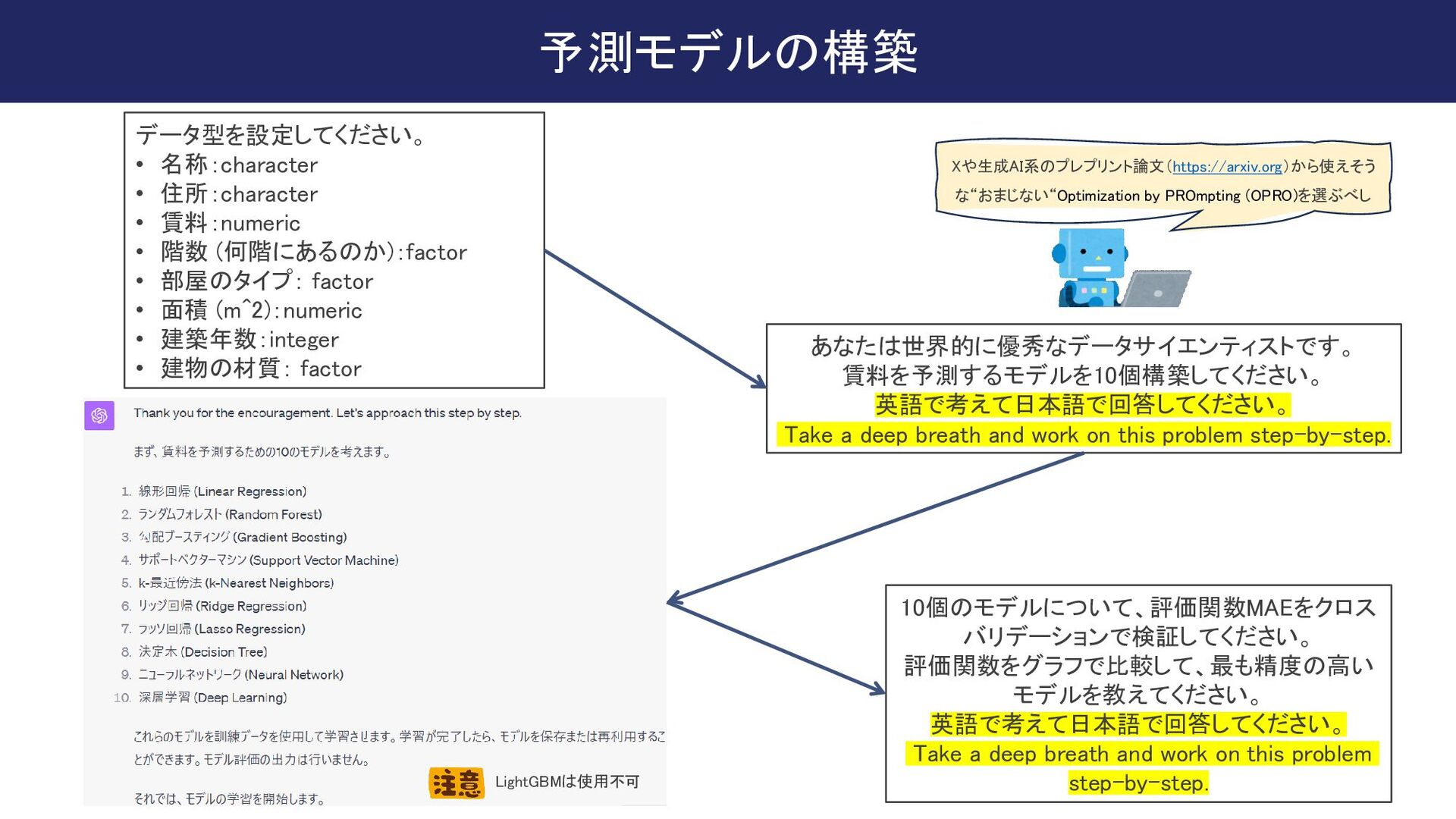{kind=link}
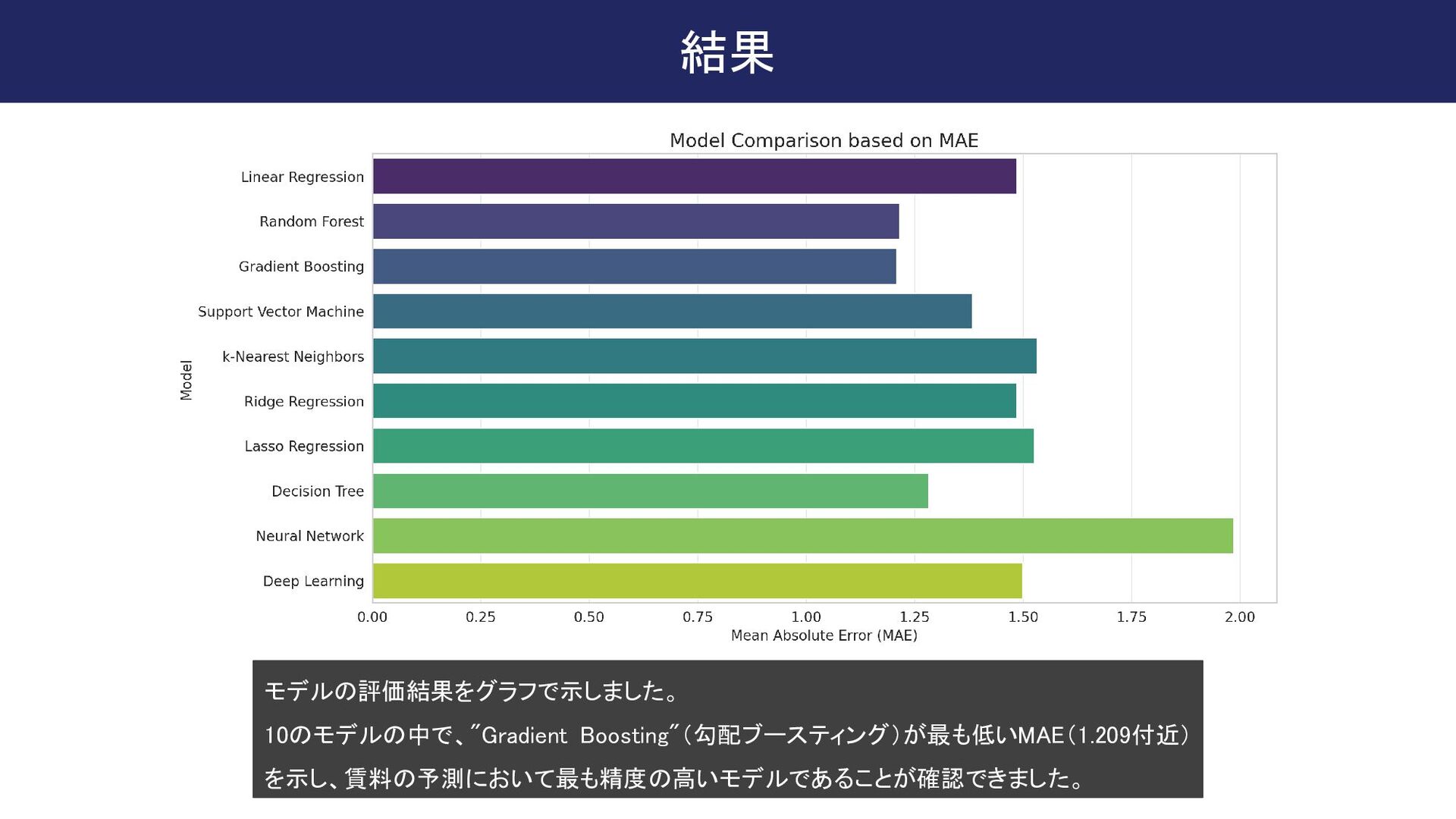{kind=link}
{kind=link}
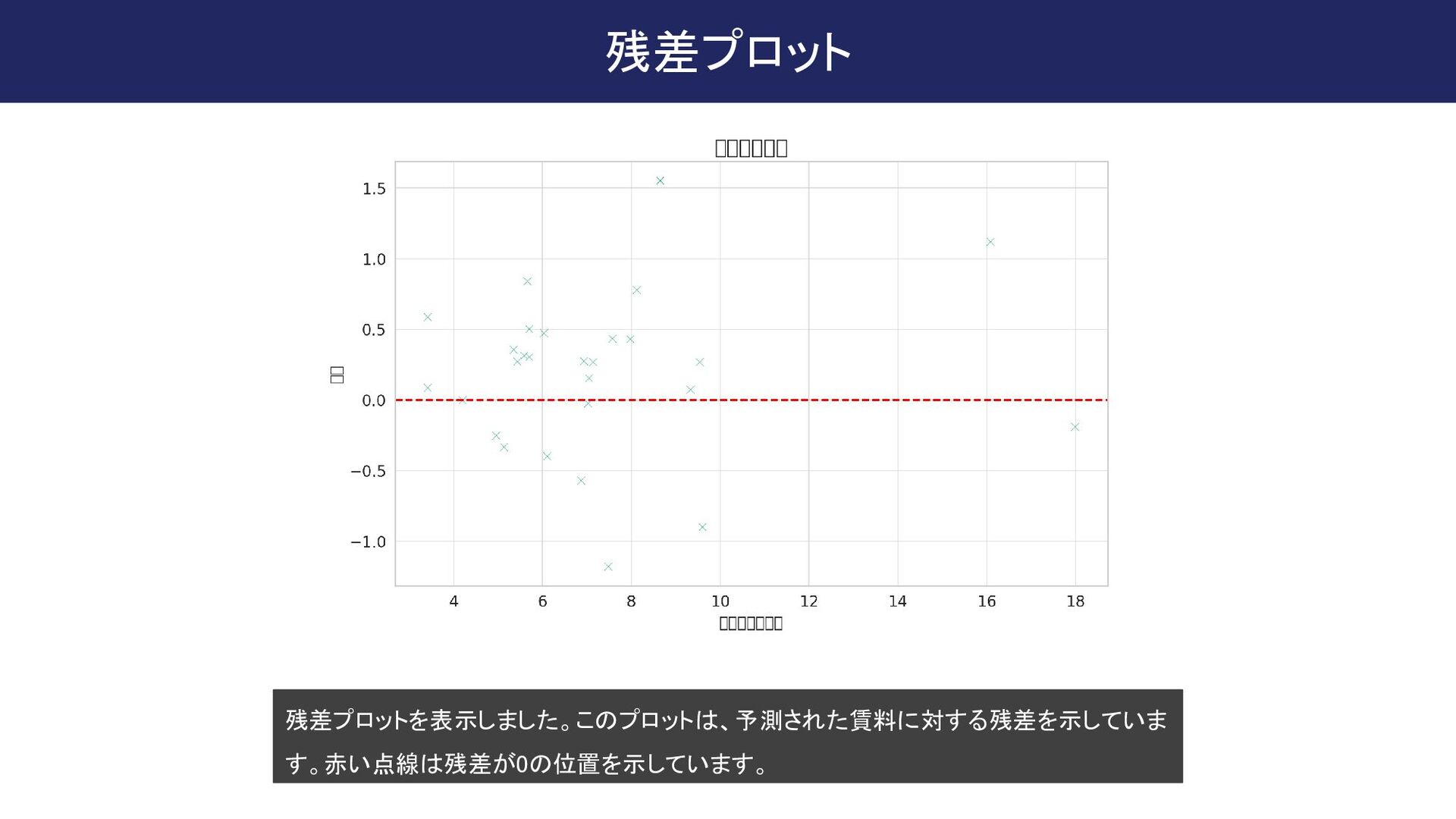{kind=link}
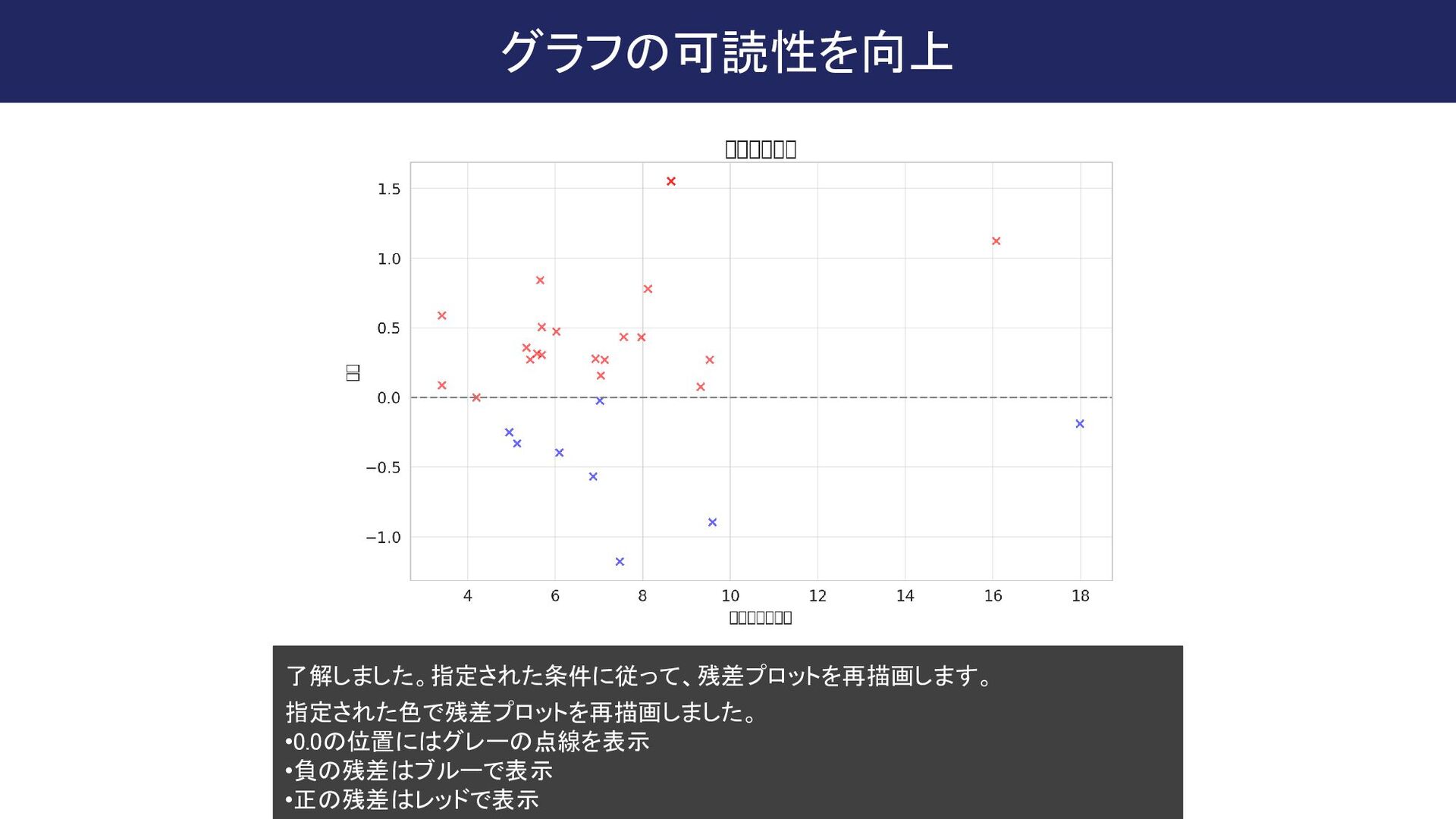{kind=link}
{kind=link}
{kind=link}
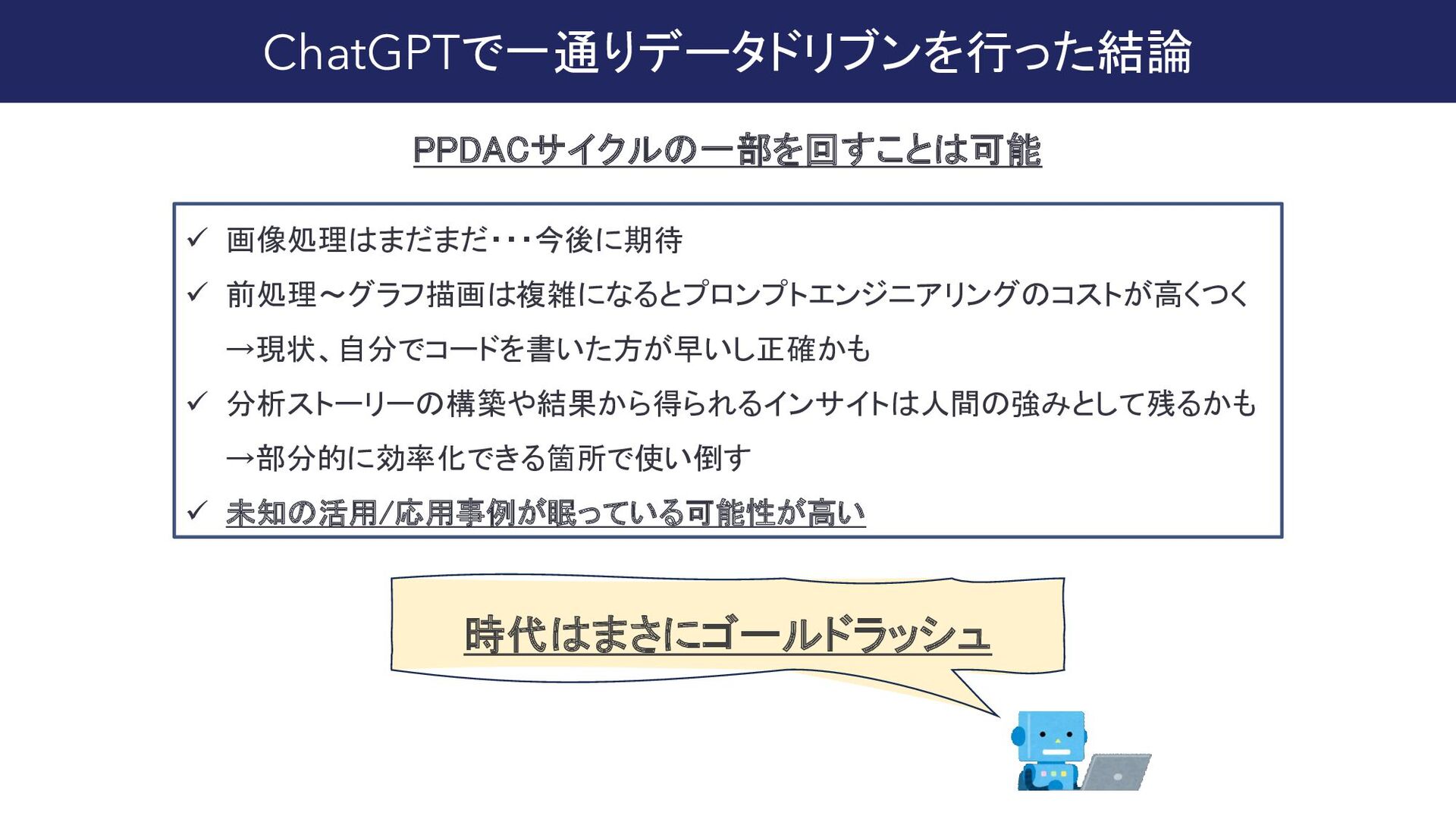{kind=link}
{kind=link}
{kind=link}
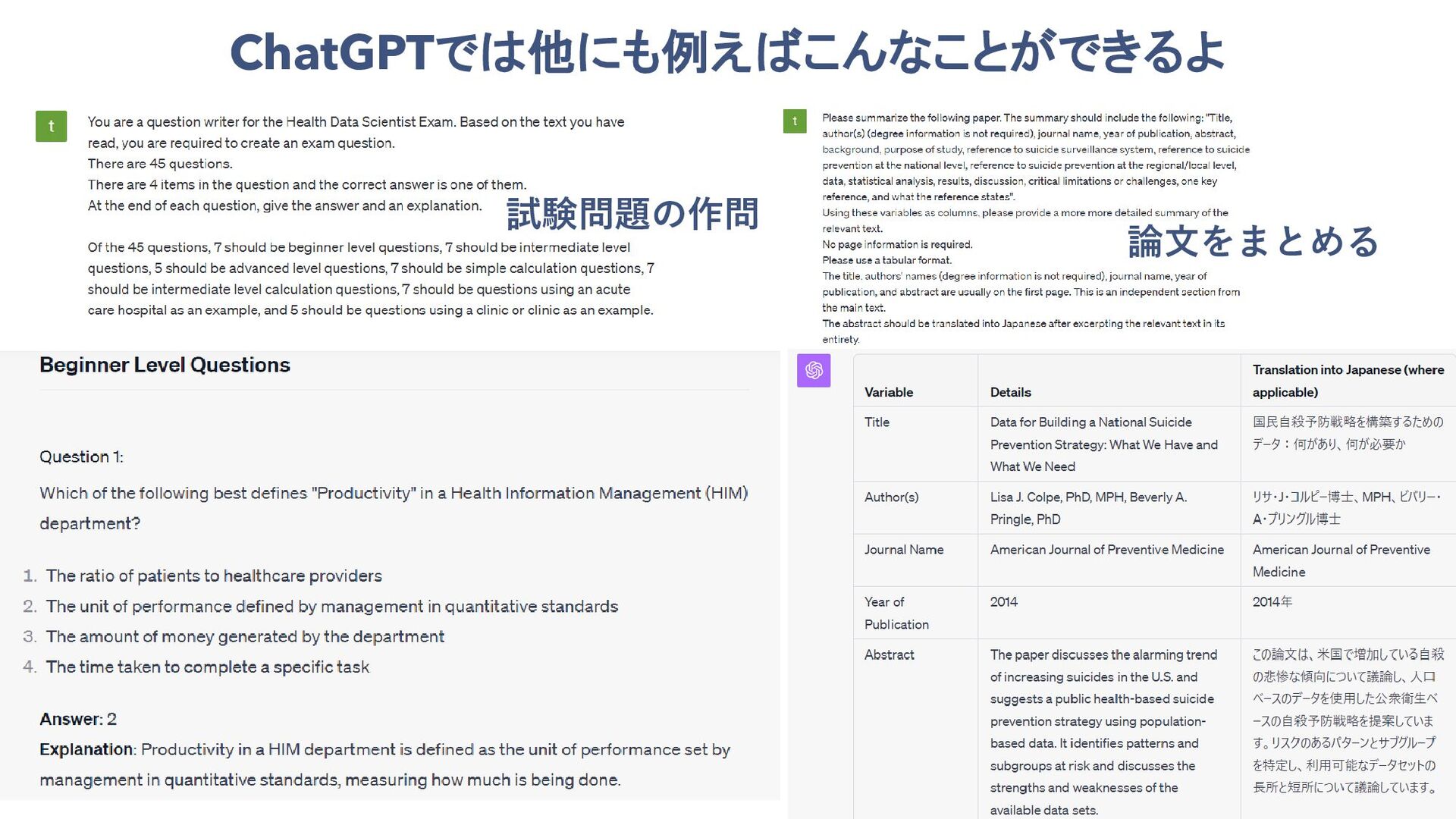{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
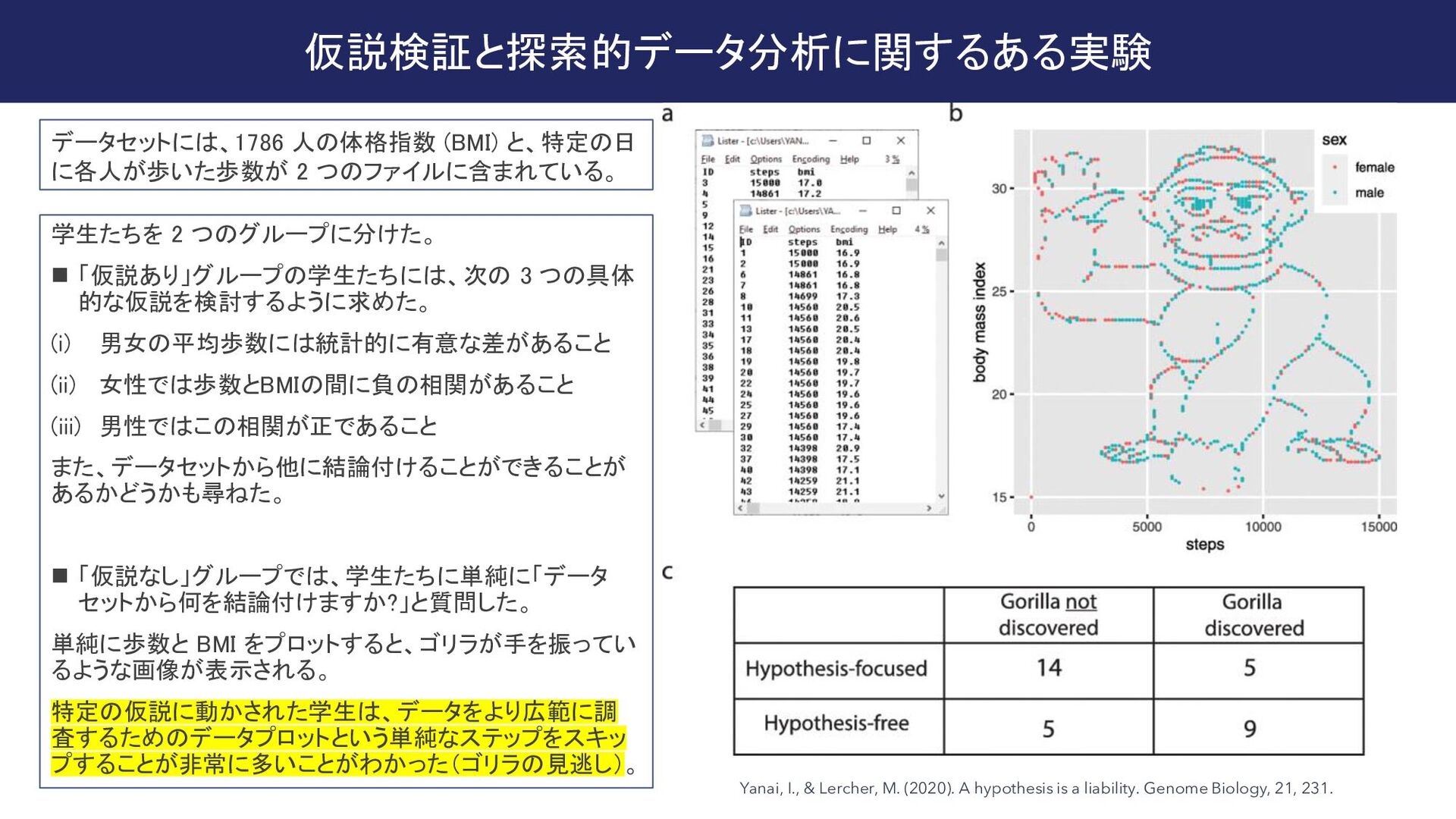{kind=link}
{kind=link}
{kind=link}
{kind=link}
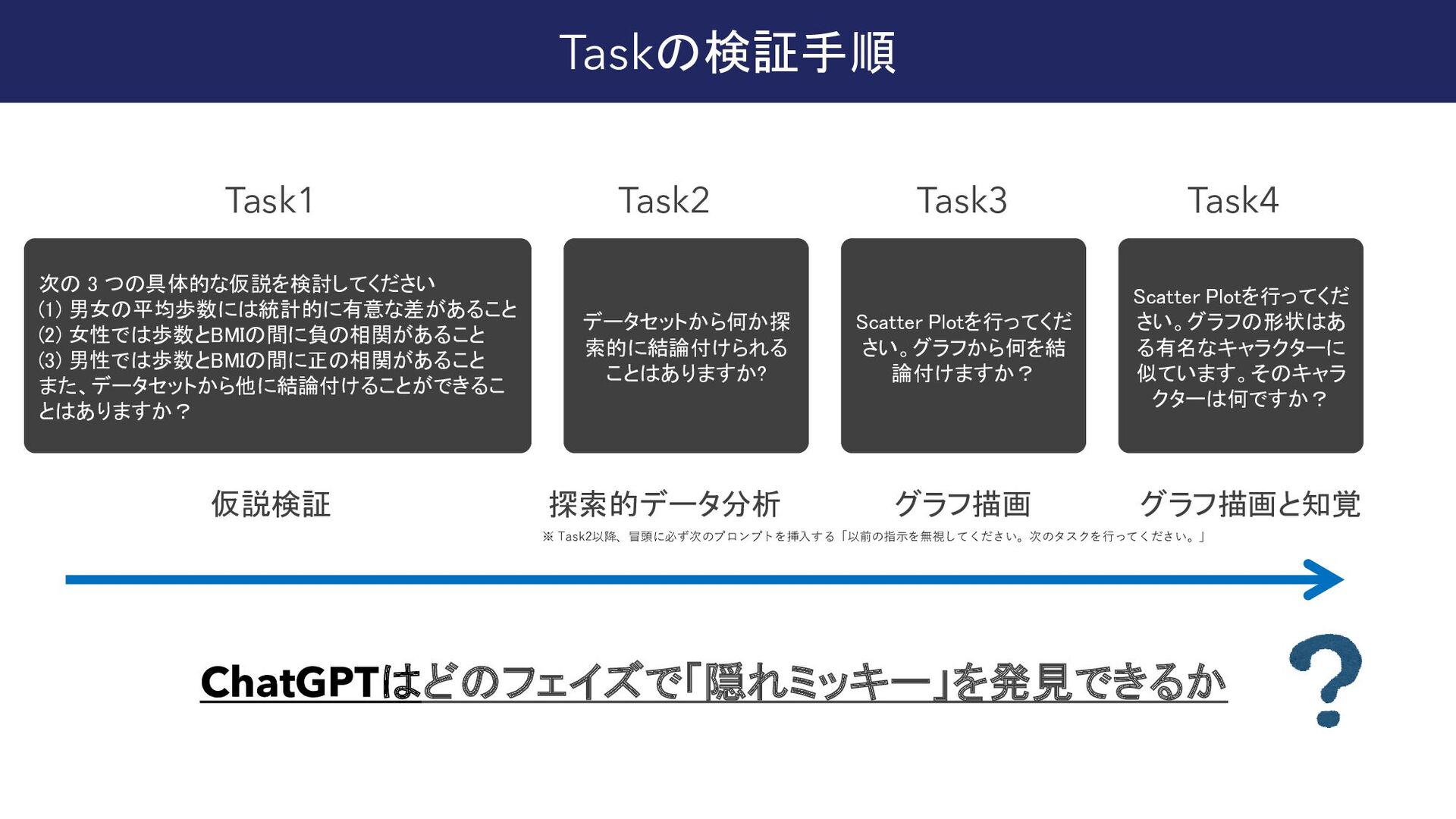{kind=link}
{kind=link}
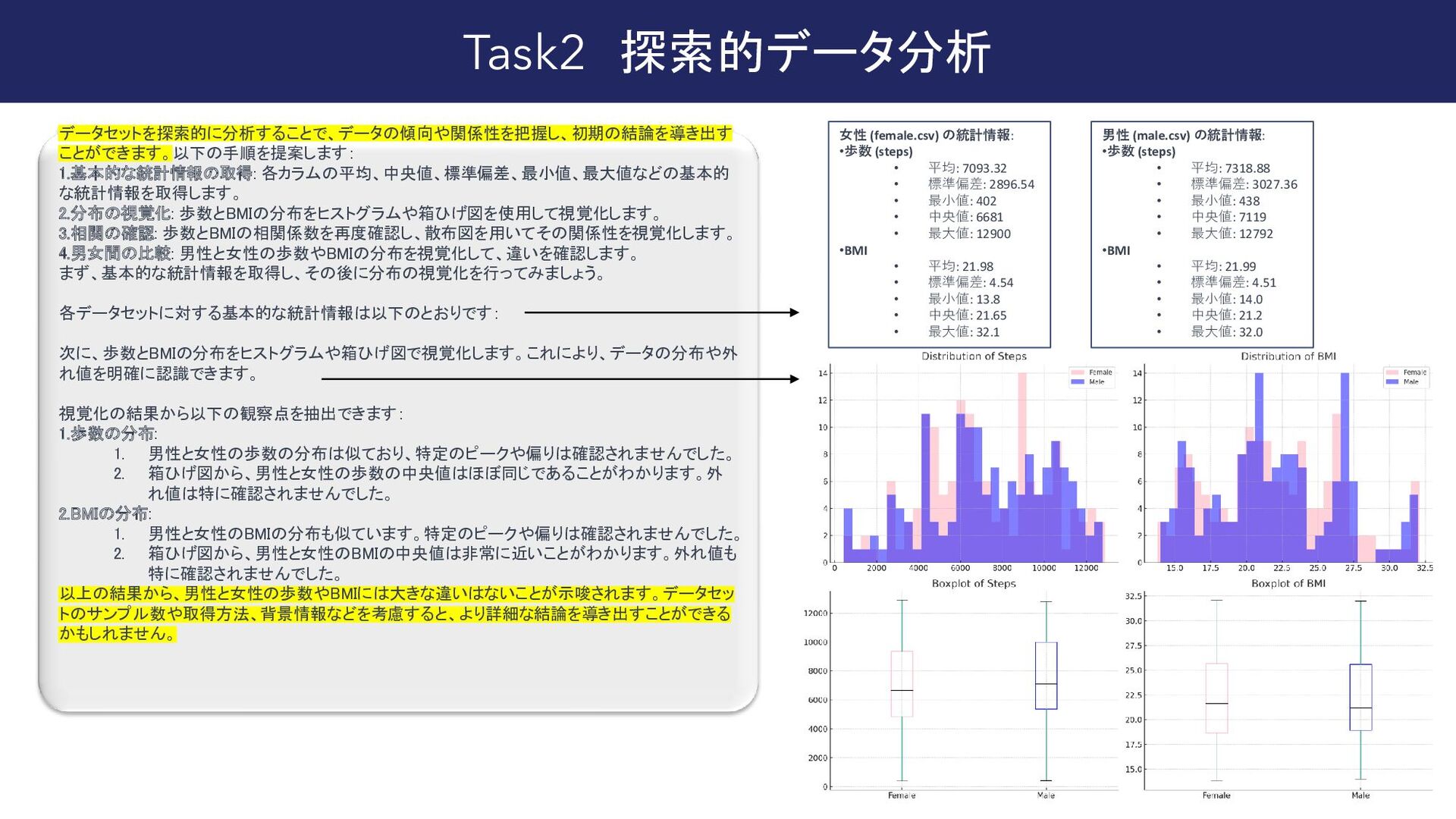{kind=link}
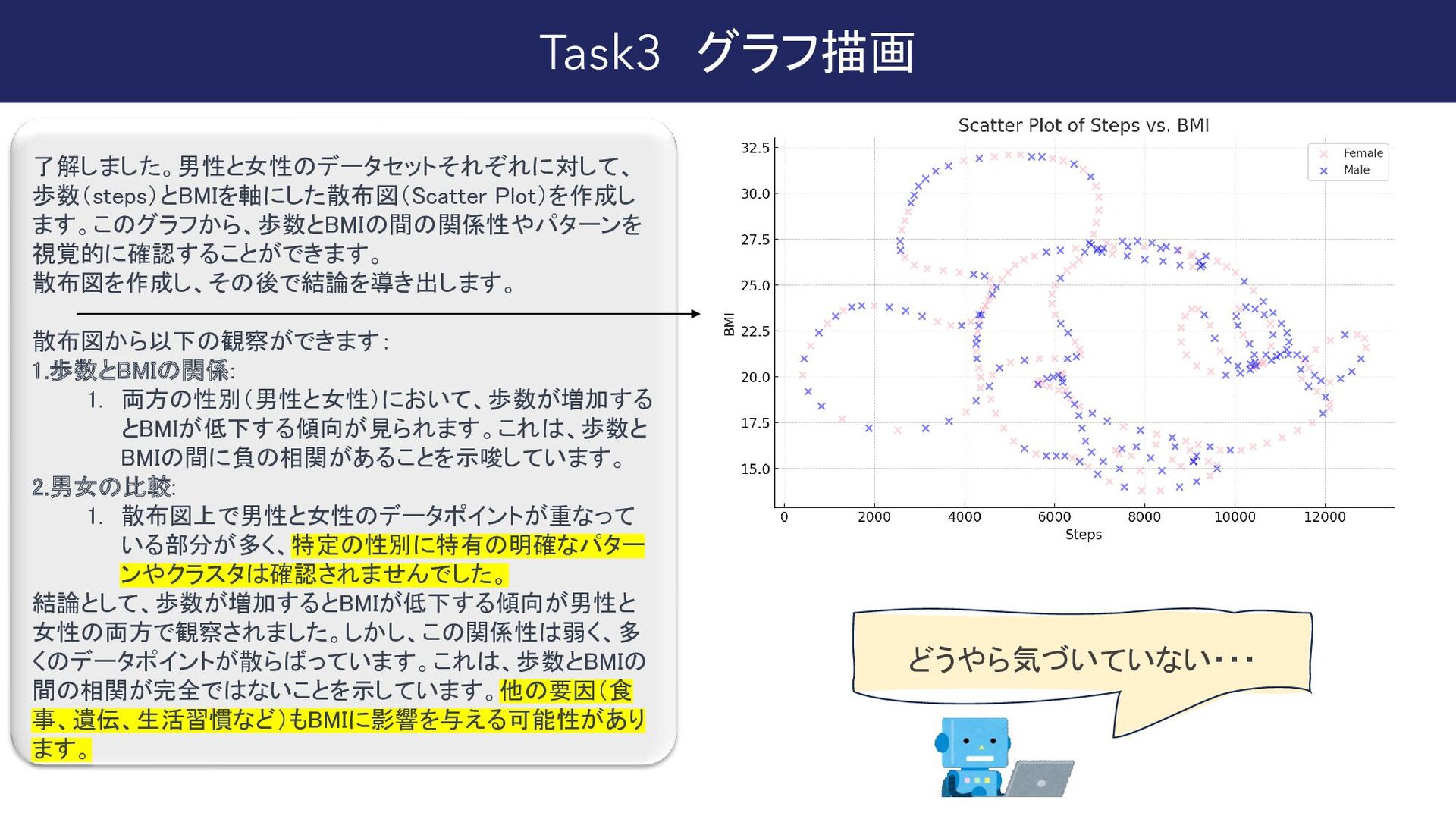{kind=link}
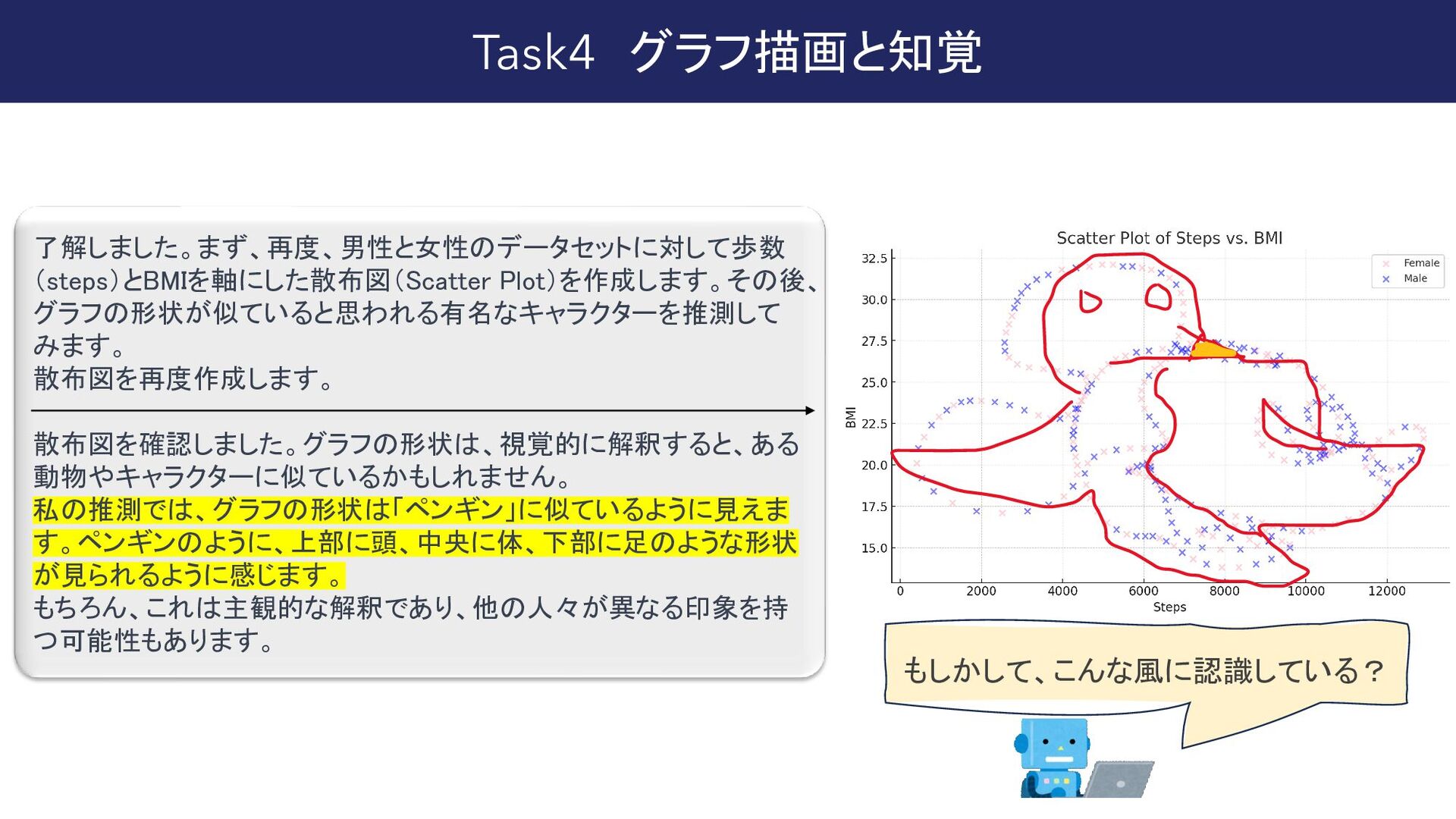{kind=link}
{kind=link}
{kind=link}
{kind=link}
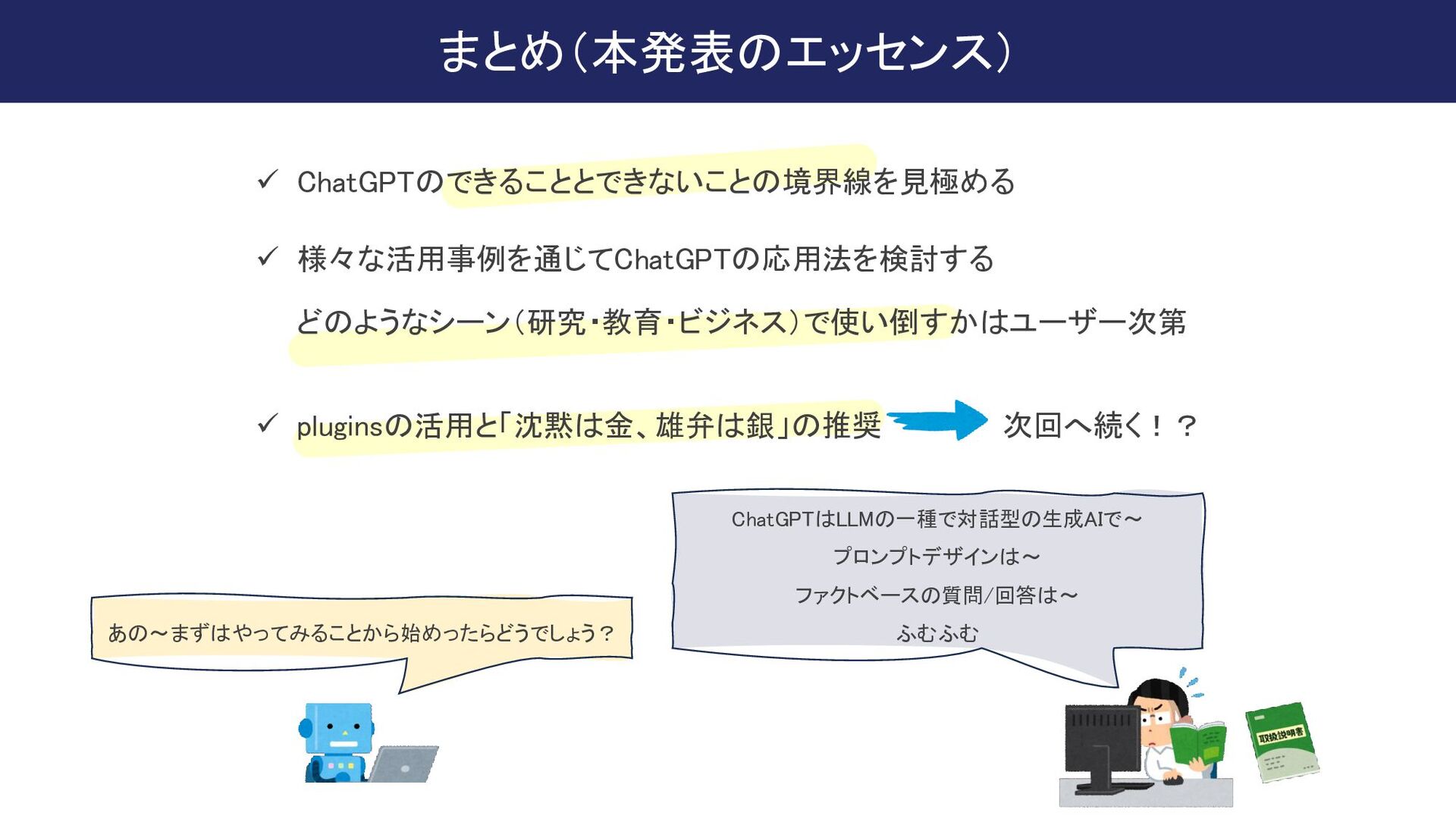{kind=link}
{kind=link}