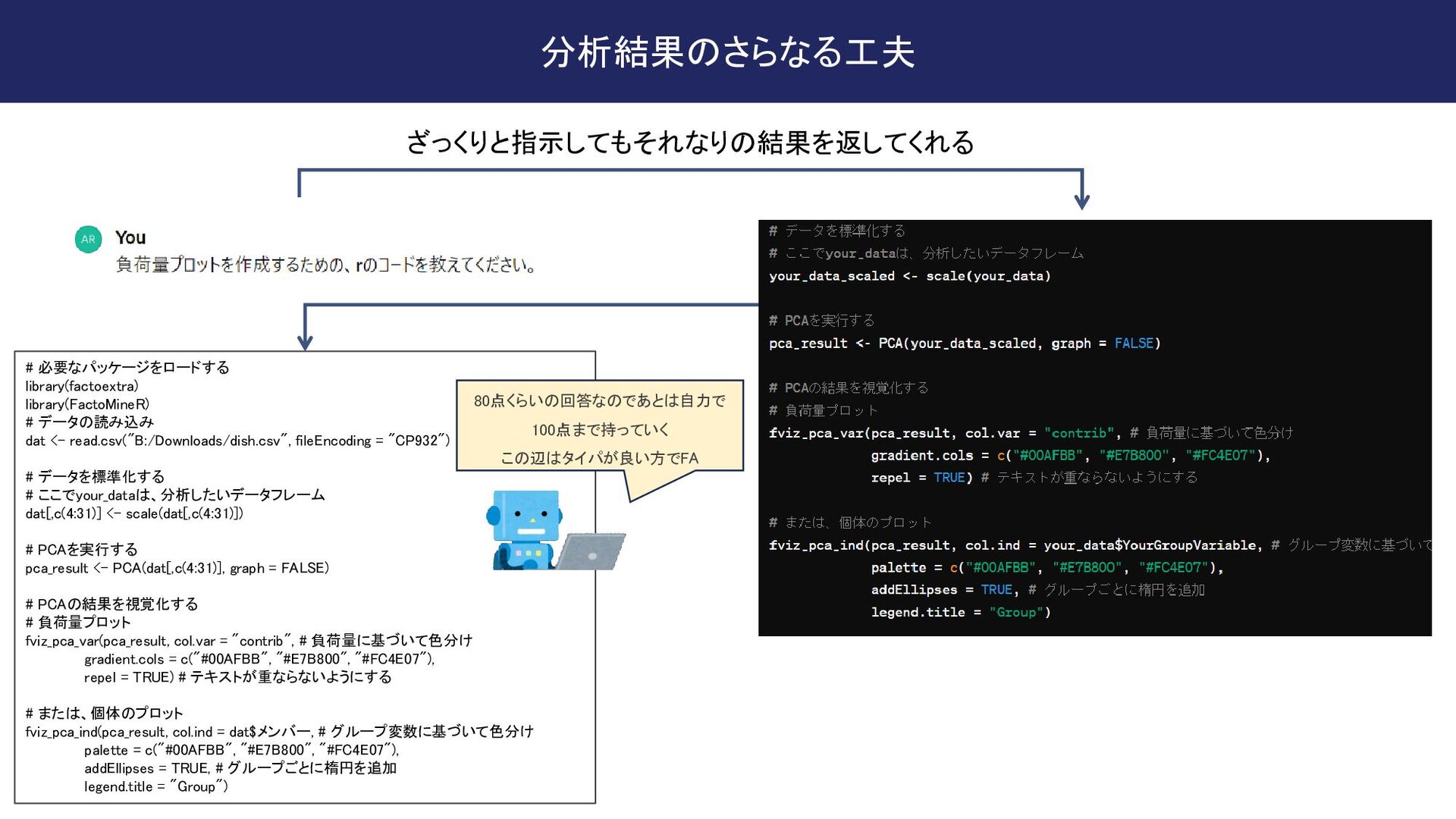
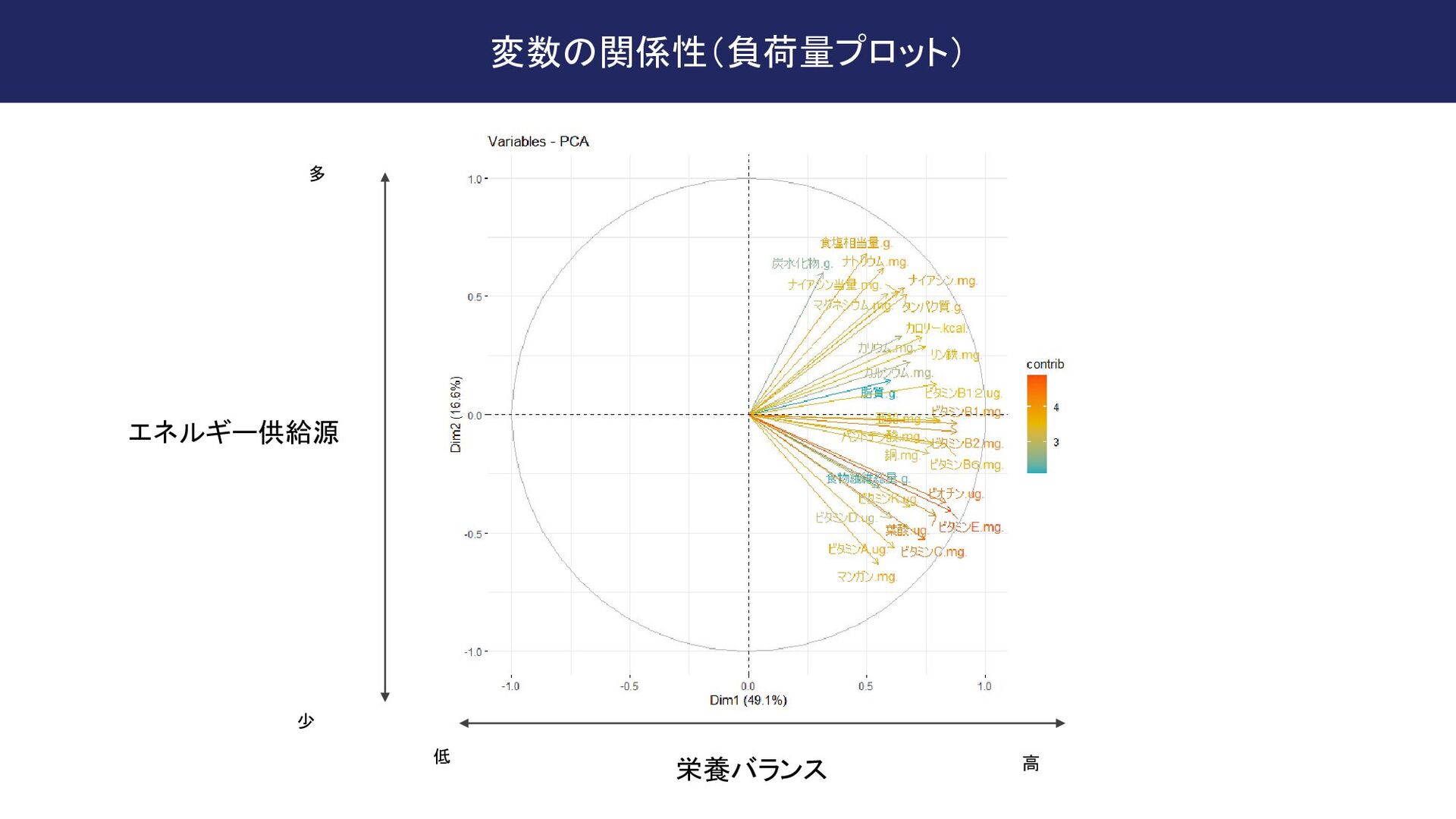
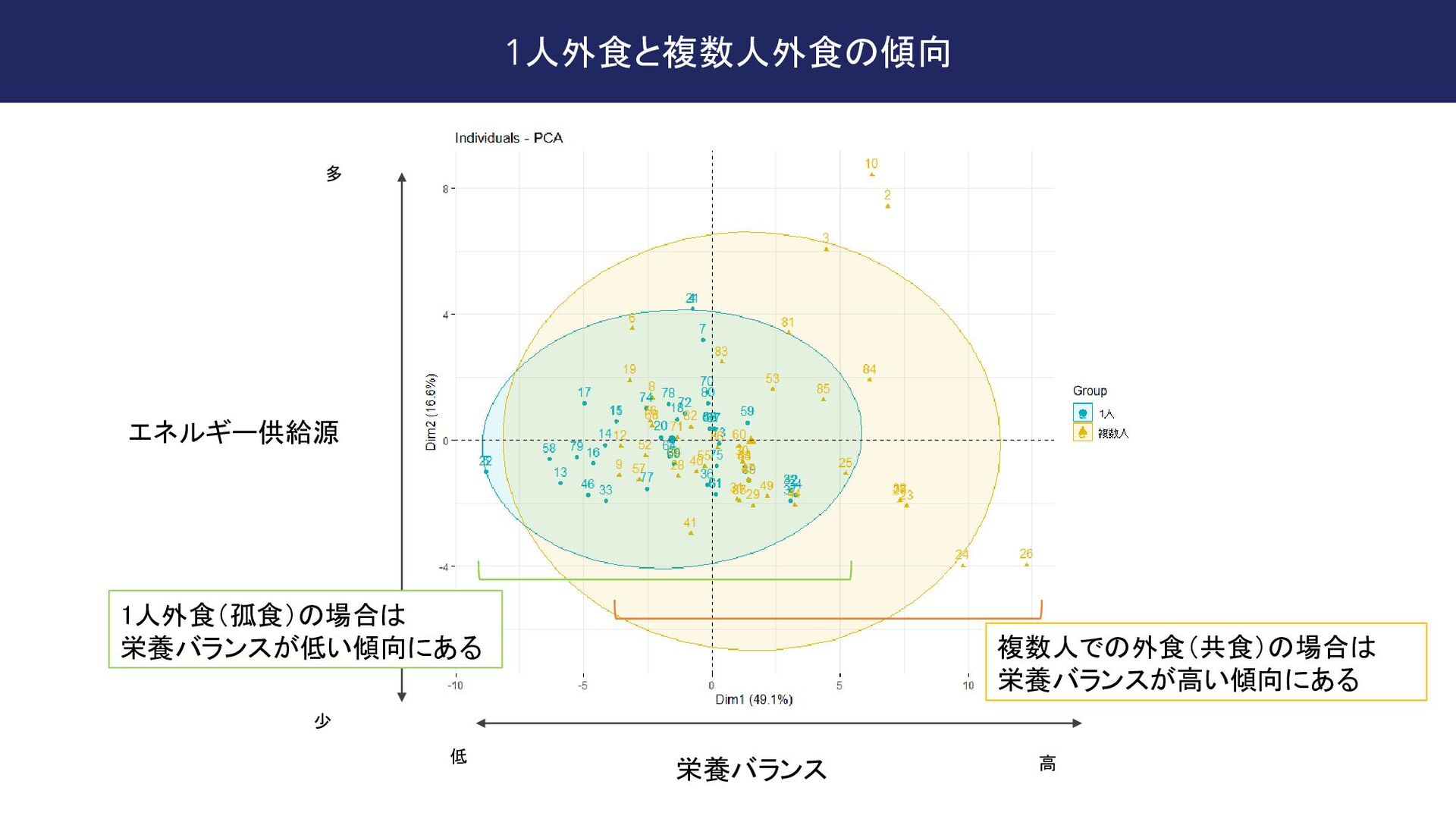
fileEncoding = "CP932") # データを標準化する # ここでyour_dataは、分析したいデータフレーム dat[,c(4:31)] <- scale(dat[,c(4:31)]) # PCAを実行する pca_result <- PCA(dat[,c(4:31)], graph = FALSE) # PCAの結果を視覚化する # 負荷量プロット fviz_pca_var(pca_result, col.var = "contrib", # 負荷量に基づいて色分け gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"), repel = TRUE) # テキストが重ならないようにする # または、個体のプロット fviz_pca_ind(pca_result, col.ind = dat$メンバー, # グループ変数に基づいて色分け palette = c("#00AFBB", "#E7B800", "#FC4E07"), addEllipses = TRUE, # グループごとに楕円を追加 legend.title = "Group") ざっくりと指示してもそれなりの結果を返してくれる 80点くらいの回答なのであとは自力で 100点まで持っていく この辺はタイパが良い方でFA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![プロンプトエンジニアリング(リバースエンジニアリング) あなたは、栄養学の専門家です。いまから、与えられる10個の料理の画像を認識してください。 料理画像から食品名を分解してください。[栄養情報データベース]を用いて、D列の食品名に対応する[項目]と成分量を推定します。分解した各食品名の栄養素を、合計し、料理画像の総合栄養成分を算出した データテーブルを作成します。したがって、1つの写真につき1レコードのデータを作成し、10個のレコードが作成されます。なお、[栄養情報データベース]は100g当たりの栄養です。推計は次のステップで行います。 1.写真から一般的な料理名を推測 2.写真から各食品名を推測する 3.[栄養情報データベース]から類似する食品名を見つけて栄養成分を計算 4.各料理の栄養成分の合計値を算出しし、料理名の栄養成分とする 最終的には、料理のクラスタリングを行うことが目的なので、それに適したCSVデータテーブルを作成してください。 #](https://files.speakerdeck.com/presentations/784f1d312bdc4c88bb8bc84d79f7cf54/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}