twitter @tammybutow. I work at Gremlin, I’m an SRE. I work remotely from Australia right now, our head office is in Silicon Valley. Where else can you find me? Twitter: twitter.com/tammybutow Website: tammybutow.com
• Incident Response • Incident Management • Observability & Monitoring • Hardware Engineering • Gamedays and Disaster Recovery Testing • Team Leadership • Security & Product Engineering Work Locations: • Sydney • Brisbane • Melbourne • New York • San Francisco • … now remote!
of CE Chaos Engineering is an emerging discipline, but the underlying concepts are not. Failure is going to happen - Are you ready for it? Put simply, Chaos Engineering is one approach to “breaking things on purpose” that teaches us new information about our systems through experimentation. By triggering incidents intentionally in a controlled way, we gain confidence that our systems can deal with those failures before they occur in production. By practicing Chaos Engineering you’ll learn how to build systems and organizations that improve in the face of failure.
of CE The lesson we should learn and remember is that sooner or later, all complex systems will fail. It’s not a matter of if, it’s a matter of when. There will always be something that can — and will — go wrong. Break Things on Purpose. Building resilient systems requires experience with failure. Waiting for things to break in production is not an option. We should rather inject failures proactively in a controlled way to gain confidence that our production systems can withstand those failures. By simulating potential errors in advance, we can verify that our systems behave as we expect — and to fix them if they don’t.
of CE You should never conduct a chaos experiment in production if you already know that it will cause severe damage, possibly affecting customers — and with them, your reputation. Always try to fix known problems first! Chaos Engineering requires a base level of resilience.
focus first? My top 3 recommendations for selecting services/systems: 1. Tier 0 / critical services - “what are your top 5 most critical systems?” 2. Services which serve critical functions, e.g. bushfire warning system 3. Services which store critical data, e.g. data storage/big data
need before you can get started? My top 3 must-have recommendations for availability: 1. High Severity Incident (SEV) Management including SEV levels and definitions 2. Availability monitoring, including a high level health dashboard for WWW and API 3. Alerts and paging that call a human and wake them up for SEVs
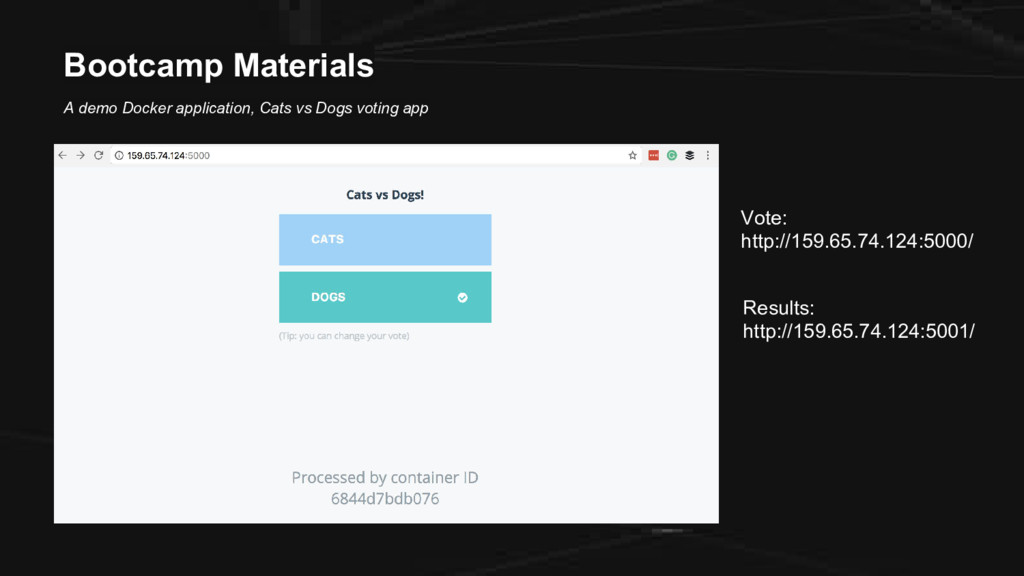
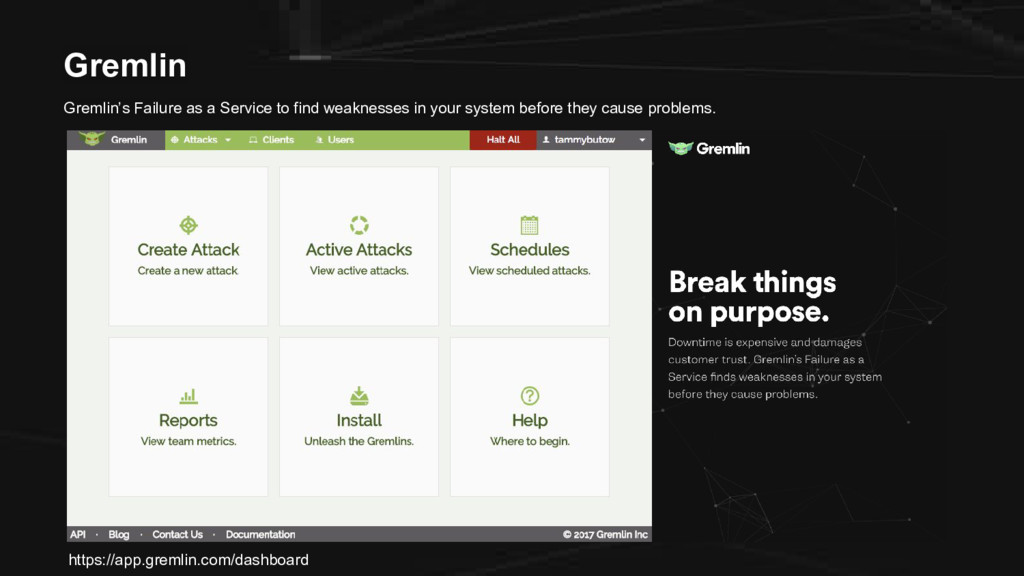
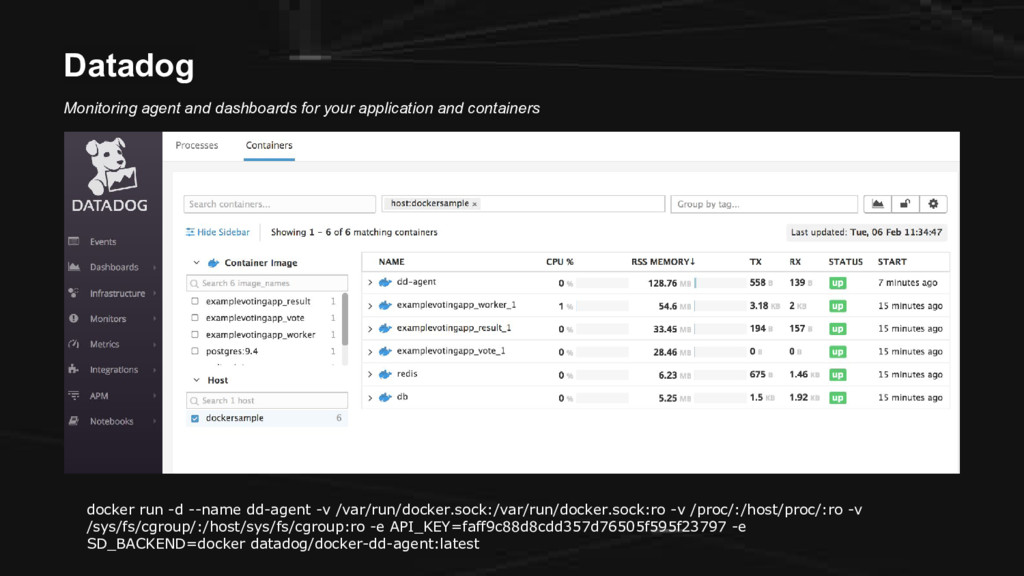
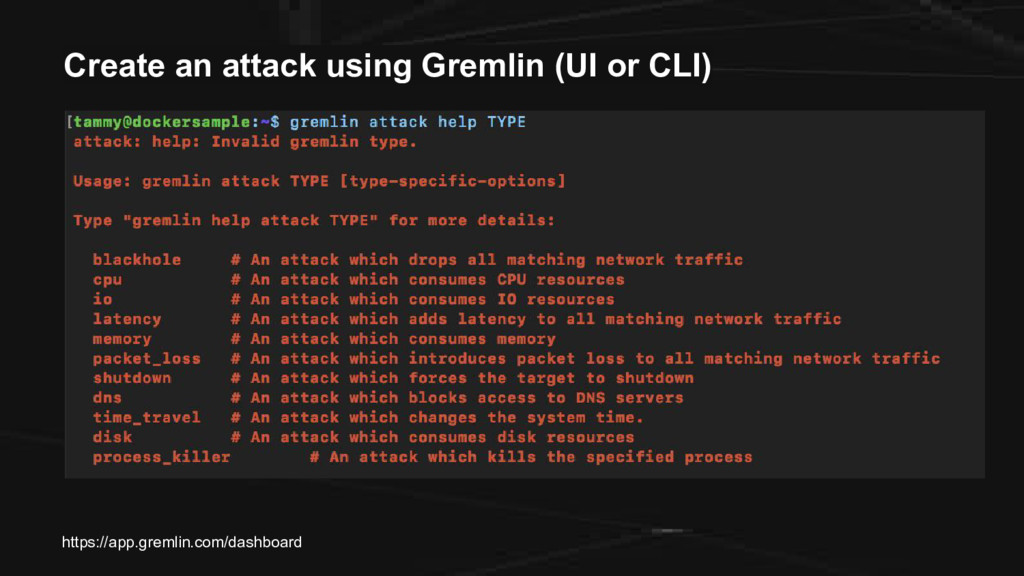
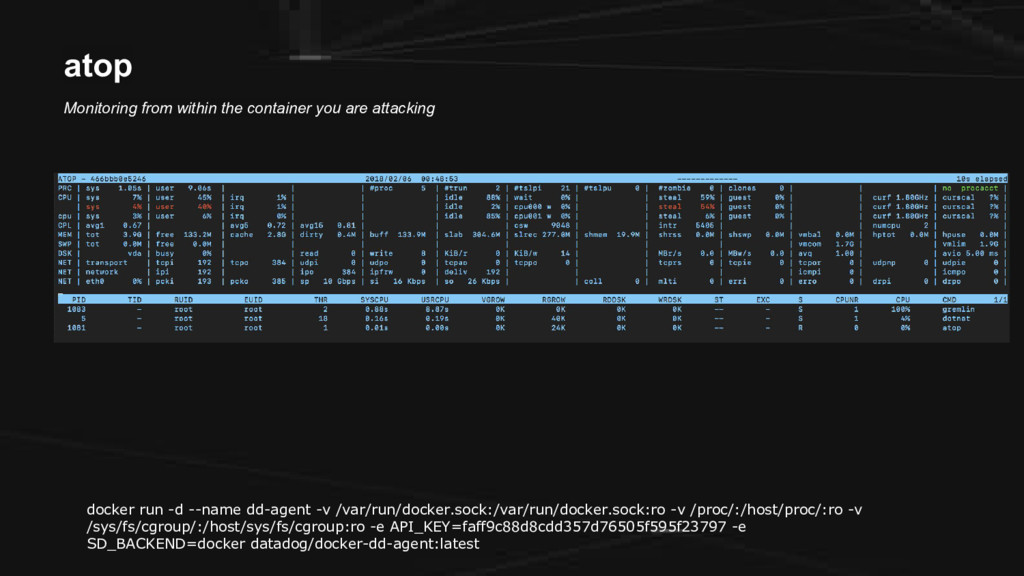
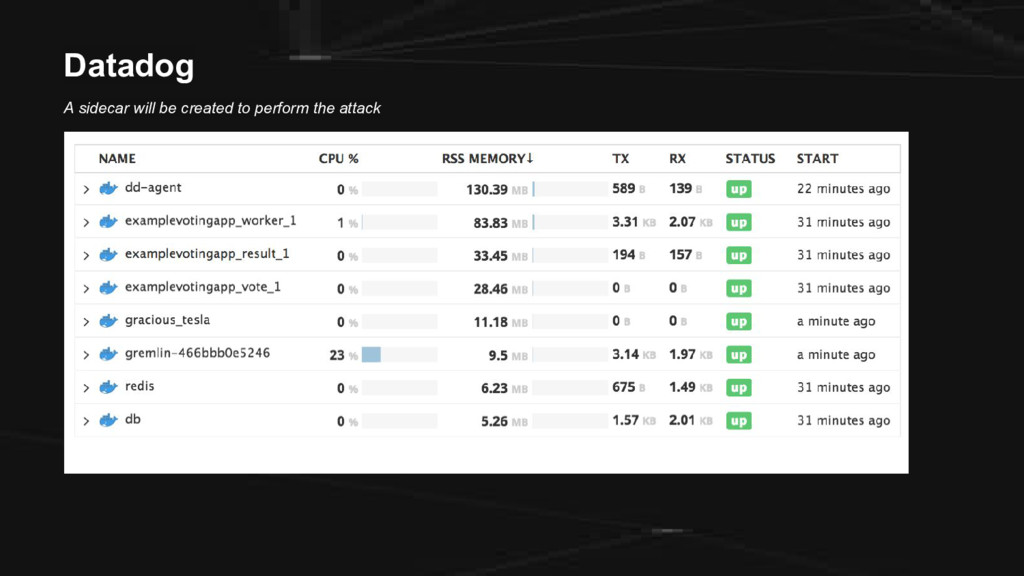
CE We have the following: 1. A droplet from DigitalOcean (cloud infrastructure) 2. Docker (containers) 3. Weavenet Sock Shop (microservices app) 4. Gremlin (chaos engineering) 5. Datadog (monitoring)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
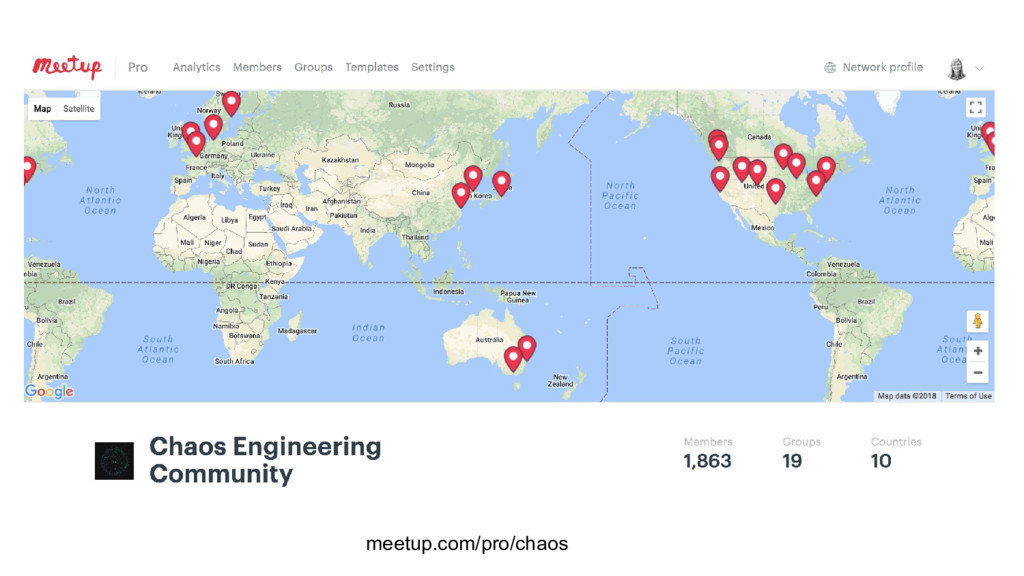{kind=link}
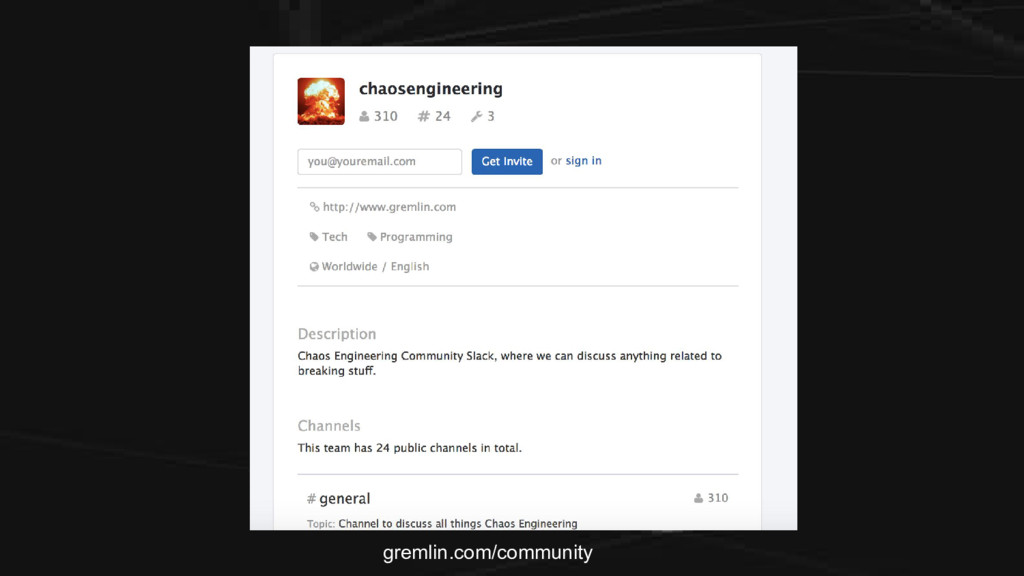{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}