Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Google Colaboratory でStable Diffusionの実装 / Impl...
Search
tasotaku
October 29, 2022
Programming
470
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Google Colaboratory でStable Diffusionの実装 / Implementation of Stable Diffusion at Google Colaboratory
Google Colaboratory でStable Diffusionを実装しました。少し遊んでみたのと、構造も少し調べました。
tasotaku
October 29, 2022
More Decks by tasotaku
See All by tasotaku
duel_masters_RAG
tasotaku
0
110
DQNによるポーカーの強化学習/Reinforcement Learning in Poker with DQN
tasotaku
0
870
オセロCPU/Othello CPU
tasotaku
0
200
オセロAI / OthelloAI
tasotaku
0
230
私、ChatGPTがChatGPTを解説するよ! / ChatGPT explains ChatGPT
tasotaku
0
520
機械学習入門
tasotaku
0
500
AIが作る予想外な画像を考える / Consider the unexpected images that AI creates
tasotaku
0
370
Other Decks in Programming
See All in Programming
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
170
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
380
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
280
そこに3びきプロダクトがいるじゃろう——生成AI時代における“価値が届かない理由”の構造
kosuket
0
140
自作OSでスライド発表する
uyuki234
1
3.9k
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
540
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.3k
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
500
関数型プログラミングのメリットって何だろう?
wanko_it
0
200
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
440
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
4
1.8k
人間の目はかわらない、だからJPEGは30年もつ
yuzneri
12
16k
Featured
See All Featured
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Practical Orchestrator
shlominoach
191
11k
30 Presentation Tips
portentint
PRO
1
350
Accessibility Awareness
sabderemane
1
160
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Leo the Paperboy
mayatellez
8
1.9k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Documentation Writing (for coders)
carmenintech
77
5.4k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
250
Transcript
Google Colaboratory で Stable Diffusionの実装 B2 tasotaku
もくじ ◼ Stable Diffusion とは ◼ Stable Diffusion の特徴 ◼
Diffusers ◼ Stable Diffusion の中身
Stable Diffusion とは ◼ Stable Diffusion とは、文章から画像を生成するAI ◼ Google Colaboratory
での実装方法はこちら ◼ できること ⚫ 文章から画像を生成 ⚫ 生成した画像を微調整する ⚫ 文章と画像から新たな画像を生成 ⚫ etc
Stable Diffusion の特徴 ◼ 解像度の高い画像を生成できる ◼ メモリや時間がかからない ⚫ ノートパソコンでも Google
Colaboratory で実行可能 ◼ 特定のジャンルに弱い ⚫ 学習に使ったデータセットに起因? ⚫ ファインチューニングすれば解決 ◼ 作成した画像はフリー画像
文章から画像を生成 a photograph of an astronaut riding a horse
画像と文章から画像を生成 Gold desk +
画像とマスク画像と文章から画像を生成 ◼ マスク画像を使うことで、部分的に調整が可能 robot
ファインチューニング ◼ 特定の画像で訓練することで、苦手な分野に対応する ファインチューニング前 ファインチューニング後
Diffusers ◼ Diffusers とは、段階的にノイズ除去するように訓練された機械学習システム ◼ Stable Diffusion はこれをベースに作られている 引用: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb
Stable Diffusion の中身 ◼ Latents ◼ A text-encoder ◼ A
U-Net ◼ Scheduler ◼ An autoencoder (VAE) 引用: https://huggingface.co/blog/stable_diffusion
Stable Diffusion の中身 ◼ Latents ◼ A text-encoder ◼ A
U-Net ◼ Scheduler ◼ An autoencoder (VAE) 引用: https://huggingface.co/blog/stable_diffusion
Latents ◼ seed値をもとにノイズ画像を作る ◼ その画像を U-Net が扱えるように、 画素行列(latents)に変換 ◼ 出力する画像は
512 × 512 なのに対して、 latents はより低次元である ◼ こうすることで、メモリと計算量を軽減している 引用: https://huggingface.co/blog/stable_diffusion
text-encoder ◼ 文章をU-Netが理解できるかたちに変換する ◼ 機械翻訳ではないので、文法はあまり見ない ⚫単語(キーワード)を複数与えるだけでも機能する 引用: https://huggingface.co/blog/stable_diffusion
U-Net と Scheduler ◼ U-Net を用いて、文章をもとにノイズ画像を ノイズの少ない画像にする ◼ Scheduler で二つの画像のノイズの差を
計算してフィードバック ◼ これを繰り返して画像(のlatents) を生成する ◼ U-Net は ResNet からなるエンコーダーと デコーダーをもつ ◼ Scheduler は複数種類があり、選ぶことができる 引用: https://huggingface.co/blog/stable_diffusion
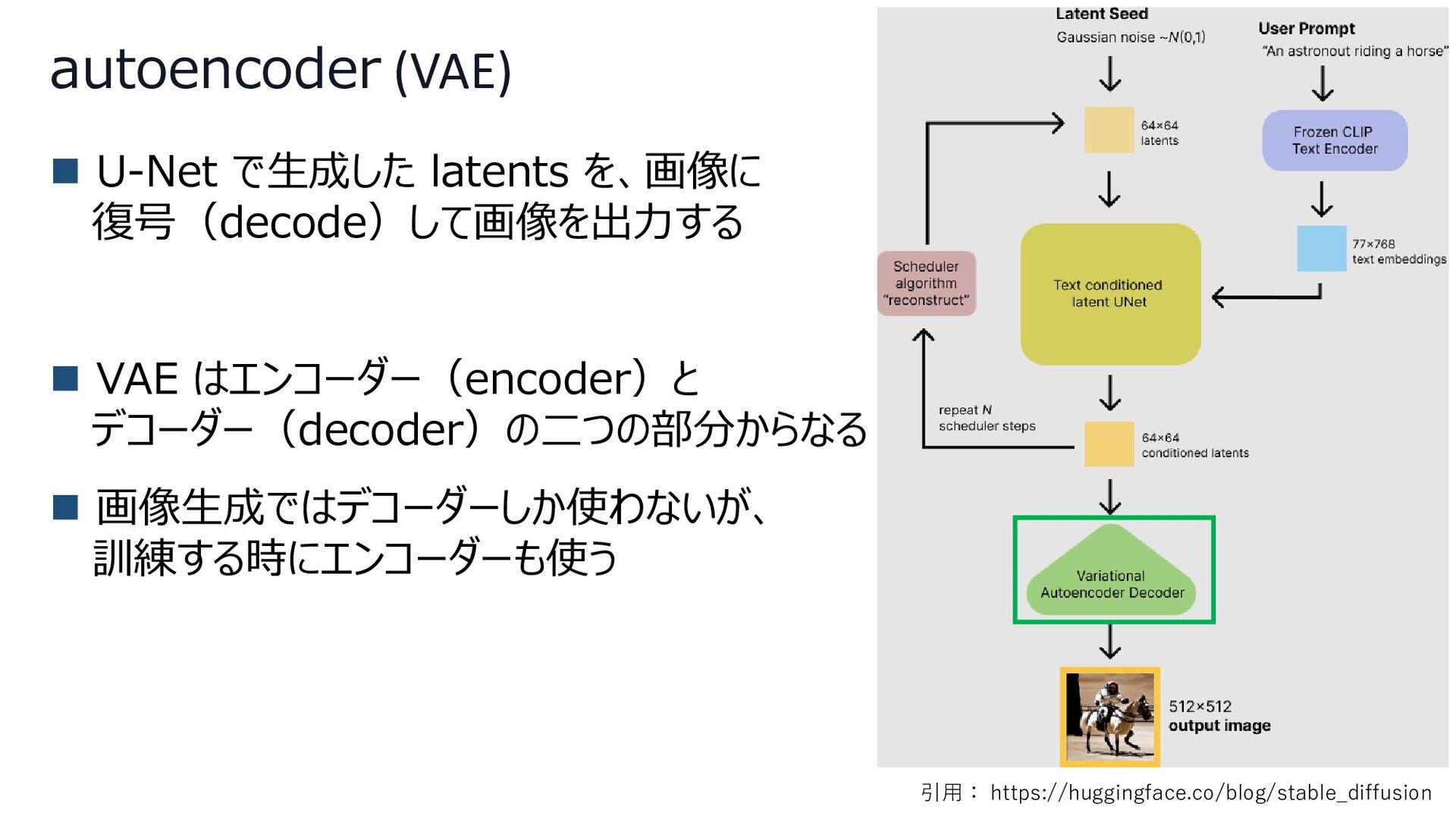
autoencoder (VAE) ◼ U-Net で生成した latents を、画像に 復号(decode)して画像を出力する ◼ VAE
はエンコーダー(encoder)と デコーダー(decoder)の二つの部分からなる ◼ 画像生成ではデコーダーしか使わないが、 訓練する時にエンコーダーも使う 引用: https://huggingface.co/blog/stable_diffusion
学習 ◼ 元の画像にノイズをかける ◼ 文章を加えてノイズを取り除く ◼ 出力と元の画像、文章から損失を計算する 文章 比較
最後に ◼ 扱いやすさを重視したお絵描きAI ◼ フリー画像の新たな選択肢 ◼ すでに Stable Diffusion を利用したアプリなどが登場している
◼ Diffusers は用途が多く、音声や動画バージョンも作成予定らしい
参考 ◼ https://github.com/huggingface/diffusers ◼ https://colab.research.google.com/github/huggingface/noteb ooks/blob/main/diffusers/stable_diffusion.ipynb
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}