Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DQNによるポーカーの強化学習/Reinforcement Learning in Poker...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
tasotaku
December 14, 2023
870
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DQNによるポーカーの強化学習/Reinforcement Learning in Poker with DQN
tasotaku
December 14, 2023
More Decks by tasotaku
See All by tasotaku
duel_masters_RAG
tasotaku
0
110
オセロCPU/Othello CPU
tasotaku
0
200
オセロAI / OthelloAI
tasotaku
0
230
私、ChatGPTがChatGPTを解説するよ! / ChatGPT explains ChatGPT
tasotaku
0
520
機械学習入門
tasotaku
0
500
AIが作る予想外な画像を考える / Consider the unexpected images that AI creates
tasotaku
0
370
Google Colaboratory でStable Diffusionの実装 / Implementation of Stable Diffusion at Google Colaboratory
tasotaku
0
470
Featured
See All Featured
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
Building Applications with DynamoDB
mza
96
7.1k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Are puppies a ranking factor?
jonoalderson
1
3.7k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
DQNによるポーカーの 強化学習 宮内翼
目次 ◼ DQNとは ⚫ Q学習 ⚫ Q関数とニューラルネットワーク(NN) ⚫ 経験再生 ⚫
ターゲットネットワーク ◼ テキサスホールデムの学習
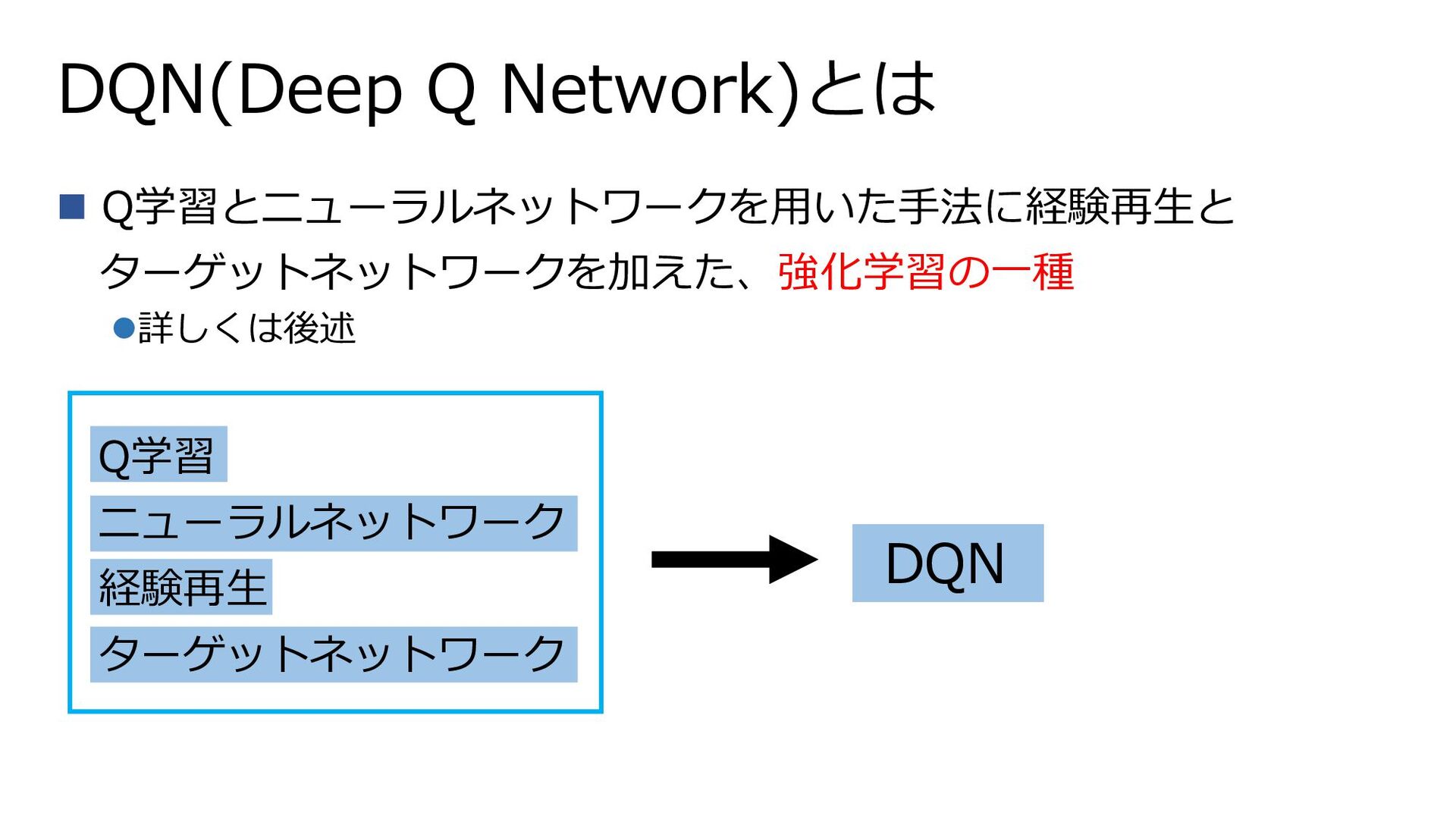
DQN(Deep Q Network)とは ◼ Q学習とニューラルネットワークを用いた手法に経験再生と ターゲットネットワークを加えた、強化学習の一種 ⚫詳しくは後述 Q学習 ニューラルネットワーク 経験再生
ターゲットネットワーク DQN
Q学習 ◼ 行動価値関数をQ関数という ◼ Q関数とは状態sと行動aの組み合わせから得られる収益 ⚫ q π (s, a)
= E[G t |S t = s, A t = a] ⚫ 最適なQ関数を知りたい ◼ Q学習はQ関数を更新する方法の一つ ◼ Q学習を使って最適なQ関数を求める
Q関数とニューラルネットワーク(NN) ◼ 例:チェスの駒の並び(状態数)は10の123乗 Q関数の候補は 状態数×行動数で膨大 ニューラルネットワークで近似 なので
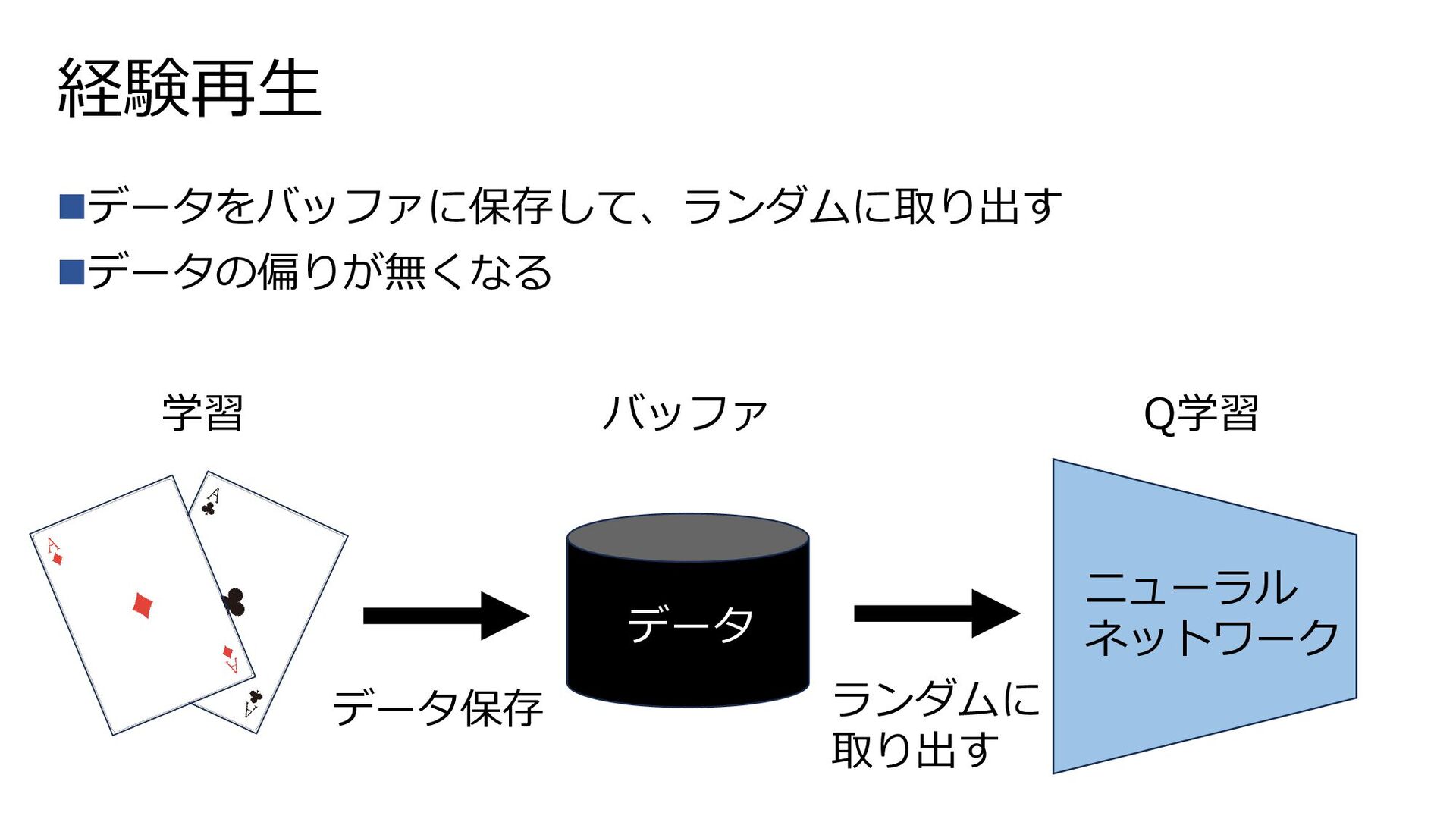
経験再生 データ ニューラル ネットワーク データ保存 Q学習 学習 ランダムに 取り出す ◼データをバッファに保存して、ランダムに取り出す
◼データの偏りが無くなる バッファ
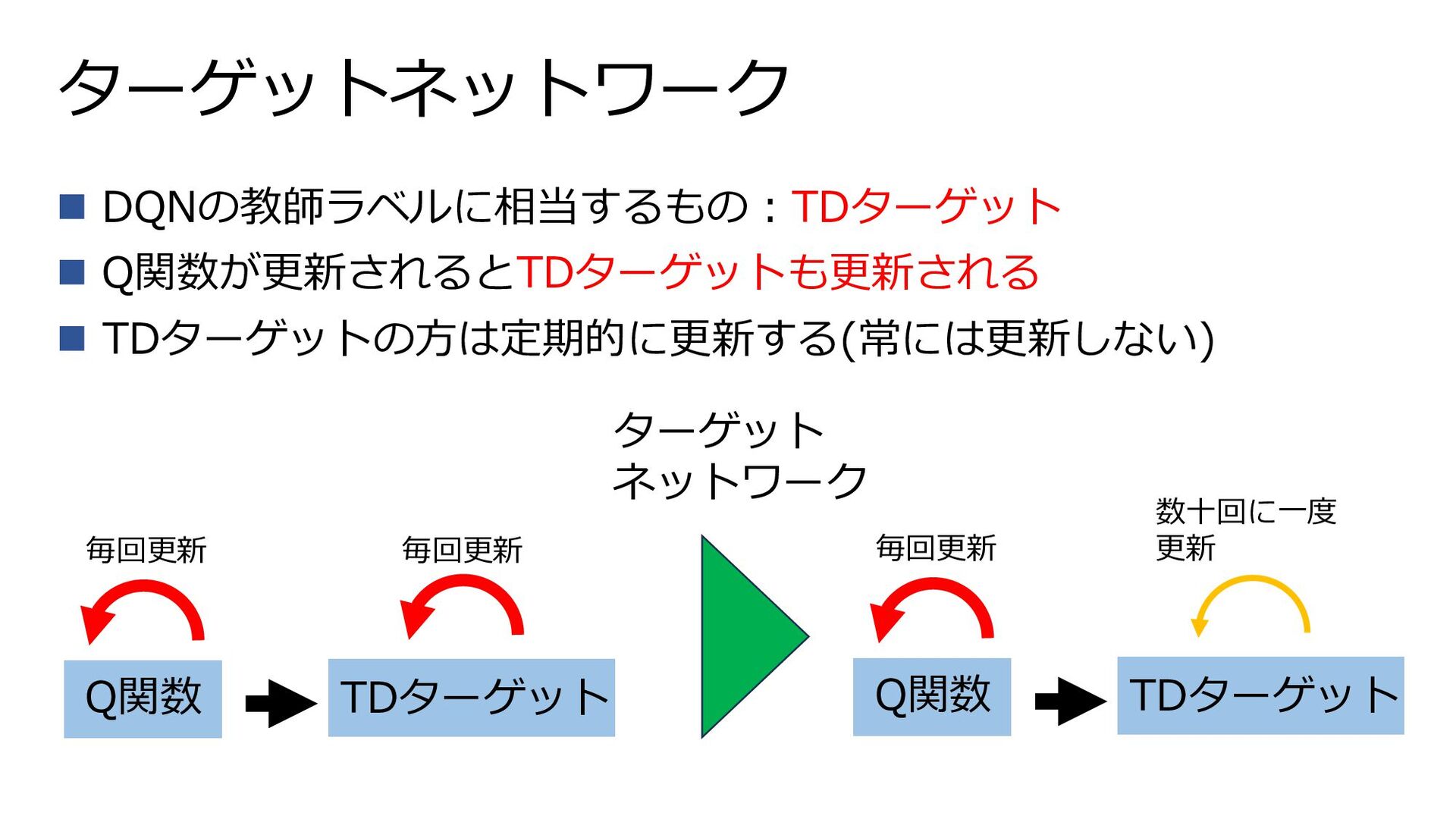
ターゲットネットワーク ◼ DQNの教師ラベルに相当するもの:TDターゲット ◼ Q関数が更新されるとTDターゲットも更新される ◼ TDターゲットの方は定期的に更新する(常には更新しない) Q関数 TDターゲット 毎回更新
毎回更新 ターゲット ネットワーク Q関数 TDターゲット 毎回更新 数十回に一度 更新
テキサスホールデムの学習 ◼ チェスや囲碁などのよく強化学習で扱われるゲームの分類 ⚫ 二人零和有限確定完全情報ゲーム ◼ テキサスホールデムの特徴 ⚫ 確定ではない(トランプのカードはランダム) ⚫
完全情報ではない(相手の手札は見えない)
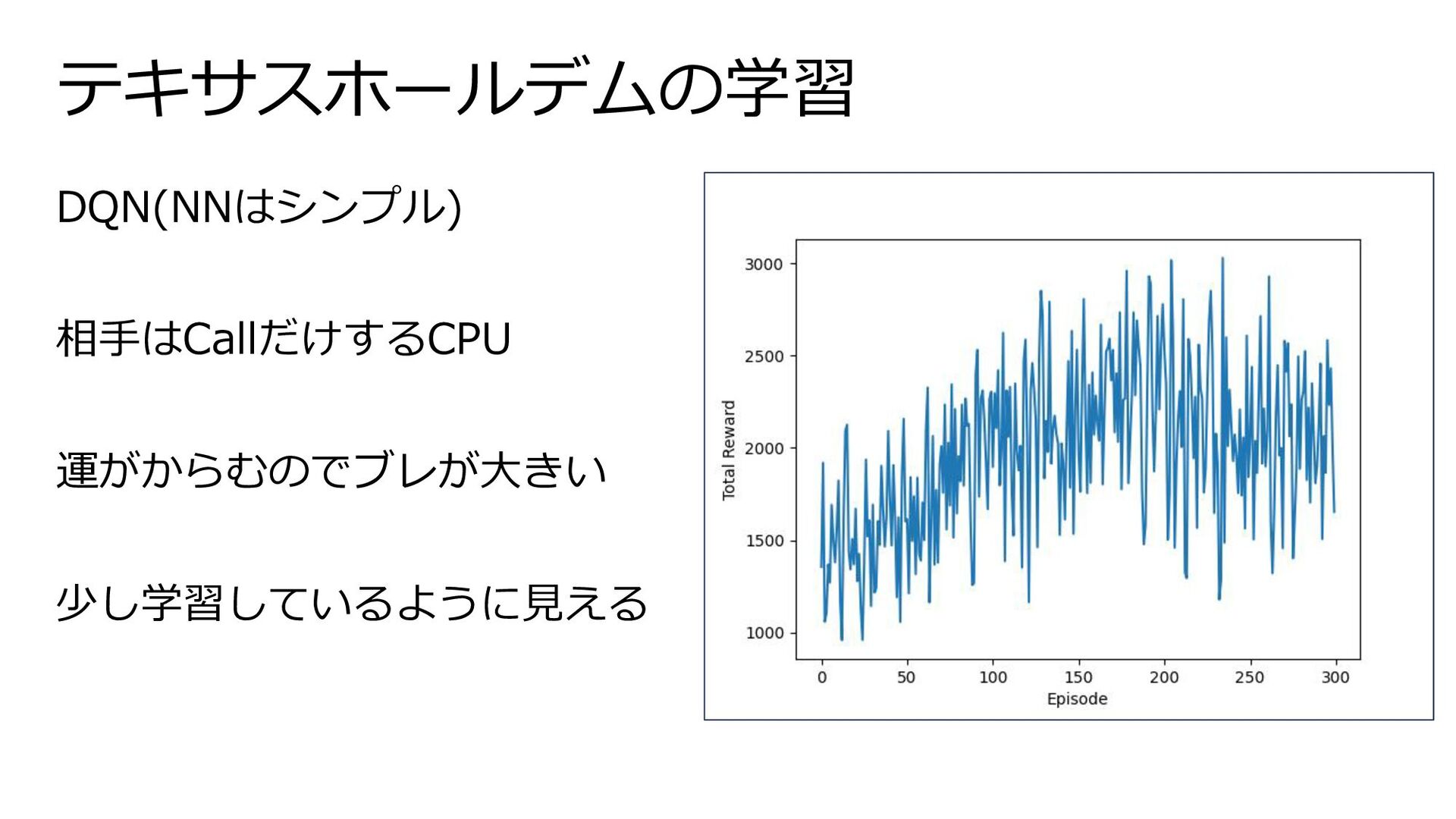
テキサスホールデムの学習 DQN(NNはシンプル) 相手はCallだけするCPU 運がからむのでブレが大きい 少し学習しているように見える
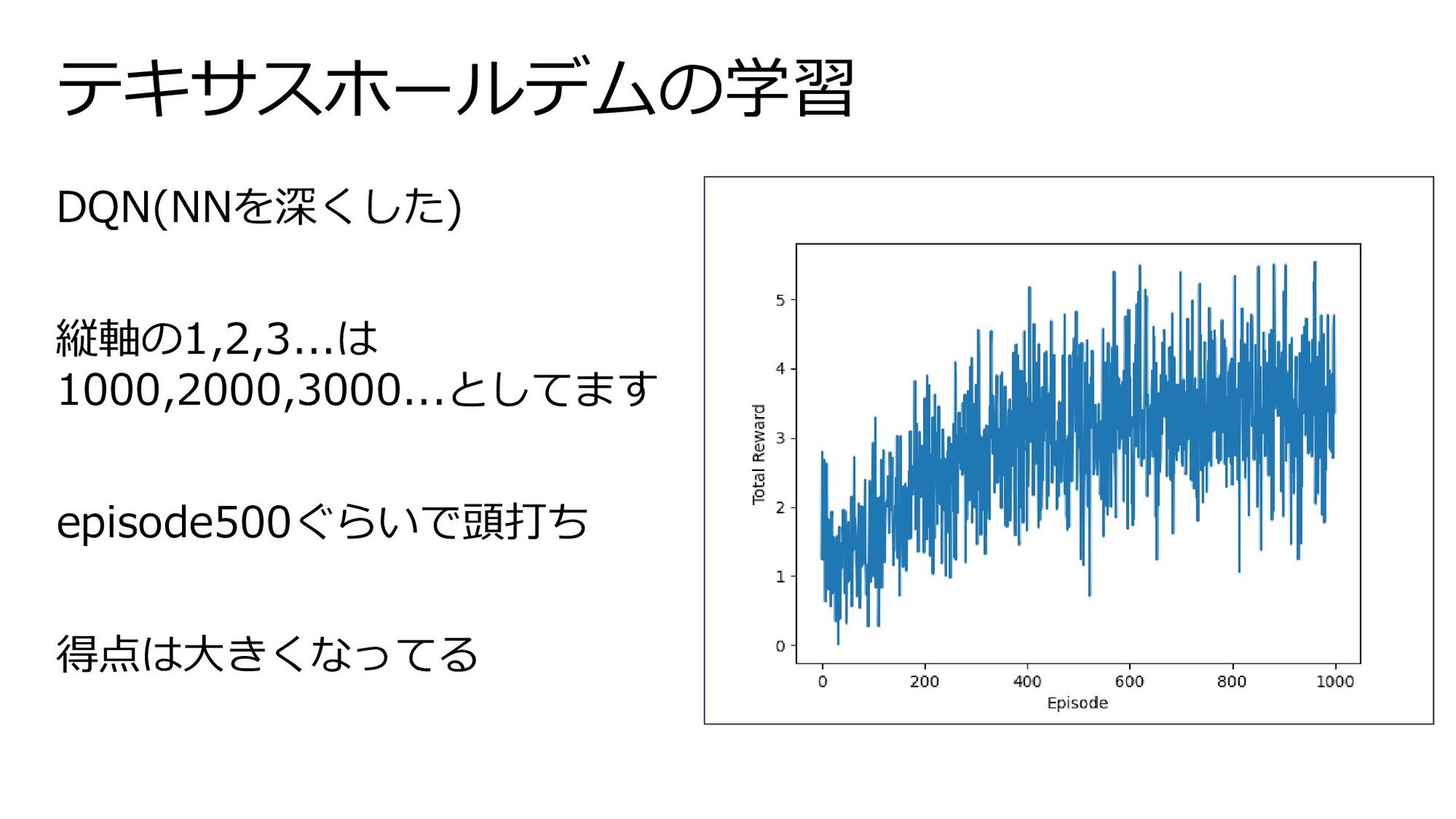
テキサスホールデムの学習 DQN(NNを深くした) 縦軸の1,2,3...は 1000,2000,3000...としてます episode500ぐらいで頭打ち 得点は大きくなってる
まとめ ◼ DQNは強化学習の一種 ◼ テキサスホールデムのような不確定かつ不完全なゲームでも学習は できる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}