Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Refactoring a Solr based api application
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Torsten Bøgh Köster
April 13, 2012
Programming
120
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Refactoring a Solr based api application
Held on Apache Lucene Eurocon 2011 in Barcelona
Torsten Bøgh Köster
April 13, 2012
More Decks by Torsten Bøgh Köster
See All by Torsten Bøgh Köster
LLMs im Griff: Observability, Tracing und Security
tboeghk
0
35
LLMs im Griff: Observability, Tracing und Security
tboeghk
0
49
Oder mache ich es lieber selbst? Wie sich Kosten und Geopolitik auf Cloud-Betrieb auswirken
tboeghk
0
73
Taking an abandoned Solr search from zero to GenAI hero
tboeghk
0
65
Oder mache ich es lieber selbst? Wie sich Kosten und Geopolitik auf Cloud-Betrieb auswirken
tboeghk
0
62
🔪 How we cut our AWS costs in half
tboeghk
0
410
Shared Nothing Logging Infrastructure
tboeghk
0
130
Beyond Cloud: A road trip into AWS and back to bare metal
tboeghk
1
120
Shared Nothing Logging Infrastructure
tboeghk
0
1.4k
Other Decks in Programming
See All in Programming
Foundation Models frameworkで画像分析
ryodeveloper
1
140
使いながら育てる Claude Code — 開発フローの1コマンド化 × 繰り返し指摘の自動仕組み化
shiki_kakaku
0
800
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
5.6k
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
620
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
180
複数の Claude Code が"放置"されてしまう問題をCLI ダッシュボードを自作して解決した話
sumihiro3
0
330
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
180
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
400
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
200
生成AI導入の「期待外れ」を乗り越える ー 開発フロー改革が目指す、真の組織変革
starfish719
0
2.5k
そこに3びきプロダクトがいるじゃろう——生成AI時代における“価値が届かない理由”の構造
kosuket
0
220
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
230
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
330
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Building Adaptive Systems
keathley
44
3.1k
The browser strikes back
jonoalderson
0
1.4k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
Become a Pro
speakerdeck
PRO
31
6k
Transcript
Architectural lessons learned from refactoring a Solr based API application.
Torsten Bøgh Köster (Shopping24) Apache Lucene Eurocon, 19.10.2011
Contents Shopping24 and it‘s API Technical scaling solutions Sharding Caching
Solr Cores „Elastic“ infrastructure business requirements as key factor
@tboeghk Software- and systems- architect 2 years experience with Solr
3 years experience with Lucene Team of 7 Java developers currently at Shopping24
shopping24 internet group
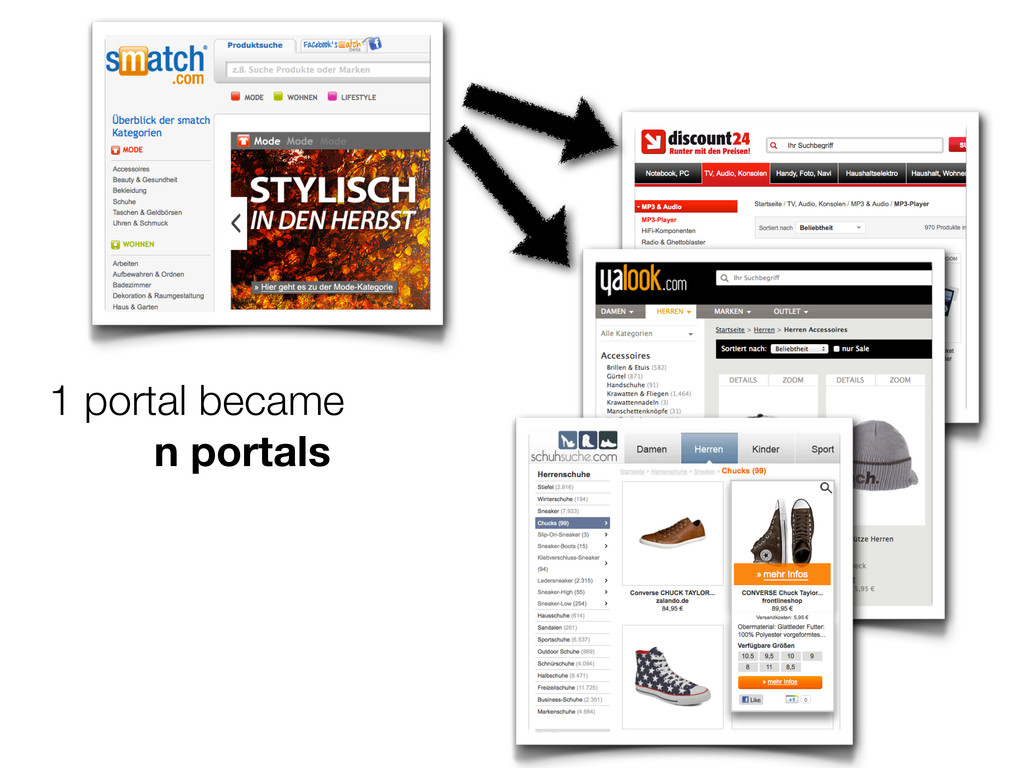
1 portal became n portals
30 partner shops became 700
500k to 7m documents
index fact time •16 Gig Data •Single-Core-Layout •Up to 17s
response time •Machine size limited •Stalled at solr version 1.4 •API designed for small tools
scaling goal: 15-50m documents
ask the nerds „Shard!“ That‘ll be fun! „Use spare compute
cores at Amazon?“ breathe load into the cloud „Reduce that index size“ „Get rid of those long running queries!“
data sharding ...
... is highly effective. 125ms 250ms 375ms 500ms 1 4
8 12 16 20 1shard 2shard 3shard 4shard 6shard 8shard concurrent requests
Sharding: size matters the bigger your index gets, the more
complex your queries are, the more concurrent requests, the more sharding you need
but wait ...
Why do we have such a big index?
7m documents vs. 2m active poducts
fashion product lifecycle meets SEO Bastografie / photocase.com
Separation of duties! Remove unsearchable data from your index.
Why do we have complex queries?
A Solr index designed for 1 portal
Grown into a multi-portal index
Let “sharding“ follow your data ...
... and build separate cores for every client.
Duplicate data as long as access is fast. andybahn /
photocase.com
Streamline your index provisioning process.
A thousand splendid cores at your fingertips.
Throwing hardware at problems. Automated.
evil traps: latency, $$
mirror your complete system – solve load balancer problems froodmat
/ photocase.com
I said faster!
use a cache layer like Varnish.
What about those complex queries? Why do we have them?
And how do we get rid of them?
Lost in encapsulation: Solr API exposed to world.
What‘s the key factor?
look at your business requirements
decrease complexity
Questions? Comments? Ideas? Twitter: @tboeghk Github: @tboeghk Email:
[email protected]
Web:
http://www.s24.com Images: sxc.hu (unless noted otherwise)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Comments? Ideas? Twitter: @tboeghk Github: @tboeghk Email: [email protected] Web:](https://files.speakerdeck.com/presentations/4f889cae3c60d30022002920/slide_36.jpg){kind=link}