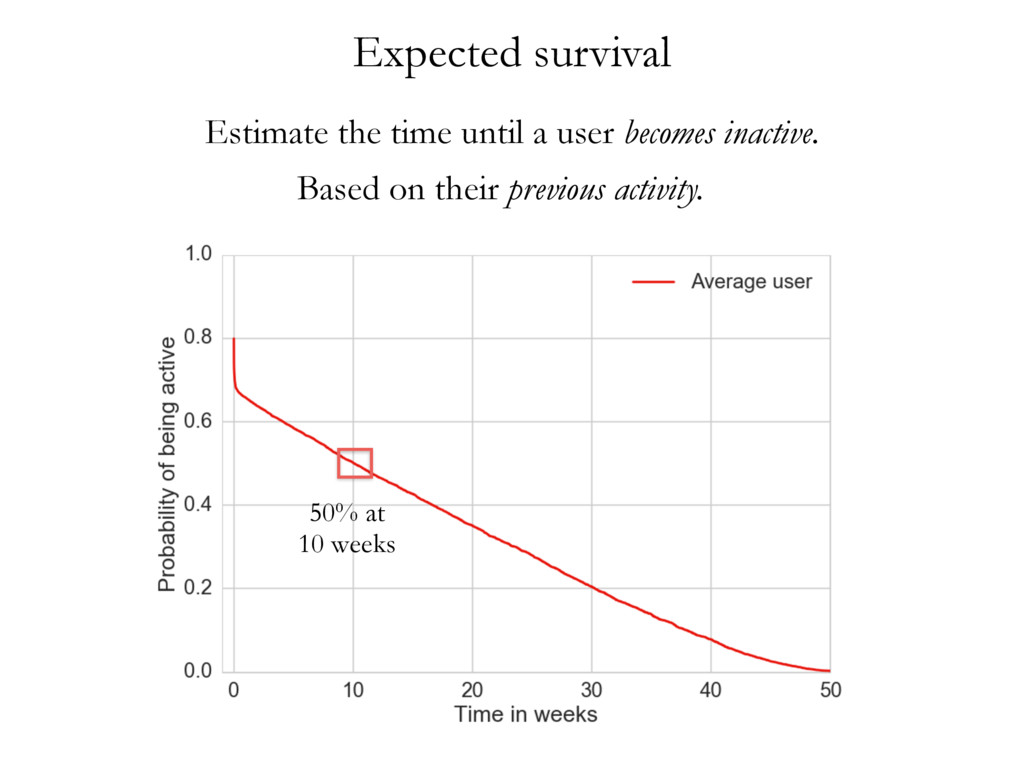
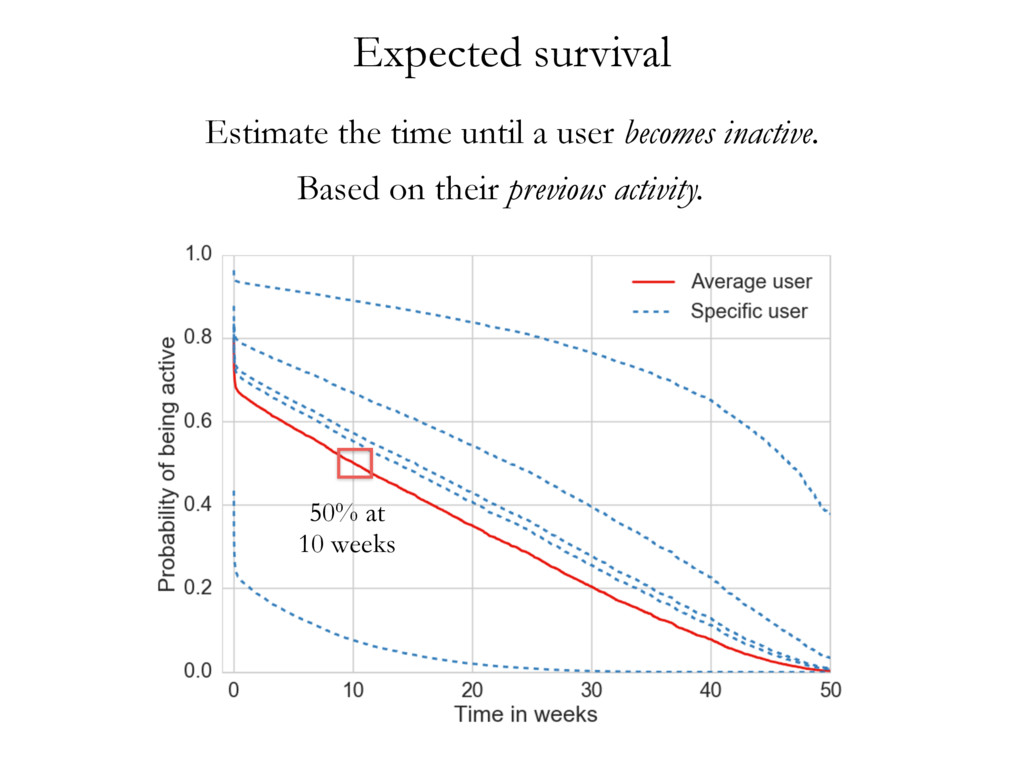
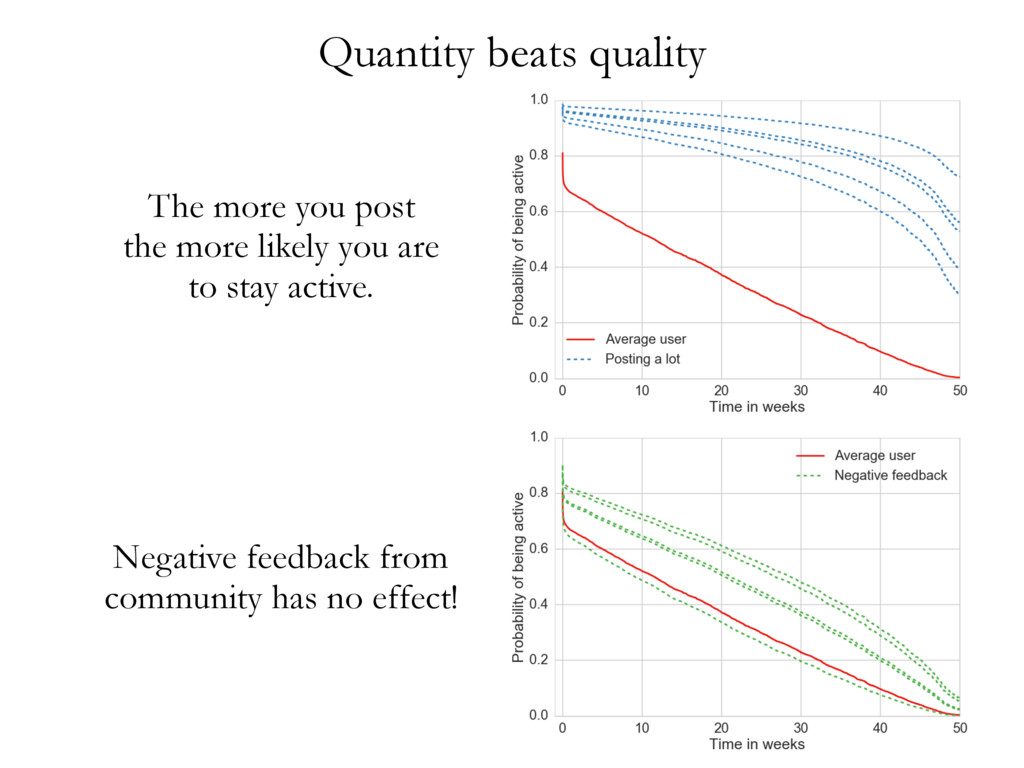
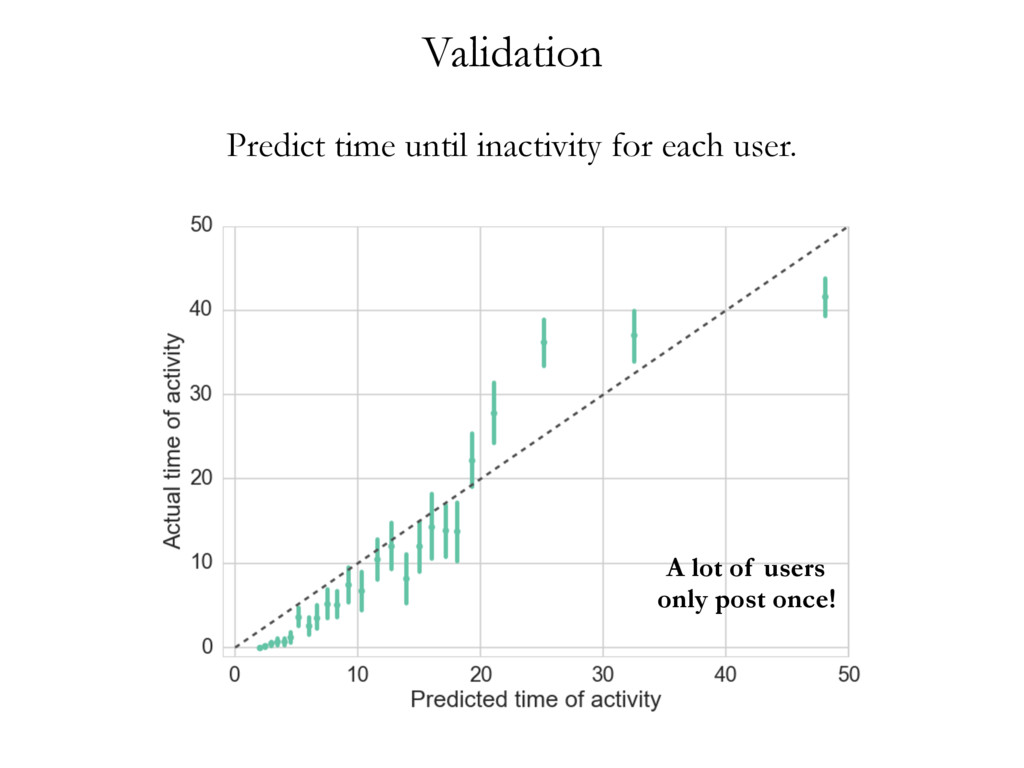
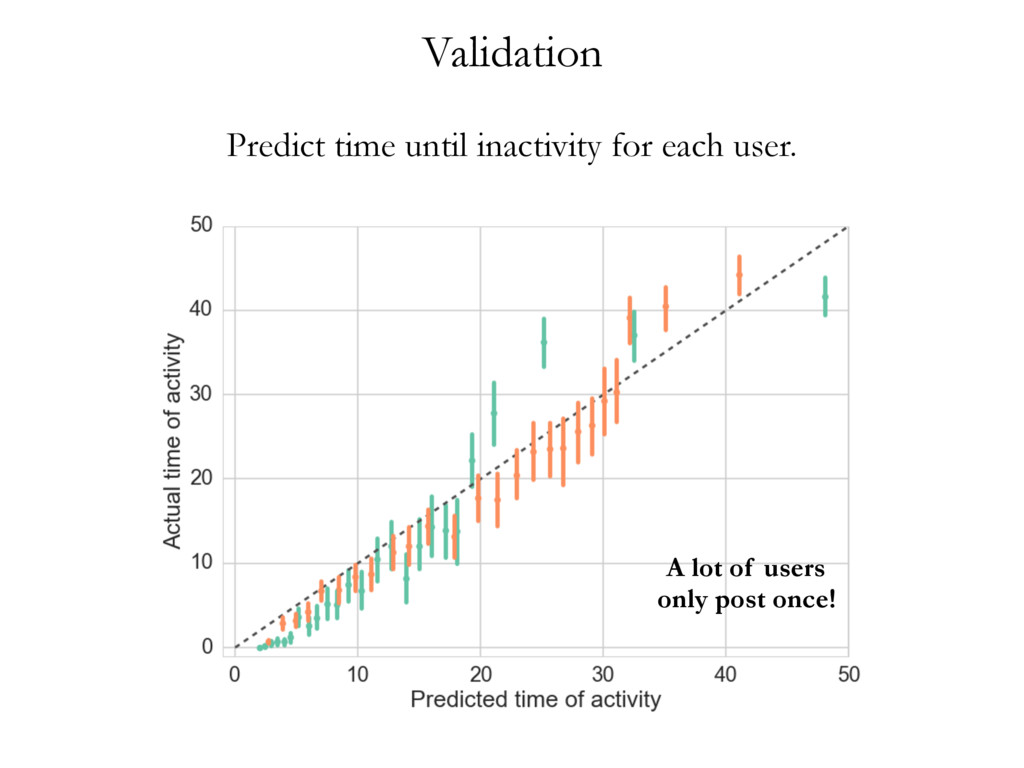
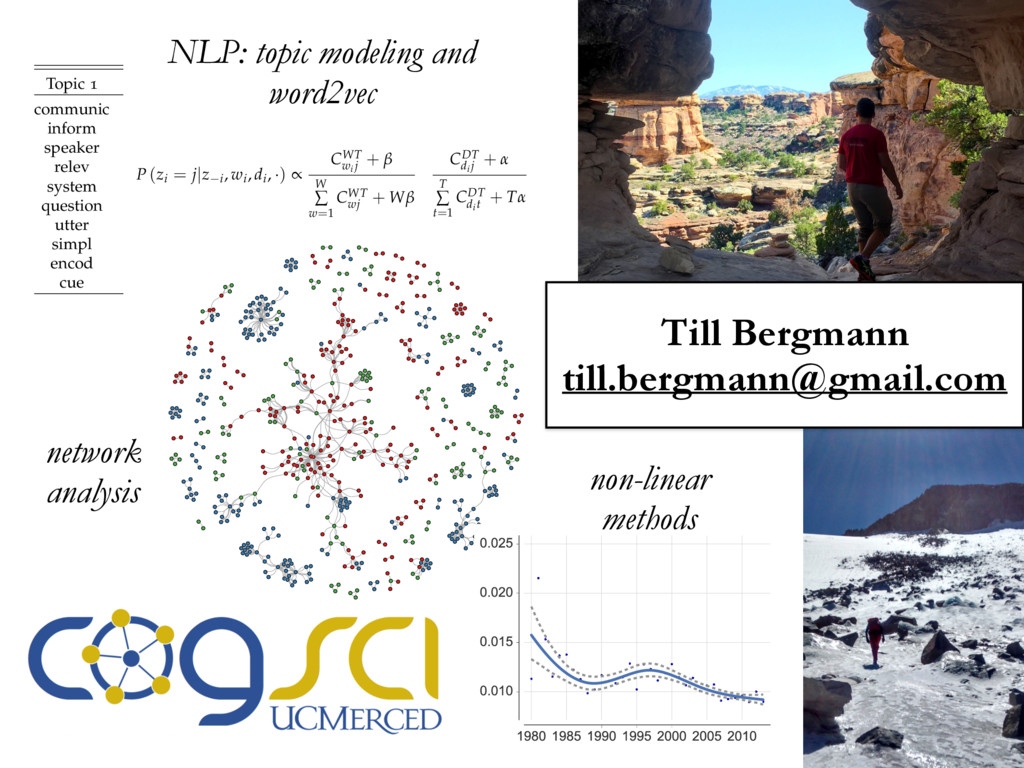
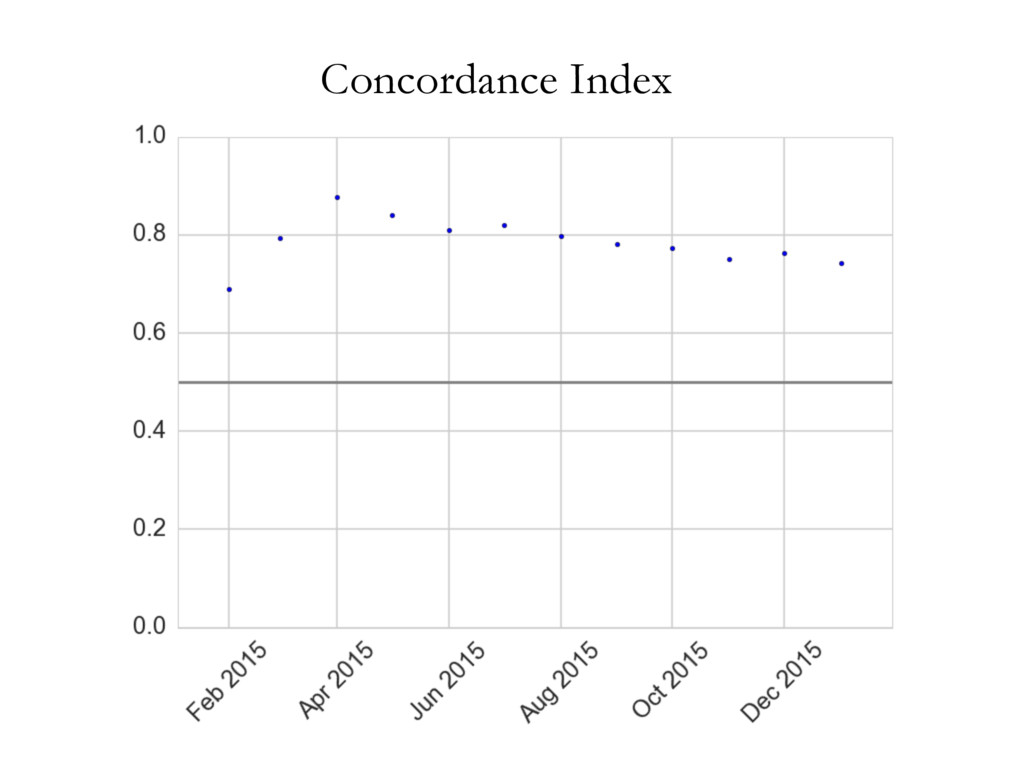
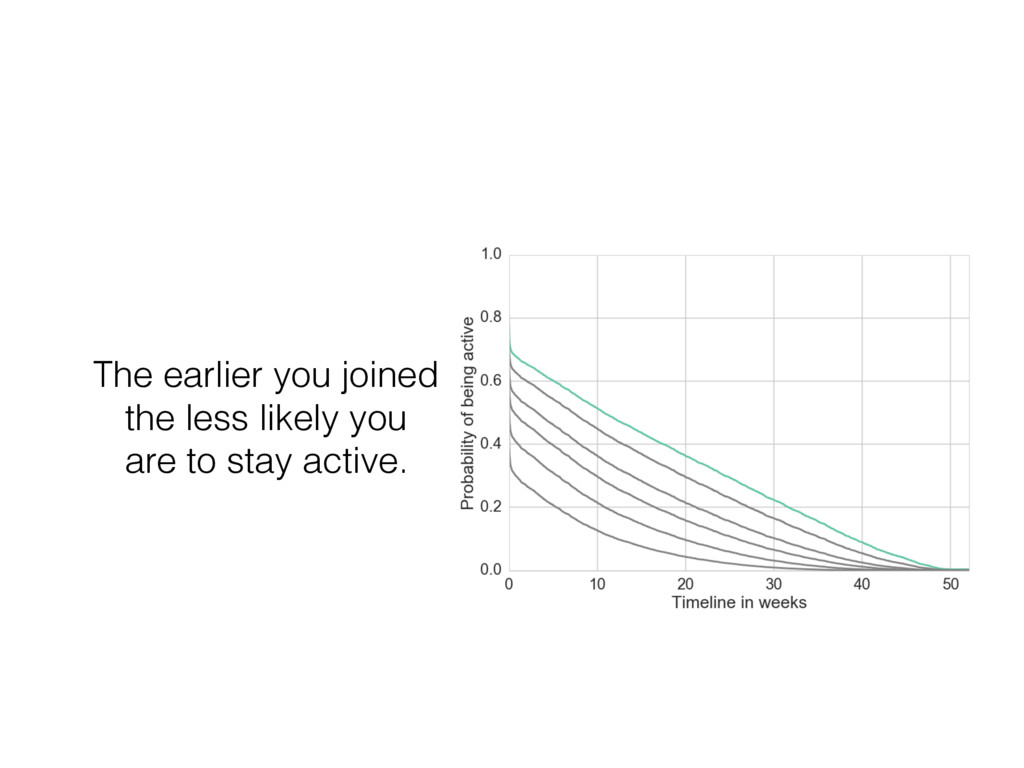
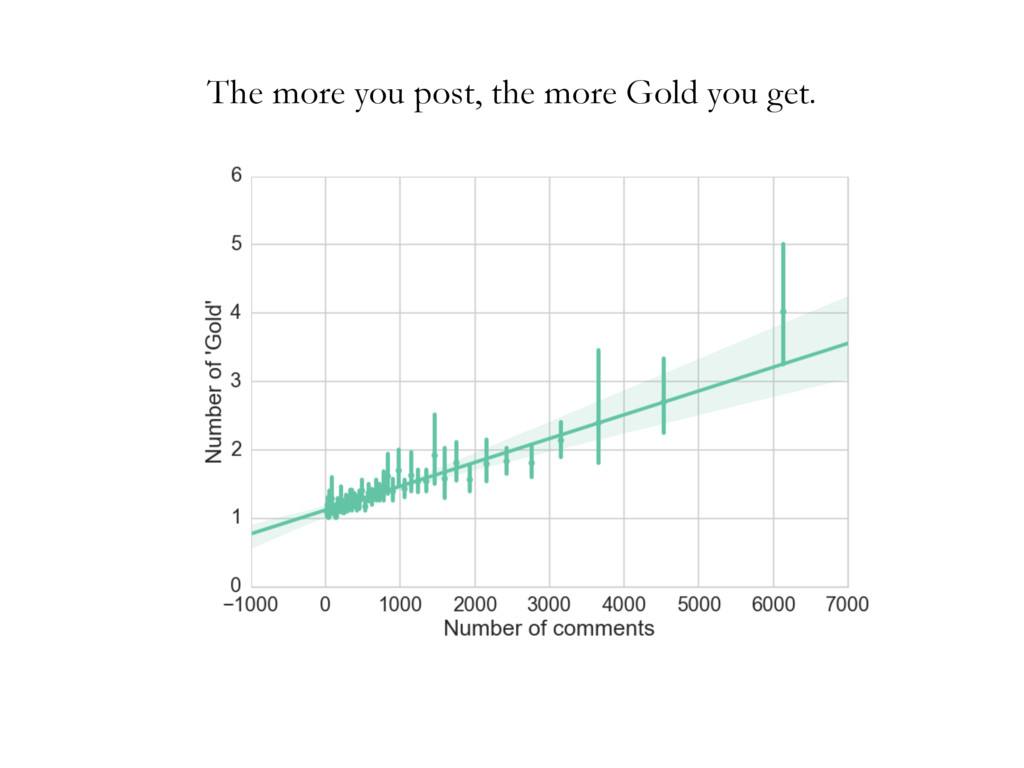
• • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • Cluster 1 Cluster 2 Cluster 3 document wdi is considered in turn, and its topic assignment zi computed conditioned on the topic assignment on all other word tokens (Steyvers & Griffiths, 2007). In other words, the probability that a specific topic j is assigned to the current word wdi depends on the probability that the same word has been assigned that topic in other positions in the corpus. Formally, this posterior can be written as: P (zi = j|z i , wi , di , ·) µ CWT wi j + b W Â w=1 CWT wj + W b CDT di j + a T Â t=1 CDT dit + T a (2.1) where · is all other known information, such as the Dirichlet priors and all other words w i and documents d i ; and µ means proportional to, as in y µ x ⌘ y = kx. CWT and CDT are matrices of counts with dimensions W ⇥ T (number of unique words in vocabulary ⇥ number of topics) and D ⇥ T (number of documents times number of topics) respectively: • CWT wj is the count of word w assigned to topic j, not including current instance i. • CDT dj is the count of of topic j assigned to some word token in document d not including current instance i. Conceptually, the first ratio is the probability of wi under topic j, and the second ratio the probability of topic j in document di . Once many tokens of word i have been assigned a topic j (across all documents), it will increase the probability that subsequent tokens of word i get the assignment topic j. Similarly, if topic j has been used multiple times within a document, it will increase the probability that any word within that document is assigned topic j. Estimates of the topic distribution q and term distribution f can then be calculated using the following formula (Griffiths & Steyvers, 2004; Steyvers & Griffiths, 2007): Table 3.1: Topics in cluster 1 and their associated terms. Topic 1 Topic 2 Topic 4 Topic 6 communic word mean experi inform order emerg particip speaker product languag categori relev event featur studi system interpret form result question semant composit set utter data space condit simpl present semant task encod studi combin test cue lexicon combinatori present Topic 10 Topic 11 Topic 18 Topic 19 signal learn gestur model game cultur languag agent system bias sign popul communic structur symbol network strategi generat system interact agent languag point simul interact linguist icon communiti high regular action dynam player learner speech comput refer transmiss form effect deling the authors of EvoLang topography of collaborations ting an authorship network from co-authored abstracts, we can nature of collaborations at EvoLang. Who collaborates with whom? f submission elicits large collaborations? Are there large components network
analysis non-linear
methods Till Bergmann
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}