Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggle: NeurIPS - Open Polymer Prediction 2025 ...
Search
calpis10000
November 04, 2025
Science
630
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kaggle: NeurIPS - Open Polymer Prediction 2025 コンペ 反省会
社内の技術共有会の発表資料です。
Kaggleの"NeurIPS - Open Polymer Prediction 2025"コンペについて、
コンペ概要や上位解法について紹介します。
calpis10000
November 04, 2025
More Decks by calpis10000
See All by calpis10000
atmaCup#10 振り返り会 3rd place solution
calpis10000
0
170
BUMP OF CHICKENの歌詞分析 -「君」と「僕」の軌跡を追いかけて-
calpis10000
0
1.5k
Other Decks in Science
See All in Science
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
390
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
960
機械学習 - SVM
trycycle
PRO
2
1.2k
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
270
(メタ)科学コミュニケーターからみたAI for Scienceの同床異夢
rmaruy
0
260
ssmonline #51 ヤマサキ春のサメ祭り 2026 / ssmjp Yamasaki Spring JAWS Festival 2026
naospon
1
100
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
560
Utiliser Bitcoin sans Internet
rlifchitz
0
300
20260220 OpenIDファウンデーション・ジャパン ご紹介 / 20260220 OpenID Foundation Japan Intro
oidfj
0
380
Bリーグのショットデータを活用した得点期待値モデルの構築 / Construction of expected points model using shot data of B.LEAGUE
konakalab
0
160
機械学習 - 決定木からはじめる機械学習
trycycle
PRO
0
1.6k
プロジェクト「Azayaka」のSARの数式とジオメトリ
syuchimu
0
380
Featured
See All Featured
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
Google's AI Overviews - The New Search
badams
0
1.1k
How to make the Groovebox
asonas
2
2.3k
WENDY [Excerpt]
tessaabrams
11
38k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Designing for Performance
lara
611
70k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
So, you think you're a good person
axbom
PRO
2
2.1k
Transcript
AI Community 2025.10.16 Kazutomo Dogome GOドライブ株式会社 Kaggle: NeurIPS - Open
Polymer Prediction 2025コンペ反省会 AI技術共有会
2 発表内容 2025年9月に終了したKaggleコンペ「NeurIPS - Open Polymer Prediction 2025」の 振り返りをします。(筆者チーム順位:269位/2241チーム) ▪
ポリマーの物性予測というテーマで、テーブル・自然言語・GNNなどの様々なアプロー チが可能な面白いコンペだったので、少しでも魅力をお伝えできればと思います。 ▪ ポリマー化学は非専門なので、誤りがありましたらご指摘をお願いします。 ▪ magic(何かに気づくことでスコアが伸びる)が猛威を振るったコンペでもあったの で、そこについても触れます。
堂込 一智(ドウゴメ カズトモ) GOドライブ株式会社 AI本部 AI技術開発2部 ▪ 業務内容 ▪ 次世代AIドラレコサービス『DRIVE CHART』の機能開発 ▪ Kaggle
▪ HN: calpis10000 ▪ Competitions Master ▪ 大学時代の専攻 ▪ 農学部(紙・印刷の研究を専攻) ▪ ポリマー化学の講義は受けたが、大昔なのであまり覚えていない😢 ▪ 今回のコンペは再学習しながら参加 3 自己紹介
4 目次 01|コンペ概要 02|基本的な戦い方 03|上位解法
5 01 コンペ概要
6 ▪ ポリマーの化学構造から5つの物性値を予測する。 ▪ 本来は実験やシミュレーションによって求めるが、労力が大きくて大変なので 機械学習を使って省力化したいというモチベーションらしい。 ▪ ポリマーとは? ▪ 小さな分子が鎖のように繋がって出来た大きな分子のこと。
▪ モノマー(単量体):ポリマーのベースとなる小さな分子 ▪ ポリマー(高分子):モノマーが繰り返し化学結合した大きな分子。 ▪ 例) コンペ概要 モノマー(エチレン) ポリマー(ポリエチレン) 結合 (※ nは繰り返し数)
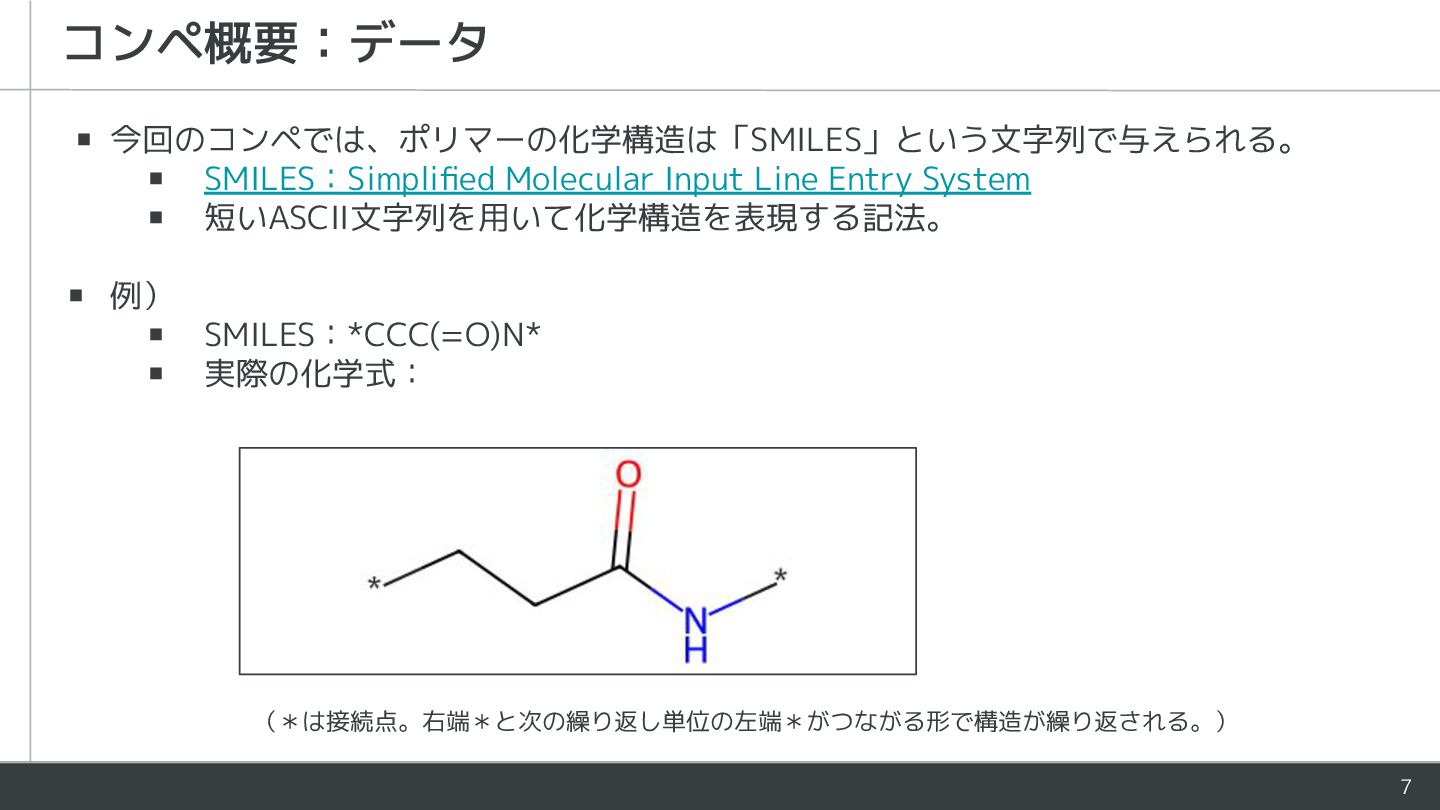
7 コンペ概要:データ ▪ 今回のコンペでは、ポリマーの化学構造は「SMILES」という文字列で与えられる。 ▪ SMILES:Simplified Molecular Input Line Entry
System ▪ 短いASCII文字列を用いて化学構造を表現する記法。 ▪ 例) ▪ SMILES:*CCC(=O)N* ▪ 実際の化学式: (*は接続点。右端*と次の繰り返し単位の左端*がつながる形で構造が繰り返される。)
8 コンペ概要:予測対象 ▪ ポリマーの化学構造から5つの物性値を予測する。 ▪ Tg(℃) ▪ ガラス転位温度。 ▪ ポリマーに熱を加えて柔らかくなる時の温度。
▪ FFV(比率) ▪ 自由体積分率。 ▪ 分子中の隙間の割合。(他の分子を通すか等に影響) ▪ Tc(W/m・K) ▪ 熱伝導率。熱をどのくらい伝えやすいか。 ▪ Density(g・cm^-3) ▪ 密度。単位体積あたりの重量。 ▪ Rg(Å) ▪ 回転半径。重心から各セグメント(モノマー/原子/etc.)の平均距離。 ▪ ポリマーが丸まっているか、まっすぐ伸びているか、の指標。
9 コンペ概要:評価指標 ▪ 加重平均絶対誤差(wMAE) ▪ 各物性値について絶対誤差を計算し、以下の観点で重みをかけた後に平均を求める。 ▪ スケールの統一 ▪ 数値範囲の大きい物性値が過度に重視されないよう補正。
▪ サンプル数 ▪ train/testのtargetには欠損があり、サンプル数が物性値により異なる。 ▪ 欠損の多い(サンプル数が少ない)物性値に重みがかかるよう補正。
10 02 基本的な戦い方
11 ▪ 与えられた情報は「trainデータのSMILESと各物性値の組み合わせ」のみ。 ▪ データを増やせるかどうか、SMILESから適切な特徴を抽出できるか、が鍵となる。 <やるべきこと> ▪ 外部データの収集 ▪ SMILESからの特徴抽出
▪ RDKitなどの化学計算ライブラリを活用 ▪ 自然言語として扱い、BERT系モデルによる特徴抽出を実施 基本的な戦い方
12 ▪ 有効な特徴を抽出できるモデルが作成できたとしても、その特徴を持つポリマーが学習 データに含まれていなければ意味がない。 ▪ 今回はデータ量が少ないコンペであった(物性値によっては数百行しかない)た め、データを増やすことが性能向上に直結した。 ▪ 今回のコンペでは、参加者によってnotebookやdiscussionで様々なデータセットが共 有され、これらを使用するかどうかで順位が大きく変化した。
▪ 例)筆者チームの最終subで外部データを使用した場合の想定順位 ▪ 外部データ不使用 :269位(メダル圏外、実際の最終結果) ▪ 外部データ使用 :37 ~ 22位(銀圏) ▪ 一方で、コンペ上の外部データ使用ルールに曖昧な点があったため、筆者チーム は使用しない選択をとった。 外部データの収集
13 ▪ SMILESから機械学習への入力を作成する手段としては、SMILESから化学構造を解析し て特徴を抽出する方法がスタンダード。 ▪ 化学構造解析用のライブラリとしては、RDKitが最もポピュラー。 ▪ 機械学習文脈では、以下のことが可能。 ▪ 記述子(特徴量)の作成
▪ Fingerprint(分子構造を表現する固定長ベクトル)の出力 ▪ 分子構造の可視化 SMILESからの特徴抽出: RDKit
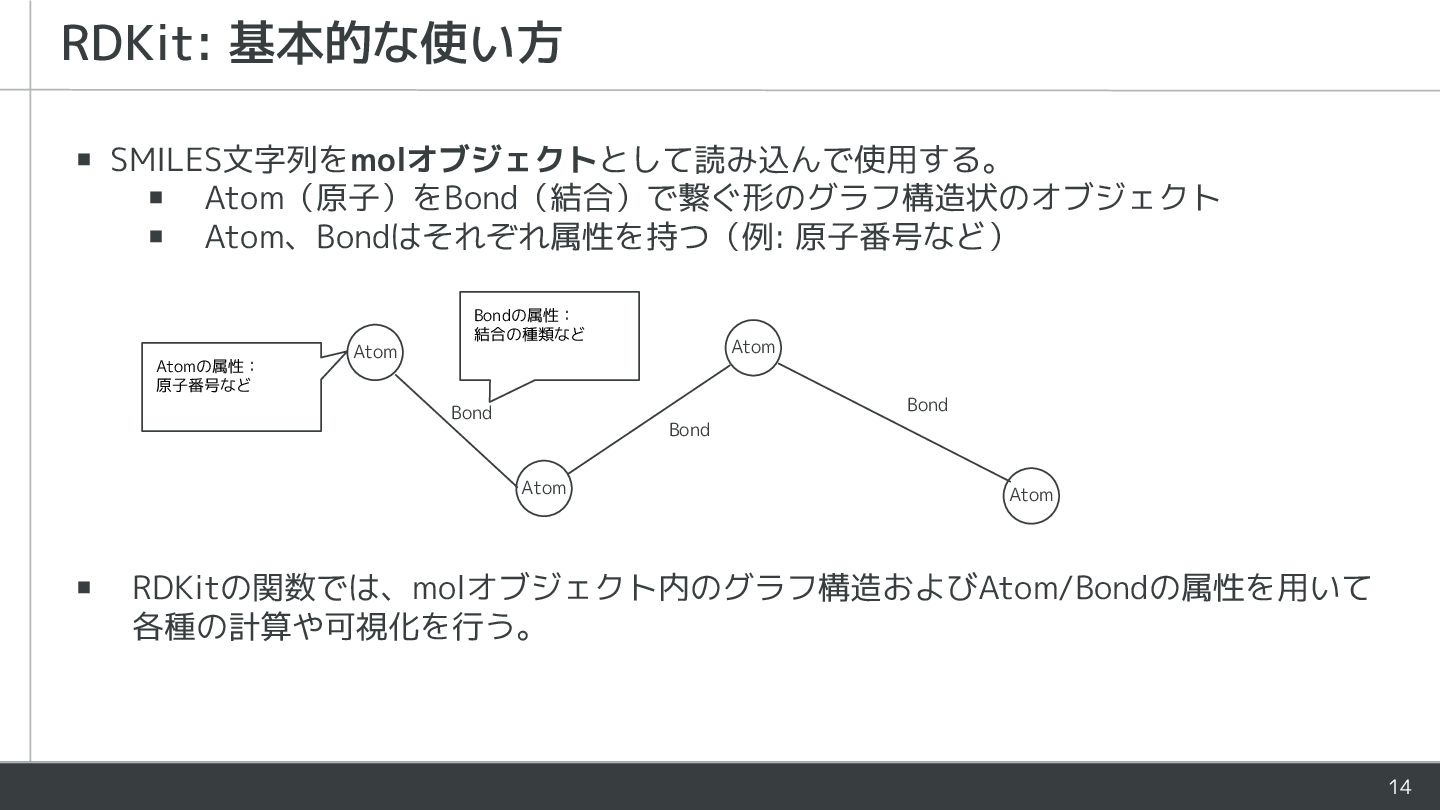
14 ▪ SMILES文字列をmolオブジェクトとして読み込んで使用する。 ▪ Atom(原子)をBond(結合)で繋ぐ形のグラフ構造状のオブジェクト ▪ Atom、Bondはそれぞれ属性を持つ(例: 原子番号など) ▪ RDKitの関数では、molオブジェクト内のグラフ構造およびAtom/Bondの属性を用いて
各種の計算や可視化を行う。 RDKit: 基本的な使い方 Atom Atom Atom Atom Bond Bond Bond Atomの属性: 原子番号など Bondの属性: 結合の種類など
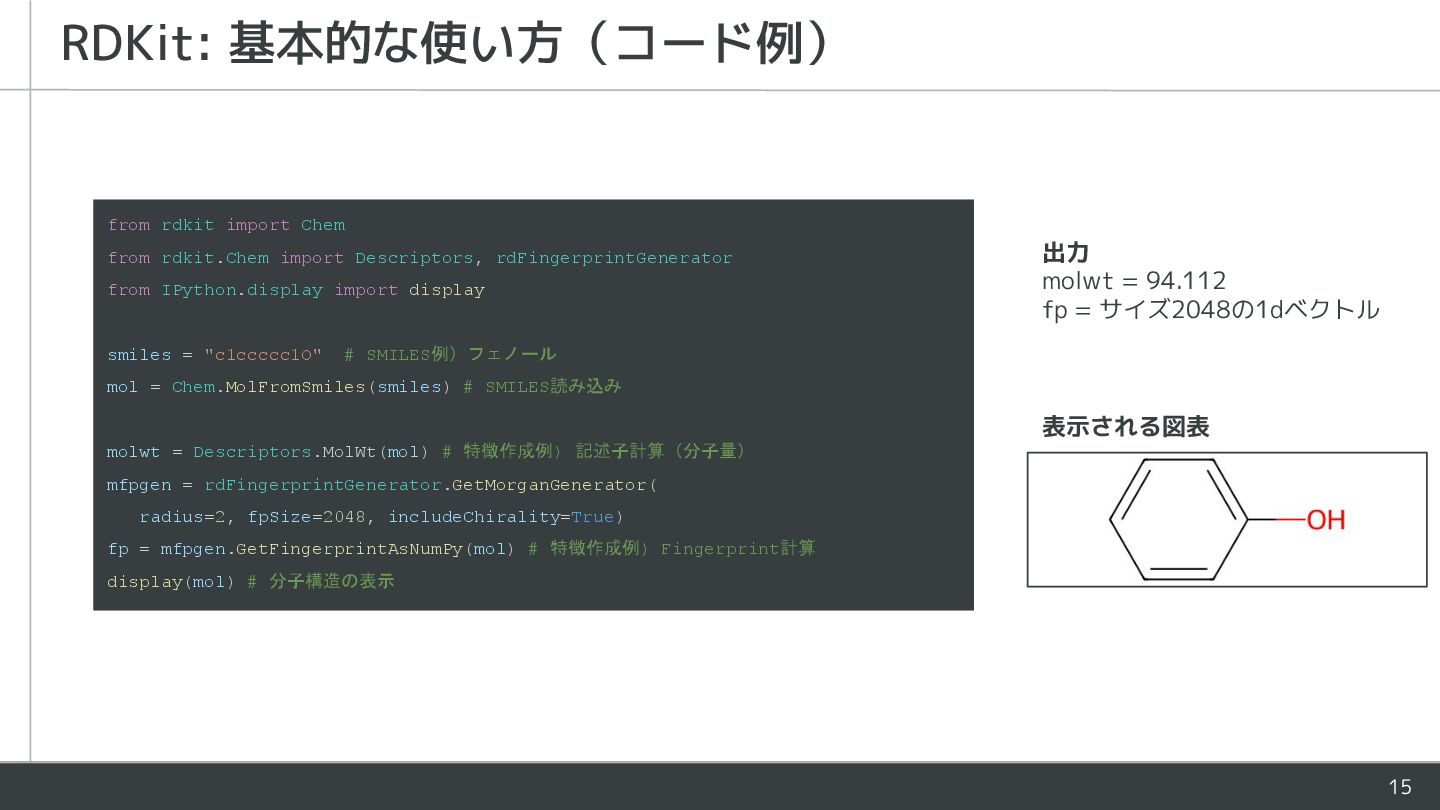
15 RDKit: 基本的な使い方(コード例) from rdkit import Chem from rdkit.Chem import
Descriptors, rdFingerprintGenerator from IPython.display import display smiles = "c1ccccc1O" # SMILES例)フェノール mol = Chem.MolFromSmiles(smiles) # SMILES読み込み molwt = Descriptors.MolWt(mol) # 特徴作成例) 記述子計算(分子量) mfpgen = rdFingerprintGenerator.GetMorganGenerator( radius=2, fpSize=2048, includeChirality=True) fp = mfpgen.GetFingerprintAsNumPy(mol) # 特徴作成例) Fingerprint計算 display(mol) # 分子構造の表示 表示される図表 出力 molwt = 94.112 fp = サイズ2048の1dベクトル
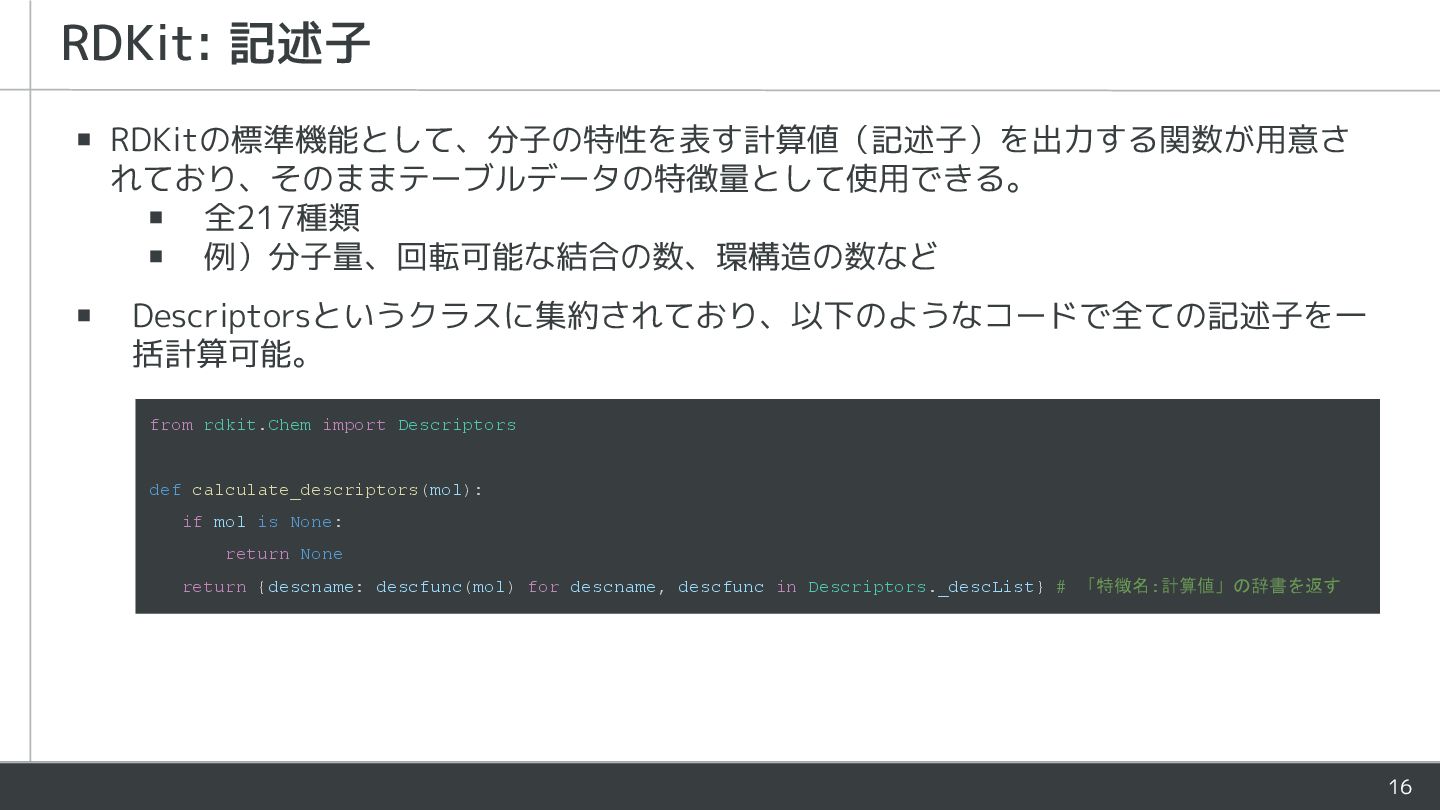
16 ▪ RDKitの標準機能として、分子の特性を表す計算値(記述子)を出力する関数が用意さ れており、そのままテーブルデータの特徴量として使用できる。 ▪ 全217種類 ▪ 例)分子量、回転可能な結合の数、環構造の数など ▪ Descriptorsというクラスに集約されており、以下のようなコードで全ての記述子を一
括計算可能。 RDKit: 記述子 from rdkit.Chem import Descriptors def calculate_descriptors(mol): if mol is None: return None return {descname: descfunc(mol) for descname, descfunc in Descriptors._descList} # 「特徴名:計算値」の辞書を返す
17 ▪ 分子構造の特徴を固定長のベクトルで表現したもの(Fingerprint)を出力可能。 ▪ ベクトル計算方法は複数用意されているが、MorganFingerprintが代表的。 ▪ それぞれの原子について周辺状態(原子番号、結合の状態など)を固定長のビッ トベクトルへ変換し、その結果を集約(ビット or カウント)する。
▪ 特徴量としてそのまま使用できる他、検索や類似度計算にも使用可能。 RDKit: Fingerprint ※引用元: ケモインフォマティクス理論(化学記述子編)
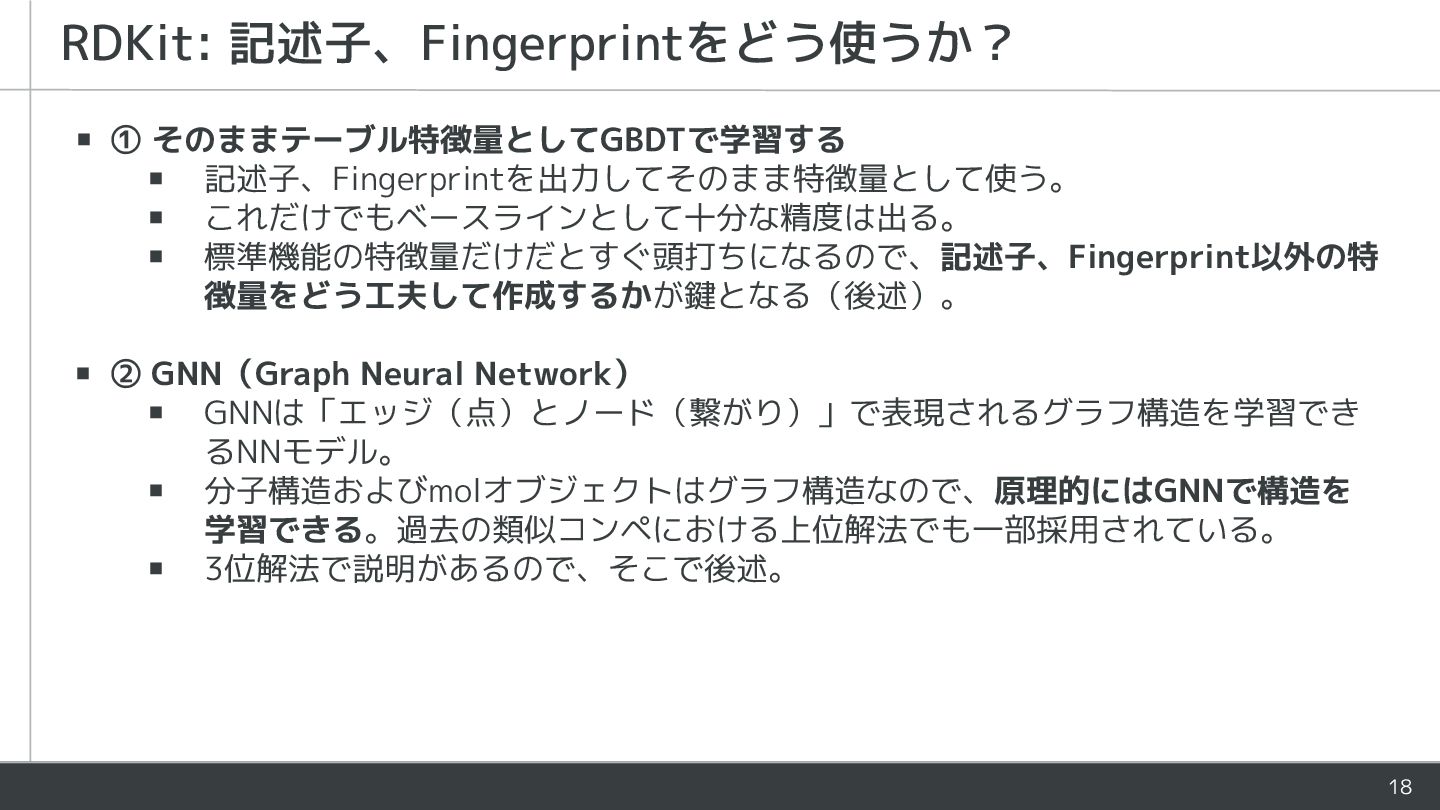
18 ▪ ① そのままテーブル特徴量としてGBDTで学習する ▪ 記述子、Fingerprintを出力してそのまま特徴量として使う。 ▪ これだけでもベースラインとして十分な精度は出る。 ▪ 標準機能の特徴量だけだとすぐ頭打ちになるので、記述子、Fingerprint以外の特
徴量をどう工夫して作成するかが鍵となる(後述)。 ▪ ② GNN(Graph Neural Network) ▪ GNNは「エッジ(点)とノード(繋がり)」で表現されるグラフ構造を学習でき るNNモデル。 ▪ 分子構造およびmolオブジェクトはグラフ構造なので、原理的にはGNNで構造を 学習できる。過去の類似コンペにおける上位解法でも一部採用されている。 ▪ 3位解法で説明があるので、そこで後述。 RDKit: 記述子、Fingerprintをどう使うか?
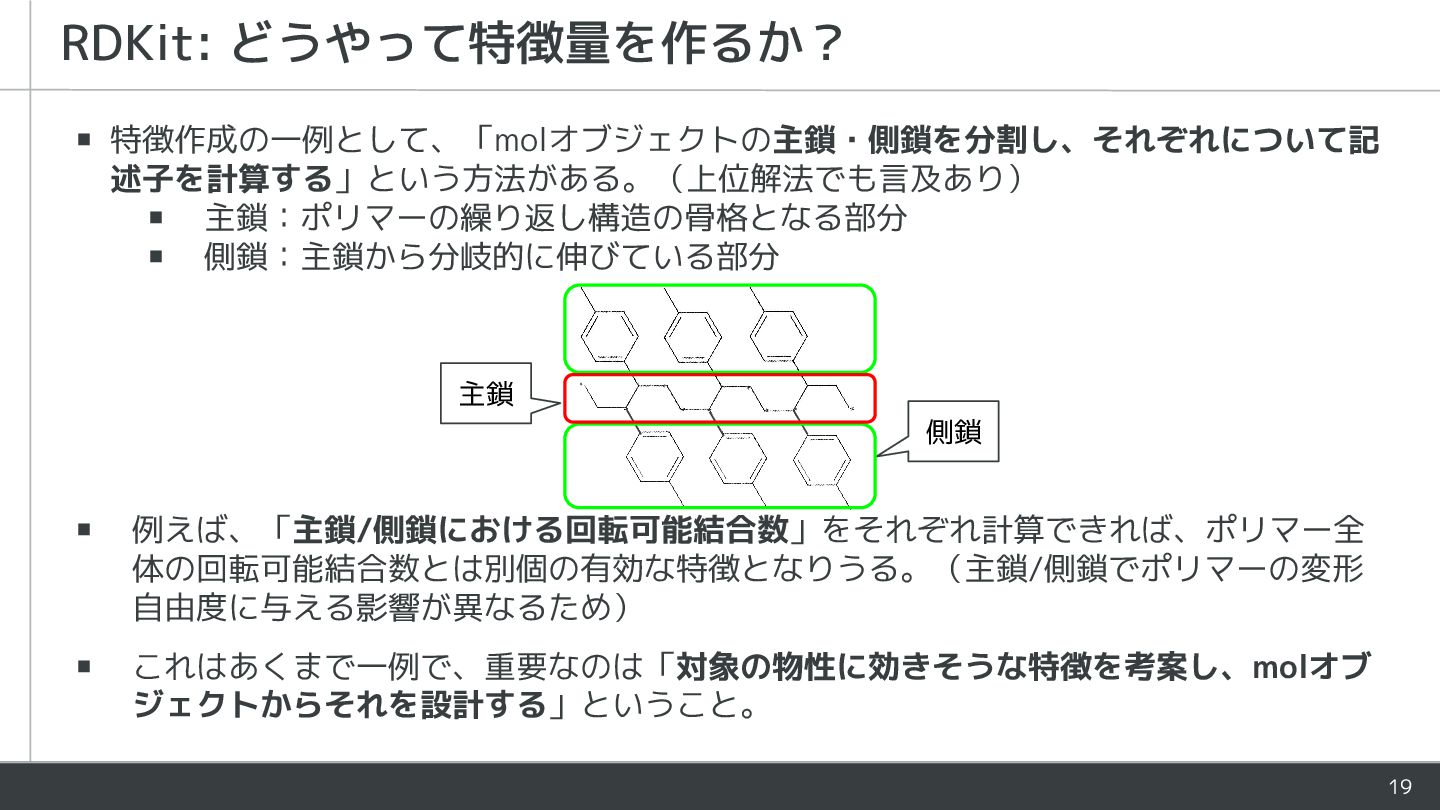
19 RDKit: どうやって特徴量を作るか? 側鎖 主鎖 ▪ 特徴作成の一例として、「molオブジェクトの主鎖・側鎖を分割し、それぞれについて記 述子を計算する」という方法がある。(上位解法でも言及あり) ▪ 主鎖:ポリマーの繰り返し構造の骨格となる部分
▪ 側鎖:主鎖から分岐的に伸びている部分 ▪ 例えば、「主鎖/側鎖における回転可能結合数」をそれぞれ計算できれば、ポリマー全 体の回転可能結合数とは別個の有効な特徴となりうる。(主鎖/側鎖でポリマーの変形 自由度に与える影響が異なるため) ▪ これはあくまで一例で、重要なのは「対象の物性に効きそうな特徴を考案し、molオブ ジェクトからそれを設計する」ということ。
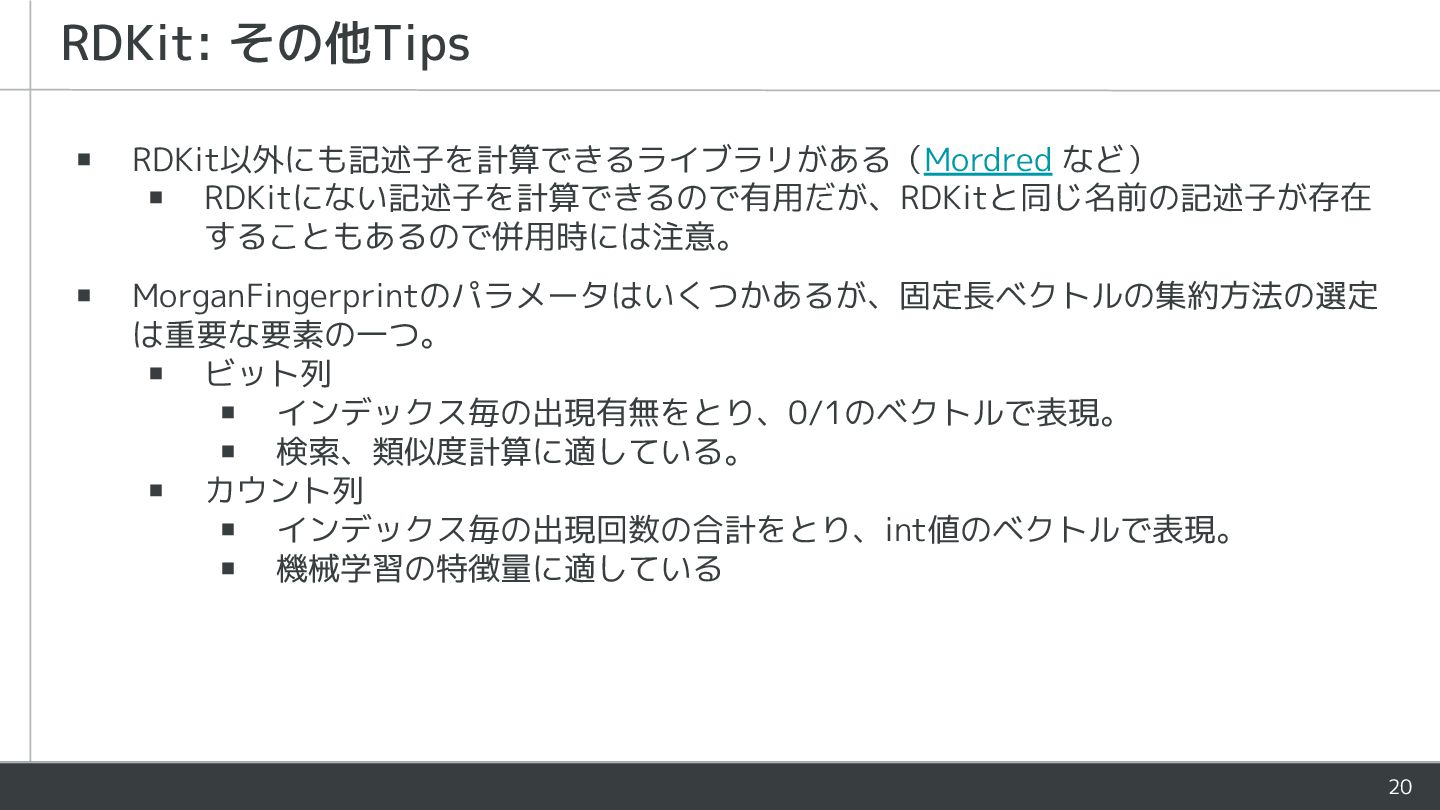
20 ▪ RDKit以外にも記述子を計算できるライブラリがある(Mordred など) ▪ RDKitにない記述子を計算できるので有用だが、RDKitと同じ名前の記述子が存在 することもあるので併用時には注意。 ▪ MorganFingerprintのパラメータはいくつかあるが、固定長ベクトルの集約方法の選定 は重要な要素の一つ。
▪ ビット列 ▪ インデックス毎の出現有無をとり、0/1のベクトルで表現。 ▪ 検索、類似度計算に適している。 ▪ カウント列 ▪ インデックス毎の出現回数の合計をとり、int値のベクトルで表現。 ▪ 機械学習の特徴量に適している RDKit: その他Tips
21 ▪ SMILESは文字列情報なので、自然言語処理のアプローチがそのまま適用可能。 ▪ 大量のSMILESを学習したBERT系モデル(ChemBERTa)があるので、まずはこちらを finetuningして使うのが良い。 ▪ SMILESは同じ分子に対して複数のパターンを取りうることから、自然言語処理アプロー チにおいてはSMILES文字列のAugmentationが有効。 ▪
RDKitでmolオブジェクトからSMILESを生成する関数があり、オプションでラン ダム化が可能。 ▪ 1位解法において、化学特化モデルではなくModernBERTも有効であることが説明され た。(後述) SMILESからの特徴抽出: 自然言語処理アプローチ
22 03 上位解法
23 上位解法の全体像 ▪ 「基本的な戦い方」に記載したのと近いものが多く、そこに独自の工夫を加えていた。 ▪ テーブルモデルの特徴量を工夫する ▪ BERTモデルのbackboneを変える ▪ GNNをembeddingsとして使う
▪ Uni-Mol というポリマーの3D構造特化のモデルも使われていた。 ▪ magicがあった。 ▪ public/private LB の Tg(ガラス転位温度)にドメインシフトがあった。 ▪ ドメインシフトを考慮してTg予測値に定数を加えるとスコアが大幅に改善した。 ▪ 1位・2位はmagicを使用しており、特に2位はmagicが解法の核であった。
24 1位解法 ▪ 概要: ▪ 独自要素: ▪ 外部データセット(PI1M)を用いたPseudoLabeling ▪ LB
Probingによるmagicの発見 ▪ モデル: ▪ BERT系: ▪ 化学特化ではなく汎用モデルを採用(ModernBERT、CodeBERT) ▪ テーブル: ▪ 特徴量はRDKit記述子、Fingerprint、主鎖・側鎖特徴、化学特化BERT (polyBERT)の埋め込みなど。 ▪ モデルはAutoGluonを採用。 ▪ 3D: ▪ Uni-Molを採用。
25 1位解法: PI1Mを用いたPseudo Labeling ▪ PI1M: ▪ 既存のポリマーデータセットから生成モデルを用いて自動生成したSMILESデータ セット(約100万ポリマー規模) ▪
Pl1Mから5万件のポリマーを抽出し、trainで学習済みのモデルを用いてPseudo Labelingを実施。 ▪ マルチタスク学習でfinetuningを実施。 ▪ 結果として、各モデルで「約0.004 LB、約0.01 CV」のスコア向上。 ▪ backboneモデルを選ばず同等の結果が出たことで順位向上へ貢献。
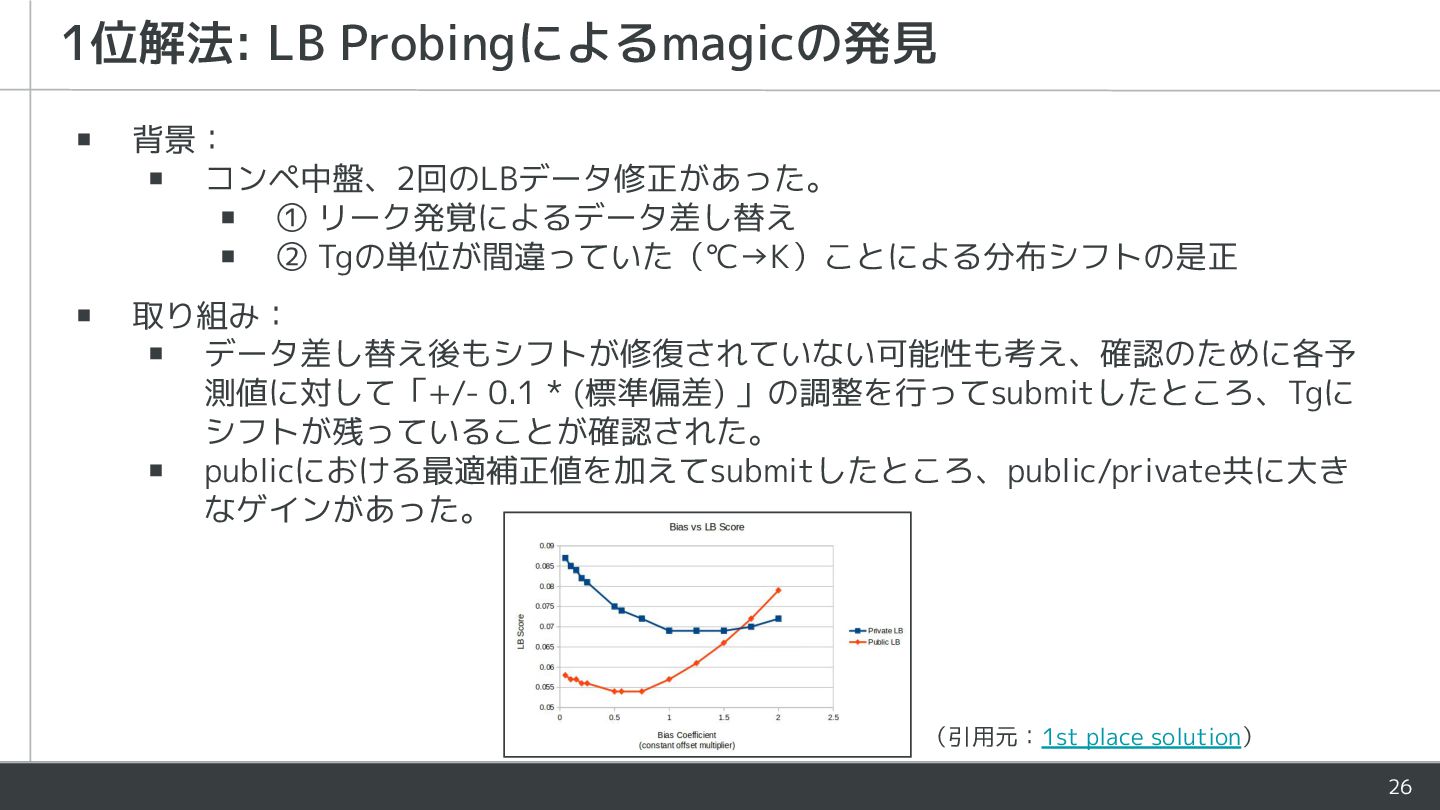
26 1位解法: LB Probingによるmagicの発見 ▪ 背景: ▪ コンペ中盤、2回のLBデータ修正があった。 ▪ ①
リーク発覚によるデータ差し替え ▪ ② Tgの単位が間違っていた(℃→K)ことによる分布シフトの是正 ▪ 取り組み: ▪ データ差し替え後もシフトが修復されていない可能性も考え、確認のために各予 測値に対して「+/- 0.1 * (標準偏差) 」の調整を行ってsubmitしたところ、Tgに シフトが残っていることが確認された。 ▪ publicにおける最適補正値を加えてsubmitしたところ、public/private共に大き なゲインがあった。 (引用元:1st place solution)
27 1位解法: BERTのbackbone選定 ▪ 化学特化モデルより汎用モデルが優れていることがある ▪ ChemBERTa(化学特化) : 0.0634 ▪
polyBERT(化学特化) : 0.592 ▪ ModernBERT-base(汎用) :0.0584 ▪ 自然言語ではなくコードによるトレーニングが効いている可能性がある ▪ 同じ汎用モデルでも、DeBERTa系は精度が悪かった(ChemBERTaより悪い) ▪ 一方、コードに特化したCodeBERTはModernBERTと同等の優れたスコア。 ▪ ModernBERTの事前トレーニングデータセットにもコードが一定量含まれてお り、プログラミング系のベンチマークでも良い結果を出している。 ▪ → コードが含まれていることで効果が出ている可能性がある。
28 2位解法 ▪ 概要: ▪ magicに気づいたため2位まで上り詰めた ▪ 取り組み: ▪ 初回のLBデータ差し替え後、Tgに273.5を加えるとスコアが伸びること
を試したが、300を加えると更に伸びることに気づいた。 ▪ 最終差し替え後も、Tgに30を加えることでpublicのスコアが大幅に向上 することに気づいた。 ▪ 数値を調整し、Tgに40を加えたものが2位解法となった。 ▪ モデルに関しては詳しい言及なし(ExtraTreesRegressorによるテーブルモデル らしい)
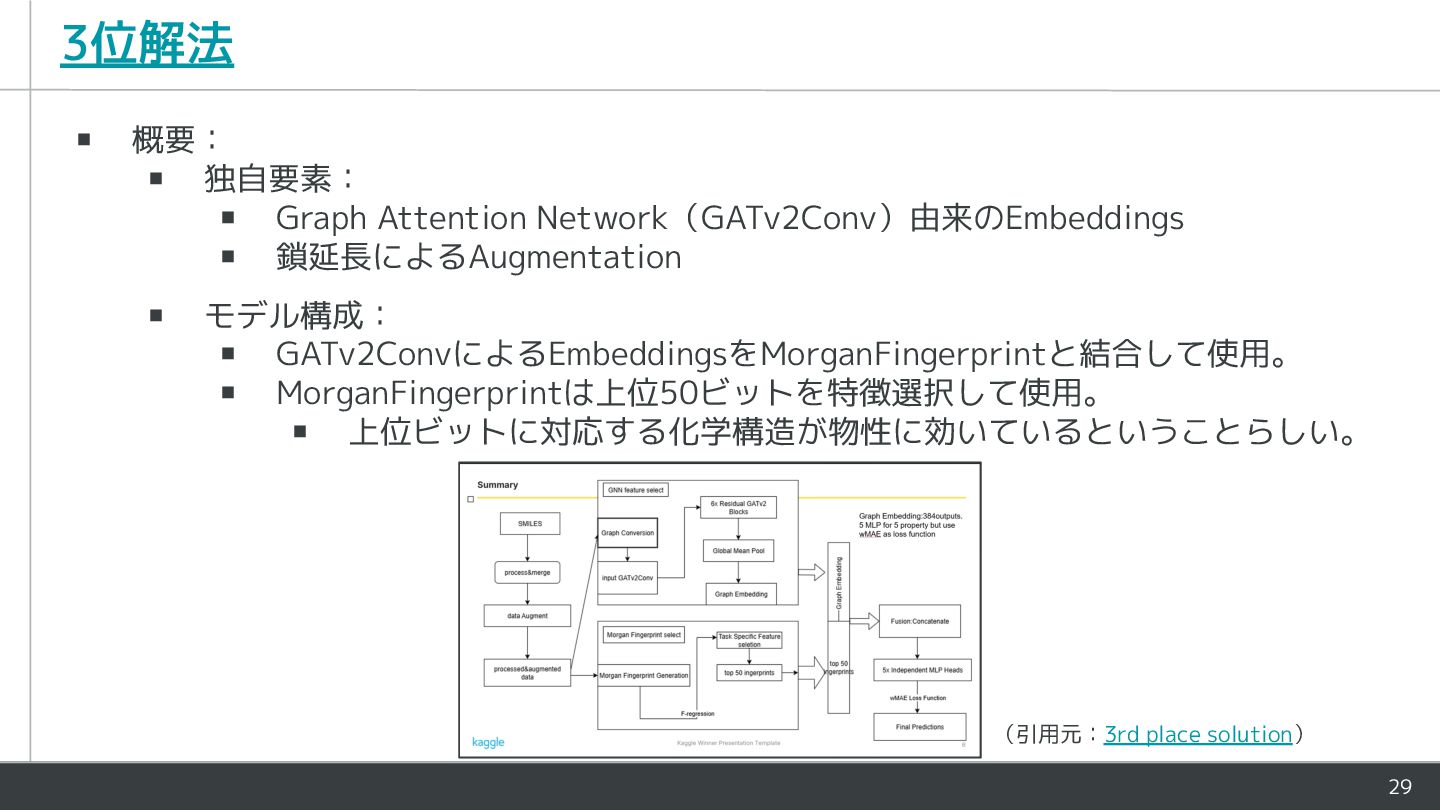
29 3位解法 ▪ 概要: ▪ 独自要素: ▪ Graph Attention Network(GATv2Conv)由来のEmbeddings
▪ 鎖延長によるAugmentation ▪ モデル構成: ▪ GATv2ConvによるEmbeddingsをMorganFingerprintと結合して使用。 ▪ MorganFingerprintは上位50ビットを特徴選択して使用。 ▪ 上位ビットに対応する化学構造が物性に効いているということらしい。 (引用元:3rd place solution)
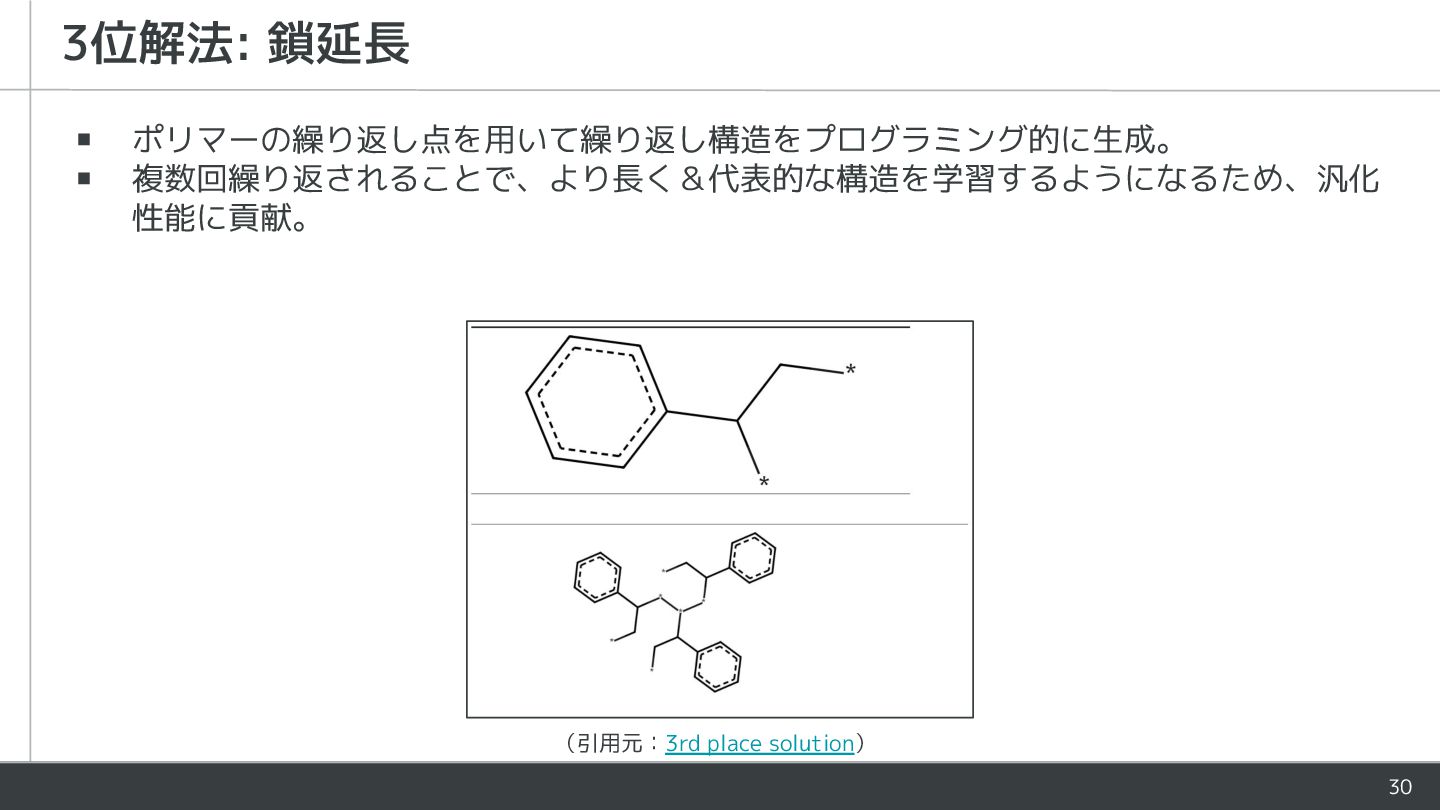
30 3位解法: 鎖延長 ▪ ポリマーの繰り返し点を用いて繰り返し構造をプログラミング的に生成。 ▪ 複数回繰り返されることで、より長く&代表的な構造を学習するようになるため、汎化 性能に貢献。 (引用元:3rd place
solution)
31 14位解法 ▪ 概要: ▪ 「15個の独自特徴量 + RDKit記述子」をランダムフォレストで学習 ▪ 化学専門の方らしく、化学知識を活用して上位に残った好例と言える。
▪ 特徴量は以下を重視して作成: ▪ フッ素の数 ▪ 水素をフッ素で置き換えた構造がある場合、フッ素は重いので密度が高 くなる ▪ 分岐、主鎖・側鎖の骨格 ▪ 分岐の数、側鎖の数、分子量など ▪ 水素結合 ▪ (主に酸素や窒素と結合した)水素原子が、近くにある別の酸素や窒素 のマイナス寄りの電荷に引き寄せられること ▪ 水素原子の数、水素供与体の数、水素受容体の数など
32 おわりに
33 ▪ ポリマーの化学構造をモデルが解釈できる情報に変えていくプロセスは非常に楽しく、 やりがいのあるコンペでした。 ▪ 一方で、定数を加えるとスコアが改善するというmagicは(見つけた方には敬意を表し たいものの)化学構造からの物性予測という観点では本質的ではないように感じまし た。正攻法で結果が出る設定となっていればより楽しめたと振り返ります。 ▪ 本質的な勝負を楽しみたい方は、LB
Probingをしっかりやっておくと、今回のよ うなケースを避けられるかもしれません。 ▪ 最終的には非常に楽しかったので、またポリマーコンペを見つけたら、きっと参加して しまうと思います。 おわりに
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}