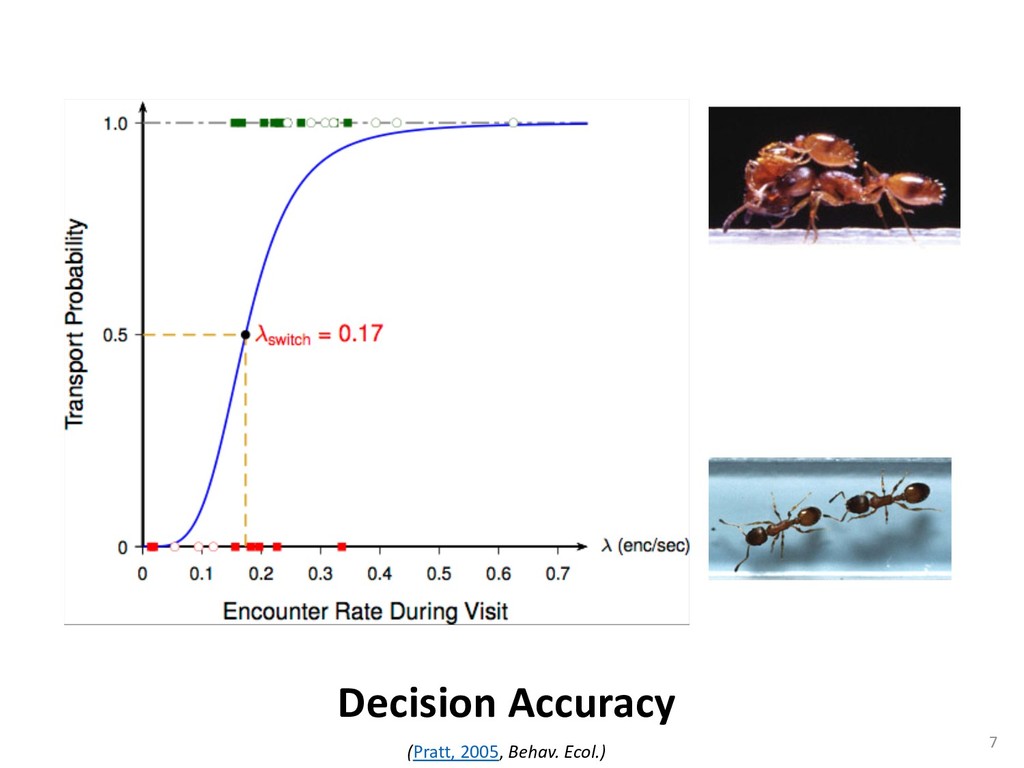
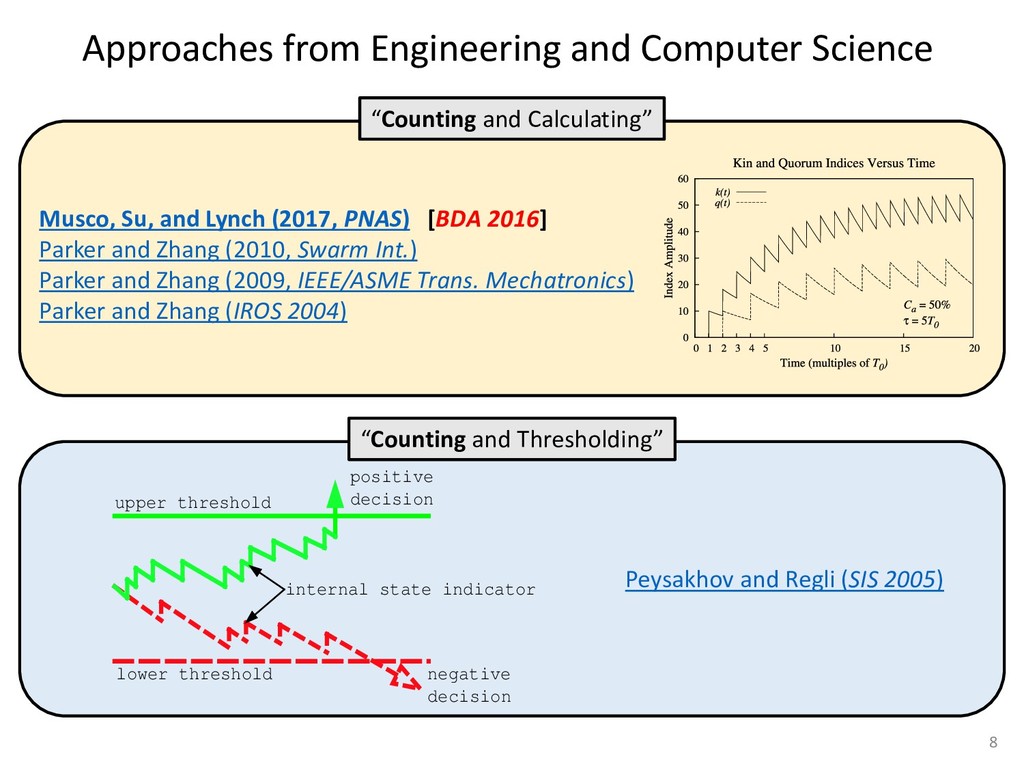
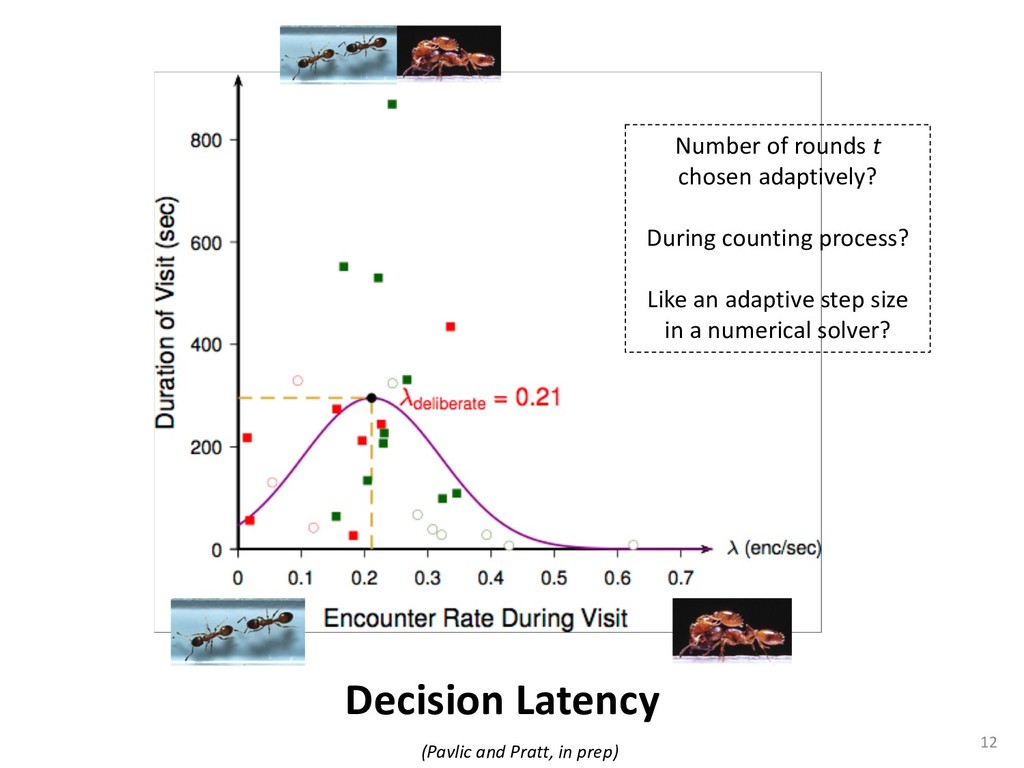
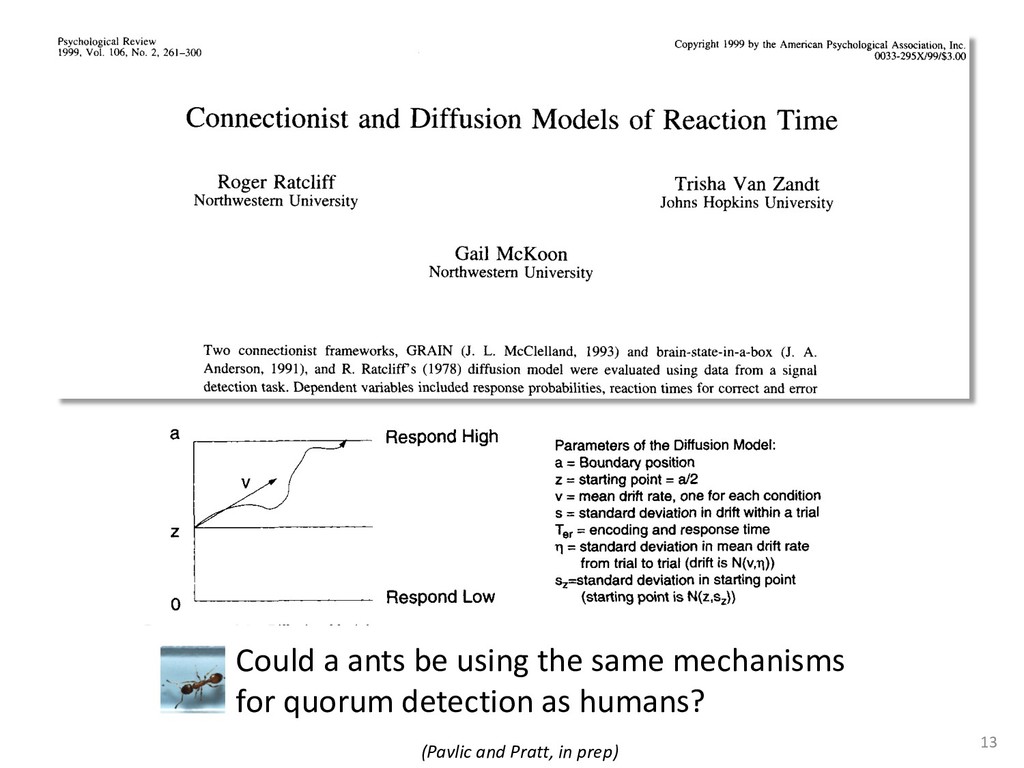
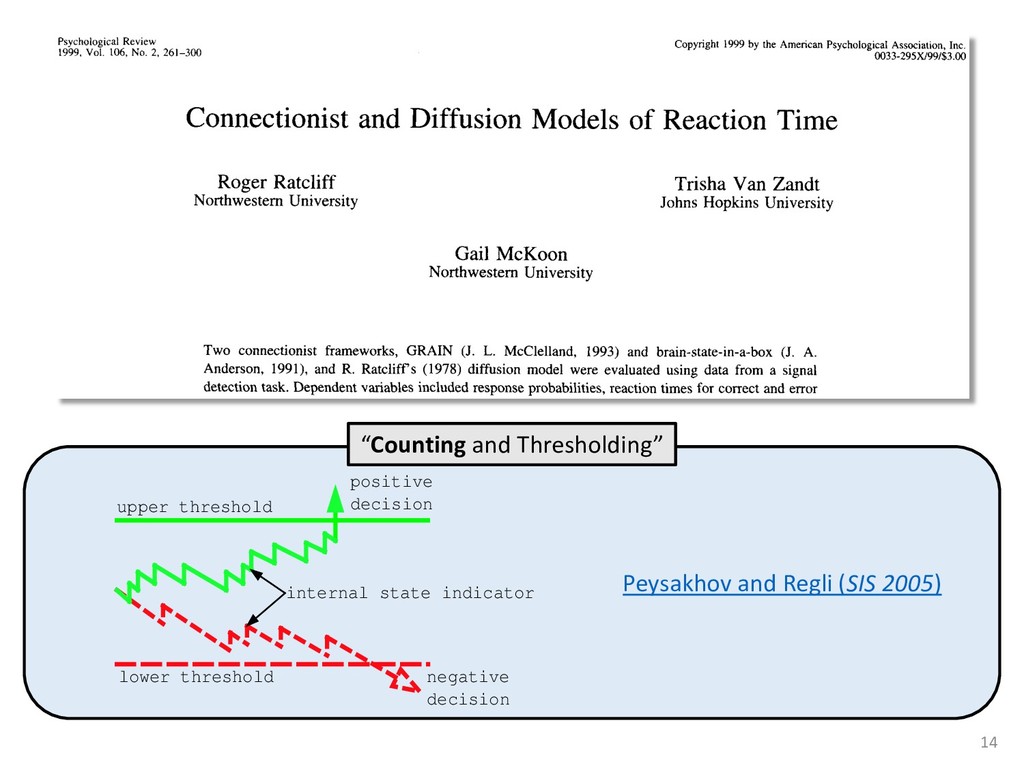
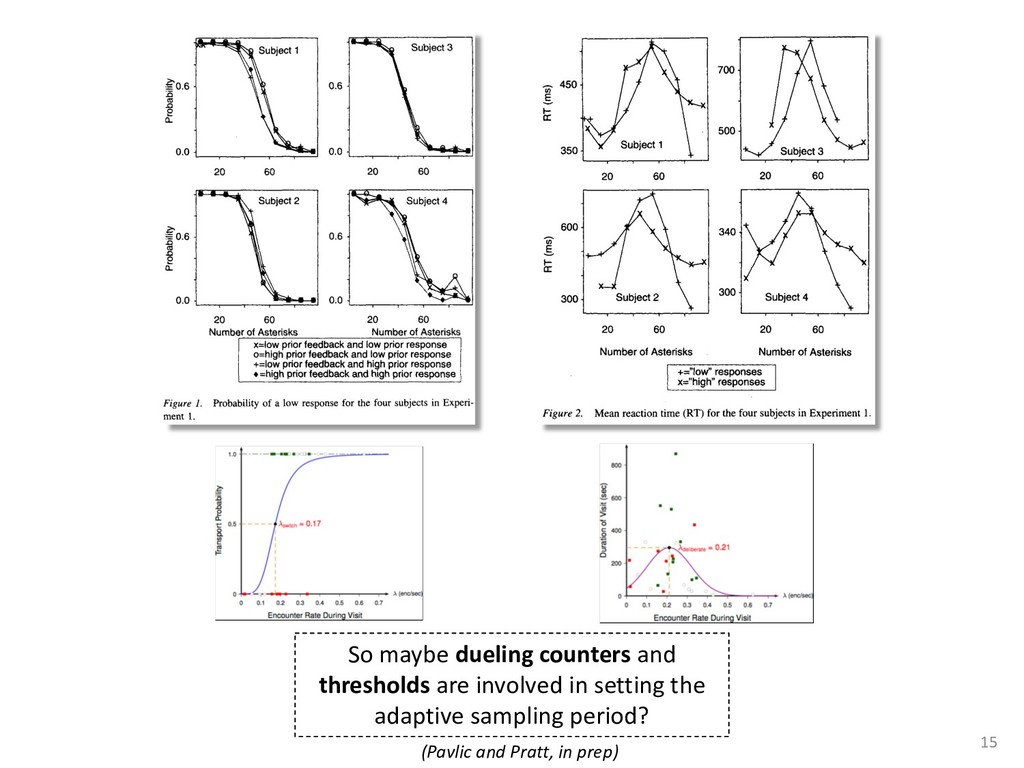
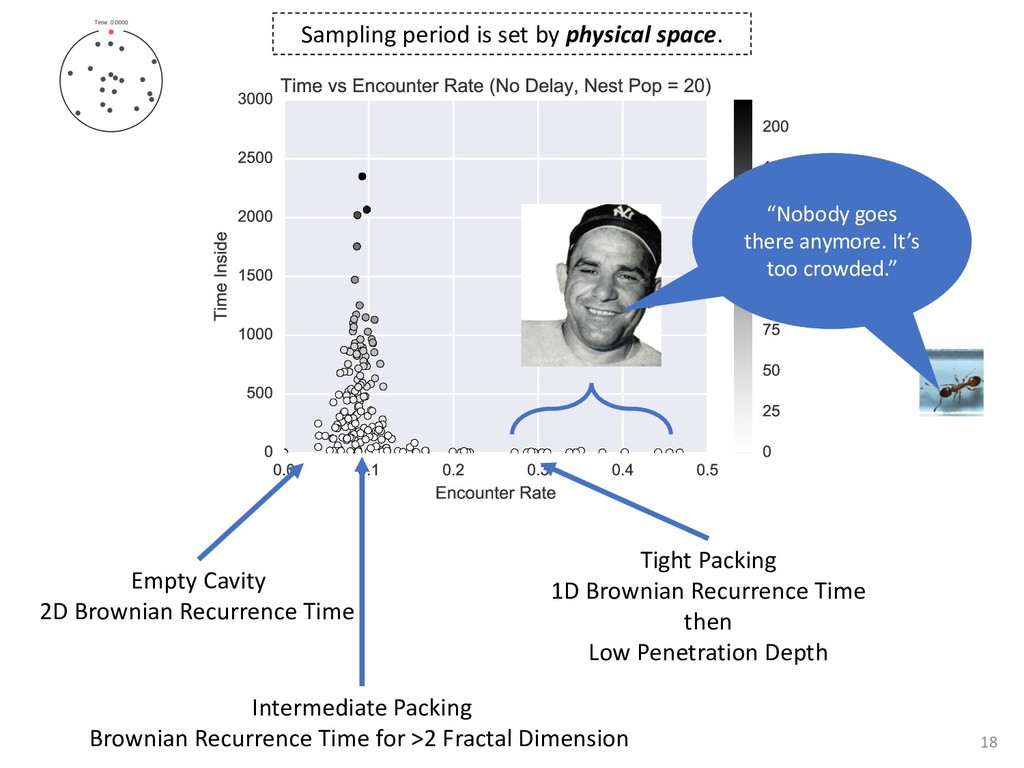
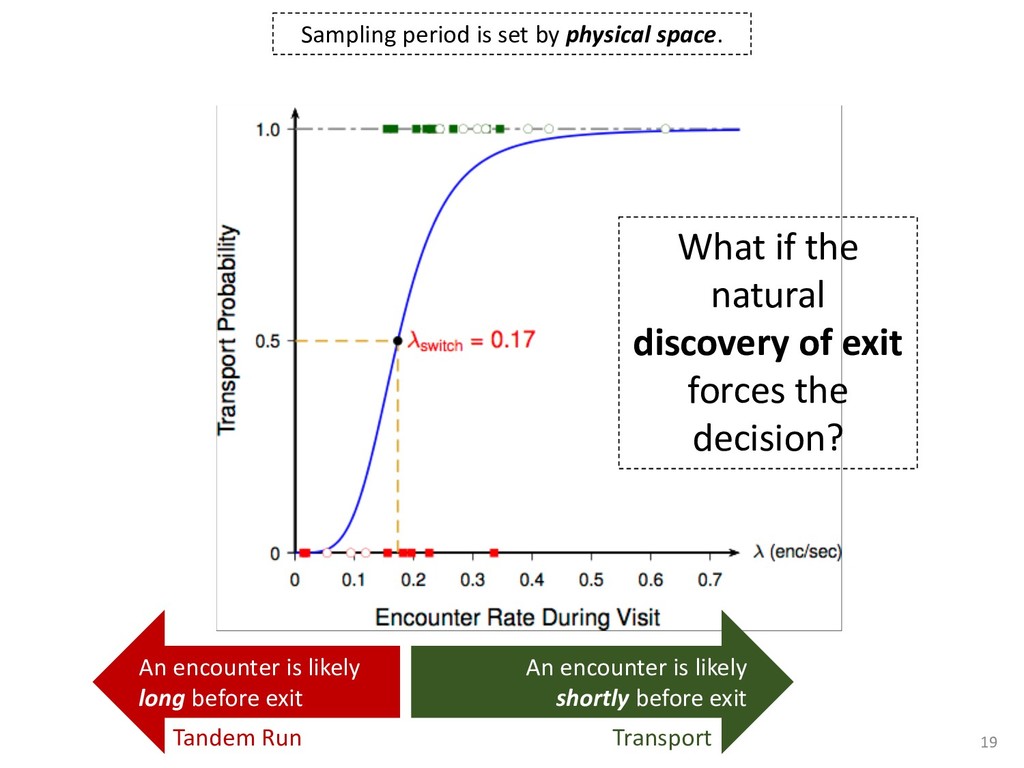
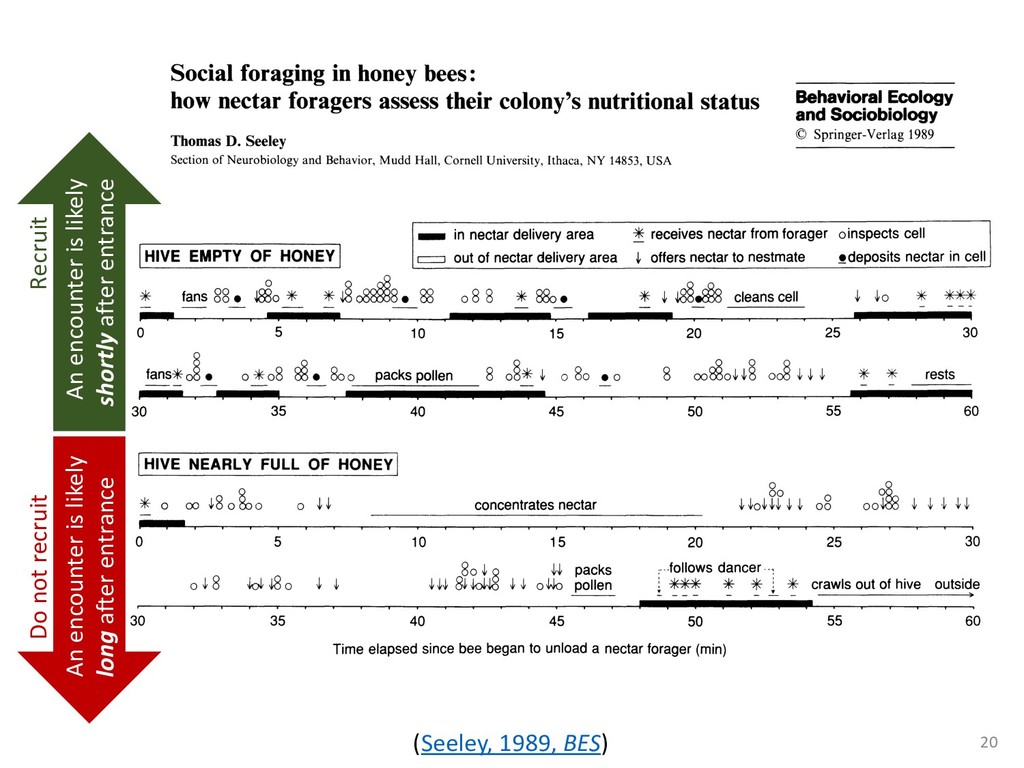
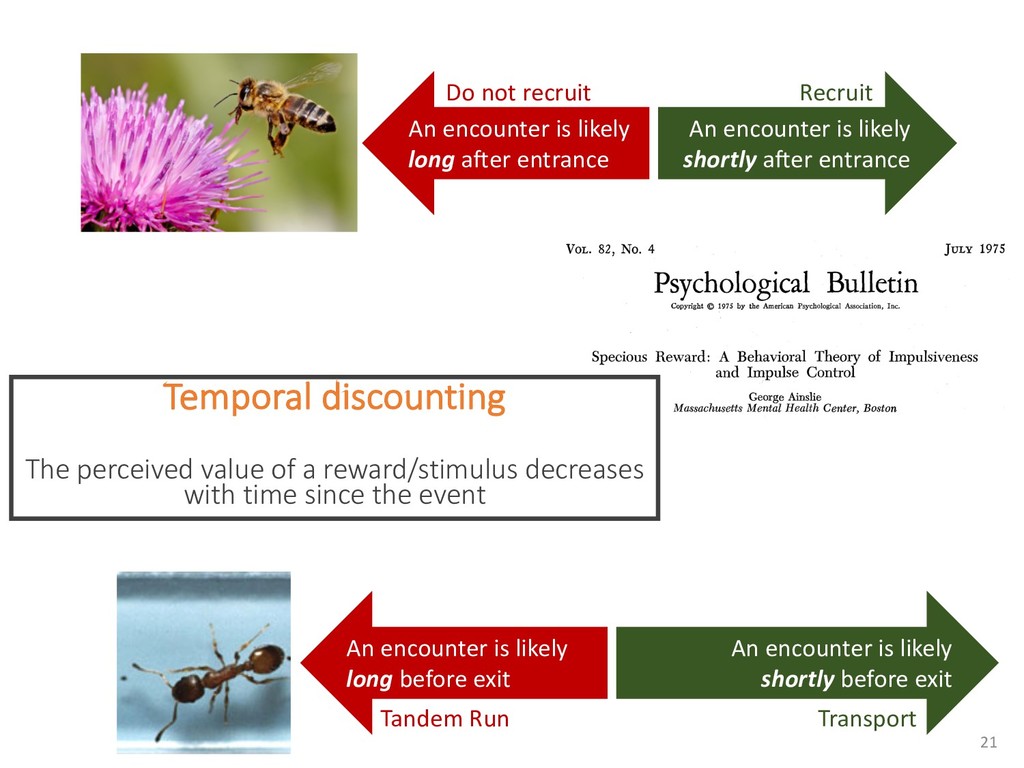
exper- add to the payment rate for the he asterisks. They remained on the ich point the screen was erased. If iting period ensued and then the d. If the response was in error, the on the screen for 500 ms, followed of 50 trials was completed in less he subject was encouraged to take 11 sessions (except Subject 1, who mately 3 weeks. Each session was hin a block, one half of the stimuli and one half were sampled from of 1,200 observations per session used in any analysis (except for observations per subject. The first rded from the analyses. rials with response times less 00 ms were discarded (these . dividual differences in perfor- e long reaction times (in the ced very short reaction times other two were intermediate. ange of behaviors is a positive the models to have flexibility. , they might fit average data l data of the more extreme vided into three parts. First, it bjects' high and low responses the probabilities high and low showed sequential effects with ected by the response on the enerally slowed as the number er the crossover point between ross subjects, the relationship times varied. Third, the distri- the typical skewed shape and n either reached asymptote or asks; see Luce, 1986). ntial effects. Figure 1 shows r each subject as a function of vious response. The probabil- d they cross the 50th percentile hich the low and high distribu- performed without systematic l effects. For Subjects 1 and 4, S Q_ 0.0 Subject 1 0.6 0.0 • Subject 3 20 60 20 60 0.0 Subject 2 0.6 - 0.0 - 20 60 Number of Asterisks 20 60 Number of Asterisks x=low prior feedback and low prior response o=high prior feedback and low prior response +=low prior feedback and high prior response »=high prior feedback and high prior response Figure 1. Probability of a low response for the four subjects in Experi- ment 1. models because the mechanism that produces sequential effects must be flexible enough to behave in opposite ways for different subjects. The fact that sequential effects were dependent on the prior response and not on prior feedback is consistent with most earlier findings with psychophysical tasks (Thomas, 1973, 1975; Treis- man & Williams, 1984) and choice reaction time (Falmagne, Cohen, & Dwivedi, 1975; see Luce, 1986, chap. 7), although some studies, particularly in absolute identification (Ward & Lockhead, 1970), did find that feedback affected response probability. In the earliest investigations of signal detection paradigms, it appeared originally that any explanation of learning would have to take prior feedback into account (e.g., Kac, 1962), but Thomas (1973, 1975) showed that learning could be modeled by assuming criterion shifts toward the presented stimulus value so that learning did not depend directly on prior feedback. Thomas's account could also deal with paradigms in which feedback was not presented to the subject. Our experimental results are consistent with these early signal detection results and with the choice reaction-time results. Subjects knew that feedback was inconsistent and that for most stimuli the correct response was sometimes high and sometimes low. This, along with the large number of sessions tested per (Pavlic and Pratt, in prep) 266 RATCLIFF, VAN ZANDT, AND McKOON 700 500 350 20 60 20 60 600 300- 340 300 20 60 Number of Asterisks 20 60 Number of Asterisks +="low" responses x="high" responses Figure 2. Mean reaction time (RT) for the four subjects in Experiment 1. high and low responses. Generally, responses slowed as they neared the crossover point. For purposes of exposition, we defined error responses accord- ing to the crossover point (47); low responses to numbers greater than 47 are labeled errors, and so are high responses to numbers less than 47. We used error as the label for these responses because it is a convenient way of describing them. A response of this type is not exactly an error, but neither is it the best response because it is less likely to be correct than the alternative. (Note that this definition does not correspond to the feedback that was given subjects; ERROR -1 POINT feedback was determined by the distribution from which a number was drawn, not by its position relative to the crossover point.) We use the error terminology for compactness of description throughout this article. The subjects showed different patterns of error versus correct response times. For Subjects 1 and 2, errors for extreme stimulus numbers (e.g., numbers above 80 or below 20) were faster than correct responses for those numbers, whereas less extreme errors were slower than correct responses. But for Subject 4, errors were always faster than correct responses, and for Subject 3 errors were always slower than correct responses. This difference among sub- collapsed. So, for example asterisks can be averaged w equivalent high responses low response to 27 asteris of a high response to 67 a can be plotted against the in Figure 3. Thus, the late a parametric plot where th stimulus difficulty. The different patterns show up in the degree to are symmetric. Errors gene probability less than .5. corresponds to an error example, if the probability sponding error probability corresponding errors had probability function wou function with a maximum is asymmetric, with errors correct responses (see Fig tions are asymmetric, wit except that the most extr sponses. For Subject 4, t errors are a little faster th Besides providing a sum response probability functi traditional sequential samp Pike, 1965; Vickers, 1979 simple random walk m 550 i 15 So maybe dueling counters and thresholds are involved in setting the adaptive sampling period?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
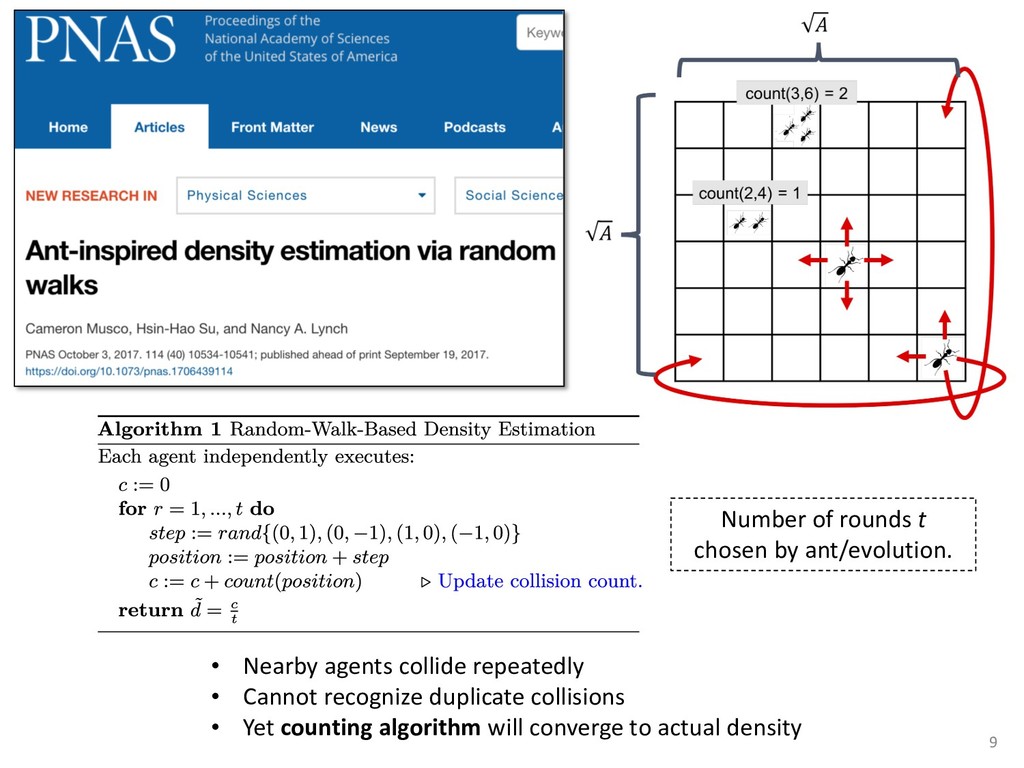{kind=link}
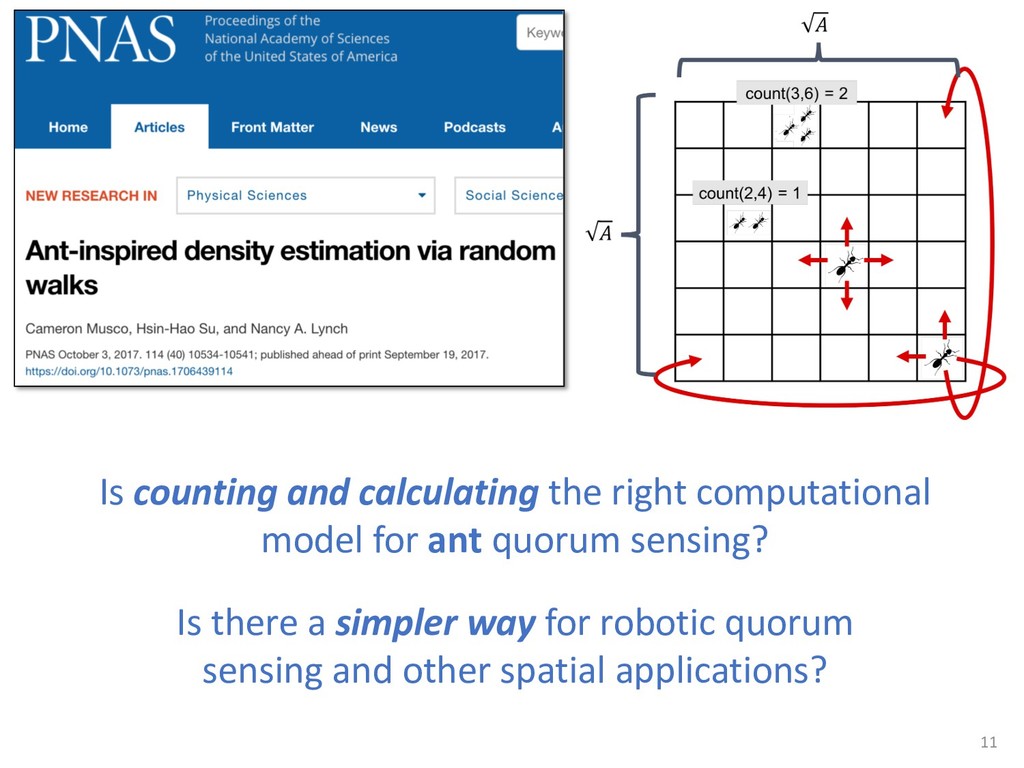{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![30 “Any questions?” @TedPavlic [email protected] Web version of simulator: http://bit.ly/bda2018quorum](https://files.speakerdeck.com/presentations/e554159425df4bf3a2da0fd85ab6f537/slide_28.jpg){kind=link}