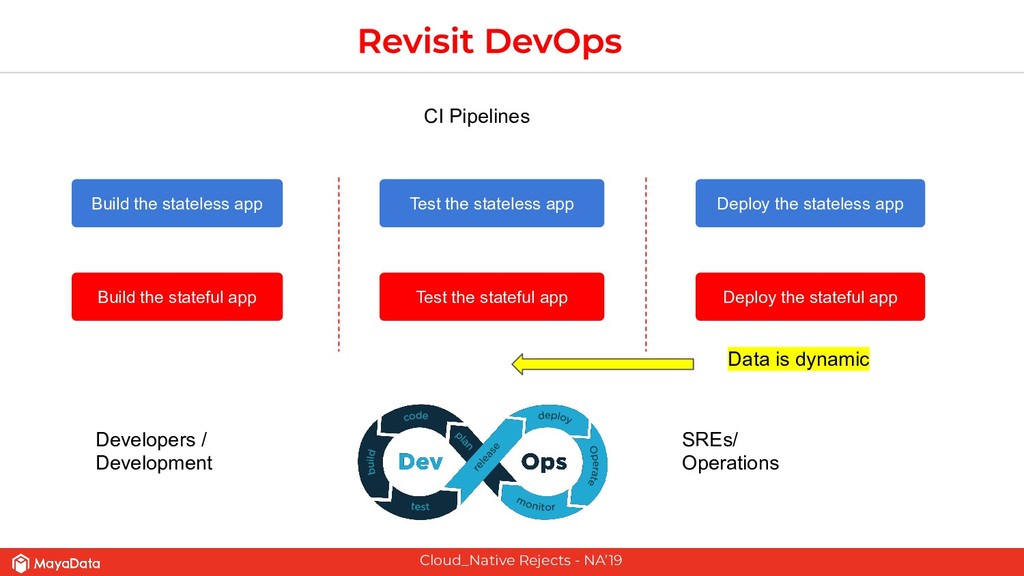
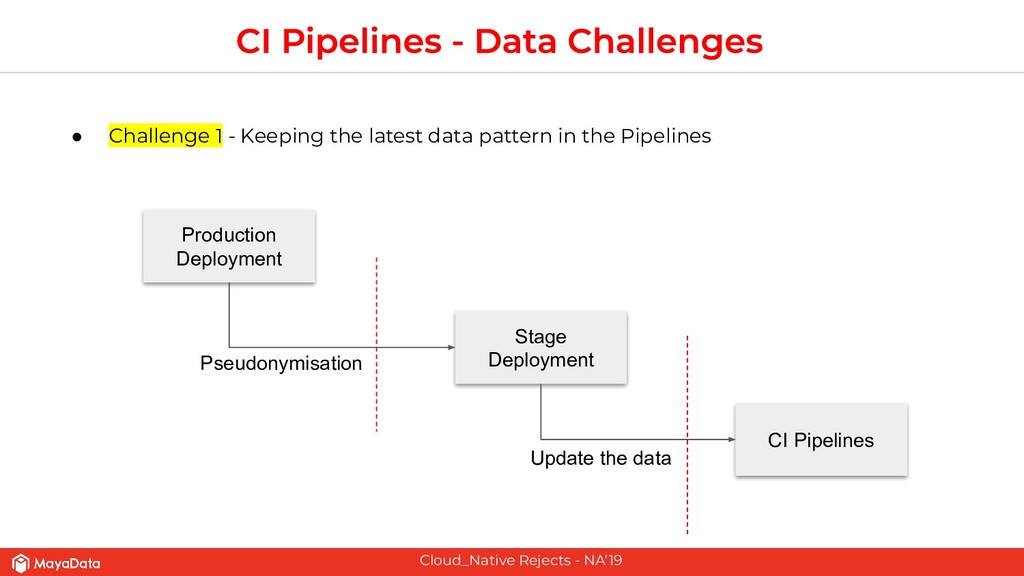
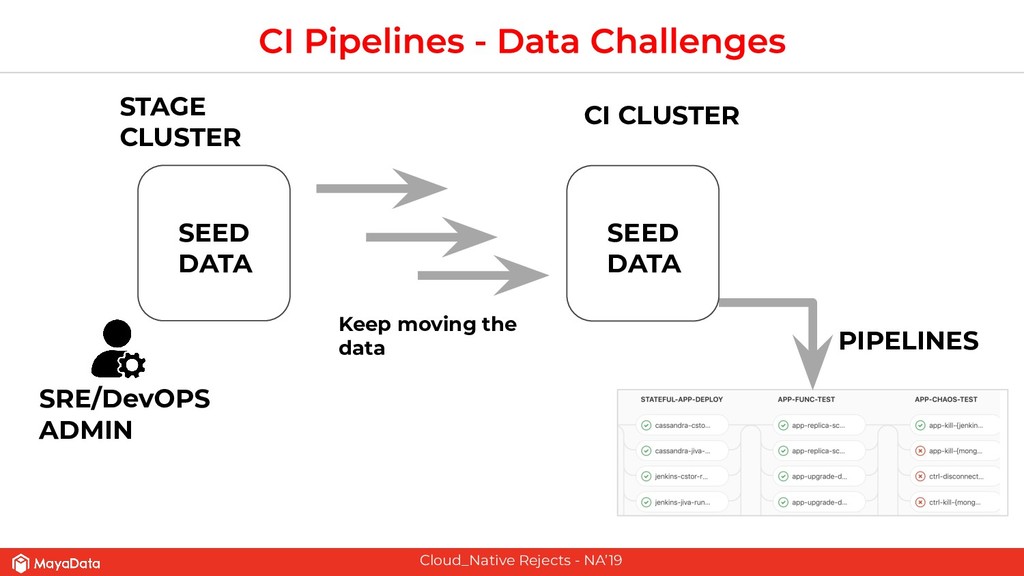
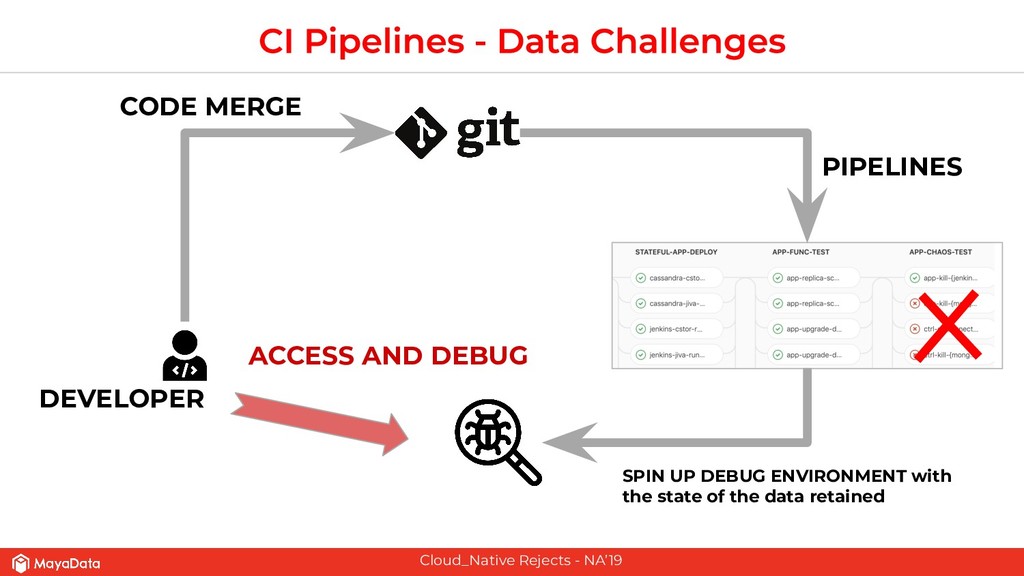
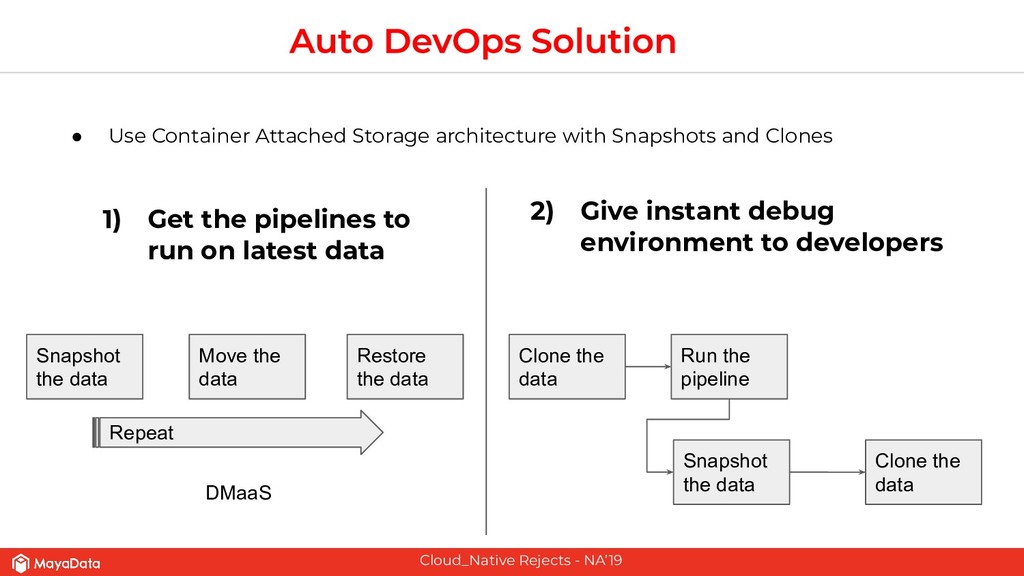
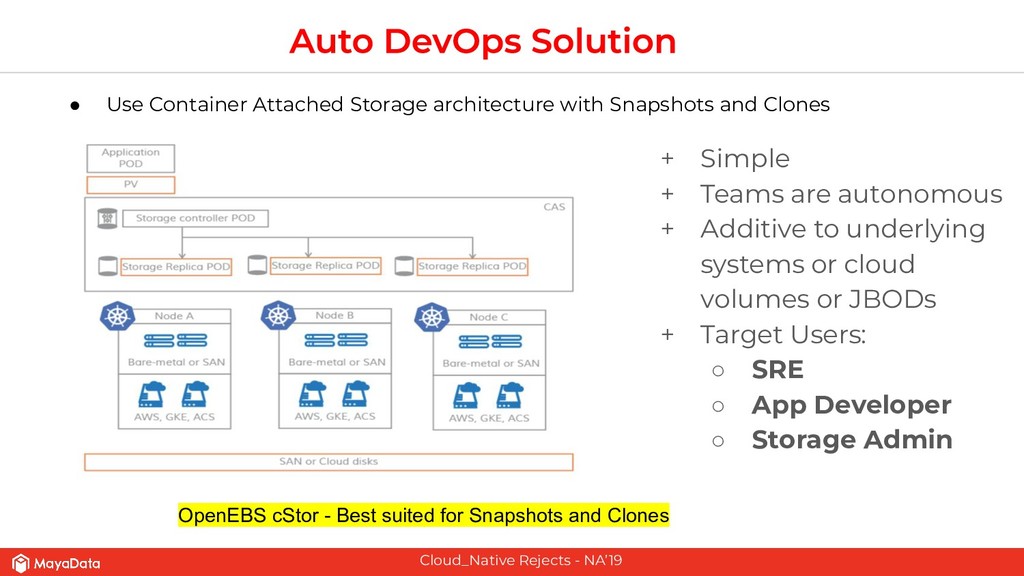
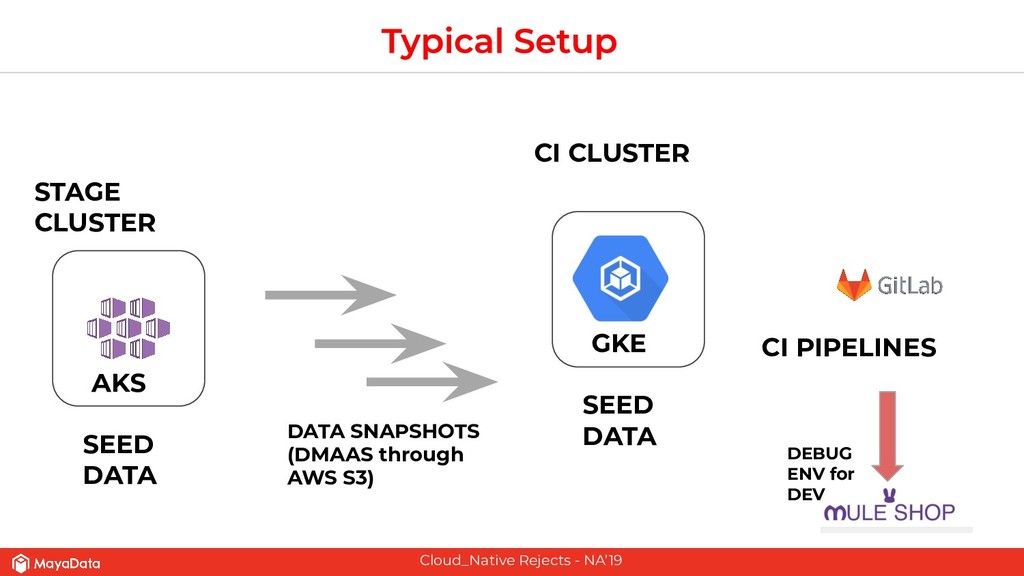
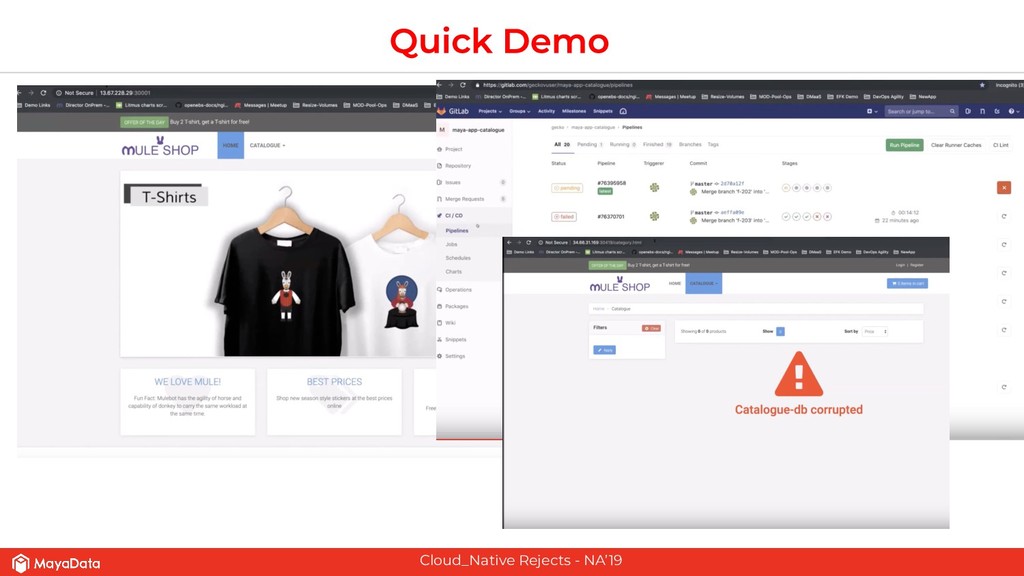
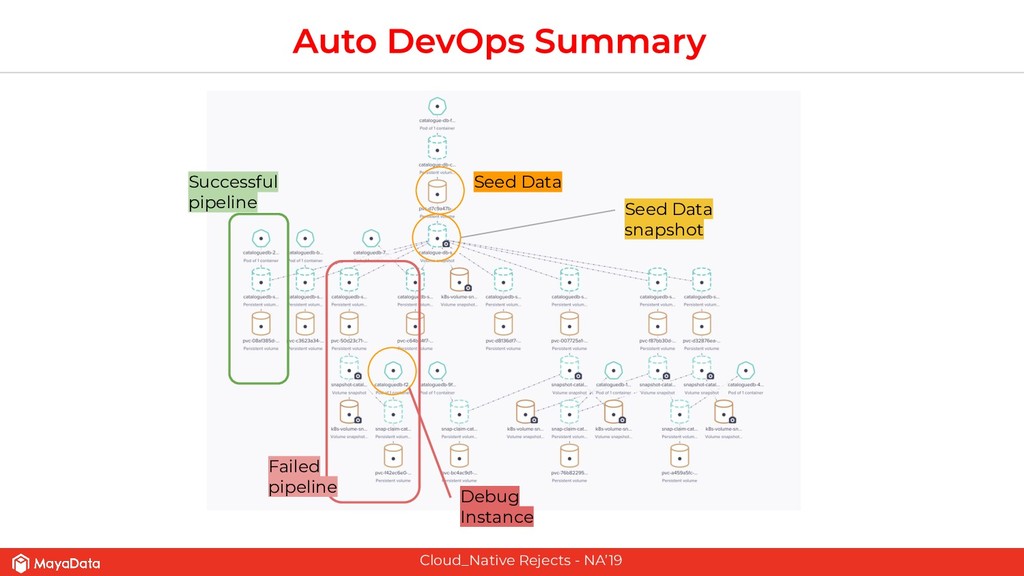
On stateful applications in production, the data patterns keep changing as the time progresses. CI pipelines need to have access to the latest data or closer to the latest data for effective testing. As Enterprises and FinTechs start to use Kubernetes and microservices-based architecture, their DevOps teams would like to solve two challenges that are well known in the pre-Kubernetes era. The first challenge is to automate the data lifecycle between production and testing. The second challenge is to give developers instantaneous access to the failed environment when the CI pipeline fails. Solving these two challenges in the Kubernetes space will make the DevOps more productive in enterprises.
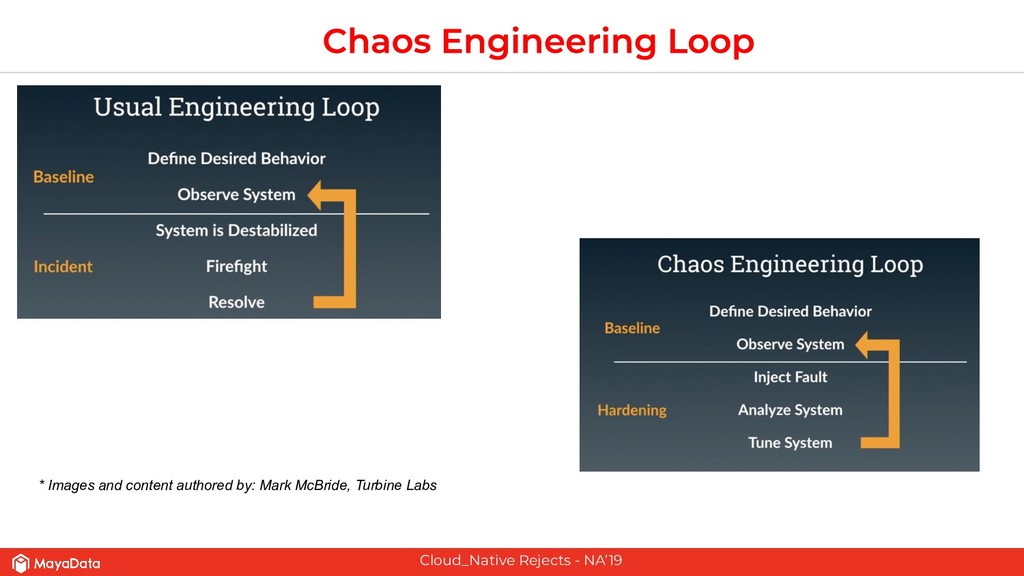
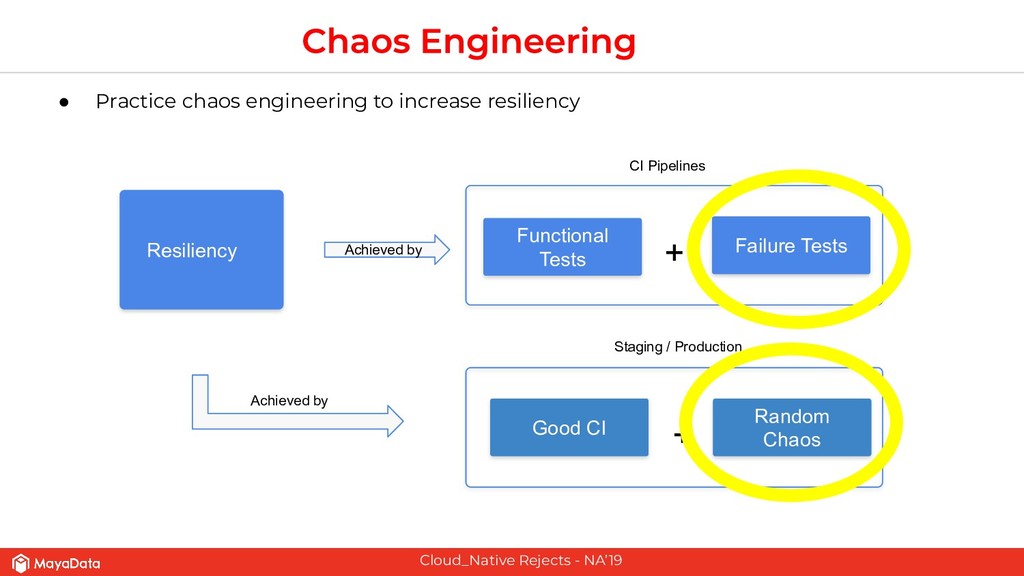
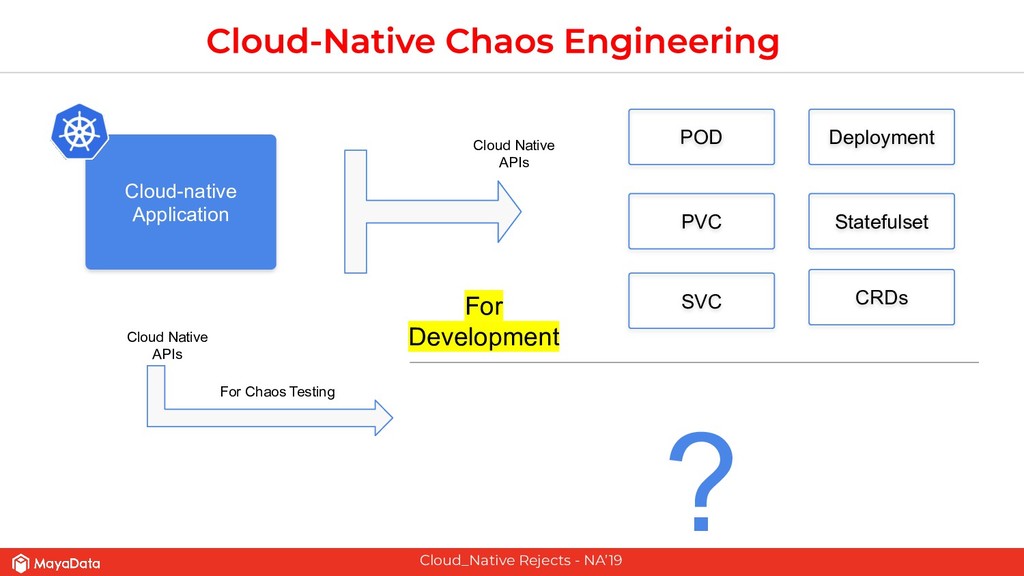
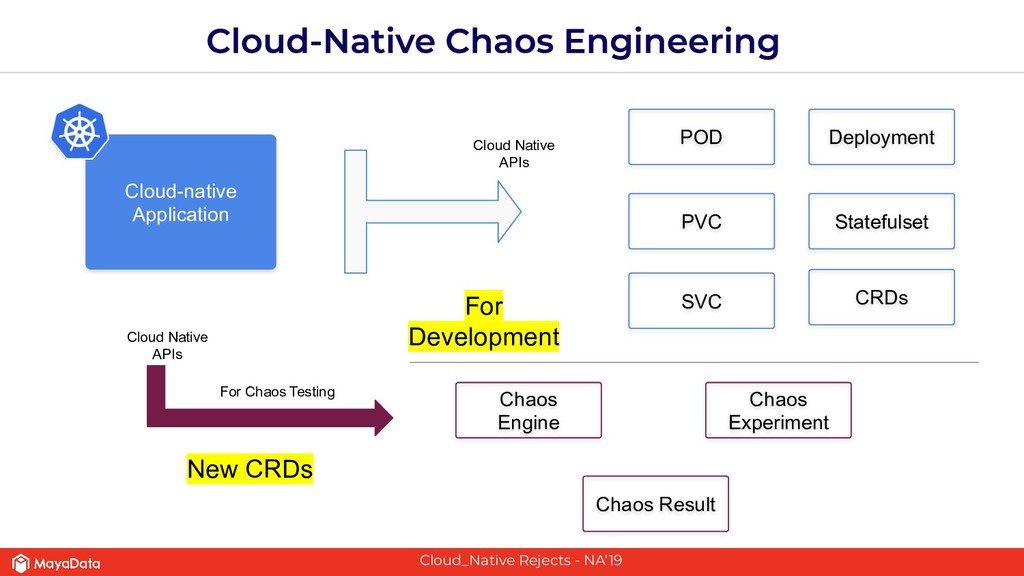
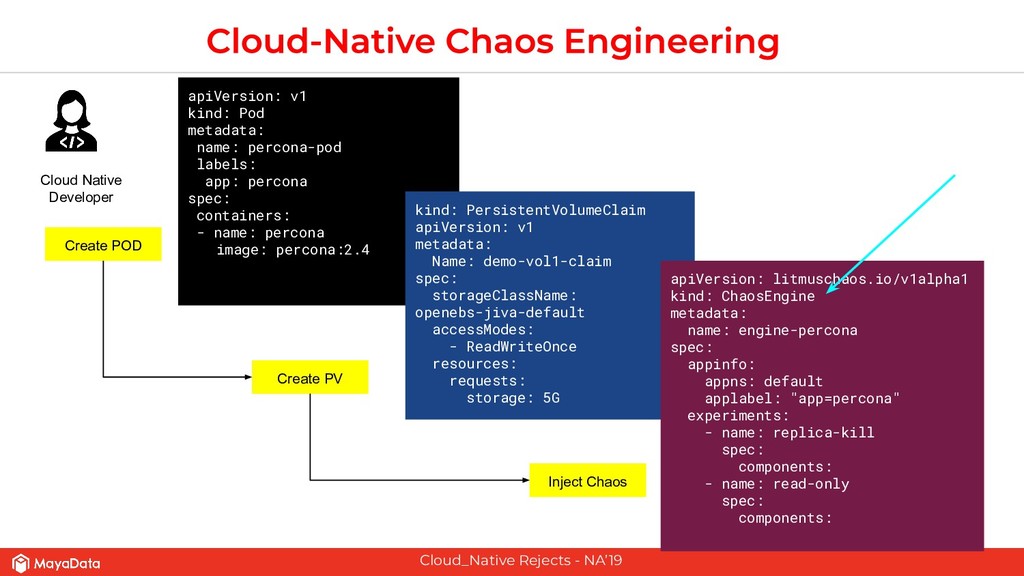
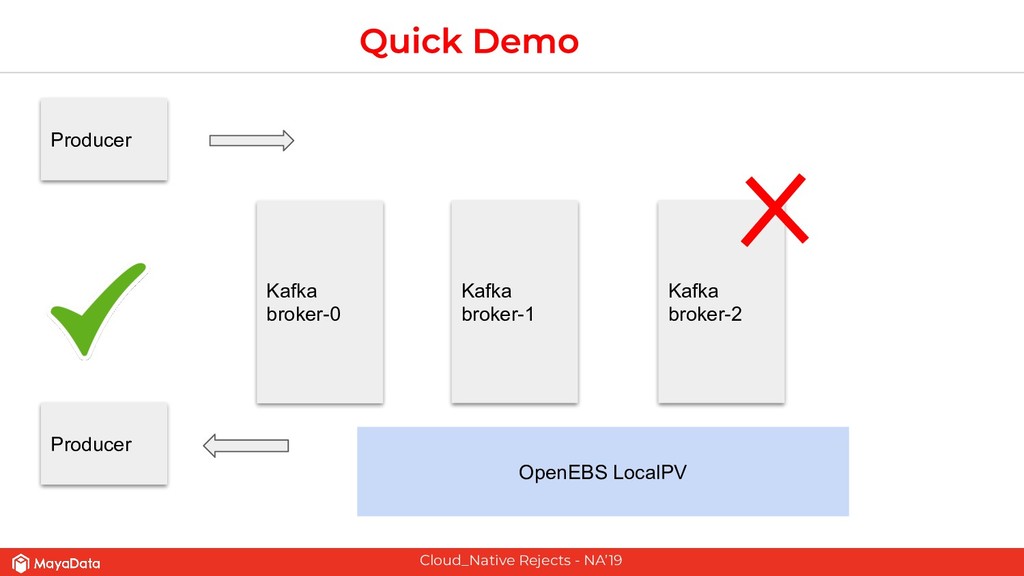
The second part of this presentation is about hardening stateful applications on Kubernetes using Chaos Engineering. We introduce need for Litmus, demonstrate injecting Chaos into Kafka.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}