Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
質問箱の負荷対策
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
umemotoryo
October 31, 2019
Programming
490
0
Share
質問箱の負荷対策
umemotoryo
October 31, 2019
More Decks by umemotoryo
See All by umemotoryo
障害対応で実施する3つのこと
umemotoryo
0
600
Other Decks in Programming
See All in Programming
AI時代のエンジニアリングの原則 / Engineering Principles in the AI Era
haru860
0
570
ローカルで稼働する AI エージェントを超えて / beyond-local-ai-agents
gawa
3
280
SREに優しいTerraform構成 modulesとstateの組み方
hiyanger
2
150
運転動画を検索可能にする〜Cosmos-Embed1とDatabricks Vector Searchで〜/cosmos-embed1-databricks-vector-search
studio_graph
0
400
HTML-Aware ERB: The Path to Reactive Rendering @ RubyKaigi 2026, Hakodate, Japan
marcoroth
0
170
Angular Signal Forms
debug_mode
0
110
感情を設計する
ichimichi
5
1.5k
Coding at the Speed of Thought: The New Era of Symfony Docker
dunglas
0
5k
Running Swift without an OS
kishikawakatsumi
0
850
Back to the roots of date
jinroq
0
310
UIの境界線をデザインする | React Tokyo #15 メイントーク
sasagar
2
380
実用!Hono RPC2026
yodaka
2
250
Featured
See All Featured
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
0
1.2k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
480
Designing for humans not robots
tammielis
254
26k
Making the Leap to Tech Lead
cromwellryan
135
9.8k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
160
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
240
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.4k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
900
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.9k
4 Signs Your Business is Dying
shpigford
187
22k
Prompt Engineering for Job Search
mfonobong
0
270
Transcript
質問箱の負荷対策
2 画像・図・グラフなど • 名前: 梅本稜 • 担当サービス ◦ 質問箱 •
実装 ◦ サーバーサイド ◦ インフラ • ジラフ歴: だいたい5年 • DDos経験: 3回 自己紹介
3 1. アーキテクチャ図(簡易版) 2. よくわからないけど繋がらなくなる 3. DBのコネクションがいっぱいになる 4. Redisのメモリが不足する 目次
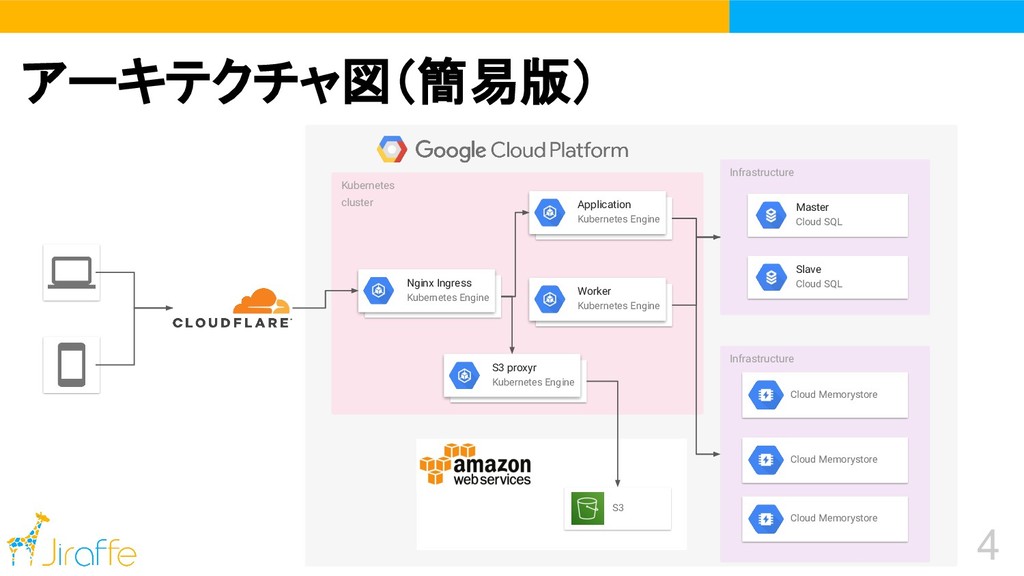
4 アーキテクチャ図(簡易版) Infrastructure Master Cloud SQL Slave Cloud SQL Kubernetes
cluster Application Kubernetes Engine Worker Kubernetes Engine Nginx Ingress Kubernetes Engine Infrastructure Cloud Memorystore Cloud Memorystore S3 Cloud Memorystore S3 proxyr Kubernetes Engine
5 よくわからないけど 繋がらなくなる
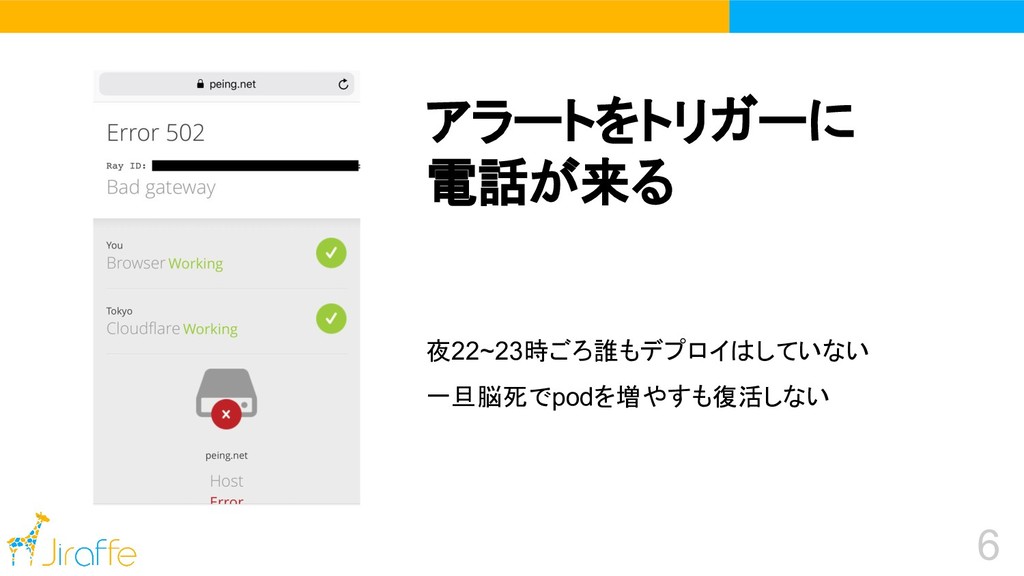
6 アラートをトリガーに 電話が来る 夜22~23時ごろ誰もデプロイはしていない 一旦脳死でpodを増やすも復活しない
7 前提 podを増やしても復活しない GCPで障害は発生していない 仮説 1. LBが死んでいる 2. DBで詰まっている 3.
Redisのメモリが溢れている 問題を切り分ける
8 1. LBが死んでいる a. これはGCPのワークロードからpodの状態を確認して問題なし 2. DBが詰まっている a. DBにshow processlistを実行すると60秒以上実行されているクエ
リが多く発見される b. しかもレプリケーションが3時間近く遅延 3. Redisのメモリが溢れている a. Stackdriverで見ると溢れていない 仮説検証する
9 1. 質問テーブルと回答テーブルをjoinしたクエリ 2. ユーザーテーブルのレコードに頻繁にアップデートが実行されロック 3. indexを貼っていないカラムで検索してフルスキャン&filesort DBが詰まっている原因
10 一次対応 Redisで出来るだけキャッシュする 実行箇所をコメントアウトして空のオブジェクトを返す 恒久対応 joinせずに2回クエリを実行する 処理を見るとjoinする必要がないものがあったのでjoinをやめる 質問テーブルと回答テーブルをjoinし たクエリの対策
11 一次対応 アクセス日はユーザーに見えないので更新するメソッドをコメントアウト 恒久対応 アクセスと同時にアップデートしていたので非同期にする 現在はBigQueryで管理 ユーザーテーブルのレコードに 頻繁にアップデートが実行されロック
12 一次対応 Redisに出来るだけキャッシュする コメントアウトして空のオブジェクトを返す 恒久対応 explainを使用して適切なindexを探す 検索する値の順番を整理する indexを貼っていないカラムで検索し てフルスキャン&filesort
13 DBのコネクションが いっぱいになる CloudSQLのmysqlの最大コネクションの 4000コネクションに到達
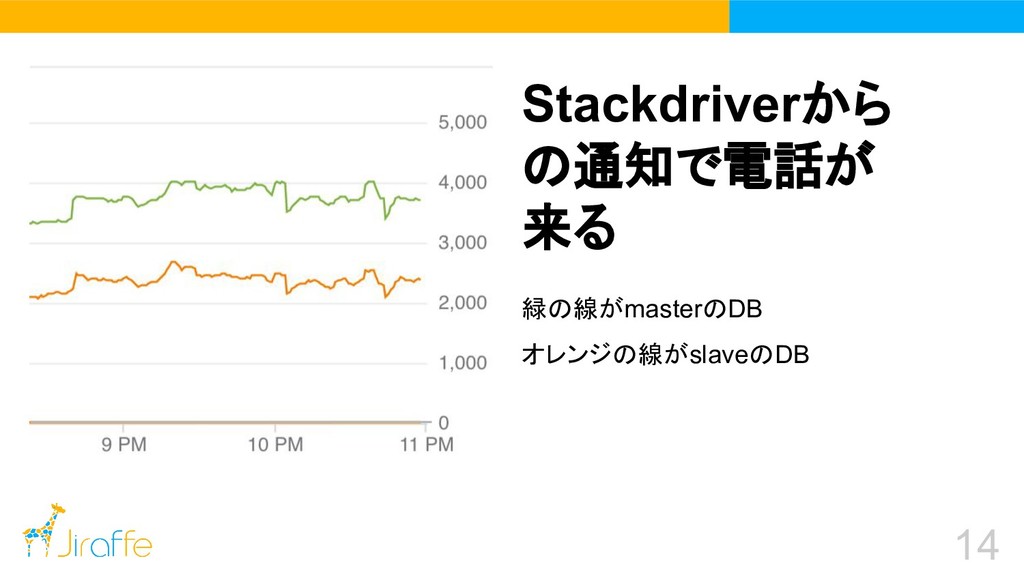
14 緑の線がmasterのDB オレンジの線がslaveのDB Stackdriverから の通知で電話が 来る 画像・図・グラフなど
15 Pumaの場合 PumaのWorker * pool らしい(ソースコードまで追ってないです) なので Pod * PumaのWorker
* pool が4000以下になるように database.yml設定を変更する コネクションの総数を計算する 方法を調べる
16 show processlistで表示される行数と Pod * PumaのWorker * pool の数を比較して減らす 怖かったので1つずつpoolを減らして様子をみる
同時にPumaの処理待ちをStackdriverで監視して処理が詰まらないことを 確認しながら行なった 質問箱の場合は最終的に 7 になった(cpu 6core, memory 32GB) database.ymlの変更
17 Redisのメモリが不足する キャッシュしすぎた
18 1. 負荷対策でキャッシュしたものが増えた 2. sidekiqで処理待ちになったjobが400万近くあった 3. キャッシュによってどの程度の容量が必要か計算していなかった 経緯
19 lib/peing_cache_pool.rbをに以下をコードを設置 複数のRedisを接続できるように変更
20 ジラフではエンジニアを募集しています! もし興味がある方は僕に声をかけて欲しいです! 最後に
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}