Are you preparing for your first data science job interview in 2025? Unified Mentor brings you a handpicked list of the most commonly asked entry-level data science interview questions along with clear, concise answers. This guide is perfect for fresh graduates, career switchers, or anyone looking to break into the fast-growing world of data science. From Python basics and SQL queries to machine learning concepts and real-world case studies, we’ve got you covered.
At Unified Mentor, we believe in empowering learners with practical, job-ready knowledge. This blog not only helps you understand what employers are looking for but also gives you the confidence to tackle interviews with ease. Whether you're gearing up for your first role or polishing your skills, this resource is your gateway to success in the competitive data science industry. Read now and take the first step toward your dream career!
![Top 30+ Entry-Level Data Science Interview Questions and Answers [2025]](https://files.speakerdeck.com/presentations/c3d3770ee6b749c6b3e7c11d02de099d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
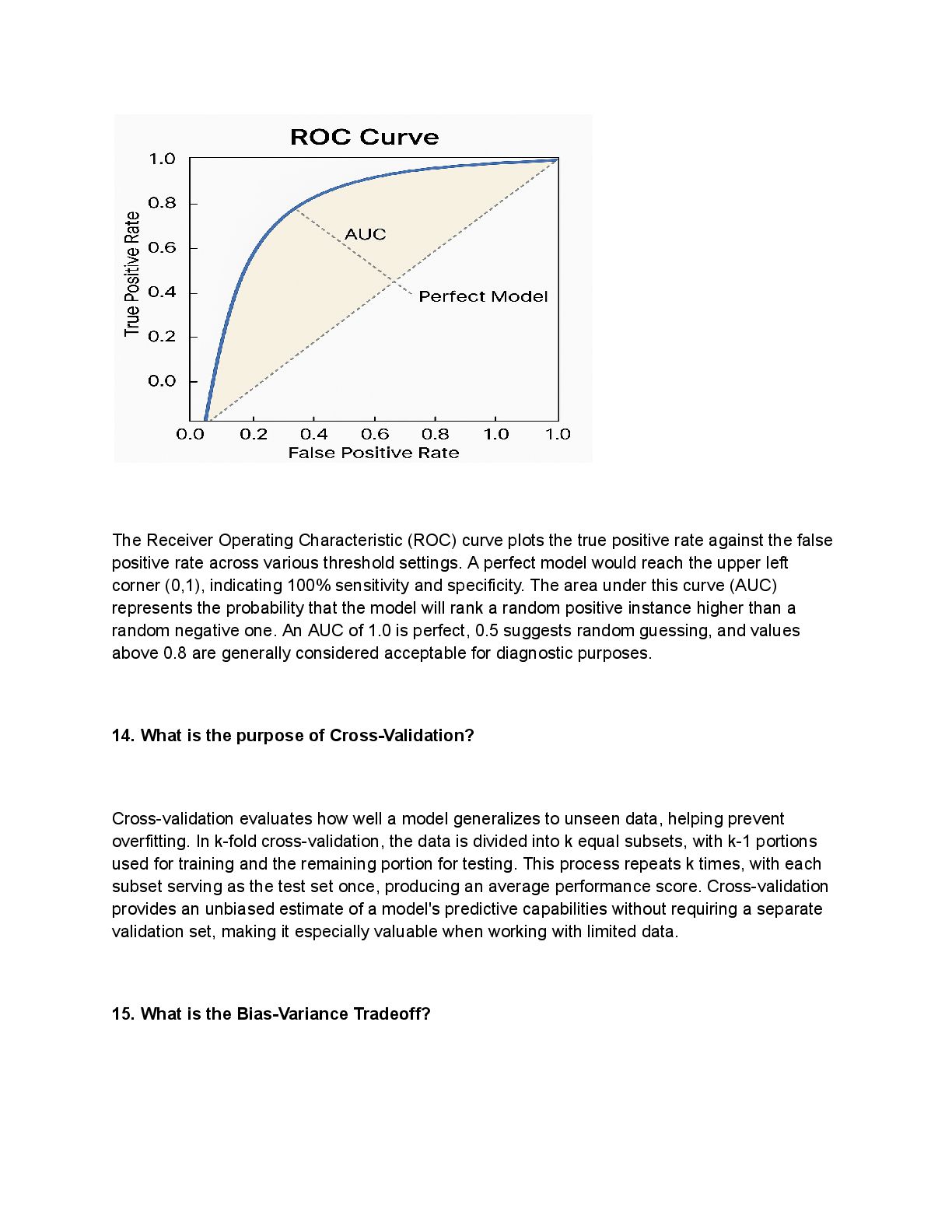{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}