Biology Zaragoza CSIC Spain [email protected] https://github.com/valdeanda @val_deanda mebs multigenomic score ENTROPY BASED The 12th International Conference on Genomics O c t o b e r 2 6 t o 2 9 , 2 0 1 7 S h e n z h e n , C h i n a A software platform to evaluate large (meta)genomic collections according to their metabolic machinery: unraveling the sulfur cycle
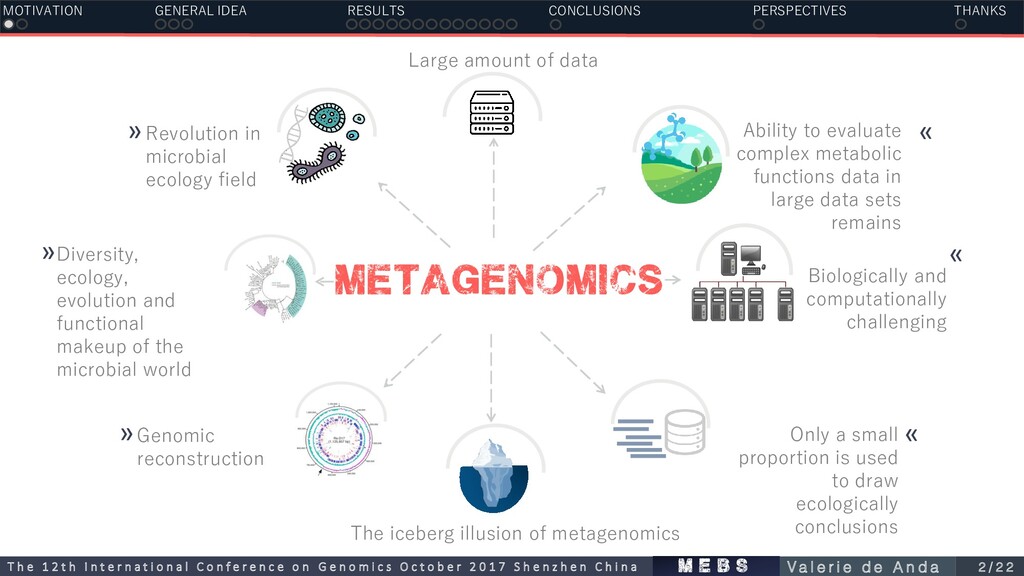
Large amount of data » Ability to evaluate complex metabolic functions data in large data sets remains » Only a small proportion is used to draw ecologically conclusions The iceberg illusion of metagenomics Biologically and computationally challenging » »Diversity, ecology, evolution and functional makeup of the microbial world MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 2 / 2 2
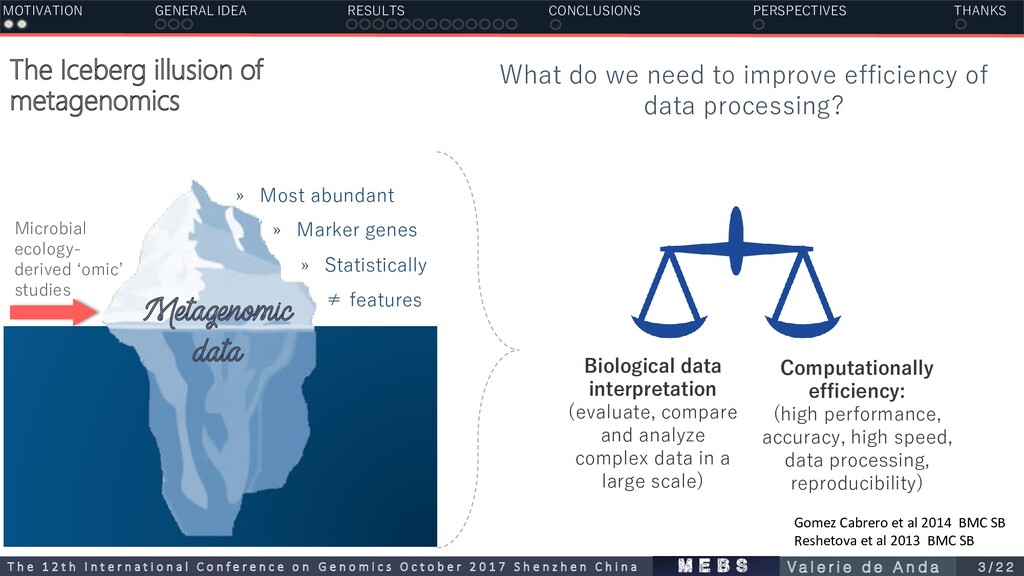
What do we need to improve efficiency of data processing? Biological data interpretation (evaluate, compare and analyze complex data in a large scale) Computationally efficiency: (high performance, accuracy, high speed, data processing, reproducibility) » Most abundant » Marker genes Metagenomic data » Statistically ≠ features Gomez Cabrero et al 2014 BMC SB Reshetova et al 2013 BMC SB MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 3 / 2 2
types) of data are available and we want to study them integratively to improve knowledge discovery What are the available data that can be used to characterize large-scale metabolic pathways? How do we integrate all to improve the understanding the system?. C Gomez Cabrero et al 2014 BMC SB Reshetova et al 2013 BMC SB Prior knowledge: To reduce the solution space and/or to focus the analysis on biological meaningful regions (specific metabolic machineries) (Targeted) Metabolism Taxa involved in that particular metabolism Proteins involved in that particular metabolism Large scale datasets Mathematical model Relative entropy Informative Score MEBS ′ = log2 n 0 ≥1 ≤0 Informative Non-Informative MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 4 / 2 2
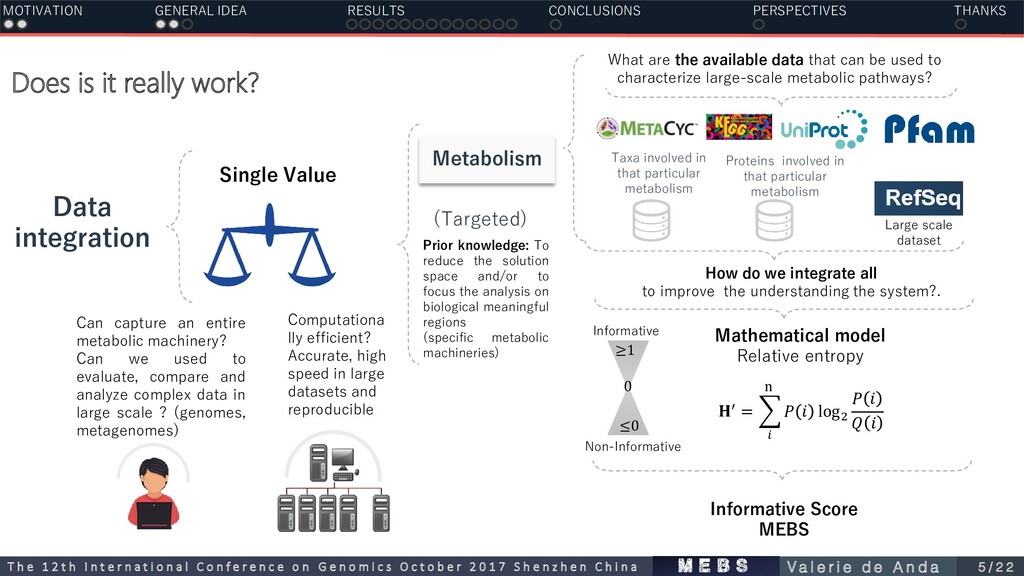
characterize large-scale metabolic pathways? How do we integrate all to improve the understanding the system?. C Prior knowledge: To reduce the solution space and/or to focus the analysis on biological meaningful regions (specific metabolic machineries) (Targeted) Metabolism Taxa involved in that particular metabolism Proteins involved in that particular metabolism Large scale dataset Mathematical model Relative entropy Informative Score MEBS ′ = log2 n 0 ≥1 ≤0 Informative Non-Informative Does is it really work? Can capture an entire metabolic machinery? Can we used to evaluate, compare and analyze complex data in large scale ? (genomes, metagenomes) Computationa lly efficient? Accurate, high speed in large datasets and reproducible Data integration Single Value MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 5 / 2 2
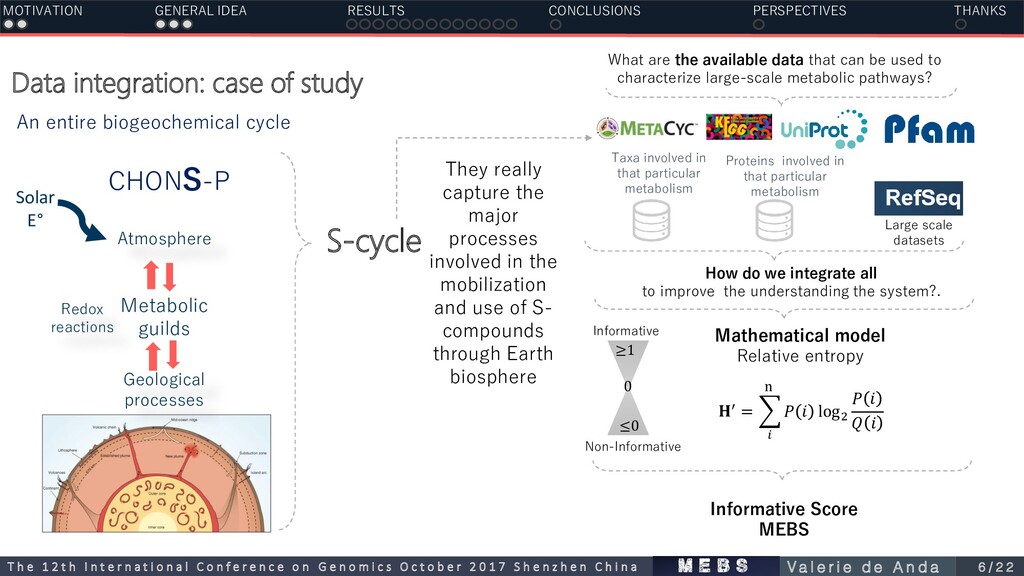
Metabolic guilds Geological processes An entire biogeochemical cycle S-cycle CHONS-P What are the available data that can be used to characterize large-scale metabolic pathways? How do we integrate all to improve the understanding the system?. Taxa involved in that particular metabolism Proteins involved in that particular metabolism Large scale datasets Mathematical model Relative entropy Informative Score MEBS ′ = log2 n 0 ≥1 ≤0 Informative Non-Informative They really capture the major processes involved in the mobilization and use of S- compounds through Earth biosphere MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 6 / 2 2
reconstruction of the S- metabolic machinery MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 7 / 2 2
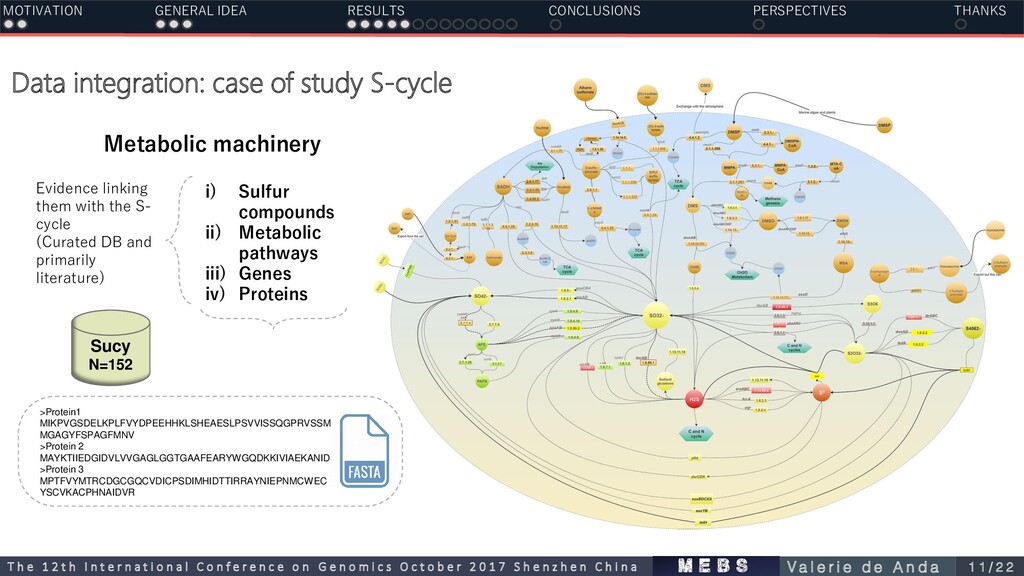
machinery i) CLSB: 24 genera ii) PSB: 25 genera iii) GSB: 9 genera iv) SRB: 40 genera v) SRM:19 genera vi) SO:4 genera Suli N=161 i) Sulfur compounds ii) Metabolic pathways iii) Genes iv) Proteins Complete nr sequenced S-genomes Sucy N=152 txt GCF_000006985.1 Chlorobium tepidum TLS GCF_000007005.1 Sulfolobus solfataricus P2 GCF_000007305.1 Pyrococcus furiosus DSM 3638 GCF_000008545.1 Thermotoga maritima MSB8 GCF_000008625.1 Aquifex aeolicus VF5 GCF_000008665.1 Archaeoglobus fulgidus DSM 4304 GCF_000009965.1 Thermococcus kodakarensis KOD1 >Protein1 MIKPVGSDELKPLFVYDPEEHHKLSHEAESLPSVVISSQGPRVSSM MGAGYFSPAGFMNV >Protein 2 MAYKTIIEDGIDVLVVGAGLGGTGAAFEARYWGQDKKIVIAEKANID >Protein 3 MPTFVYMTRCDGCGQCVDICPSDIMHIDTTIRRAYNIEPNMCWEC YSCVKACPHNAIDVR Evidence linking them with the S- cycle (Curated DB and primarily literature) Evidence suggesting their physiological and biochemical involvement in the use of sulfur compounds. MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 8 / 2 2
compounds ii) Metabolic pathways iii) Genes iv) Proteins Sucy N=152 >Protein1 MIKPVGSDELKPLFVYDPEEHHKLSHEAESLPSVVISSQGPRVSSM MGAGYFSPAGFMNV >Protein 2 MAYKTIIEDGIDVLVVGAGLGGTGAAFEARYWGQDKKIVIAEKANID >Protein 3 MPTFVYMTRCDGCGQCVDICPSDIMHIDTTIRRAYNIEPNMCWEC YSCVKACPHNAIDVR Evidence linking them with the S- cycle (Curated DB and primarily literature) MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 9 / 2 2
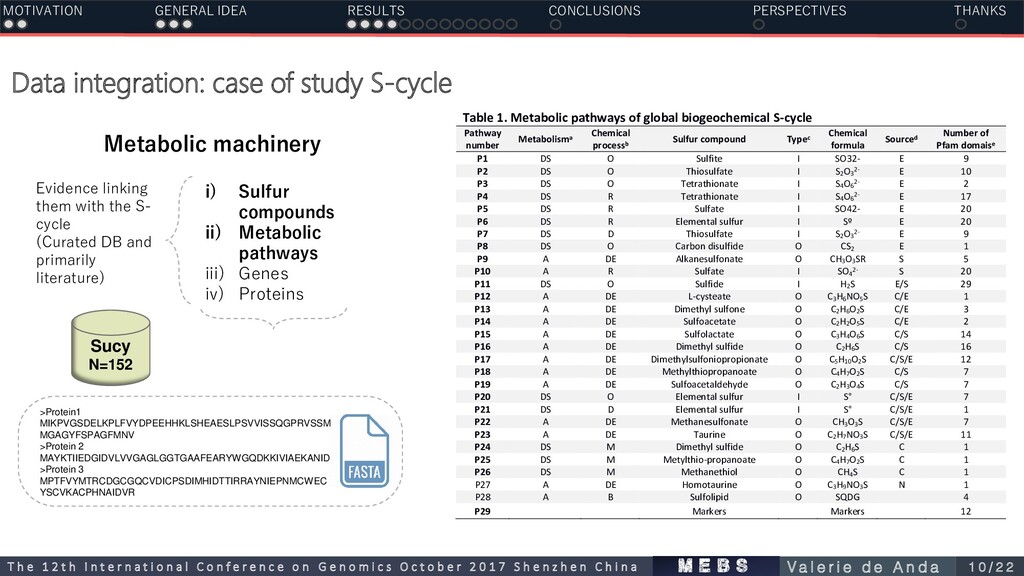
of global biogeochemical S-cycle Pathway number Metabolisma Chemical processb Sulfur compound Typec Chemical formula Sourced Number of Pfam domaise P1 DS O Sulfite I SO32- E 9 P2 DS O Thiosulfate I S2 O3 2- E 10 P3 DS O Tetrathionate I S4 O6 2- E 2 P4 DS R Tetrathionate I S4 O6 2- E 17 P5 DS R Sulfate I SO42- E 20 P6 DS R Elemental sulfur I Sº E 20 P7 DS D Thiosulfate I S2 O3 2- E 9 P8 DS O Carbon disulfide O CS2 E 1 P9 A DE Alkanesulfonate O CH3 O3 SR S 5 P10 A R Sulfate I SO4 2- S 20 P11 DS O Sulfide I H2 S E/S 29 P12 A DE L-cysteate O C3 H6 NO5 S C/E 1 P13 A DE Dimethyl sulfone O C2 H6 O2 S C/E 3 P14 A DE Sulfoacetate O C2 H2 O5 S C/E 2 P15 A DE Sulfolactate O C3 H4 O6 S C/S 14 P16 A DE Dimethyl sulfide O C2 H6 S C/S 16 P17 A DE Dimethylsulfoniopropionate O C5 H10 O2 S C/S/E 12 P18 A DE Methylthiopropanoate O C4 H7 O2 S C/S 7 P19 A DE Sulfoacetaldehyde O C2 H3 O4 S C/S 7 P20 DS O Elemental sulfur I S° C/S/E 7 P21 DS D Elemental sulfur I S° C/S/E 1 P22 A DE Methanesulfonate O CH3 O3 S C/S/E 7 P23 A DE Taurine O C2 H7 NO3 S C/S/E 11 P24 DS M Dimethyl sulfide O C2 H6 S C 1 P25 DS M Metylthio-propanoate O C4 H7 O2 S C 1 P26 DS M Methanethiol O CH4 S C 1 P27 A DE Homotaurine O C3 H9 NO3 S N 1 P28 A B Sulfolipid O SQDG 4 P29 Markers Markers 12 1 Metabolic machinery i) Sulfur compounds ii) Metabolic pathways iii) Genes iv) Proteins Sucy N=152 >Protein1 MIKPVGSDELKPLFVYDPEEHHKLSHEAESLPSVVISSQGPRVSSM MGAGYFSPAGFMNV >Protein 2 MAYKTIIEDGIDVLVVGAGLGGTGAAFEARYWGQDKKIVIAEKANID >Protein 3 MPTFVYMTRCDGCGQCVDICPSDIMHIDTTIRRAYNIEPNMCWEC YSCVKACPHNAIDVR Evidence linking them with the S- cycle (Curated DB and primarily literature) MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 0 / 2 2
compounds ii) Metabolic pathways iii) Genes iv) Proteins Sucy N=152 >Protein1 MIKPVGSDELKPLFVYDPEEHHKLSHEAESLPSVVISSQGPRVSSM MGAGYFSPAGFMNV >Protein 2 MAYKTIIEDGIDVLVVGAGLGGTGAAFEARYWGQDKKIVIAEKANID >Protein 3 MPTFVYMTRCDGCGQCVDICPSDIMHIDTTIRRAYNIEPNMCWEC YSCVKACPHNAIDVR Evidence linking them with the S- cycle (Curated DB and primarily literature) MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 1 / 2 2
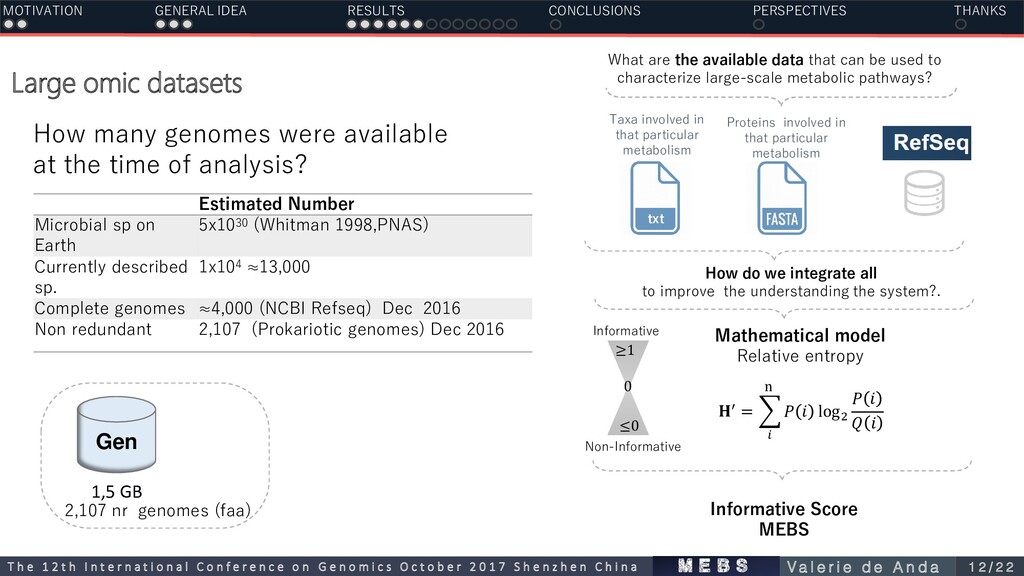
be used to characterize large-scale metabolic pathways? How do we integrate all to improve the understanding the system?. Mathematical model Relative entropy Informative Score MEBS ′ = log2 n 0 ≥1 ≤0 Informative Non-Informative Taxa involved in that particular metabolism Proteins involved in that particular metabolism txt 2,107 nr genomes (faa) Gen 1,5 GB Estimated Number Microbial sp on Earth 5x1030 (Whitman 1998,PNAS) Currently described sp. 1x104 ≈13,000 Complete genomes ≈4,000 (NCBI Refseq) Dec 2016 Non redundant 2,107 (Prokariotic genomes) Dec 2016 How many genomes were available at the time of analysis? MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 2 / 2 2
be used to characterize large-scale metabolic pathways? How do we integrate all to improve the understanding the system?. Mathematical model Relative entropy Informative Score MEBS ′ = log2 n 0 ≥1 ≤0 Informative Non-Informative Taxa: Suli Proteins: Sucy txt 2,107 nr genomes (faa) Gen Met GenF 104GB ≈ 500 GB 1,5 GB How many metagenomes were available at the time of analysis? i) were publicly available ii) contained associated metadata iii) had been isolated from well-defined environments (i.e., rivers, soil, biofilms) iv) discarding host associated microbiome sequences (i.e., human, cow, chicken) MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 3 / 2 2
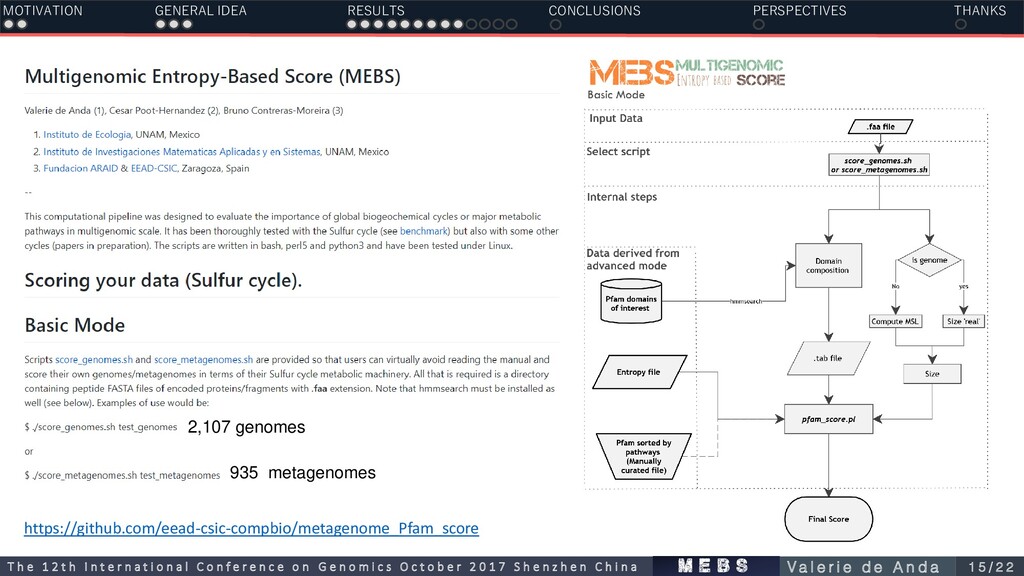
Sulfolobus solfataricus P2 GCF_000007305.1 Pyrococcus furiosus DSM 3638 GCF_000008545.1 Thermotoga maritima MSB8 GCF_000008625.1 Aquifex aeolicus VF5 GCF_000008665.1 Archaeoglobus fulgidus DSM 4304 GCF_000009965.1 Thermococcus kodakarensis KOD1 >Protein1 MIKPVGSDELKPLFVYDPEEHHKLSHEAESLPSVVISSQGPRVSSM MGAGYFSPAGFMNV >Protein 2 MAYKTIIEDGIDVLVVGAGLGGTGAAFEARYWGQDKKIVIAEKANID >Protein 3 MPTFVYMTRCDGCGQCVDICPSDIMHIDTTIRRAYNIEPNMCWEC YSCVKACPHNAIDVR 2,107 nr genomes (faa) Gen GenF Stage 1: Manual curation and omic datasets Stage 2: Domain composition Stage 4: Informative Score Can capture the S- metabolic machinery? Can we used to evaluate, compare and analyze complex data in large scale ? (genomes, metagenomes) Computationally efficient? Accurate, high speed in large datasets and reproducible Single Value Mathematical model ′ = log2 () () n ≥1 Informative Non-Informative Stage 3: Relative Entropy Domains enriched among the microorganisms of interest = frequency of protein domain i in S genomes (161) Q = frequency of protein domain i in Gen (2,107) 0 ≤0 Taxa: Suli Proteins: Sucy MEBS: GENERAL OVERVIEW MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 4 / 2 2
PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 5 / 2 2
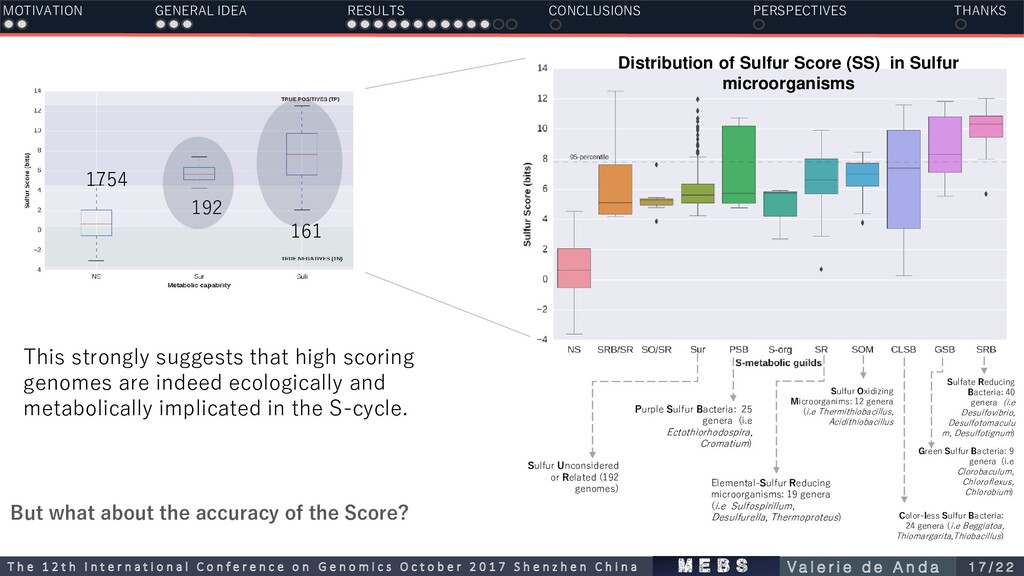
smoker chimney archaeon Geoglobus ahangari, sampled from a 2,000m depth hydrothermal vent . 192 Distribution of Sulfur Score (SS) in 2,107 nr-genomes 161 1754 Sur N=192 Suli N=161 SS≥4 Candidatus Desulforudis audaxviator MP104C Metagenomic reconstructions hard-to culture taxa Manually curated databases Sur N=192 » » » MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 6 / 2 2
and metabolically implicated in the S-cycle. 192 161 1754 Distribution of Sulfur Score (SS) in Sulfur microorganisms Color-less Sulfur Bacteria: 24 genera (i.e Beggiatoa, Thiomargarita,Thiobacillus) Purple Sulfur Bacteria: 25 genera (i.e Ectothiorhodospira, Cromatium) Sulfate Reducing Bacteria: 40 genera (i.e Desulfovibrio, Desulfotomaculu m, Desulfotignum) Green Sulfur Bacteria: 9 genera (i.e Clorobaculum, Chloroflexus, Chlorobium) Sulfur Oxidizing Microorganims: 12 genera (i.e Thermithiobacillus, Acidithiobacillus Elemental-Sulfur Reducing microorganisms: 19 genera (i.e Sulfospirillum, Desulfurella, Thermoproteus) Sulfur Unconsidered or Related (192 genomes) But what about the accuracy of the Score? MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 7 / 2 2
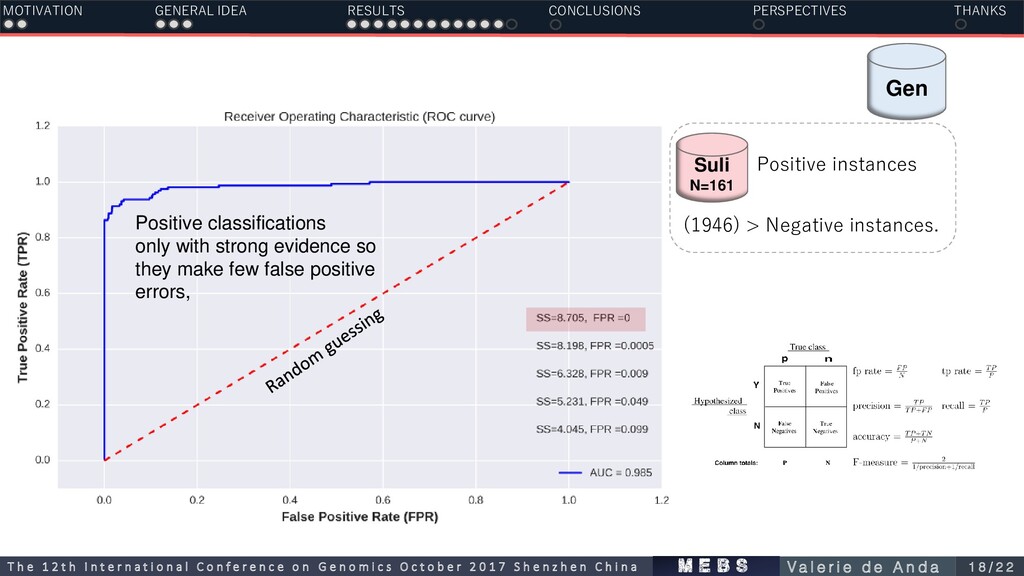
make few false positive errors, MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 8 / 2 2 Suli N=161 (1946) > Negative instances. Gen
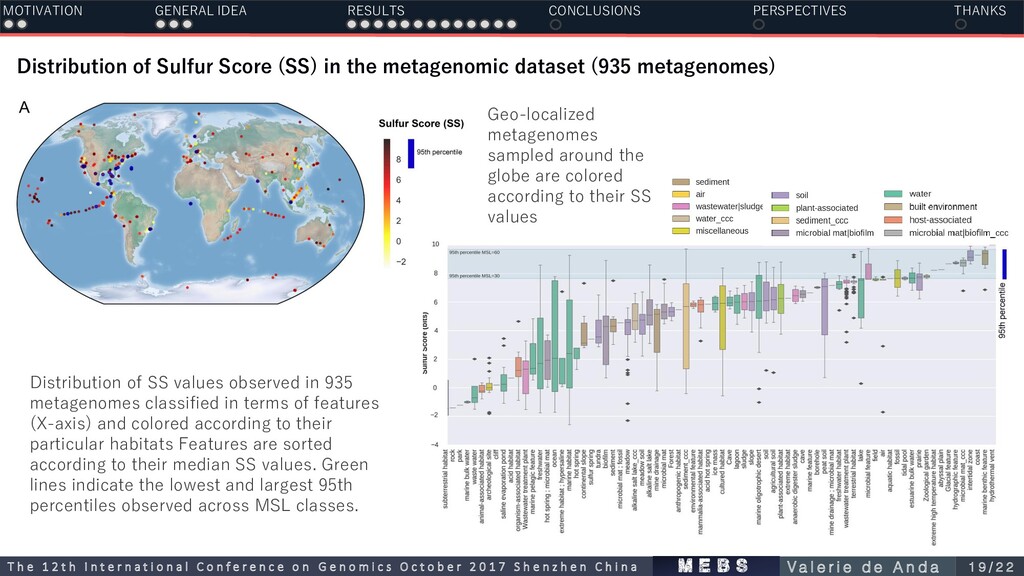
metagenomes) MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS Distribution of SS values observed in 935 metagenomes classified in terms of features (X-axis) and colored according to their particular habitats Features are sorted according to their median SS values. Green lines indicate the lowest and largest 95th percentiles observed across MSL classes. Geo-localized metagenomes sampled around the globe are colored according to their SS values m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 9 / 2 2
Markers Comp MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS C Conclusions » We present MEBS a new open source software to evaluate, quantify, compare, and predict the metabolic machinery of interest in large ‘omic’ datasets using one single value » To test the applicability of this approach, we evaluated one of the most complex biogeochemical cycles the sulfur cycle. » Using data integration and manual curation we reconstructed the entire sulfur machinery: Suli and Sucy » We prove that the use of the mathematical framework of the relative entropy can be used to capture complex metabolic machineries in large scale omic samples. » MEBS powerful and broadly applicable approach to predict, and classify microorganisms closely involved in the sulfur cycle even in hard-to culture microbial lineages » Computationally efficient, accurate (AUC0985) and reproducible. » Not in the presentation: the entropy can be used to detect marker domains and the completeness of the S-cycle pathways can be benchmarked in large scale m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 2 0 / 2 2 MEBS
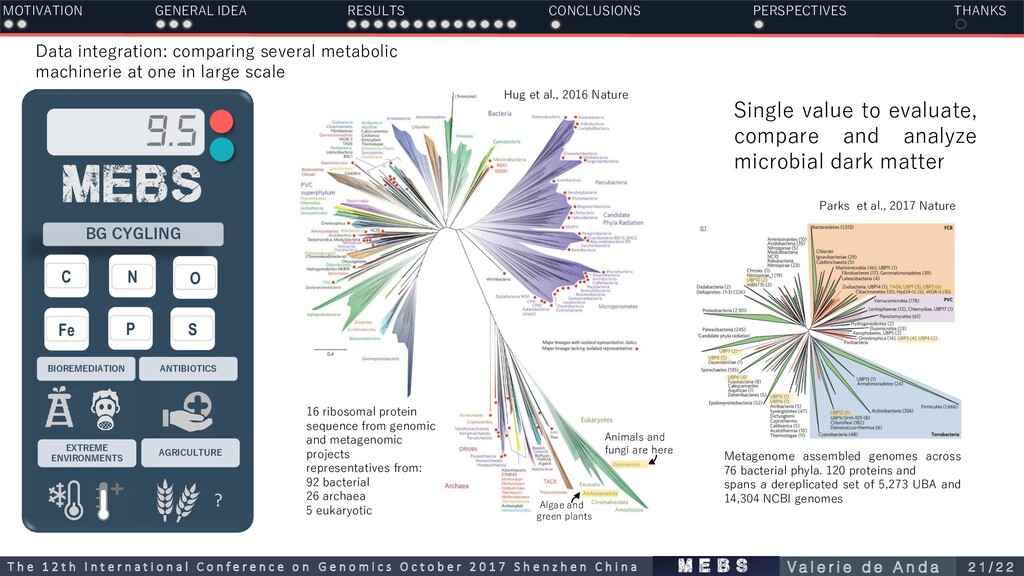
s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 2 1 / 2 2 mebs BG CYGLING 9.5 C N O S Fe P BIOREMEDIATION ANTIBIOTICS EXTREME ENVIRONMENTS AGRICULTURE ? Data integration: comparing several metabolic machinerie at one in large scale Animals and fungi are here Algae and green plants Hug et al., 2016 Nature 16 ribosomal protein sequence from genomic and metagenomic projects representatives from: 92 bacterial 26 archaea 5 eukaryotic Metagenome assembled genomes across 76 bacterial phyla. 120 proteins and spans a dereplicated set of 5,273 UBA and 14,304 NCBI genomes Parks et al., 2017 Nature Single value to evaluate, compare and analyze microbial dark matter
et al., 2017 MEBS, a software platform to evaluate large (meta)genomic collections according to their metabolic machinery: unraveling the sulfur cycle GigaScience in press Cesar-Poot Hernandez MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 2 2 / 2 2
O F M O L E C U L A R A N D E X P E R I M E N T A L E V O L U T I O N E C O L O G Y I N S T I T U T E U N A M M E X I C O 23 L A B O R A T O R Y O F C O M P U T A T I O N A L B I O L O G Y MOTIVATION GENERAL IDEA RESULTS CONCLUSIONS PERSPECTIVES THANKS
2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a 1 / 1 2
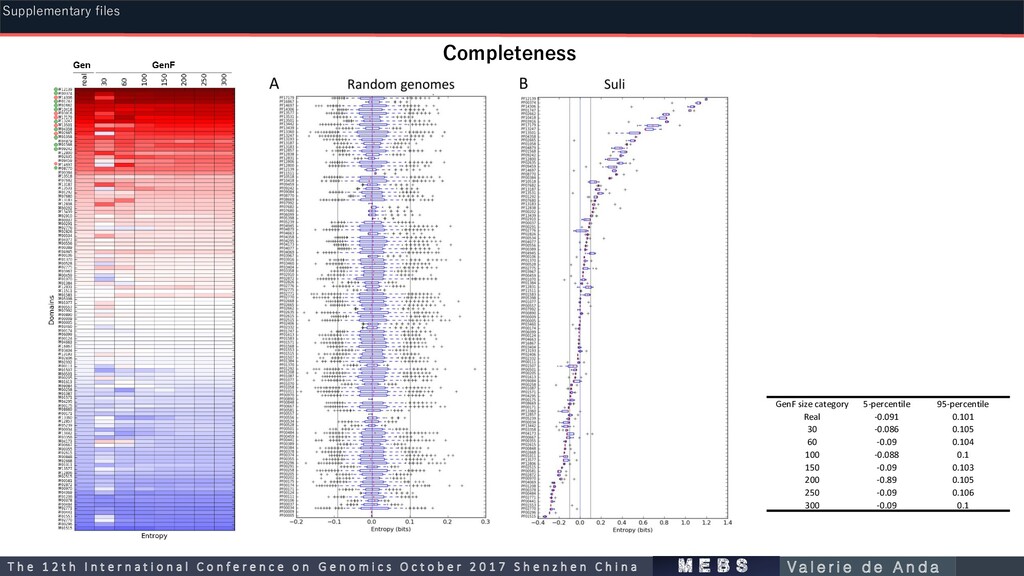
caldus A. ferrivorans T. mobilis D. aromatica T. hauera sp. T. humireducens A. denitrificans S. tokodaii A. hospitalis (among other 12 genomes) P. phaeoclathratiforme C. chlorochromatii C. tepidum T. denitrificans T. violascens S. thiotaurini Completeness Supplementary files m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a
Metabolisma Chemical processb Sulfur compound Typec Chemical formula Sourced Number of Pfam domaise P1 DS O Sulfite I SO32- E 9 P2 DS O Thiosulfate I S2 O3 2- E 10 P3 DS O Tetrathionate I S4 O6 2- E 2 P4 DS R Tetrathionate I S4 O6 2- E 17 P5 DS R Sulfate I SO42- E 20 P6 DS R Elemental sulfur I Sº E 20 P7 DS D Thiosulfate I S2 O3 2- E 9 P8 DS O Carbon disulfide O CS2 E 1 P9 A DE Alkanesulfonate O CH3 O3 SR S 5 P10 A R Sulfate I SO4 2- S 20 P11 DS O Sulfide I H2 S E/S 29 P12 A DE L-cysteate O C3 H6 NO5 S C/E 1 P13 A DE Dimethyl sulfone O C2 H6 O2 S C/E 3 P14 A DE Sulfoacetate O C2 H2 O5 S C/E 2 P15 A DE Sulfolactate O C3 H4 O6 S C/S 14 P16 A DE Dimethyl sulfide O C2 H6 S C/S 16 P17 A DE Dimethylsulfoniopropionate O C5 H10 O2 S C/S/E 12 P18 A DE Methylthiopropanoate O C4 H7 O2 S C/S 7 P19 A DE Sulfoacetaldehyde O C2 H3 O4 S C/S 7 P20 DS O Elemental sulfur I S° C/S/E 7 P21 DS D Elemental sulfur I S° C/S/E 1 P22 A DE Methanesulfonate O CH3 O3 S C/S/E 7 P23 A DE Taurine O C2 H7 NO3 S C/S/E 11 P24 DS M Dimethyl sulfide O C2 H6 S C 1 P25 DS M Metylthio-propanoate O C4 H7 O2 S C 1 P26 DS M Methanethiol O CH4 S C 1 P27 A DE Homotaurine O C3 H9 NO3 S N 1 P28 A B Sulfolipid O SQDG 4 P29 Markers Markers 12 1 The protein domains currently present in any given sample are divided by the total number of domains in the pre-defined pathway Completeness Supplementary files m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a
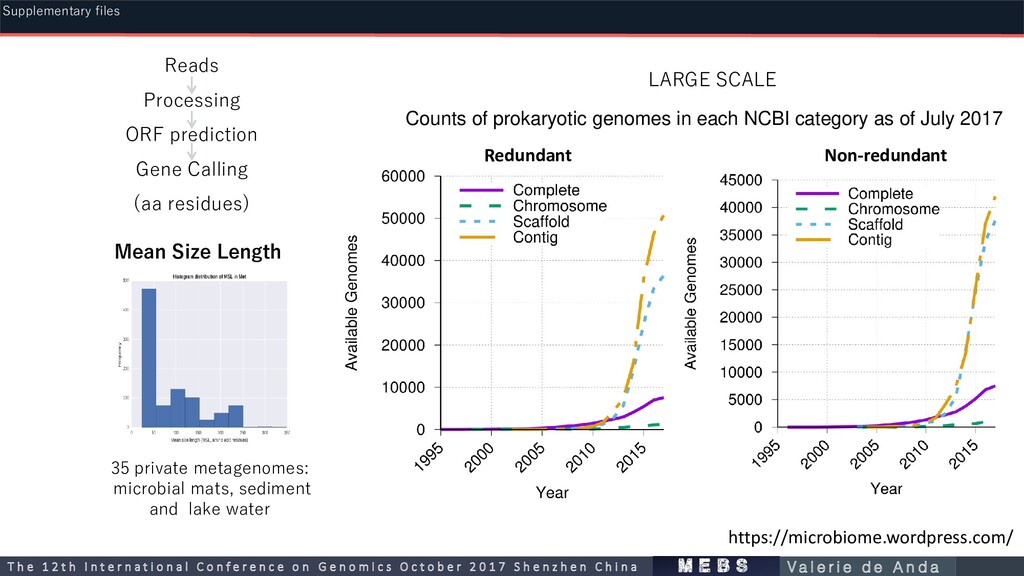
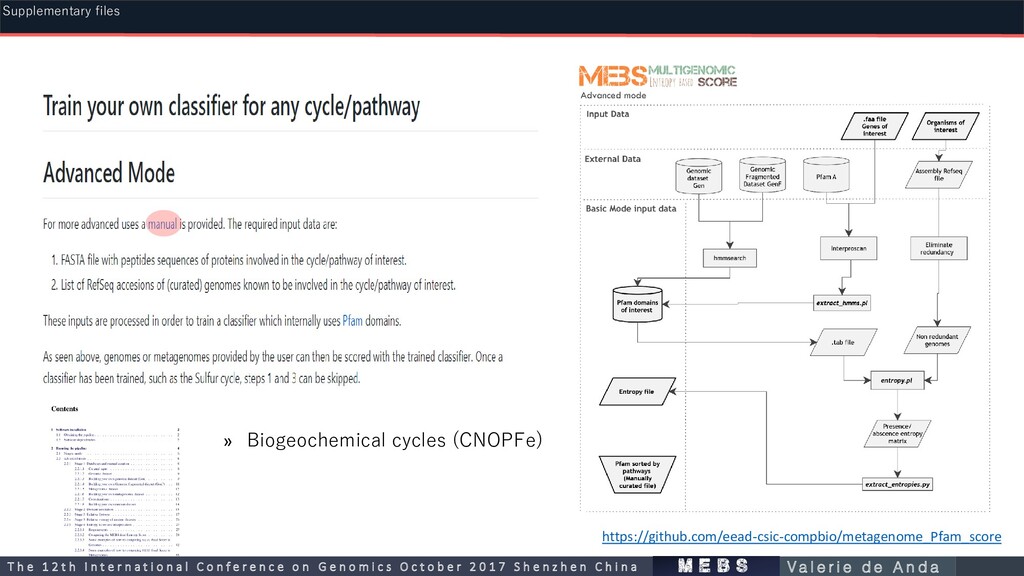
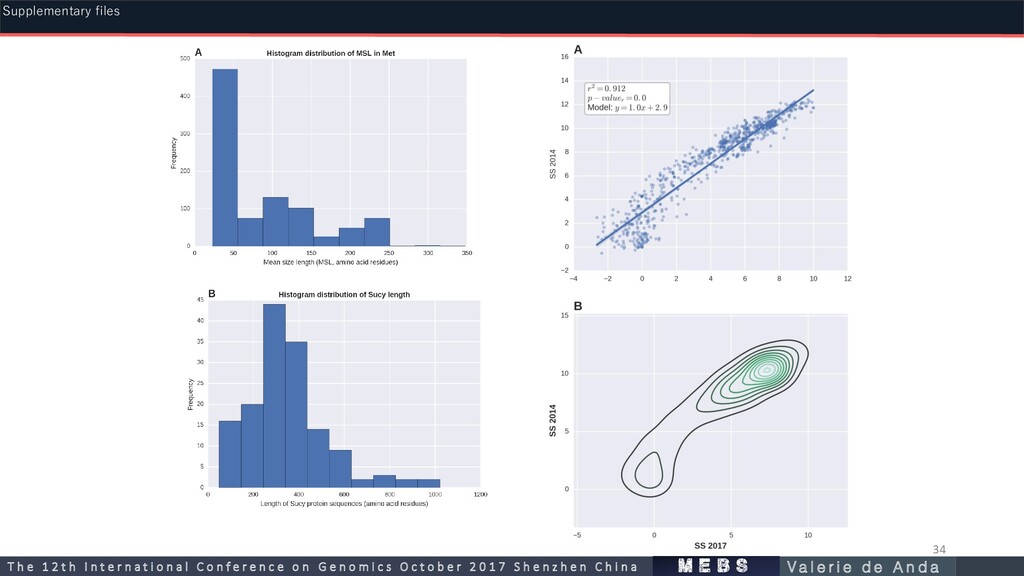
Processing ORF prediction Gene Calling (aa residues) Mean Size Length https://microbiome.wordpress.com/ Counts of prokaryotic genomes in each NCBI category as of July 2017 Non-redundant Redundant LARGE SCALE m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
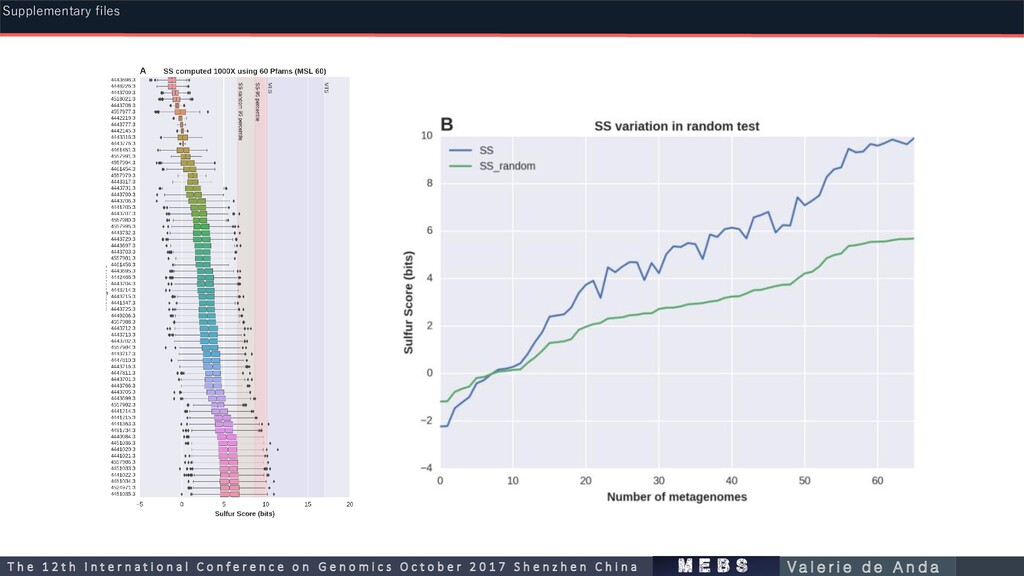
0.105 60 -0.09 0.104 100 -0.088 0.1 150 -0.09 0.103 200 -0.89 0.105 250 -0.09 0.106 300 -0.09 0.1 Completeness Supplementary files m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a
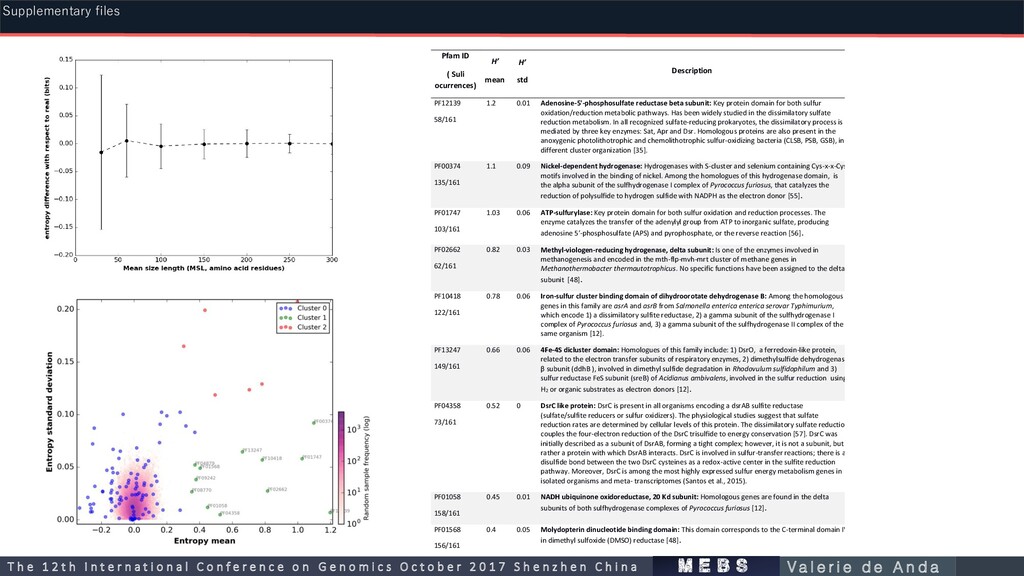
std. Novel proposed molecular marker domains in metagenomic data of variable MSL Pfam ID ( Suli ocurrences) H’ mean H’ std Description PF12139 58/161 1.2 0.01 Adenosine-5'-phosphosulfate reductase beta subunit: Key protein domain for both sulfur oxidation/reduction metabolic pathways. Has been widely studied in the dissimilatory sulfate reduction metabolism. In all recognized sulfate-reducing prokaryotes, the dissimilatory process is mediated by three key enzymes: Sat, Apr and Dsr. Homologous proteins are also present in the anoxygenic photolithotrophic and chemolithotrophic sulfur-oxidizing bacteria (CLSB, PSB, GSB), in different cluster organization [35]. PF00374 135/161 1.1 0.09 Nickel-dependent hydrogenase: Hydrogenases with S-cluster and selenium containing Cys-x-x-Cys motifs involved in the binding of nickel. Among the homologues of this hydrogenase domain, is the alpha subunit of the sulfhydrogenase I complex of Pyrococcus furiosus, that catalyzes the reduction of polysulfide to hydrogen sulfide with NADPH as the electron donor [55]. PF01747 103/161 1.03 0.06 ATP-sulfurylase: Key protein domain for both sulfur oxidation and reduction processes. The enzyme catalyzes the transfer of the adenylyl group from ATP to inorganic sulfate, producing adenosine 5′-phosphosulfate (APS) and pyrophosphate, or the reverse reaction [56]. PF02662 62/161 0.82 0.03 Methyl-viologen-reducing hydrogenase, delta subunit: Is one of the enzymes involved in methanogenesis and encoded in the mth-flp-mvh-mrt cluster of methane genes in Methanothermobacter thermautotrophicus. No specific functions have been assigned to the delta subunit [48]. PF10418 122/161 0.78 0.06 Iron-sulfur cluster binding domain of dihydroorotate dehydrogenase B: Among the homologous genes in this family are asrA and asrB from Salmonella enterica enterica serovar Typhimurium, which encode 1) a dissimilatory sulfite reductase, 2) a gamma subunit of the sulfhydrogenase I complex of Pyrococcus furiosus and, 3) a gamma subunit of the sulfhydrogenase II complex of the same organism [12]. PF13247 149/161 0.66 0.06 4Fe-4S dicluster domain: Homologues of this family include: 1) DsrO, a ferredoxin-like protein, related to the electron transfer subunits of respiratory enzymes, 2) dimethylsulfide dehydrogenase β subunit (ddhB ), involved in dimethyl sulfide degradation in Rhodovulum sulfidophilum and 3) sulfur reductase FeS subunit (sreB) of Acidianus ambivalens, involved in the sulfur reduction using H2 or organic substrates as electron donors [12]. PF04358 73/161 0.52 0 DsrC like protein: DsrC is present in all organisms encoding a dsrAB sulfite reductase (sulfate/sulfite reducers or sulfur oxidizers). The physiological studies suggest that sulfate reduction rates are determined by cellular levels of this protein. The dissimilatory sulfate reduction couples the four-electron reduction of the DsrC trisulfide to energy conservation [57]. DsrC was initially described as a subunit of DsrAB, forming a tight complex; however, it is not a subunit, but rather a protein with which DsrAB interacts. DsrC is involved in sulfur-transfer reactions; there is a disulfide bond between the two DsrC cysteines as a redox-active center in the sulfite reduction pathway. Moreover, DsrC is among the most highly expressed sulfur energy metabolism genes in isolated organisms and meta- transcriptomes (Santos et al., 2015). PF01058 158/161 0.45 0.01 NADH ubiquinone oxidoreductase, 20 Kd subunit: Homologous genes are found in the delta subunits of both sulfhydrogenase complexes of Pyrococcus furiosus [12]. PF01568 156/161 0.4 0.05 Molydopterin dinucleotide binding domain: This domain corresponds to the C-terminal domain IV in dimethyl sulfoxide (DMSO) reductase [48]. Supplementary files m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a
b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
SRB/SR Archaeoglobus profundus DSM 5631 12,024 Archaeoglobus SRB Candidatus Desulforudis audaxviator MP104C 11,972 Candidatus Desulforudis Sur Pelodictyon phaeoclathratiforme BU-1 11,836 Chlorobium/Pelodictyon group GSB Chlorobium phaeobacteroides BS1 11,649 Chlorobium/Pelodictyon group GSB Chlorobium chlorochromatii CaD3 11,625 Chlorobium/Pelodictyon group GSB Thiobacillus denitrificans ATCC 25259 11,61 Thiobacillus CLSB Desulfohalobium retbaense DSM 5692 11,511 Desulfohalobium SRB Desulfovibrio alaskensis G20 11,5 Desulfovibrio SRB Desulfovibrio vulgaris DP4 11,442 Desulfovibrio SRB Chlorobium tepidum TLS 11,354 Chlorobaculum GSB endosymbiont of unidentified scaly snail isolate Monju 11,205 0 Sur Desulfovibrio vulgaris str. 'Miyazaki F' 11,093 Desulfovibrio SRB Desulfovibrio desulfuricans subsp. desulfuricans str. ATCC 27774 11,034 Desulfovibrio SRB m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
H’ m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files Iron: 112 H’
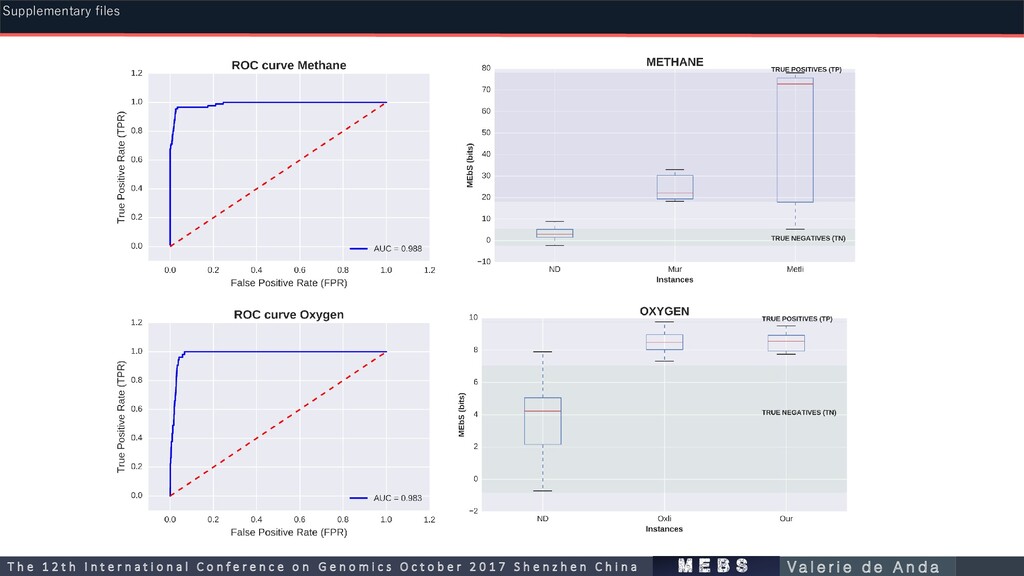
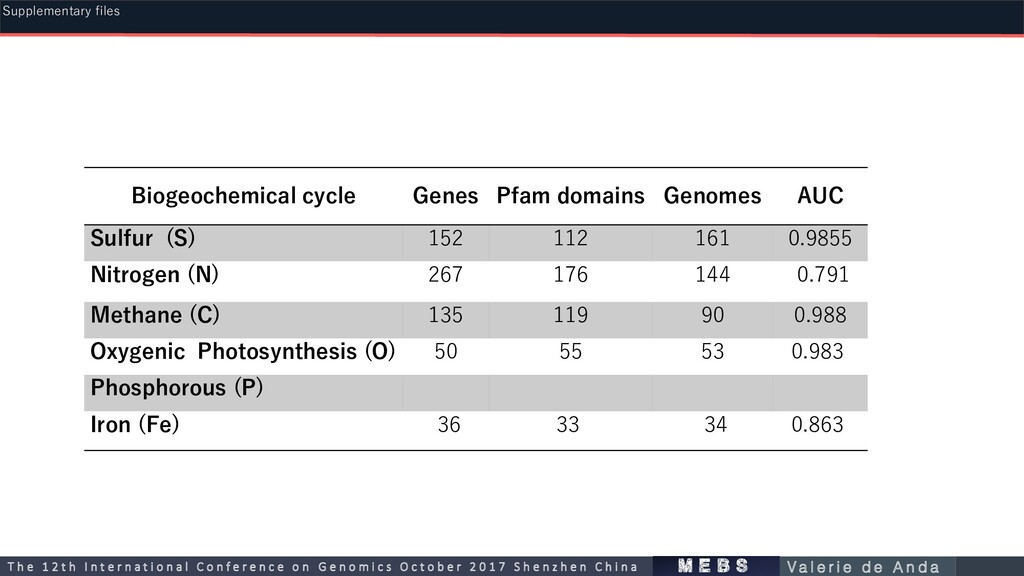
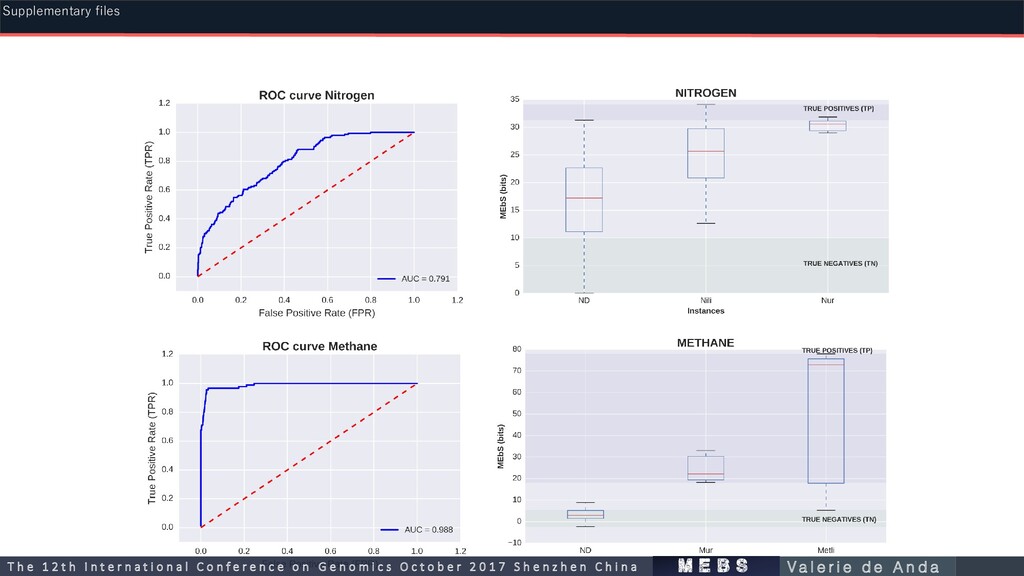
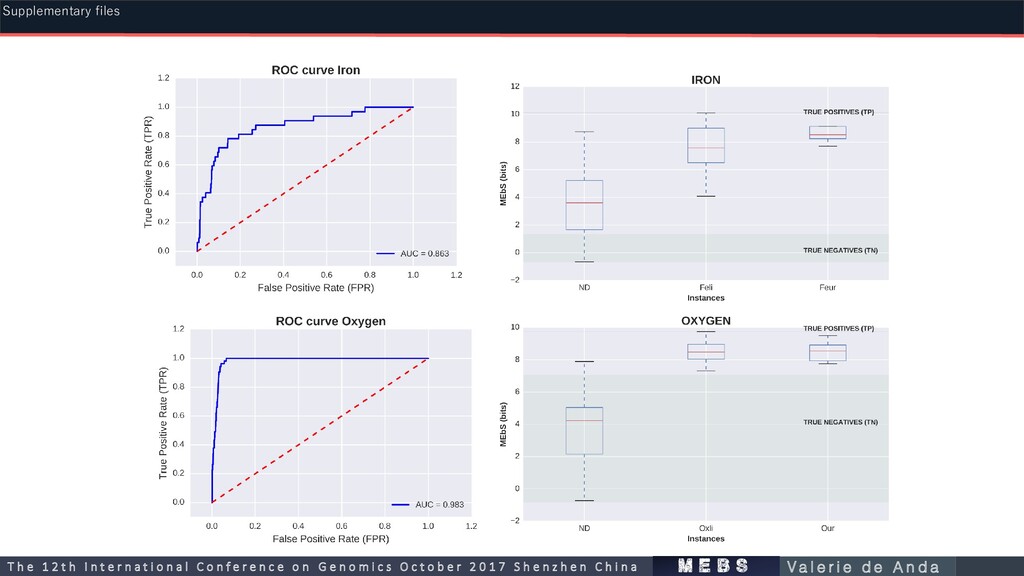
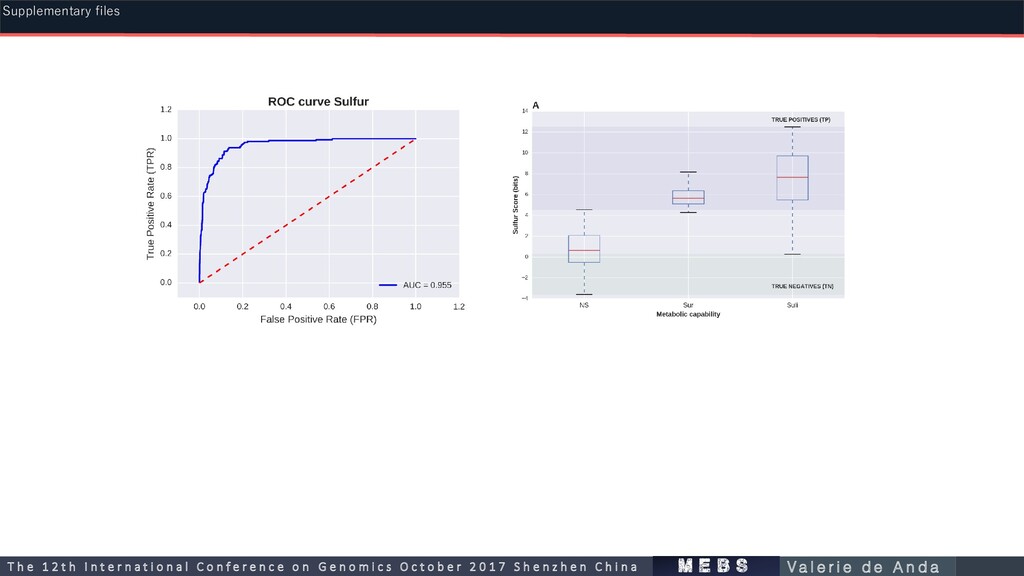
112 161 0.9855 Nitrogen (N) 267 176 144 0.791 Methane (C) 135 119 90 0.988 Oxygenic Photosynthesis (O) 50 55 53 0.983 Phosphorous (P) Iron (Fe) 36 33 34 0.863 m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
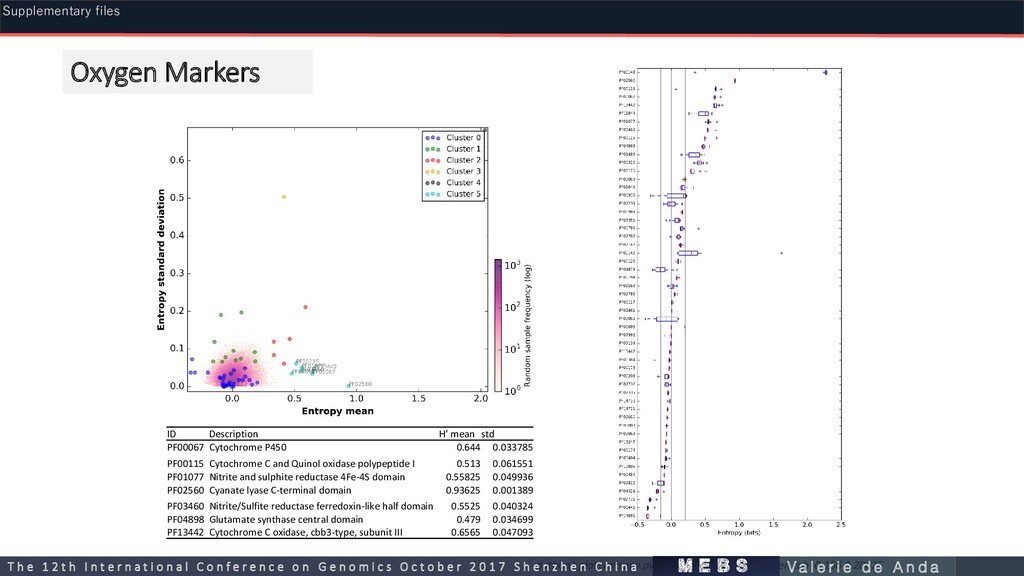
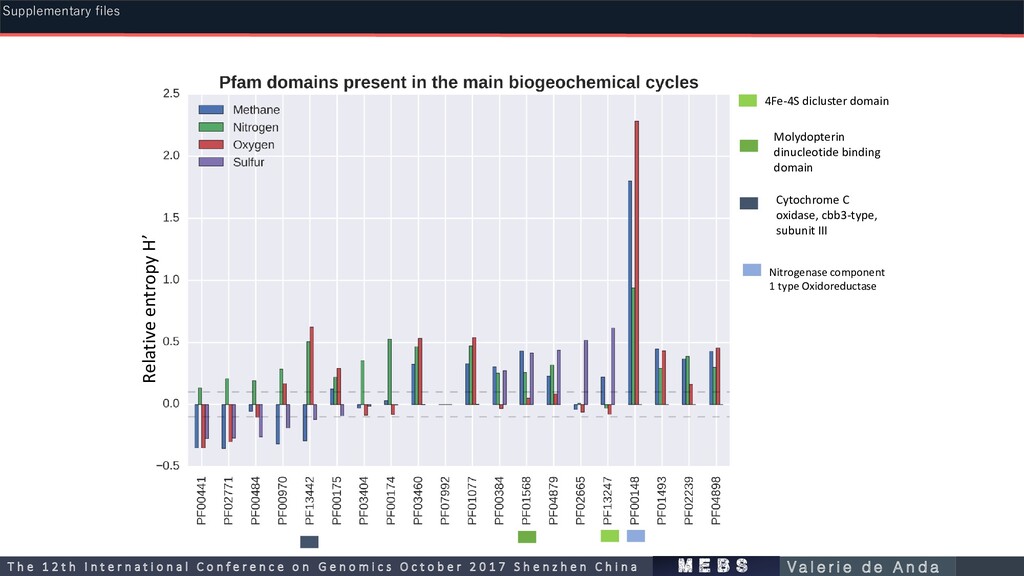
PF00115 Cytochrome C and Quinol oxidase polypeptide I 0.513 0.061551 PF01077 Nitrite and sulphite reductase 4Fe-4S domain 0.55825 0.049936 PF02560 Cyanate lyase C-terminal domain 0.93625 0.001389 PF03460 Nitrite/Sulfite reductase ferredoxin-like half domain 0.5525 0.040324 PF04898 Glutamate synthase central domain 0.479 0.034699 PF13442 Cytochrome C oxidase, cbb3-type, subunit III 0.6565 0.047093 python3 plot_entropy.py gen_genF_entropies.oxygen.tab -0.156 0.20625 Oxygen Markers m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
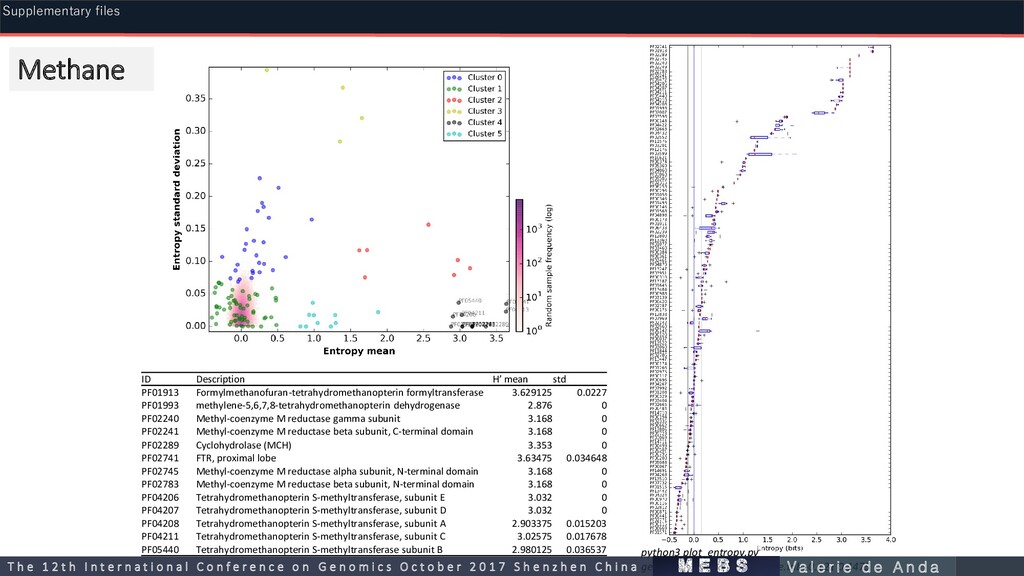
PF01993 methylene-5,6,7,8-tetrahydromethanopterin dehydrogenase 2.876 0 PF02240 Methyl-coenzyme M reductase gamma subunit 3.168 0 PF02241 Methyl-coenzyme M reductase beta subunit, C-terminal domain 3.168 0 PF02289 Cyclohydrolase (MCH) 3.353 0 PF02741 FTR, proximal lobe 3.63475 0.034648 PF02745 Methyl-coenzyme M reductase alpha subunit, N-terminal domain 3.168 0 PF02783 Methyl-coenzyme M reductase beta subunit, N-terminal domain 3.168 0 PF04206 Tetrahydromethanopterin S-methyltransferase, subunit E 3.032 0 PF04207 Tetrahydromethanopterin S-methyltransferase, subunit D 3.032 0 PF04208 Tetrahydromethanopterin S-methyltransferase, subunit A 2.903375 0.015203 PF04211 Tetrahydromethanopterin S-methyltransferase, subunit C 3.02575 0.017678 PF05440 Tetrahydromethanopterin S-methyltransferase subunit B 2.980125 0.036537 python3 plot_entropy.py gen_genF_entropies.methane.tab -0.121 0.1475 m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files Methane
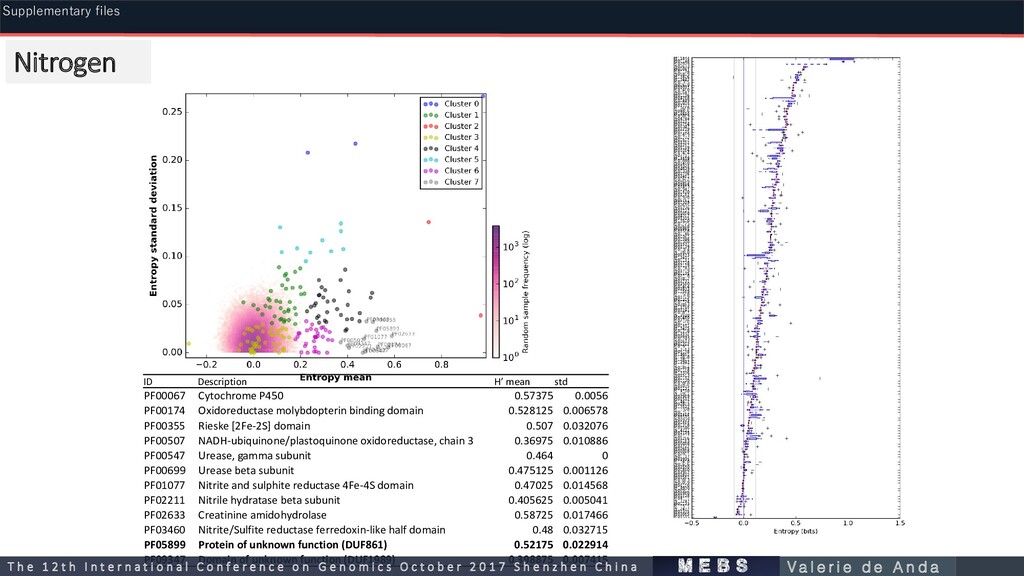
PF00174 Oxidoreductase molybdopterin binding domain 0.528125 0.006578 PF00355 Rieske [2Fe-2S] domain 0.507 0.032076 PF00507 NADH-ubiquinone/plastoquinone oxidoreductase, chain 3 0.36975 0.010886 PF00547 Urease, gamma subunit 0.464 0 PF00699 Urease beta subunit 0.475125 0.001126 PF01077 Nitrite and sulphite reductase 4Fe-4S domain 0.47025 0.014568 PF02211 Nitrile hydratase beta subunit 0.405625 0.005041 PF02633 Creatinine amidohydrolase 0.58725 0.017466 PF03460 Nitrite/Sulfite reductase ferredoxin-like half domain 0.48 0.032715 PF05899 Protein of unknown function (DUF861) 0.52175 0.022914 PF09347 Domain of unknown function (DUF1989) 0.398875 0.007415 Nitrogen m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
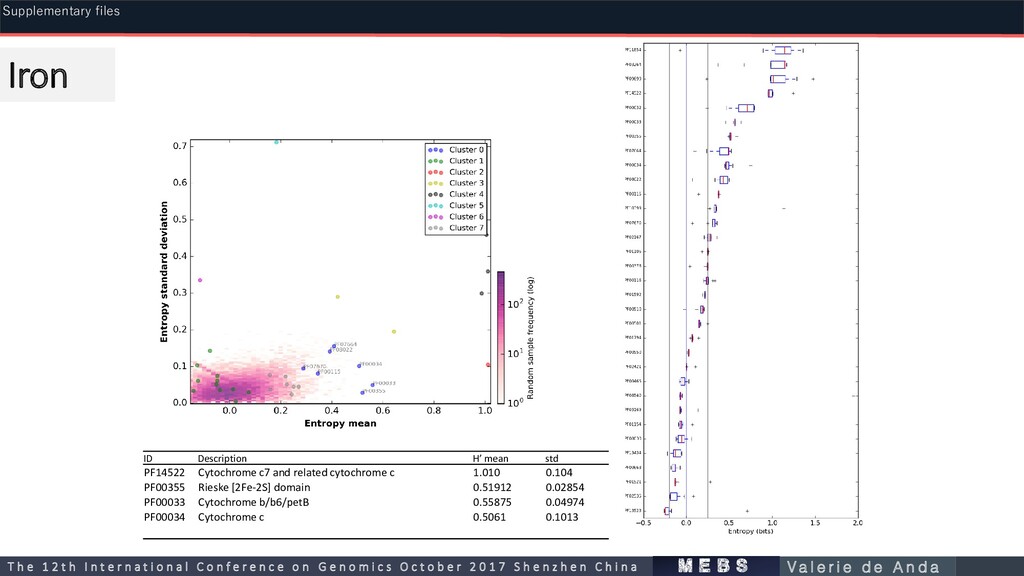
related cytochrome c 1.010 0.104 PF00355 Rieske [2Fe-2S] domain 0.51912 0.02854 PF00033 Cytochrome b/b6/petB 0.55875 0.04974 PF00034 Cytochrome c 0.5061 0.1013 m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
Cytochrome C oxidase, cbb3-type, subunit III Nitrogenase component 1 type Oxidoreductase m e b s T h e 1 2 t h I n t e r n a t i o n a l C o n f e r e n c e o n G e n o m i c s O c t o b e r 2 0 1 7 S h e n z h e n C h i n a V a l e r i e d e A n d a Supplementary files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}