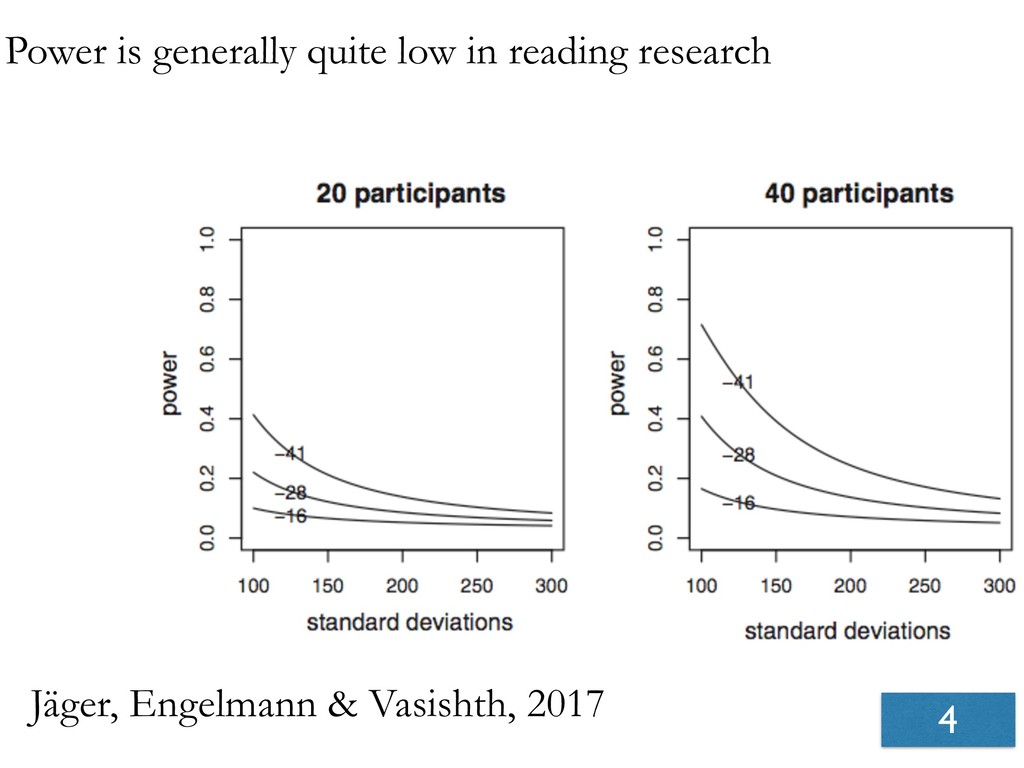
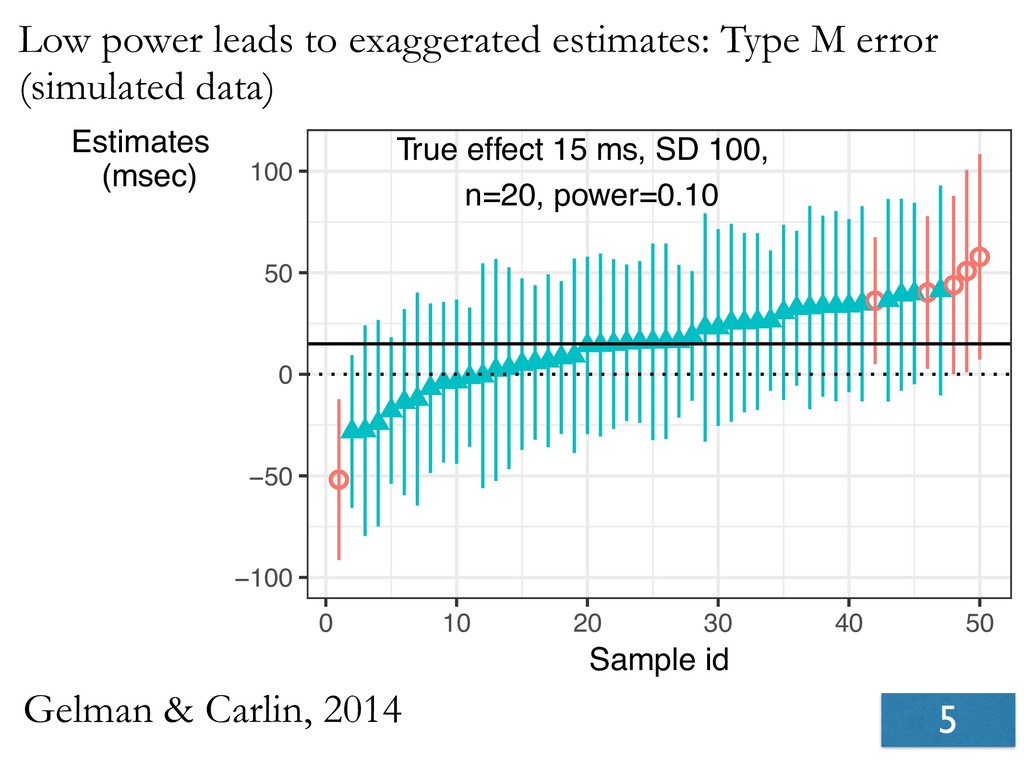
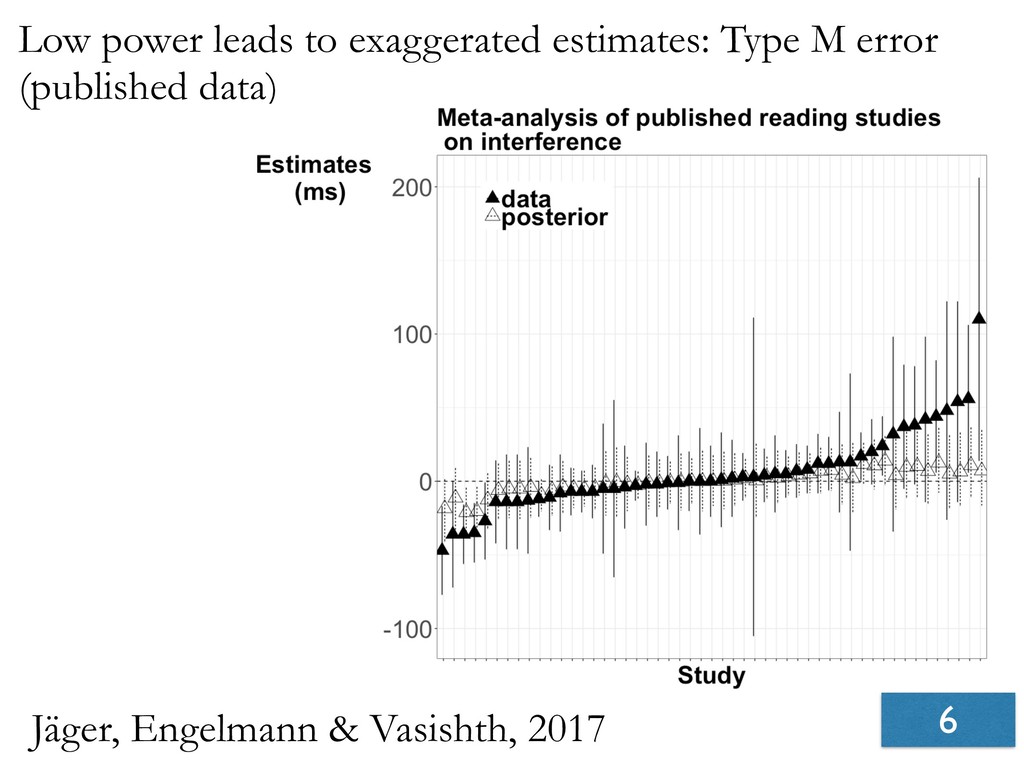
- When low-powered studies show significant effects, these will be overestimates.
- Significant effects from low-powered studies will not be replicable.
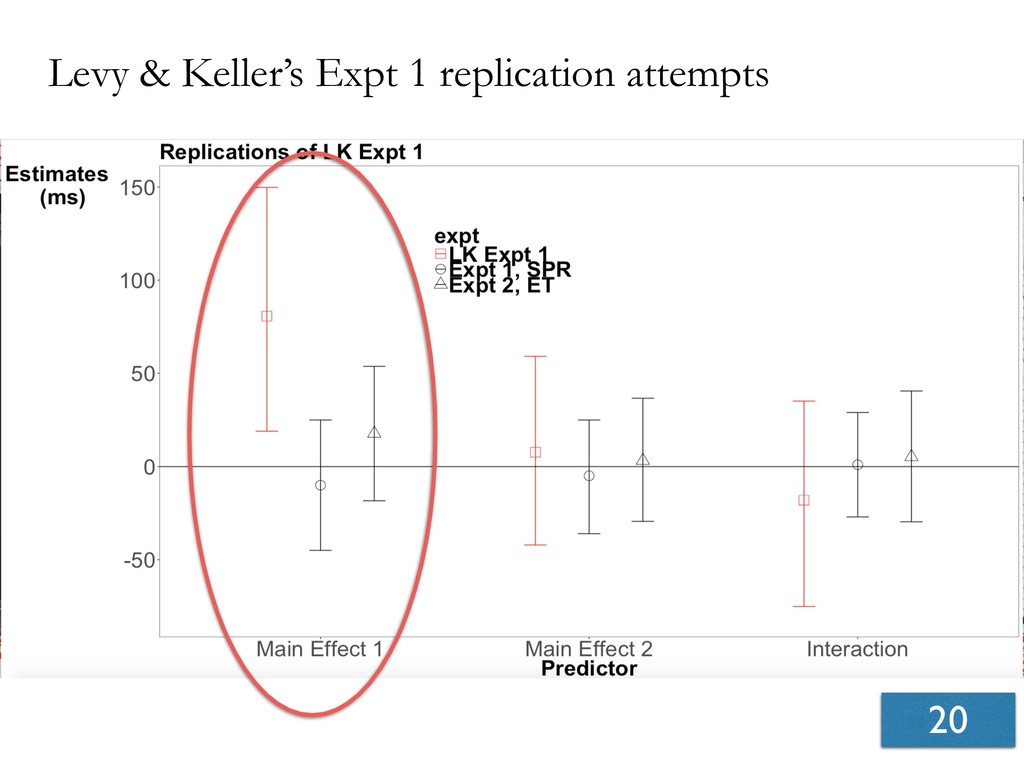
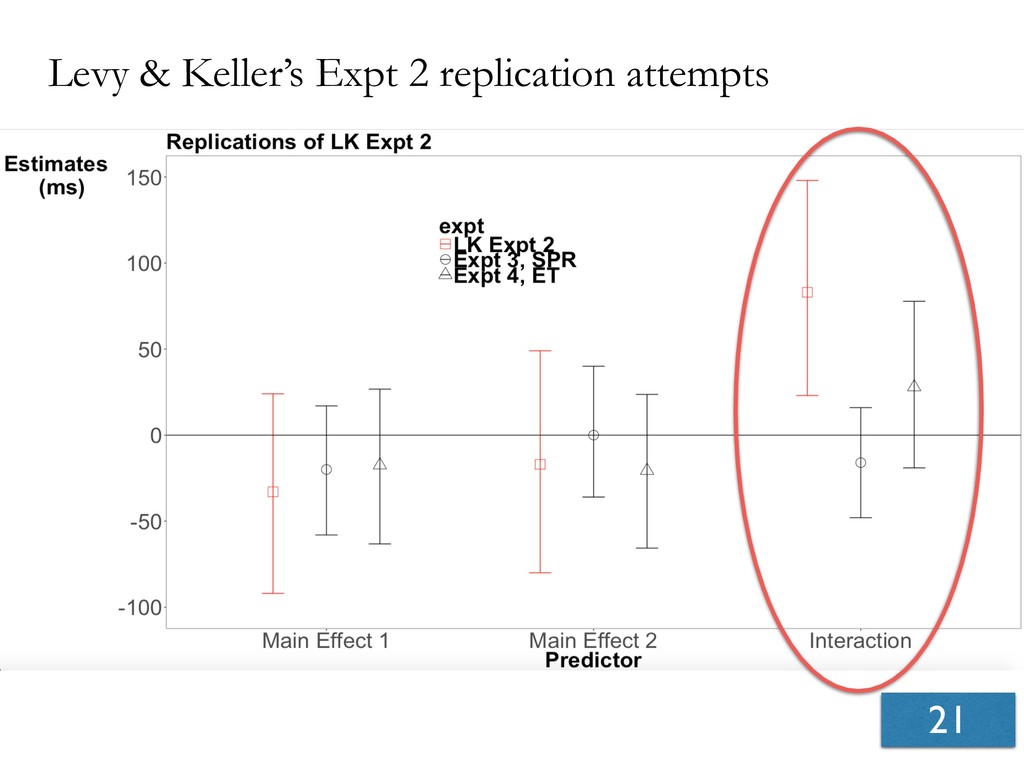
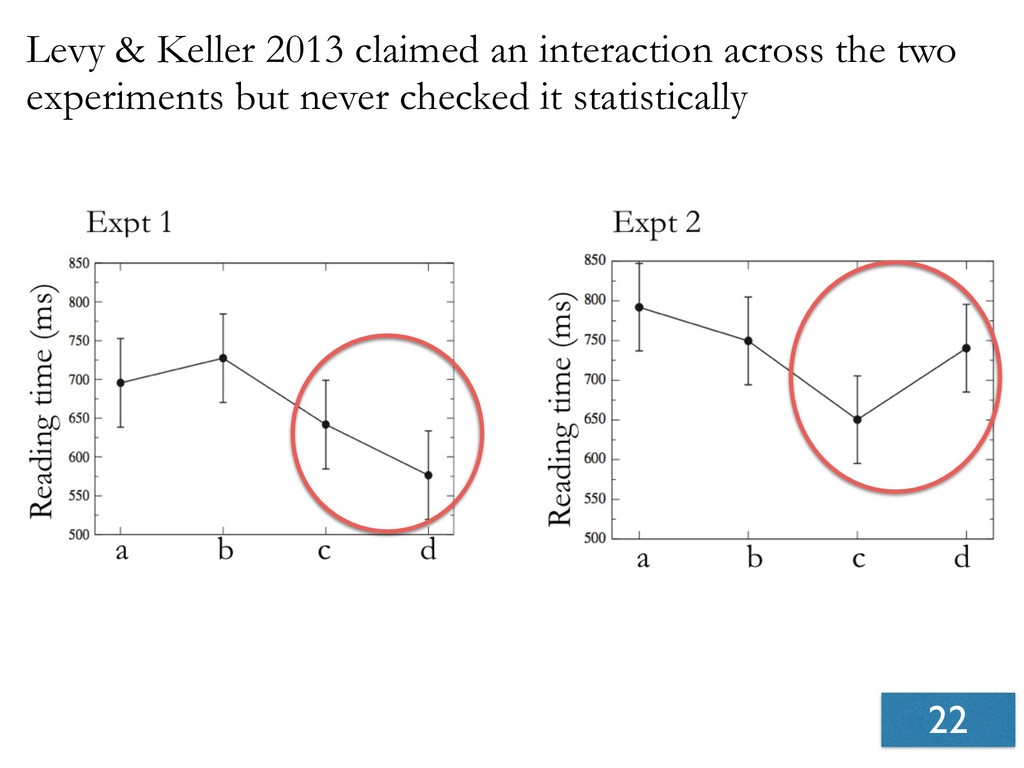
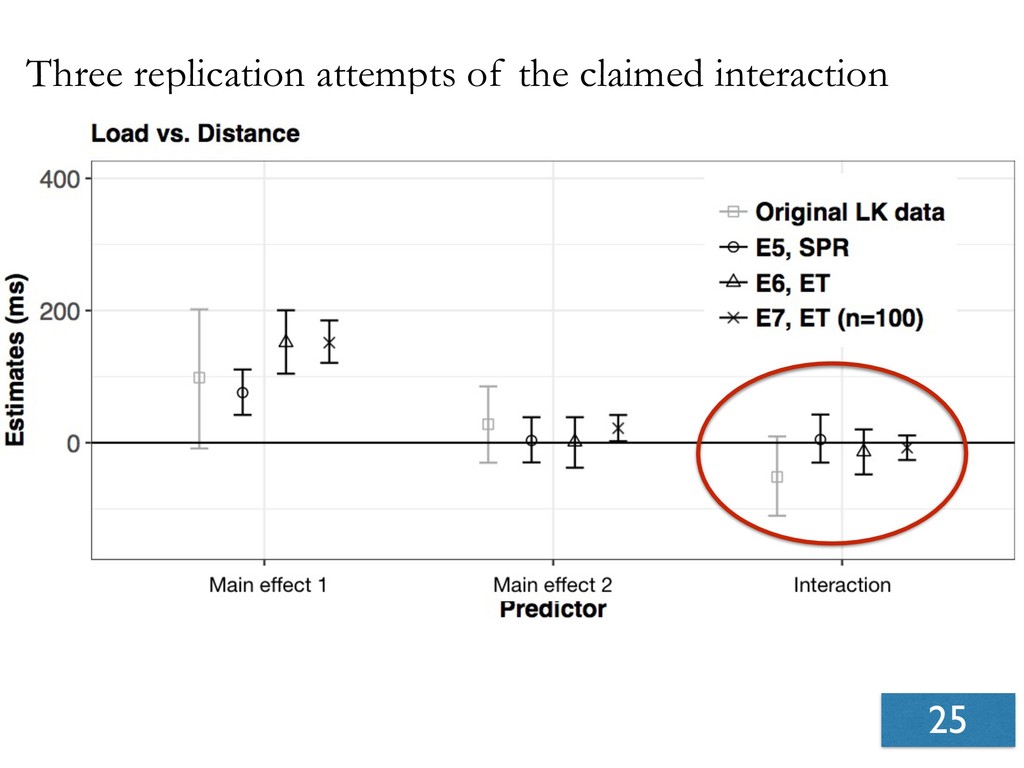
- Seven experiments show that effects reported in Levy & Keller, 2013 are not replicable.
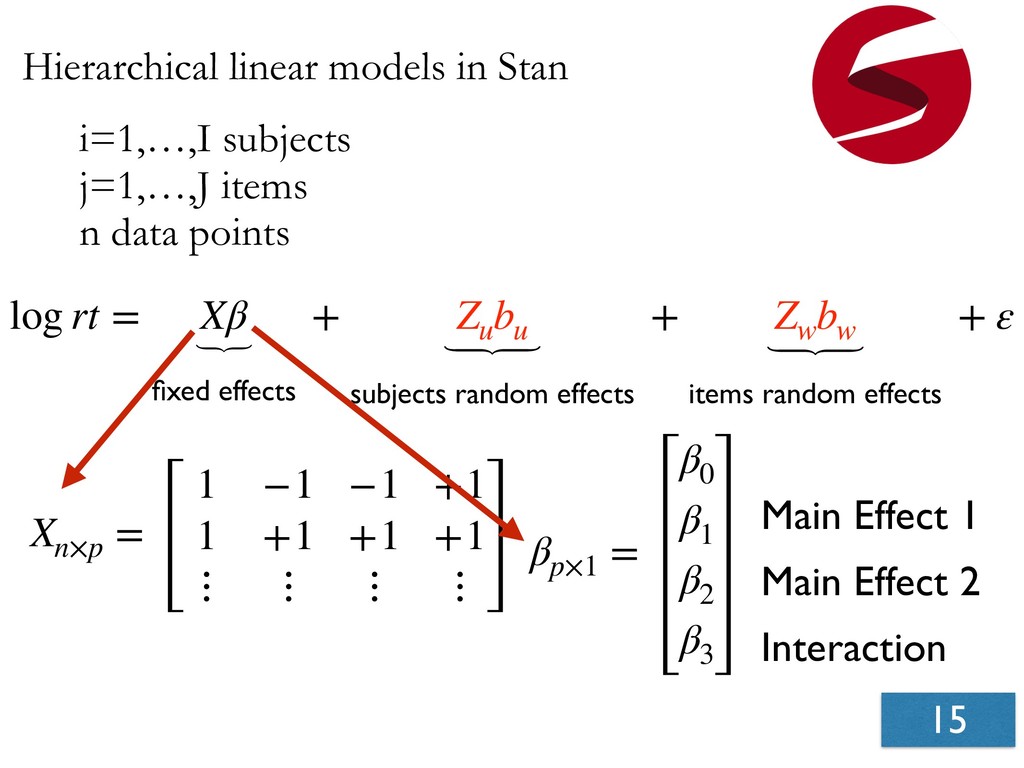
- Relying only on statistical significance leads to overconfident expectations of replicability.
- We make several suggestions for improving current practices.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}