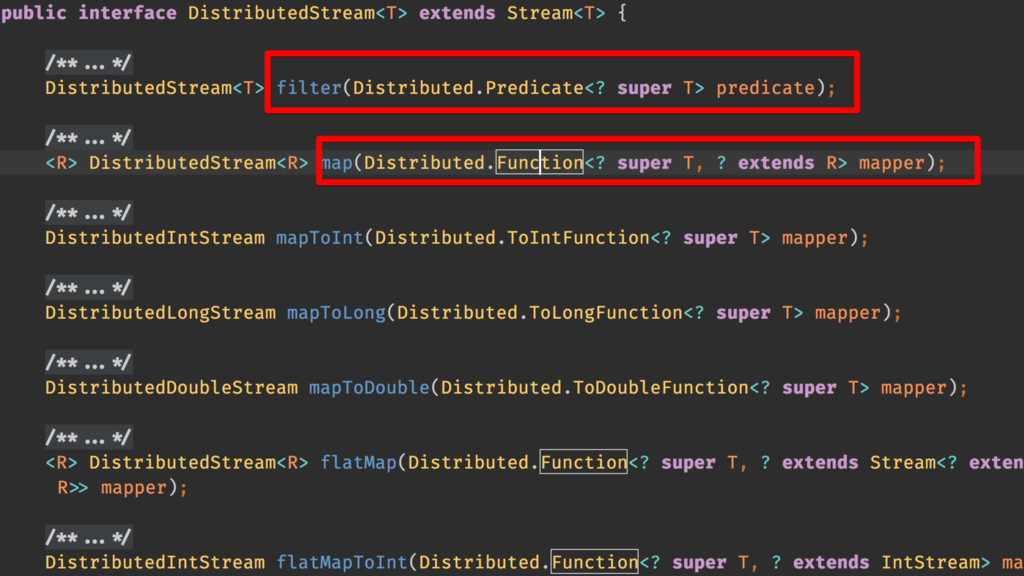
Java 8 introduced the Stream API as a modern, functional, and very powerful tool for processing collections of data. One of the main benefits of the Stream API is that it hides the details of iteration over the underlying data set, allowing for parallel processing within a single JVM, using a fork/join framework.
I will talk about a Stream API implementation that enables parallel processing across many machines and many JVMs.
You will learn how you can use the same API to process massive data sets across large clusters, which you already know how to do in a single JVM.
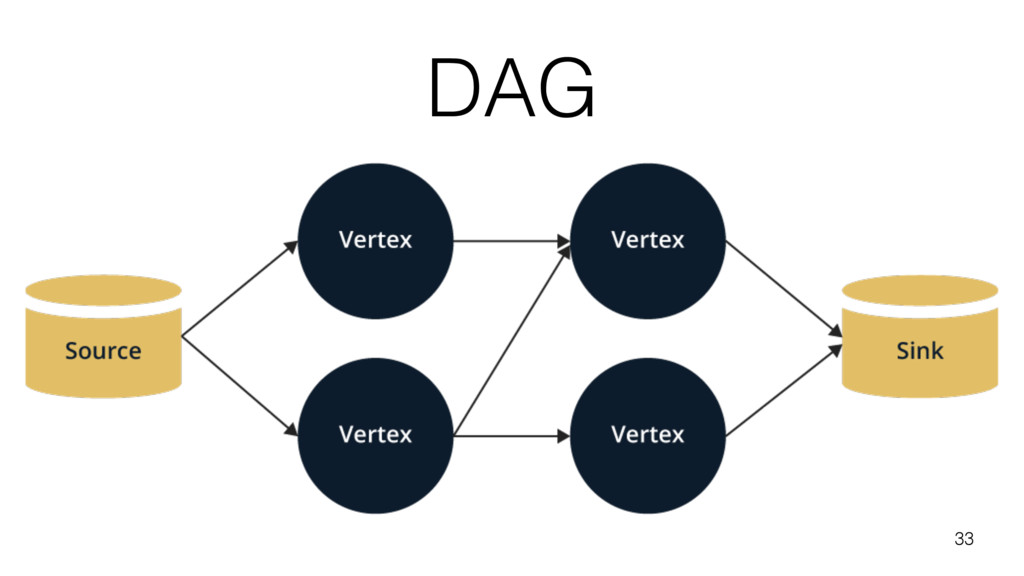
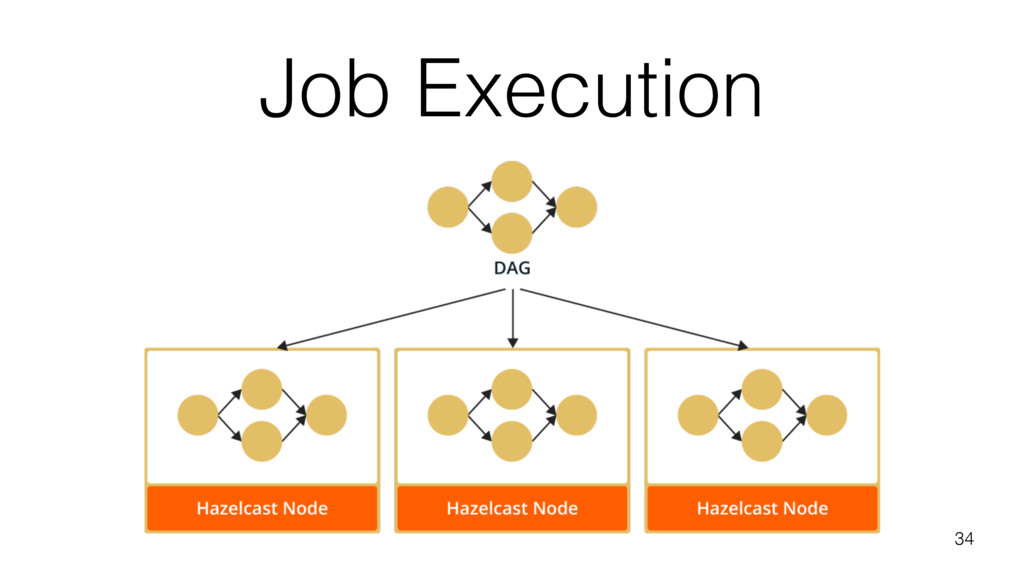
With an explanation of internals of the implementation, I will give an introduction to the general design behind stream processing using DAG (directed acyclic graph) engines and how an actor-based implementation can provide in-memory performance while still leveraging industry-wide known frameworks as Java Streams API.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
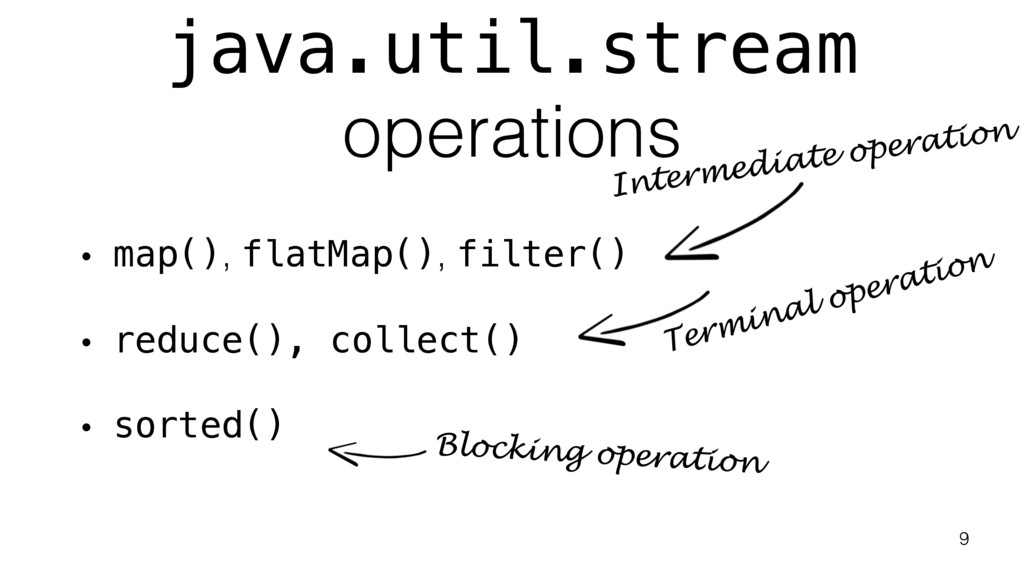{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
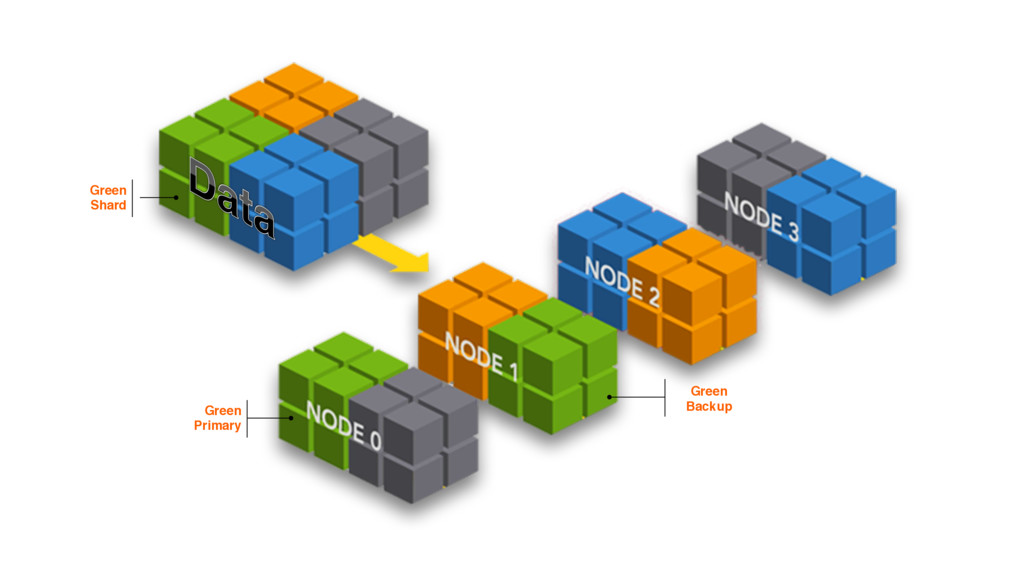{kind=link}
{kind=link}
{kind=link}
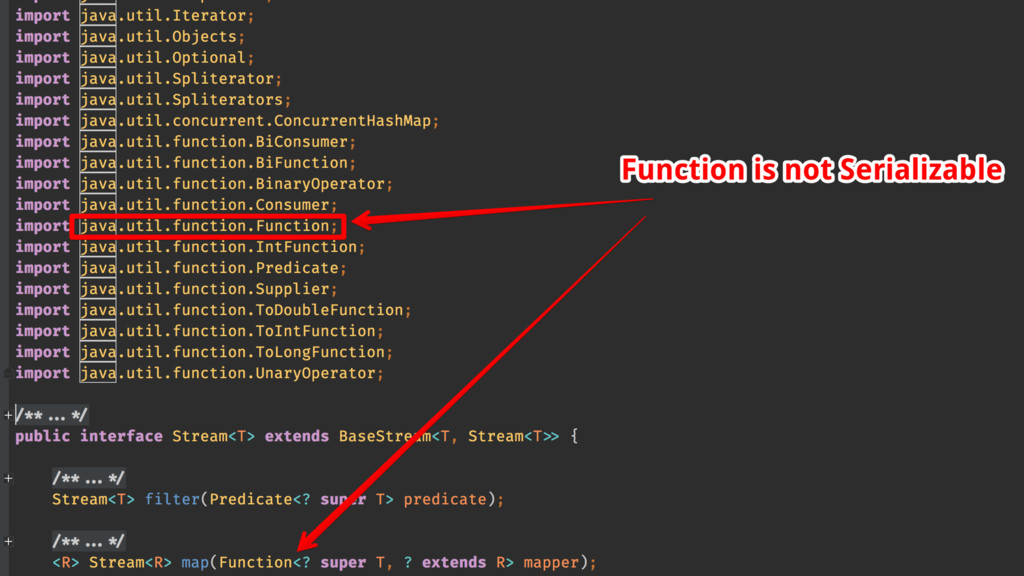{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}