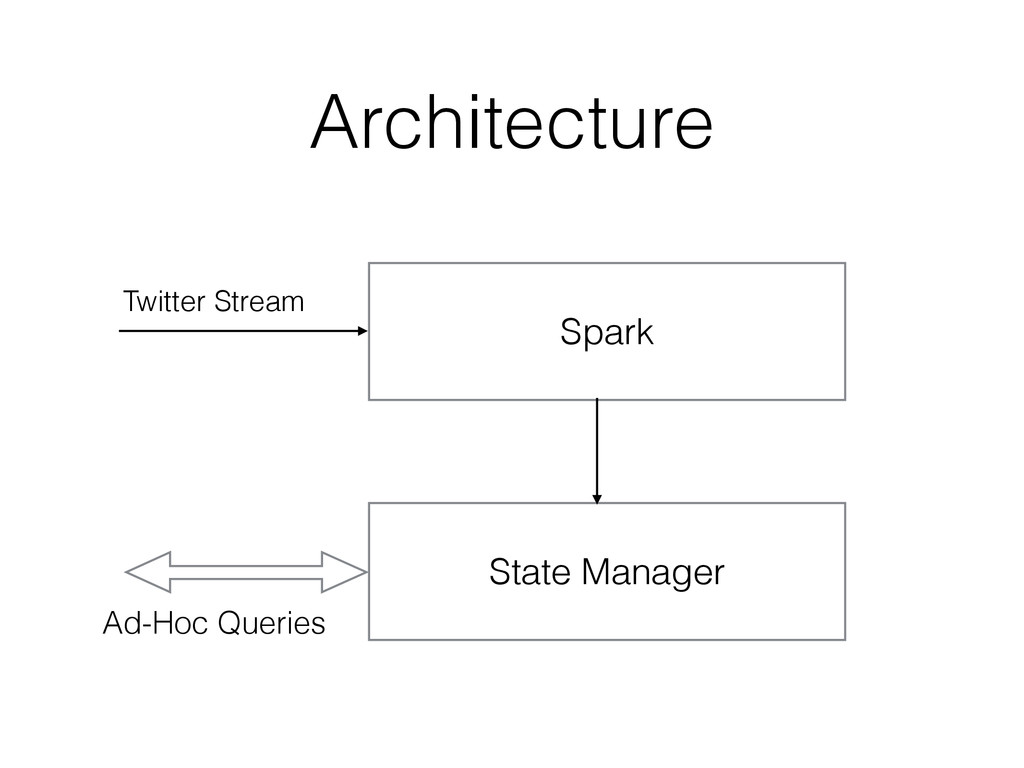
does not have support for ad-hoc queries. • It is also very inconvenient to maintain state in the way that is required by the BDMO algorithm using Spark Streaming. (It can be done using updateStateByKey but the resulting state cannot be queried externally.)
• Filters out tweets without geolocation information. • Clusters the locations in each 30s window of Tweets using k-means. • Passes the results of the clustering to the state manager component.
bucket, find the closest point in the larger bucket and update it to the size- weighted average position of the two points. • Meaningful when clusters parameters change gradually rather than abruptly, which is generally the case in a stream. • Can be enhanced by considering number of points associated with each cluster rather than the bucket size.
throughput will scale linearly with the number of nodes. • This is important because the Spark component is what consumes data from the stream and needs to be able to cope with sudden increases in load. • Processes 3000-4000 tweets/second on a single node. (For context, on a regular day Twitter gets 5700 tweets/second on average.)
processes requests is controlled by the Spark Streaming window size. • We have an established upper bound on the amount of work that can be needed to fulfil a single request. • Can be sharded if needed, though it would be easier to sacrifice latency instead.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}