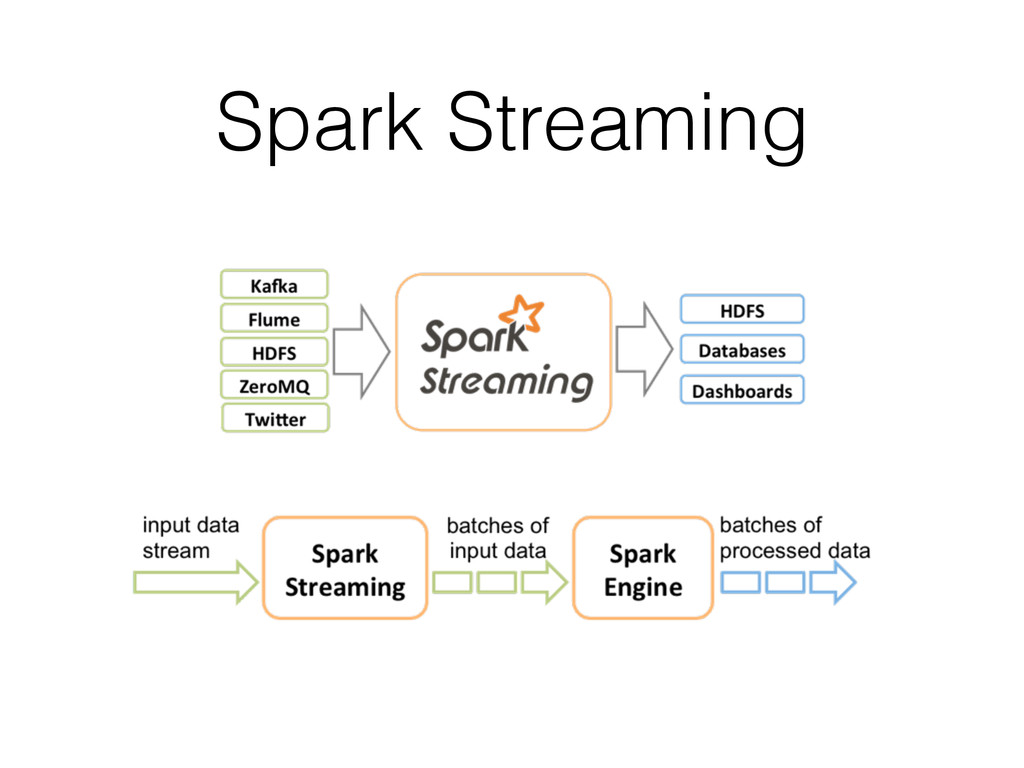
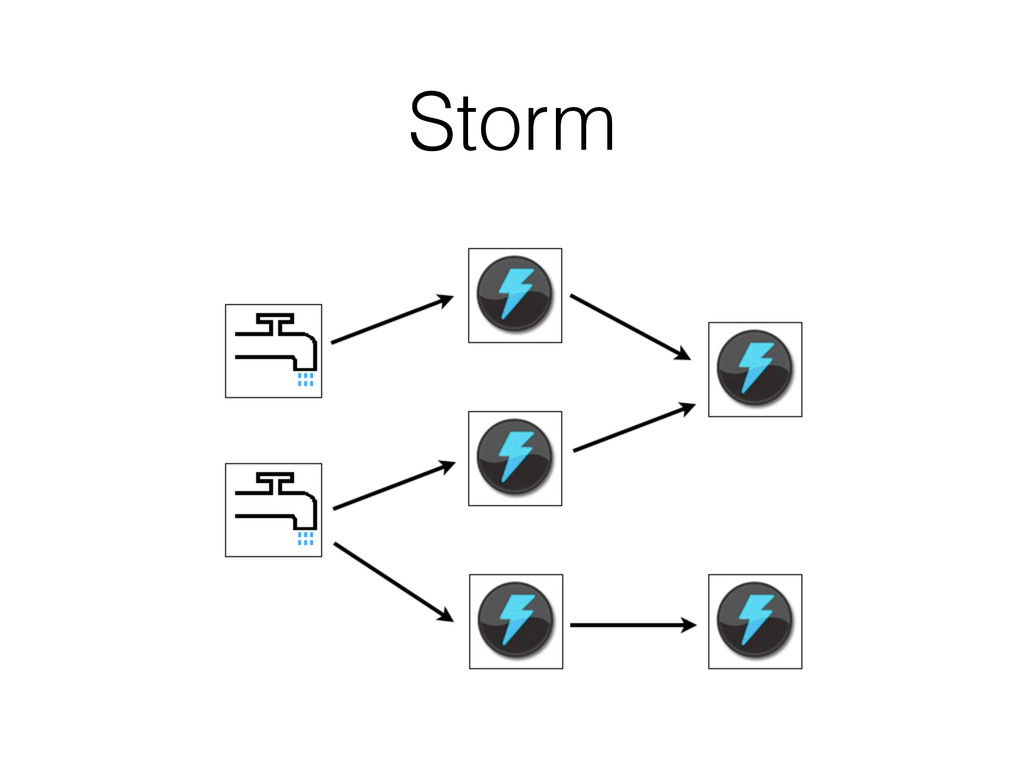
since it is received too fast. (In 2010 Twitter was generating 8TB of data every day, in 2012 Facebook was generating 500TB of data each day.) • Latency constraints. (Trending Topics)
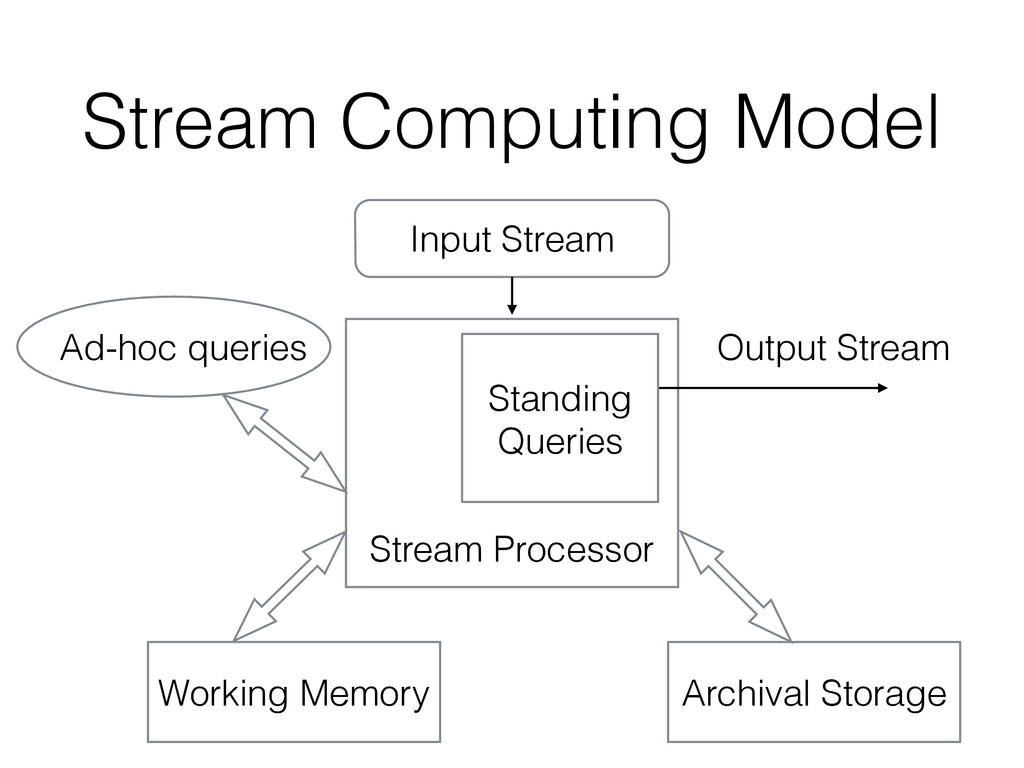
output at appropriate times. Example: 95th percentile latency. • Ad-hoc queries: questions asked about the current state of a stream. Usually supported by storing a summary of the stream if we know what kind of queries will be asked, or by storing a sliding window.
in some space. • Sliding window consists of N most recent points. • We want to pre-cluster points in the stream so that we can quickly get the clusters of the last m points, where m ≤ N.
are partitioned and summarized by buckets whose sizes are powers of two. • There are one or two buckets of each size up to a limit. • Bucket sizes are non-decreasing as we go back in time. Number of buckets will be O(log N).
a single reduce job. • Each map task is given a subset of the points and emits a set of k-v pairs where the key is 1 and the value describes a single cluster. • Reduce task merges the clusters.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}