Related blog post: https://blog.socialcops.com/engineering/apache-airflow-disease-outbreaks-india/
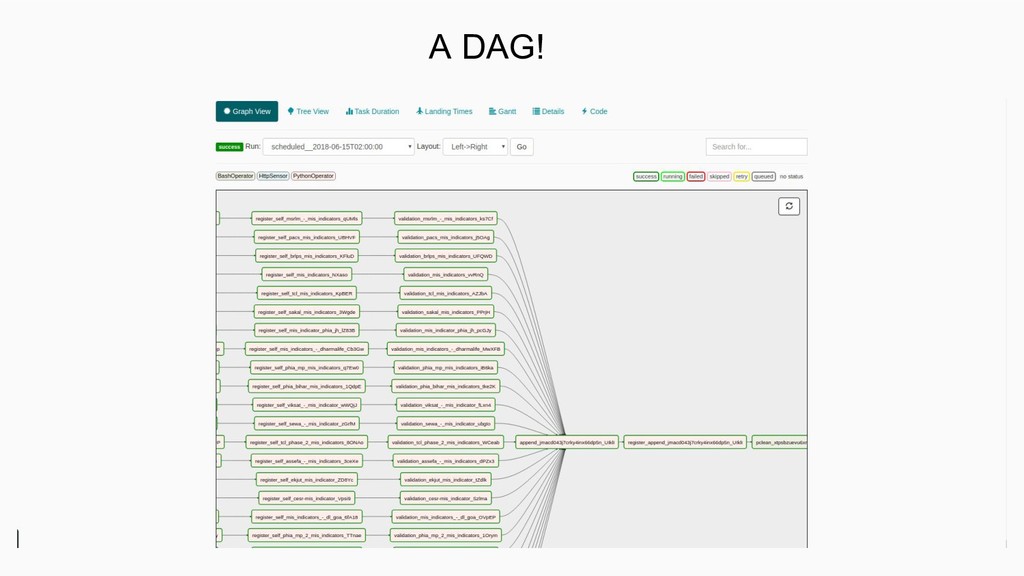
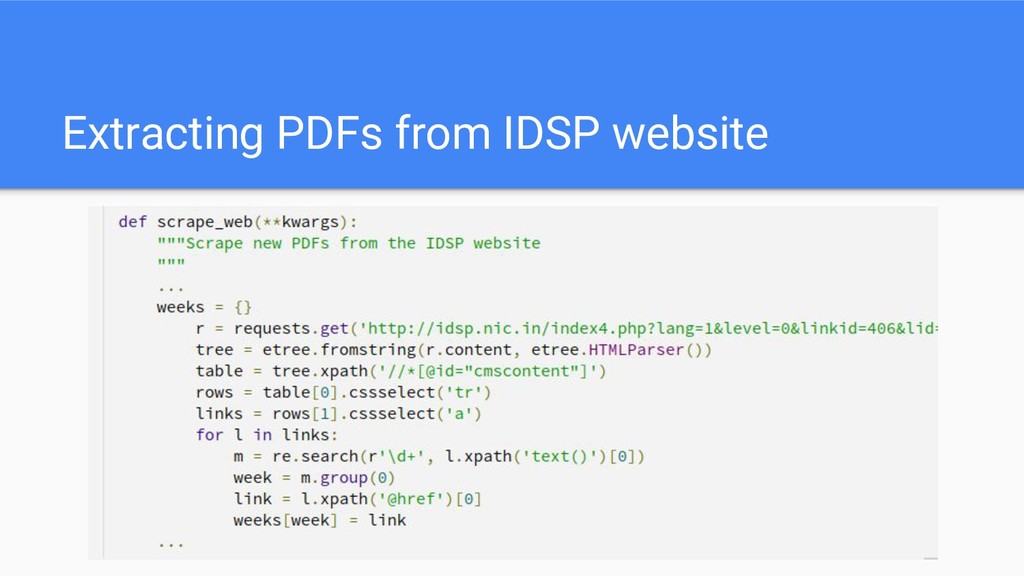
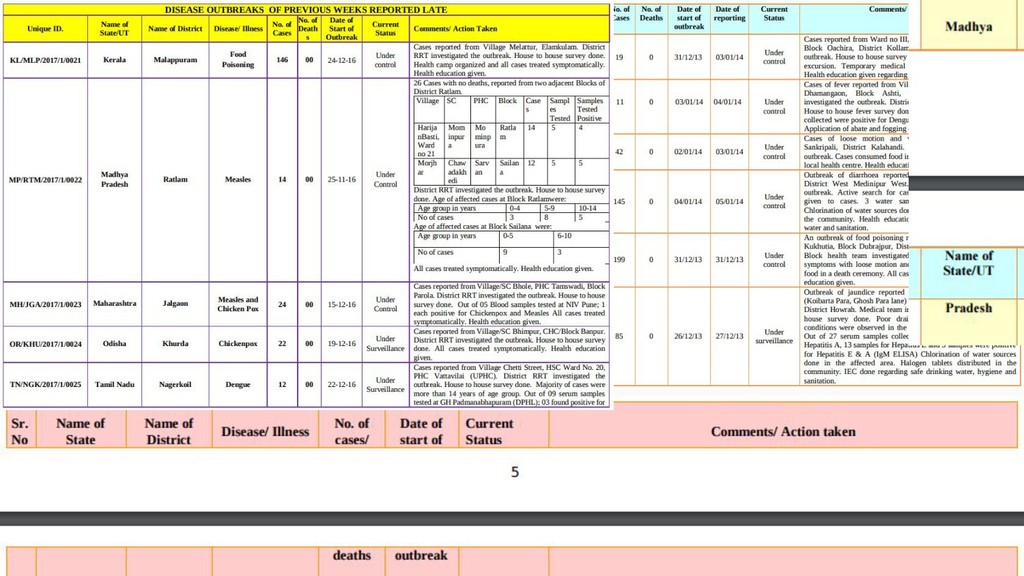
The presentation begins with a general introduction to Apache Airflow and then goes into how the audience can develop their own ETL workflows using the framework, with the help of an example use case of "tracking disease outbreaks in India". It also talks about briefly how SocialCops has used Apache Airflow to power the DISHA dashboard (https://blog.socialcops.com/inside-sc/announcements/disha-dashboard-good-governance/) and to move data across their internal systems.
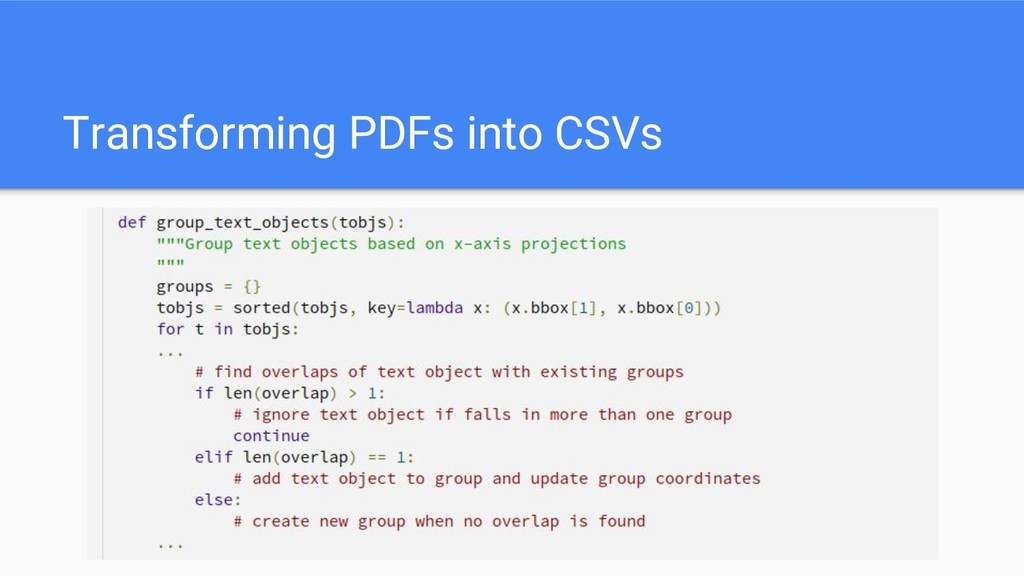
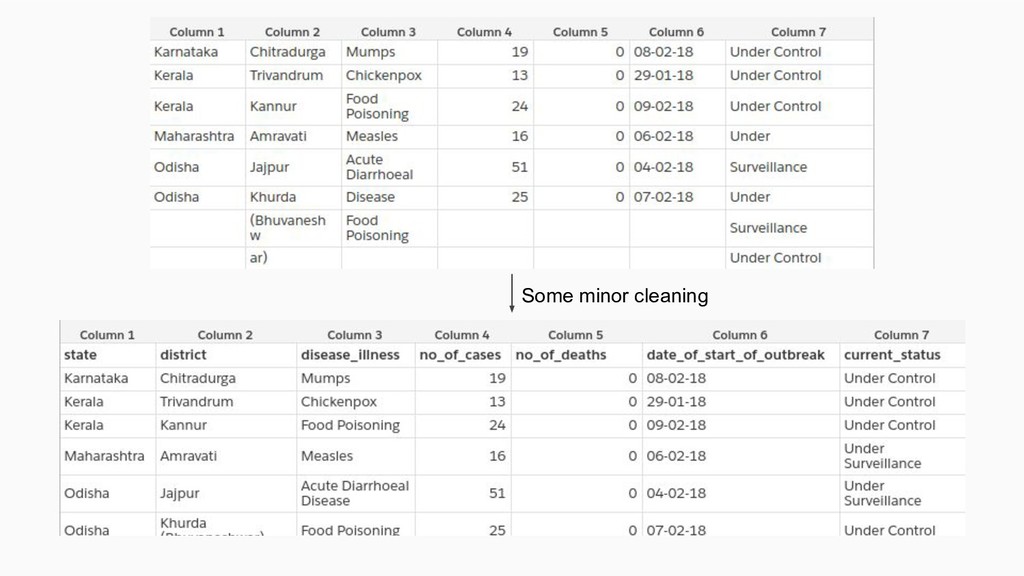
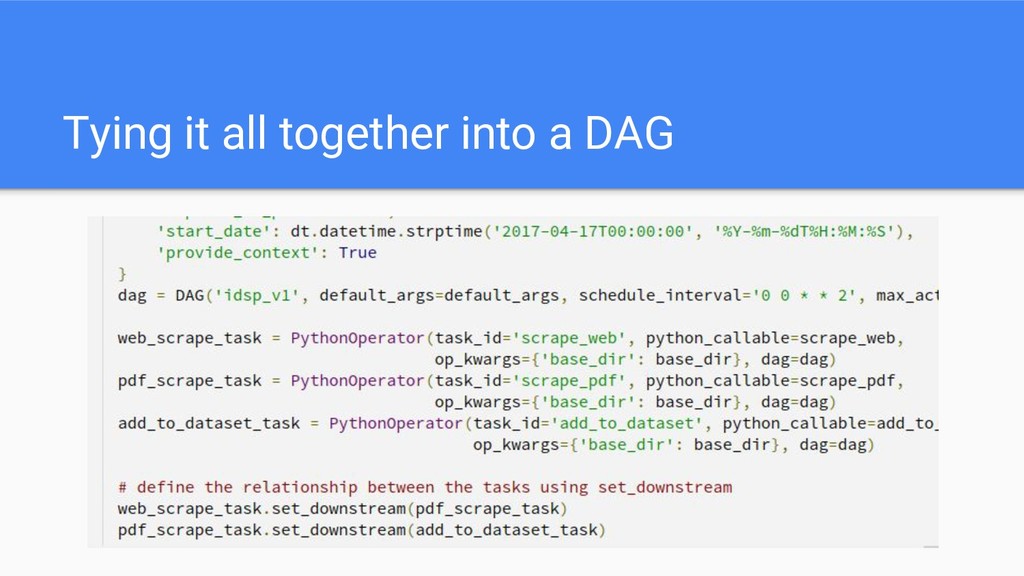
The full code is present here: https://github.com/socialcopsdev/airflow_blog
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! SocialCops https://twitter.com/social_cops Email: [email protected] Blog: blog.socialcops.com Website: www.socialcops.com](https://files.speakerdeck.com/presentations/8b3de84663d149ddaefbe77a2e7f3434/slide_30.jpg){kind=link}