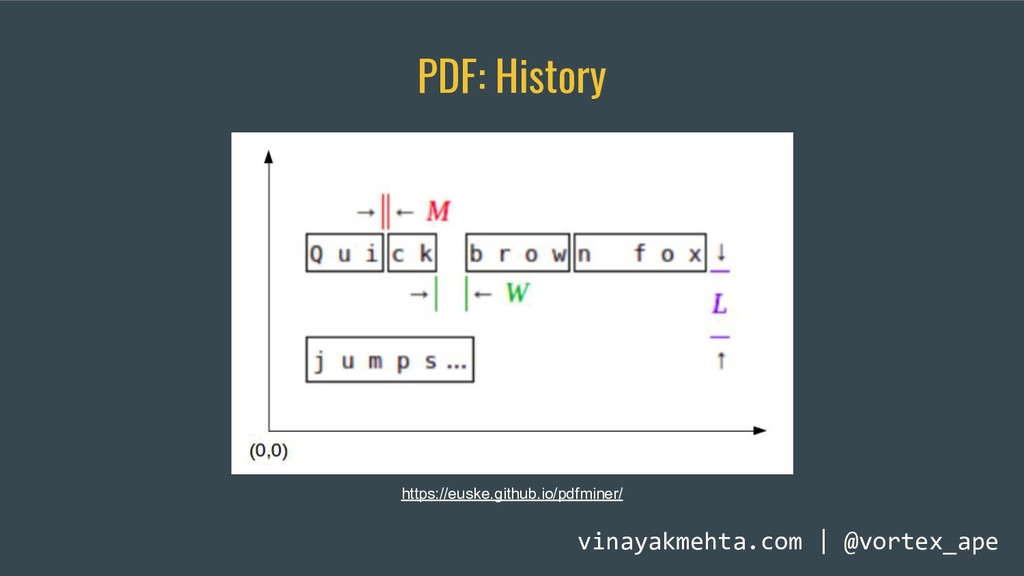
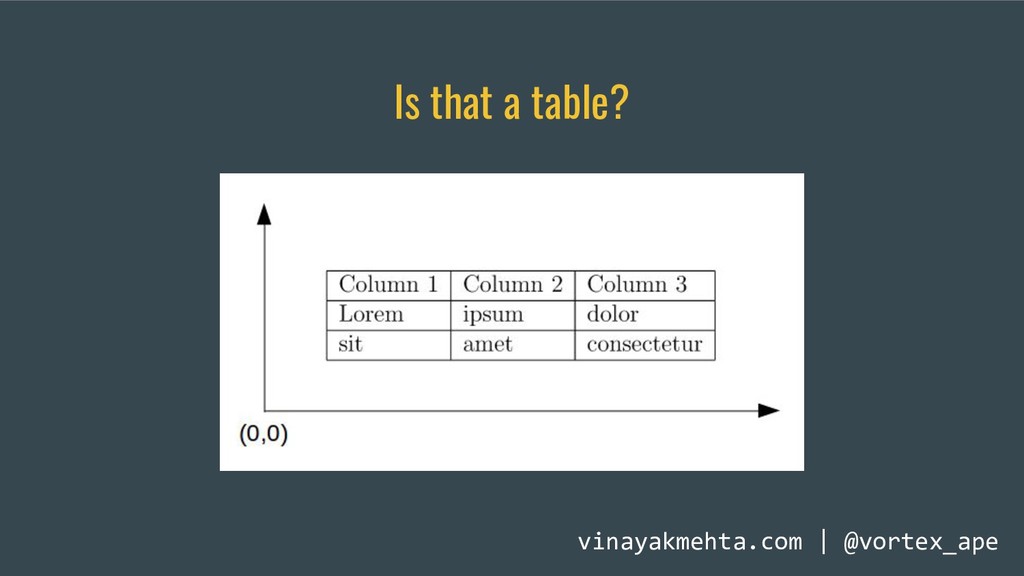
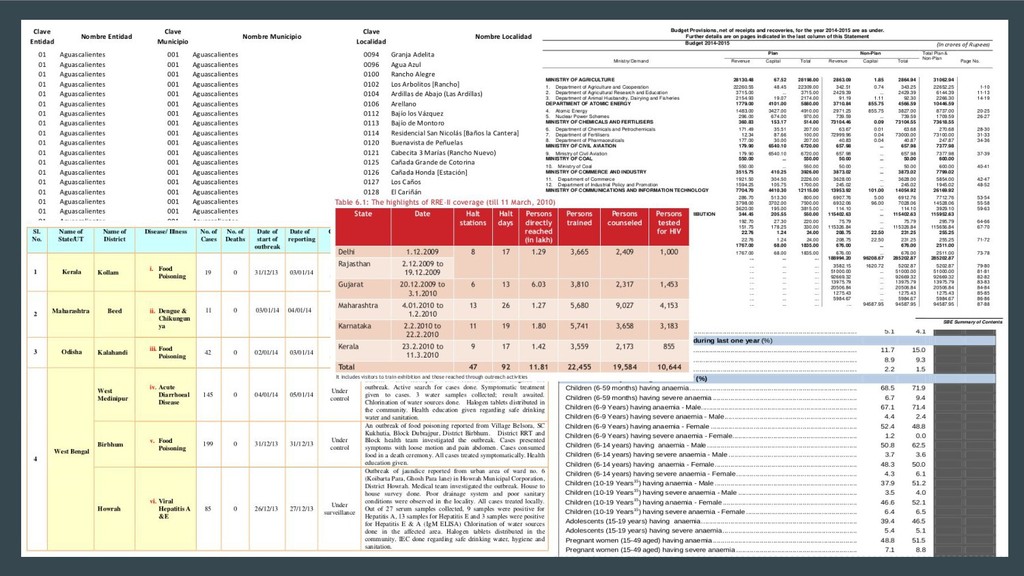
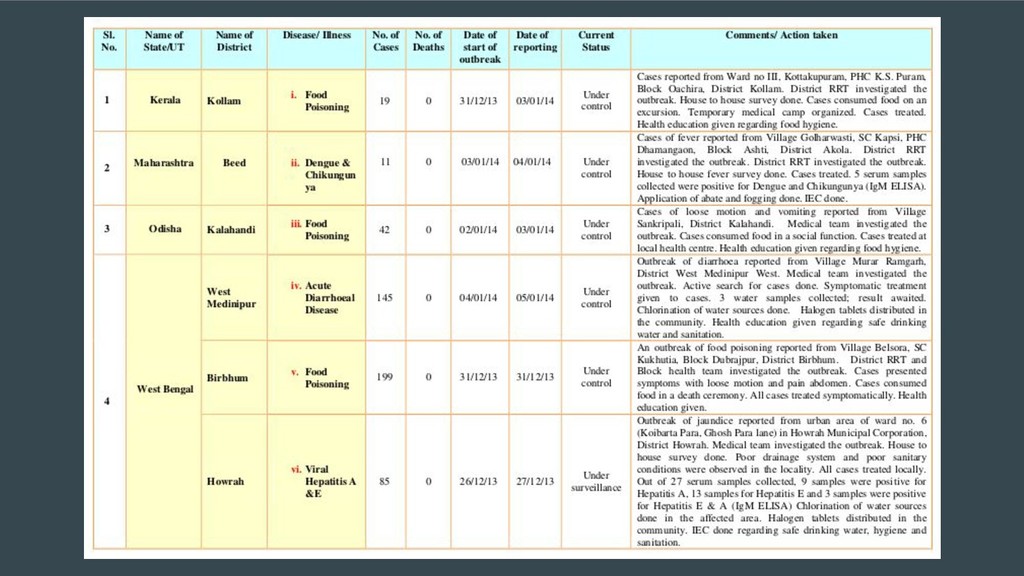
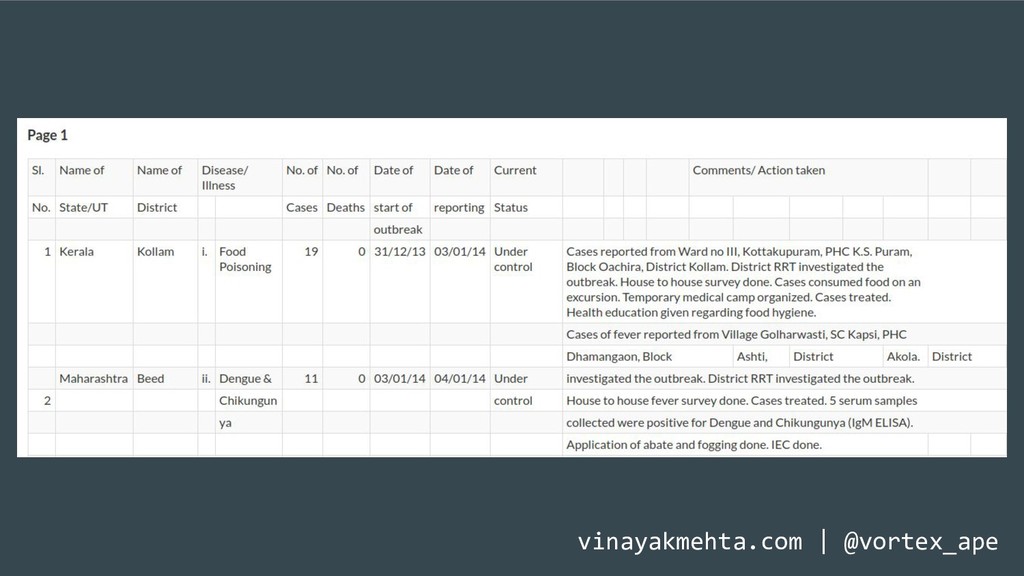
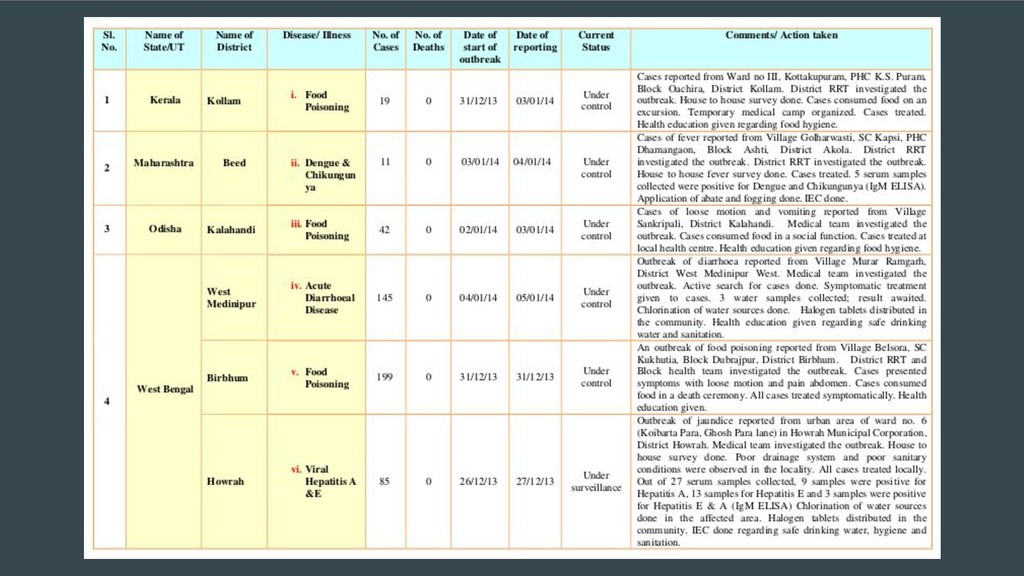
Extracting tables from PDFs is hard. The Portable Document Format was not designed for tabular data. Sadly, a lot of open data is shared as PDFs and getting tables out for analysis is a pain. A simple copy-and-paste from a PDF into a text file or spreadsheet program doesn't work.
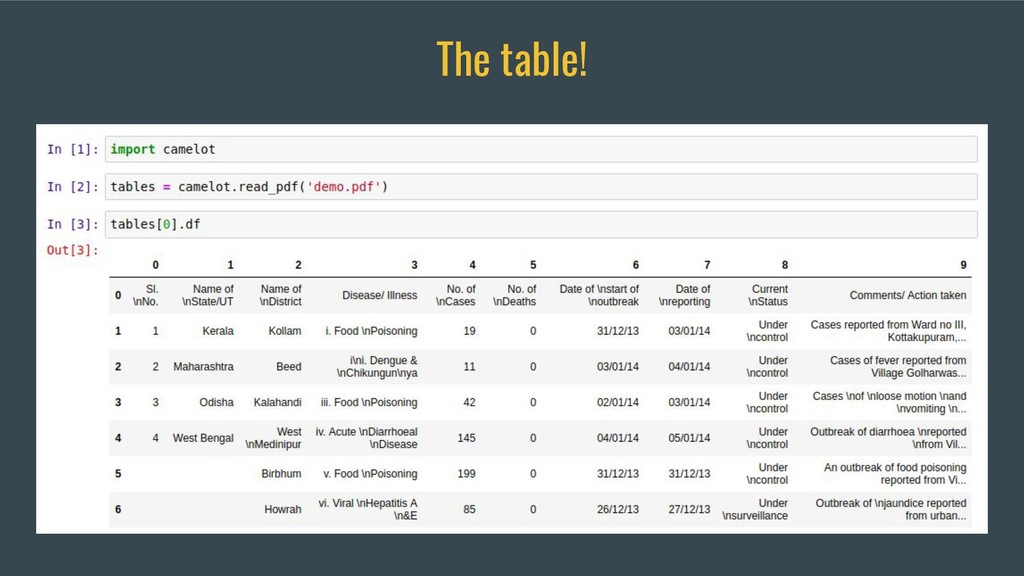
This talk will briefly touch upon the history of the Portable Document Format, discuss some problems that arise when extracting tabular data from PDFs using the current ecosystem of libraries and tools and demonstrate how Camelot and Excalibur solve this problem better and in a scalable manner. These easy-to-use packages automatically detect and extract tables from PDFs and give you access to the extracted tables in pandas DataFrames. You can also download them as CSVs or Excel files.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}