mouvant et performance en mode persistant » Conseille redis ou zeromq … persistence, sécurité, installation ... Notre avis : marche très bien avec le lapin jusqu'à des volumétries moyennes (<5000/s)
Java RabbitMQ, à l'arrêt est bloqué dans un appel com.rabbitmq.utility.BlockingValueOrException.uninterruptibleGetValue Idem si le mot de passe est incorrect Egalement deadlock possible à l'arrêt des applis si des messages restent à envoyer à la destruction des appenders
autre projet du client, une sorte de MDC un peu évolué fait bien le travail … mais sur log4j A minima utilisation de la façade slf4j log4j 2 prévu (LMAX Disruptor)
pour un bon fonctionnement en production frame_max,hearbeat,tcp_listen_options inet_dist_listen... disk_free_limit,vm_memory_high_watermark cluster_partition_handling
find queried attribute with name") AND !( (application:kafka AND "Connection reset by peer") "No data found" "caught end of stream" "from old client" ("in zookeeper" AND "doesn't exist yet") ((troncon OR branchement) AND "ne sera pas") (environment:rec AND NullPointerException AND MaterielServiceImpl:12) (environment:perf AND durationmillisec:) )
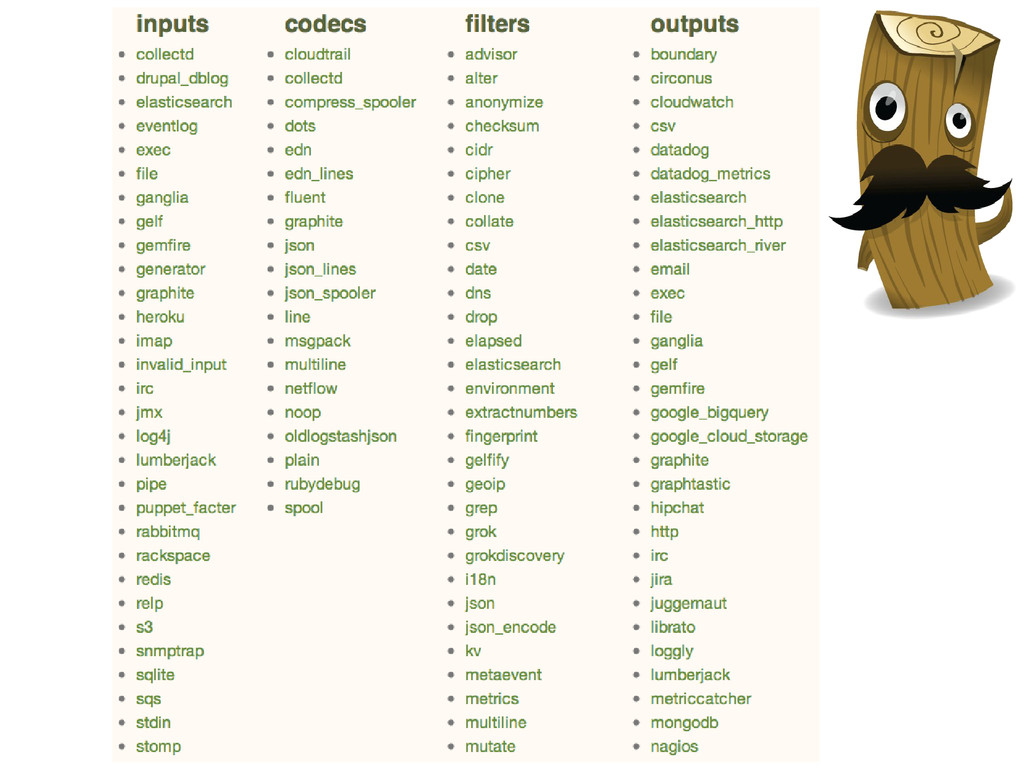
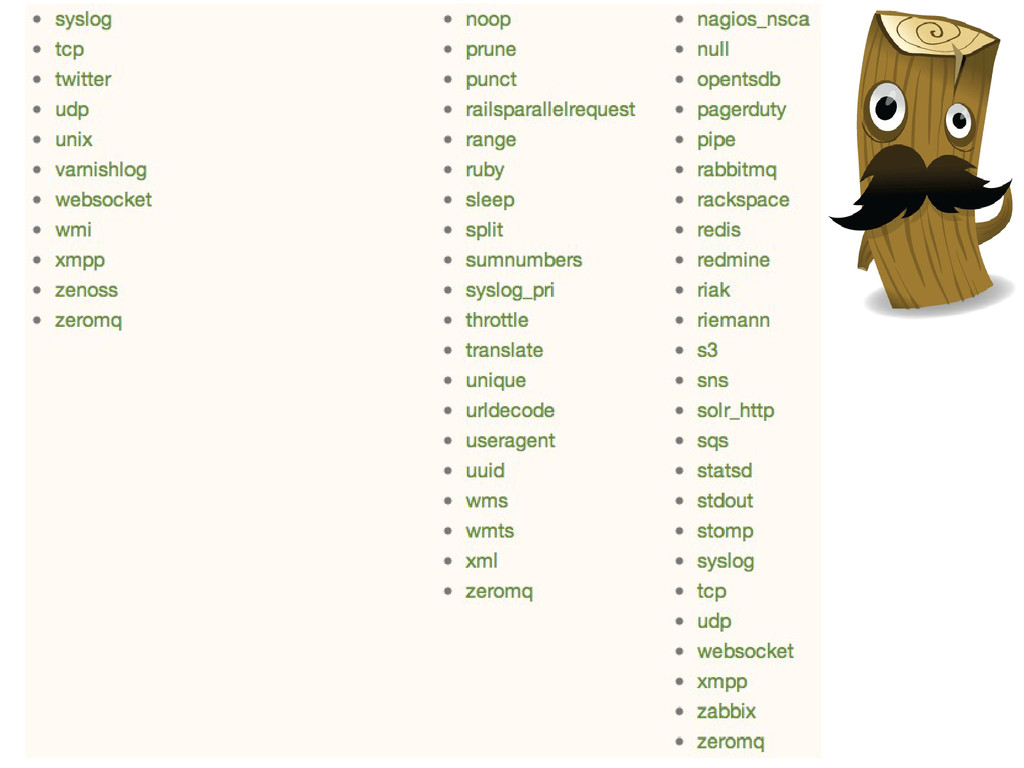
(pas multiligne, ni wildcard, ni buffer persistant sauf dans version premium, AMPQ pas en premium, API ..., 1 fichier persist, buffer sortie …) flume / hadoop (pas de tail, Hadoop, intéractif ..., ops …) Piste intéressante : sink Flume avec un split sur elasticsearch et HDFS/HBase ou écoute de HDFS/HBase ou elasticsearch-hadoop Graylog2 (ruby gem …, Java dernière version, GELF spécifique, mongodb, mapping, 1 index)
flux en | Morphlines de Cloudera / Zlogd de Zumba / Utiliser Solr (Logsene@sematext) Splunk (puissant, bien intégré, indexation brute, reporting, corrélation / alerte, C et python, plugin, pas extensible / intégrable, très cher) PAAS (Loggly, New Relic, Papertrail, Logentries / ok/nécessaire dans le cloud, RSSI pas content, coût assez obscur)
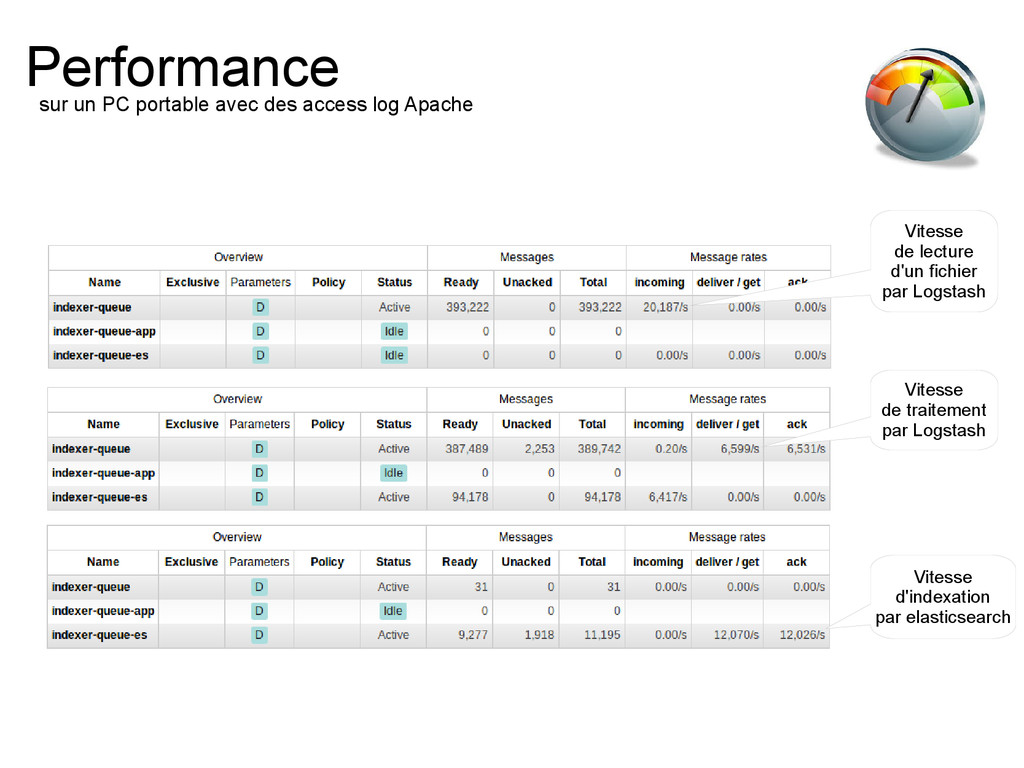
à très forte charge • throughput impressionnant • > 20 000/s en production et > 200 000/s en consommation sur un portable • scalabilité horizontale • nativement persistant • ok dans un écosystème bigdata • API consommation pas simple
de nouvelles technologies nécessaire (apprentissage, maîtrise, complexité) Overhead, très limité (Logstash et appender 10- 100ms) et rapport gain/perte OK RabbitMQ a montre ses limites
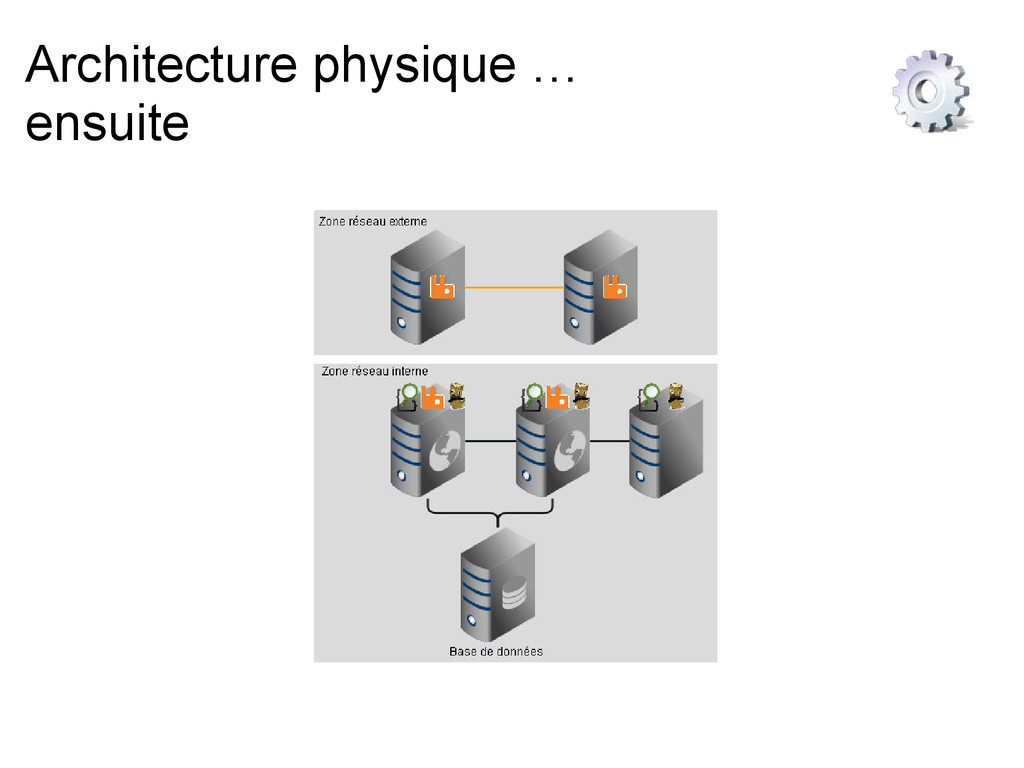
cookbooks chef, modules Puppet, Ansible, deb, RPM existent … si ils correspondent à votre environnement Architecture à scaler pour très grande volumétrie En plein mouvement
Temps de diagnostic des problèmes et des tests de performance réduit drastiquement Développeurs & SNx autonomes Devenu un des outils le plus utilisé chez ERDF
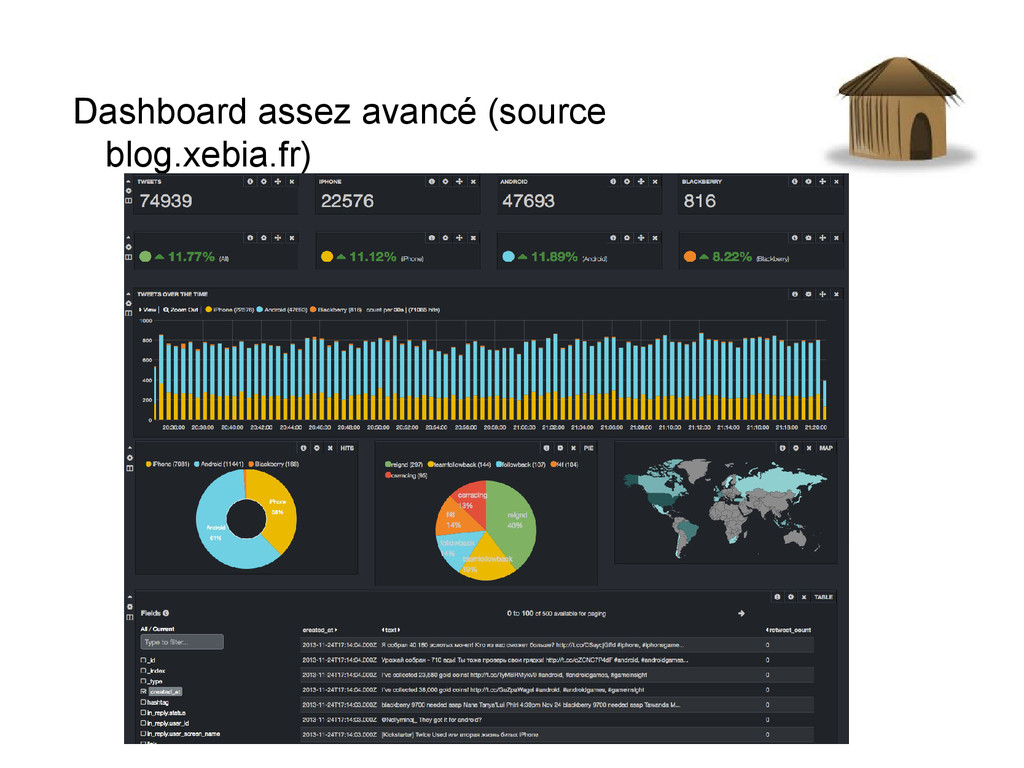
la qualité « visible depuis les logs » Corrélation à travers toute l'architecture, top 10 erreurs, ... Recherche de reproductibilité de bug facile Statistiques diverses ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}