9 • jcmd <pid> VM.log output="file=gc-%p-%t.log" what="gc=debug,gc*,age*=trace,safepoint" decorators="time,level" output_options="filecount=10,filesize=10M" • Mode plus avancé (et verbeux) : -Xlog:gc*=debug,gc+ergo*=trace,gc+age*=trace,safepoint*,pagesize,os* • Un paquet de tags disponibles : add, age, alloc, annotation, aot, arguments, attach, barrier, biasedlocking, blocks, bot, breakpoint, bytecode, cds, census, class, classhisto, cleanup, codecache, compaction, compilation, constantpool, constraints, container, coops, cpu, cset, data, datacreation, dcmd, decoder, defaultmethods, director, dump, ergo, event, exceptions, exit, fingerprint, free, freelist, gc, handshake, hashtables, heap, humongous, ihop, iklass, init, inlining, interpreter, itables, jfr, jit, jni, jvmti, liveness, load, loader, logging, malloc, mark, marking, membername, memops, metadata, metaspace, methodcomparator, mirror, mmu, module, monitorinflation, monitormismatch, nestmates, nmethod, normalize, objecttagging, obsolete, oldobject, oom, oopmap, oops, oopstorage, os, pagesize, parser, patch, path, perf, phases, plab, preorder, preview, promotion, protectiondomain, purge, redefine, ref, refine, region, reloc, remset, resolve, safepoint, sampling, scavenge, setting, smr, stackmap, stacktrace, stackwalk, start, startuptime, state, stats, stringdedup, stringtable, subclass, survivor, sweep, system, table, task, thread, time, timer, tlab, tracking, unload, unshareable, update, verification, verify, vmoperation, vmthread, vtables, vtablestubs, workgang • Via jcmd <pid> PerfCounter.print | egrep 'safepointTime|applicationTime' • % de temps dans des safepoint, pour la plupart du GC : 100 * safepointTime / safepointTime + applicationTime
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
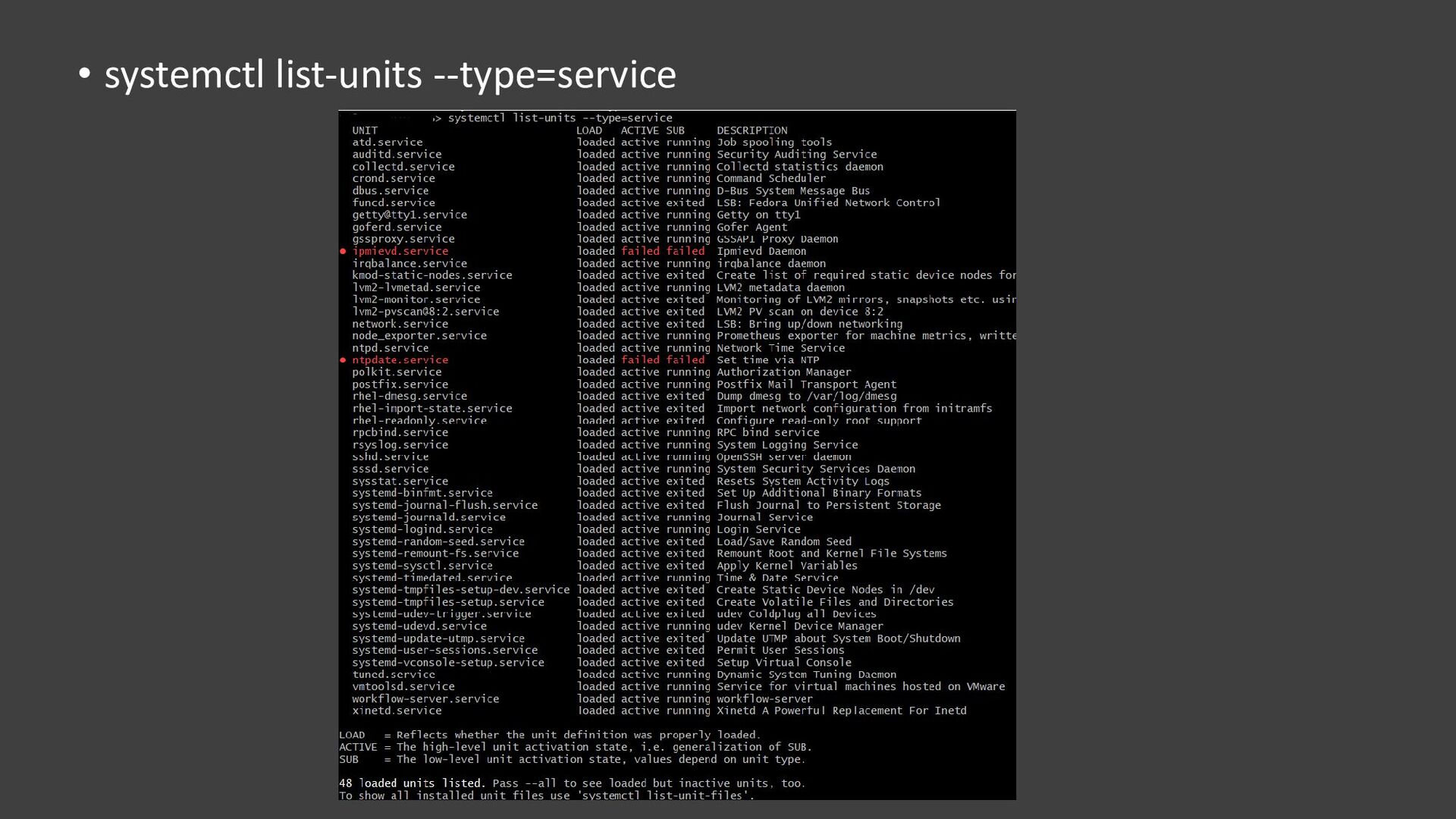{kind=link}
{kind=link}
{kind=link}
{kind=link}
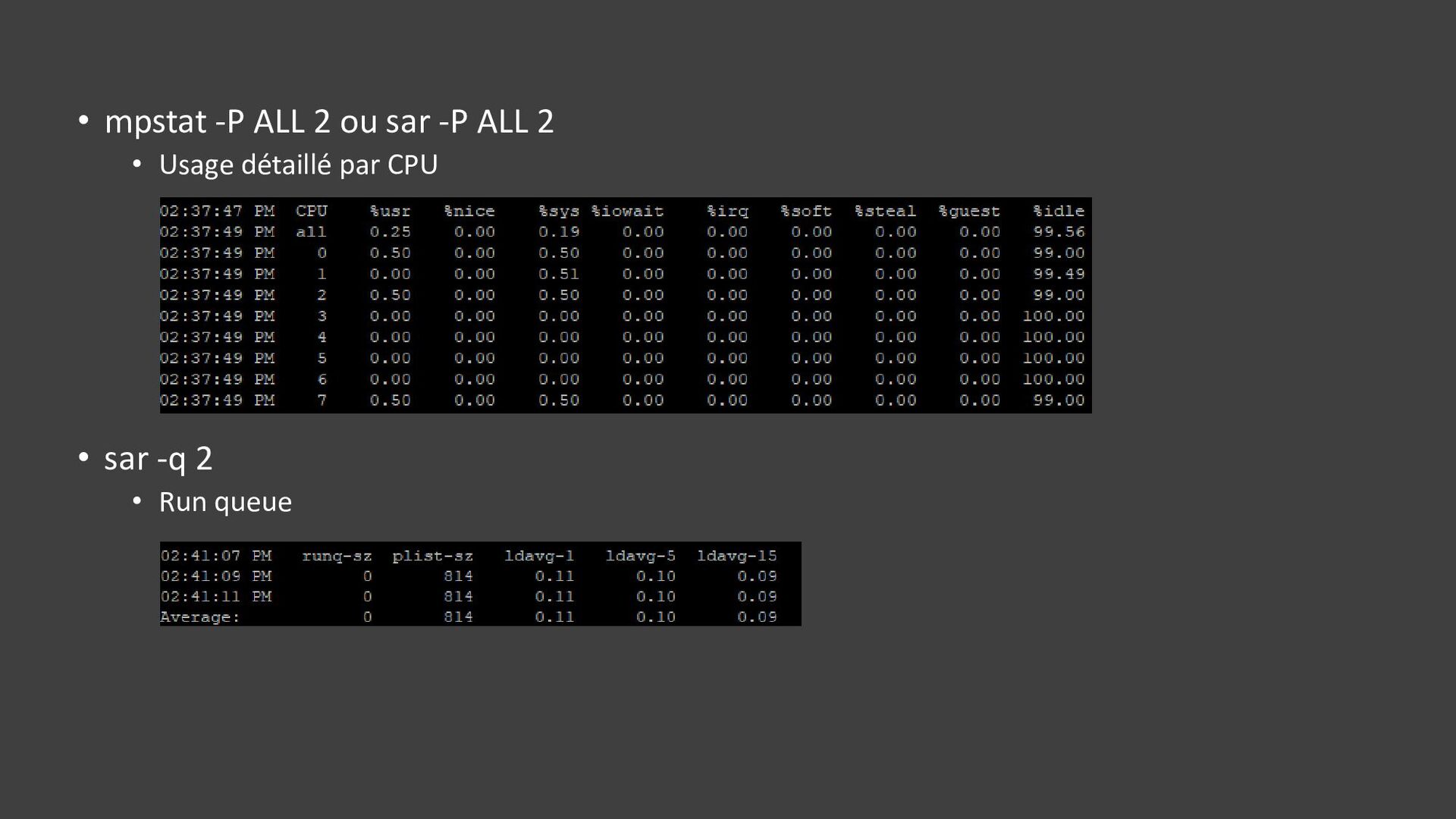{kind=link}
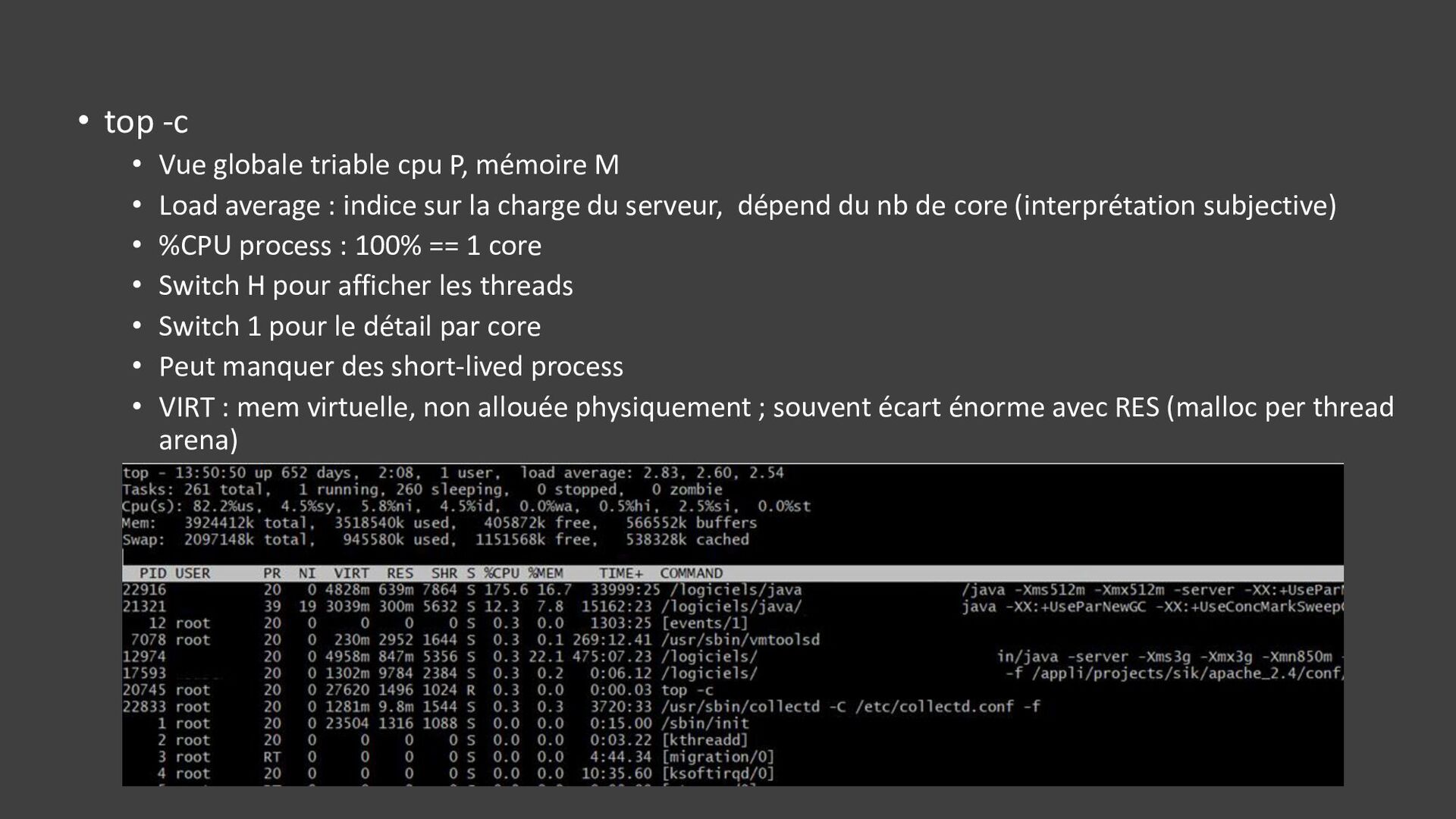{kind=link}
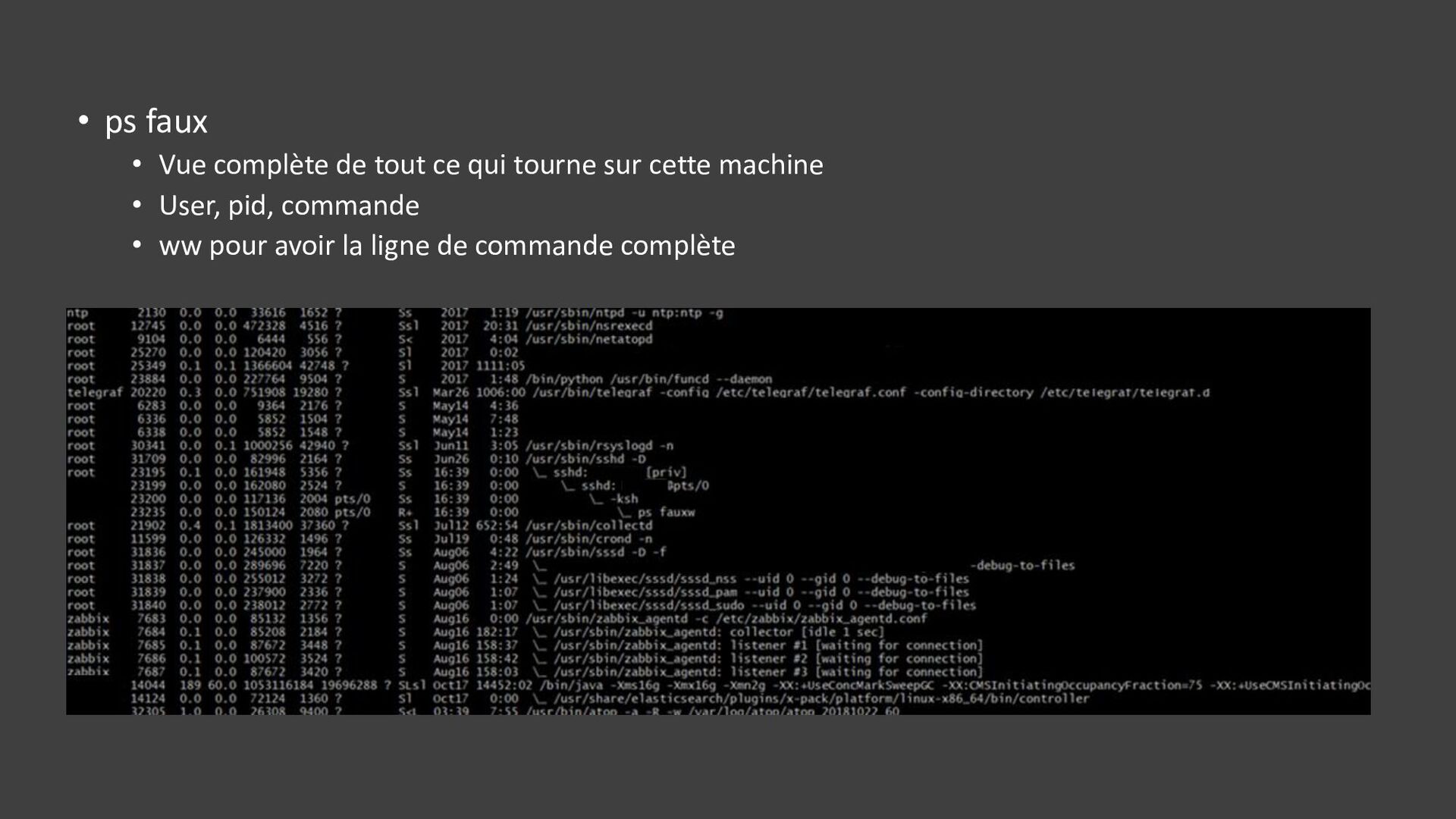{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
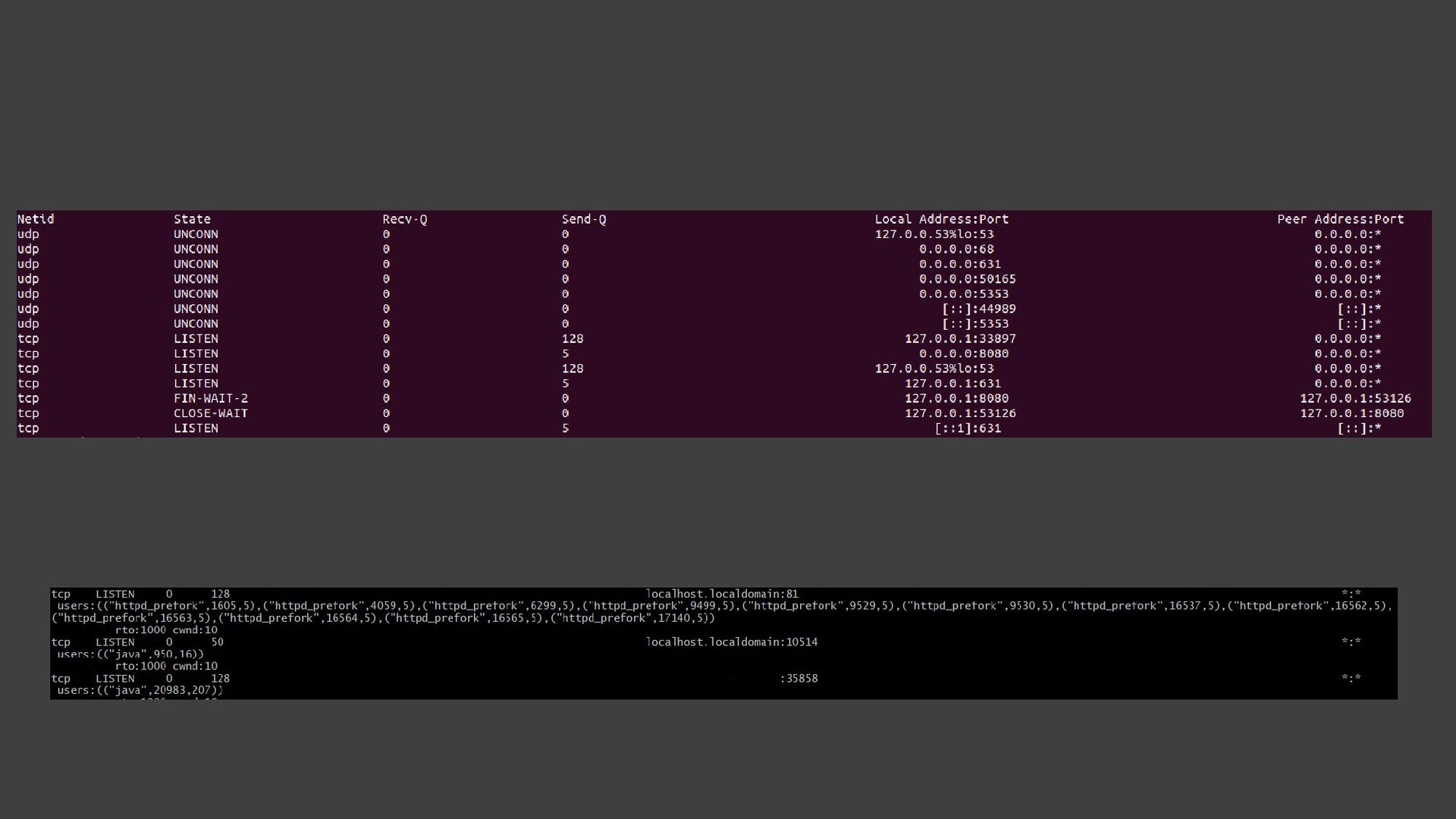
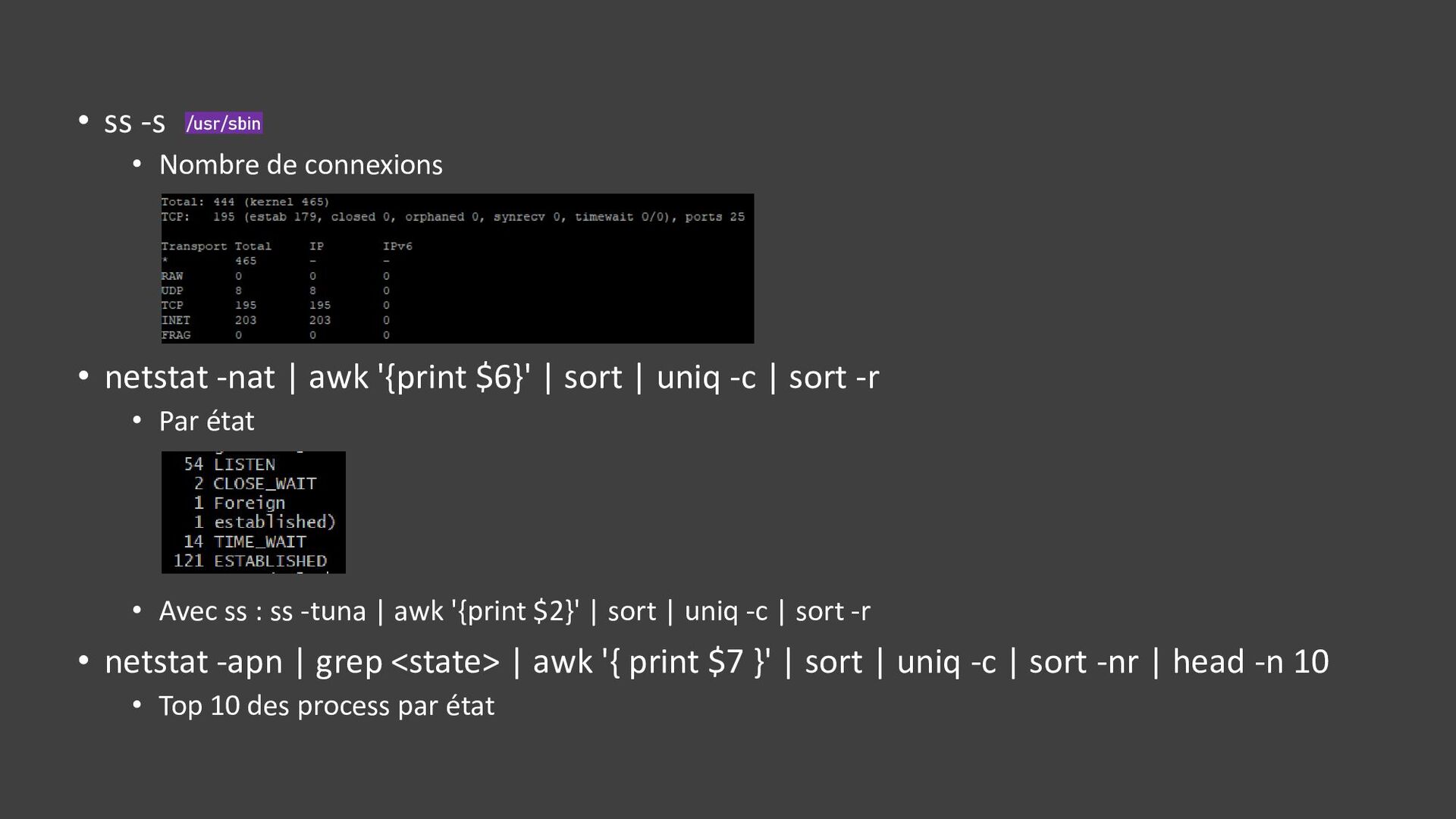
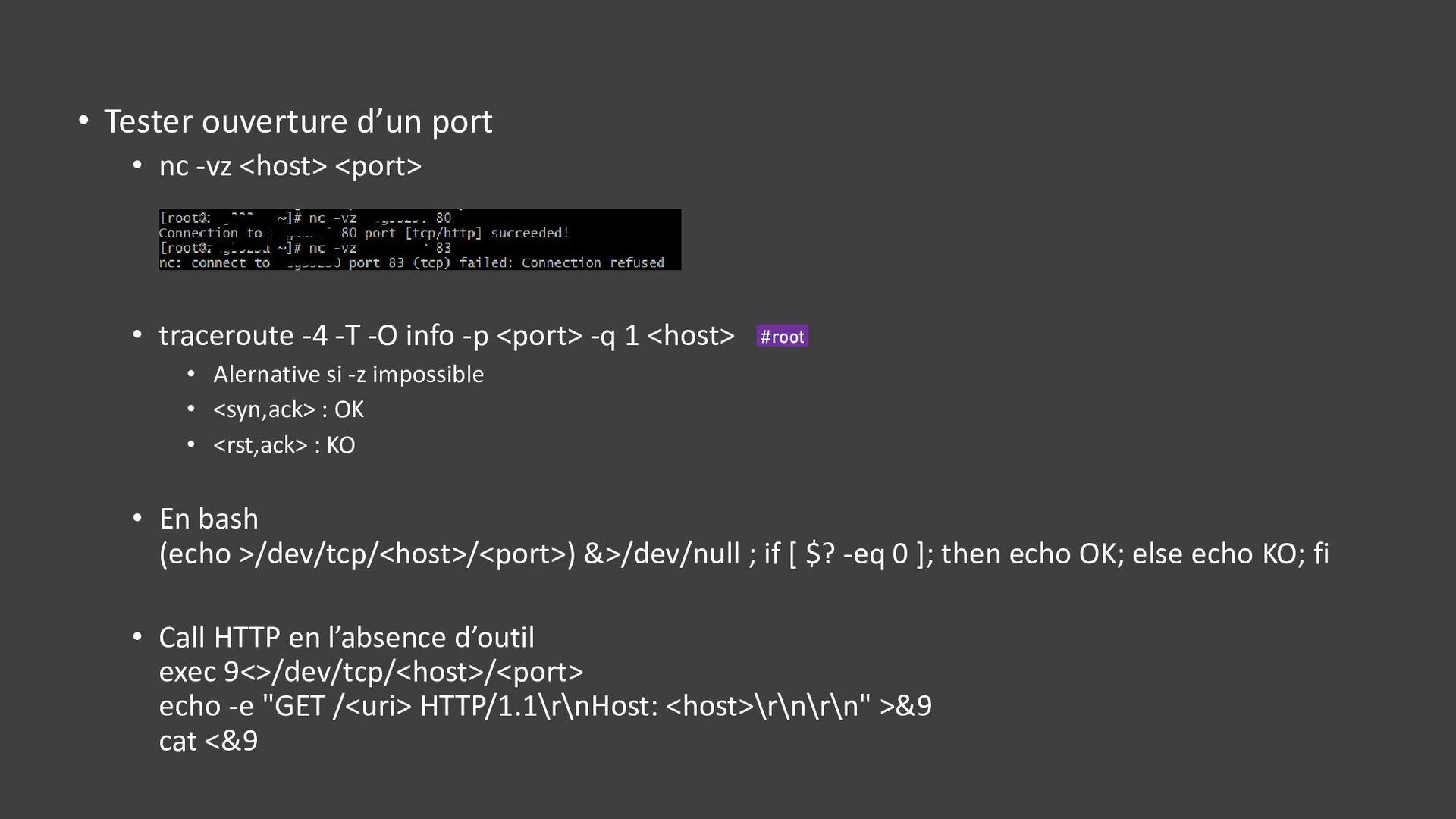
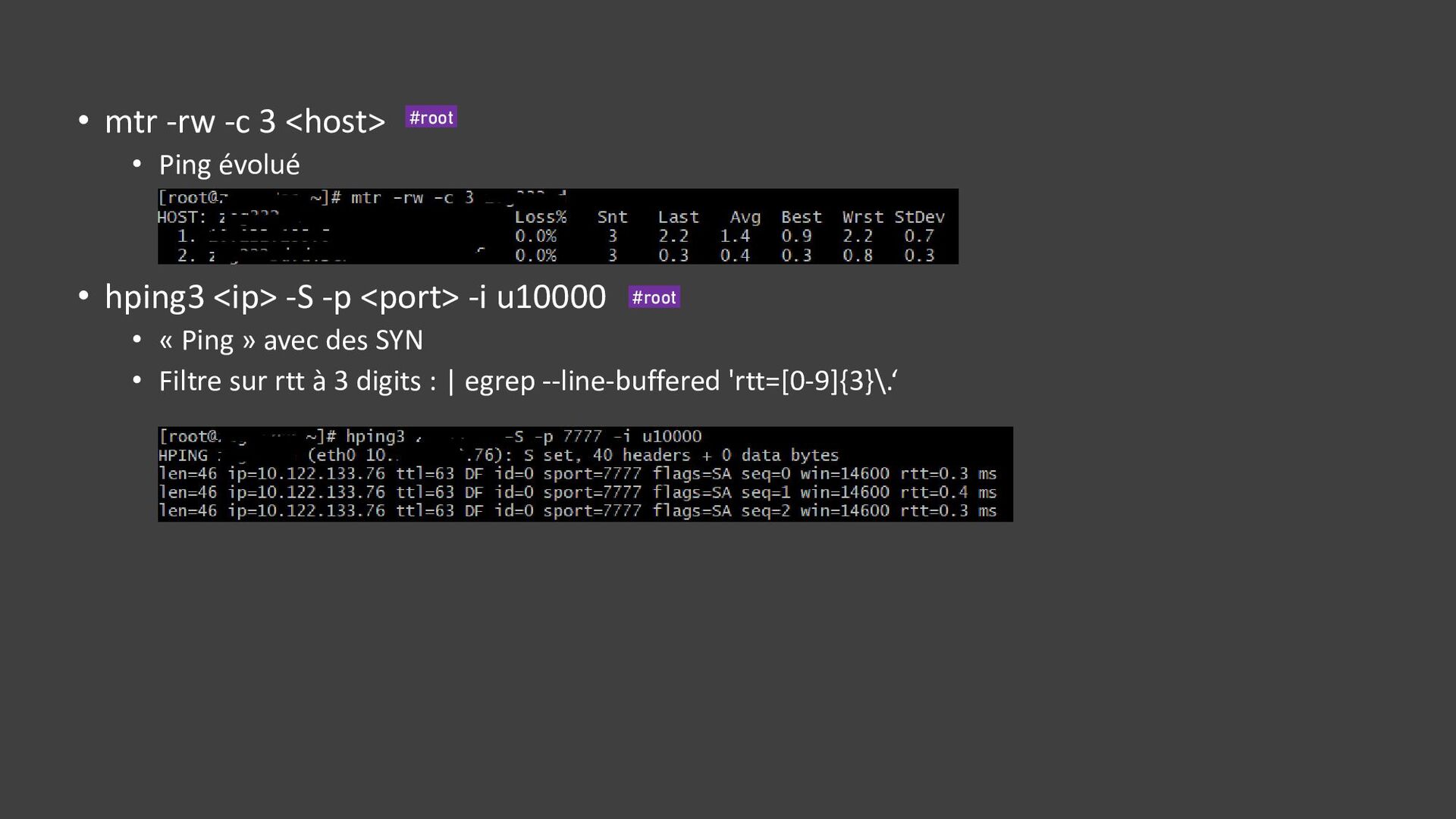
![• ss -tuna[ropi] • Connexions • Etat des connexions :](https://files.speakerdeck.com/presentations/7c862d9e04a243b8a393e547abc1e1fe/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
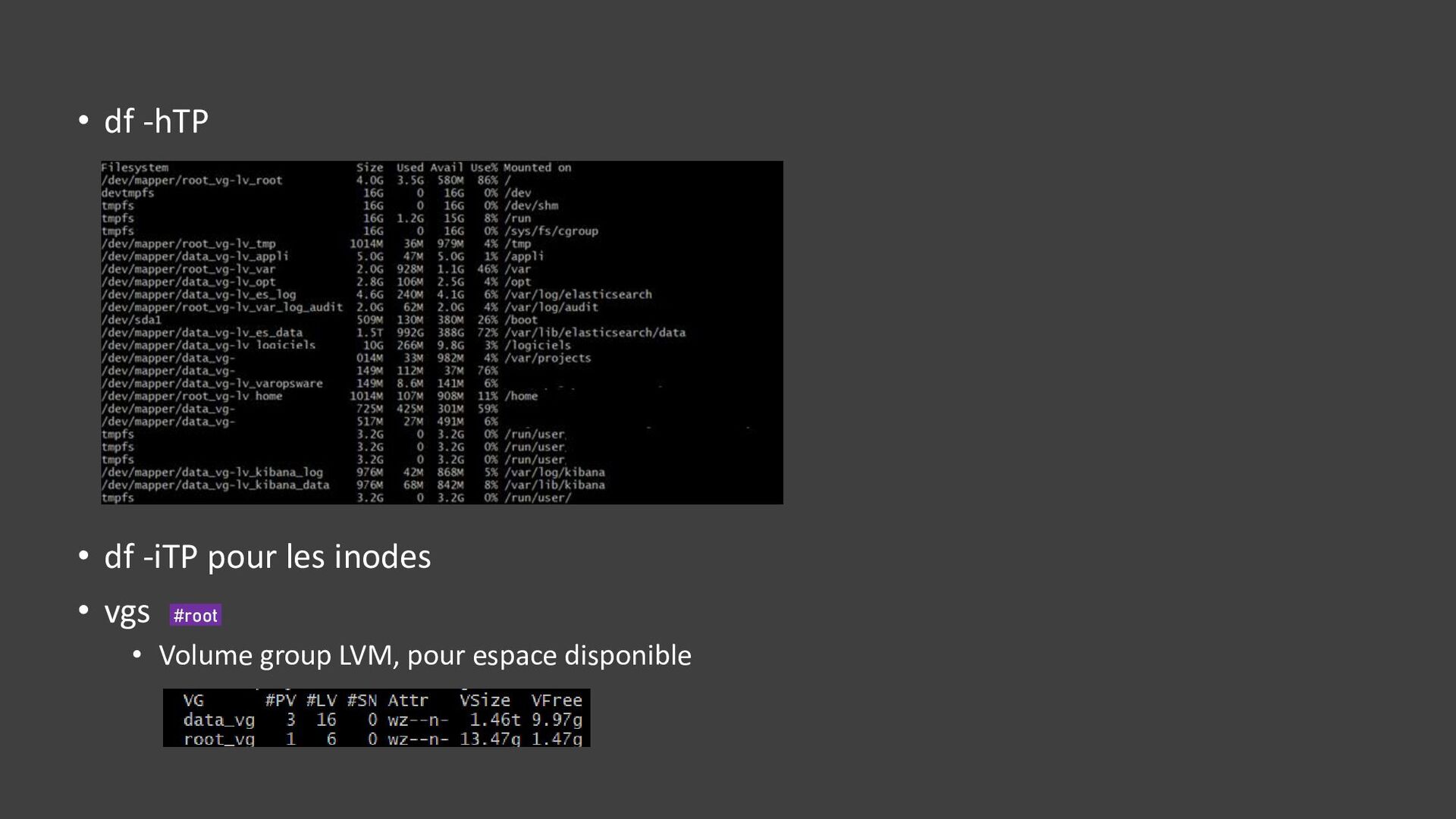{kind=link}
{kind=link}
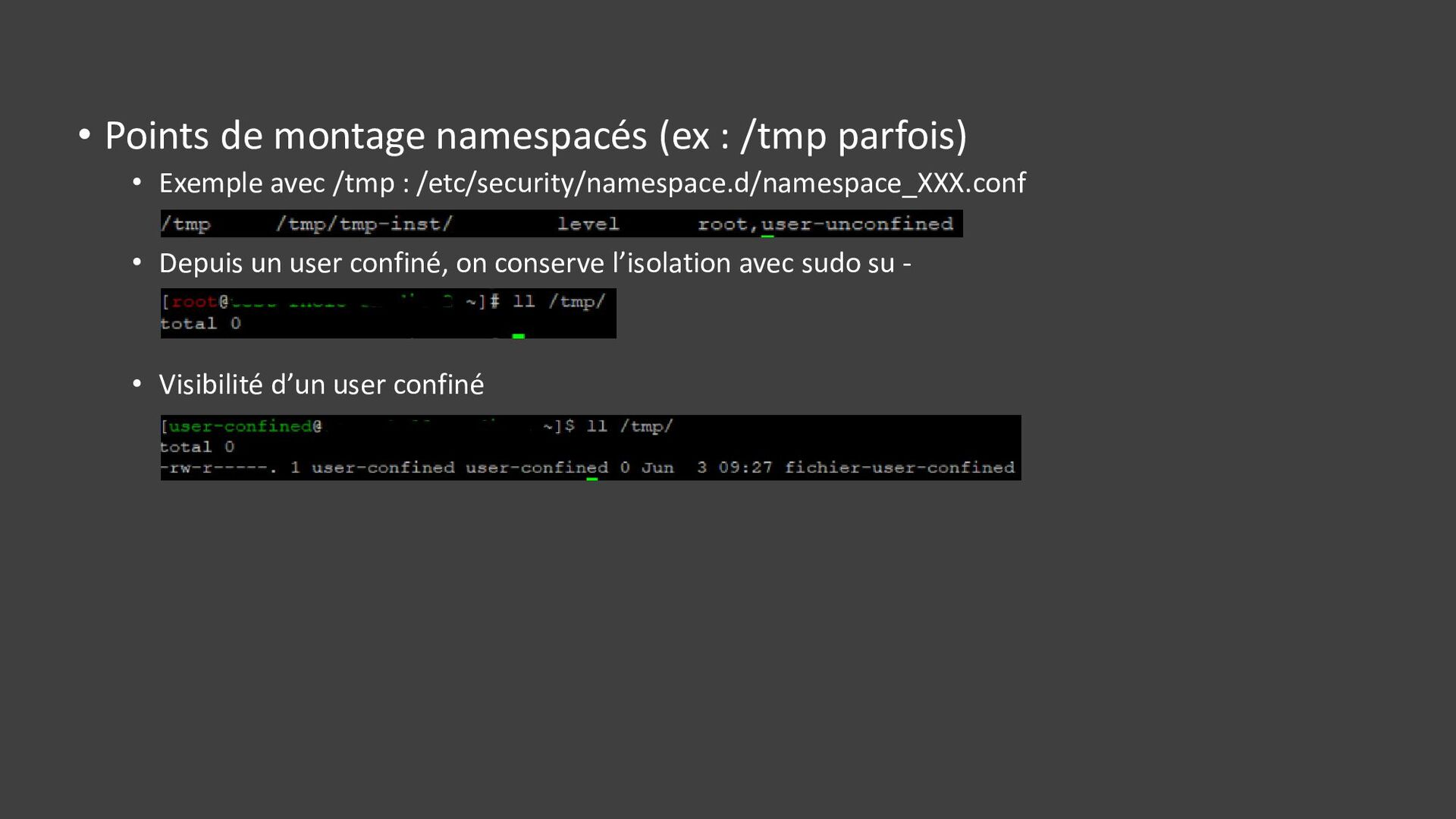{kind=link}
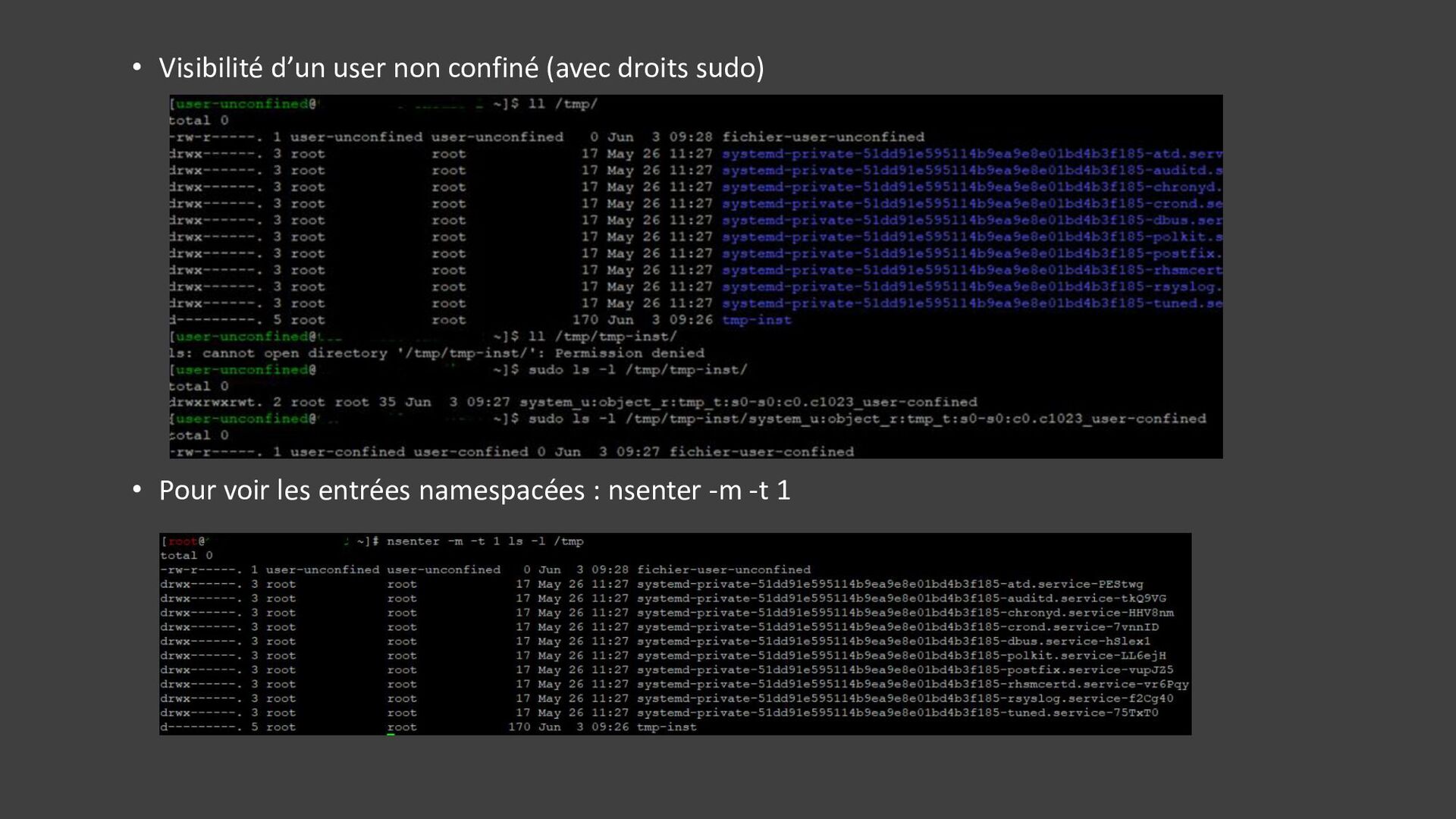{kind=link}
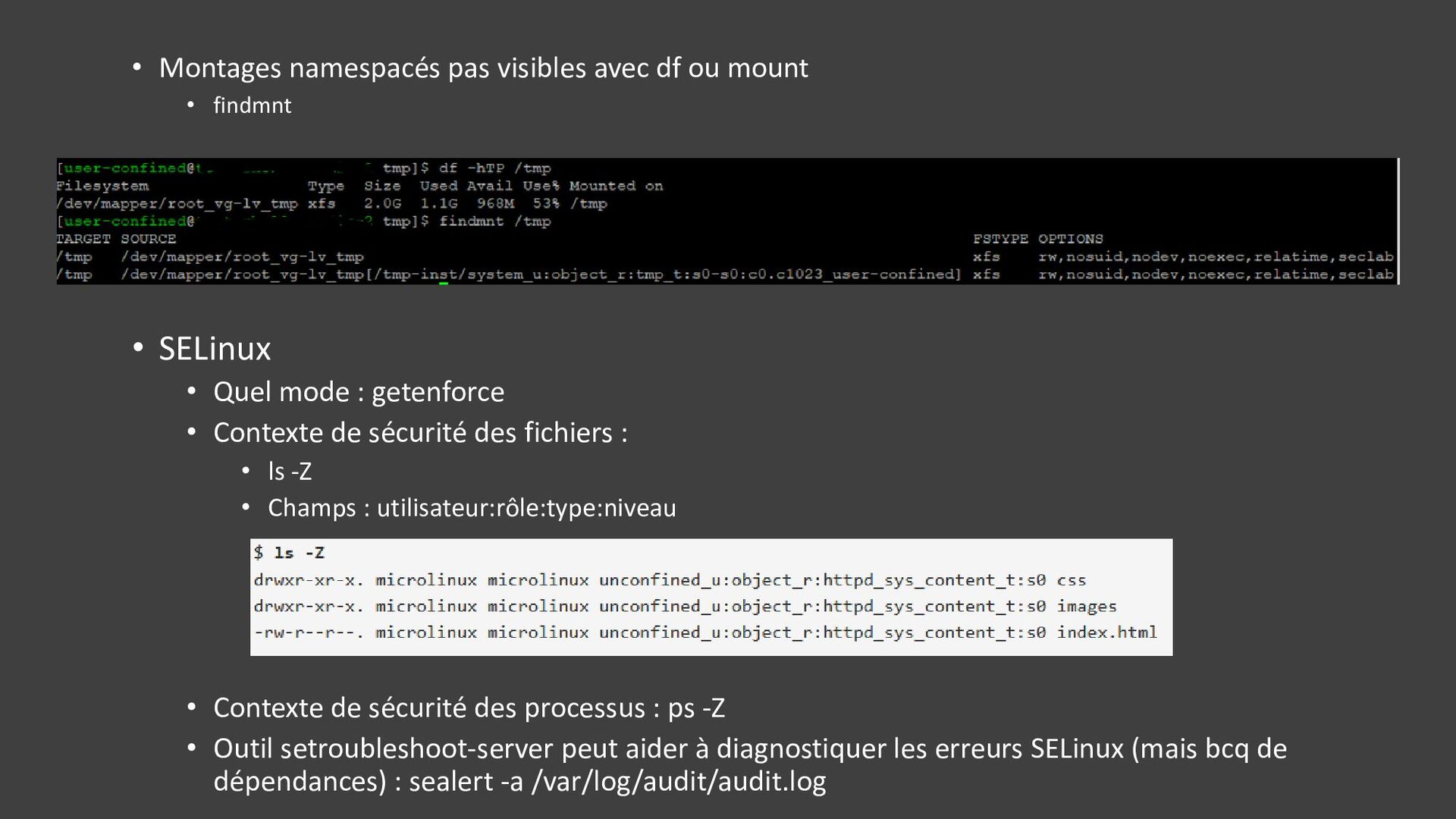{kind=link}
![• lsof -P [-p <pid>] • Fichiers ouverts [par process]](https://files.speakerdeck.com/presentations/7c862d9e04a243b8a393e547abc1e1fe/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
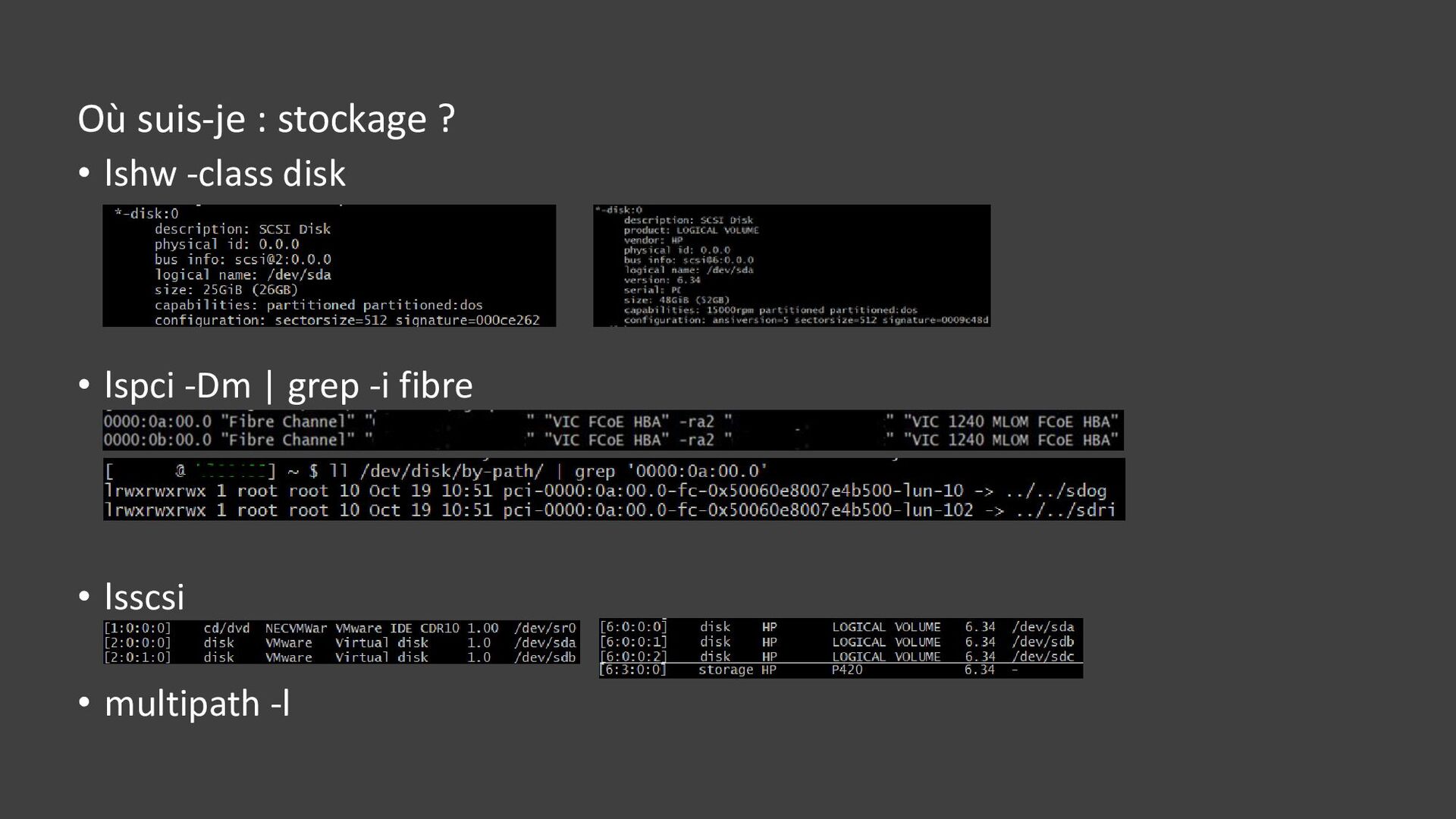{kind=link}
{kind=link}
{kind=link}
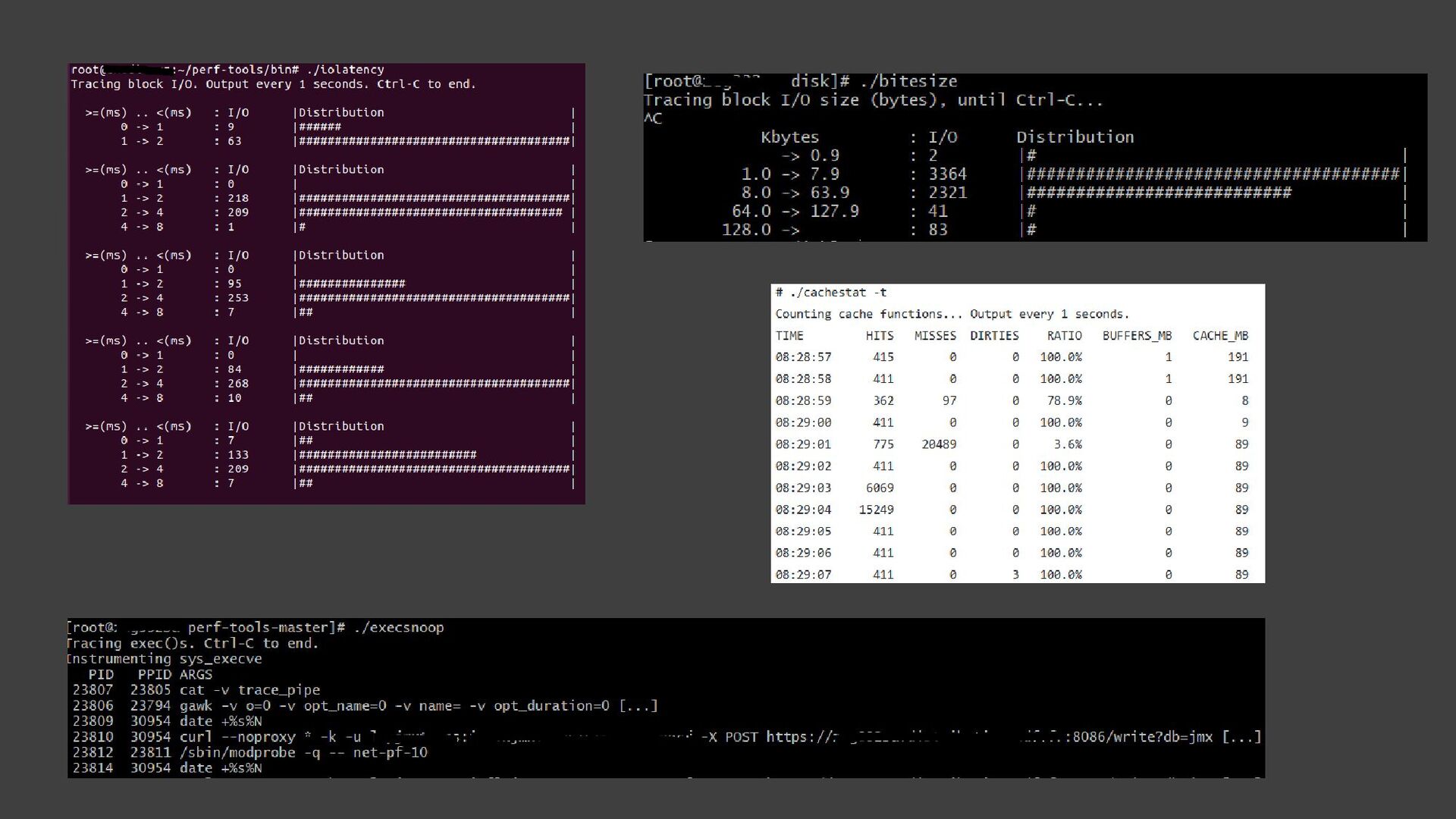{kind=link}
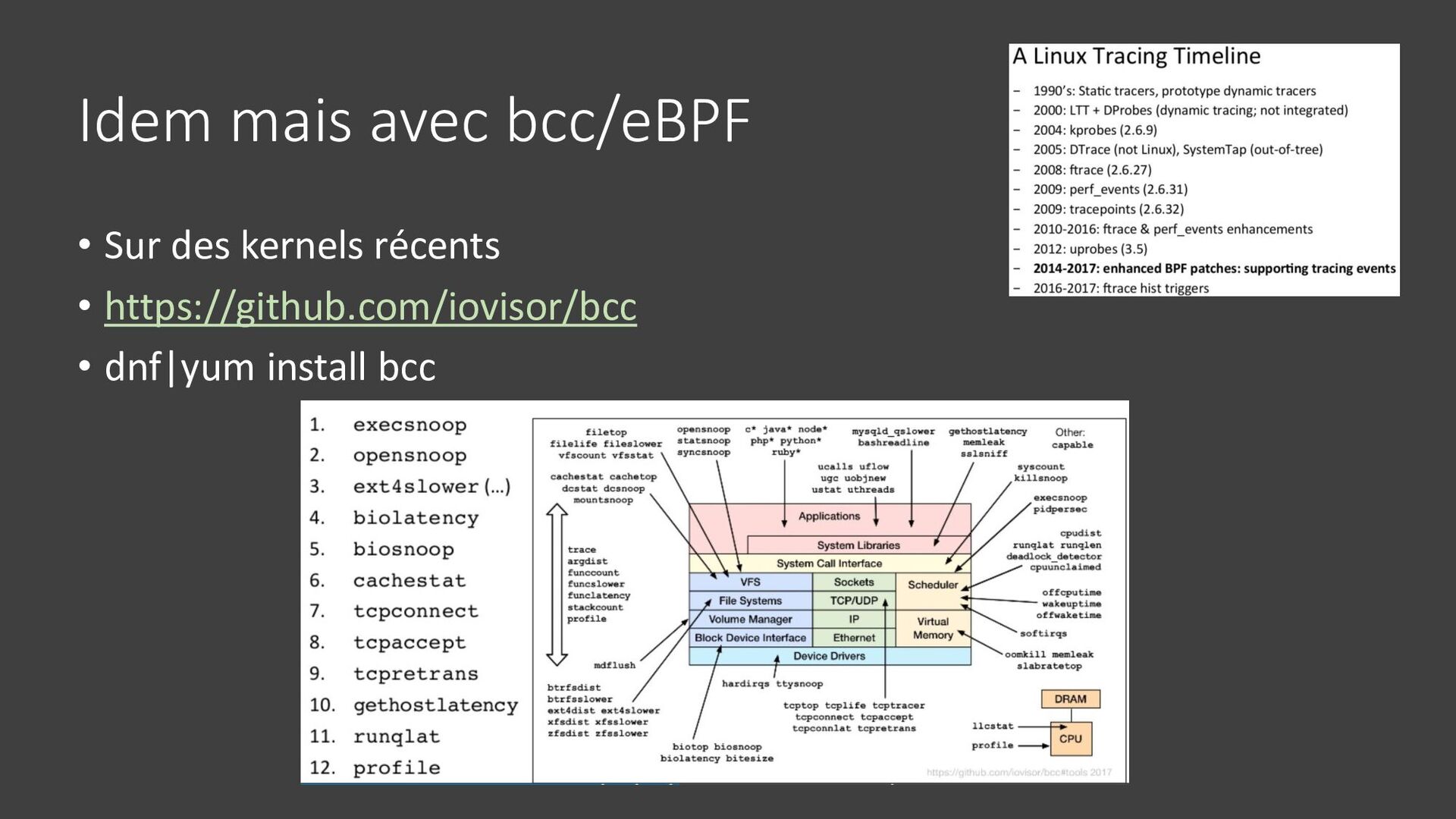{kind=link}
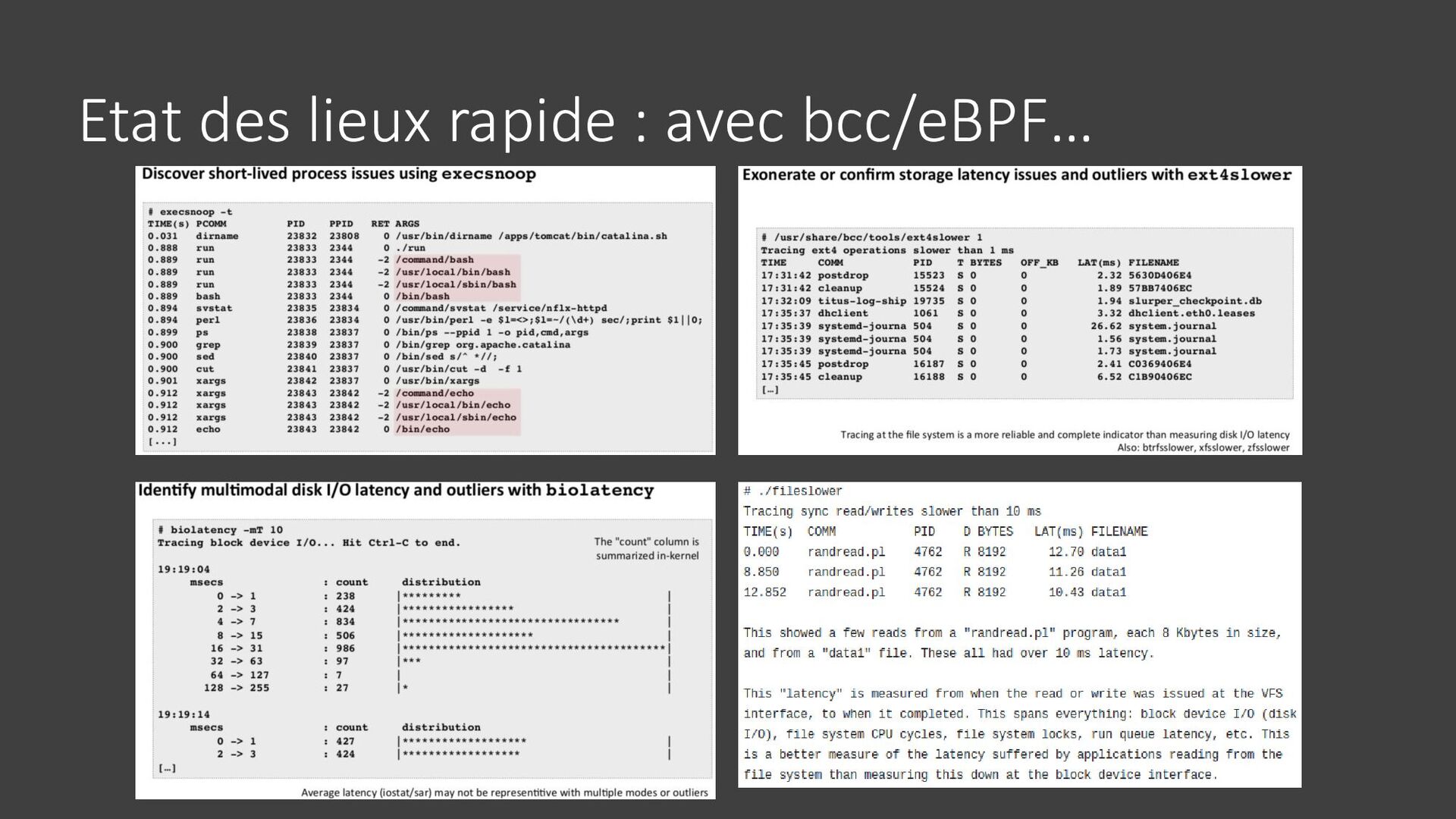{kind=link}
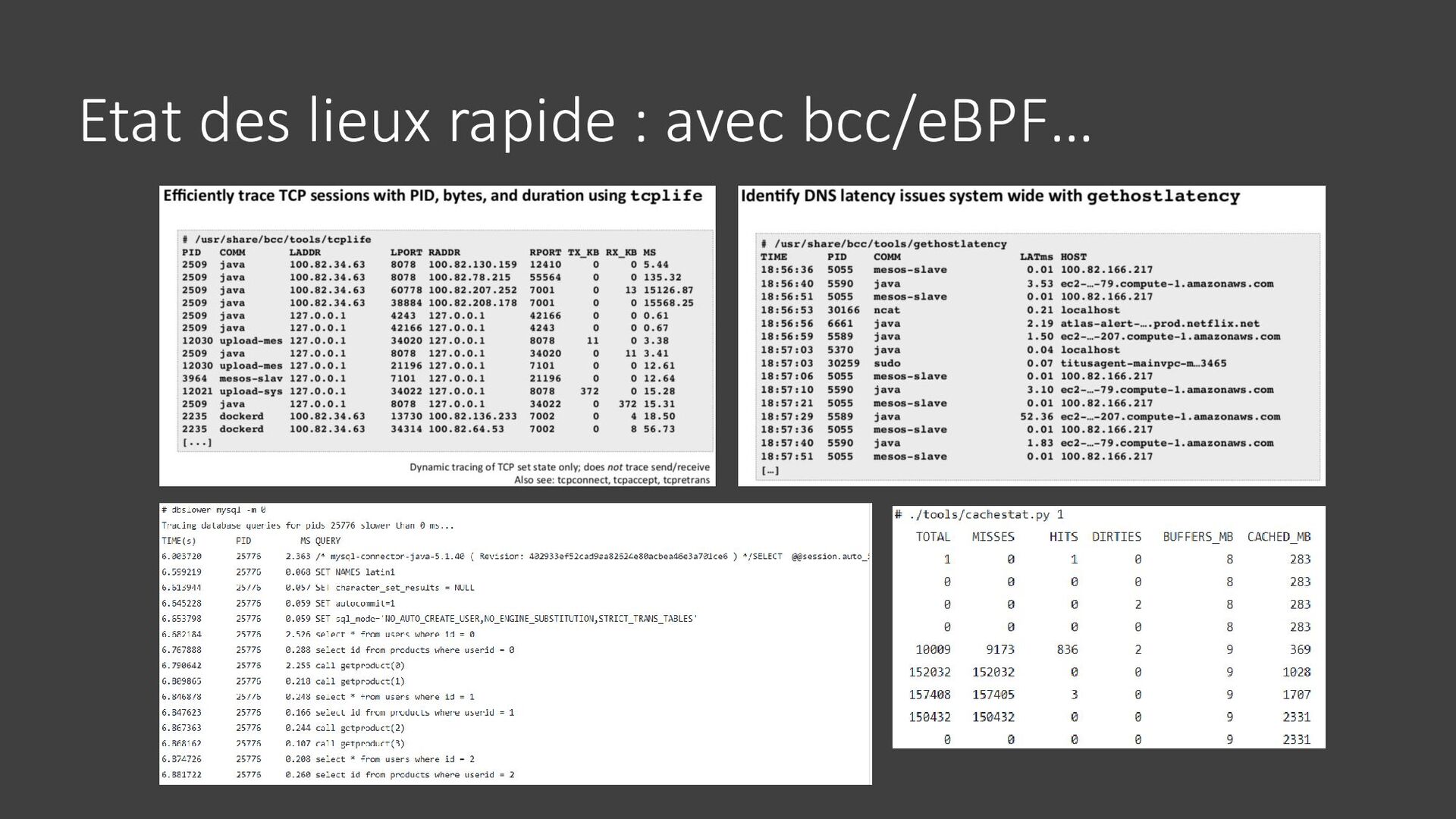{kind=link}
{kind=link}
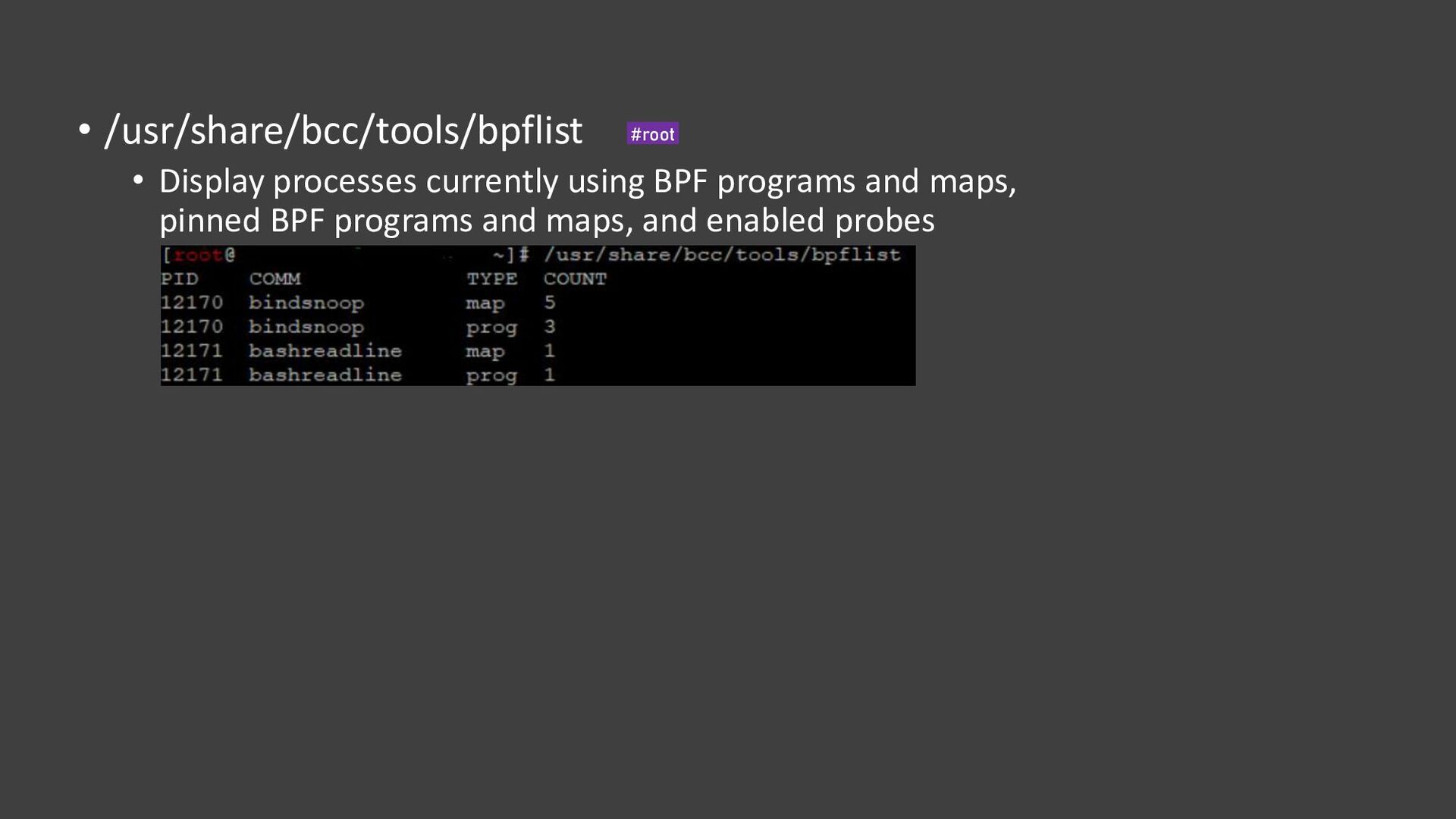{kind=link}
{kind=link}
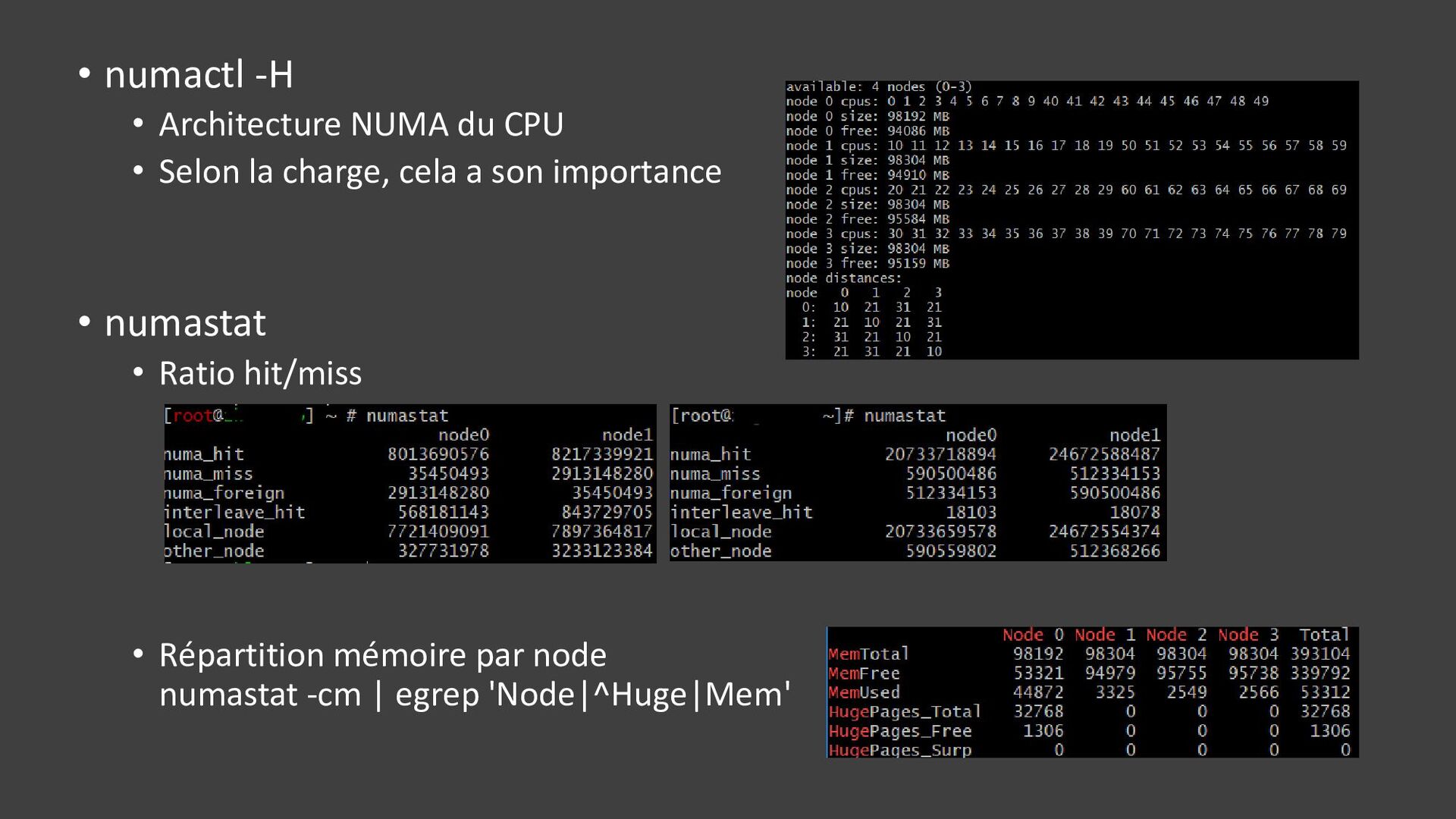{kind=link}
{kind=link}
{kind=link}
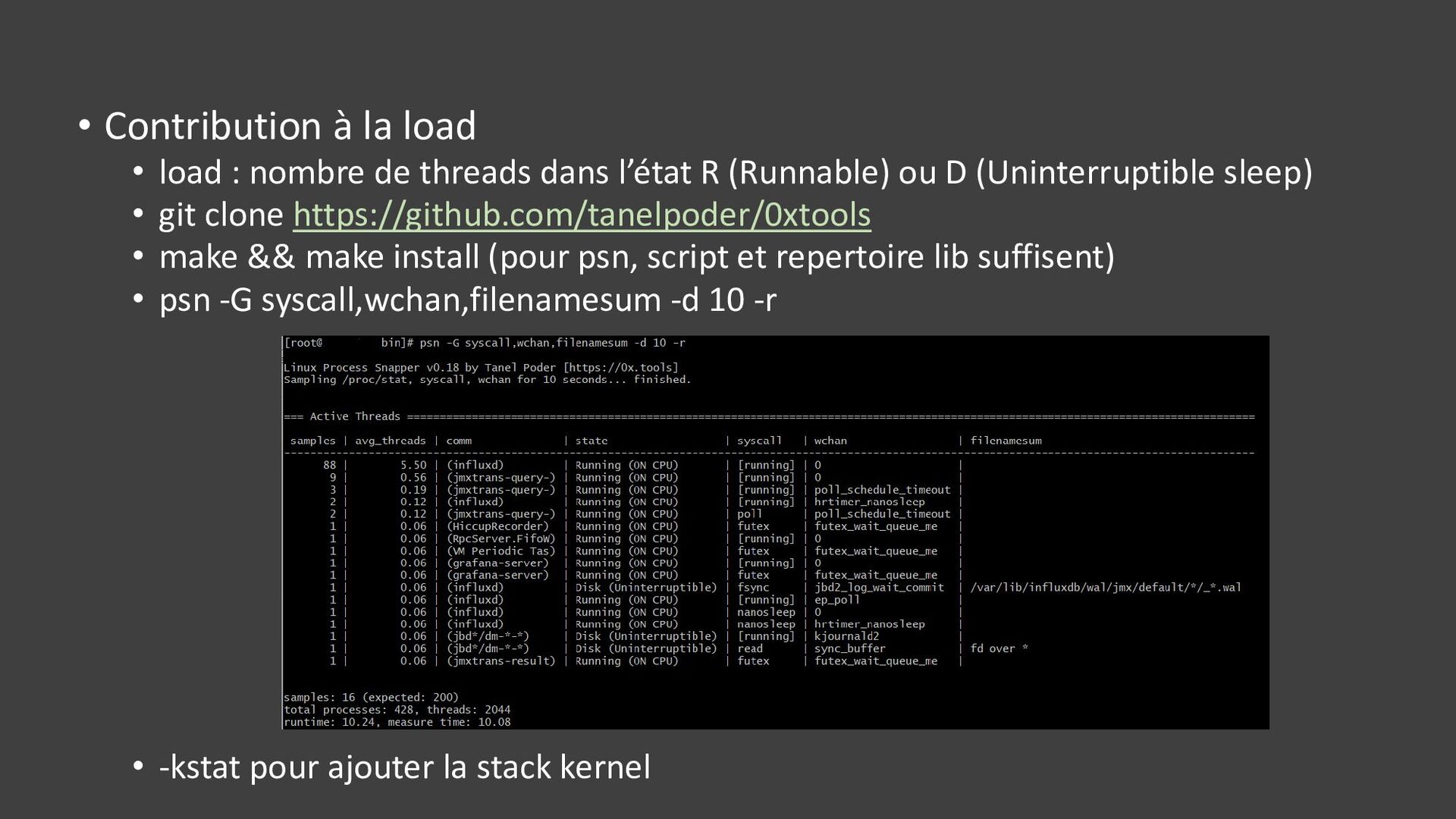{kind=link}
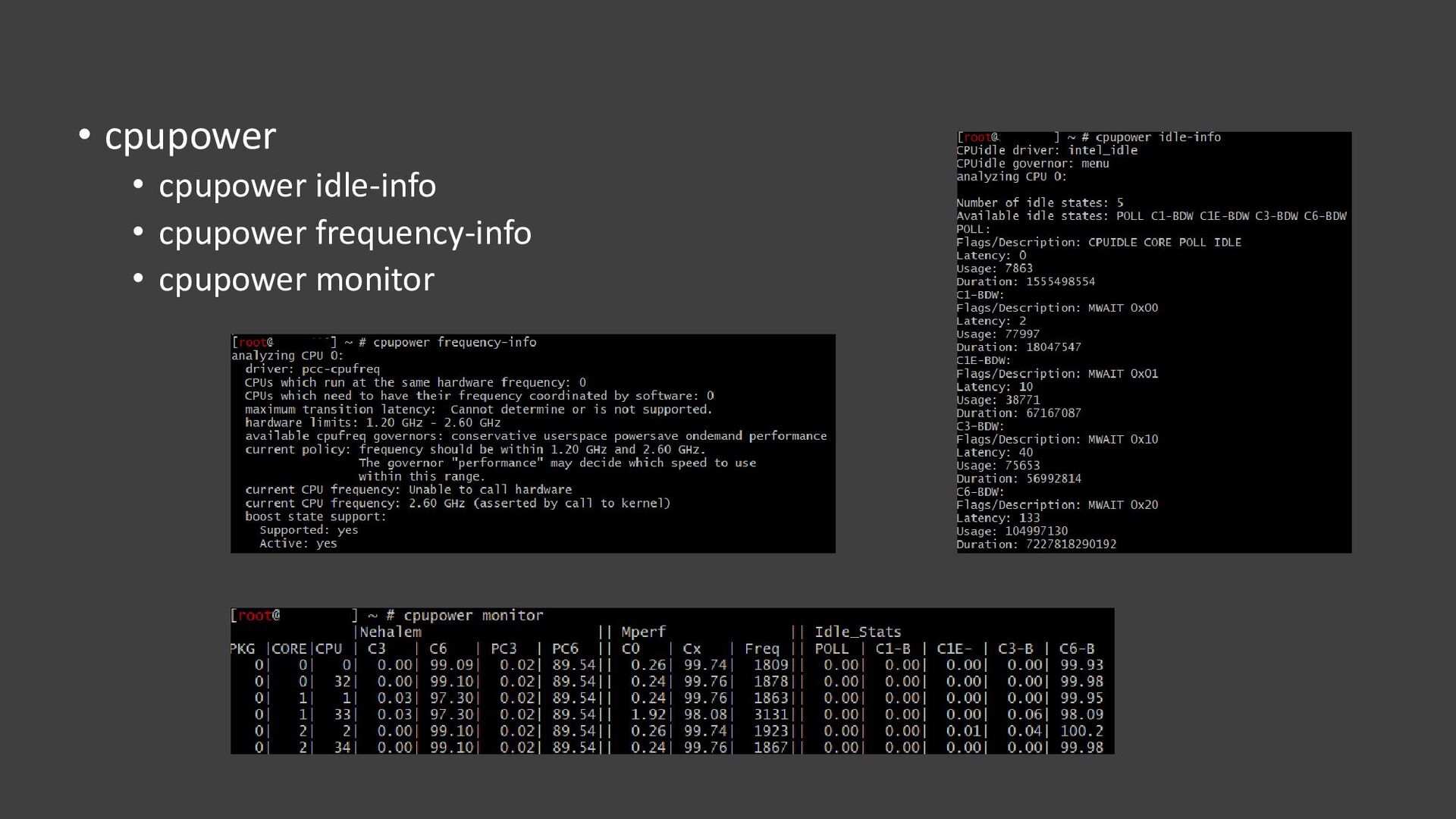{kind=link}
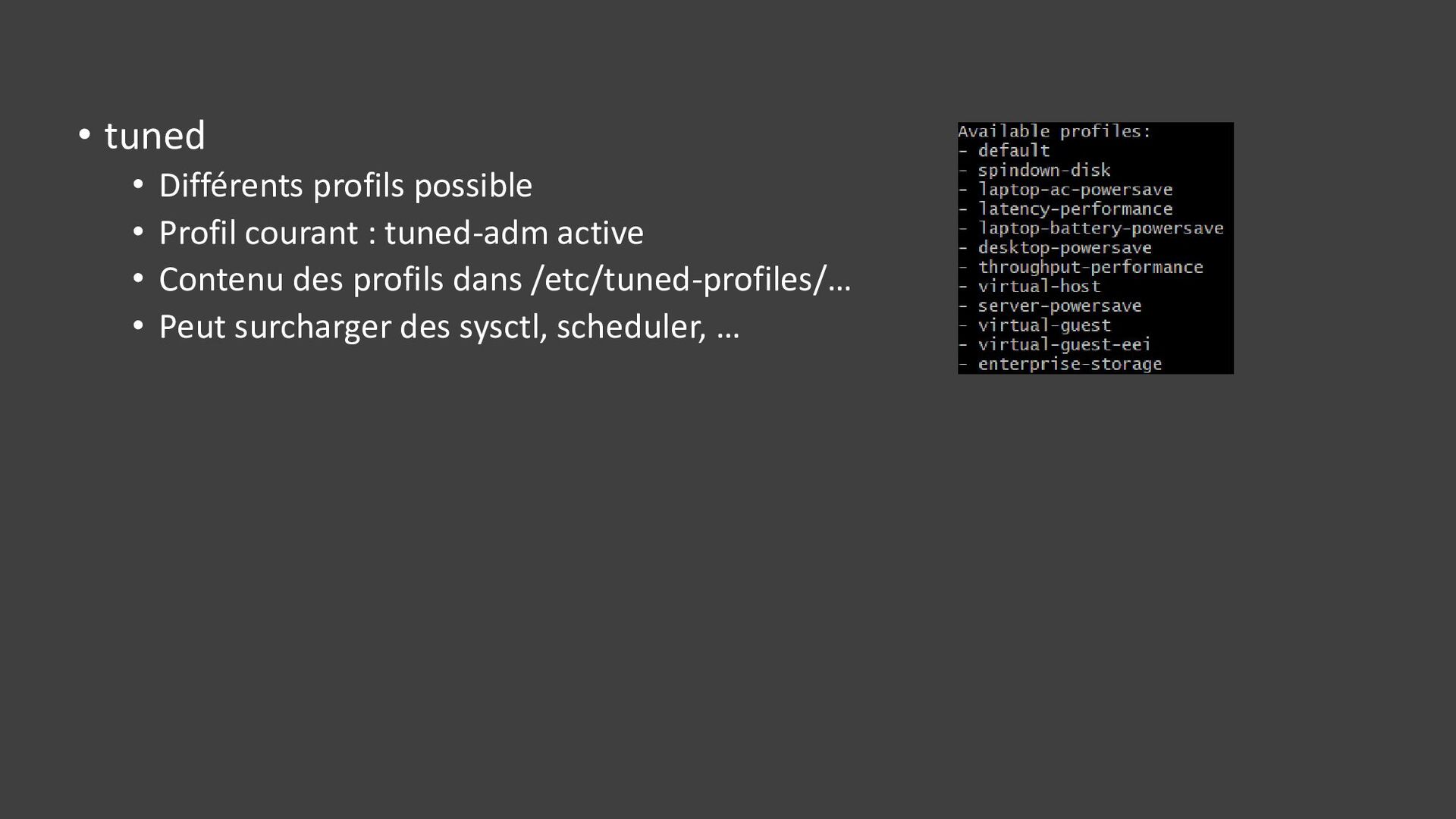{kind=link}
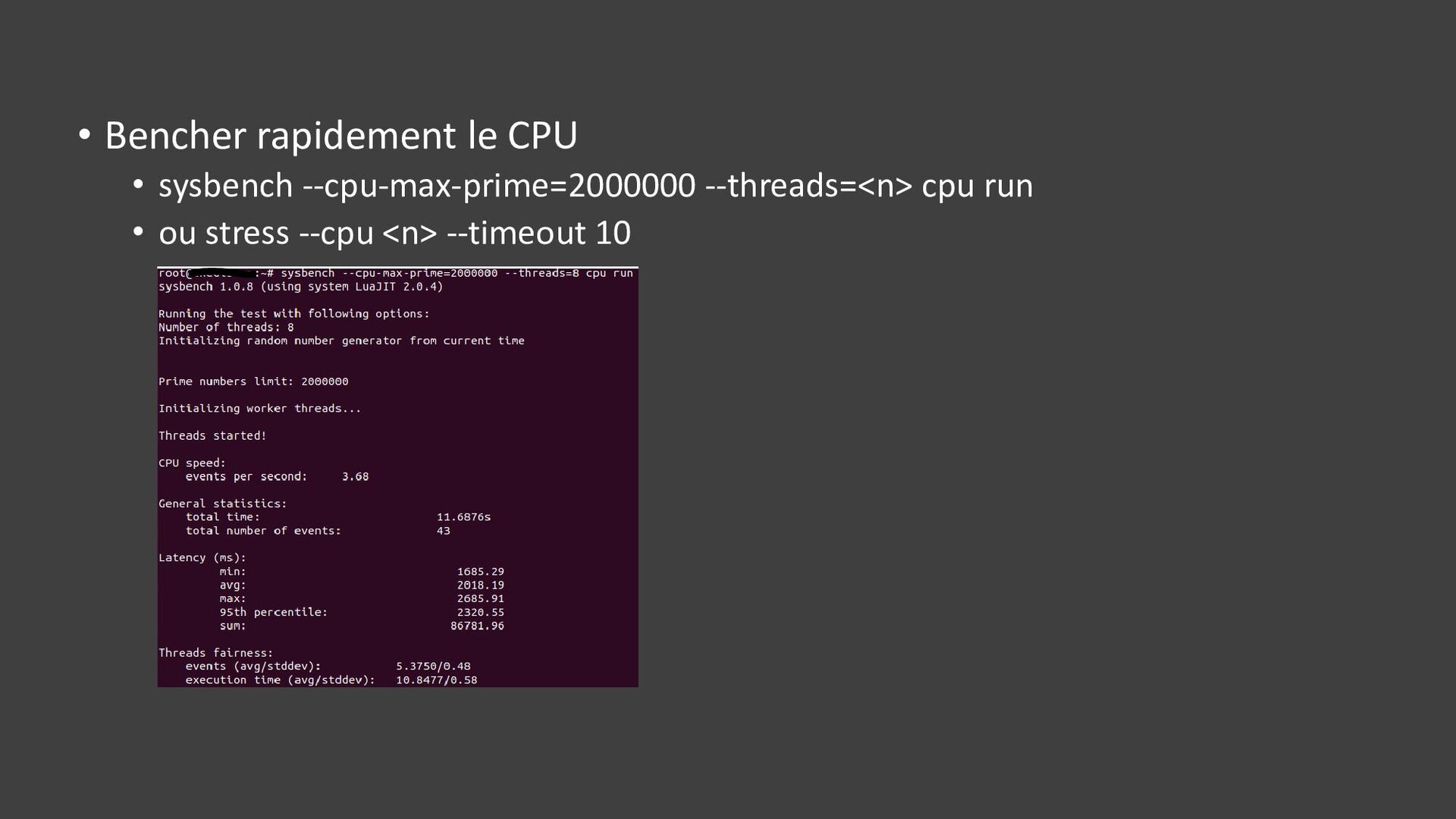{kind=link}
{kind=link}
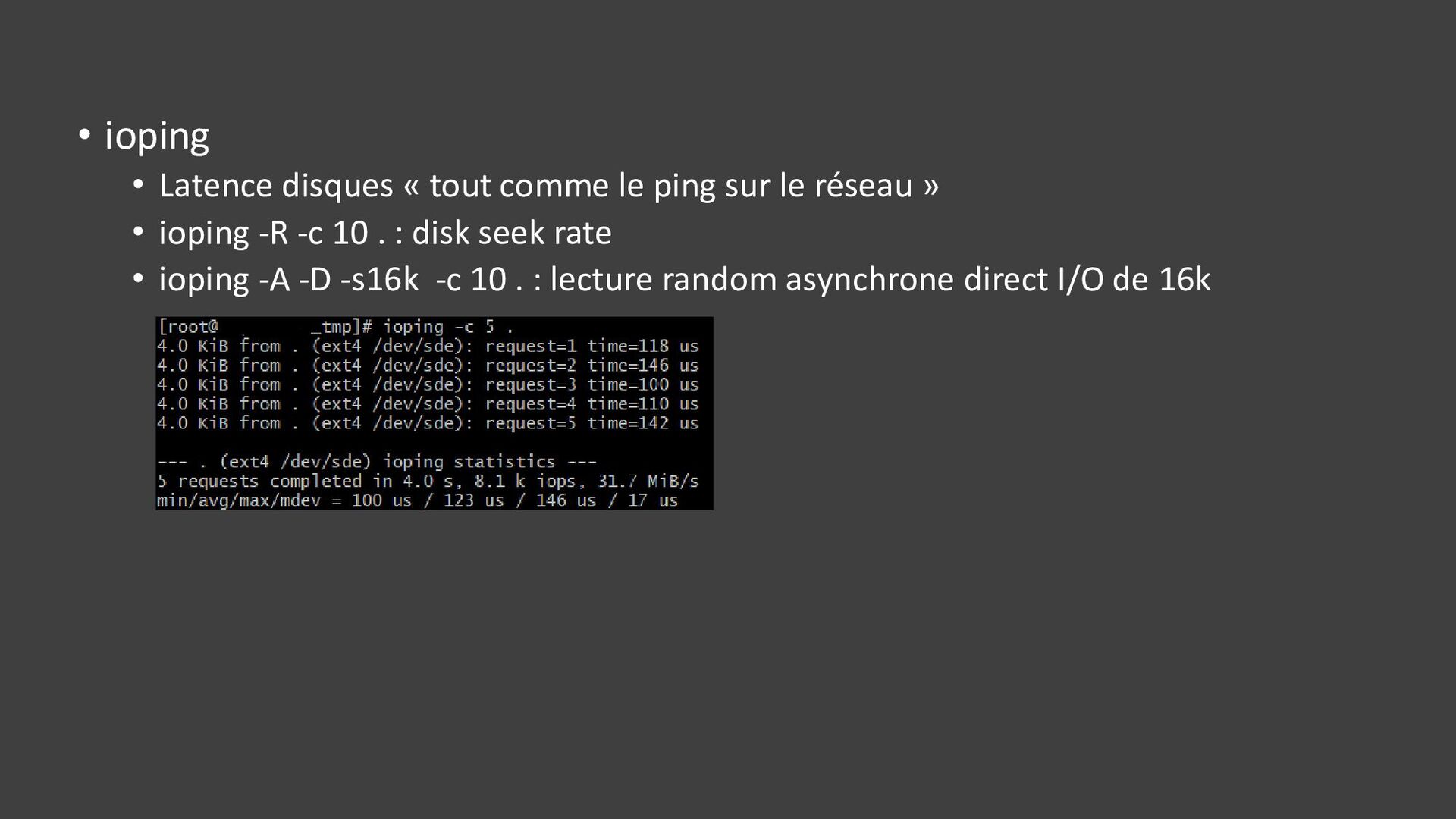{kind=link}
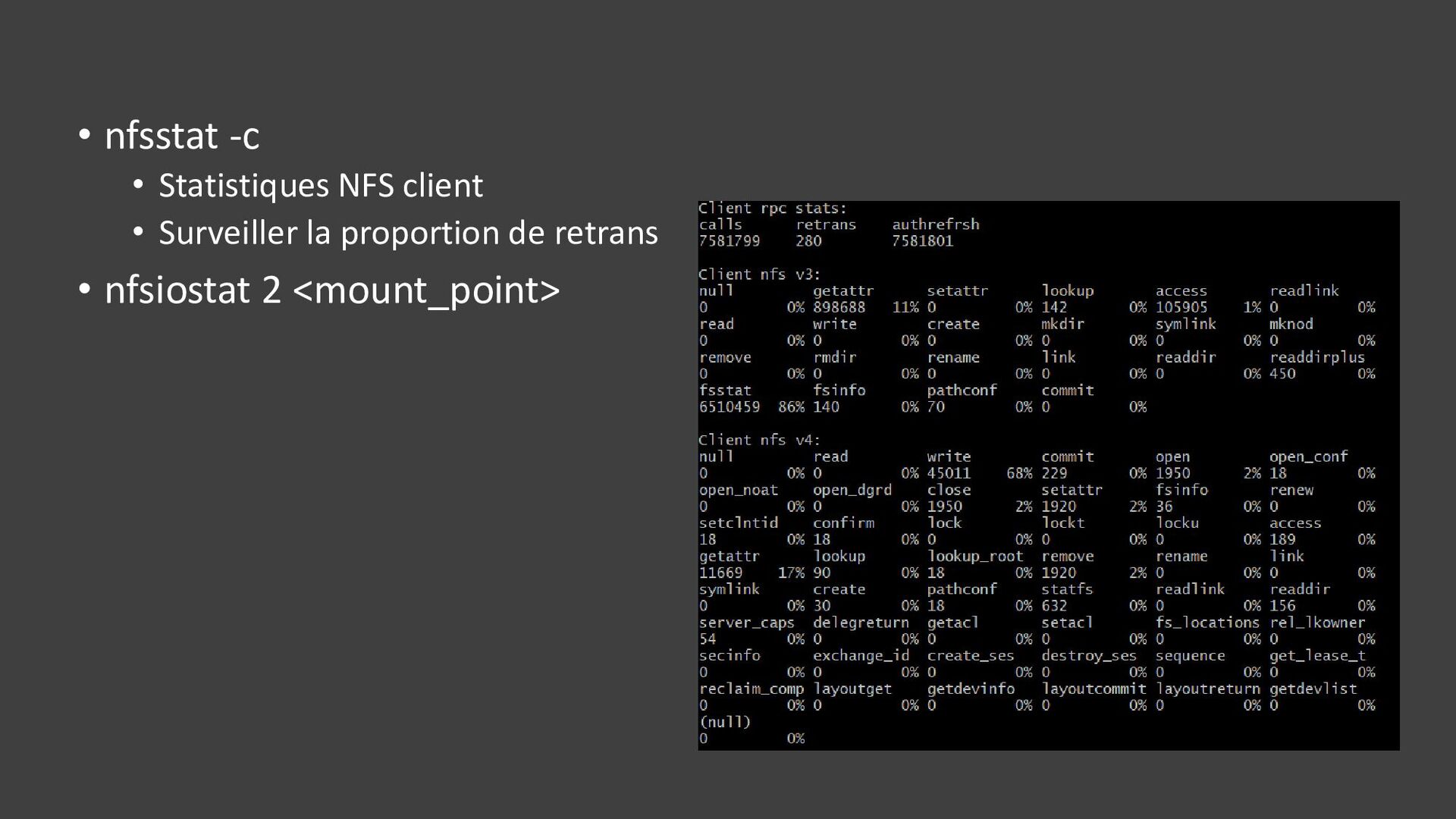{kind=link}
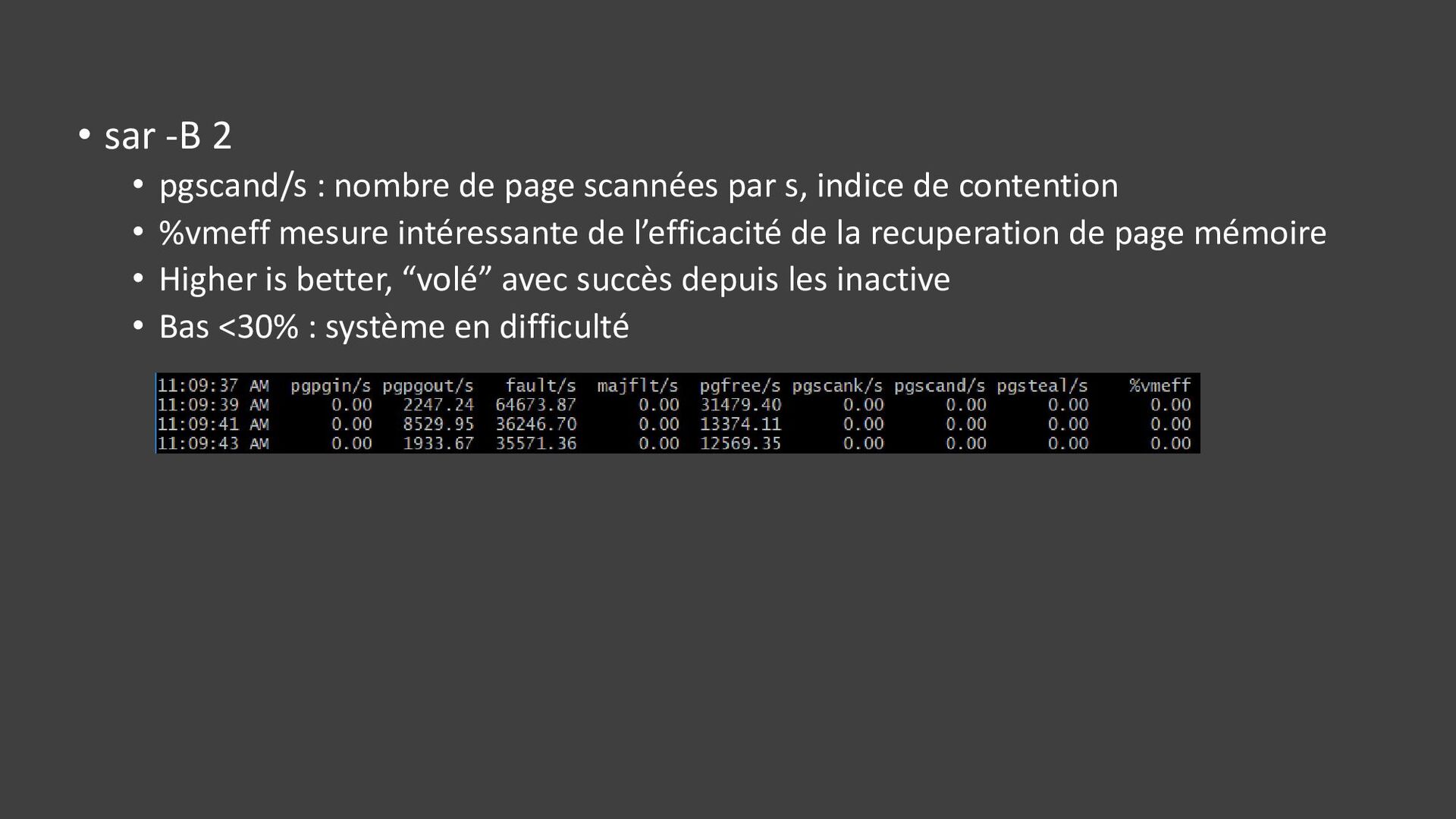{kind=link}
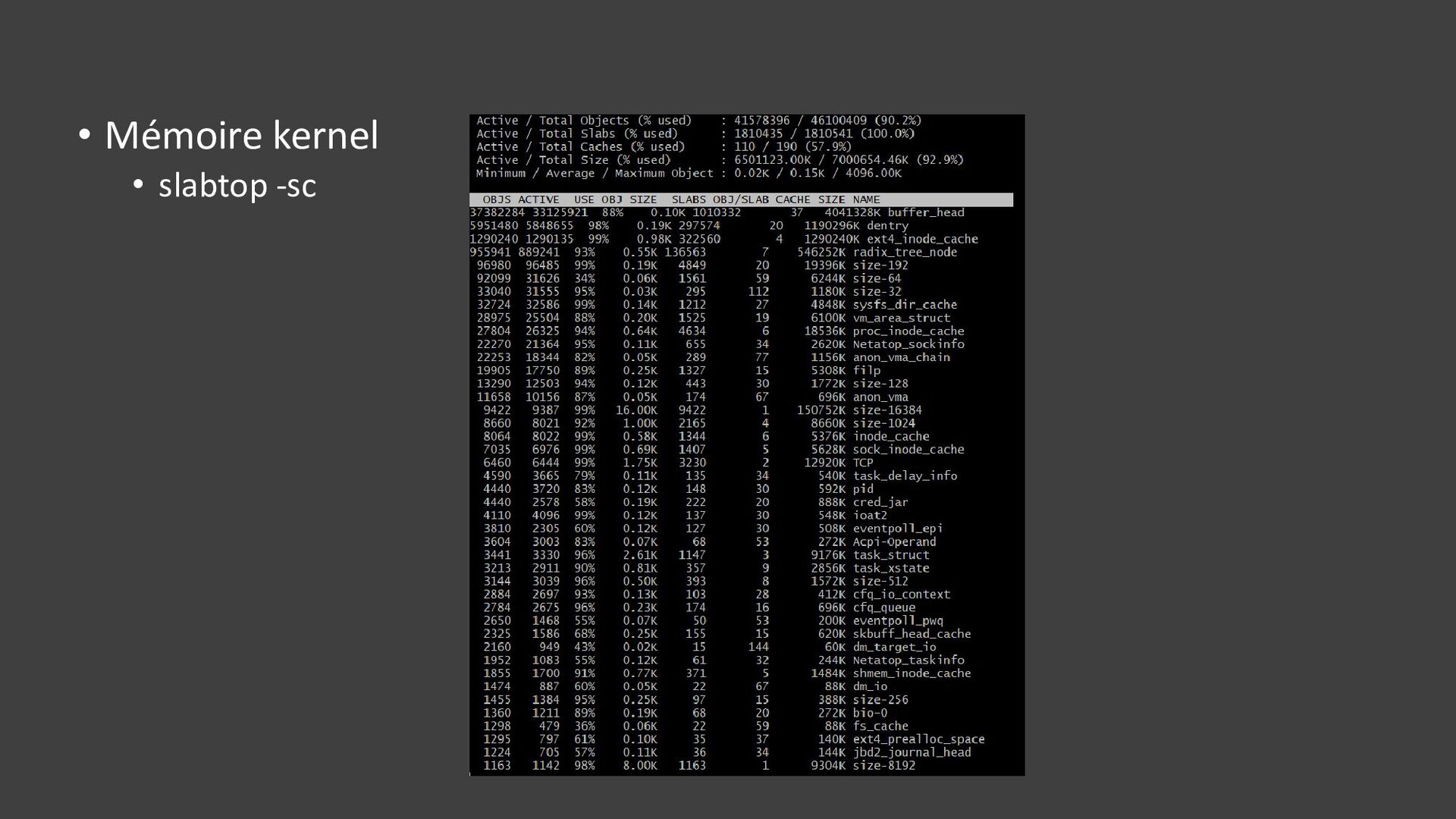{kind=link}
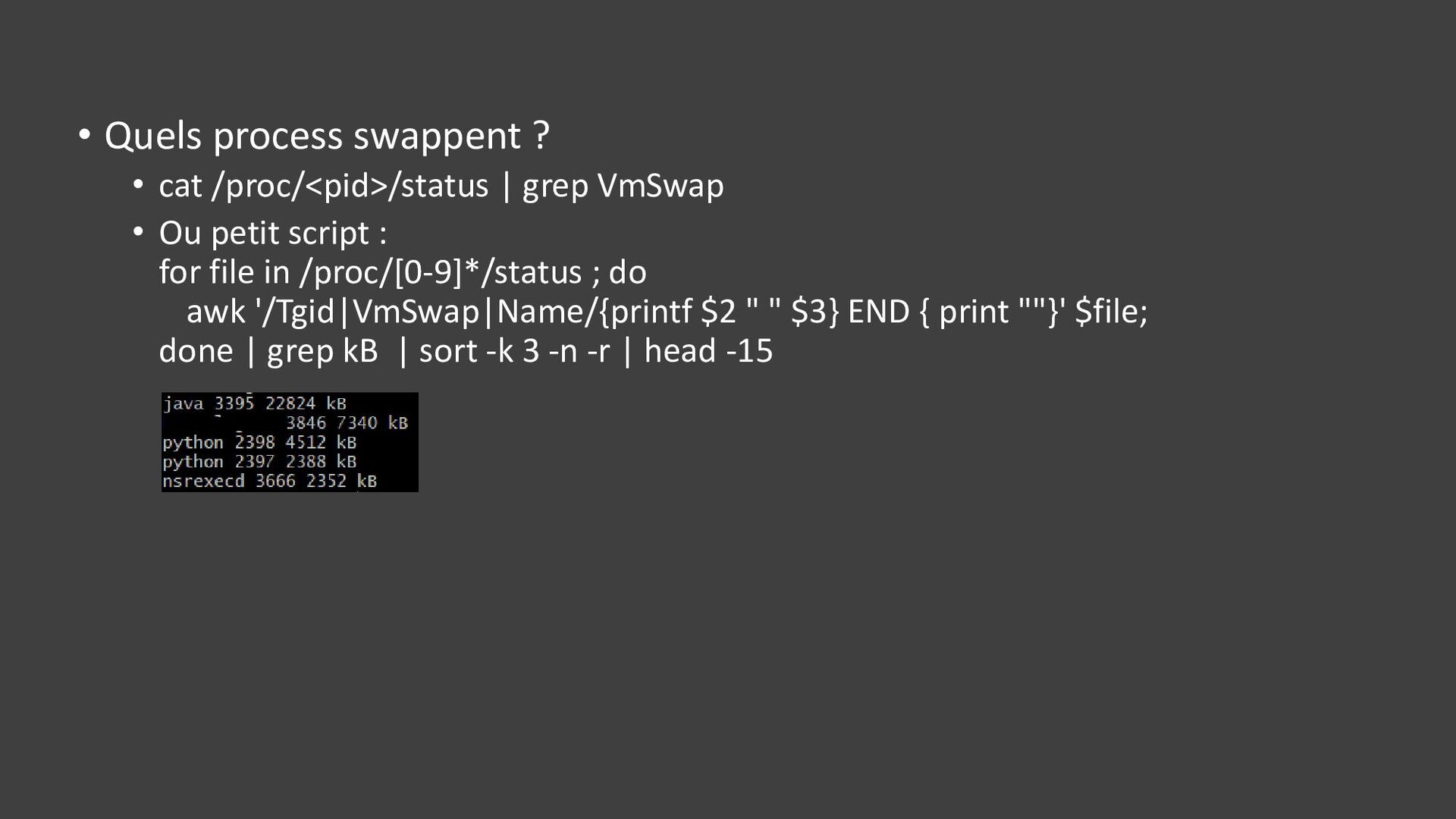{kind=link}
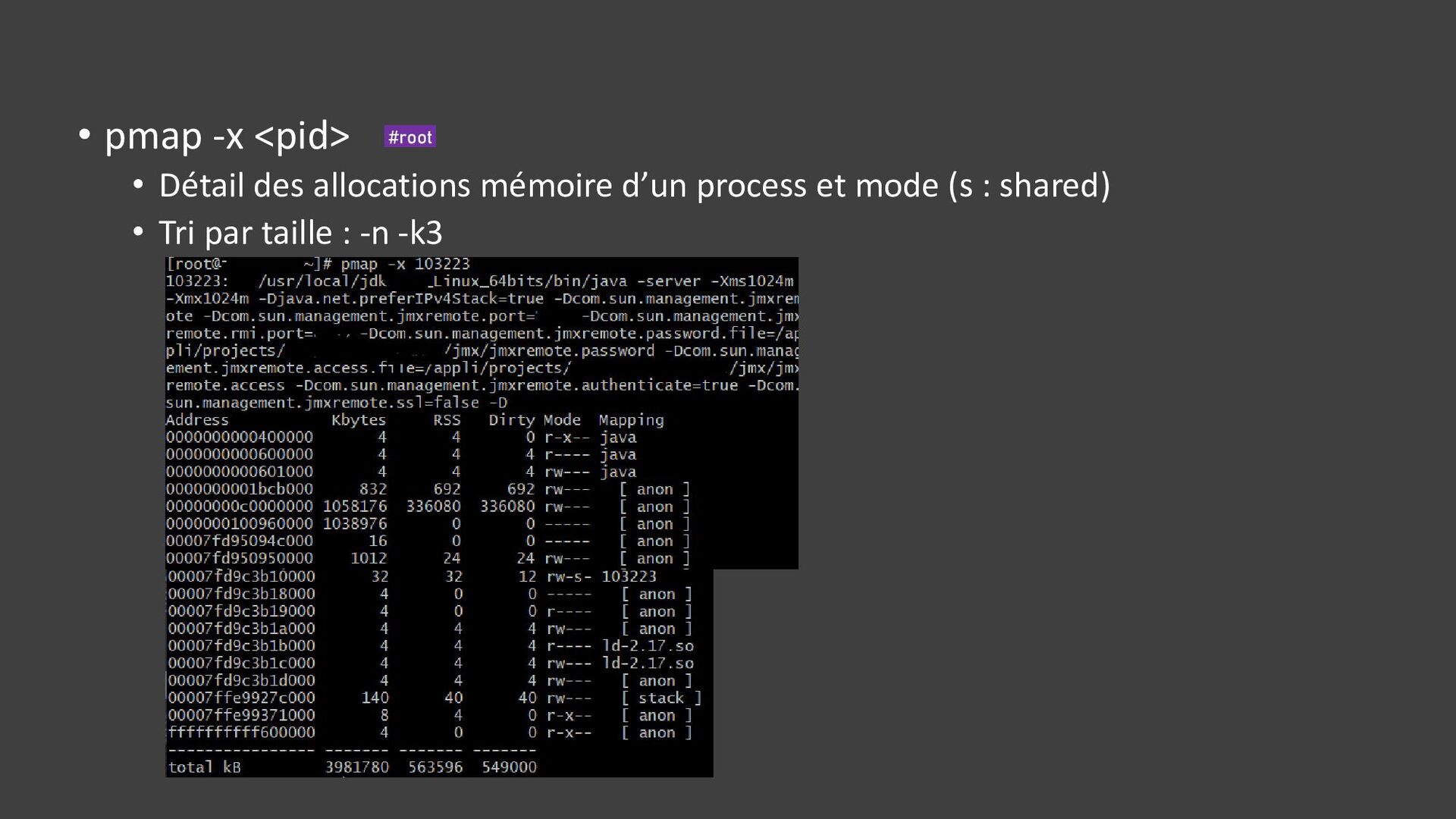{kind=link}
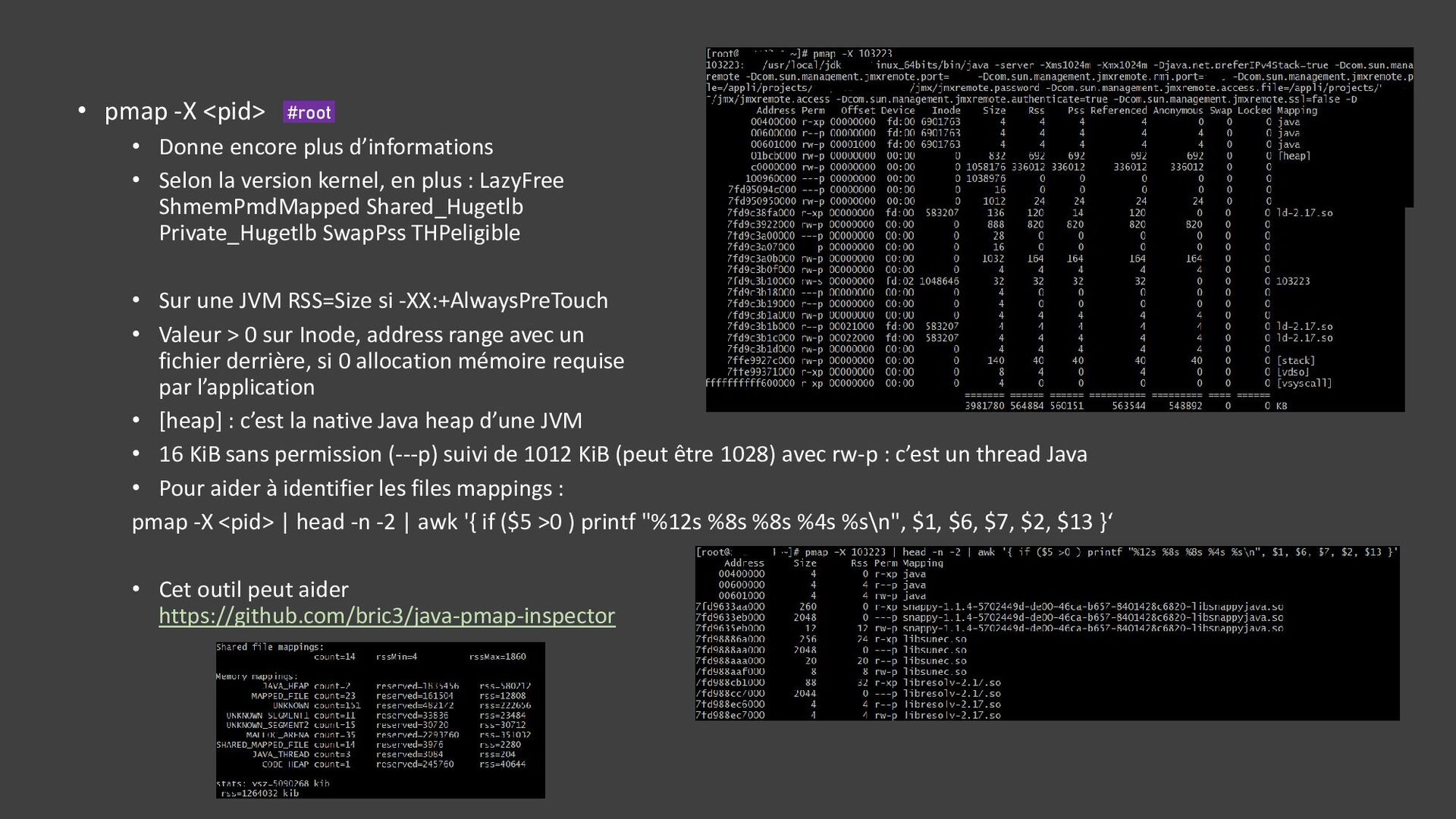{kind=link}
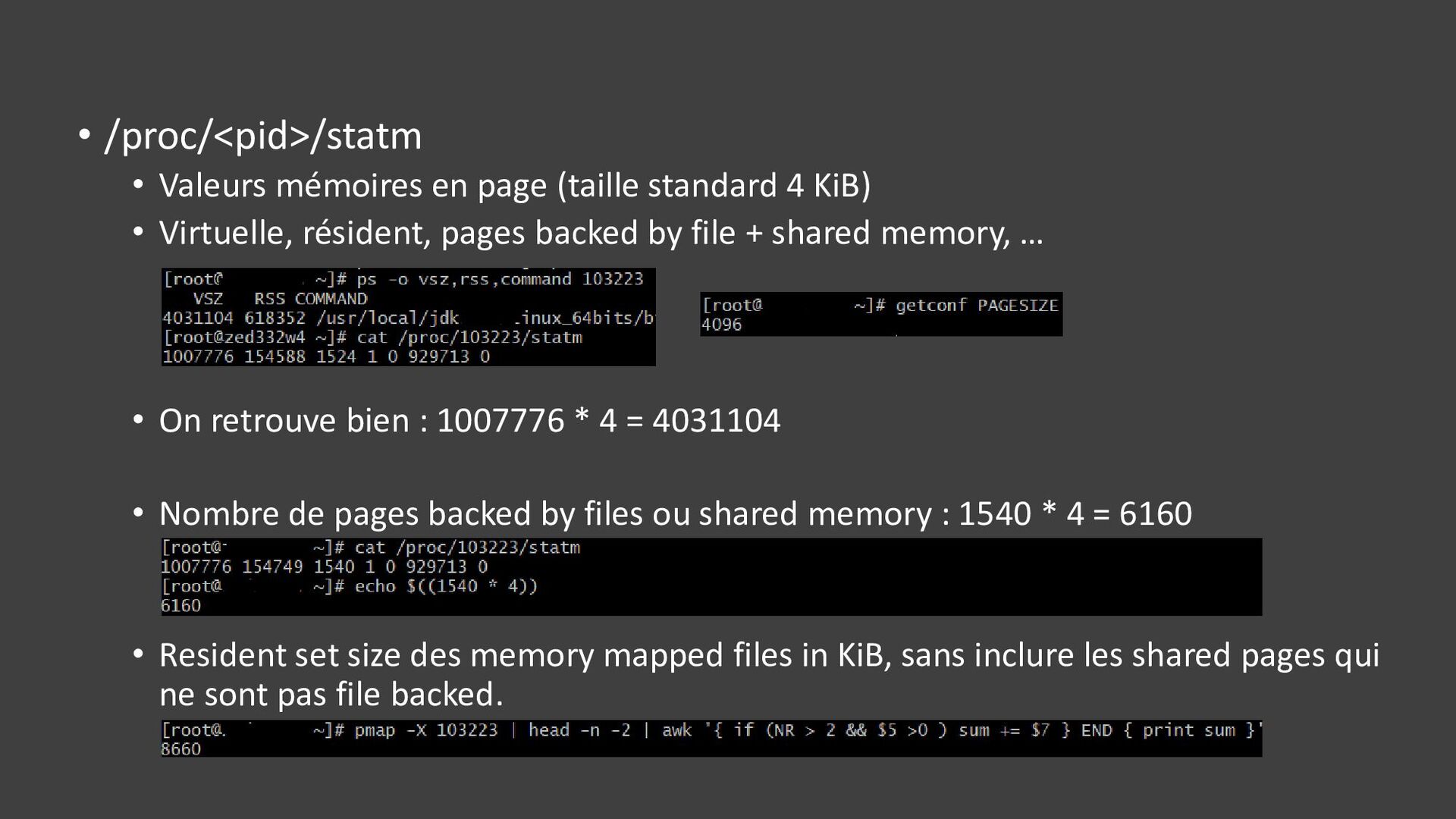{kind=link}
{kind=link}
{kind=link}
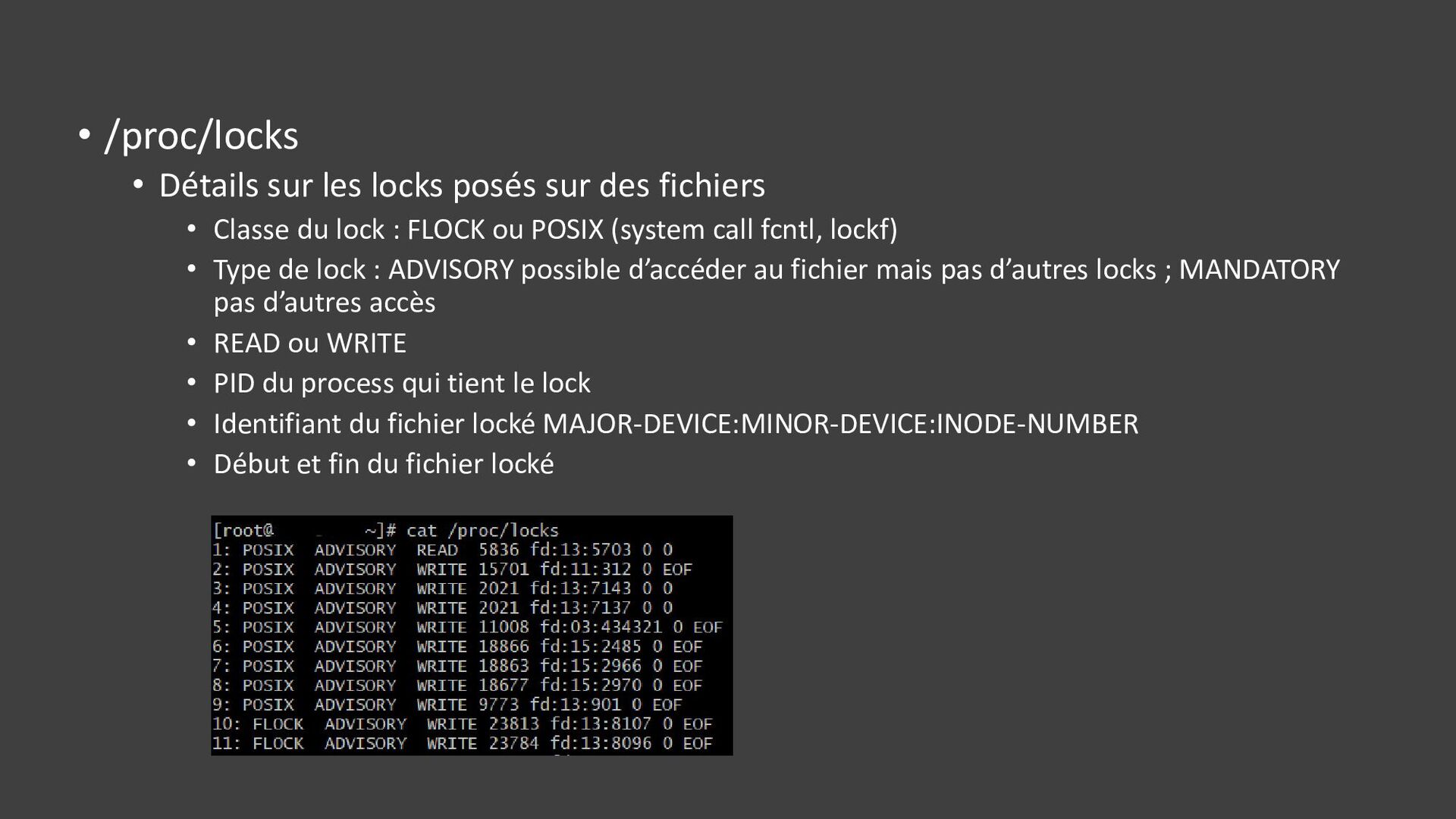{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
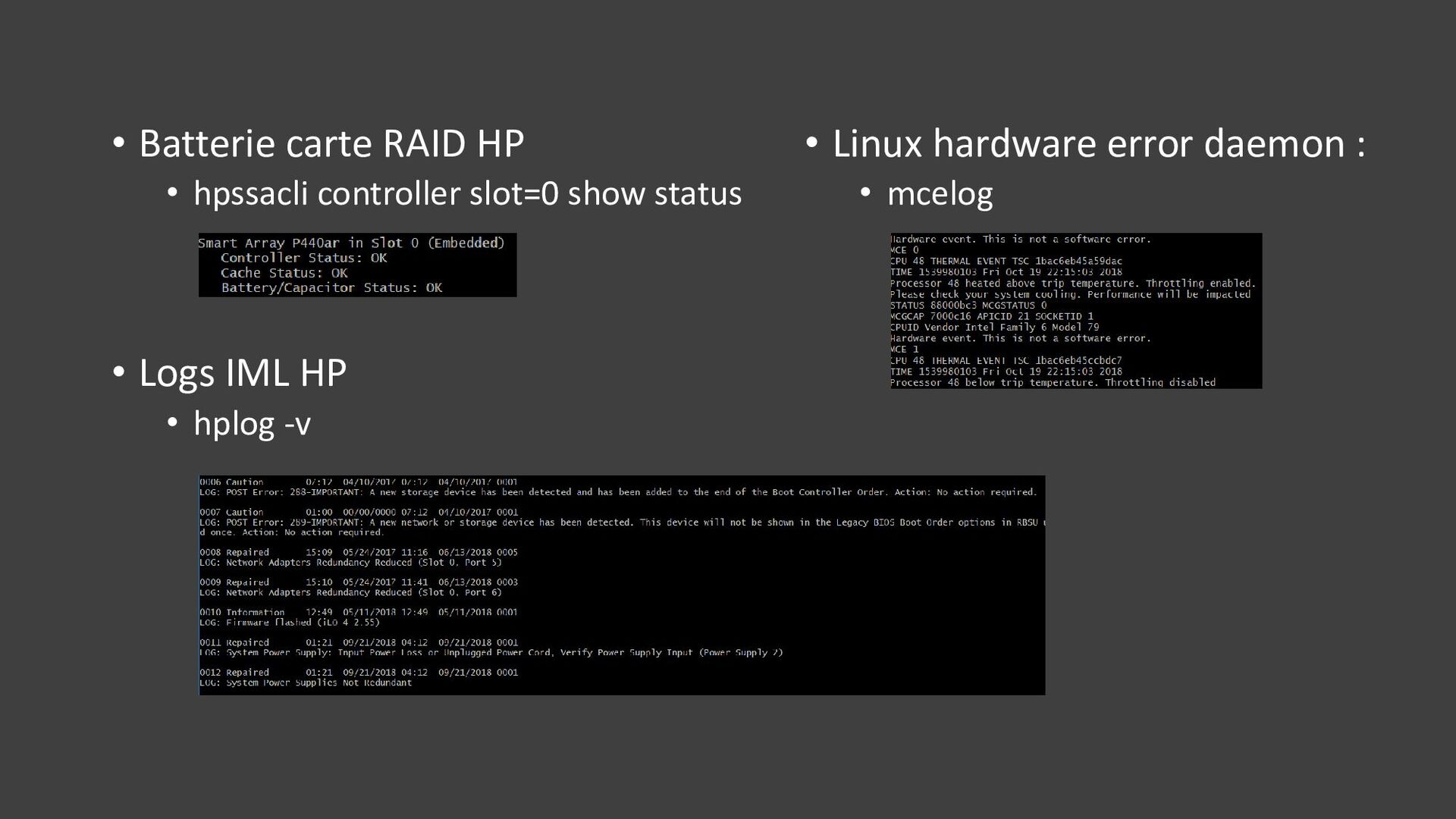{kind=link}
{kind=link}
![• perf top [-p <pid>] #root](https://files.speakerdeck.com/presentations/7c862d9e04a243b8a393e547abc1e1fe/slide_98.jpg){kind=link}
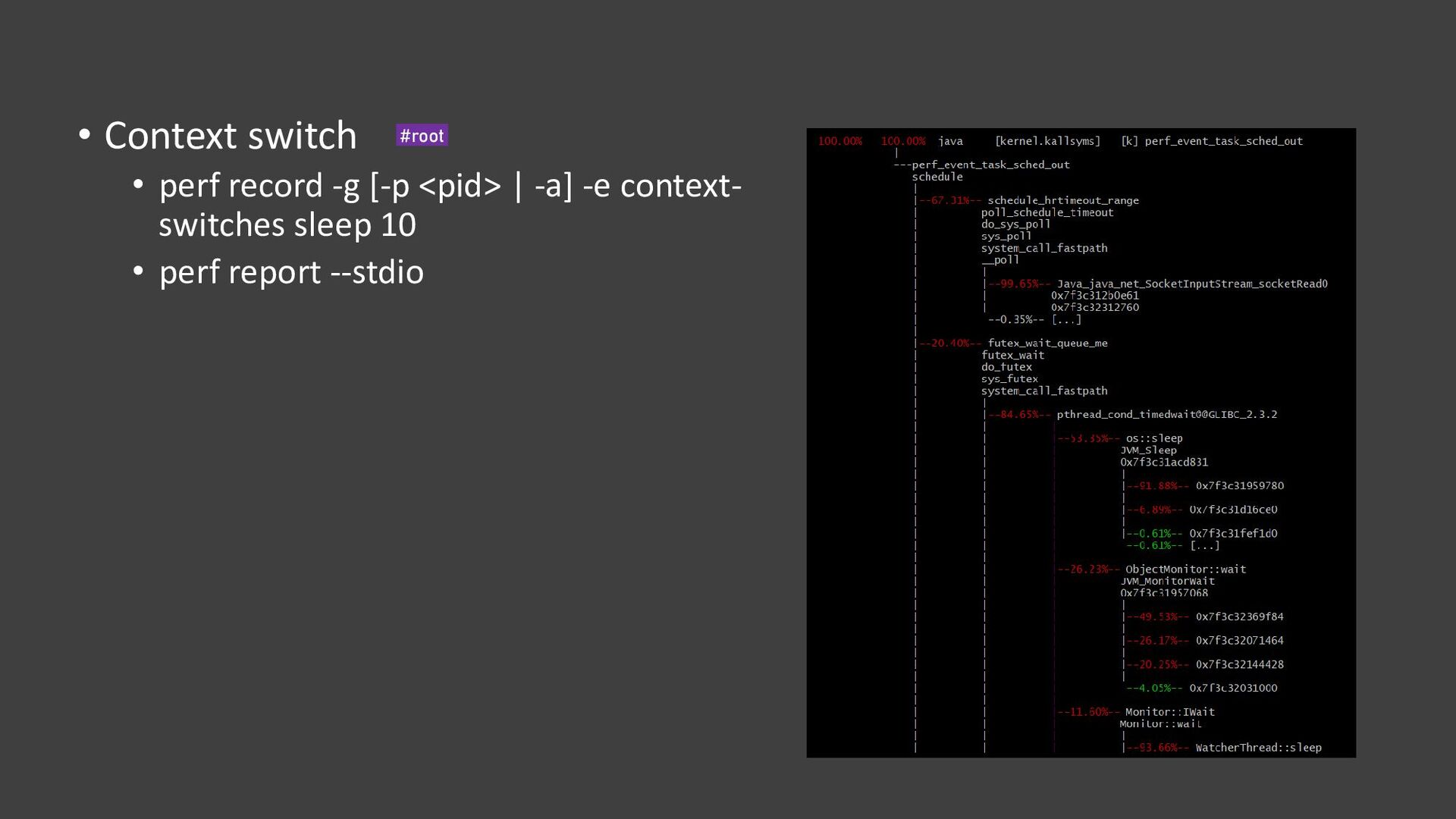{kind=link}
![• perf stat -ad -- sleep 10 • [-A] detail](https://files.speakerdeck.com/presentations/7c862d9e04a243b8a393e547abc1e1fe/slide_100.jpg){kind=link}
{kind=link}
{kind=link}
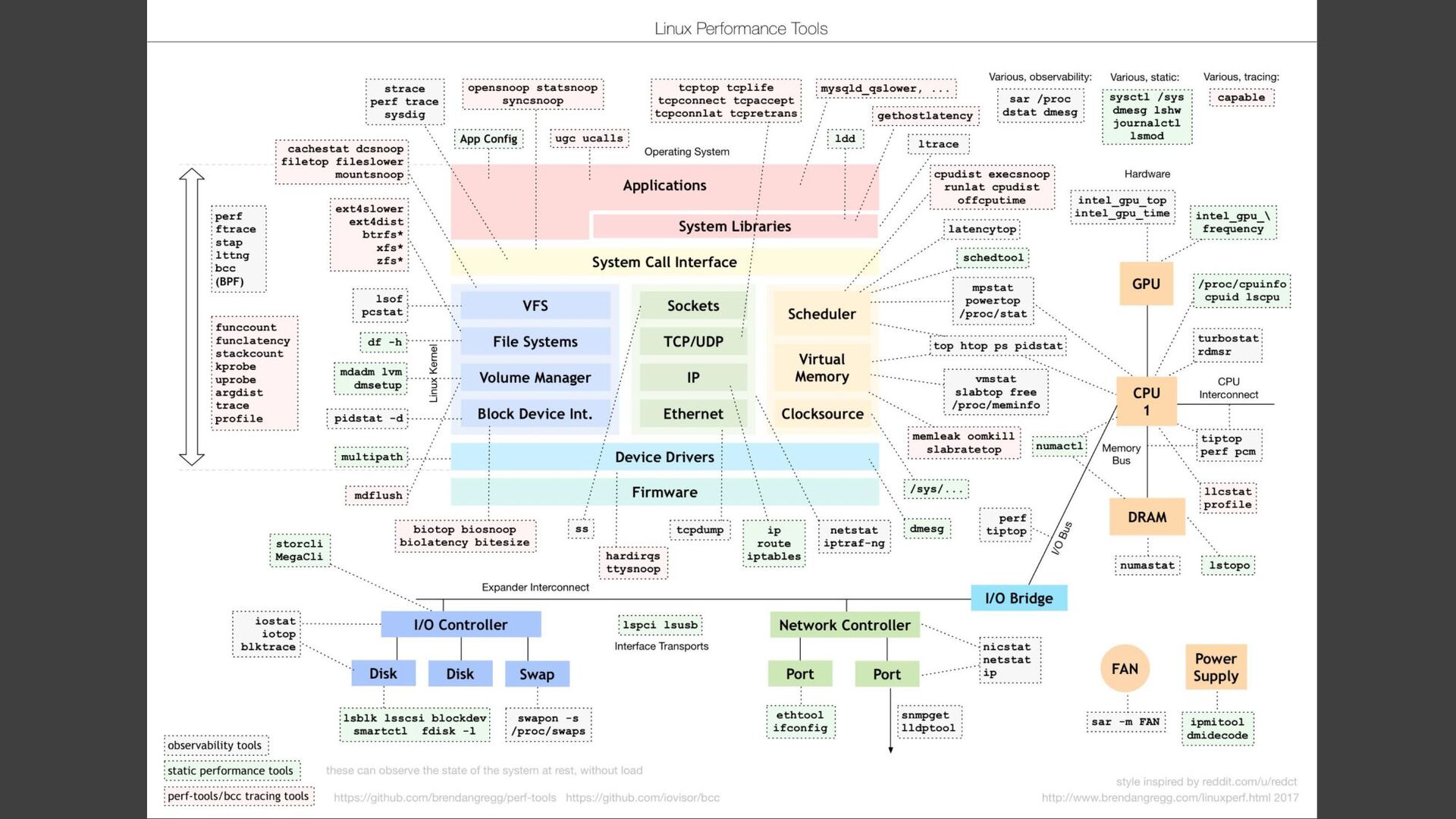{kind=link}
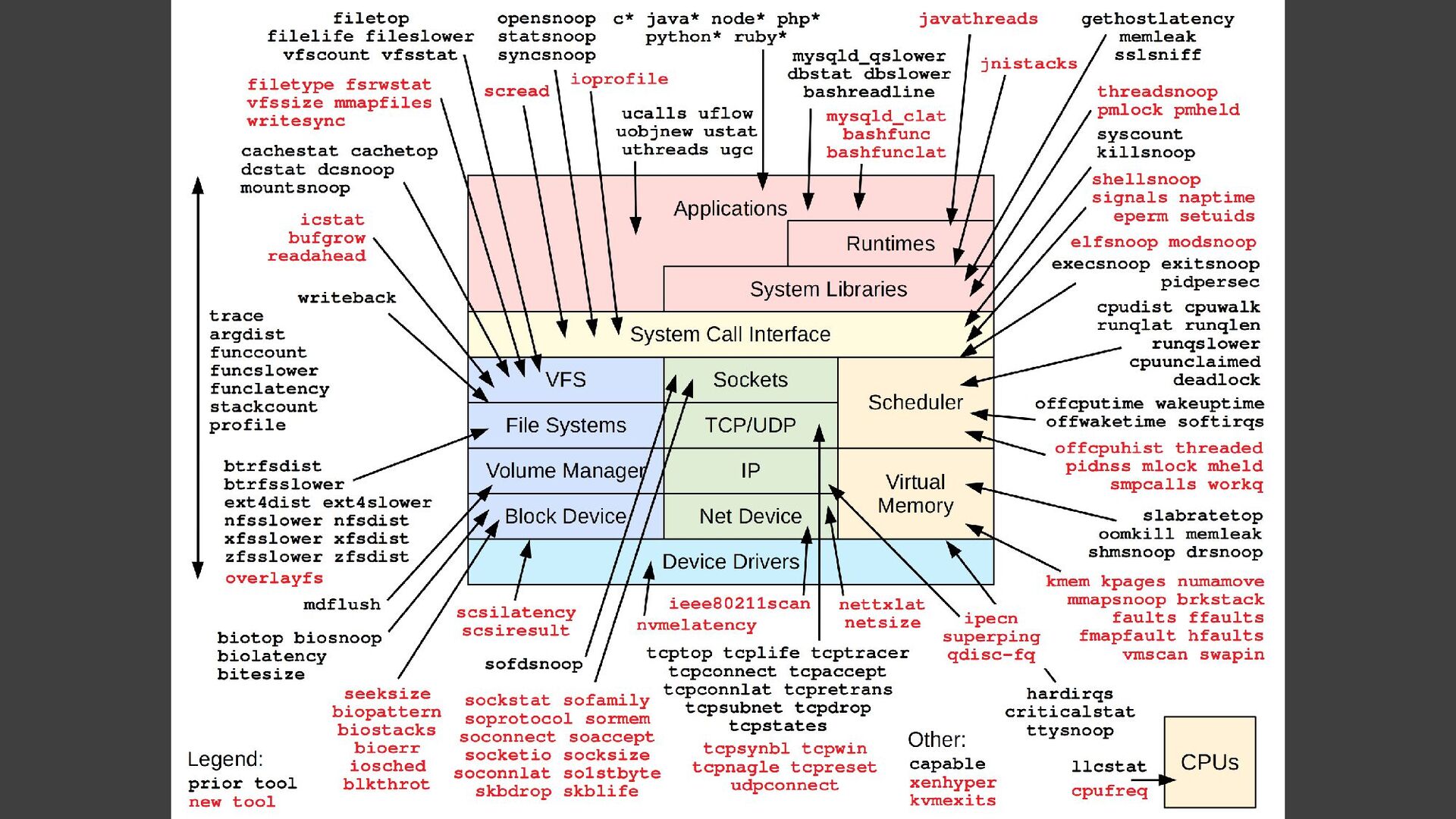{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
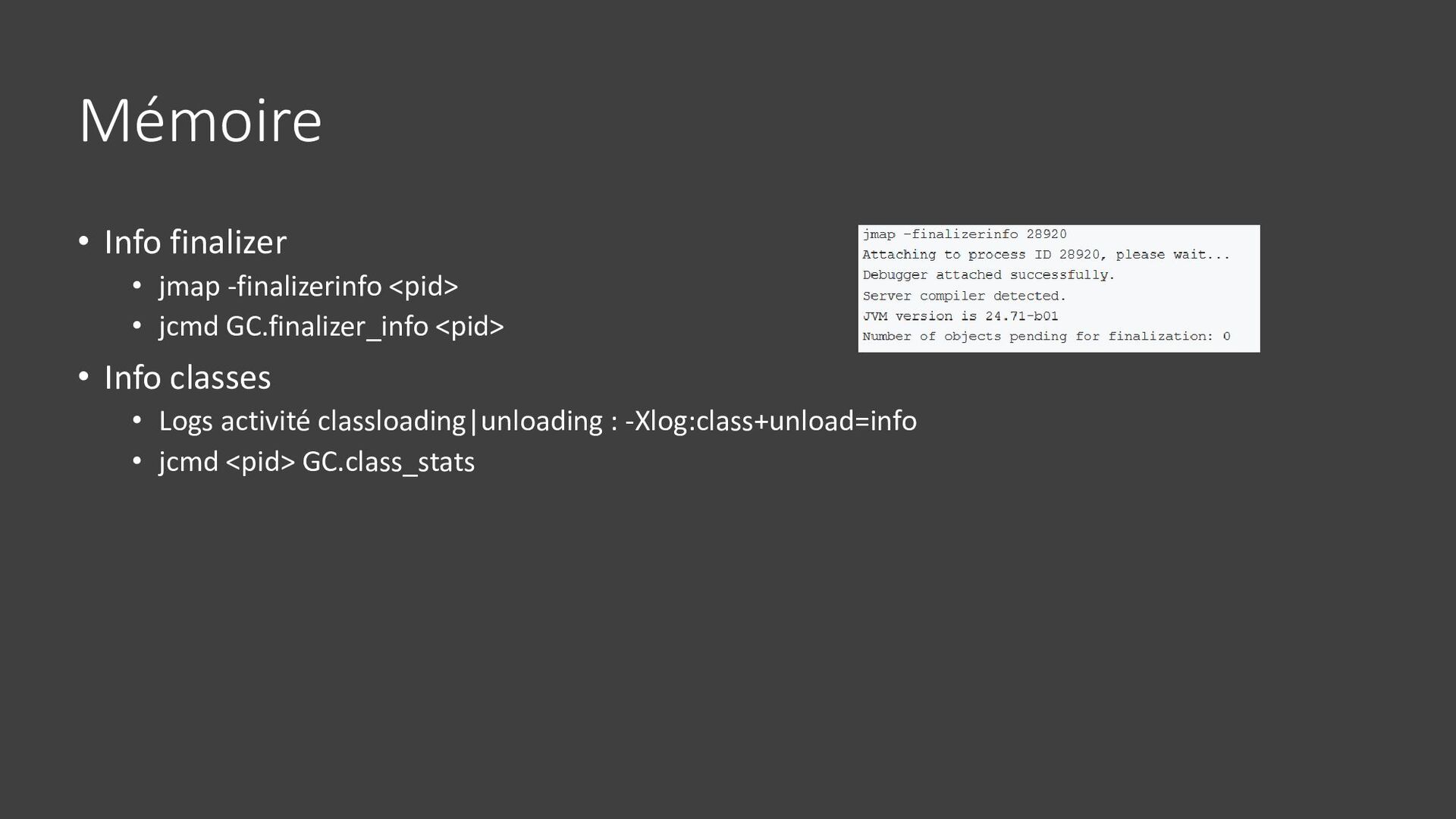{kind=link}
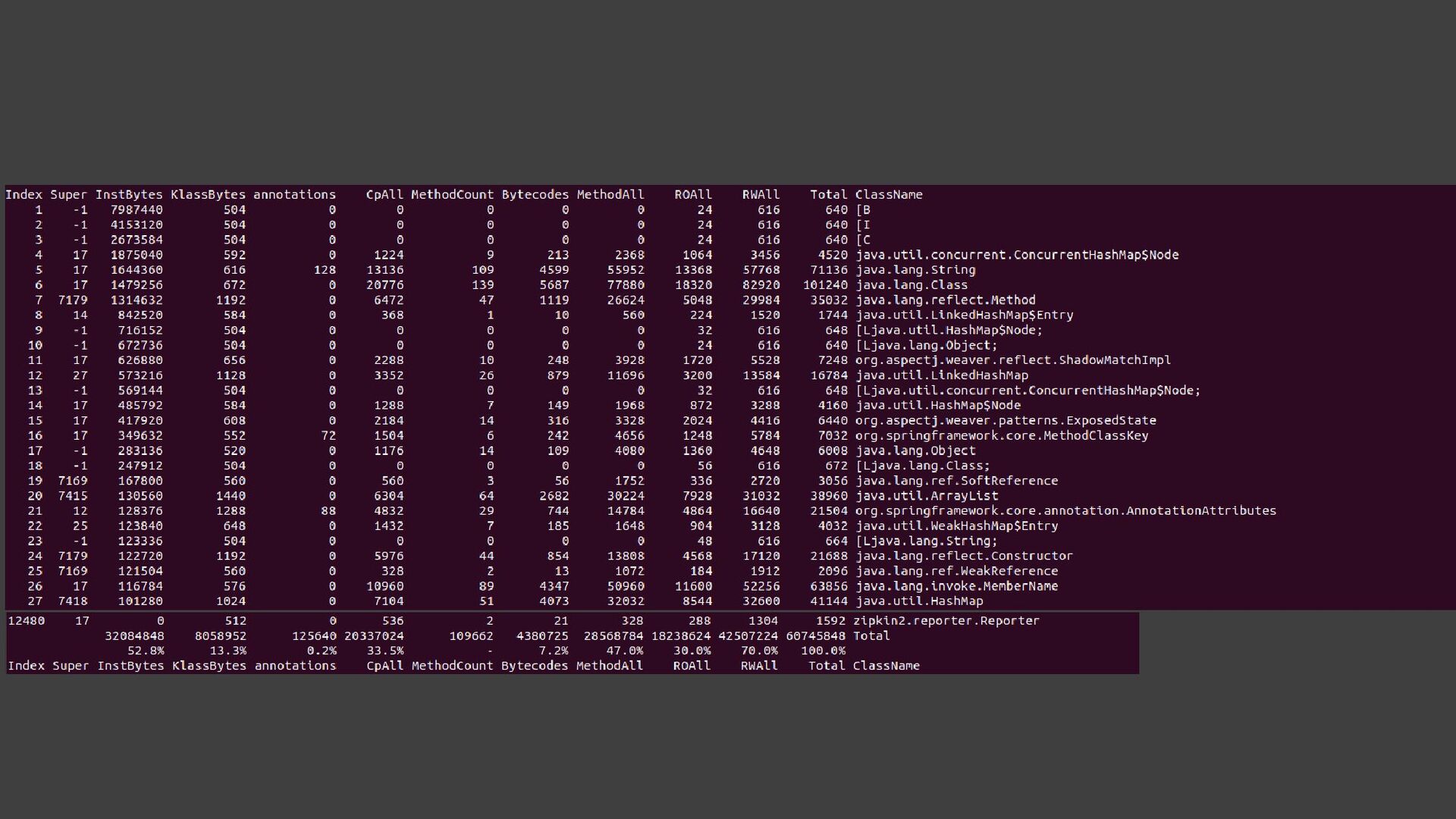{kind=link}
{kind=link}
{kind=link}
{kind=link}
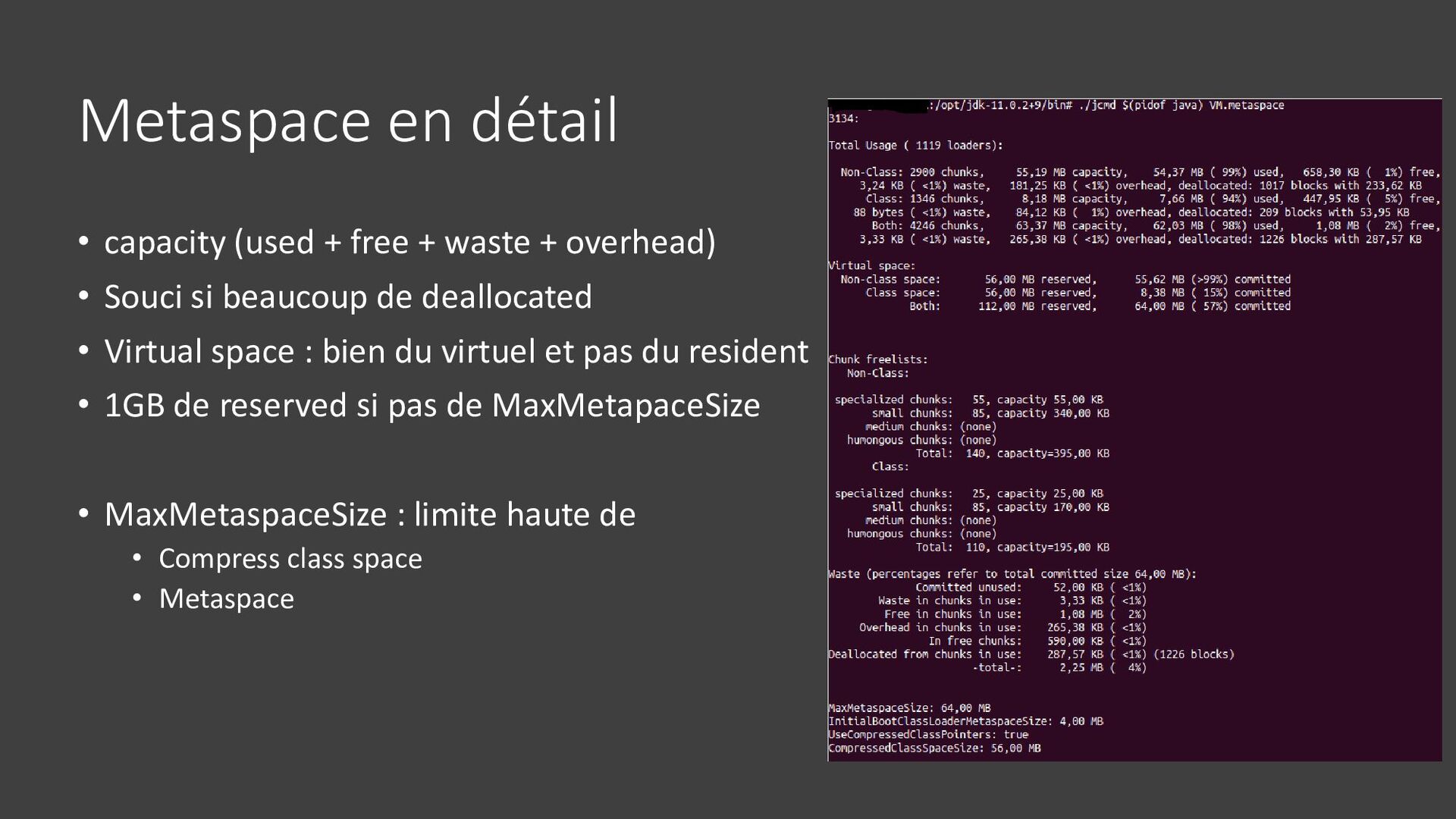{kind=link}
{kind=link}
{kind=link}
{kind=link}
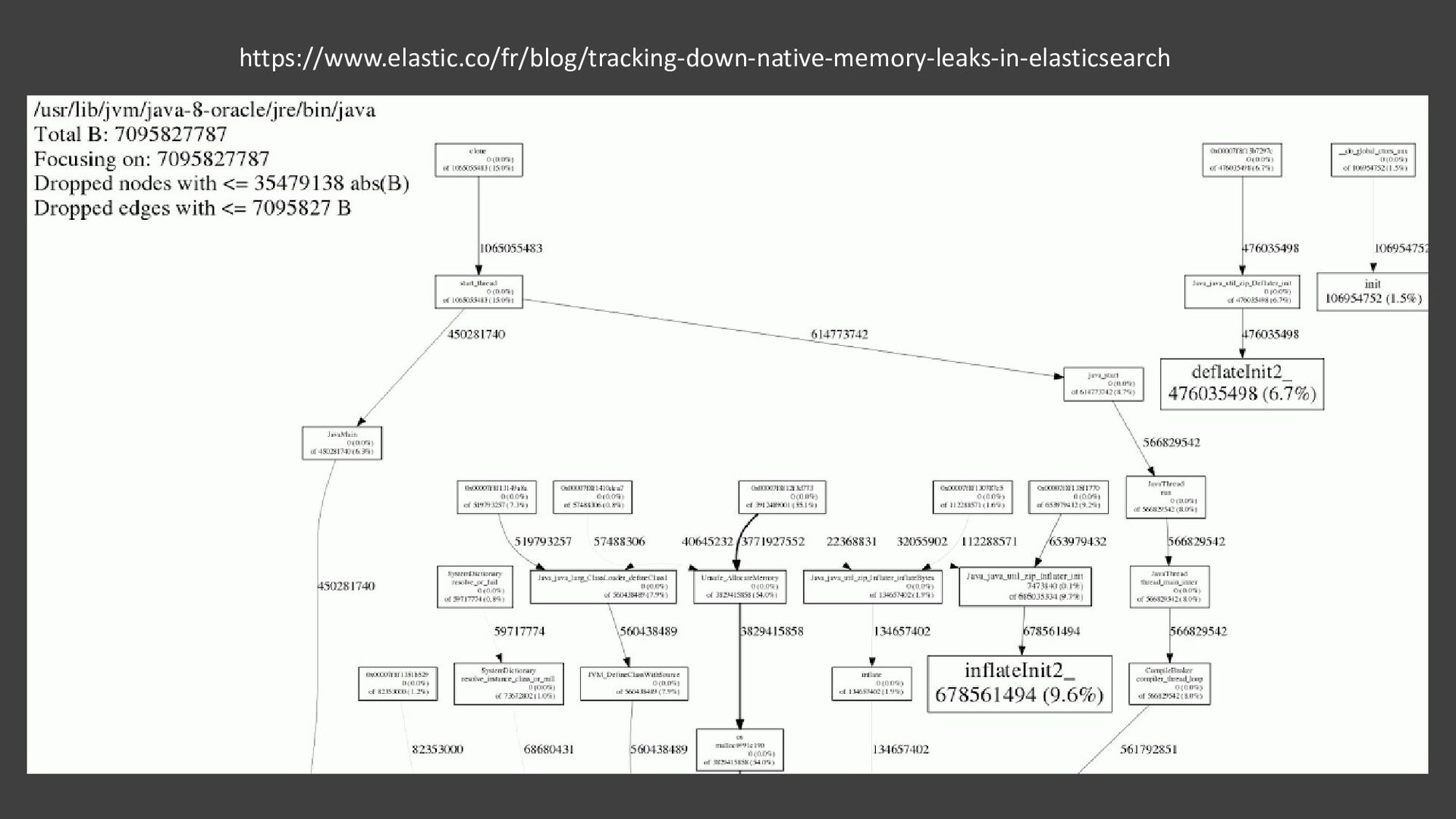{kind=link}
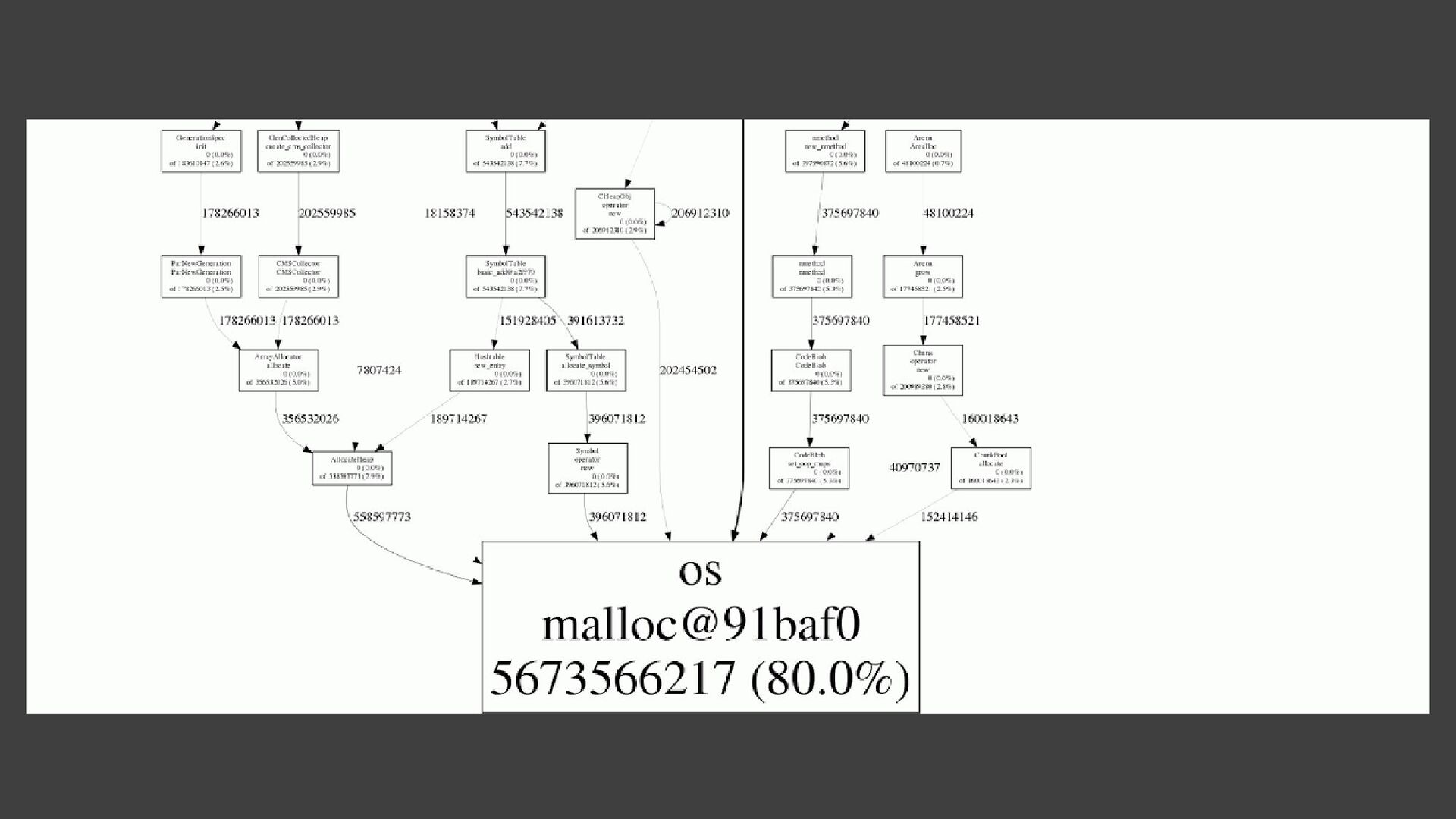{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
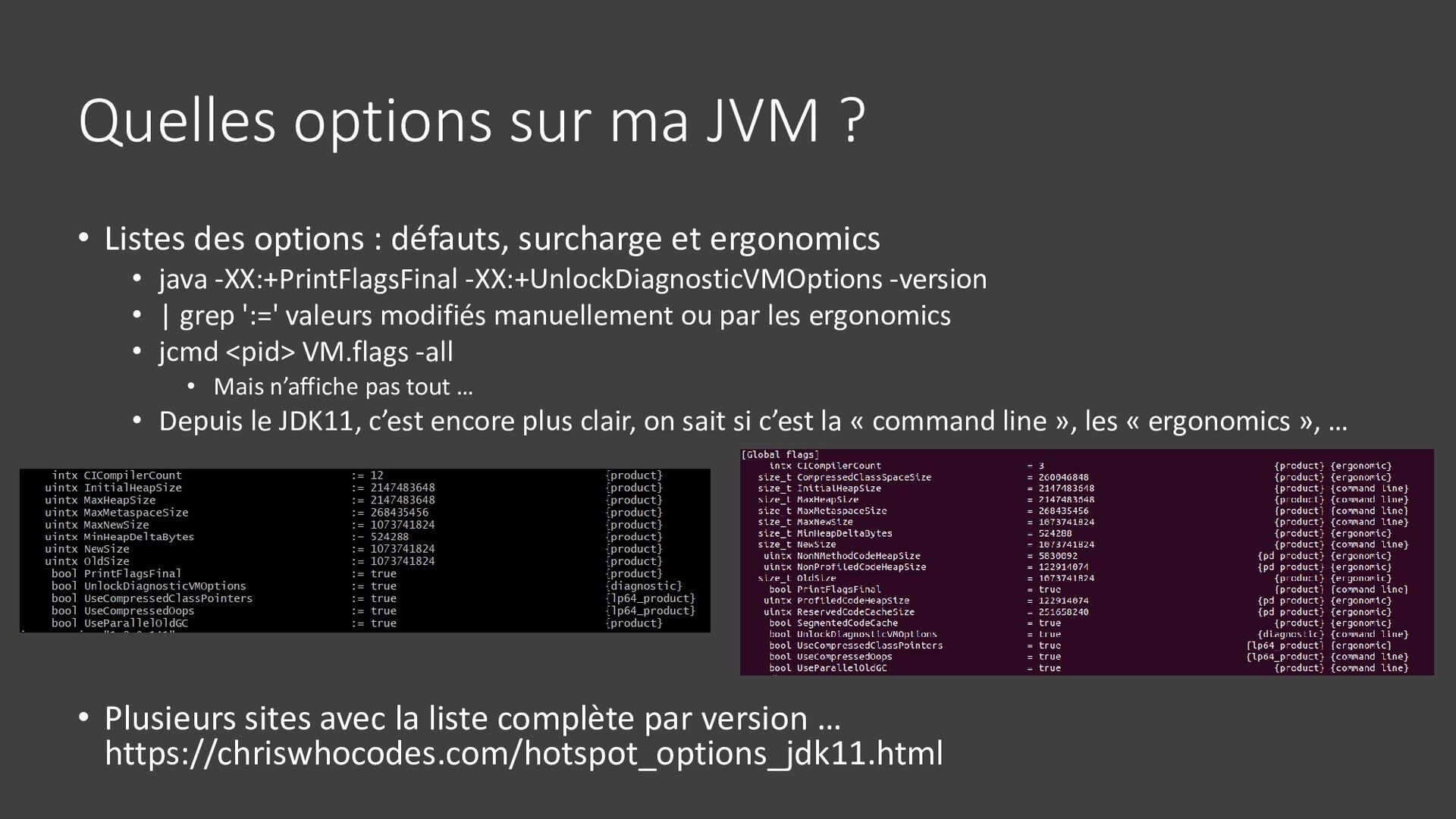{kind=link}
{kind=link}
{kind=link}
{kind=link}
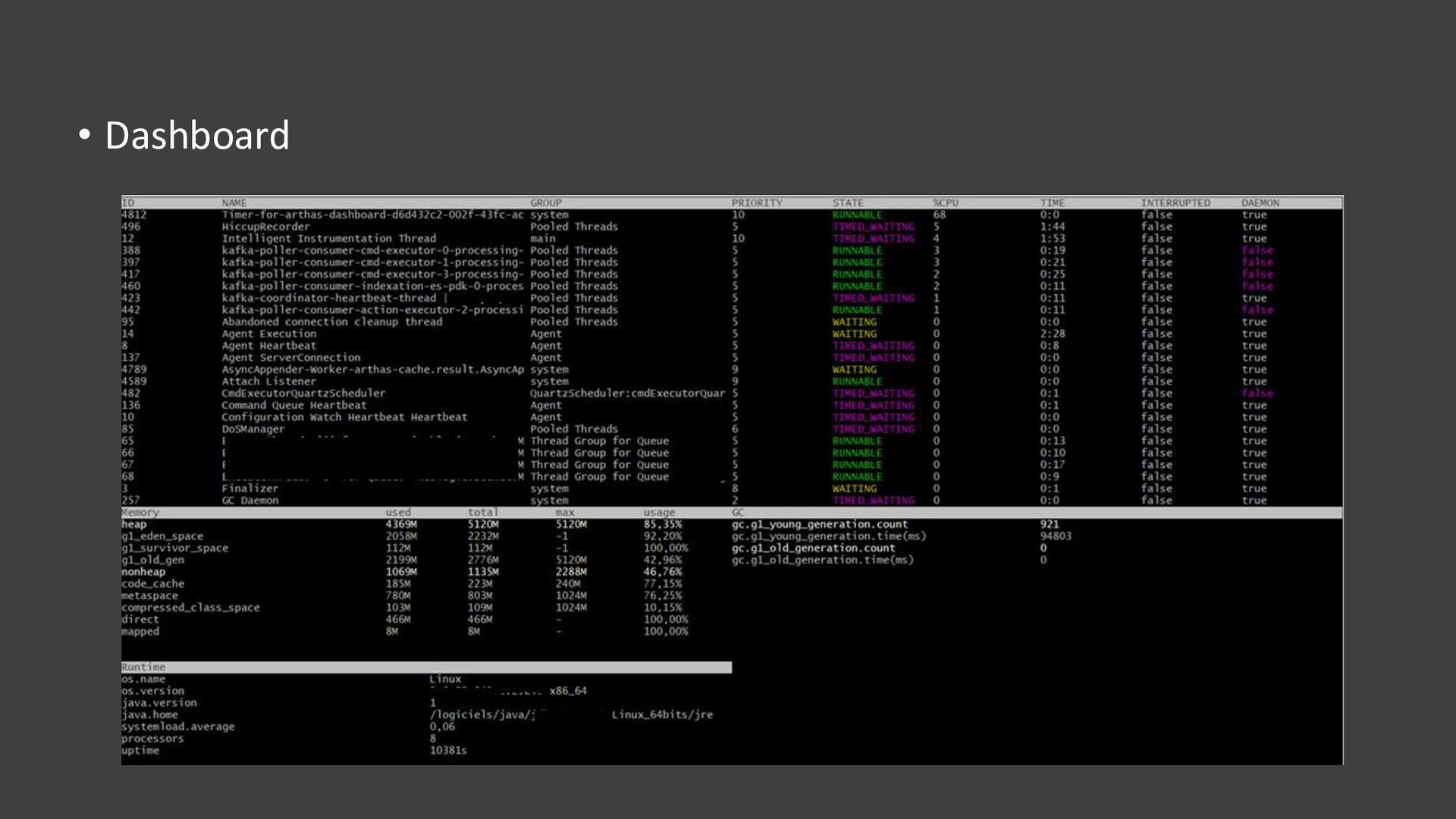{kind=link}
{kind=link}
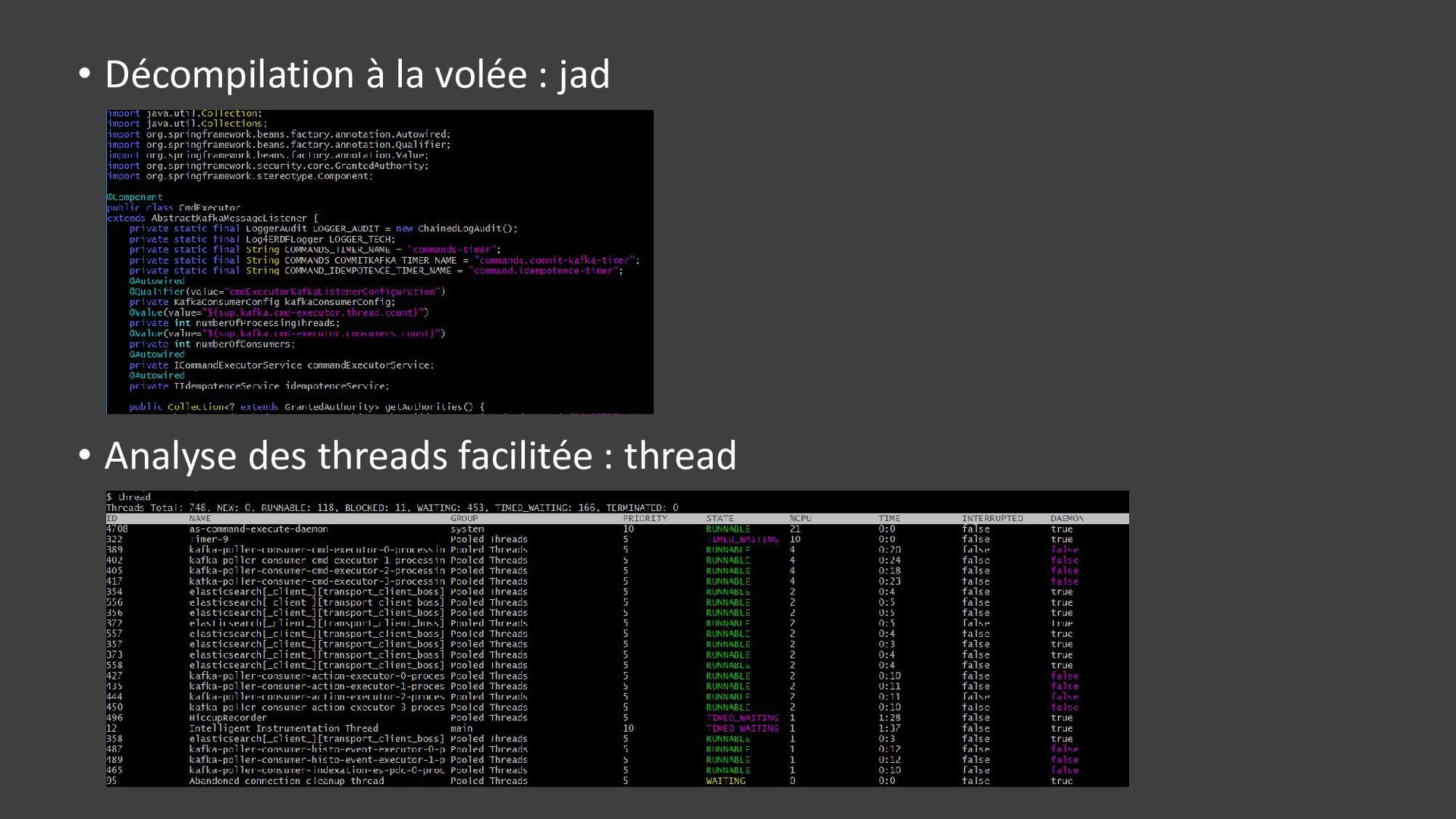{kind=link}
{kind=link}
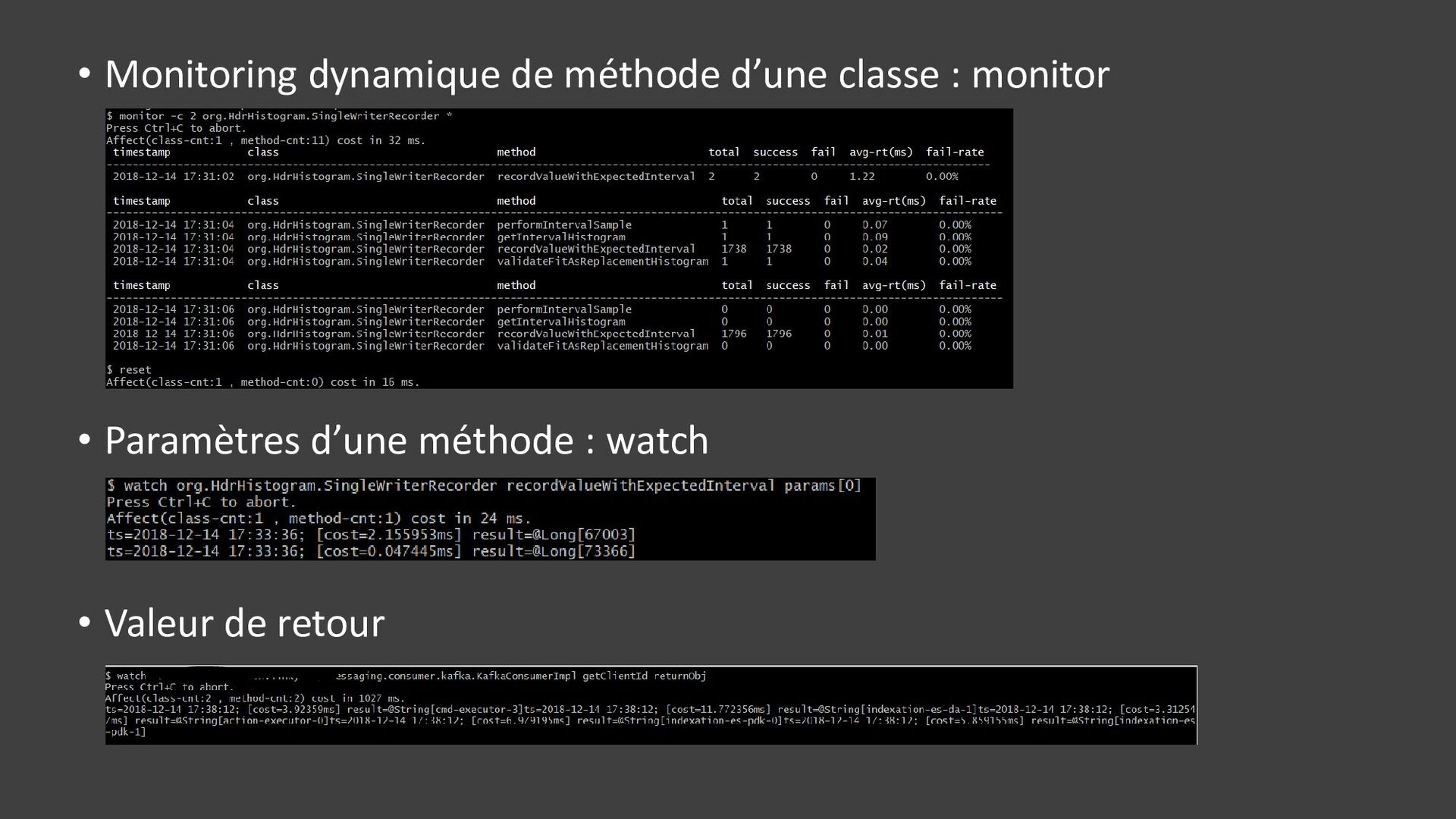
![• Les deux • Filtrage possible sur arguments ('params[0].contains("jms")'), duration](https://files.speakerdeck.com/presentations/7c862d9e04a243b8a393e547abc1e1fe/slide_150.jpg){kind=link}
{kind=link}
{kind=link}
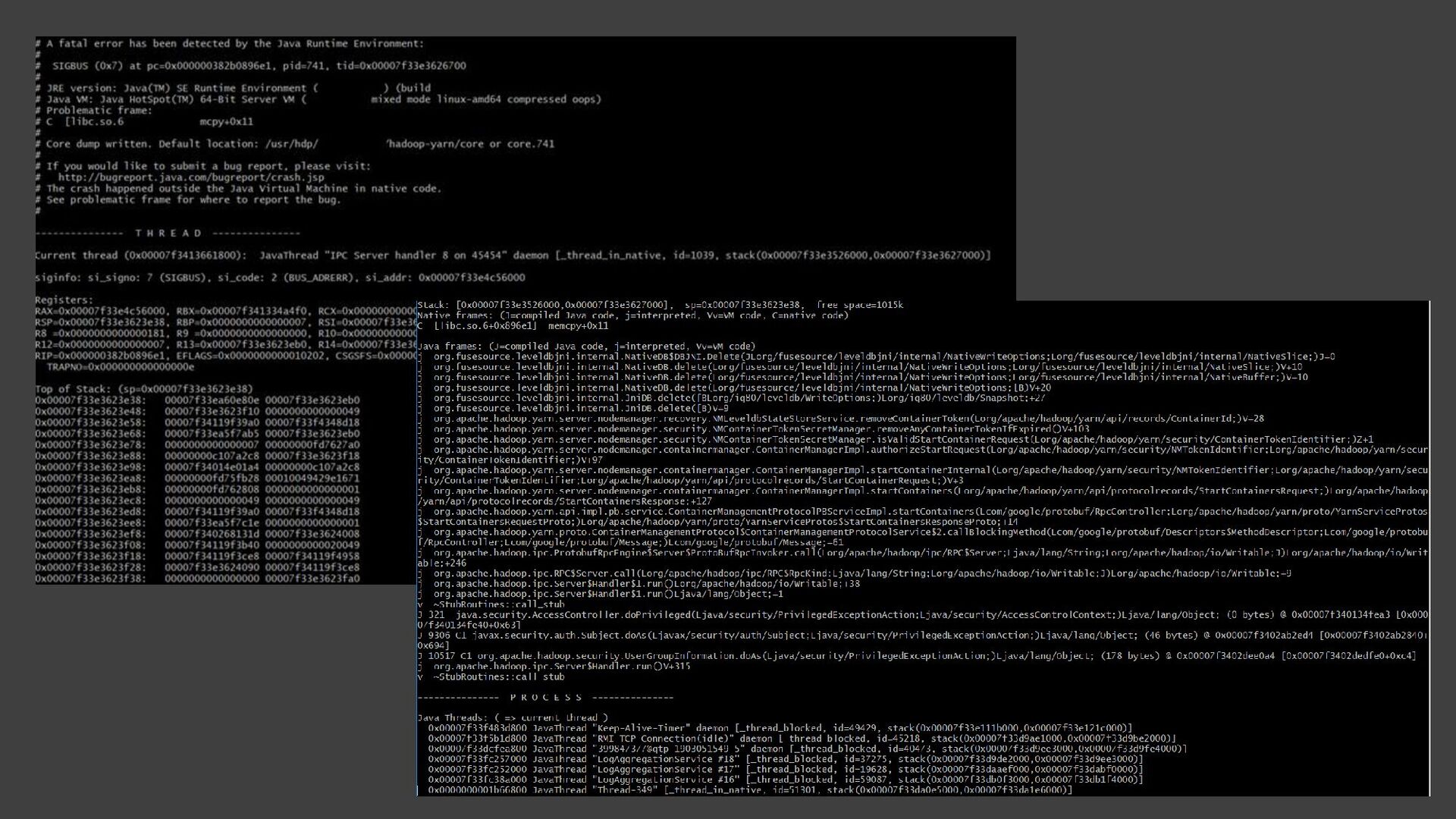{kind=link}
{kind=link}
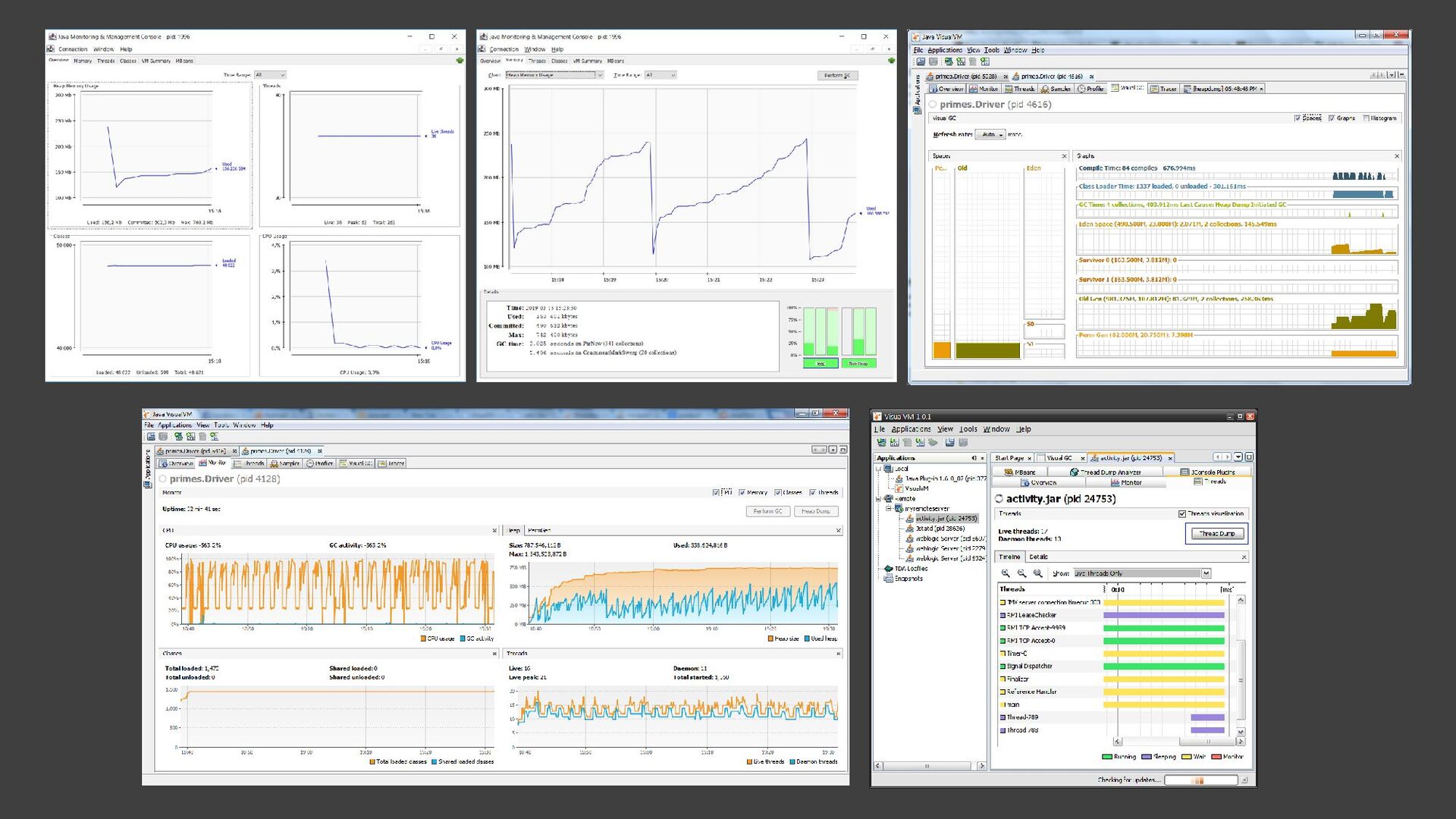{kind=link}
{kind=link}
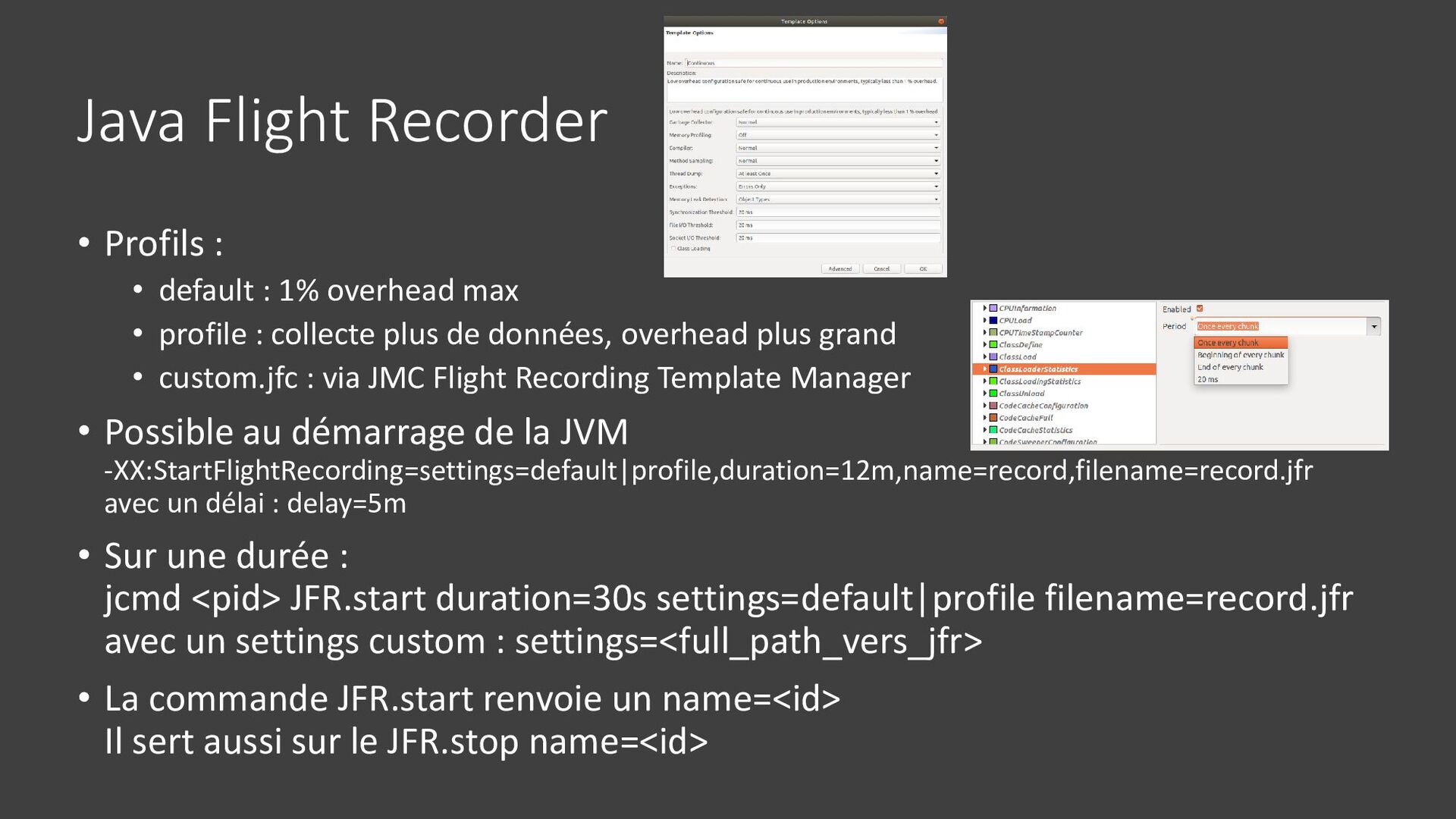{kind=link}
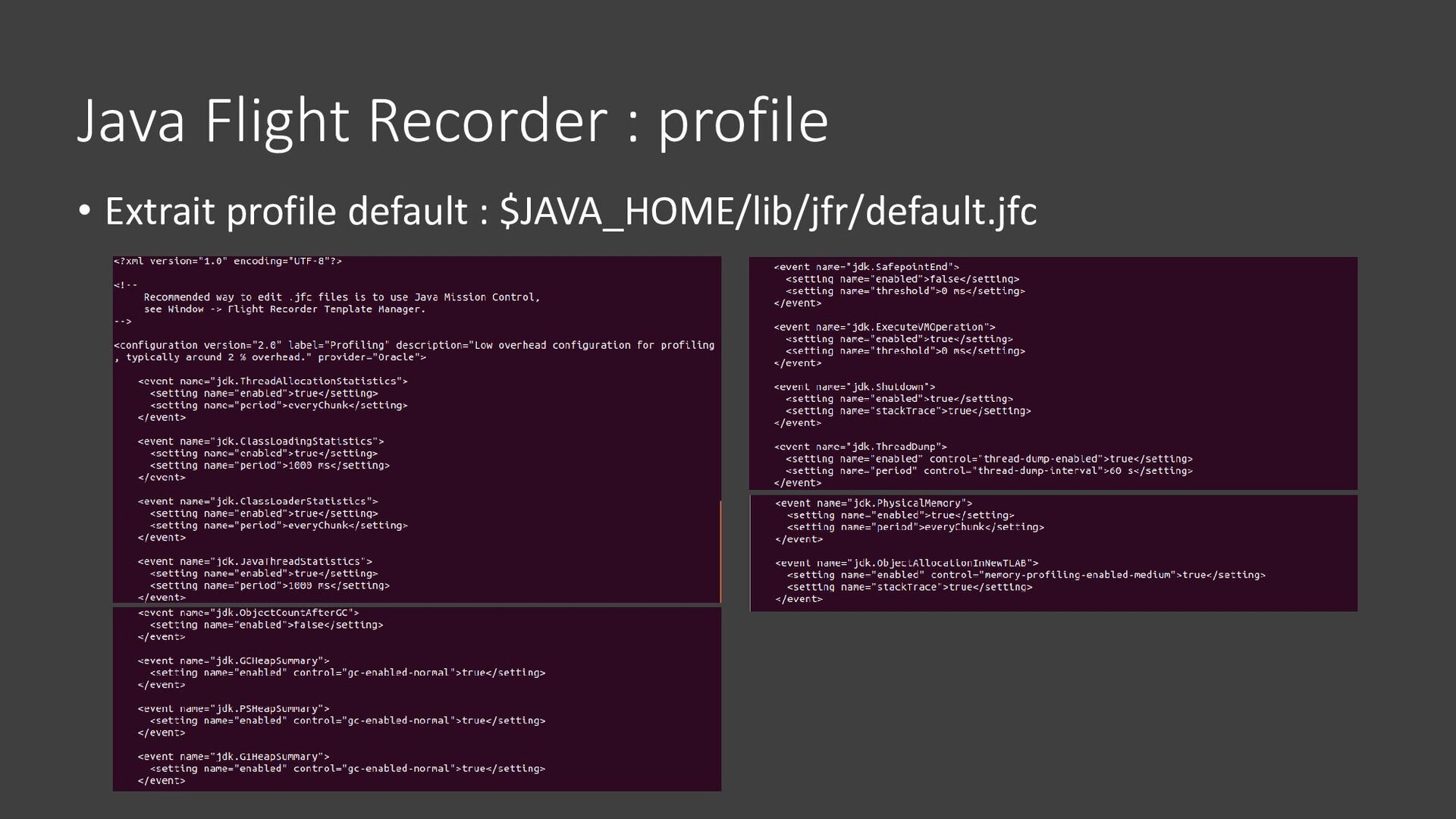{kind=link}
{kind=link}
{kind=link}
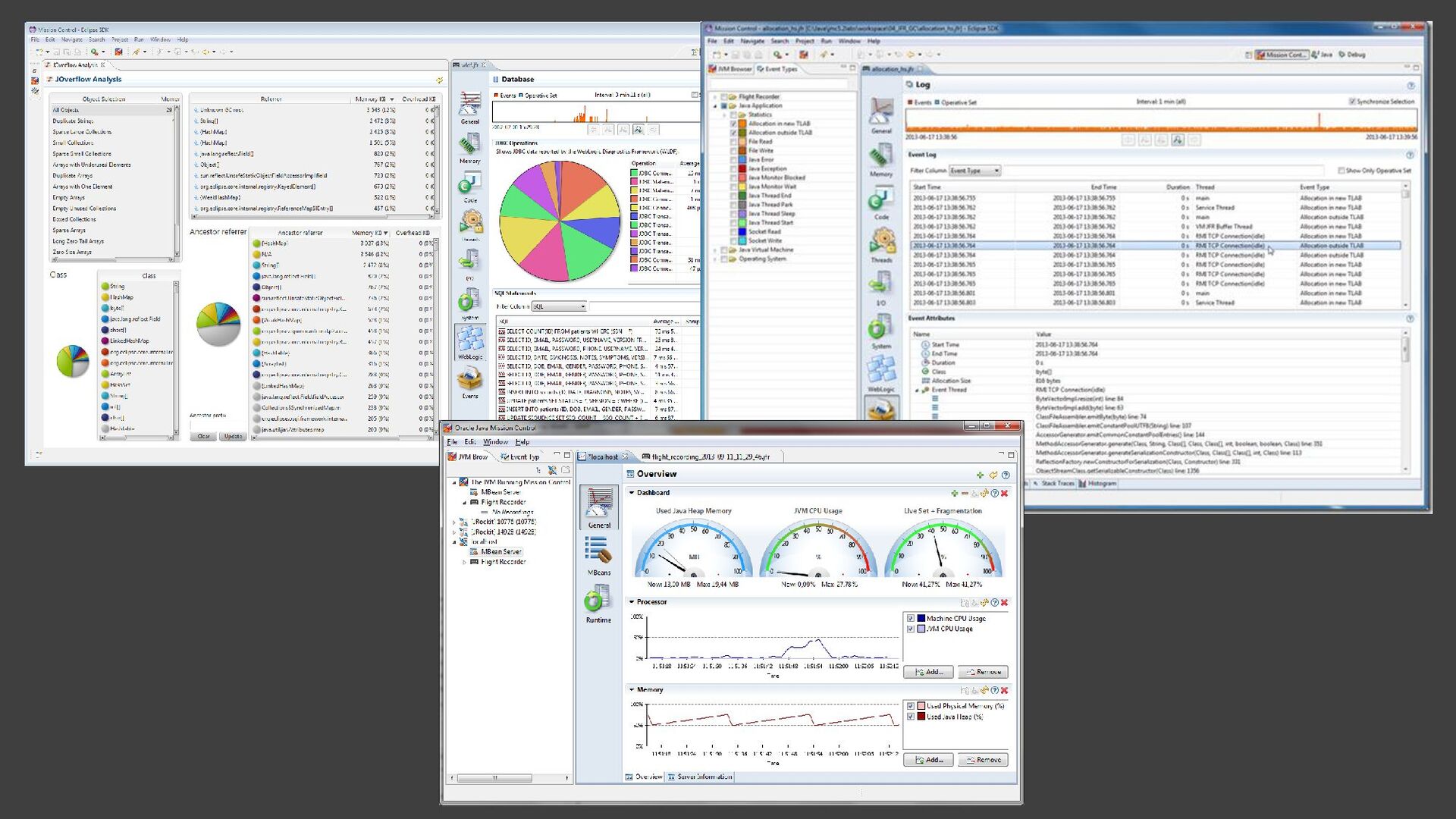{kind=link}
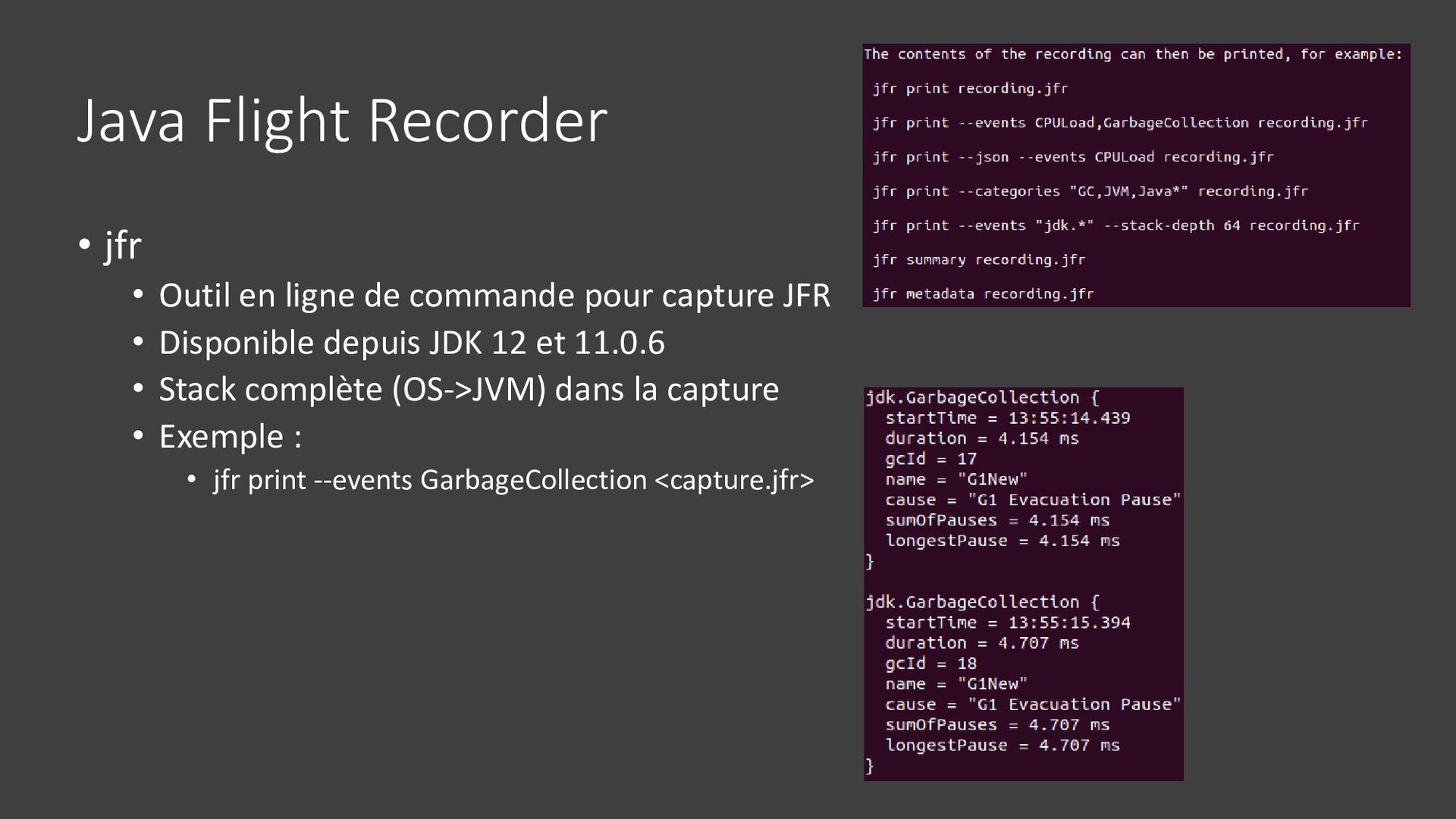{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
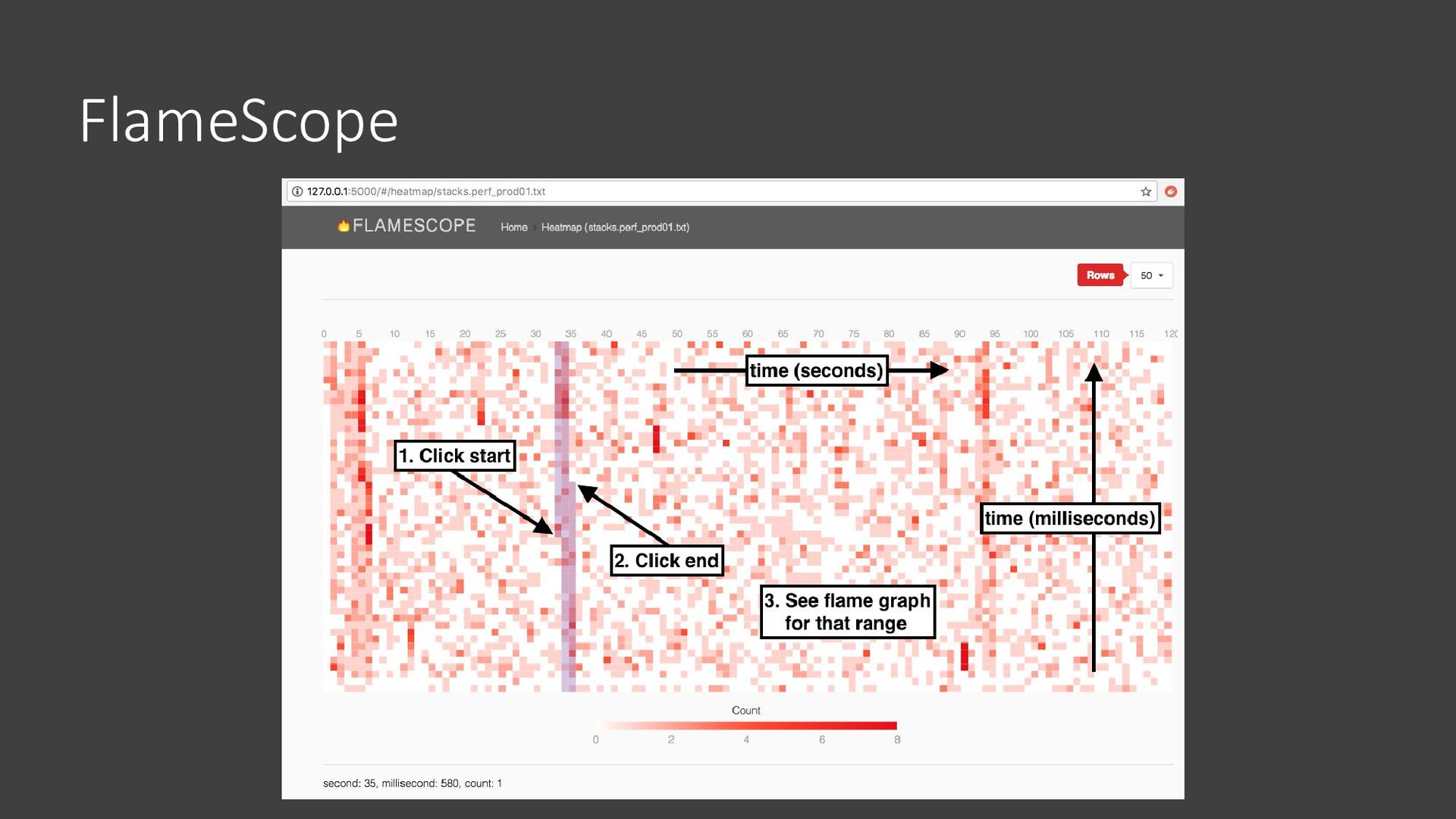{kind=link}
{kind=link}
{kind=link}
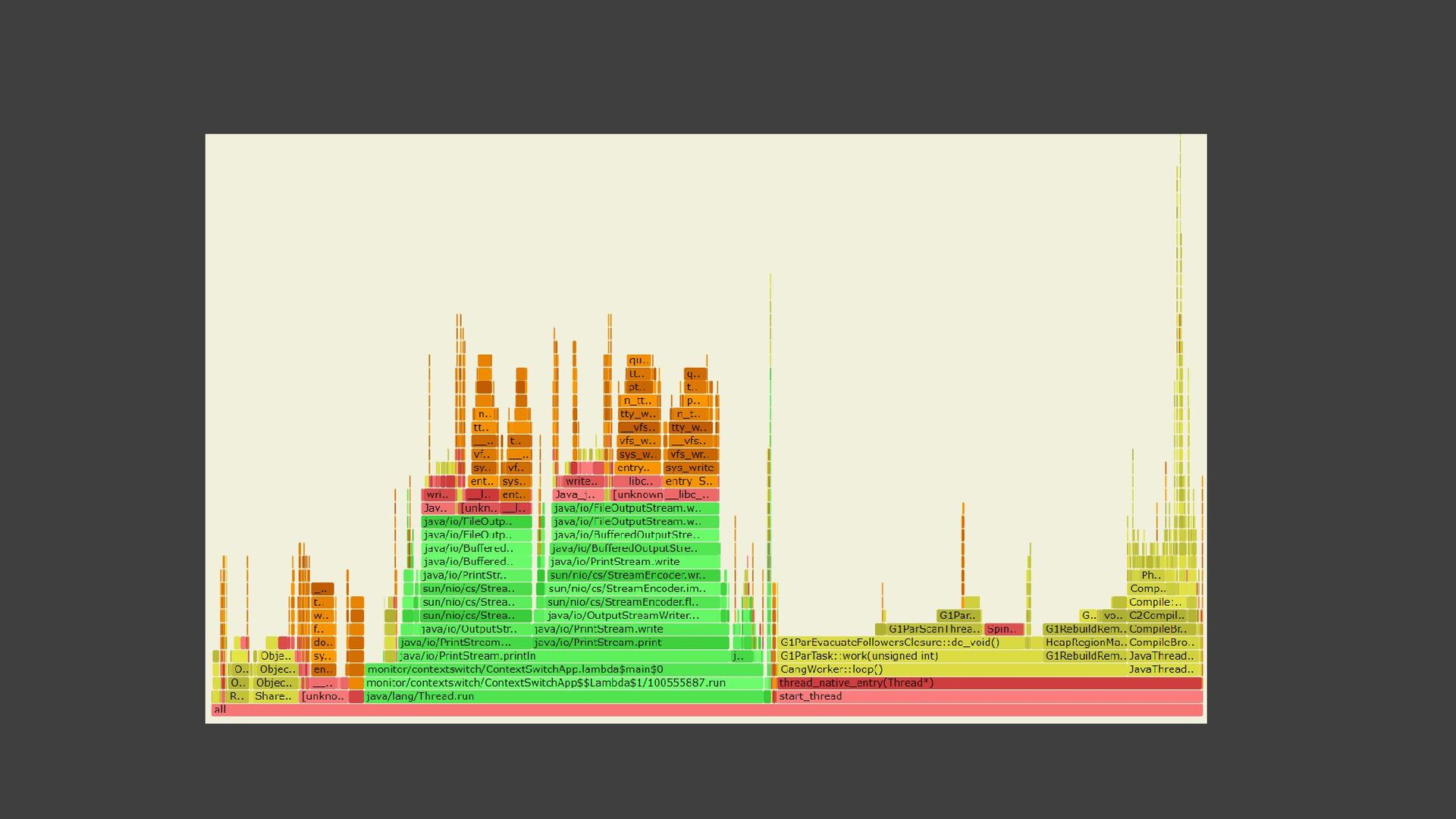{kind=link}
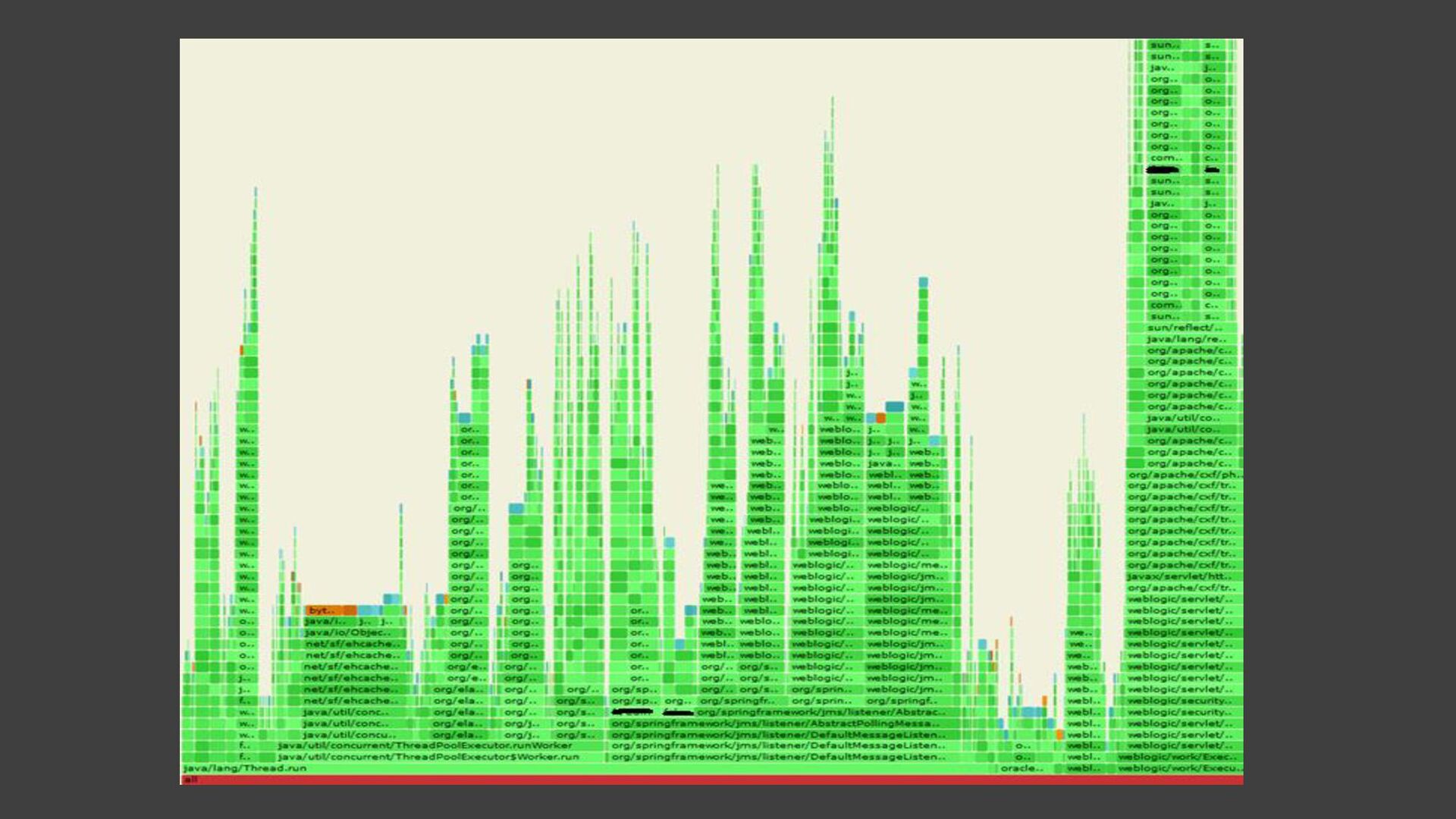{kind=link}
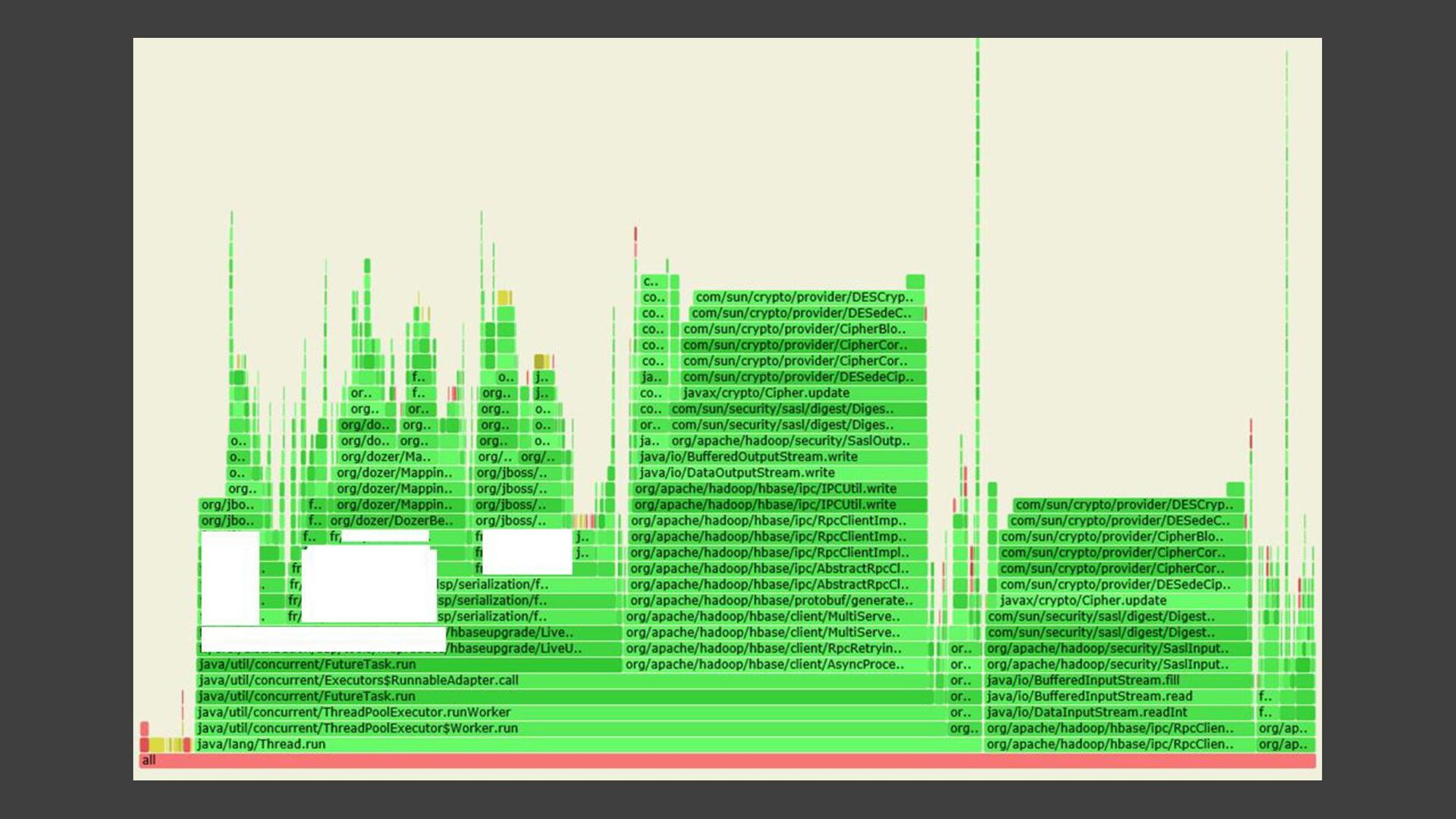{kind=link}
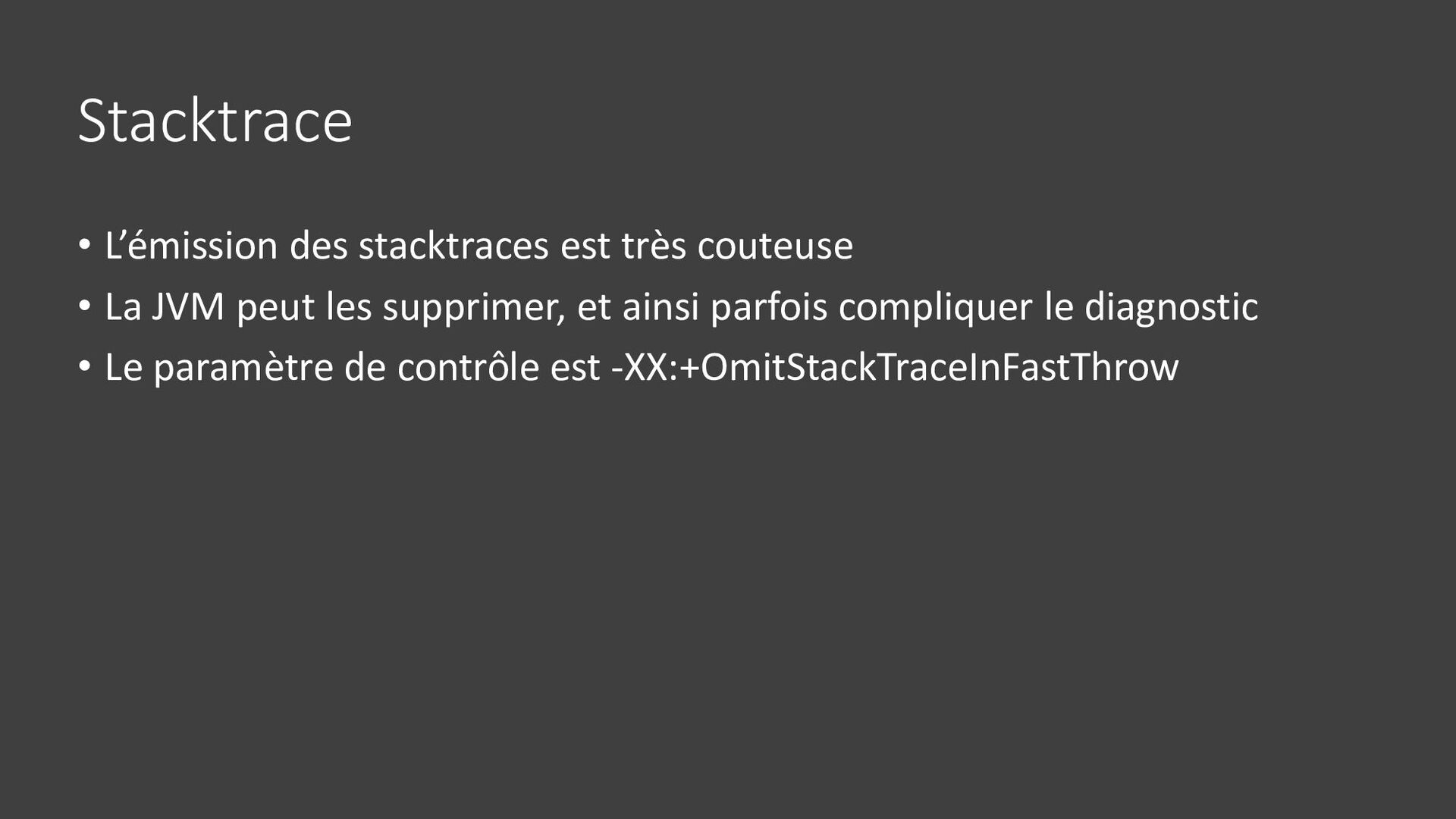{kind=link}
{kind=link}
{kind=link}
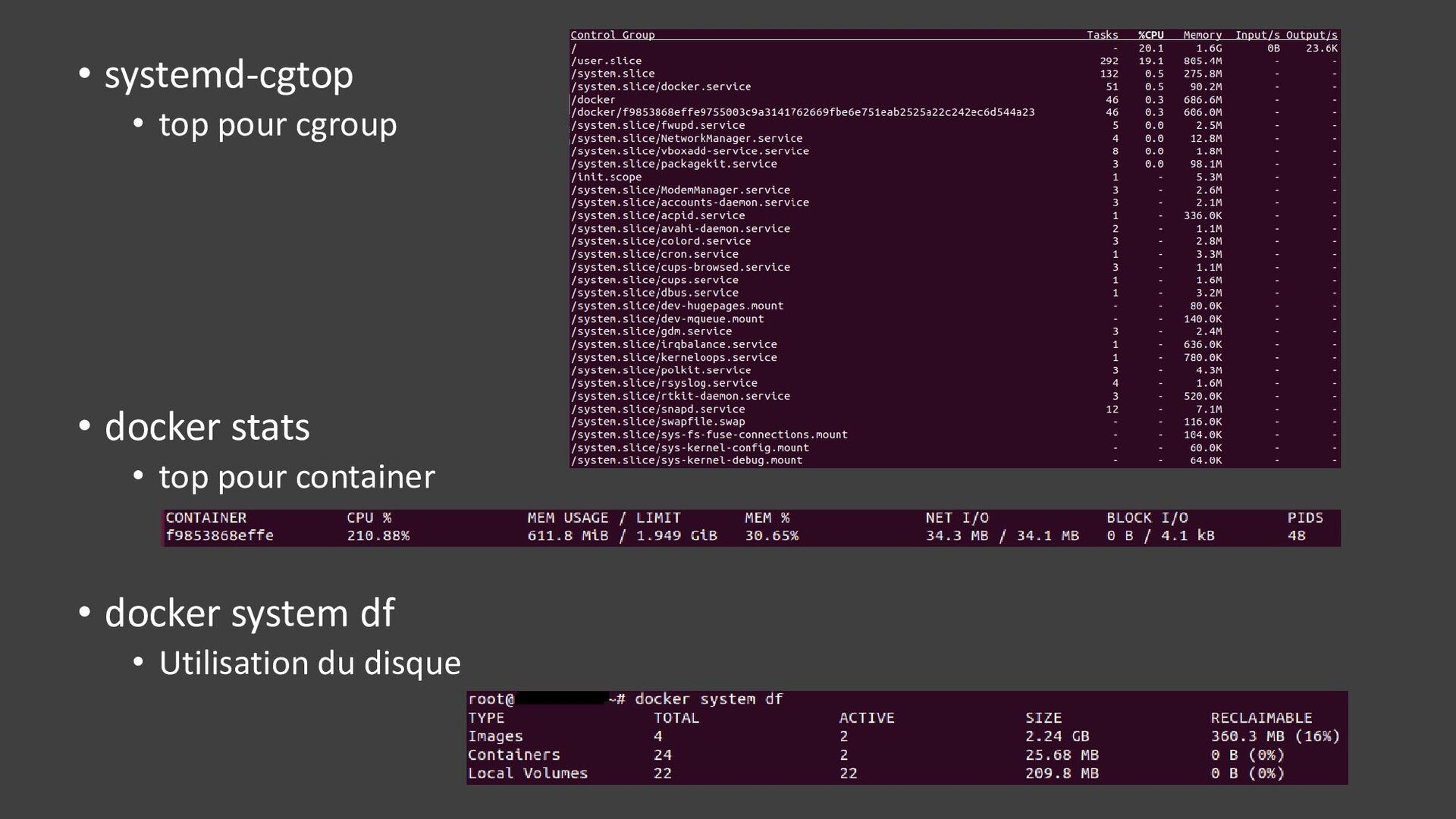{kind=link}
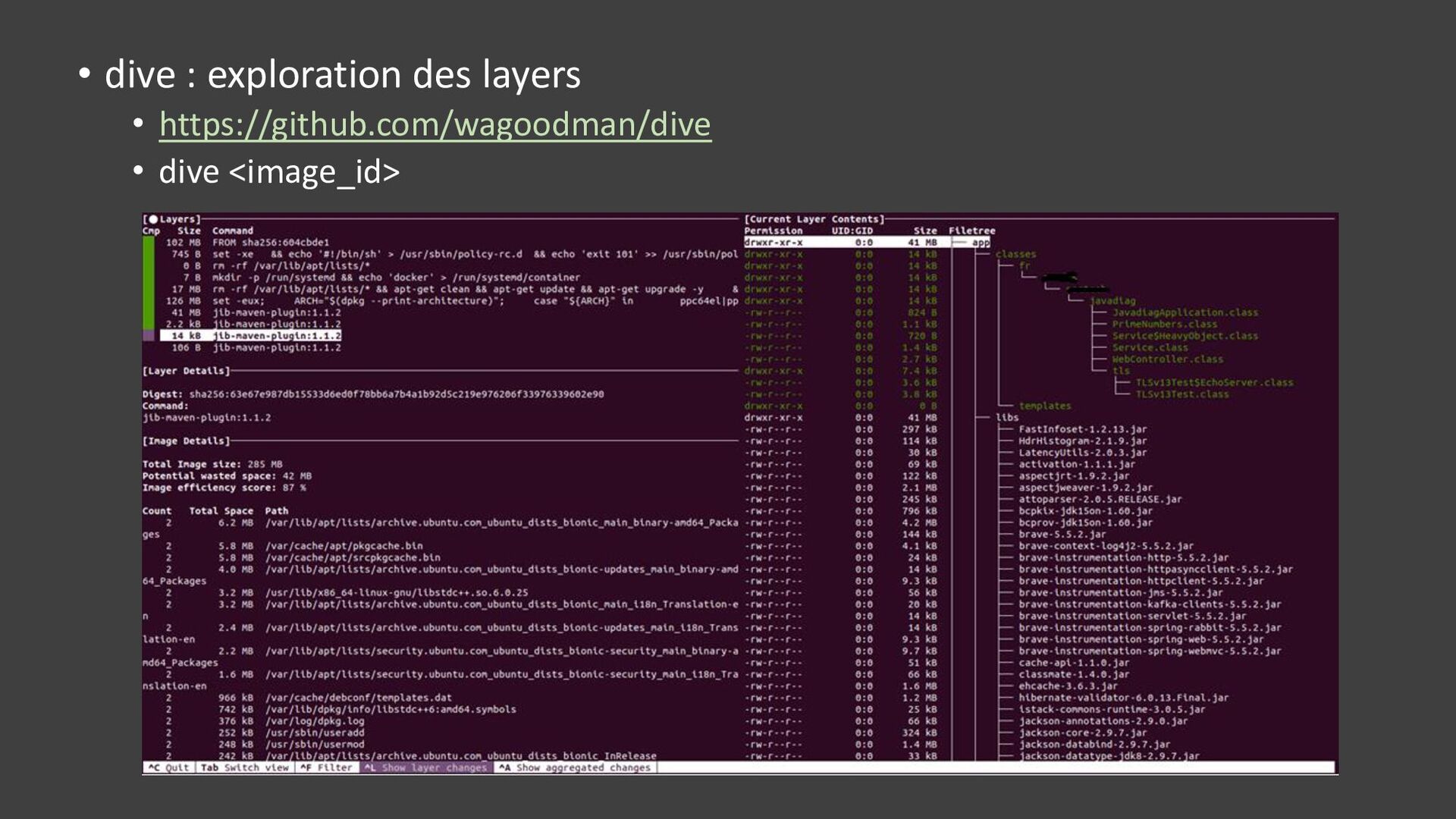{kind=link}
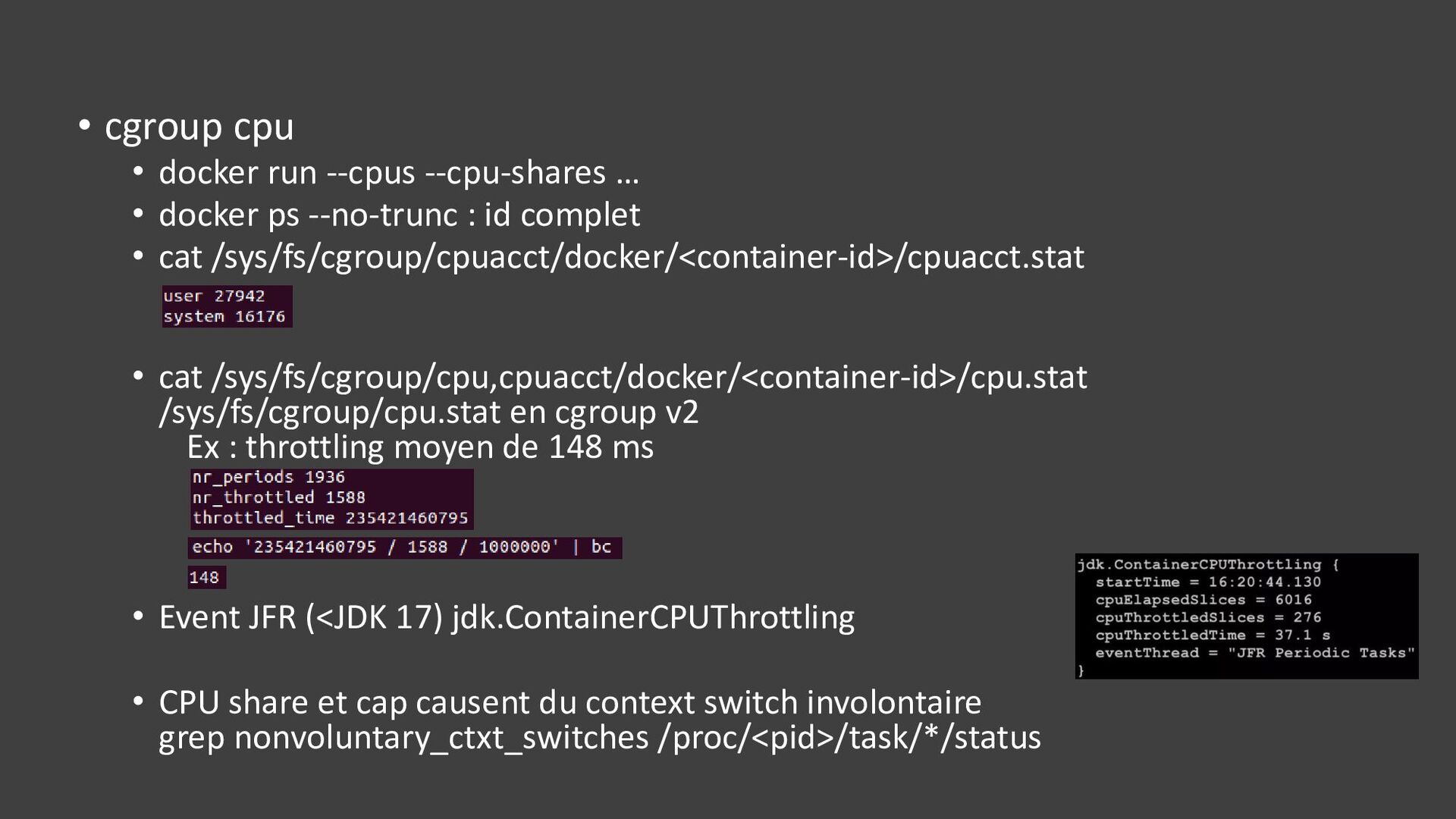{kind=link}
{kind=link}
{kind=link}
{kind=link}
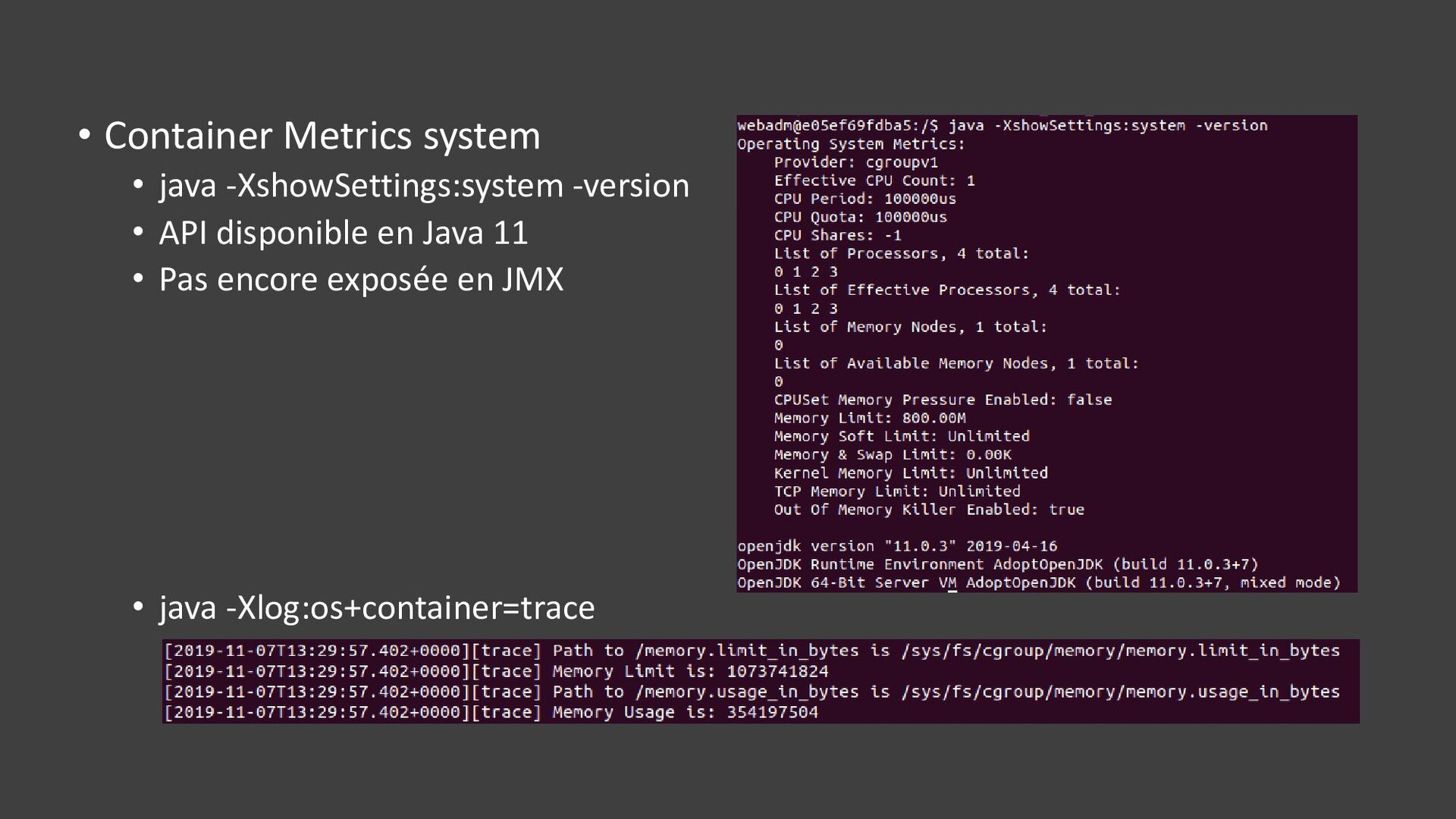{kind=link}
{kind=link}
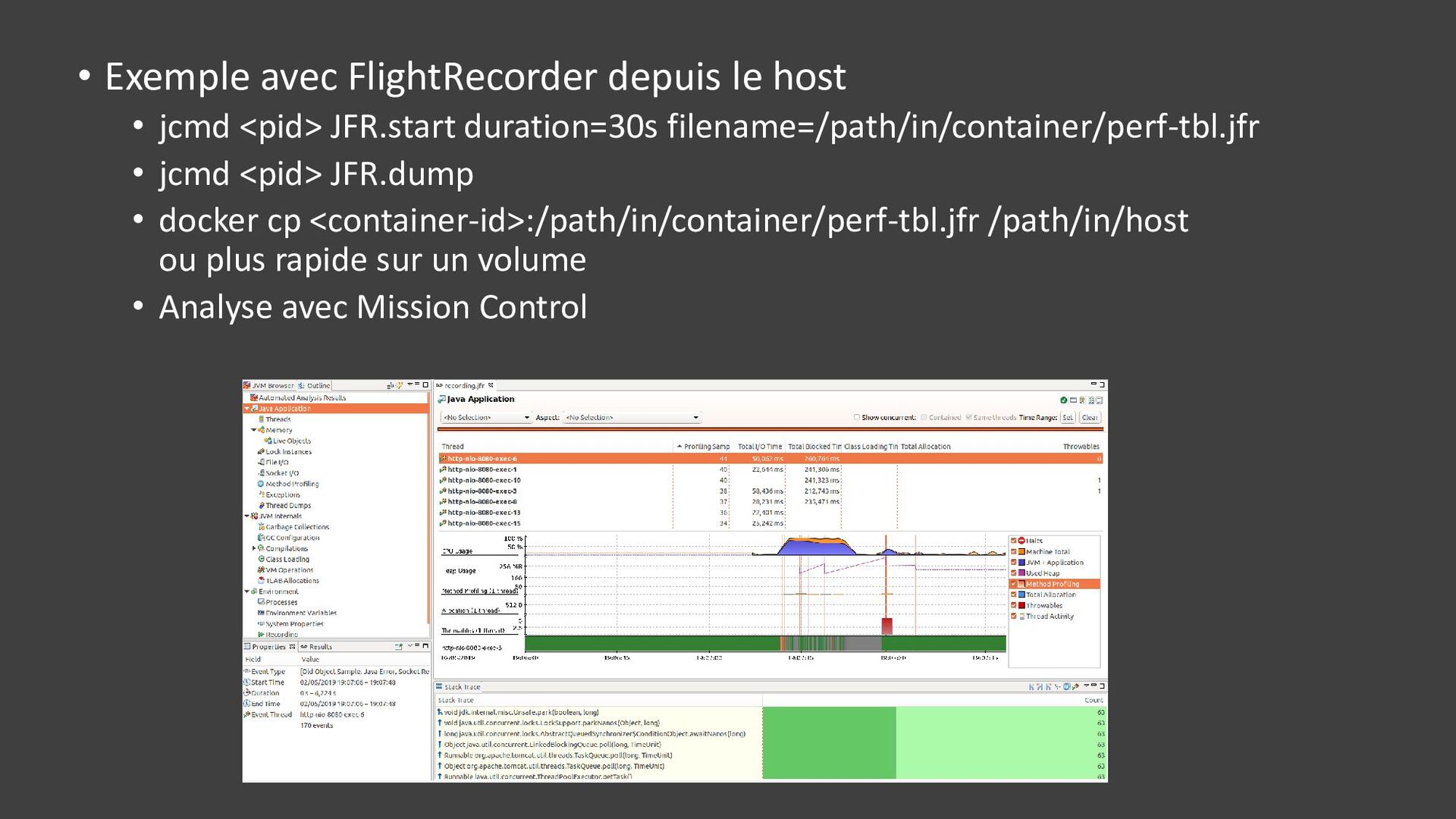{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
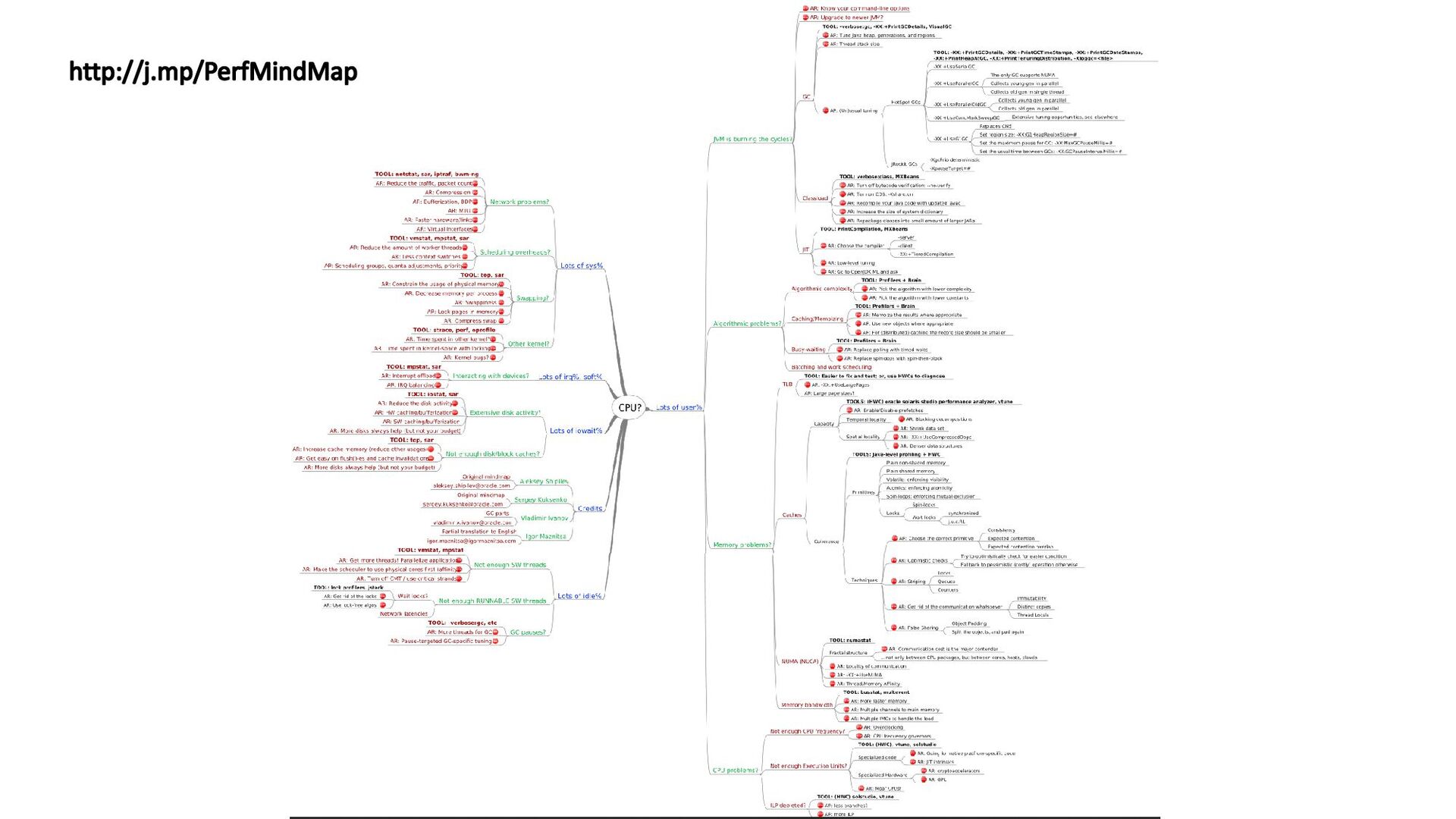{kind=link}