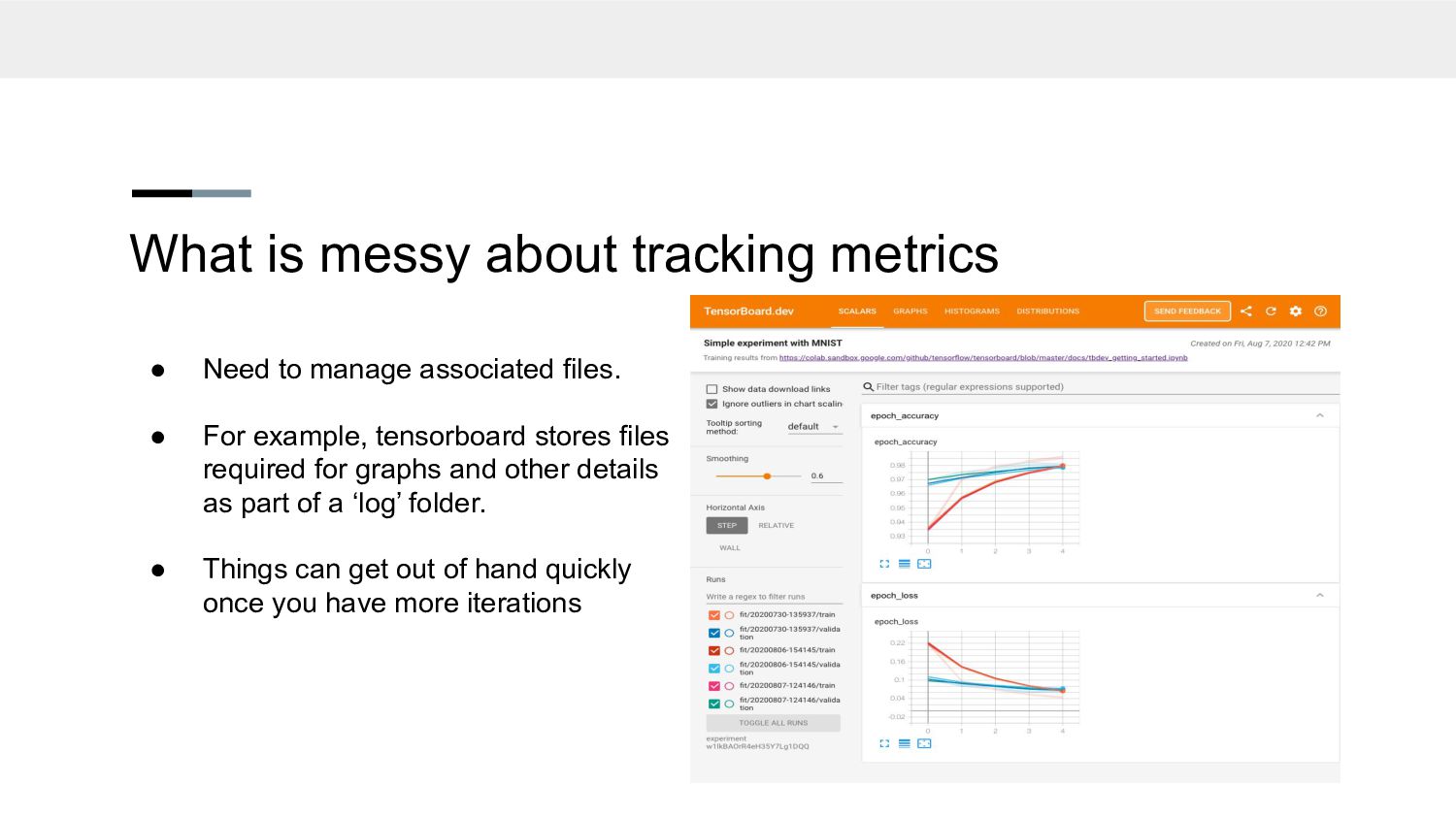
associated files. • For example, tensorboard stores files required for graphs and other details as part of a ‘log’ folder. • Things can get out of hand quickly once you have more iterations
2016, deepsense.ai won the Right Whale Recognition contest on Kaggle. • To collect the prize, the winning team had to provide source code and a description of how to recreate the winning solution. • The team took 3 weeks to recreate the winning solution. • Funnily enough the trauma made Deepsense.ai build Neptune.ai (similar tool to MLFlow)
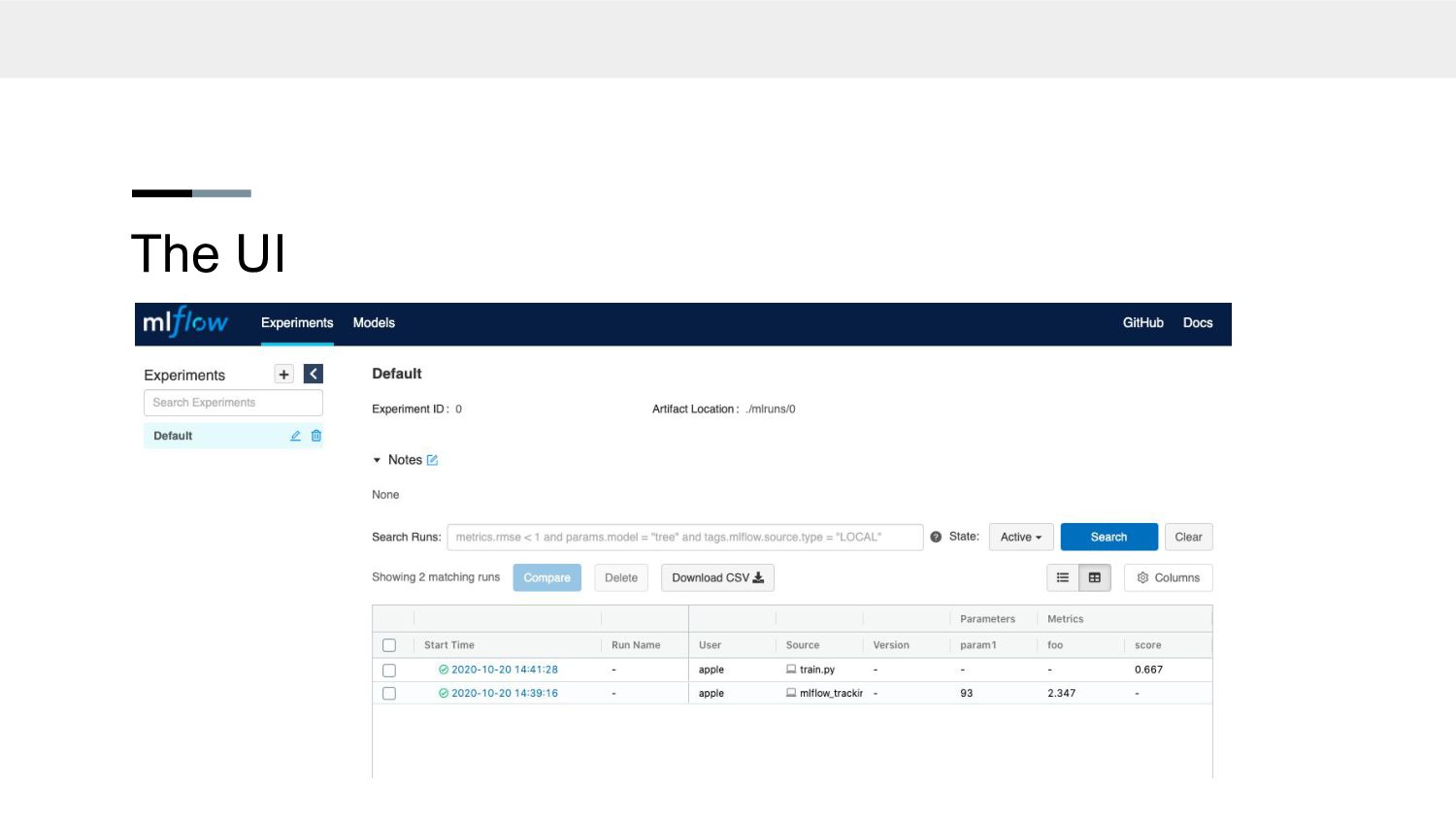
the run date • It’s nice but not simple on the eyes • Tag runs with a version number for reference • Multiple teams can run different experiments on the same server
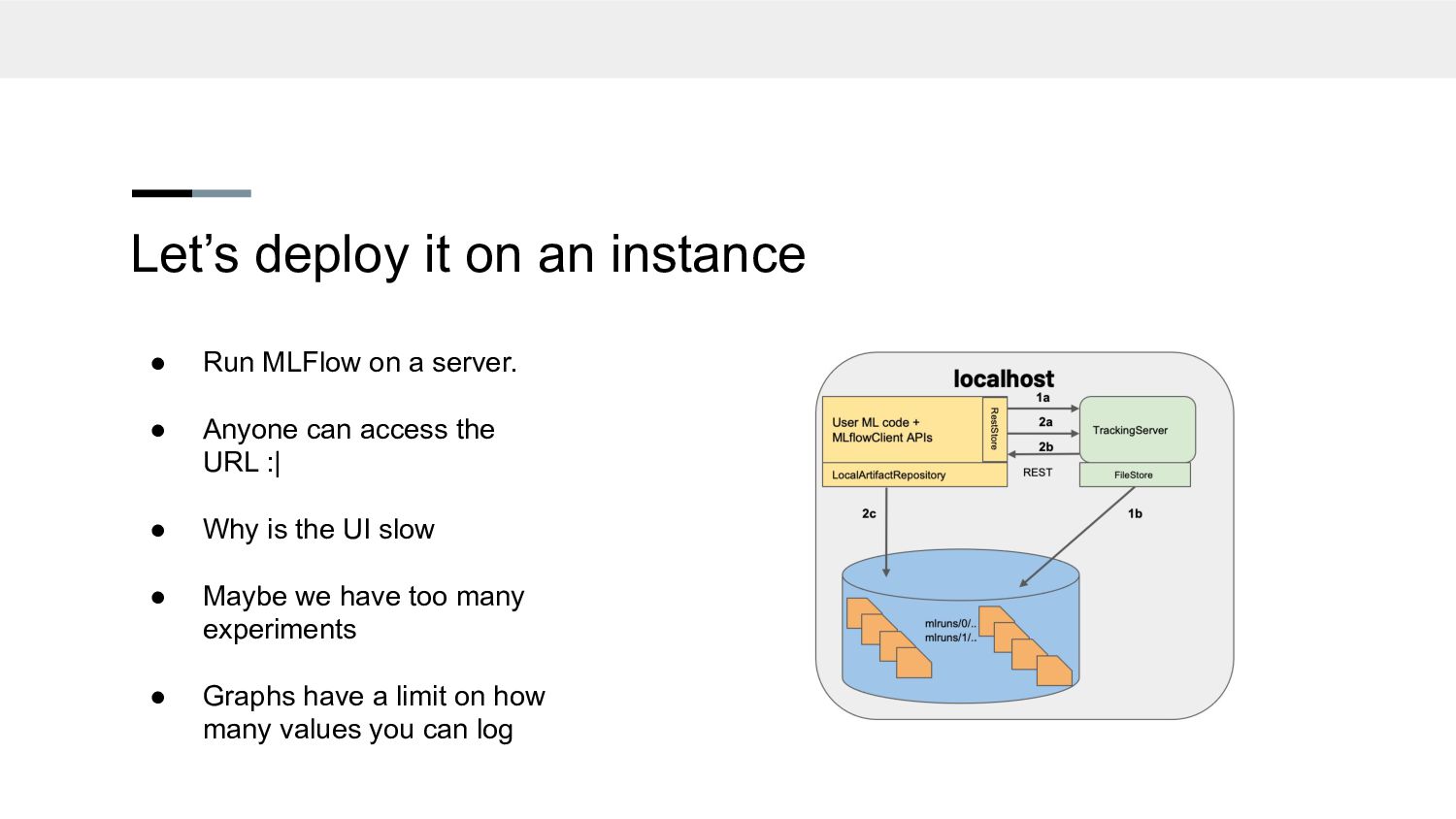
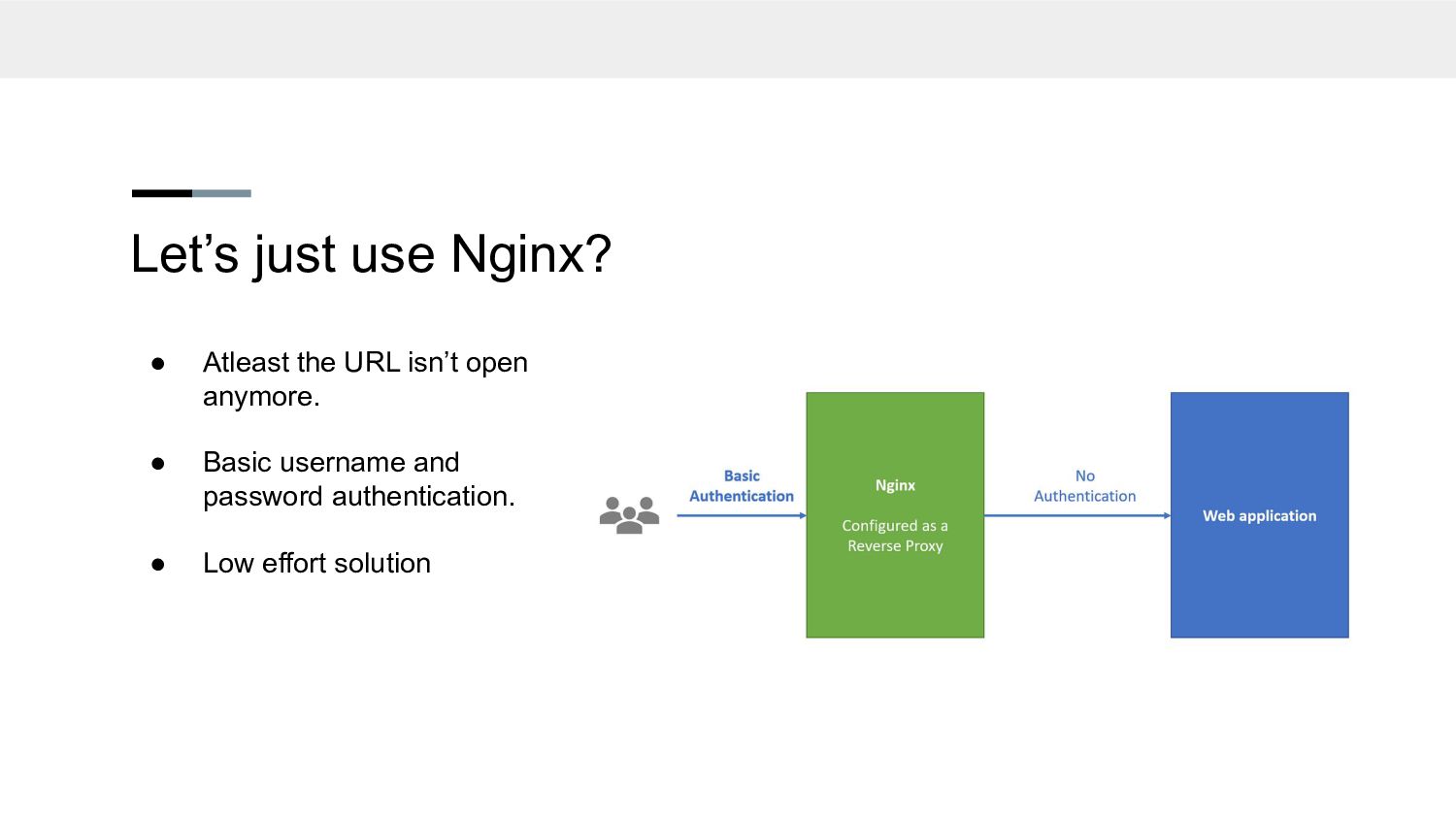
a server. • Anyone can access the URL :| • Why is the UI slow • Maybe we have too many experiments • Graphs have a limit on how many values you can log
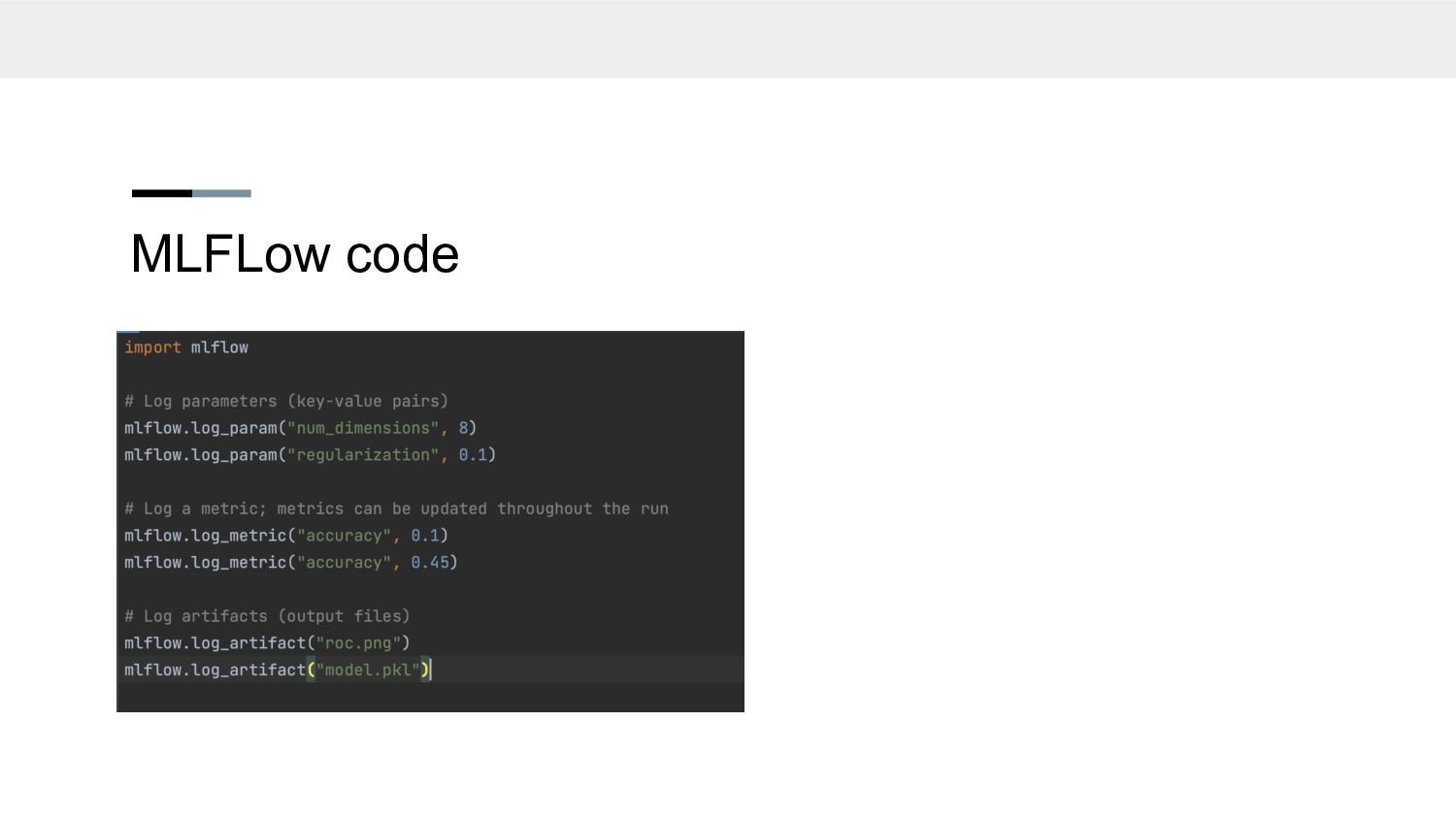
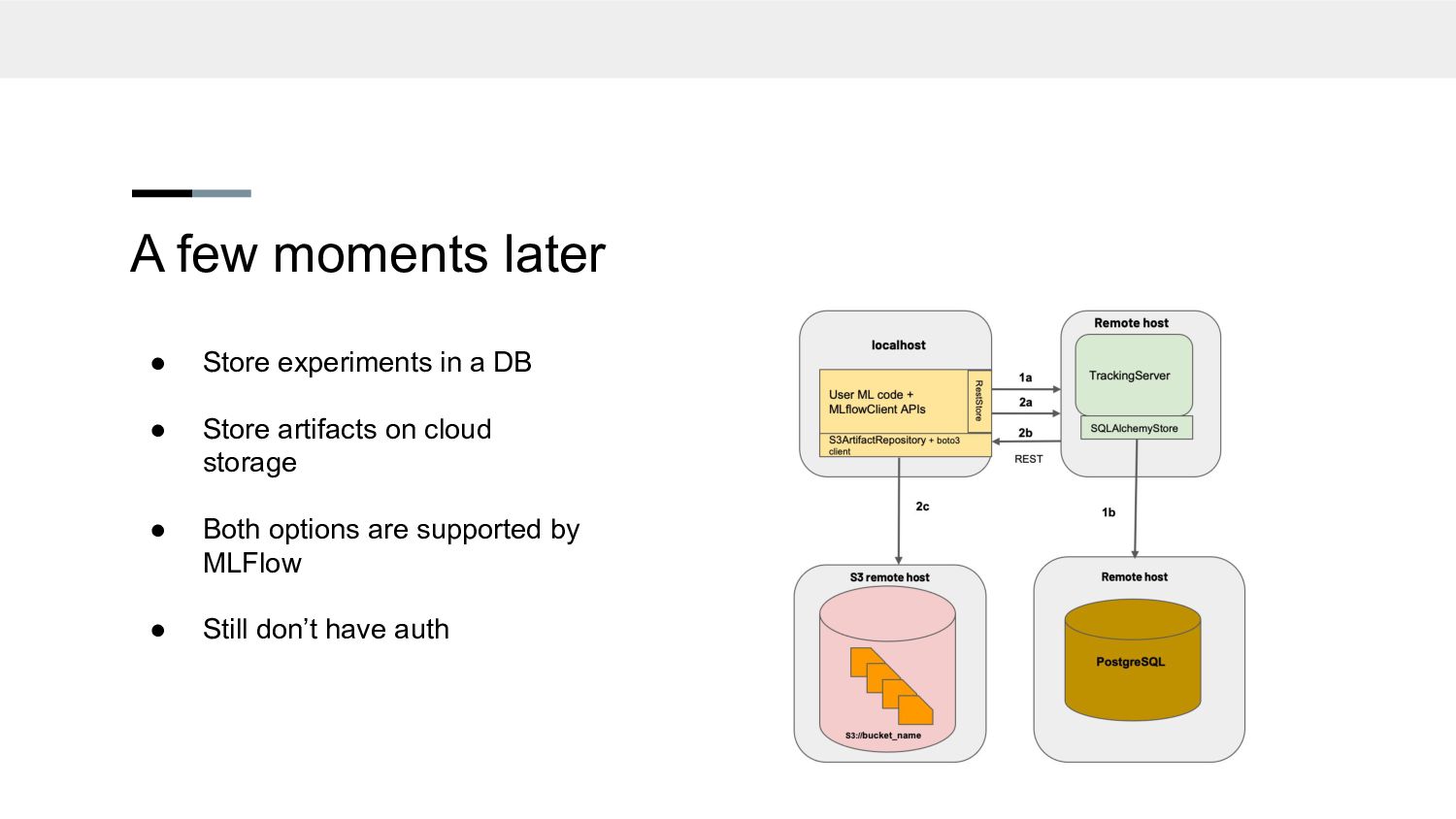
everything related to the experiment • Metrics, parameters, model artifacts • Easy access to details (RIP google sheets) • Number of iterations didn’t matter anymore • A proper goodbye to debugging nightmares
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Thanks! Twitter vikas_sshetty Email [email protected]](https://files.speakerdeck.com/presentations/aefdb554e5b84bb2ba64ddabdd2787a6/slide_22.jpg){kind=link}