Intro to machine learning and scikit-learn (with speaker notes)
A basic introduction to key concepts underpinning machine learning and provides useful resources to get started, suitable for someone new to the field. Slides presented at The App Business (Dec, 2017) and Socrates UK conference (June, 2018).
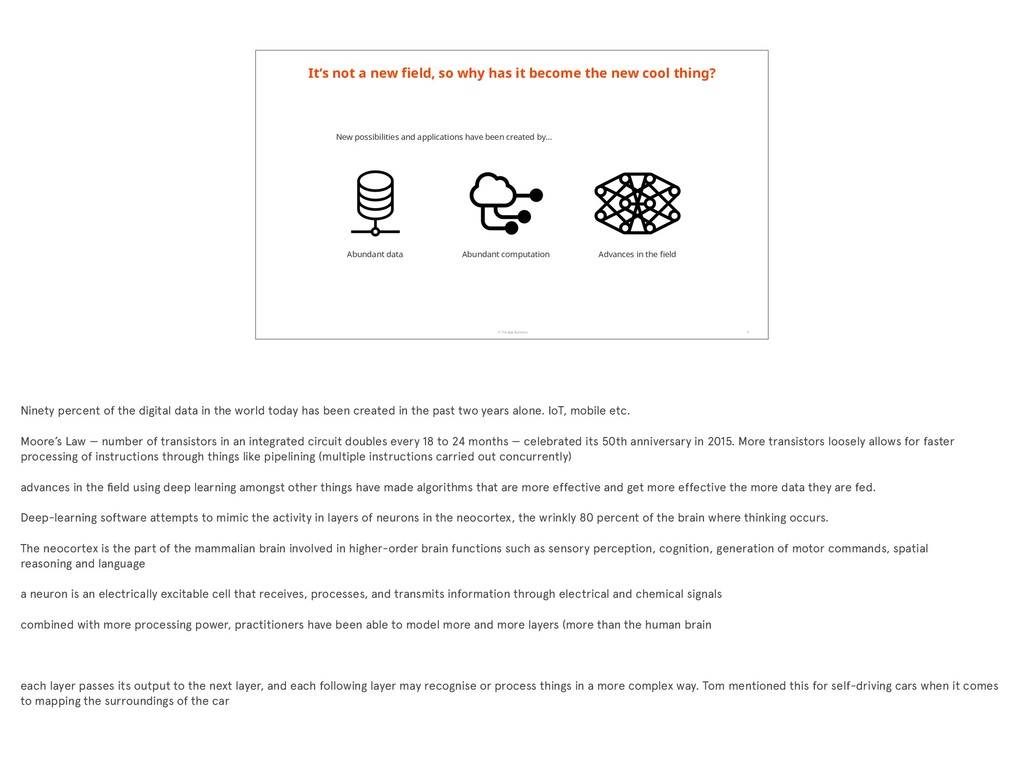
why has it become the new cool thing? 3 Abundant data Abundant computation Advances in the field New possibilities and applications have been created by… Ninety percent of the digital data in the world today has been created in the past two years alone. IoT, mobile etc. Moore’s Law — number of transistors in an integrated circuit doubles every 18 to 24 months — celebrated its 50th anniversary in 2015. More transistors loosely allows for faster processing of instructions through things like pipelining (multiple instructions carried out concurrently) advances in the field using deep learning amongst other things have made algorithms that are more effective and get more effective the more data they are fed. Deep-learning software attempts to mimic the activity in layers of neurons in the neocortex, the wrinkly 80 percent of the brain where thinking occurs. The neocortex is the part of the mammalian brain involved in higher-order brain functions such as sensory perception, cognition, generation of motor commands, spatial reasoning and language a neuron is an electrically excitable cell that receives, processes, and transmits information through electrical and chemical signals combined with more processing power, practitioners have been able to model more and more layers (more than the human brain each layer passes its output to the next layer, and each following layer may recognise or process things in a more complex way. Tom mentioned this for self-driving cars when it comes to mapping the surroundings of the car
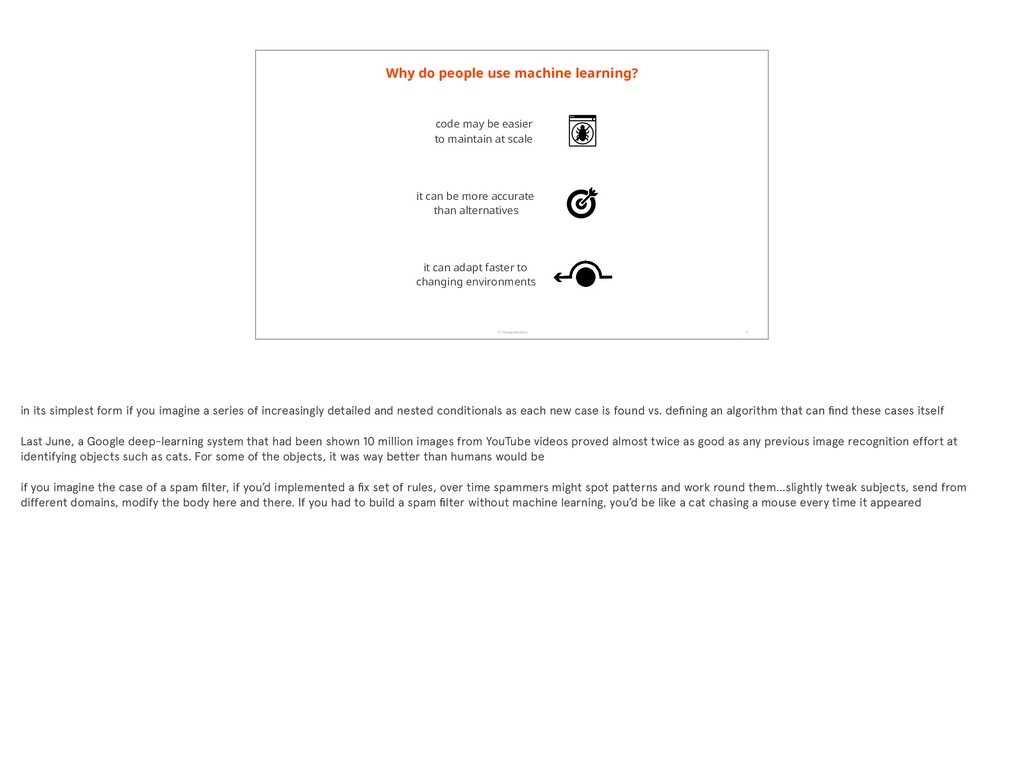
4 code may be easier to maintain at scale it can be more accurate than alternatives it can adapt faster to changing environments in its simplest form if you imagine a series of increasingly detailed and nested conditionals as each new case is found vs. defining an algorithm that can find these cases itself Last June, a Google deep-learning system that had been shown 10 million images from YouTube videos proved almost twice as good as any previous image recognition effort at identifying objects such as cats. For some of the objects, it was way better than humans would be if you imagine the case of a spam filter, if you’d implemented a fix set of rules, over time spammers might spot patterns and work round them…slightly tweak subjects, send from different domains, modify the body here and there. If you had to build a spam filter without machine learning, you’d be like a cat chasing a mouse every time it appeared
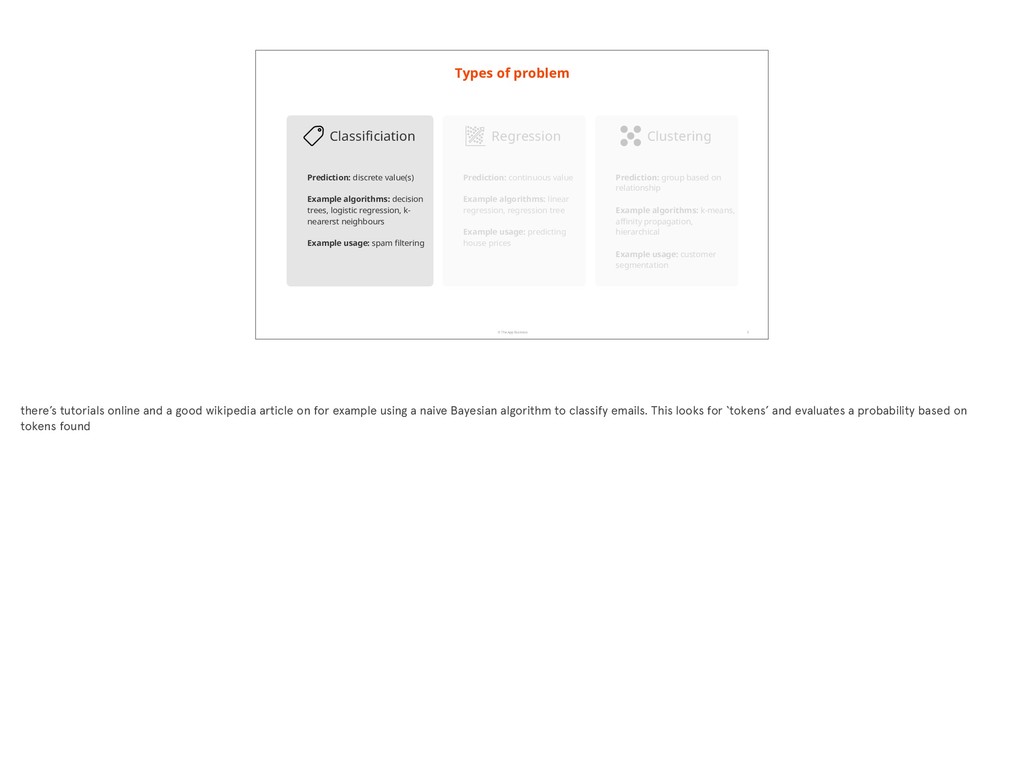
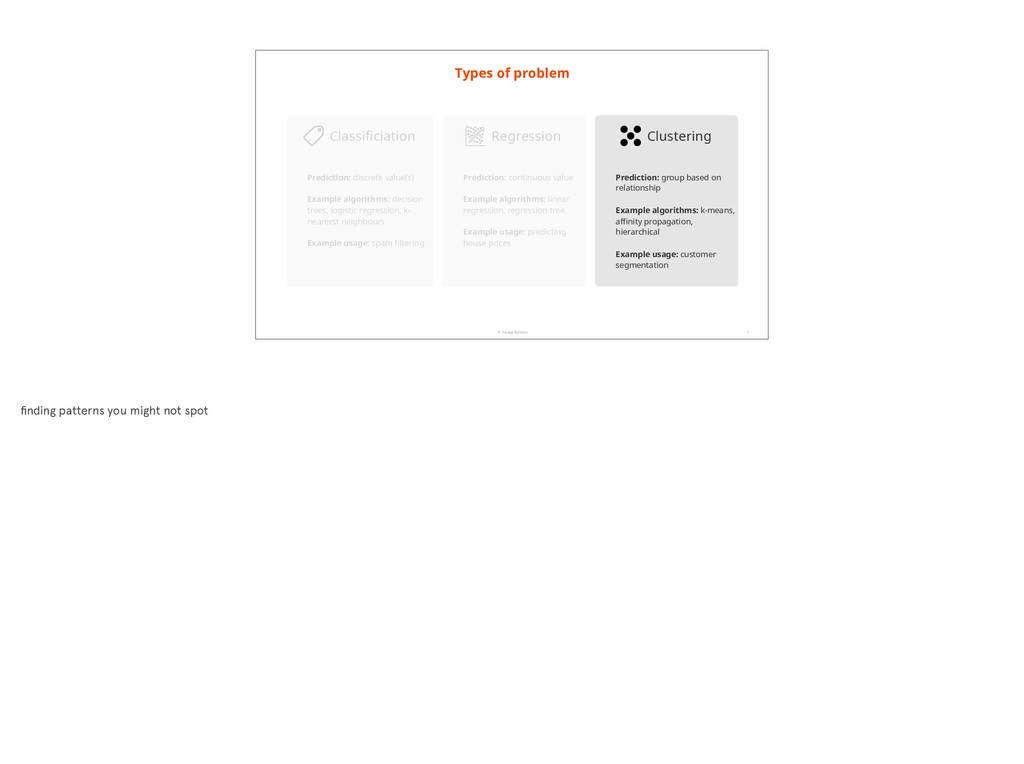
value(s) Example algorithms: decision trees, logistic regression, k- nearerst neighbours Example usage: spam filtering Prediction: continuous value Example algorithms: linear regression, regression tree Example usage: predicting house prices Regression Classificiation Prediction: group based on relationship Example algorithms: k-means, affinity propagation, hierarchical Example usage: customer segmentation Clustering there’s tutorials online and a good wikipedia article on for example using a naive Bayesian algorithm to classify emails. This looks for ‘tokens’ and evaluates a probability based on tokens found
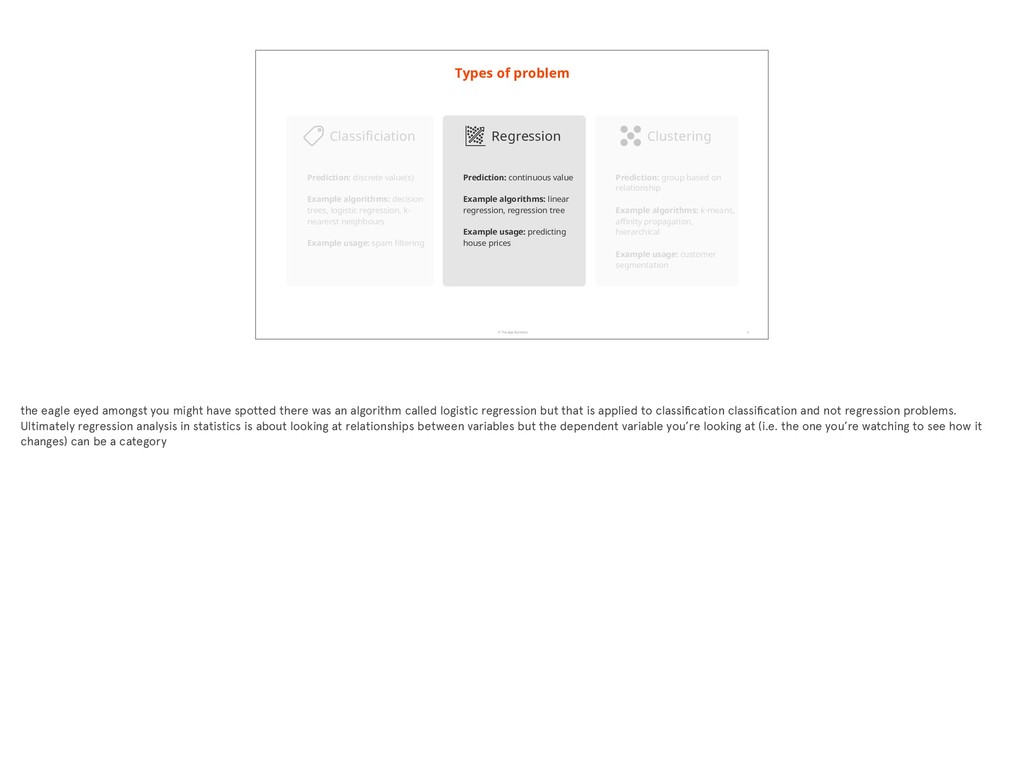
value(s) Example algorithms: decision trees, logistic regression, k- nearerst neighbours Example usage: spam filtering Prediction: continuous value Example algorithms: linear regression, regression tree Example usage: predicting house prices Regression Classificiation Prediction: group based on relationship Example algorithms: k-means, affinity propagation, hierarchical Example usage: customer segmentation Clustering the eagle eyed amongst you might have spotted there was an algorithm called logistic regression but that is applied to classification classification and not regression problems. Ultimately regression analysis in statistics is about looking at relationships between variables but the dependent variable you’re looking at (i.e. the one you’re watching to see how it changes) can be a category
value(s) Example algorithms: decision trees, logistic regression, k- nearerst neighbours Example usage: spam filtering Prediction: continuous value Example algorithms: linear regression, regression tree Example usage: predicting house prices Regression Classificiation Prediction: group based on relationship Example algorithms: k-means, affinity propagation, hierarchical Example usage: customer segmentation Clustering finding patterns you might not spot
and comprehensive data Subtitle 9 Source: @mrogati most organisations aren’t ready to apply machine learning and any kind of advanced data science because they a). don’t capture data, b) have poor quality, duplicated, erroneous data (I remember huge projects in my time in banking to define the ‘golden source’ for data on trades, for example, to alleviate this problem) and/or c). can’t capture data in a repeatable and fast enough way anyone worked in environments where systems are a black box, somethings wrong but you’ve no idea what? Or where you wish you had data on something but you don’t so you just use old processes and best guesses? ever started to rely on tooling that someone hacked together on their own over a few months? it’s got no tests and they just did it in any way that worked for the initially small dataset. what happens when that breaks and that person is no longer at the company? or when you load more data in? anyone worked in data warehouse environments? Or come across ETL tools? there’s always masses of effort invested into cleaning data, detecting anomalies etc. anyone worked with analysts or scientists who are expected to be SQL experts or know python when their background isn’t in programming? Anyone found worked at companies who generate loads of analytics from products (using tools like Google Analytics) but then don’t know what to do with it? Taking the example of self driving cars, many of the companies developing cars have to spend a lot of time driving around recording roads etc. to build up training data, they have to do so in controlled conditions to carefully manage the data quality, and so on
training data includes desired solutions e.g. example spam/not spam messages Unsupervised training data doesn’t have labels or any penalties/rewards to guide e.g. suggest similar news articles Semi-supervised a mixture of the above two e.g. photo tagging where users tags a person in one picture & others with them found Reinforcement receive rewards and penalties from environment and learns using those e.g. show/hide this ad on Facebook unsupervised example could use clustering, detecting relationships between articles that you haven’t spotted you can also combine these….like with the semi supervised example, or imagine the news article example but with the option for users to feedback and say they were/weren’t interested in the articles suggested.
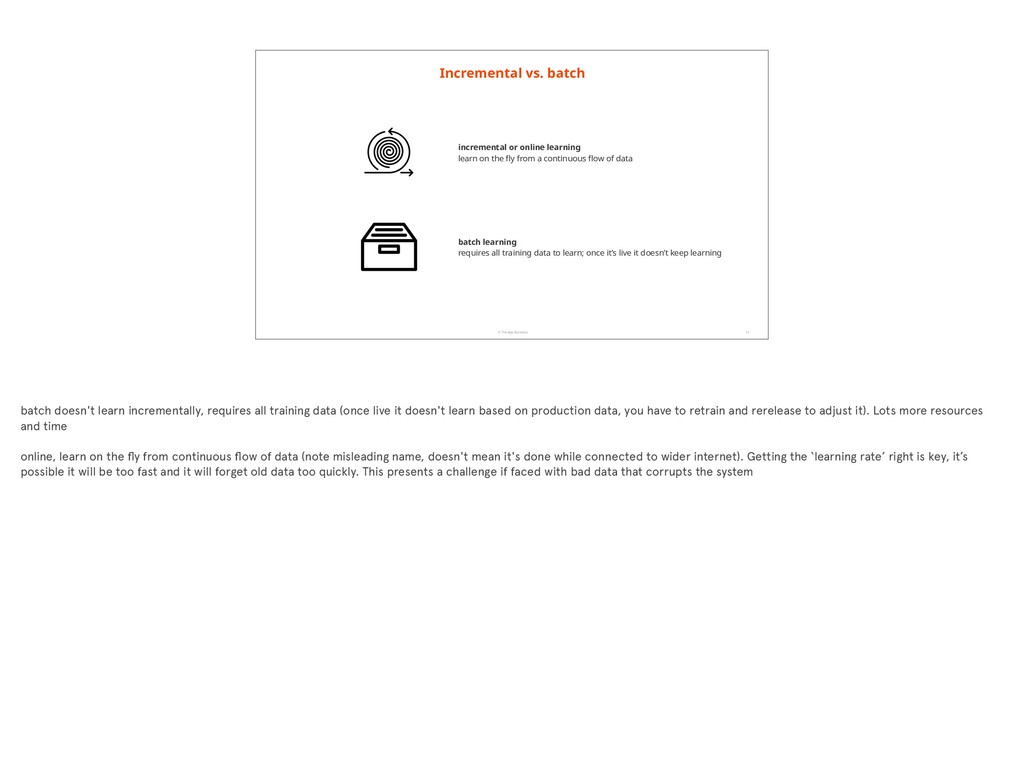
online learning learn on the fly from a continuous flow of data batch learning requires all training data to learn; once it’s live it doesn’t keep learning batch doesn't learn incrementally, requires all training data (once live it doesn't learn based on production data, you have to retrain and rerelease to adjust it). Lots more resources and time online, learn on the fly from continuous flow of data (note misleading name, doesn't mean it's done while connected to wider internet). Getting the ‘learning rate’ right is key, it’s possible it will be too fast and it will forget old data too quickly. This presents a challenge if faced with bad data that corrupts the system
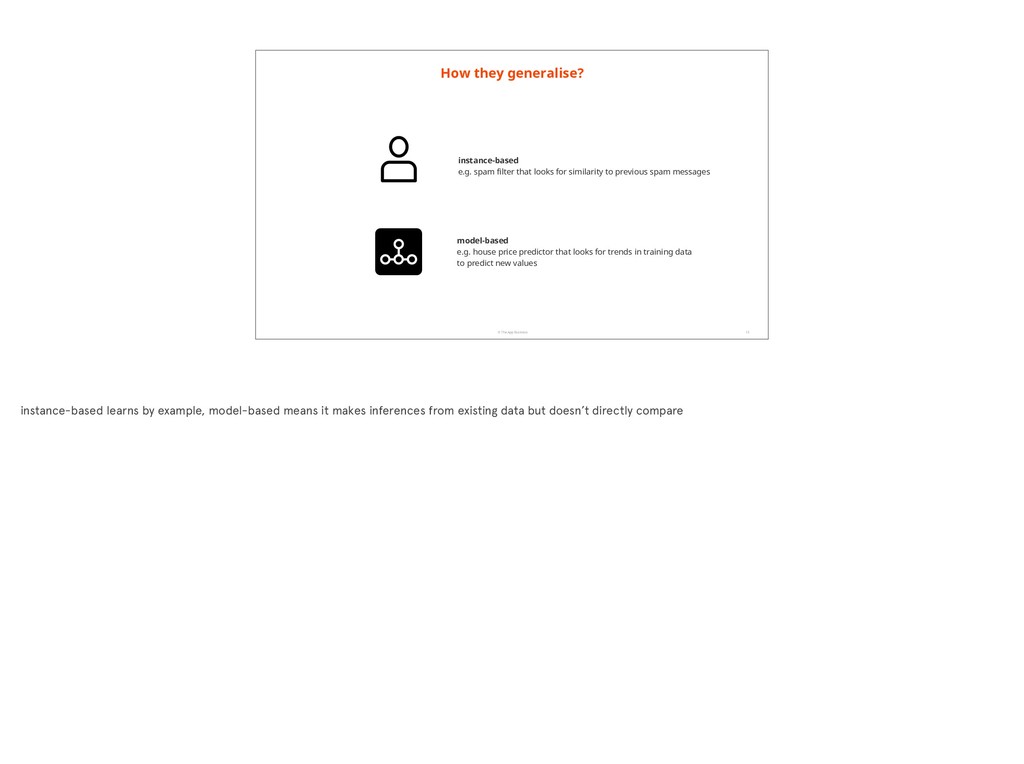
spam filter that looks for similarity to previous spam messages model-based e.g. house price predictor that looks for trends in training data to predict new values instance-based learns by example, model-based means it makes inferences from existing data but doesn’t directly compare
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}